MERL:Multimodal Event Representation Learning in Heterogeneous Embedding Spaces
오늘 리뷰할 논문은 어떤 하나의 Event를 Embedding 공간안에 표현하여 학습을 시키는 방법론, Event Representation 방법에 대해 소개한 논문입니다.
Abstract
먼저 Event representation에 대하여 간단히 설명하겠습니다. 예시로, 아래 3개의 문장이 있습니다.
- Person X threw basketball.
- Person Y threw bomb.
- Person Z attacked embassy.
이 때, 우리는 비슷한 의미를 가진 문장은 가까운 공간에 임베딩하고 비교적 다른 의미를 가진 문장을 먼 공간에 임베딩해야 할것입니다.

2번 문장과 3번 문장은 테러와 관련된 event이므로 비슷한 공간에 임베딩을 하고, 1번 문장은 다른 두 문장과는 조금 다른 의미를 가지므로 먼 공간에 임베딩시킵니다. 이러한 방식의 딥러닝을 Event Representation Learning이라고 합니다.
하지만 여전히 textual description에만 기반하여 event간의 미묘한 의미의 차이점을 학습하는 것은 어려운 과제입니다.
이를 해결하기 위해, 이미지와 텍스트를 동시에 사용하여 event representation을 학습하는 MERL(Multimodal Event Representation Learning)을 제안합니다.
이미지는 사건을 이해하는데에 비교적 직관적인 관점을 더해준다고 합니다.
Text는 가우시안 인코더로 임베딩하고, 이미지는 visual event componentaware image encoder로 임베딩합니다. 이 두 개의 임베딩 공간을 조정하기 위해 새로운 함수를 도입하여 다양한 실험을 수행합니다. 그 결과, MERL을 사용할 때 성능이 좋았다고 합니다.
Introduction
자연어처리에서는 언어의 이해가 중요하기때문에 텍스트에서 사건을 나타내는 event 구조를 구성하는 것이 중요합니다. event를 컴퓨터가 이해할 수 있는 형식으로 전송하는 것은 지금까지 event를 low-dimensional dense vector로 표현해왔습니다.
이후, Event Represention Learning은 주어와 동사, 목적어 세개의 triple로 표현하고 학습시켰을 때 극적인 발전이 있었습니다.
하지만 모델이 text에만 기반하여 사건간의 미묘한 의미 차이를 학습하는 것은 여전히 어려운 과제였습니다. 그 이유는 같은 단어가 서로 다른 문장에서 다른 의미로 쓰일 수 있고, 또 다른 단어더라도 서로 다른 문장에서 비슷한 의미로 쓰일 수 있는데 이러한 상황 embedding이 어렵기 때문입니다.
이러한 문제를 해결하기 위한 방식이, Multimodal을 사용하는 방식입니다. 이는 text의 triple(주어, 동사, 목적어)에 더하여 그 event와 관련된 이미지를 같이 embedding하여 정확도를 높이는 학습법입니다.

위 사진과 같이 각각 triple과 함께 해당 사건을 표현하는 이미지를 같이 학습시킵니다.
이 방식에 대해, 본 논문의 저자는 image와 triple(text)을 같은 공간에 매핑하는것이 부적절하다고 지적합니다.
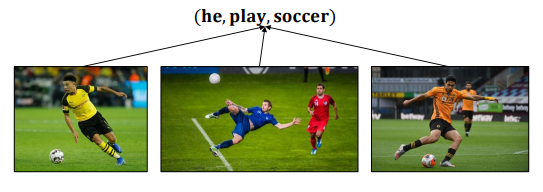
그 이유는 텍스트에 비해 같은 사건을 다루는 이미지는 상대적으로 너무 다양하기 때문입니다. 위 사진에서도, 축구를 하는 이미지는 자세나 배경을 살짝 바꾸면 무한대의 이미지를 매핑할 수 있습니다.
그래서 event triple과 event image는 다른 공간에 매핑되어야 하고, text는 하나의 포인트가 아니라 이미지 전체를 나타낼 수 있는 distribution의 형태로 나타내야 한다고 제안합니다.
- triple : density embedding
- image : point embedding
- triple과 image는 서로 다른 공간에 매핑
Methodogies
먼저 MERL의 전체적인 architecture를 소개하고 triple encoder와 image encoder에 대한 세부적인 내용을 소개합니다. 그 후 training framework를 설명하겠습니다.
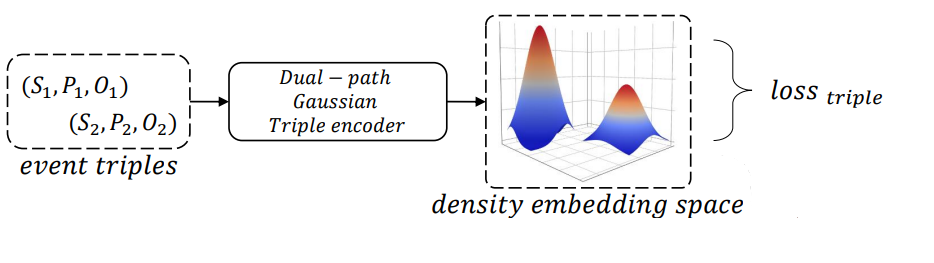
Multimodal Event Representation Learning on Heterogeneous Embedding Spaces
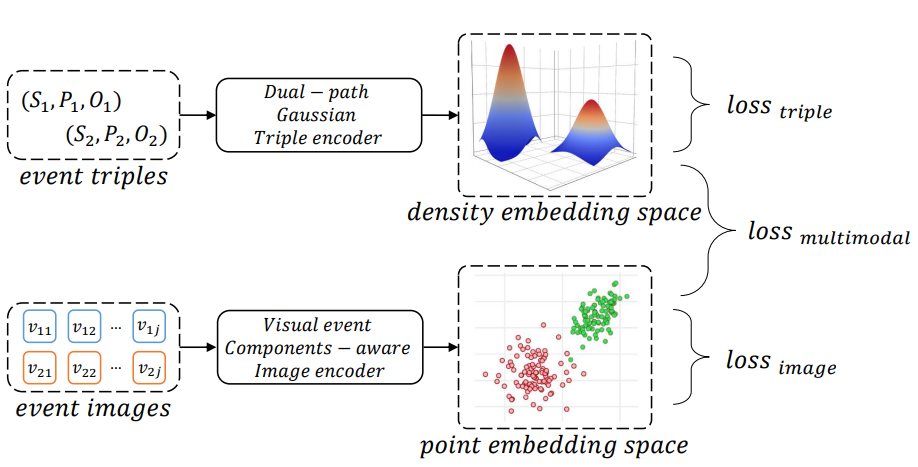
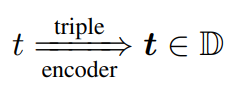
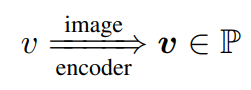
위 그림은 MERL의 전체적인 framework입니다. 앞서 말씀드렸듯이 event triples를 Dual-path Gaussian Triple encoder를 통해 density embedding space에 embedding하고, loss를 구합니다.
Dual-path Gaussian Triple Encoder
앞서 봤던 Triple Encoder의 구조를 다시 보겠습니다. 우리는 event triples(S, P, O)를 받아서 하나의 Gaussian distribution으로 표현을 해야합니다. 이를 위해서 distribution의 평균과 표준편차를 알아내야 합니다.
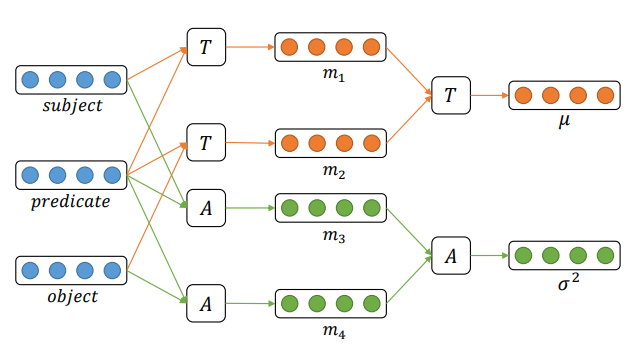
여기서 인코더 모델을 Dual-path라고 칭하는데, 평균을 예측하는 모델과 표준편차를 예측하는 모델이 따로 병렬적으로 존재하는데 각각의 예측 인코더가 2개의 path로 이루어져있기 때문입니다.
평균이 의미하는 바는 Gaussian Embedding 공간 안에서 위치를 나타냅니다. 이 mean vector는 subject와 predicate의 관계, predicate와 object의 관계에 따라서 Embedding공간 안에서 위치가 바뀐다고 가정합니다. 그래서 이러한 관계를 임베딩할 수 있도록 아래 식과 같은 텐서를 학습시킵니다.
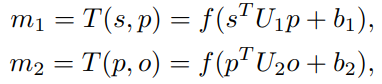
m1 식은 주어와 동사간의 관계를 계산하고 m2는 동사와 목적어의 관게를 계산합니다. 이렇게 계산한 두 개의 관계를 다시한번 계산합니다.
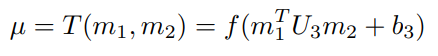
이렇게해서 총 Mean vector를 계산합니다.
표준편차를 계산할 때는 triple이 얼만큼의 범위를 다루는지를 반영합니다. 이 논문에서는 표준편차는 주어와 목적어는 별로 중요하지 않고 동사에 따라 분포가 결정된다고 합니다. 그래서 굳이 관계를 임베딩하지 않고,
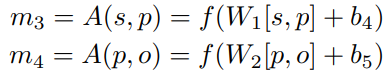
동사와 주어를 concat해서 NLP레이어에 넣어주고 동사와 목적어를 concat해서 NLP레이어에 넣어준 후
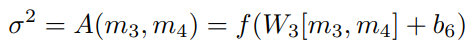
이 두개를 concat해서 분산을 구하도록 설정합니다.
Visual Event Components-aware Image Encoder
이미지는 하나의 point와 매핑시켜 하나의 triple의 distribution과 같은 event일 때 이 두 개가 비슷한 분포를 띄도록 학습을 시킬 것입니다. 먼저 이미지를 embedding하고, 여기에서 주어, 목적어, 동사를 뽑아내기 위해 pre-training을 진행합니다.
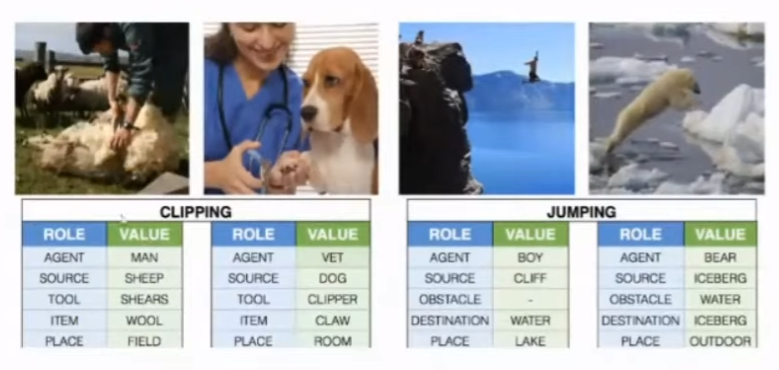
pre-training을 진행하기 위한 데이터로는 ImSitu dataset을 사용했고 이는 위의 자료와 같이 구성되어있습니다.
첫 번째 사진을 보면, 한 남자가 양의 털을 깎고 있습니다. 여기서 activity는 clipping이 되고 agent는 man이 되며 source(목적어)는 sheep이라고 되어있습니다. 여기에서 필요한 것은 주어,동사,목적어이므로 이미지에 대해 agent, source, activity 세가지를 뽑아와서 학습을 시킵니다.
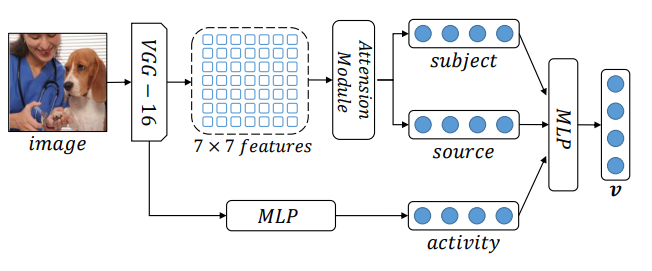
처음에 이미지를 VGG net을 사용하여 글로벌벡터를 뽑아내고, 7x7 convolutional fetures를 사용하여 local fetures를 뽑아냅니다. local fetures에 대해 subject 따로 source 따로 Attention 모델을 적용합니다. 사실 주어와 목적어는 사진을 보면 확실히 나와있는 정보이기 때문에 이러한 기법을 사용한 것 같습니다. (주어의 위치에 집중할지, 목적어의 위치에 집중할지를 attention을 활용하여 구함)
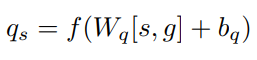
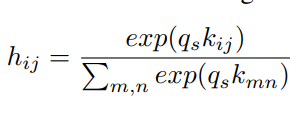
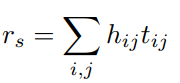
이와 달리 동사에 해당하는 단어는 이미지 전체의 흐름을 이해해야 하기 때문에 이미지 자체를 MLP에 넣어서 activity를 임베딩합니다. 이렇게 세 개를 뽑고 각각을 classification하는 pre-training 과정을 진행합니다.
위 예시에서 subject의 답은 수의사가 되고, object는 강아지, activity는 clipping이 되도록 학습시킵니다.
그 후 세 벡터를 조합해서 point vector를 매핑시킬때는 하나의 MLP 레이어를 학습시키게 됩니다. 나머지는 사전학습을 하고, 모델에서는 지막 layer만 학습되는 것입니다.
이 때 MLP layer는 다음과 같이 사전학습 결과를 concat한 후 적용시키게 됩니다.
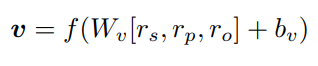
이렇게 Point vector를 구할 수 있습니다.
Training
Training은 총 3단계의 과정이 있습니다.
- triple을 임베딩하는 loss를 적용
- image를 임베딩하는 loss를 적용
- 최종적으로 이 두 개의 다른 공간을 매핑하는 loss를 적용
먼저 triple loss는 max-margin loss를 사용합니다.
진짜로 비슷한 event와 유사도를 계산했을 때 유사도가 높아야 하고 (positive sample) 전혀 다른 embedding vector와 similarity를 계산했을 때에는 낮아야 합니다.
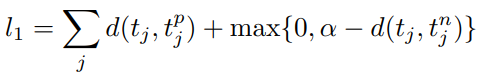
triple은 event 하나를 distribution에 매핑하기 때문에 앞서 구한 가우시안 분포의 평균, 표준편차를 이용해서 두 개의 distribution간의 유사도를 구합니다.
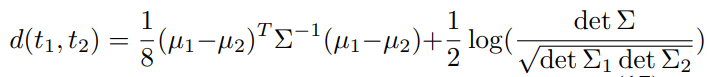
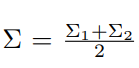
이 loss를 낮추는 방향으로 학습이 진행됩니다.
다음으로 image loss 또한 max-margin loss를 적용합니다.
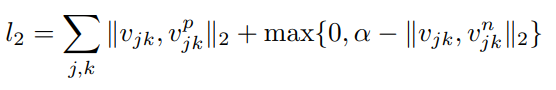
이 때는 point vector이기 때문에 유클리디안 거리를 이용하여 loss를 계산합니다.
마지막 loss는 triple의 가우시안 분포와 그 triple에 해당하는 여러가지 이미지가 있을 때 그 이미지가 띄고 있는 분포의 KL-Divergence loss를 구해서 이 두개의 distribution이 유사하도록 학습합니다.
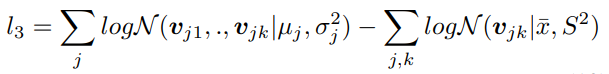
이렇게 세 개의 loss를 적용합니다.
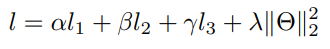
위 식은 최종 objective function입니다. (loss들의 가중합 + 모든 파라미터들의 l2norm)
다음은 본 모델의 pseudocode입니다.

Experiment
데이터셋은 1,000개의 event triple이 positive sample과 negative sample로 묶여있습니다.
positive sample e.g. , police catch robber / authorities apprehend suspect
negative sample e.g. , police catch robber / police catch disease
용의자를 체포한 같은 사건은 positive sample로 묶여있고, 주체와 동사는 같은데 전혀 다른 event인 경우 negative sample입니다.
이 데이터셋을 확장시킵니다. 구글 이미지에 넣어서 사람이 걸러서 triple과 가장 비슷한 10개의 이미지를 매핑시켜줍니다. 문장도 3,000개로 확장하였고, 따라서 30,000개의 event image를 사용하여 학습을 진행했습니다.
3가지의 Task를 다룹니다.
Multimodal Event Similarity
같은 event를 다루는 다른 이미지에 대해 유사성을 얼마나 잘 판단하는지!
아래 두 가지 데이터셋에 대해 테스트를 진행합니다.
- Multimodal hard similarity dataset
- Transitive sentence similarity dataset
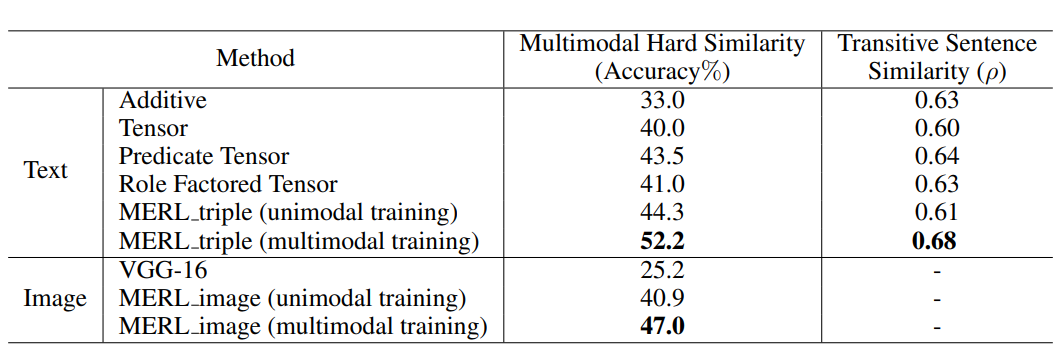
그 결과 본 논문에서 제안한 MERL 모델이 가장 성능이 높습니다.
Script Event Prediction
하나의 대본에서 다음 장면이 뭔지 예측!
이 task에 최적화된 모델을 사용하는데, Embedding만 MERL로 대체해서 성능을 평가했습니다. Multiple choice narrative cloze dataset을 사용했습니다.

여기서도 MERL이 성능을 높였습니다.
Cross-modal Event Retrieval
event triple이 주어졌을 때 가장 유사한 이미지를 찾아주는 task (구글이미지검색과 비슷)
Cross-modal event retrieval dataset을 사용했습니다.

먼저 triple을 넣고 비슷한 triple을 retrieval하는 task에서는 다소 떨어진 성능을 보였는데 비교 method가 text의 선후관계를 사용하여 embedding하는 방식이라고 합니다.
