Transformer-xl: Attentive language models beyond a fixed-length context

 Transformer-XL ICLR Open Review
Transformer-XL ICLR Open Review
Transformer-XL은 Language Model이 긴 sequence를 받을 수 있는 방법론을 제시한 모델로 구글이 2019 ICLR에서 reject을 당한 후에 2019 ACL에 accept된 논문이다. 당시 ICLR open review를 살펴보면, 과연 더 긴 sequence를 받아 성능이 향상된 것이 실질적인 down-stream task와 의미있는 생성으로 이어질 수 있느냐에 대한 의문을 제기한다. 따라서 해당 저자들은 Transformer-XL을 다음에 발표할 XL-NET이라는 모델로 발전시켜 2019 NIPS에 accept시키게 된다.
1. Introduction
Long-Term dependency를 요구하는 Language Modeling(향후 글에서는 축약어인 LM으로 대체체합니다.)은 수많은 unsupervised pretraining의 목적함수로 사용되었다. 초반에는 RNN으로 구현되었던 LM은 long-term dependency를 해결하기 위한 Gate의 도입(LSTM,GRU), 원타임으로 멀리 있는 token에 접근가능한 Attention의 도입으로 성능향상을 이어왔다. 하지만 Transformer기반 LM 모델도 결국 Attention에 의한 연산량 증가로 512나 1024 Token까지 밖에 받지 못하는 한계가 존재한다.
결국 문장의 맥락적 의미를 고려하지 않고 단지 Max_Length에 맞춰서 Token을 잘라서 훈련할 수 밖에 없는 환경은 LM의 진정한 능력인 Long-Term dependency학습에 한계가 있다.
(ex. 각 Segment길이가 512라고 할 때, [[Segment01], [Segment02], [Segment03]]로 이루어진 문서에서 기존의 LM이 Segment02를 학습할 때 Segment01의 이전 맥락을 전혀 활용하지 못한다.)
이러한 문제들을 하기 위해서 저자들은 아래의 2가지 테크닉이 추가된 Transformer-XL (XL=Extra Large)을 제시한다.
1. Segment-Level Recurrence with State Reuse
말그대로 이전 Segment(t-1)의 Hidden State를 활용해 현재 Segment(t)에서의 LM을 수행하는 방법을 말한다. 본 논문과 추후 XL-NET에서 저자들은 이전 Segment를 'Memory'라고 명명한다.
2. Relative Postional Encoding (PE)
이전 Segment들(t-1, t-2, ...)을 활용하면, PE(Positional Encoding을 앞으로 PE로 대체합니다) 설계에 있어서 문제가 생겨버립니다. (ex. Segment02의 PE는 Segment01의 PE와 다라야 한다) 따라서 저자들은 기존의 Word Embedding에 PE를 더하는 방식이 아닌 (PE의 본질 : Position을 고려하는 이유는 0,1,2와 같은 순차적인 정보보다 토큰 간의 거리 정보를 넣어주기 위함), Attention 연산 시에 Token간의 상대적인 위치를 반영하도록 하는 새로운 방법론을 제시한다.
2. Related Work
기존 AR Model들이 발전해온 간략한 줄거리에 대해서 작성이 되어 있어서 제외했습니다..!!
3. Model
Auto-Regressive 모델은 이전 time-step의 모든 hidden states를 input으로 넣어서 현재 time-step에 대한 logit을 계산하는 모델이다.
3.1 Vanilla Transformer Language Modeling
Transformer에서 LM을 구현할 때의 'Key'는 결국 어떻게 매우 긴 1~t-1개의 input들을 t번째 토큰 예측을 위한 1차원 벡터로 사상하는가 이다. 지금까지는 단순히 max_len을 기준으로 input으로 나누어서 (논문에서는 이를 segment라고 표기) 학습시켰다. 논문에서는 이러한 방법론을 'vanilla transformer'라고 하며, 이러한 방법들은 아래의 한계가 있다.
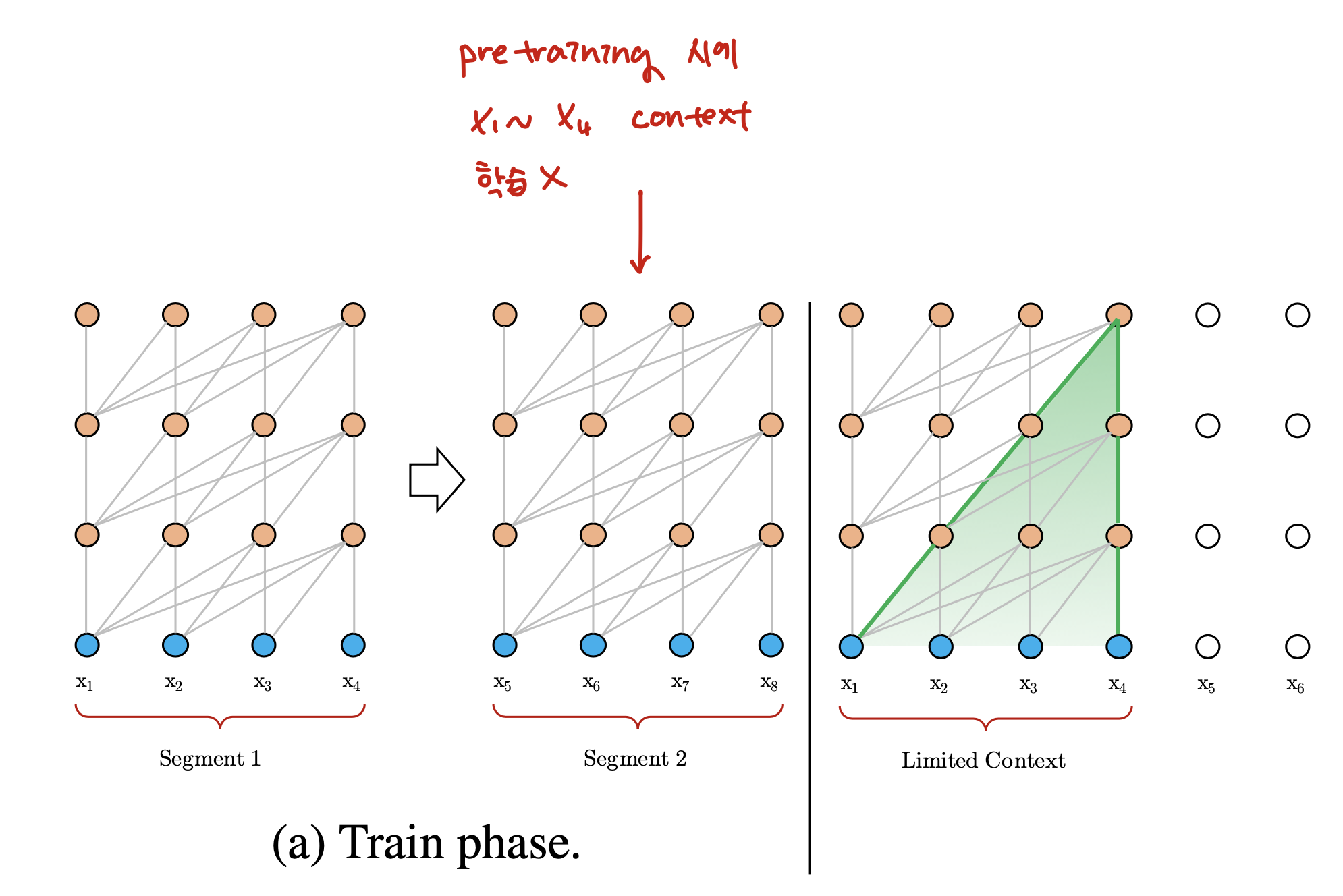 Context Fragmentation in Training Phase
Context Fragmentation in Training Phase
-
가장 긴 dependency는 segment길이이다. 따라서 segment간의 맥락적 의미를 학습할 수 없게 된다. Sequence Modeling에서 Transformer의 최대 장점인 'gradient 소실 극복'을 충분히 활용하지 못한다.
-
1과 마찬가지로 효율성을 위해 결국 LM 학습은 어쩔 수 없이 max_len으로 나눈 문서로 학습된다는 것이다.
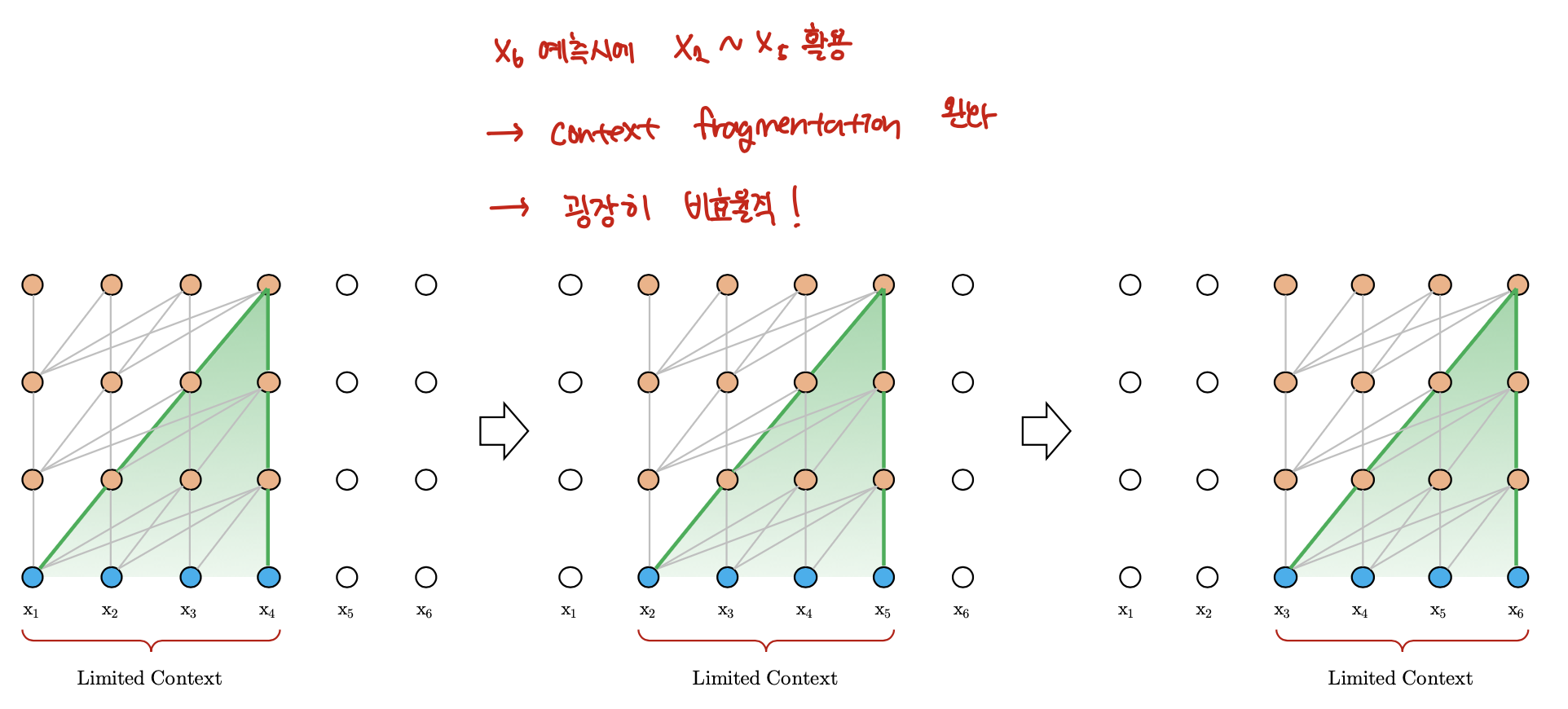 Evaluation Phase for Vanilla Transformer
Evaluation Phase for Vanilla Transformer
위 그림에서 보는 것처럼 Transformer-XL은 1 position씩 right shift하며 inference을 진행한다. 연산측면에서 굉장히 비효율적이지만 (매 time-step마다 from the scratch로 최대 받을 수 있는 max_len만큼 forwarding) Training시에 마주쳤던 context fragmentation는 조금 완화된다.
저자들은 Attention연산이 일어나는 부분을 아래와 같이 분해한다.
3.2 Segment-Level Recurrence with State Reuse
Vanilla Transformer가 겪는 max_len에 의존적인 학습을 해결하는 방법론이 'Segment-Level Recurrence with State Reuse'이다. 간단히 말하면 이전 Segment의 모든 hidden step(L-1 Layer)을 활용해 현재 segment에 대한 hidden representation (L Layer)을 구하자는 것이다.
다음 아래의 식과 행렬표현을 보자.
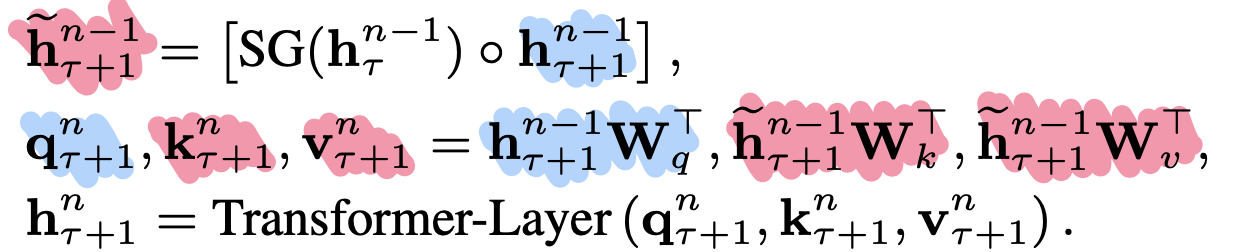
n-1 Layer에 있는 segment의 hidden state와 segment의 hidden state를 concat하고 해당 hidden state를 key, value로 사상. segment의 hidden state만을 활용해 query로 사상하는 것이다. query가 특정 step 토큰의 의미 표현을 물어보고 key와 value가 맥락적 의미를 만드는 벡터라는 점을 참고하면 되다. 여기서 SG는 Stop Gradient로 이전 segment에 대해서는 gradient를 흘리지 않는다는 뜻을 의미한다. (아마 FFN이랑 Layer Normalization weight 같음..)
Segment 2개만을 놓고 볼 경우 아래의 그림처럼 query, key, value로 사상할 것이다.
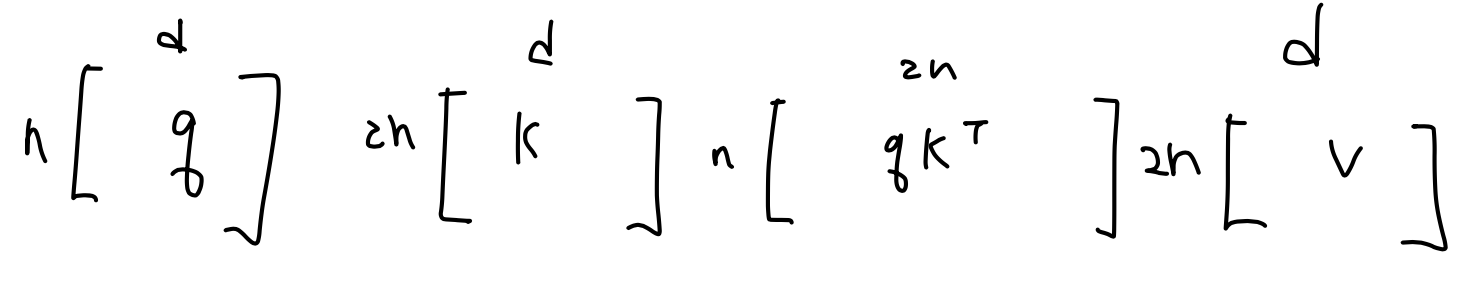
실제 코드를 보면 현재 max_len만큰 모든 Layer에 대해서 Forwarding해준 hidden state를 gradient를 죽이고, computation graph를 끊어준 상태에서 memory로 추가해주는 형식으로 구현 되어있다.


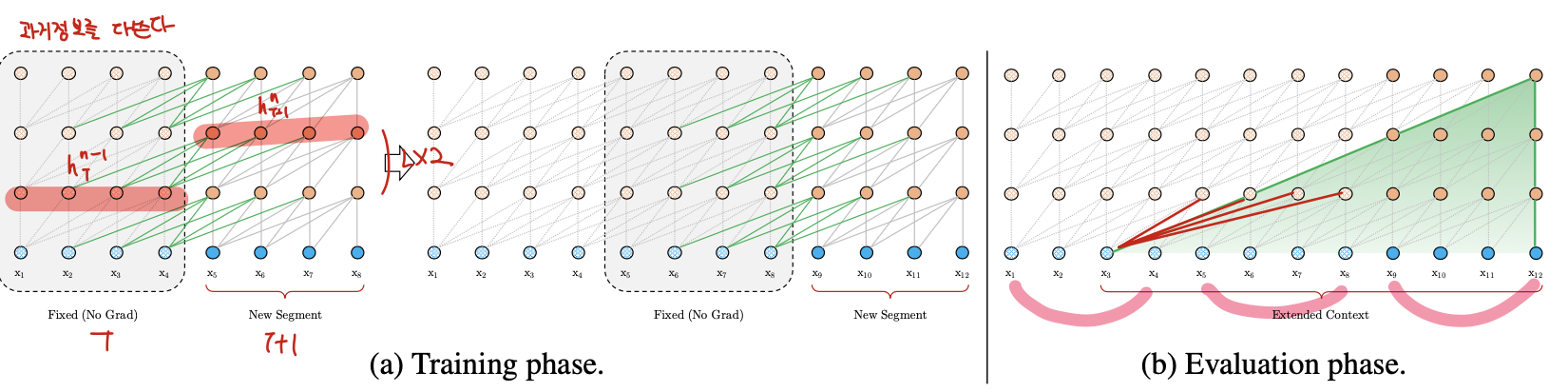 Segment-Level Recurrence with State Reuse
Segment-Level Recurrence with State Reuse
3.3 Relative Postional Encoding
3.2절에서 논의한 바와 같은 hidden state representation 재사용을 하게 되면 기존 Word Embedding에 더하는 Positional Embedding을 더 이상 사용할 수 없다.
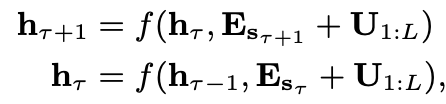 기존 PE의 한계
기존 PE의 한계
U가 PE라고 할 때 segment와 segment에 동일한 PE를 더해주면 position에 대한 중복 정보가 들어가게 됩니다. 이게 왜 문제가 되는지는 아래의 그림으로 설명한다.
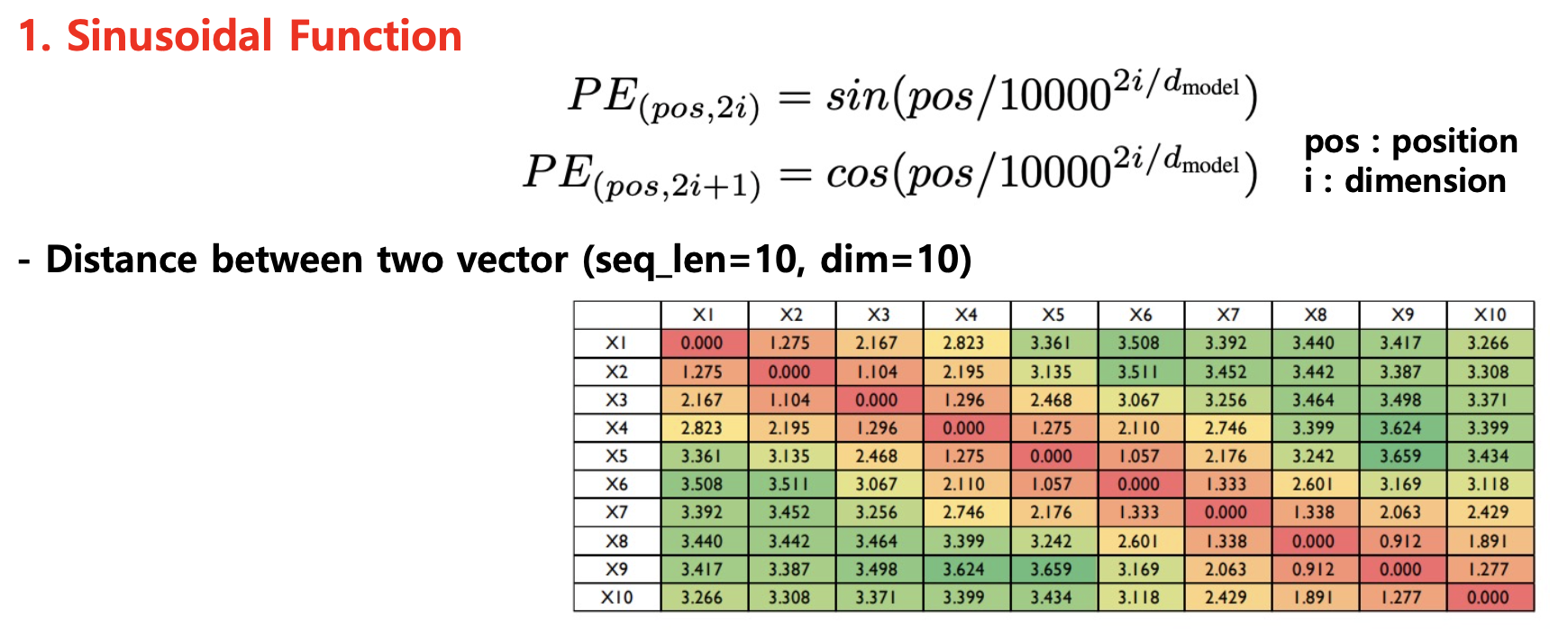
결국 PE는 내가 상대적으로 얼마나 떨어진 토큰에게 attention을 주는지에 대한 정보를 주기 위해 사용되는 것인데, 저자들은 굳이 initial embedding에 더하는 식 말고도 이러한 정보를 충분히 주입할 수 있다고 주장한다.
맞다. 결국 상대적인 거리 차이만 토큰에 더해줄 수 있으면 되는 것이다. 서로 다른 토큰 간에 연산이 일어나는 곳은 Attention이기 때문에 저자들은 Attention이 일어나는 행렬연산 부근을 분해해 Relational PE를 주입한다.

위에 보는 것처럼 Attention 연산은 Content 정보(Word Embedding, Hidden State)가 들어가 있는 와 Position 정보가 들어가 있는 로 분해될 수 있다. 가 query, 가 key라고 할때, position 정보가 들어가 있는 를 상대적인 위치 값을 갖는 (j번째 key가 i번째 query로부터 얼만큼 멀리 떨어져 있는가?)로 대체한다. 그리고 이미 상대적인 위치 정보를 주었으니 기존 query에 투영되는 벡터는 로 바꿔준다. (에서 이미 상대적인 위치 정보를 반영해주었기 때문에 query 자체의 위치 정보는 모든 position마다 동일해야 하기 때문)
re-parameterize된 상태에서 각각 term은 아래의 의미를 가진다.
(a) content based addressing
(b) content dependent positional bias
(c) governs a global content bias
(d) encodes a global positional bias
저자들은 을 삼각함수를 활용하여 evaluation시에 더 긴 input을 처리할 때도 탄력있게 대응하도록 했다. 최종 모델의 식은 아래와 같다.

4. Experiments
저자들은 다양한 word & character level의 데이터셋을 활용해 실험을 진행했다.
각 실험에 쓰인 metric으로는 PPL, BPC가 있는데 간략히 정리해보면 다음과 같다.
-
PPL : 특정 데이터셋에서 LM의 likelihood가 얼마나 좋은가?
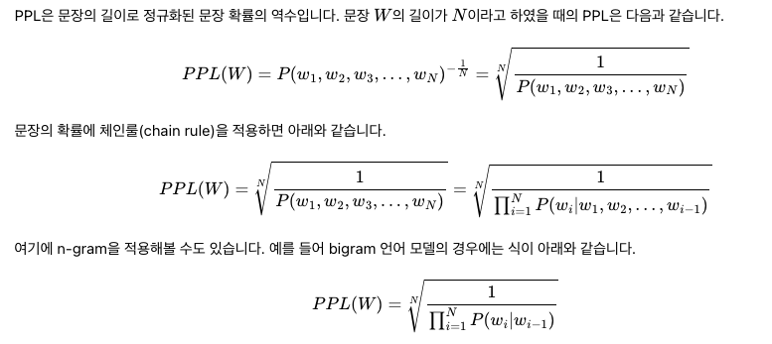
-
BPC : Cross entropy of char-level language modeling with 2-base log function
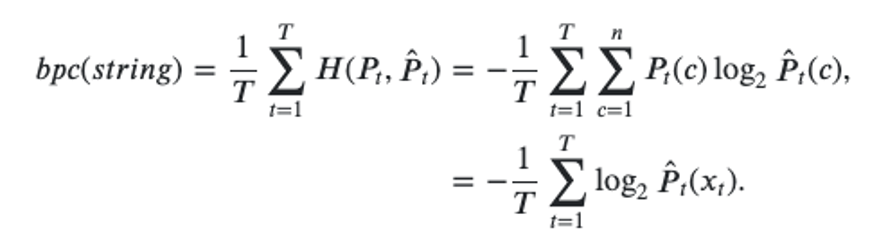
4.1 Main Results
WikiText : the largest available word-level language modeling benchmark with long-term dependency
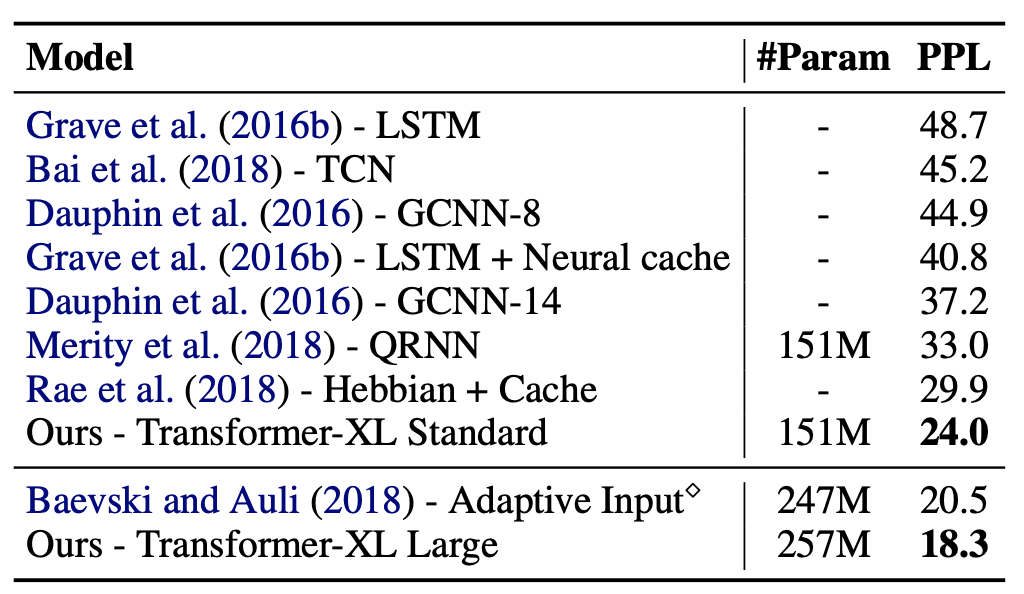
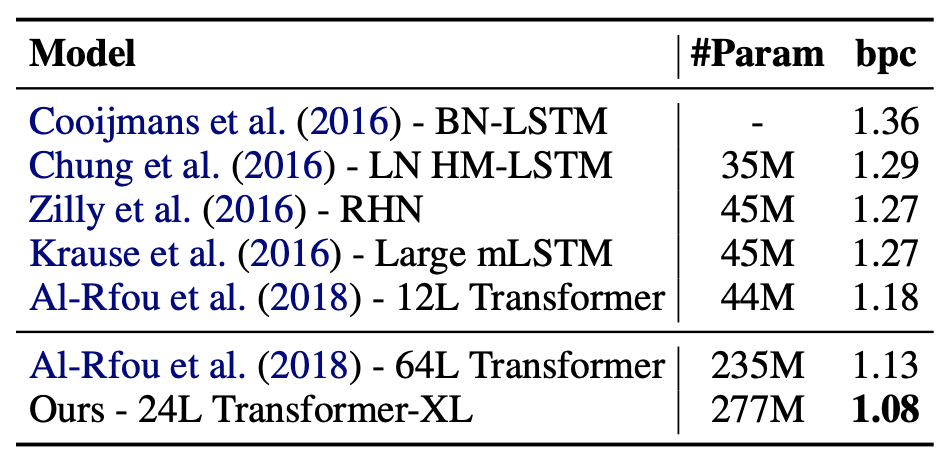
Enwiki8 : contains 100M bytes of unprocessed Wikipedia text (character-level LM benchmark)
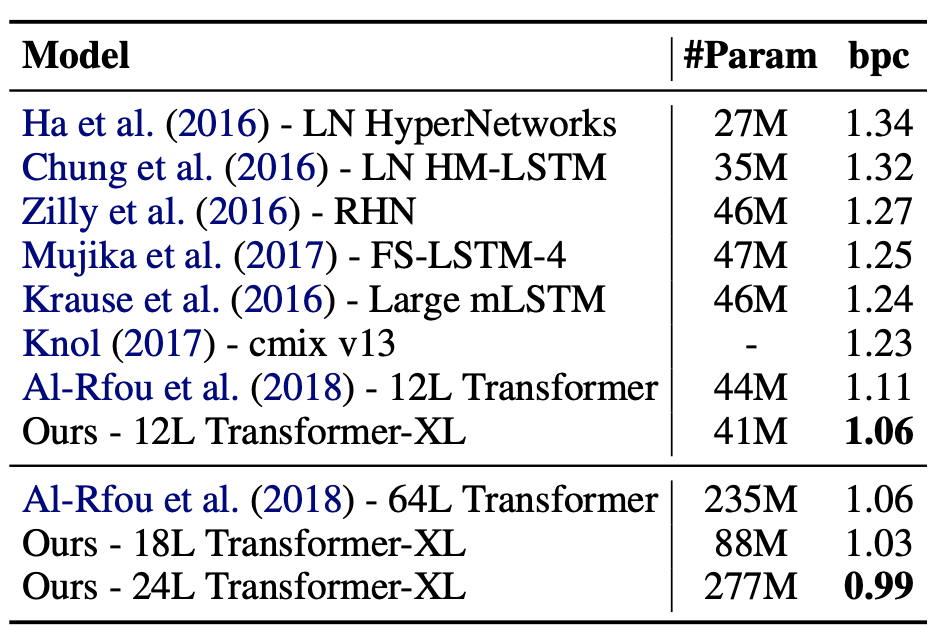
처음으로 BPC 1보다 낮은 값을 기록했다.
Text8 : enwiki보다 더 clean된 character-level LM benchmark
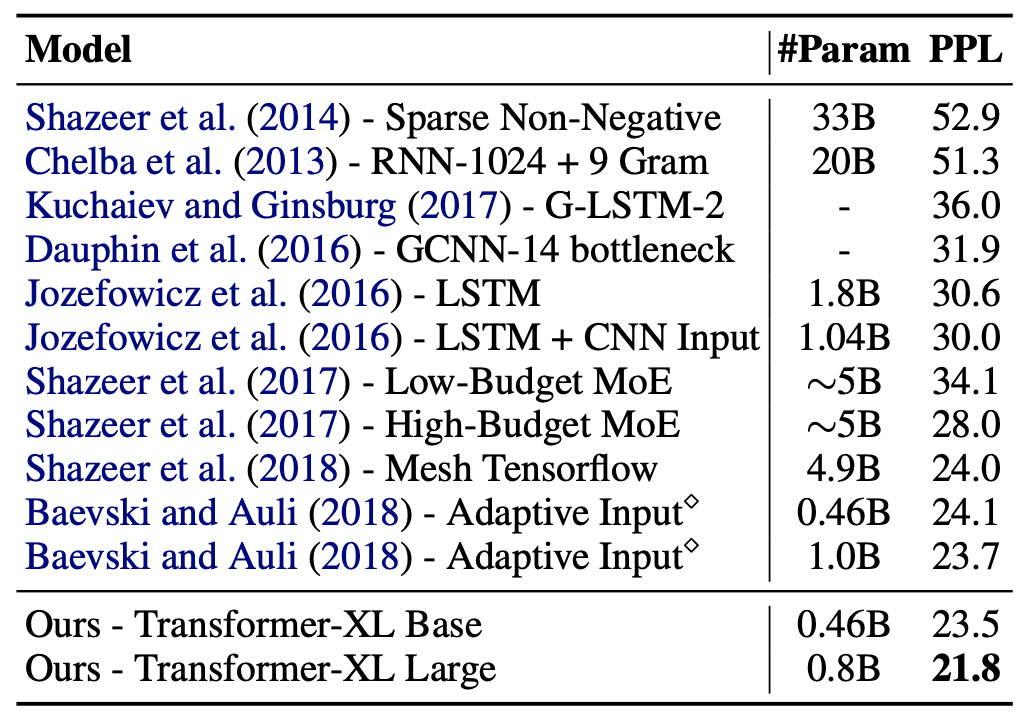
One billion word (문장들이 shuffled되어 있음 = ability of modeling only short-term dependency)
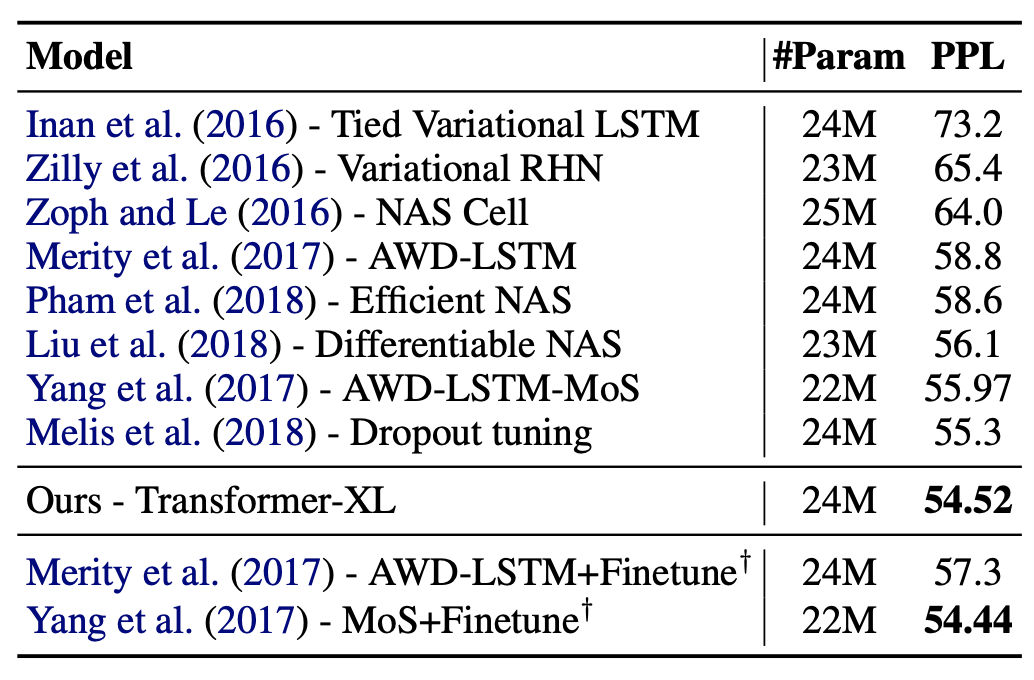
Penn Treebank (small dataset에서도 잘 동작함을 보여주기 위해)
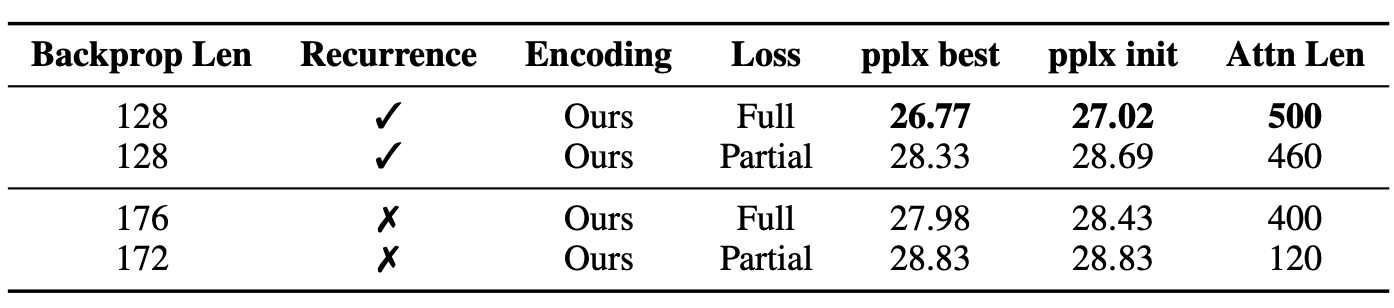
4.2 Ablation Study
WikiText-103
Relative PE : Ours, Shaw et.al
Absoulte PE : Vaswani et al, Al-rfou et al
Full vs Half (input의 전체 or 절반에만 cross entropy loss를 계산하는지)
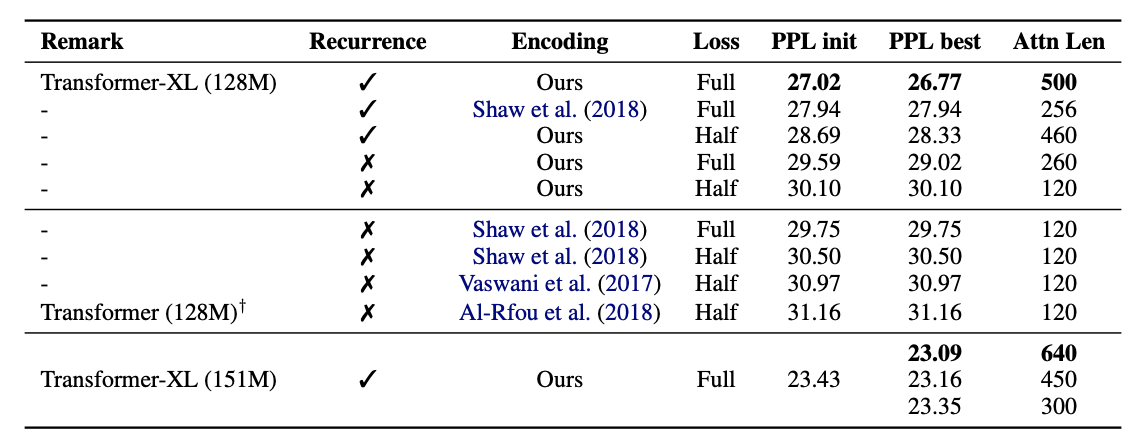
Recurrence를 활용하면 Back propagation으로 더 짧은 input에만 gradient를 흘려주어도 성능이 좋아진 것을 확인할 수 있다.
'동일한 GPU memory에서 recurrence 사용 = Short Input' (memory with Stop Gradient) VS 'Long Input'
Transformer-XL의 recurrence mechanism은 long-term dependency가 없는 데이터에서도 context fragment를 해결한다.
Long-term dependency가 없는 One Billion Word Dataset에서 Recurrence mechanism이 좋은 성능을 달성했다. (사실상 더 긴 입력문을 받으니까 long-term dependency와는 무관하게 성능이 향상된 것은 당연한게 아닌가..?)

4.3 Relative Effective Context Length
저자들은 더 많은 context (LM 조건부 확률에서 condition부분이라고 이해했네요,,)가 얼마나 더 유효한 PPL 감소를 이루어냈냐를 측정한다. 해당 성능 측정을 위해 Effective Context Length (ECL)라는 것이 사용되었다고 하는데, 이 metric은 이미 baseline context 로 모델이 낮은 PPL을 달성했거나 여러 모델을 비교하기에는 어렵다고 주장하면서 Relative Effective Context Length라는 것을 제시하는데 아래와 같다.

는 번째 모델이 context 만을 활용했을 때 번째 토큰에 대한 Loss이다. 이때 로 더 긴 context 를 활용했을 때 Loss가 더 떨어지면 longer context 활용에 대한 유효성을 보일 수 있는 것이다.
는 번째 token에 대한 baseline loss이며, 는 더 긴 context를 활용했을 때 baseline 대비 갱신된 loss이다.

는 baseline 상향 조정을 위해 특정 position을 설정한 것이고, 은 context 증가에 따른 PPL 감소로 볼 수 있다.
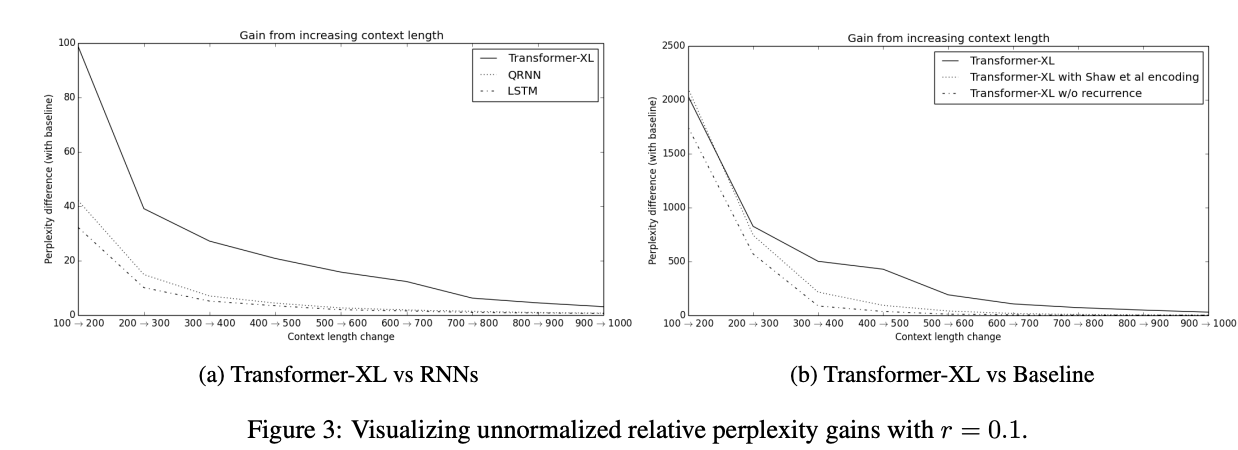
결과표에 의하면 Transforme-XL이 긴 context에서도 연장된 context 길이만큼 PPL이 다른 모델에 비해서 상대적으로 더 잘 줄어드는 것을 볼 수 있다.
5. Conclusion
- Recurrence Mechanism
- Relative PE
를 통해 long-term dependency를 제대로 활용할 수 있는 PPL이 낮은 AR 모델을 제안하였다.

안녕하세요
공부 중 올려주신 블로그의 도움을 많이 받았습니다! 감사합니다.
와중에 모델에 대해서 공부하던 도중 혼자서 이해하기 힘든 부분이 생겨
이렇게 댓글을 남깁니다!!
transformer xl, xlnet에서 사용하는 함수 tf.einsum (‘ibnd,jbnd->ijbn’, (head_q, head_k) 는 모든 단어와의 상관관계를 계산하지 않는 것 같습니다. 예를 들어, [[i,am],[a,boy]] 라는 문장끼리의 상관성을 계산한다고 했을 때
i 는 i,a
am 은 am,boy
A 는 i, a
Boy 는 am,boy 와의 상관성만을 계산합니다.
혹시 이부분에 대해서 알고 계신 부분이 있을까요??
모델에 데이터를 인풋할 때 위의 i,am,a,boy 처럼 배치가 없이 2차원의 형태로 데이터가 들어가는 것으로 알고있습니다!!