Poly-Encoders : Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring
오늘 발표할 poly-encoder 논문은 Facebook AI Research team이 2020 ICLR에 출판된 논문으로, 빠르고 정확하게 여러 문장을 비교하고 스코어링 하기 위한 방법을 소개하고 있습니다. 기존에 두 문장을 비교하는 task에서 일반적으로 사용되던 Cross-encoder와 Bi-encoder 방식의 장점을 각각 취한 형태의 Poly-encoder 구조를 제안하고, 실험을 통해 4가지 task에 대해 sota를 달성했음을 보입니다.
Introduction
BERT가 발표된 이후 BERT 모델을 사용한 연구가 많이 이루어지는 가운데, Sequence 간의 pairwise 비교를 하는 태스크에 대해 보통 sequence pair를 한번에 인코딩(full self-attention)하는 Cross-encoder 방식과 sequence pair를 각각 인코딩하는 Bi-encoder 방식을 사용합니다. 하지만 cross encoder는 속도가 너무 느리고, Bi-encoder는 성능이 떨어집니다. 저자들은 이러한 cross encoder와 bi encoder의 장점을 결합한 Poly-Encoder를 제안하고 있습니다.
Tasks
우선 Method를 좀 더 쉽게 이해하기 위해 해당 논문에서 사용한 Task에 대해 먼저 살펴보겠습니다. 논문에서는 Dialogue 및 Article Research 분야에서 실험을 수행했습니다.
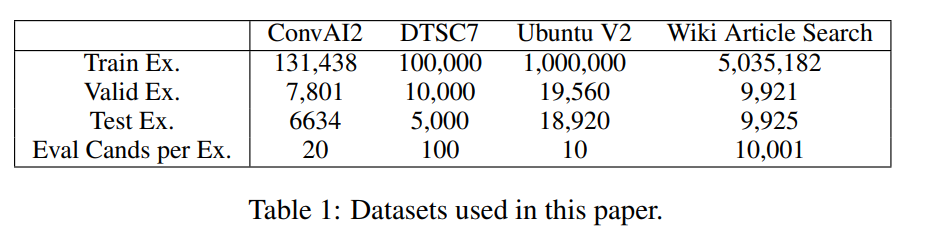
- ConvAI2 : 두 화자의 대화를 담고 있는 Persona-Chat dataset을 기반으로 함
- DSTC7 : Ubuntu 채팅 로그에서 추출한 대화로 구성됨
- Ubuntu V2 : 위와 비슷하지만 좀 더 크고 유명한 corpus
- Wiki Article Search : 가장 관련성 높은 article(web documents) 검색
Methods
Transformer
이 파트에서는 저자들이 어떻게 BERT를 pre-train했는지 소개하고 있습니다.
bi-encoder, cross-encoder, poly-encoder는 모두 BERT-base를 기반으로 합니다. 해당 논문에서는 BERT-base로 두 가지를 pre-train했다고 합니다.
- Wikipedia와 Toronto Books Corpus
--> 이는 기존의 BERT-base와 같은 데이터셋입니다. - 온라인 플랫폼 Reddit에서 추출한 데이터셋
--> 이 데이터셋은 관심있는 다운스트림 작업과 더 유사한 데이터에 대한 pre-train이 도움이 되는지 보기 위한 것입니다.
pre-trainig input은 [INPUT, LABEL]의 concatenation으로 들어가는데, input은 context 문장이고 label은 그 다음의 문장(candidate)입니다.
Bi-Encoder

바이인코더에서는 input으로 들어가는 context와 candidate label이 각각 벡터로 인코딩됩니다. 위의 수식에서 는 pre-tained된 트랜스포머의 output, 는 벡터들의 시퀀스를 하나의 벡터로 줄이는 함수입니다. 최종적으로 얻어지는 y 는 각 Encoder의 Contextualized Embedding을 의미합니다. (세그먼트 임베딩은 둘 다 0)
따라서 해당 과정을 통해 Context Embedding과 Candidate Embedding을 각각 따로 구할 수 있는데, Bi-Encoder에서는 해당 임베딩 벡터를 내적하여 candidate가 context 다음으로 적절한가 계산하는 score를 만듭니다.
- [(ctxt, cand1), (ctxt, cand2), …, (ctxt, candn)]의 cross-entropy loss를 최소화하는 방향으로 학습합니다.
이 때, cand1이 correct label, 나머지는 training에서 가져온 다른 labels - 학습할 때는 batch 내의 샘플을 negatives로 사용하여 더 빠른 training과 더 많은 batch size를 사용할 수 있도록 합니다.
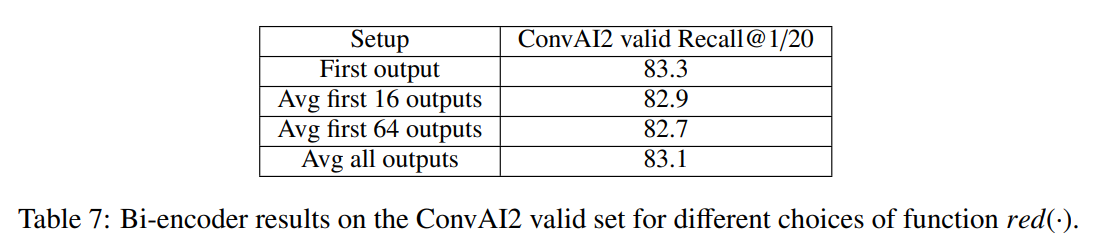
또한 저자는 red(⋅)로 아래 세 가지 과정을 고려했으나 실험을 통해 첫 번째 방식을 사용하였다고 합니다.
- 첫 토큰 선택
- 토큰별 아웃풋을 평균 냄
- 첫 토큰부터 m개까지의 토큰을 평균
Cross-Encoder

Cross-encoder의 경우 비교하고자 하는 문장 2개를 이어붙여서 하나의 모델에 넣어 계산하는 방법입니다.
- Bi-encoder와 달리 인코딩 과정에서 context와 candidate 간의 self-attention을 적용할 수 있기 때문에 둘 간의 관계를 훨씬 깊게 파악할 수 있다는 장점이 있고, 성능 역시 보통 Bi-encoder 방식에 비해 더 좋습니다.
- 그러나 하나의 context를 모든 candidate와 연결 후 scoring하여 비교하기 때문에 BERT 같은 큰 모델의 경우 연산하는데 시간이 오래 걸리고, 문장의 수가 늘어나면 늘어날 수록 실제 서비스 환경에서 사용하기 어려운 단점이 있었습니다.
는 생성된 벡터 시퀀스의 첫번째 벡터만을 취하는 함수입니다. (red()와 같은 방식 취한 거라고 보면 될듯)
Cross-Encoder에서는 벡터 W를 곱해 y를 스칼라로 만들어 scoring합니다. 배치의 구성은 bi-encoder와 동일하지만, negatives를 recycle할 수 없기 때문에 training set에 제공되는 external negatives를 사용한다고 합니다.
Poly-Encoder
해당 논문에서는 바이 인코더와 크로스 인코더의 장점을 모두 포함한 Poly-encoder를 제안합니다. candidate는 바이 인코더처럼 하나의 벡터로 표현되며, input은 크로스 인코더처럼 candidate와 동시에 인코딩되어 시간을 줄이고 더 많은 정보를 추출할 수 있다고 합니다.
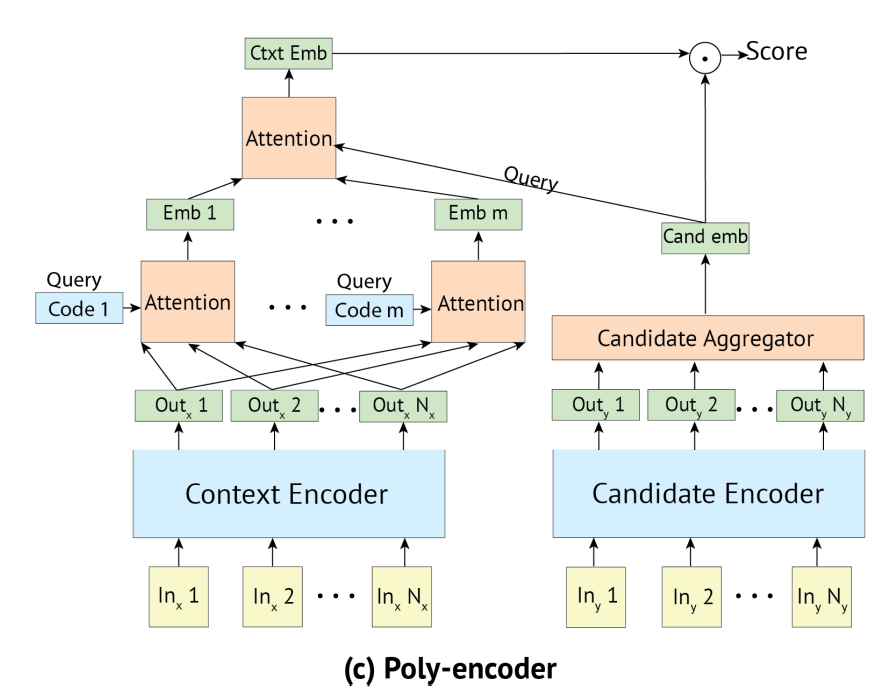
그림과 같이 폴리 인코더는 바이 인코더처럼 context와 candidate 두 개의 인코더로 나뉘어 있습니다.
- Candidate는 바이인코더와 같이 single vector 로 인코딩됨
- input Context는 우선 m개의 벡터()로 표현됨
- 기존에는 Context Encoder의 output을 red(⋅)을 통해 바로 하나의 벡터로 합쳤지만, Poly-encodeer는 code vector와의 attention을 통해서 여러 개의 embedding 벡터를 만들어냄
where
이때 code vector 는 일종의 latent variable이라고 볼 수 있으며, 학습 초기에는 random initialize 되고 학습 과정 중에 learnable parameter로써 함께 학습됩니다. 이는 context의 여러 의미를 포착하는 역할을 한다고 볼 수 있을 것 같습니다.
where
이렇게 얻어진 벡터들(Figure에서 Emb 1 ~ Emb m)에 대해서 Candidate Embedding과의 attention을 통해서 한 번 더 벡터들을 합치고 최종 Context Embedding을 구합니다.
최종적으로 와 를 구했으니, 바이인코더에서처럼 두 벡터를 내적하여 최종 스코어를 도출합니다. m<N이고, context-candidate attention이 가장 마지막에만 이루어지기 때문에 해당 방법은 cross-encoder의 full self-attention보다 훨씬 속도가 빠릅니다.
Experiments
- R@k/C : test sample이 C개의 candidates 선택할 수 있을 때의 Recall@k (+K에서의 재현율: 관련있는 상위-K 셋에서 발견된 관련 항목의 비율)
- MRR : 평균 상호 순위 (+해당 쿼리와 일치하는게 몇번째에 있는가?)

Poly-Encoder
- 폴리인코더는 바이인코더와 같은 배치 사이즈
- 폴리인코더가 바이인코더보다 성능 좋음
- code 많을수록 더 좋은 성능 --> 컴퓨팅되는 한 가장 큰 code 쓰는게 좋다!
- 기존 버트의 가중치로 pre-train한 DSTC7에서, 360 code 사용한 폴리인코더는 크로스 인코더보다도 성능이 좋았음!!
Domain-Specific pre-training
- Reddit으로 사전학습한 결과가 기존의 BERT 실험보다 성능이 좋았다.
- 본 논문에서 직접 pre-train한 BERT와 기존의 BERT 성능이 비슷한 것으로 보아, pre-train 시의 데이터셋 성능이 최종 결과에 큰 영향을 미친다는 것을 알 수 있다.
- 즉, 관심 있는 downstream과 유사한 데이터셋으로 pre-train하는 것이 성능 향상에 도움이 된다.
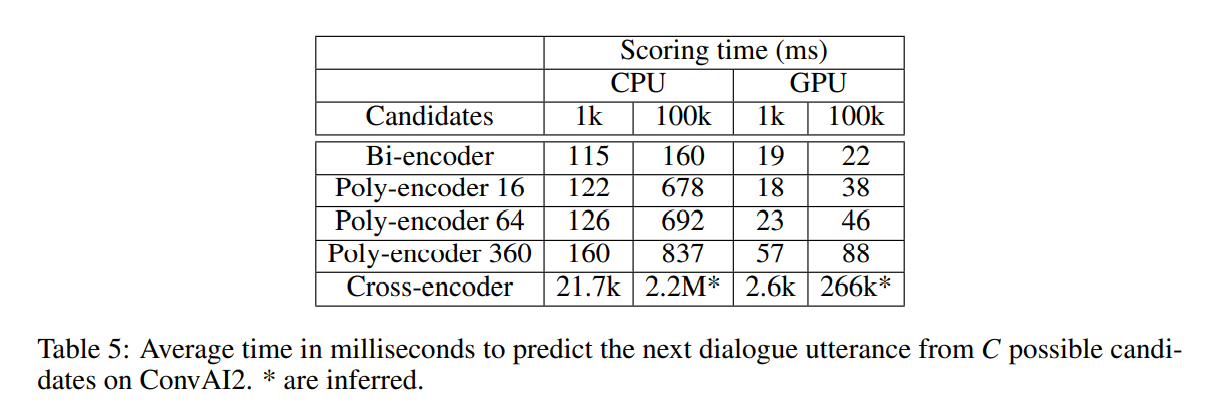
- 크로스 인코더의 scoring time은 처참하다...
Conclusion
- 바이인코더보다 정확하면서 크로스인코더보다 빠른 폴리인코더를 제안해 기존 정확도와 속도 사이의 균형을 개선했습니다.
- downstream task와 더 밀접하게 연관된 pre-training이 결과가 매우 향상됨을 보였습니다.
+)코드 : https://github.com/chijames/Poly-Encoder/blob/701354372c66396d6b6678b664e82416f65f3a84/encoder.py
