RoBERTa
오늘 발표할 RoBERTa 논문은 이름에서도 예상가능하듯이 BERT를 활용한 모델입니다. 앞선 발표들의 Experiment 과정에서 RoBERTa 모형이 BERT와 함께 상당히 자주 등장해서 앞으로는 어떤 모형인지 이해하고 공부하기 위해 본 논문을 읽어봤습니다.
구글이 2018년 발표한 BERT 논문은 기존의 자연어처리 문제들에서 빠르게 SOTA를 달성하며 급부상했는데, BERT 논문에서는 hyperparameter에 대한 실험이 제대로 진행되지 않았습니다. 그래서 Facebook AI팀에서 기존 BERT모델을 유지하며 학습단계의 hyperparameter를 조정하여 성능을 높이는 방법인 RoBERTa를 공개했습니다.
Introduction
RoBERTa의 뜻은 Robustly optimized BERT approach입니다. 기본적인 구조는 전부 BERT를 따라가며 기존 BERT 모델에 비해 RoBERTa에서 추가되는 부분은 다음과 같습니다.
(1) dynamic masking
(2) NSP 제거
(3) 더 긴 시퀀스로 학습
(4) 더 많은 데이터 사용하여 더 큰 배치로 학습
Training Procedure Analysis
BERTbase 의 크기인 L=12, H=768, A=12, 110M params에 맞춰 학습을 진행한다.
Static vs Dynamic Masking
original BERT는 랜덤하게 마스킹을 하고 토큰을 예측하는 single static mask를 사용하는데, 이는 data preprocessing과정에서 masking을 한번 수행합니다. 버트는 학습 전에 마스킹을 하기 때문에 매 학습에서 같은 mask를 보게 됩니다. 이를 보완하기 위해 데이터를 10번씩 중복시키고 각각의 시퀀스마다 10가지의 다른 위치로 마스킹을 하는 작업을 수행했습니다. 따라서 학습이 40에폭으로 진행되는 동안 training sequence는 4번씩만 같은 마스킹을 가지게 되지만, 이는 크기가 큰 데이터에 대해서는 비효율적입니다.
따라서 RoBERTa에서는 오리지널 버트와 다르게 dynamic masking을 사용하는데, 이는 매 에폭마다 새로운 마스킹을 시키는 태스크입니다.
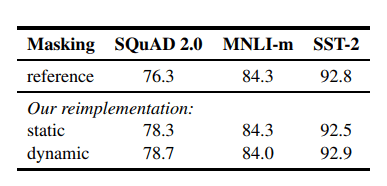
BERTbase에서 static과 dynamic making을 비교한 결과 비슷하거나 dynamic masking이 살짝 더 높습니다. 더 많은 step이나 더 큰 dataset에서 학습할 시 해당 과정이 중요해진다고 합니다.
Model Input Format and NSP
기존 BERT에는 두 문장이 이어졌는지 판단하는 pretraining 과정인 NSP(next sentence prediction)가 존재합니다. 그러나 이전의 버트 발표에서도 언급해주셨듯이 BERT의 pre-training은 MLM을 중점으로 하고 있고, NSP의 성능에 관해서 의문점이 남았습니다. 다음의 비교를 통해 자세히 알아보도록 하겠습니다.
-
SEGMENT-PAIR + NSP
: BERT와 동일한 구조 -
SENTENCE-PAIR + NSP
: document의 인접부분 또는 다른 document의 sentence 쌍으로 구성됨 -
FULL-SENTENCES
: 하나 이상의 document에서 연속적으로 sampling된 전체 sentence -
DOC-SENTENCES
: FULL-SENTENCES와 같지만 document를 건너뛸 수 없음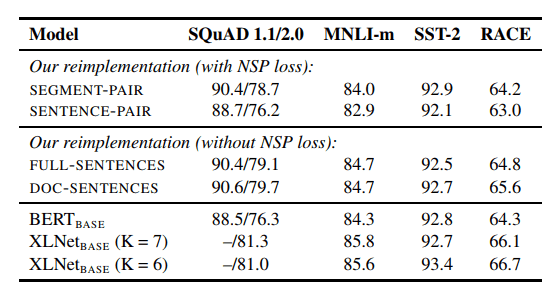
SEGMENT-PAIR+NSP와 SENTENCE-PAIR+NSP를 먼저 비교해보면 두 format모두 NSP를 유지하지만 후자는 single sentence를 사용합니다. 결과를 통해 single sentence를 사용하는 것이 downstream task에 대한 성능을 저해한다는 것을 알 수 있습니다. model이 long-range dependency를 배울 수 없기 때문입니다.
NSP를 적용시킨 task들과 적용시키지 않은 task들을 살펴보면 NSP가 없을 때 성능이 비슷하거나 조금 올라갑니다. 또한, FULL-SENTENCES와 DOC-SENTENCES를 비교하면 DOC-SENTENCE의 성능이 더 높습니다. 하지만 배치 사이즈 조절의 편의성때문에 아래의 실험 부분에서는 FULL-SENTENCES를 사용해서 진행합니다.
Training with large batches
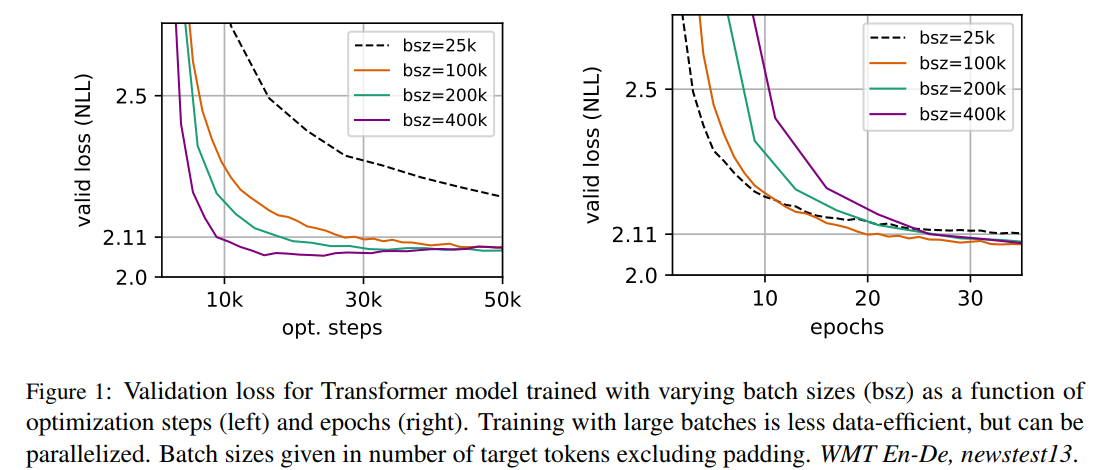
과거 NMT 연구(Scaling Neural Machine Translation)에서 아주 큰 mini-batch로 학습하면 적절한 학습률을 사용할 때 optimization speed와 end-task performance를 모두 향상시킬 수 있다는 것이 밝혀졌다고 합니다. 따라서 Roberta에서도 이를 적용했습니다.
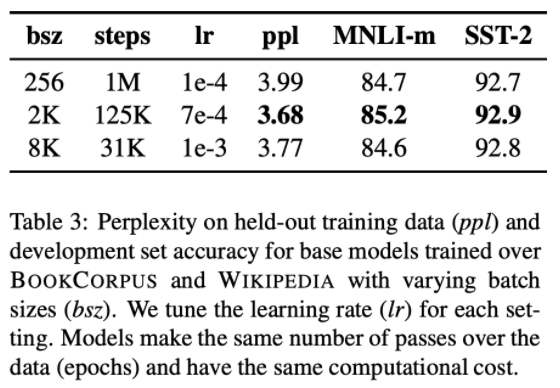
BERTbase의 배치사이즈는 256, 스텝사이즈는 1M입니다. 위의 table을 통해 배치사이즈와 스텝사이즈 별 성능을 확인할 수 있는데, 배치사이즈가 커졌을 때 perplexity가 낮아짐과 동시에 성능이 향상되며, 2k개에서 가장 성능이 높았다고 합니다. 배치사이즈가 클 때 데이터를 parallelize하기 쉽기 때문에 RoBERTa에서는 8k개의 배치사이즈를 사용합니다.
Text Encoding
Byte-pair Encoding(BPE)는 word 단위와 character 단위의 중간에 있는 text encoding이며, 학습 코퍼스의 통계치에 의해 결정되는 sub-word unit입니다.
BERT에서는 학습 코퍼스에 휴리스틱한 토크나이징을 진행하고 character-level의 BPE를 학습시켰고, 30k 사이즈의 사전을 이용했습니다. RoBERTa는 byte단위의 BPE를 학습했고, 50k 사이즈의 사전을 이용했습니다. 선행 연구에서 Byte단위가 character 단위에 비해 조금 안좋은 결과를 보였지만, universal encoding의 이점 때문에 Byte단위를 사용합니다.
RoBERTa
위의 내용을 종합하면 RoBERTa는 다음과 같이 개선합니다.
- dymamic masking
- full-sentences without NSP loss
- large mini-batches
- larger byte-level BPE
추가적으로 RoBERTa는 original BERT보다 훨씬 큰 데이터셋을 사용합니다. BERT는 16GB를 pretraining한 반면, RoBERTa는 160GB를 pretraining했습니다.
- English Wikipedia & English Wekipedia(16G)
- CC-News(Common Crawl News corpus, 76G): 2016.9 - 2019.2 까지 뉴스 기사를 크롤링 한 것으로 약 63M개의 뉴스 기사를 포함합니다.
- Open Web Text(38G): reddit에서 up투표를 3이상 받은 공유된 URL의 내용을 크롤링 한 것입니다.(GPT에서도 이용함)
- Stories(31G): 크롤링된 데이터로 story-like style의 형식을 가집니다.
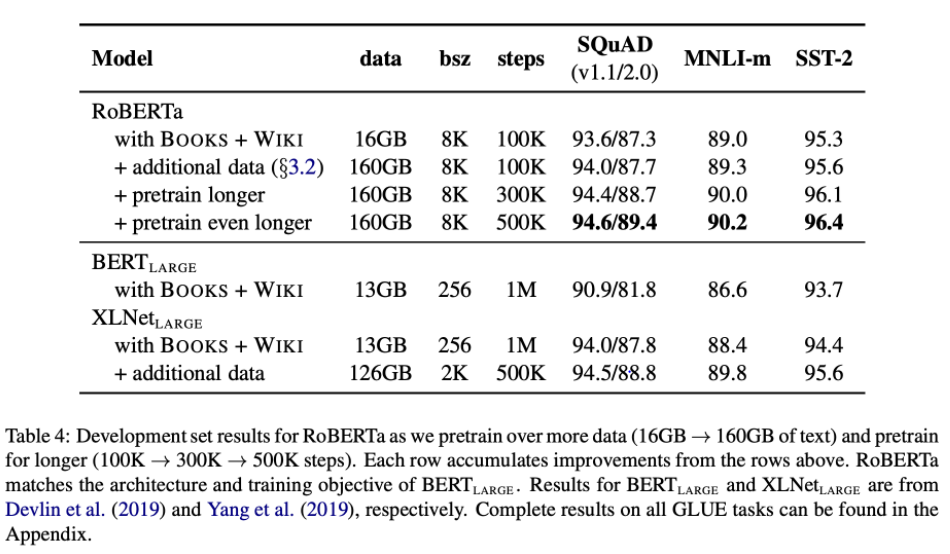
RoBERTa가 BERTlarge결과보다 더 크게 개선되었습니다. 오래 훈련된 모델도 데이터에 과적합되지 않았습니다.
Results
GLUE
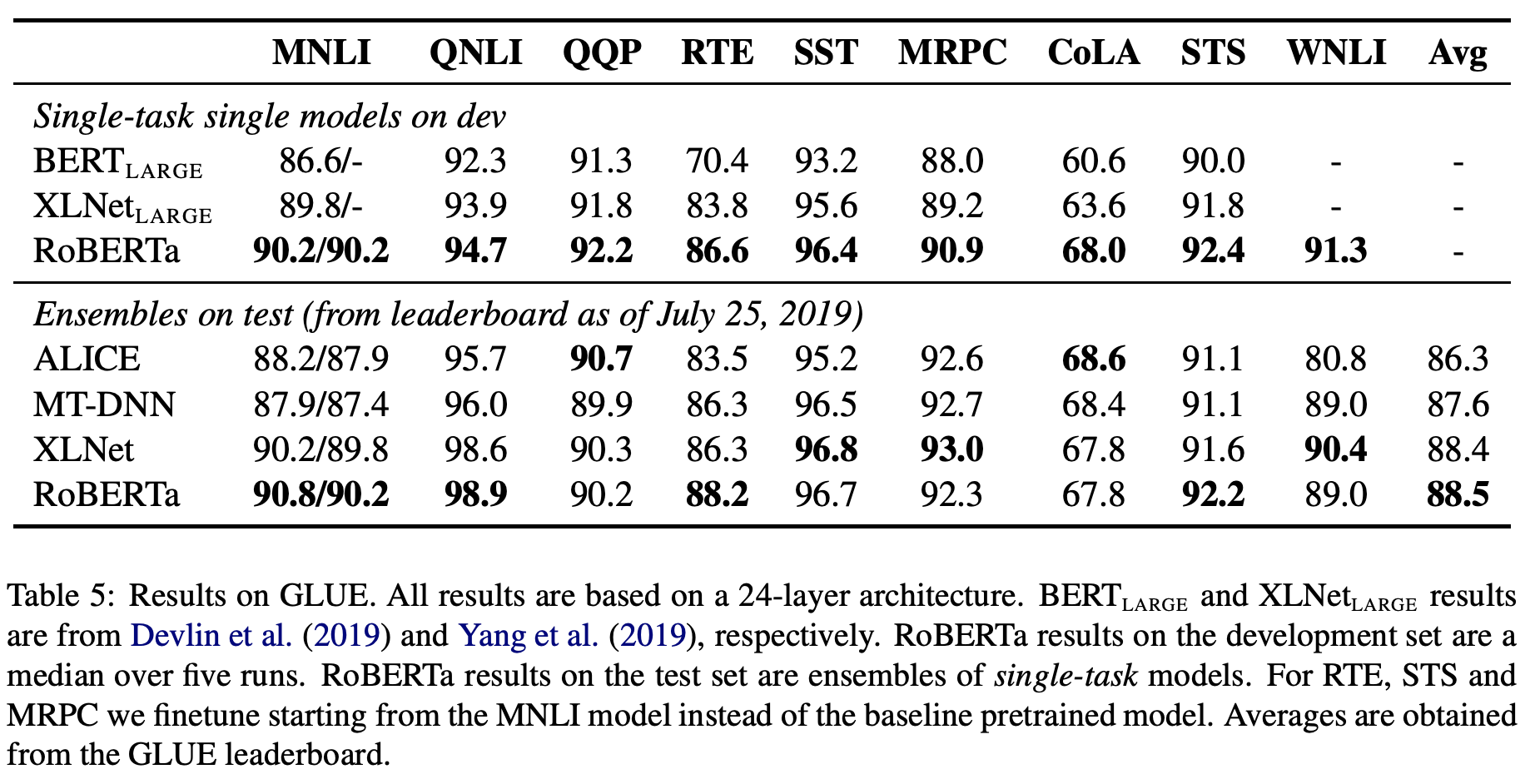
-
Single model 설정: GLUE의 모든 태스크들에 대해 각각 single training을 진행했고, 다른 논문들과 유사하게 hyperparameter는 적절한 범위 내에서 선택했습니다. BERT가 3만큼의 epoch만 학습하는 반면, 10epoch의 학습과 early stopping을 진행했습니다.
-
Ensemble model 설정: 넓은 hyperparameter 범위에서 5~7개의 모델들을 학습하여 앙상블하였습니다. 또한 RTE(Recognizing Textual Entailment), STS(Semantic Textual Similarity), MRPC(Microsoft Research Paraphrase Corpus)는 pretraining 모델에서 시작하기보다 , MNLI(Multi-Genre Natural Language Inference)로 fine tuning된 모델을 다시 fine tuning하는 방법이 더 성능이 좋았다고 합니다.
결과적으로 single model 설정은 9개의 테스크에서 모두 가장 좋은 성능을 보였고, ensemble model 설정은 4개 테스크의 성능과 평균 성능에서 가장 좋은 성능을 보였습니다. RoBERTa는 BERT와 동일한 모델 구조와 Masked LM를 이용하면서 다른 모델 구조를 사용한 접근법들을 능가했기 때문에 모델 구조보다 데이터 양, 학습 시간 등이 더 중요할 수 있다고 판단합니다.
SQuAD
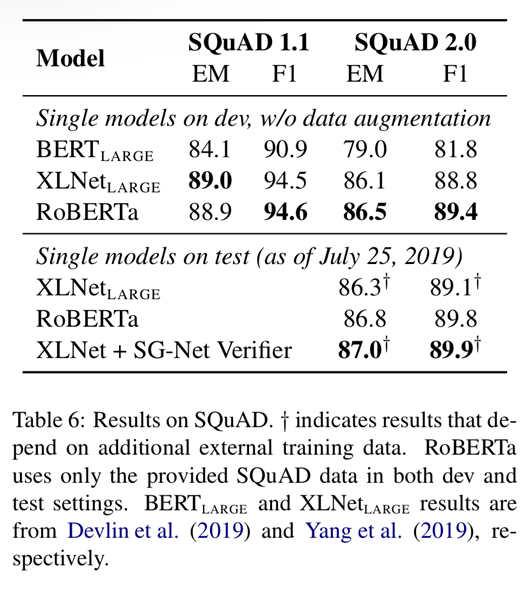
BERT나 XLNet은 다른 QA 데이터셋을 추가적으로 사용하였지만, RoBERTa는 오직 스쿼드 셋만을 사용하였다고 합니다. 또한 다른 lr scheduer등을 사용하지않고, 모든 레이어에 동일한 lr값을 사용했다고 합니다. SQuAD v1.1은 devlin의 파인튜닝 과정을 그대로 사용하고, v2.0에 대해서는 추가적으로 답이 있는지 확인하는 classifier loss를 결합하여 사용했습니다.
결과적으로 v1.1에 대해서는 XLNet large와 겨룰만한 성능을, v2.0에 대해서는 SOTA를 기록했습니다.
RACE
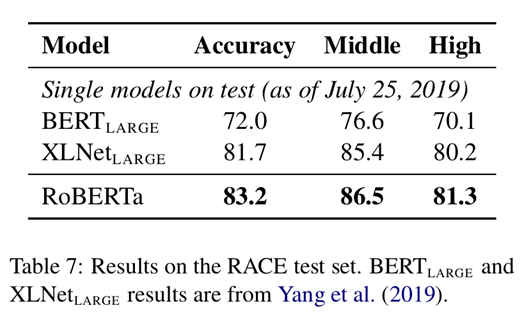
RACE는 문단, 질문, 4개의 후보정답군이 주어지면, 어떤 답이 맞는 답인지 찾는 문제입니다. 이 또한 결과적으로 SOTA를 기록했습니다.
Conclusion
RoBERTa는 hyperparameter가 untrained되어있는 BERT의 성능을 개선시킨 모형으로, 여러 실험에서 SOTA를 달성했습니다. 이로써 이전의 연구에서 간과된 요소들의 중요성을 확인하고, 최근에 제안된 다른 모델과 겨루어도 충분히 경쟁력이 있을 수 있음을 보여주었습니다.
참고자료
https://vanche.github.io/spanbert_roberta/
https://baekyeongmin.github.io/paper-review/roberta-review/
