Universal Sentence Encoder (USE)
1.Introduction
본 논문은 기존에 사용되고 있는 NLP training model들에 대해 전반적인 문제점을 지적하고 있다.
- NLP task에 사용되는 training data의 크기는 제한적이다.
- 대부분의 NLP 관련 연구나 실무에서 large training set을 사용하기 힘들다.
대부분의 연구 및 실험에서는 amount of dataset에 대한 issue로 인해서 transfer learning(word embbeding ; word2vec, GloVe)을 통해 한계점을 해결하고자 한다. 또한, 최근의 연구(Conneau, 2017)에서 sentence 수준의 pre-trained model이 transfer task에서 성능 입증되었다.
따라서 본 논문은 sentence embedding 생성을 위해 2가지 model을 제안한다.
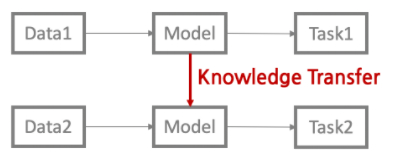
transfer learning
특정 tsak에서 수행하기 위해 훈련된 model을 다른 task에 사용하는 방법
- task1 : pre-trained, task2 : transfer learning (downstream)
- fine-tunning / prompt-tunning / in-context learnig
2. Model Toolkit
본 논문에서 제안한 model은 Transformer와 DAN(Deep Averaging Network)를 encoder로 사용한다. 본 model은 TF(Tensorflow)에서 구현되며, 아래와 같은 방법으로 사용 할 수 있다.

제공되는 model은 English를 sentence 단위로 embedding vector로 변환시킨다.
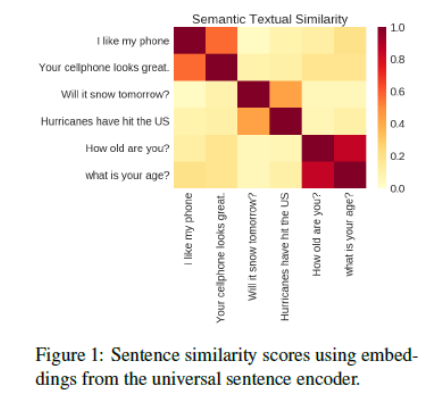
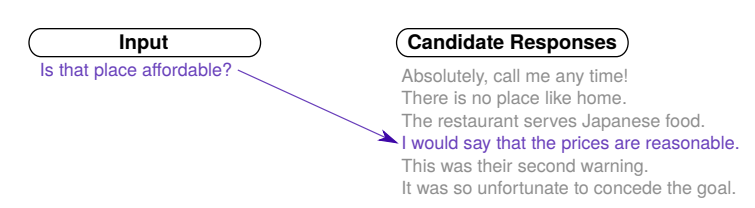
Figure 1 같이 sentence embedding을 했을 때 비슷한 문장들끼리의 유사성이 높게 나타남을 아 수 있다.
3. Encoders
각 Encoder들은 서로 다른 특징을 가지고 사용이 된다.
Transformer : high accuarcy, high cost of complexity and resource consumption
DAN : Efficient inference with slightly reduced accuracy
3.1 Transformer
Transformer는 sentence encoding model로 sentence embedding 역할을 수행한다.
- 단어들 간의 context aware representation을 파악하는데 문맥의 순서와 의미를 고려하기 위해 sub-graph를 사용한다.
- context aware word representation은 고정된 길이의 sentence embedding vector를 가진다.
- 각 word들의 embedding vector들을 Transformer에 input으로 넣는다.
- 나온 output을 elemet-wise sum해서 사용한다.
- Encoder(Transformer)의 input은 lowercase PTB tokenized를 사용하며 output은 512 dimensional vector를 가진다.
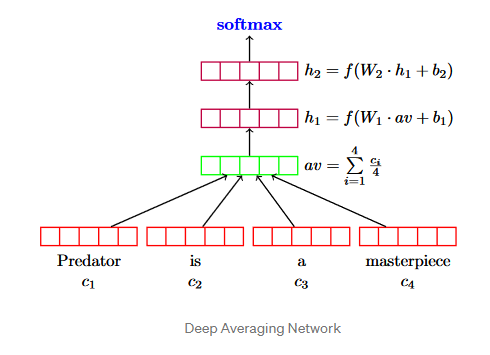
3.2 Deep Averaging Network(DAN)
앞서 언급한 Transformer와 마찬가지로 sentence embedding역할을 수행한다.
Transformer와 같이 input은 lowercase PTB tokenized를 사용하며 output은 512 dimensional vector를 가진다. 주된 장점은 Input sentence length에 비례하여 compute time이 선형적으로 증가한다.
DAN(Deep Averaging Network)의 계산 방법은 각각의 word embedding에 대해서 평균을 내준다. 그 평균 av를 input으로 deep nural network에 넣어주어 output을 얻게 된다.
Encoding model은 multi-task learning을 수행한다. 사용되는 Task는 Skip-thought, conversational input-response, classification 이며, 사용된 Encoder 대신 본 논문에서 제안한 Encoder를 사용해서 진행된다.
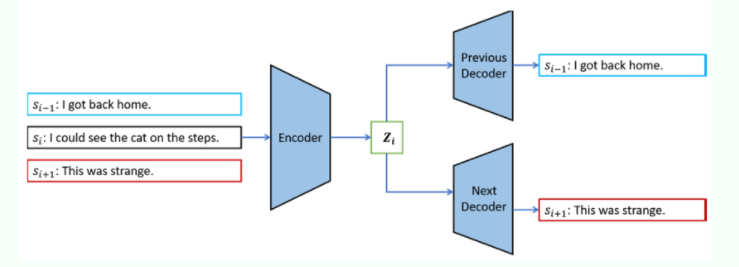
Skip-thought task
Si-1,Si,Si+1 3가지 문장을 하나로 입력을 받아 Encoder(LSTM)에 넣는다. 현재문장 (Si)를 이용하여 이전 문장(Si-1)과 다음 문장(Si+1)을 예측하여 sentence embedding vector를 학습한다.
Conversational input-response
siamese network처럼 input과 response data를 encoder에 넣은 후 Dot product해서 score를 학습
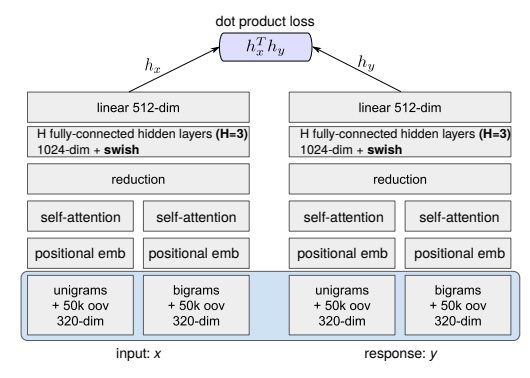
3.3 Encoder Training Data
- Stanford Natural Language Inference (SNLI) corpus
- Wikipedia, web news, web question-anwser page
4. Transfer Tasks
model의 bias를 측정하기 위해서 Word Embedding Association Test(WEAT)를 사용하였다.
아래는 Transfer learning에 사용된 dev and training dataset이다.
MR : Movie review snippet sentiment on a five star scale
CR : Sentiment of sentences mined from customer reviews
SUBJ : Subjectivity of sentences from movie reviews and plot summaries
MPQA : Phrase level opinion polarity from news data
TREC : Fine grained question classification sourced from TREC
SST : Binary phrase level sentiment classification
STS Benchmark : Semantic textual similarity (STS) between sentence pairs scored by Pearson correlation with human judgments
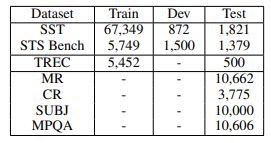
각 dataset의 크기는 SST Training dataset이 가장 많으며 MR,CR,SUBJ,MPQA dataset은 test dataset로 사용이 되었다.
5. Transfer Learning Models
Pair-wise semantic similarity task에 한하여 USE_T와 USE_D model의 output들을 DNN에 태워서 나온 U,V vector들을 cosine similarity에서 변형된 angular distance를 구한다.
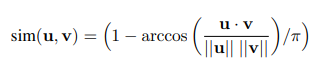
5.1 Baselines
- Transfer task를 비교하기 위해서 baseline으로 word 단위의 transfer learning(word2vec embedding)을 사용한 방법과 그렇지 않은 방법(random embedding)을 비교한다.
- 생성된 word2vec embedding과 random embedding은 각각 CNN과 DAN의 input으로 들어가게 된다 (word 단위의 embedding 생성).
- 또한, word단위의 embedding과 word embedding -> encoder 를 통해 나온 sentence embedding의 성능 차이를 비교한다.
5.2 Conbined transfer Models
- word level의 transfer model과 sentence level model을 concatenate를 진행하여 conbined representation을 알아보고자 한다.
진행과정
1. Random하게 word embedding을 생성한다.
2. Transformer or DAN을 encoder로 task를 진행한다.
3. 그렇게 추출된 sentence embedding과 word embedding을 CNN or DAN에 태워 concatenate를 한다.
baseline 기반의 4가지 경우의 수로 각각의 dataset의 성능을 파악한 후 가장 좋은 경우의 수를 선택한다.
- word Transfer learning (CNN/DAN) + Sentence embedding , concat
- No word Transfer learning (CNN/DAN) + Sentence embedding , concat
- word Transfer learning
- No word Transfer learning
6.Experiments
- Transfer task model의 hyperparameter는 vizier과 light maual tuning대로 진행 했다.
- dev dataset으로 이용해 tuning을 진행하였지만 dev dataset이 없으면 cross-validation을 통해 진행하였다.
- training은 각 model별로 10번씩 반복 진행
- Transformer는 DAN과 다르게 trade-off를 재정의 했는데 model complexity와 일정 성능을 나타내기에 필요한 dataset의 크기로 정의하였다.
7.Result
- Table 2를 보면 Transformer encoder가 DAN encoder보다 성능이 좋아보이는 것을 알 수 있다.
- DAN encoder가 가끔 Transformer encoder보다 좋은 성능을 보이는 부분이 있다.
- sentence embedding을 사용한 Transfer learning을 보면 word ebedding만 사용한 model보다 성능이 좋음을 알 수 있다.
- Sentence & Word ebedding Transfer learning이 다른 model들에 비해 성능이 매우 좋았다.
- Sentence embedding이 word embedding보다 성능에 더 영향을 줌을 알 수 있다.
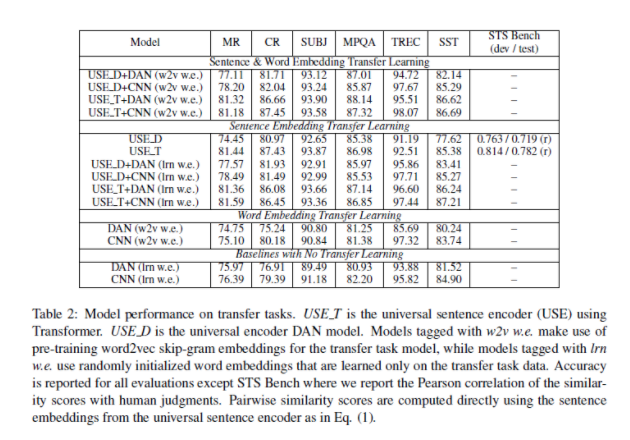
용어 정리
- USE_T : universal sentence encoder Transformer
- USE_D : universal sentence encoder Deep Averaging Network
- w2v w.e : pre-training word2vec embedding
- lrn w.e : randomly initialized word embedding
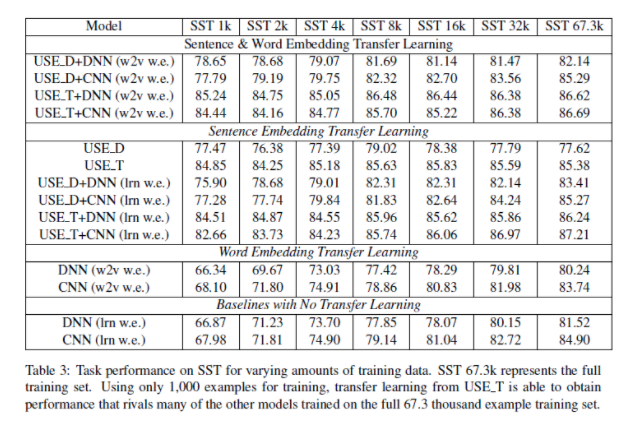
- Table 3은 데이터 셋의 크기에 따라서 성능의 차이를 보여준다.
- 많은 양의 데이터 일수록 model마다 성능이 상향됨을 알 수 있다.
- transfer learning을 하지 않은 model의 경우 상향되는 정도가 크다.
- 적은 양의 데이터 일수록 sentence 단위의 transfer learning이 좋은 성능을 나타냄을 알 수 있다.
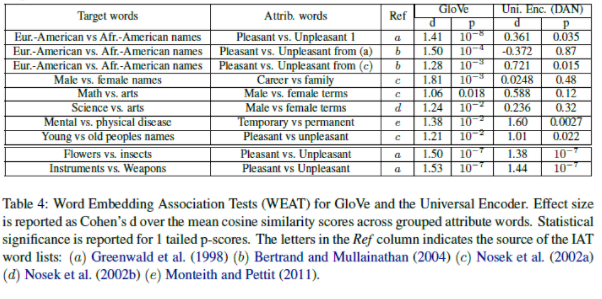
- Table 4는 GloVe embedding과 DAN을 비교한 것이다.
- DAN은 GloVe와 비슷한 결과를 냈지만, ageism,racism,sexism과 관련된 dataset의 경우 성능이 약하다.
7.1 Discussion
- 데이터 셋의 크기가 적으면 transfer learning을 사용한 model이 성능이 좋다.
- complexity와 accuarcy간의 trade-off를 적절히 맞게 해야한다.
8. Resource Usage
Resource Usage 같은 경우는 compute usage와 memory usage로 나눠 볼 수 있다.
- compute usage
- Transformer의 경우, time complexity가 O(n2)을 가진다.- DAN의 경우, time complexity가 O(n)을 가진다.
- memory usage
- Tramsformer의 경우, space complexity가 O(n2)를 가진다.- DAN의 경우, space complexity가 일정하다.
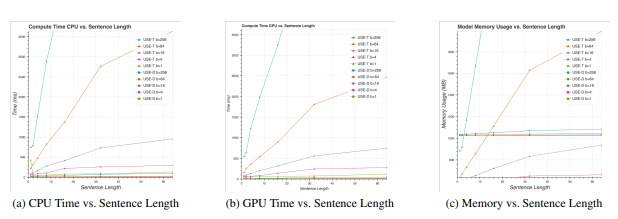
-CPU, GPU의 경우 sentence length가 커짐에 따라서
- Transformer의 경우 기울기가 커짐을 알 수 있다.
- DAN의 경우 기울기가 유사하거나 별 차이가 없음을 알 수 있다.
- Memory의 경우 sentence length가 커짐에 따라서
- Transformer의 경우 기울기가 커짐을 알 수 있다.- DAN의 경우 기울기가 유사하거나 별 차이가 없음을 알 수 있다.
- 다만, 낮은 batch size에 대해서는 Transformer가 유리하다.
9. Conclusion
- Transformer와 DAN 모두 sentence embedding으로 좋은 성능을 나타냄.
- sentence level embedding이 word level embedding에 비해 성능이 좋음.
- 그 중, transfer learning word embedding + sentence embedding model의 성능이 가장 좋음
- limited training dataset이 있을때 고려해볼 가치가 있음.
- Transformer와 DAN을 사용할때 compute time과 memory의 trade-off를 고려해서 선택할 필요가 있음.
- reference
https://www.researchgate.net/publication/333616995_Training_Neural_Response_Selection_for_Task-Oriented_Dialogue_Systems
https://sh-tsang.medium.com/review-skip-thought-vectors-a18565e7255a
https://arxiv.org/pdf/1803.11175.pdf
