Text Summarization with Pretrained Encoders (BERTSUM)
0. Abstract
BERT는 최근 광범위한 NLP task를 발전시킨 Pretrained Language model입니다. 본 논문에서는, BERT를 활용하여 텍스트 요약에 적용할 수 있는 방법을 소개하고 Extractive model(추출모델)과 Abstractive model(생성모델) 모두에 대한 일반적인 framework를 제안합니다.
1. Introduction
ELMo, GPT, BERT 등과 같은 pretrained language model은 sentiment analysis, to question answering, natural language inference(NLI), named entity recognition, textual similarity에 이르는 많은 NLP task에서 SOTA를 달성했습니다. 대부분의 pretrained language model은 다양한 classification task들과 관련된 문장 및 문단 수준의 자연어 이해를 위한 encoder로 채택되었습니다. (e.g. 두 문장이 entailment 관계인지 예측, 4개의 alernative sentences 중 문장의 완성도 결정 등)
본 논문에서는, language model이 text summarization에 미치는 영향을 검증합니다. 이전의 task들과는 달리, ‘Text Summarization’은 개별 단어와 문장의 의미를 이해하는 것을 뛰어넘는 광범위한 자연어 이해 능력이 요구되며, 문서의 의미를 대부분 보존하면서 더 짧게 ‘압축’하는 것을 의미합니다.
본 논문에서는, summarization의 2가지 유형인 Extractive model, Abstractive model을 모두 포함하는 일반적인 framework에서 텍스트 요약에 대한 BERT의 잠재력을 탐구하며, BERT 기반의 새로운 문서 수준의 encoder를 제안합니다.
- Extractive Model : 문서 수준의 특징을 포착하기 위해 encoder의 맨 위에 inter-sentence transformer layers를 쌓아서 생성
- Abstractive Model : 사전 훈련된 BERT encoder를 랜덤하게 초기화된 transformer decoder와 결합하는 encoder-decoder architecture 제안
여러 데이터셋에 걸쳐, Extractive, Abstractive setting 모두에서 SOTA를 달성
- Contribution 3가지
1) summarization task에 대한 document encoding의 중요성 강조
2) Extractive & Abstractive summarization 모두에서 pretrained language model을 효과적으로 사용하는 방법 제시
3) 추후 비슷한 연구들의 baesline이 될 가능성
2. Background
2.1 Pretrained Language Models
Pretrained Language model은 NLP task의 핵심기술로 사용되고 있으며, 대규모 말뭉치를 기반으로 단어의 contextual representation을 학습함으로써 단어 임베딩의 아이디어를 확장시켜 나갑니다. BERT는 3,300M 단어 말뭉치에 대해 MLM(Masekd Language Model)과 NSP(Next Sentence Prediction)를 기반으로 훈련된 language representation model입니다.
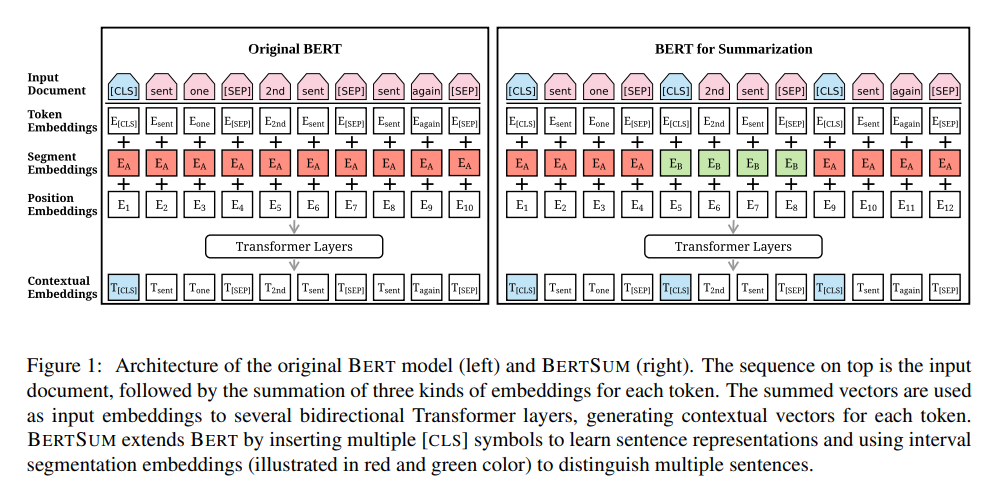
BERT의 일반적인 architecture는 그림 1의 왼쪽 부분에 나와있습니다. ‘sent one’, ‘2nd sent’, ‘sent again’ 이라는 문장이 입력으로 주어진 경우, 먼저 입력 문장을 토큰 형태로 변경한 다음 첫 문장의 시작 부분에만 [CLS] 토큰을 추가하고 모든 문장의 마지막 부분에 [SEP] 토큰을 추가합니다. [CLS]의 출력 표현은 전체 시퀀스에서 정보를 집계하는데 사용됩니다. 수정된 텍스트는 으로 표현되고, 토큰을 BERT에 입력하기 전에 각 토큰 에 총 3가지 종류의 임베딩(token embedding, segmentation embedding, position embedding)이 할당됩니다. 이 3가지의 임베딩은 single input vector 로 합쳐지며, BERT의 input으로 입력됩니다.
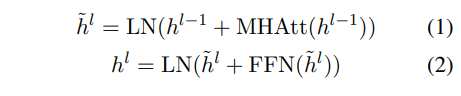
위 식에서 는 input vector, LN은 layer nomalization(정규화 연산), MHAtt는 multi-head attention 연산, 은 stacked layer의 깊이를 나타냅니다. BERT는 풍부한 contextual information과 함께 각 토큰에 대한 output vector 를 생성합니다.
2.2 Extractive Summarization
이제 추출요약과 생성요약에 대해 살펴보도록 하겠습니다.
Extractive Summarization은 주어진 텍스트에서 문서의 본질적인 의미를 담고 있는 중요한 문장만 추출해 요약하는 과정을 의미합니다.
neural model은 extractive summarization을 classification 문제로 간주하며, neural encoder는 sentence representation을 만들고, 분류기는 어떤 sentence을 요약으로 선택해야 하는지를 예측하게 됩니다.
2.3 Abstractive Summarization
Abstractive Summarization은 주어진 텍스트를 의역해서 텍스트의 본질적인 의미를 담고 있는 새로운 문장을 생성합니다.
neural approach는 abstractive summarization을 sequence-to-sequence 문제로 개념화합니다.
- encoder :
mapping (a sequence of tokens) → (continuous representations) - decoder :
-토큰별로 (target summary) 자동으로 생성
-auto-regressive manner → 모델링 조건부 확률 :
3. Fine-tuning BERT for Summarization
이제 요약을 위한 BERT의 fine-tuning 과정을 살펴보도록 하겠습니다.
3.1 Summarization Encoder
기존의 BERT를 summarization에 바로 적용하기엔 한계가 있는데 그 이유는 다음과 같습니다.
- 첫번째로, BERT는 MLM으로 훈련되기 때문에 출력 벡터는 문장단위가 아닌 토큰 단위로 출력하게 됩니다. 하지만 요약 task에서는 대부분의 모델이 문장 수준의 표현을 다루게 됩니다.
- 두번째로, BERT는 segment embedding으로 sentence-pair를 입력으로 받게 됩니다. 하지만 요약 task에서 우리는 여러 개의 문장(2문장 이상)들을 인코딩해야 합니다.
따라서 입력데이터의 형태를 수정해서 사용하게 됩니다.
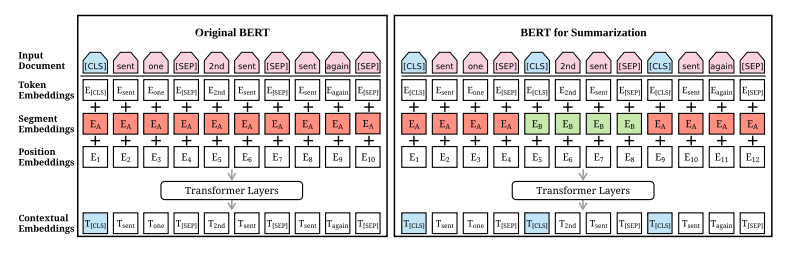
제안된 BERTSUM의 architecture는 그림 1의 오른쪽 부분에 나와있습니다. 기존 BERT에서는 첫번째 문장의 시작 부분에만 [CLS] 토큰을 추가했지만 요약 task에서는 BERT 모델에 여러 문장을 입력하고 입력한 모든 문장에 대한 표현이 필요합니다. 따라서 BERTSUM에서는 모든 문장의 시작 부분에 [CLS] 토큰을 추가하고 [CLS] 토큰 위치의 출력 벡터는 해당 문장의 feature를 함축하게 됩니다. 이후 문장을 구별하는 segment embedding을 진행하는데 BERT에서는 주어진 두 문장을 또는 형태로 반환합니다. 하지만 요약 task에서는 2개 이상의 문장을 입력하므로 interval segment embedding을 통해 여러 문장을 구별하게 됩니다. 홀수 번째 문장에서 발생한 토큰은 에, 짝수 번째 문장에서 발생한 토큰은 에 매핑합니다. 그림에서 1,3번째 문장의 토큰들은 , 2번째 문장의 토큰들은 로 매핑된 것을 확인할 수 있습니다. 이런 식으로 구성함으로써 하위 transformer layer가 인접한 문장을 표현하고, 상위 transformer layer가 여러 문장의 결합된 형태를 표현하는 방식으로 구조적으로 Document Representation을 학습할 수 있다고 합니다. 또한 기존 BERT 모델의 positional embedding의 최대 길이는 512인데, BERTSUM에서는 무작위로 초기화되고, encoder에서 다른 매개변수로 finetuned 되는 더 많은 positional embedding을 추가하여 이 한계를 극복했다고 합니다.
3.2 Extractive Summarization
(문장들을 포함하는 document)
: document의 i번째 문장
Extractive Summarization은 document의 각 i번째 문장()을 요약문에 포함시킬지에 대한 여부를 {0,1}로 라벨링하는 것이라 정의할 수 있습니다.
BERTSUM에서 i번째 [CLS] 토큰의 출력이 를 표현하는 벡터입니다. (→ ). BERT의 결과(BERT에서 얻은 문장 표현 : T)를 transformer의 encoder layer에 공급합니다.
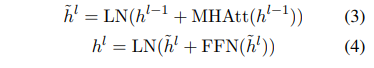
= encoder
= encoder로부터 표현된 은닉 상태 (encoder는 hidden state를 출력)
: BERTSUM에 의해 출력된 문장 벡터
: 벡터 T에 각 문장의 위치를 나타내는 positional embedding을 더해주는 함수
→ 입력값 T에 위치 임베딩을 추가한 값
= 최상위 encoder
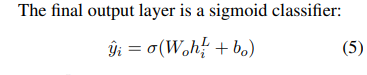
마지막 output layer는 sigmoid classifier → 각 문장을 요약에 포함시킬지 여부의 확률을 얻음
: transformer의 top layer (L번째 layer)의 (i번째 문장)에 대한 벡터 → L = 2인 transformer가 가장 성능이 우수
⇒ 우리는 이 모델을 BERTSumExt라고 합니다.
loss는 y와 y_pred 간의 binary classification entropy를 이용했고, BERTSUM과 함께 동시에 fine-tuning 되었습니다. 또한 Adam 옵티마이저(=0.9, =0.999)를 사용하고 learning rate는 다음을 따릅니다.
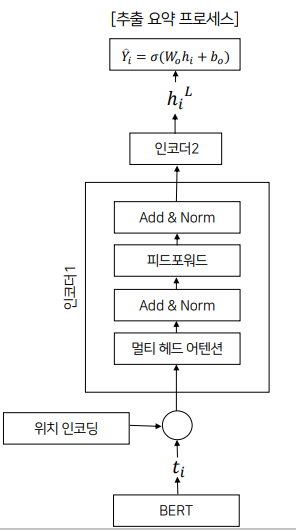
정리하면, BERT로부터 나온 문장의 표현인 를 입력받아서 위치 인코딩을 해준 후, 트랜스포머의 인코더에 입력으로 넣어주고, 인코더를 거쳐 최상위 인코더의 은닉 상태인 값을 얻습니다. 그 이후 을 시그모이드 분류기에 입력해 요약에 문장의 포함 여부를 반환하는 프로세스를 거치게 됩니다.
3.3 Abstractive Summarization
생성 요약에서는 주어진 텍스트의 내용을 압축해 새로운 형태의 요약 문장을 생성하지만, BERT는 입력한 토큰의 표현만 반환하므로 본 논문에서는 Abstractive Summarization을 수행하기 위해 stardard encoder-decoder framework를 사용합니다. encoder는 pretrained BERTSUM, decoder는 무작위로 초기화된 6-layered transformer로 정의합니다. 따라서 encoder는 의미있는 표현을 생성하고, decoder는 이 표현을 사용해 요약을 생성하는 방법을 학습하게 됩니다. 하지만 여기에는 fine-tuning 중에 encoder와 decoder 사이에 불일치가 발생한다는 문제점이 존재합니다. encoder는 pretrained 되어있기 때문에 과적합될 수 있고, decoder는 무작위로 초기화되어있기 때문에 과소적합이 발생할 수 있습니다. 이를 해결하기 위해 adam optimizer 2개를 사용합니다.() 즉, encoder와 decoder에 서로 다른 학습률을 적용하게 됩니다. encoder가 pretrained 되어 있기 때문에 학습률을 줄이고 좀 더 부드럽게 감쇠하도록 설정합니다. (decoder가 안정화되고 있을 때 encoder가 더 정확한 gradient로 학습될 수 있도록)
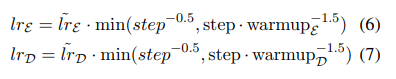
encoder의 학습률은 (6), decoder의 학습률은 (7)이고, 이때 ~ 이고, , ~ 이고, 입니다.
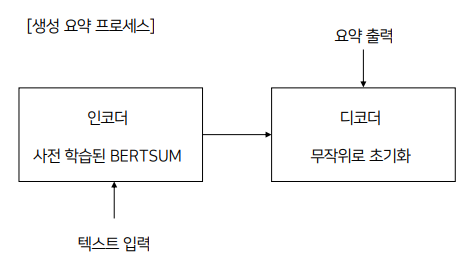
⇒ 우리는 이 모델을 BERTSumAbs라고 부릅니다.
또한 논문에서는 Two-stage fine-tuning approach를 제안하는데, 먼저 Extractive Summarization task에서 encoder를 먼저 fine-tuning하고, 이후 Abstractive Summarization task에서 fine-tuning을 진행하는 BERTSumExtAbs를 제안합니다. 이 접근 방식은 개념적으로 매우 간단하며, 모델은 architecture의 변화없이 두 task간의 공유되는 정보를 활용할 수 있다는 장점이 있습니다. BERTSumAbs보다 BERTSumExtAbs의 성능이 더 뛰어나다고 합니다.
4. Experimental Setup
4.1 Summarization Datasets
본 논문에서는 모델 평가를 위해 3가지의 benchmark dataset을 이용했고, 이 dataset들은 강조부터 매우 간단한 문장 요약까지 다양한 요약 스타일을 나타냅니다.
- 1) the CNN/DailyMail news highlights dataset : somewhat Extractive
-뉴스 기사 & 관련 하이라이트 : 기사에 대한 간략한 개요 제공
-입력 document : 512 tokens로 제한
- 2) the New York Times Annotated Corpus(NYT) : somewhat Extractive
-추상적인 요약이 있는 110,540개의 기사(article) 수록
-입력 document : 800 tokens로 제한
- 3) XSum : Abstractive
-‘What is this articles about?’의 질문에 답하는 226,711개의 뉴스 기사 + 한 문장 요약본
-입력 document : 512 tokens로 제한
- 3가지 dataset에 대한 다양한 통계 외에도, 추상성의 척도로써 gold summaries에서 새로운 bi-gram의 비율을 나타냈습니다. (Table 1)
- Extractive model은 Extractive summary를 가진 dataset에서 더 나은 성능을 발휘하고, Abstractive model은 Abstractive summary를 가진 dataset에서 더 나은 성능을 발휘할 것이라 기대
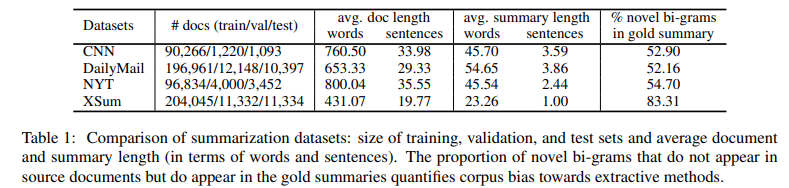
1) train, validation, test set의 크기 2) 평균 문서 길이(단어, 문장) 3) 평균 요약 길이(단어, 문장) 4) 새로운 bi-gram 비율(원본 문서에는 나타나지 않지만, gold summary에서는 나타나는)
→ DailyMail의 경우 요약문의 길이가 길고, XSUM의 경우 요약문의 길이가 짧음
→ CNN/DailyMail은 요약문에 원본 문서에 등장하지 않은 새로운 단어가 상대적으로 적게 등장하기 때문에 추출 요약문과 유사하다고 표현함
→ XSum은 요약문의 길이가 짧지만 대부분 새로운 단어로만 요약을 작성했기 때문에 굉장히 Abstractive하다고 할 수 있음
4.2 Implemetation Details
Extractive & Abstractive setting 모두에 대해 BERTSUM을 구현하기 위해 ‘bert-base-uncased’ 버전의 BERT를 사용했습니다.
- Extractive Summarization
-5000 steps 동안 학습이 되었고, 2 step마다 gradient accumulation을 적용 & 1000 step 마다 model checkpoint 저장
-validation set의 evalution loss를 기반으로 상위 3개의 checkpoint를 선택하고, test set의 평균 결과를 보고
- ORACLE summary : greedy하게 추출된 추출 요약용 정답 요약문
→ 존재하는 대부분의 데이터셋이 생성 요약을 기준으로 작성되었기 때문에 추출 요약 학습에 사용하기 위해 ROUGE-2 score를 gold summary에 대해 최대화하는 문장을 자체적으로 생성 - LEAD-3 : 뉴스기사의 첫 3문장을 추출 요약의 정답 요약문으로 작성한 경우
-새로운 문서에 대해 예측할 때, 각 문장에 대한 점수를 순위 매겨서 요약으로 상위 3문장을 선택했습니다.
-중복 문장을 줄이기 위해서 요약문 내의 후보 문장끼리 겹치는 trigram이 존재하면 해당 후보를 스킵하는 방식인 Trigram Blocking 방식을 사용했습니다. (고려중인 문장과 이미 요약의 일부로 선택된 문장 사이의 유사성을 최소화 하고자 하는 것 같음)
- Abstractive Summarization
-모든 abstractive model에서 모든 linear layer 앞에 dropout(0.1)을 적용 (Label smoothing with smoothing factor 0.1)
-Transformer Decoder :
1) hidden units : 768
2) hidden size for feed-forward layers : 2048
-200,000 steps 마다 학습이 되었고, 5 step마다 gradient accumulation을 적용 & 2500 step 마다 model checkpoint 저장
-validation set의 evalution loss를 기반으로 상위 3개의 checkpoint를 선택하고, test set의 평균 결과를 보고
-End-of-sequence token이 나올 때까지 decoding & Trigram Blocking
-Decoder가 Copy & Coverage Mechanism 사용 X → minimum-requirement model을 만들기 위해서 + 추가적인 하이퍼파마미터 도입해서 튜닝할 수 있음
5. Results
5.1 Automatic Evaluation
ROUGE를 평가지표로 사용하였으며, informativesness를 평가하기 위해 ROGUE-1(unigram)과 ROUGE-2(bigram overlap), fluency를 평가하기 위해 ROUGE-L을 사용했습니다.
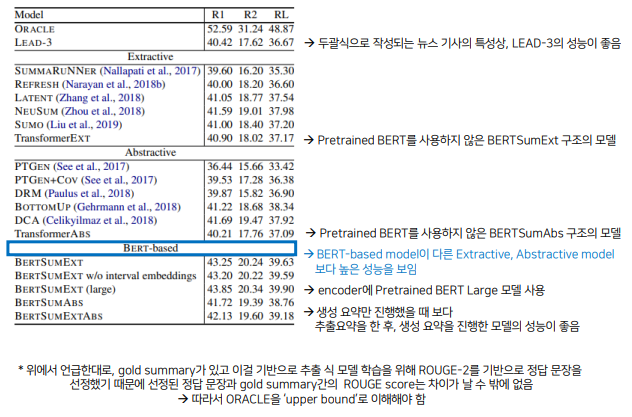
- 1) CNN/DailyMail
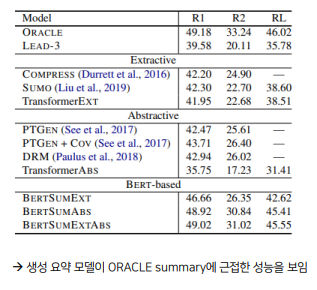
- 2) NYT
- 3) XSum

5.2 Model Analysis
- Learning Rates
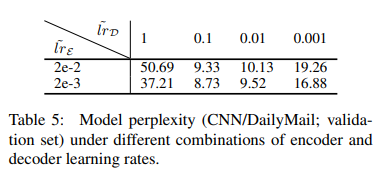
Table 5는 다양한 encoder, decoder의 learning rate 조합에서의 CNN/DailyMail validation set에 대한 model perplexity를 보여줍니다. ~ ,~ 일 때가 최적임을 알 수 있습니다.
- Position of Extracted Sentences
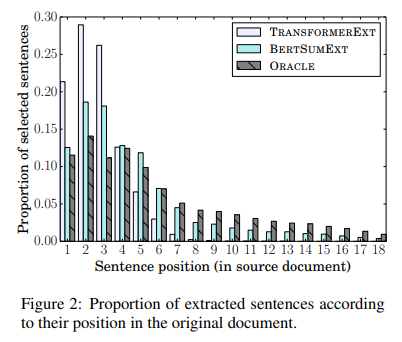
CNN/DailyMail에 대해서 추출 요약 모델이 선택한 요약 문장의 원본 문서에서의 위치를 조사했습니다. ORACLE summary는 비교적 고르게 분포되었습니다. 랜덤하게 encoder를 설정한 TransformerEXT 모델은 대부분 원본 문서에서 앞에 있는 문장을 요약 문장으로 선택합니다. 제안한 추출요약 모델인 BERTSumExt는 ORACLE summary와 비슷하게 비교적 고른 선택을 하는 것을 알 수 있었습니다.
- Novel N-grams
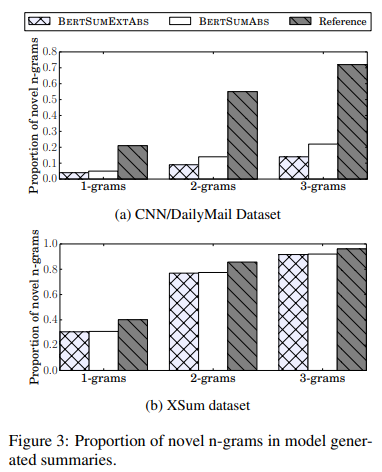
CNN/DailyMail에서 생성 요약 모델의 새로운 n-gram 비율은 reference summary에 비해서 훨씬 낮지만, XSum에서는 이 차이가 작게 나타납니다. 또한 BERTSumExtAbs는 BERTSumAbs보다 새로운 n-gram이 적게 생성되는데 BERTSumExtAbs는 처음에 추출 모델로 학습되기 때문에 원본 문서에서 문장을 선택할 때 조금 더 치우칠 수 밖에 없습니다.
5.3 Human Evaluation
Human Evalution의 경우 사람이 모델의 성능을 평가한 것으로 Amazon Mechanical Turk를 이용해 아래와 같은 방식으로 Human Evaluation을 수행합니다.
- Question : 문제를 내는 실험자가 정답 요약문(gold summary)만을 보고 질문을 만든 뒤, 해당 질문과 모델이 추출, 생성한 요약문만 평가자(피험자)에게 줬을 때 얼마나 대답을 할 수 있는지를 평가(원본 문서와 정답 요약문은 주지 않음)
- RANK : 각 모델들이 생성한 요약문들과 정답 요약문(gold summary)을 주고 informativesness(정보성), fluency(유창성), succinctness(간결함)에 대해 순위를 매김
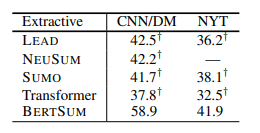
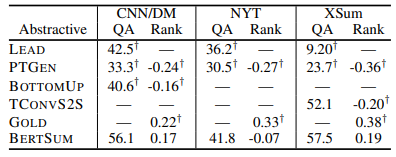
→ 모든 경우에서 BERTSUM이 타 모델들에 비해서 높은 성능을 보이는 것을 확인할 수 있습니다.
6. Conclusion
- Pretrained BERT는 텍스트 요약에 유용하게 활용될 수 있음을 보여줌
- 새로운 문서 수준의 encoder를 도입
- Abstractive & Extractive Summarization을 위한 일반적인 framework를 제안함
- 3가지 데이터셋에 대한 실험결과는 BERTSUM 모델이 automatic & human-based 평가 지표에도 SOTA를 달성한다는 것을 보여줌
7. References
https://www.youtube.com/watch?v=PQk9kr9dGu0
https://kubig-2021-2.tistory.com/53
구글 BERT의 정석 → ch6. 텍스트 요약을 위한 BERTSUM 탐색
