[Paper Review](2020, Ruoxi Wang) DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems
Recommender_System

📄 DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems(2020, Ruoxi Wang)
작성자: 오진석
ABSTRACT
-
Feature engineering 많은 예측 모델에서 중요한 과정 및 역할을 하고 있지만, 복잡하고 직접 하나하나 진행해야 한다는 exhaustive search와 같은 과정을 거쳐야 한다는 단점이 있습니다.
-
딥러닝 모델은 학습하는 과정에 있어, feature 간의 interaction이 implicit하게 반영되기는 하지만 feature cross를 효과적으로 학습하는 것에 있어서는 무리가 있다고 합니다.
-
이번 논문에서는 추천 시스템의 성공적인 성능을 위한 효과적인 feature cross의 학습을 가능하게 해주는 딥러닝 기반의 Deep & Cross Network, DCN 모델을 소개할 예정입니다.
- feature cross, 특성 교차는 하나 이상의 feature를 조합하여(crossing) 만들어진 합성(synthetic) feature를 의미합니다.
- feature간 crossing(결합)을 통한 Feature Engineering은 기존의 feature가 개별적으로 줄 수 있는 영향 이상을 주며 예측 성능을 높일 수 있습니다.
-
그러나 보통 모델에 사용되는 feature는 매우 sparse and large하기 때문에, 효과적인 cross를 조합하여 의미있는 feature cross를 찾는 과정은 exhaustive search(완전 탐색)을 요구하게 되며 당연히 비효율적이게 됩니다.
-
Deep & Cross Network, DCN은 feature interaction(feature간 상호작용)을 자동적으로 그리고 효율적으로 가능하게 해주는 구조를 제안했었습니다.(2017, Deep & Cross Network for Ad Click Predictions)
-
그러나 방대한 학습 데이터와 모델 서빙 관점에서 과거 2017년 DCN은 feature interaction을 학습함에 있어 한계점을 보이기도 했습니다.
-
아직까지도 모델 production 과정에서 많은 DNN 모델들은 여전히 전통적인 feed-forward neural network에 의존하고 있으며, 이는 feature cross에 있어 조금 비효율적이라고 말할 수 있습니다.
-
-
결론적으로 2020년에 발표된 DCN 논문에서는 방대한 데이터 환경의 large scale에서 적용가능한 DCN-Version 2를 제안하게 되었습니다.
-
DCN-V2는 feature interaction을 학습함에 있어 여전히 비효율적인 cost 문제가 남아있기는 하지만 대부분의 대표적인 dataset에서 SOTA의 성능을 보였습니다.
1. INTRODUCTION
-
Learning to rank, LTR 은 방대한 데이터와 정보가 넘쳐흐르는 현대에서 정보검색 분야에 있어 굉장히 흥미로운 과제로 발전할 수 있었고 검색 분야, 추천 시스템, 광고 분야에서 머신러닝과 딥러닝이 결합되면서 더욱 광범위하게 발전하고 있는 분야가 되고 있습니다.
- LTR 모델의 중요한 요소 중 하나는, 효과적인 feature crosses를 통해 수학적으로 그리고 실무적으로 모두 모델의 성능에 기여할 수 있는 것입니다.
-
효과적인 feature crosses는 많은 모델의 높은 성능에 있어 굉장히 중요한 열쇠라고 할 수 있는데, 그 이유는 개별 feature가 모델에 전달하는 영향 이외의 추가적인 상호작용 정보가 포함되어 있기 때문입니다.
-
예를 들어 'country'와 'language'의 조합은 각 feature가 전달하는 기능 이상의 정보를 전달할 수 있다고 합니다. (한번에 이해가 가지는 않습니다..)
-
추가적인 예로는, 믹서기를 고객에게 추천하는 모델을 설계하려 할 때, 바나나와 요리책 구매 여부에 대한 각 feature는 개별적인 정보를 전달해줄 수는 있지만 바나나와 요리책 구매 여부에 대한 feature cross는 고객이 믹서기를 구매함에 있어 보다 추가적인 정보를 전달해 줄 수 있습니다.
-


출처 : https://www.tensorflow.org/recommenders/examples/dcn
-
선형 모델에서는 보통 hand-craft가 요구되는 feature engineering을 통해 feature crosses를 진행하고 모델의 expressiveness를 확대하게 됩니다.
-
또한 대부분의 데이터가 categorical한 web-scale applications 상에서는 large and sparse의 특징인 combinatorial search space(수많은 조합)를 수반하기 때문에 exhaustive 합니다.(비효율적, 오래걸리는....)
-
그렇기 때문에 보통 domain 지식이 요구되고 모델을 generalize 하게 설계하기 굉장히 어렵습니다.
-
-
시간이 지나면서, 고차원 벡터를 저차원 벡터로 투영하는 임베딩 기술이 발전하게 되면서 다양한 분야에서 일반적으로 사용하게 되었습니다.
-
Factorization Machines(FMs)은 2개의 latent vectors(잠재 변수)의 내적을 통해 feature interactions을 뽑아내기도 했습니다.
- 선형 모델의 전통적인 feature cross와 비교했을 때, FM은 보다 generalize한 성능을 반영했다고 할 수 있었습니다.
-
지난 몇 십년간, 컴퓨팅 파워와 데이터의 폭발적 증가로, 산업에서 LTR 모델은 linear model과 FM-기반 모델에서 딥러닝 모델로 점진적으로 변화하고 있으며, 이러한 변화 및 발전은 추천 시스템과 검색 분야의 전반적인 모델 향상을 일궈냈습니다.
- 보통 딥러닝 모델은 feature interaction을 찾는 것에 괜찮은 성능을 보이는 것으로 여겨졌지만, 사실 최근 연구를 통해서 단순 딥러닝 모델로는 2nd, 3rd feature cross를 추정하는 것에는 비효율적이라고 밝혀졌습니다.
-
효과적인 feature crosses를 찾기 위한 보다 정확하고 통상적인 해결책으로는 wider하고 deeper한 Network를 통해 model capacity를 증가시키는 것입니다.
- model capacity가 증가하게 되면 일반적으로 무거운 모델이라고 표현할 수 있으며, 이러한 방법은 모델을 serving하고 production하는 과정에서 문제점이 발견되기 때문에 양날의 검이라고 표현할 수도 있습니다. (무거운 모델이란, 파라미터가 많고 추론하는데 시간이 오래 걸리는 것 등으로 표현할 수 있을 것 같습니다.)
-
DCN 또한 wider하고 deeper한 Network를 기반으로 feature cross를 적용하는 것에는 효과적이었지만, large-scale 환경에서의 production 과정에서는 굉장히 많은 어려움을 마주쳤습니다.
-
그래서 2017년에 걸쳐 2020년에 발표한 DCV-V2 에서는 기존 DCN을 개선하게 되었으며, 이미 실험들을 통해 learning to rank 시스템에 성공적으로 배포하였습니다.
- DCN-V2의 핵심은 cross layer 를 통한 explicit한 feature interaction을 학습하고 deep layer 를 통해 추가적인 implicit한 interaction을 학습함에 있습니다.
2. RELATED WORK
-
최근의 feature interaction을 학습하는 핵심 아이디어는 딥러닝을 통해 explicit, implicit feature crosses를 모두 뽑아내는 것이었습니다.
-
explicit crosses를 모델링하기 위해서 대부분의 최근 연구들은 딥러닝에서 비효율적인 multiplicative operations(곱셈)을 제안했으며, feature x1과 x2의 interaction을 효과적이고 명백하게 모델링하기 위해 function f(x1, x2)를 설계하였습니다.
-
다음은 어떻게 explicit, implicit 한 feature crosses를 조합하기 위해 제안했던 연구 방법론들에 대해 알아보겠습니다.
Parallel Structure
- Wide & Deep Model:
Wide 부분은 raw feature의 cross를 입력으로 하고 Deep 부분은 DNN 모델인 Wide & Deep model으로 부터 영감을 얻어 한번에 Parallel(병렬적)으로 학습하는 구조임
-
그러나 Wide 부분을 위한 cross features를 선별하는 과정에서 feature engineering 문제를 만나게 됨
-
그럼에도 불구하고 Wide & Deep model은 이러한 parallel한 구조가 많은 연구에 차용되었고 발전되고 있음
Stacked Structure
-
또 하나의 연구는 explicit한 feature crosses를 뽑아내는 interaction layer를 임베딩 layer와 DNN 모델 중간에 위치되어 있는 stacked(쌓여 있는)으로 학습하는 구조임
-
이 구조는 초반에 feature interaction을 뽑아내고 DNN 모델에서 충분한 학습을 진행하게 됨
3. PROPOSED ARCHITECTURE: DCN-V2
-
이번 목차에서는 explicit, implicit feature interactions를 모두 학습하는 새로운 모델인 DCN-V2의 구조에 대해서 다루게 됩니다.
-
DCN-V2는 embedding layer를 시작으로 explicit feature interaction을 뽑아내는 복수의 cross layer를 포함하는 cross network, 그리고 implicit feature interactions를 뽑아내는 deep network로 구성되어 있습니다.
-
기존 DCN에 비해 DCN-V2가 개선된 점은 쉬운 배포를 위해 elegant formula를 유지함에도 불구하고 web-scale production data 관점에서 복잡한 explicit cross를 모델링함으로써 풍부한 표현력을 가지게 되었고 production 과정에 보다 최적화 되어 있다고 합니다.
-
cross network와 deep network를 결합하는 방식의 차이로 stacked과 parallel한 2가지 구조가 존재합니다.

3-1. Embedding Layer
-
embedding layer에는 categorical과 dense feature가 입력으로 들어가게 됩니다.
-
최종 embedded vector은 categorical features의 임베딩과 dense features의 정규화된 값이 concat되어 출력됩니다.
3-2. Cross Network
-
DCN-V2의 핵심은 explicit feature crosses를 뽑아내는 cross layer에 있으며, layer가 가지는 수식은 다음과 같이 확인할 수 있습니다.
-
은 기본 feature를 의미하는 embedding layer의 출력 벡터라고 생각할 수 있습니다.
-
은 반복적으로 계산되는 각 layer의 입력 및 출력 벡터를 의미하며 는 각 layer에서 학습되는 weight와 bias 벡터입니다.
-
-
각 layer에서 발생하는 cross layer function을 시각화하여 표현하면 다음과 같이 이해할 수 있습니다.
-
각 layer의 입력인 은 똑같이 weight와 bias로 linear 계산이 이뤄지게 된 뒤에, embedding layer의 출력인 을 element-wise product 해줌으로써 feature간 interaction이 반복적으로 계산됩니다.
-
첫번째 cross layer의 계산 과정은, 가 linear 계산을 통과한 결과와 가 element-wise product되면서 update되는 weight가 기존 feature간의 interaction 정보를 담고 있다고 할 수 있습니다.
-

- 1개의 cross layer가 계산되는 과정을 간단하게 살펴보면, 2nd feature interaction에 대한 정보를 가지고 있는 weight를 확보할 수 있게 되며 weight를 2차원으로 표현하면 다음과 같습니다.
x_0 = [v1, v2, v3] # feature embedding vector
W = [[w11, w12, w13],
[w21, w22, w23],
[w31, W32, W33]]
x_1 = [[W11*V1*V1, W12*V1*V2, W13*V1*V3],
[W21*V2*V1, W22*V2*V2, W23*V2*V3],
[W31*V3*V1, W32*V3*V2, W33*V3*V3]]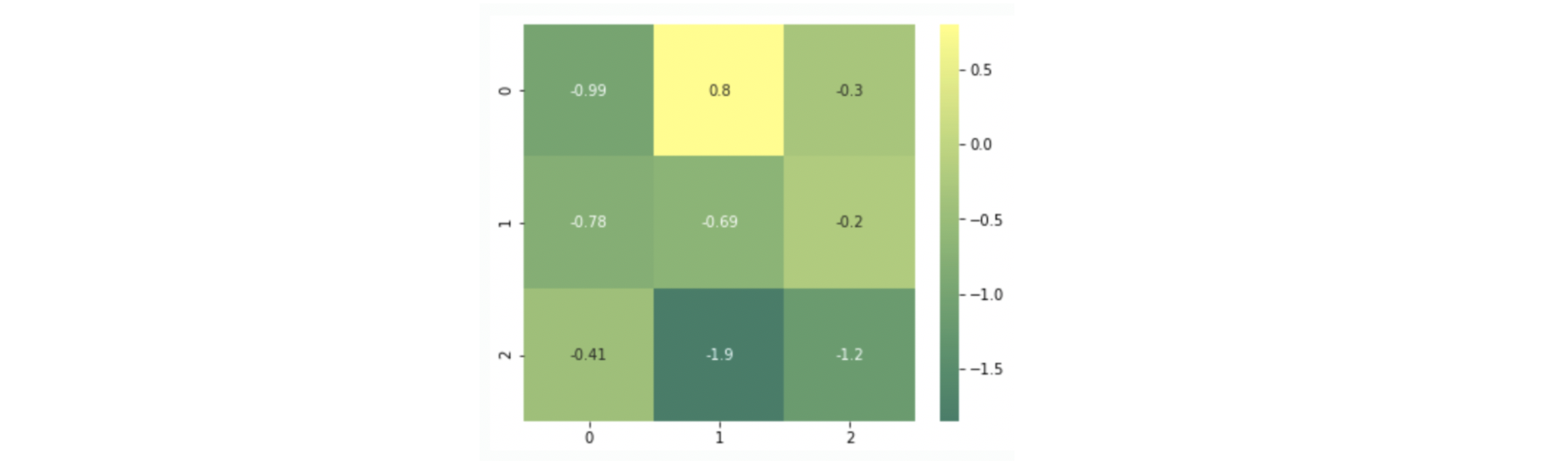
-
해당 heatmap은 첫번째 cross layer가 가지고 있는 weight를 시각화한 것이며, 각 weight가 feature간의 2차원 조합을 기반으로 update됨을 알 수 있습니다.
-
이 때, weight가 더 높을수록 해당 feature 조합이 해당 모델의 결과를 예측하는 것에 있어 강한 상호작용을 의미한다고 해석할 수 있습니다.
3-3. Deep Network
- Deep Network는 전형적인 feed-forward neural network로 다음과 같은 linear 계산과 activation fuction으로 이루어져 있음
3-4. Deep and Cross Combination
-
앞 서 언급했듯이, cross network와 deep network를 결합하는 방식의 차이로 Stacked Structure과 Parallel Structure로 구분할 수 있으며, 데이터에 따라서 성능의 차이를 보인다고 합니다.
-
Stacked Structure은 가 cross network를 통과한 후에 deep network를 통과하는 구조입니다.
- cross network의 출력값인 가 deep network의 입력값인 에 해당합니다.

- Parallel Structure은 가 동시에 cross network와 deep network에 입력되는 구조로 cross network의 출력인 와 deep network의 출력인 의 결합(concatenate)으로 최종 output layer를 통과하게 됩니다.

- 학습을 위한 손실함수, loss function으로는 binary label의 learning to rank system에서 주로 사용되는 Log Loss를 사용합니다.
❗️Log Loss 설명: 출처 - [데이콘 평가산식] log loss에 대해 알아보자, 데이콘
참고 자료

3개의 댓글

15기 류채은
[Paper Review](2020, Ruoxi Wang)DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems
- 단순 딥러닝 모델로는 2nd, 3rd feature cross를 추정하는 것에는 비효율적이다.
- DCV-V2 에서는 기존 DCN을 개선하게 되었으며, 이미 실험들을 통해 learning to rank 시스템에 성공적으로 배포한다
<구성>
embedding layer를 시작으로 explicit feature interaction을 뽑아내는 복수의 cross layer를 포함하는 cross network, 그리고 implicit feature interactions를 뽑아내는 deep network이 있다.
<결합 방식>
1) stacked
2) parallel
- Embedding Layer
: categorical과 dense feature가 입력 - Cross network
: explicit feature crosses를 뽑아냄 - Deep Network
: feed-forward neural network - Deep and Cross Combination
1) Stacked Structure
2) Parallel Structure

14기 박지은
DCV-V2는 feature 간의 feature cross의 학습을 가능하게 해주는 모델로, 기존의 DCN보다 더 방대한 데이터 환경의 large scale에서 적용 가능하도록 발전했습니다. DCN-V2는 embedding layer, cross network, deep network로 구성되어 있습니다. 먼저 embedding layer에서는 categorical feature와 dense feature가 입력으로 들어가서 categorical feature의 임베딩 값과 dense feature의 정규화된 값이 concat하여 출력됩니다. cross network는 cross layer로 feature 간의 interaction을 학습하는 DCN-V2의 핵심적인 기능이 있습니다. deep network는 전형적인 feed-forward neural network로, cross network와 stacked하거나 parallel한 방식으로 결합합니다. 이 두 가지 방식은 데이터에 따라 성능의 차이가 있다고 합니다. 마지막으로 손실함수는 log loss를 사용하게 됩니다. 기존의 추천시스템과는 다르게 feature 간의 상호작용도 학습할 수 있다는 것이 인상깊었던 논문이었습니다. 좋은 강의 감사합니다!
[15기 이성범]
본 논문에서 제안하는 Deep & Cross Network – Version 2, DCN-V2 모델은 기존의 DCN 모델보다 방대한 데이터 셋에서 적용 가능한 모델이다. 기본적으로 DNN 모델은 feature 간의 interaction을 implicit하게 반영한다. 하지만 feature cross, feature를 조합하여 새로운 feature를 학습하는 것에는 어려움이 존재한다. 이러한 어려움을 해결한 모델이 DCN 모델이다. DCN 모델은 feature cross를 효과적으로 학습하는 모델이다. 그러나 기존의 DCN 모델은 wider하고 deeper한 Network 구조를 가지기 때문에 Model Capacity가 매우 높아서 Large-Scale의 환경에서는 적용하기 어려웠다. 따라서 DCN의 효과적인 feature cross의 성능을 가짐과 동시에 Large-Scale의 환경에 적용시킬 수 있도록 고안된 모델이 바로 본 논문에서 제시하는 DCN-V2 모델이다.
DCN-V2 모델은 Embedding Layer를 시작으로 explicit feature interaction을 뽑아내는 복수의 Cross Layer를 구성하는 Cross Network, 그리고 implicit feature interaction을 뽑아내는 Deep Network로 구성되어 있다. DCN-V2 모델은 Cross Network와 Deep Network의 결합 방식에 따라서 Stacked와 Parallel 구조로 나뉘어진다. Stacked는 말그대로 모델을 쌓아서 Cross Network를 통과한 후에 Deep Network를 통과하여 output을 구하는 방식이고, Parallel는 말그대로 모델을 병렬적으로 구성하여 Cross Network를 통과한 값과 Deep Network를 통과한 값을 서로 concat 하여 output을 구하는 방식이다.
Embedding Layer에는 Categorical 형식의 Sparse한 feature의 Embedding feature과 Dens feature이 정규화 된 값의 형태로 concat되어 출력된다. Cross Network는 ResNet의 residual learning과 비슷한 방식으로 학습이 진행된다. Layer의 통과 전 feature와 통과 후의 feature를 서로 element-wise product를 하는 방식으로 feature간의 interaction이 학습된다. Deep Network는 우리가 잘 알고 있는 기본적인 DNN의 구조로 linear Layer와 Activation function으로 구성으로 학습이 진행된다.