[CS224N] Lecture 14 - T5 and large language models
T5 논문 배경
2018년, 2019년 경 많은 논문들
모델을 발전시켜나간다고 하지만 이후의 논문이 이전의 논문보다 더 좋은 성능을 보인다고 하기 어려움 (다른 데이터 셋을 이용해서 진행하기 때문에)
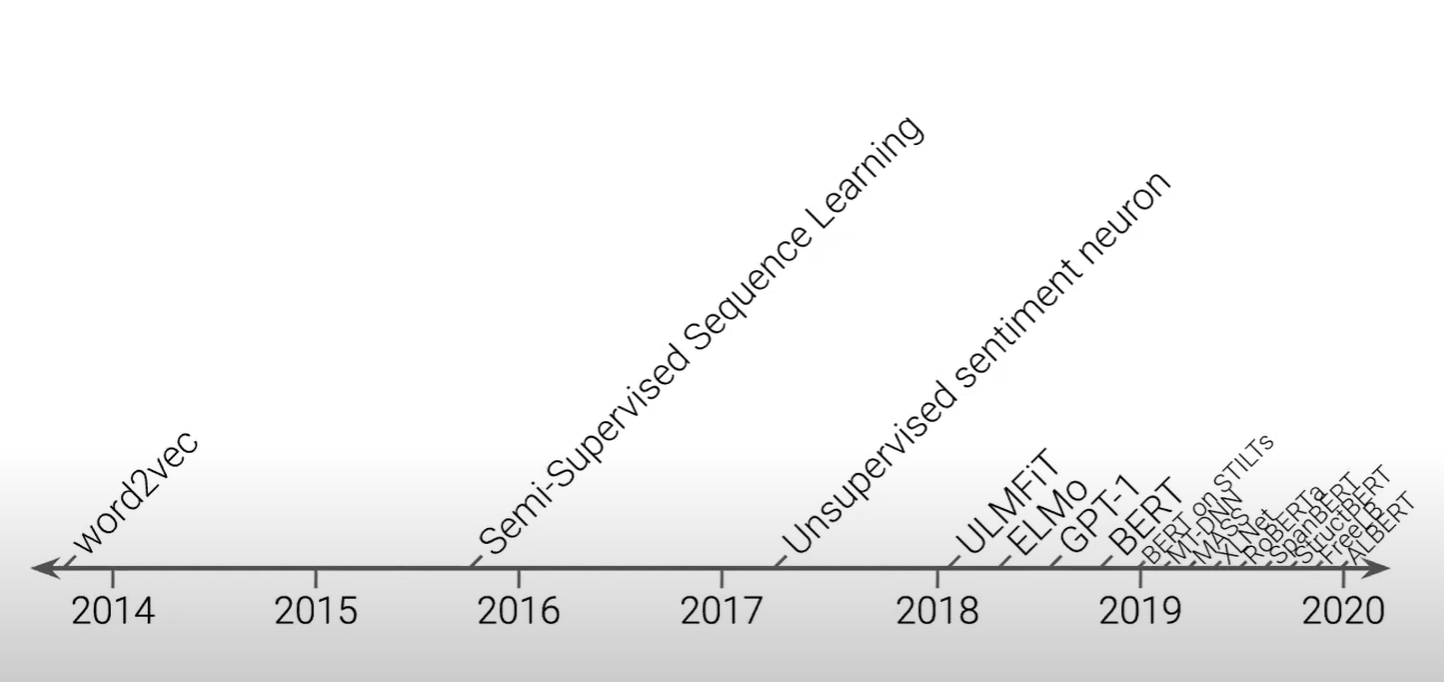
-> 진짜 좋은 작업을 수행하는 것이 무엇인가를 바라본 것이 T5 논문
T5 : Text-to-Text Transfer Transformer
모든 text problem을 같은 format 으로 바라보자!
-> 모든 문제를 text-to-text 작업으로 생각하는 것

Q1? 분류문제는 어떻게 해결할 것인가?
A1 ) label을 text를 이용해서 학습
Q2? regression 문제는 어떻게 해결? (숫자)
A2 ) "3.8" 처럼 floating point 숫자를 string으로 converting -> 성공적으로 regression
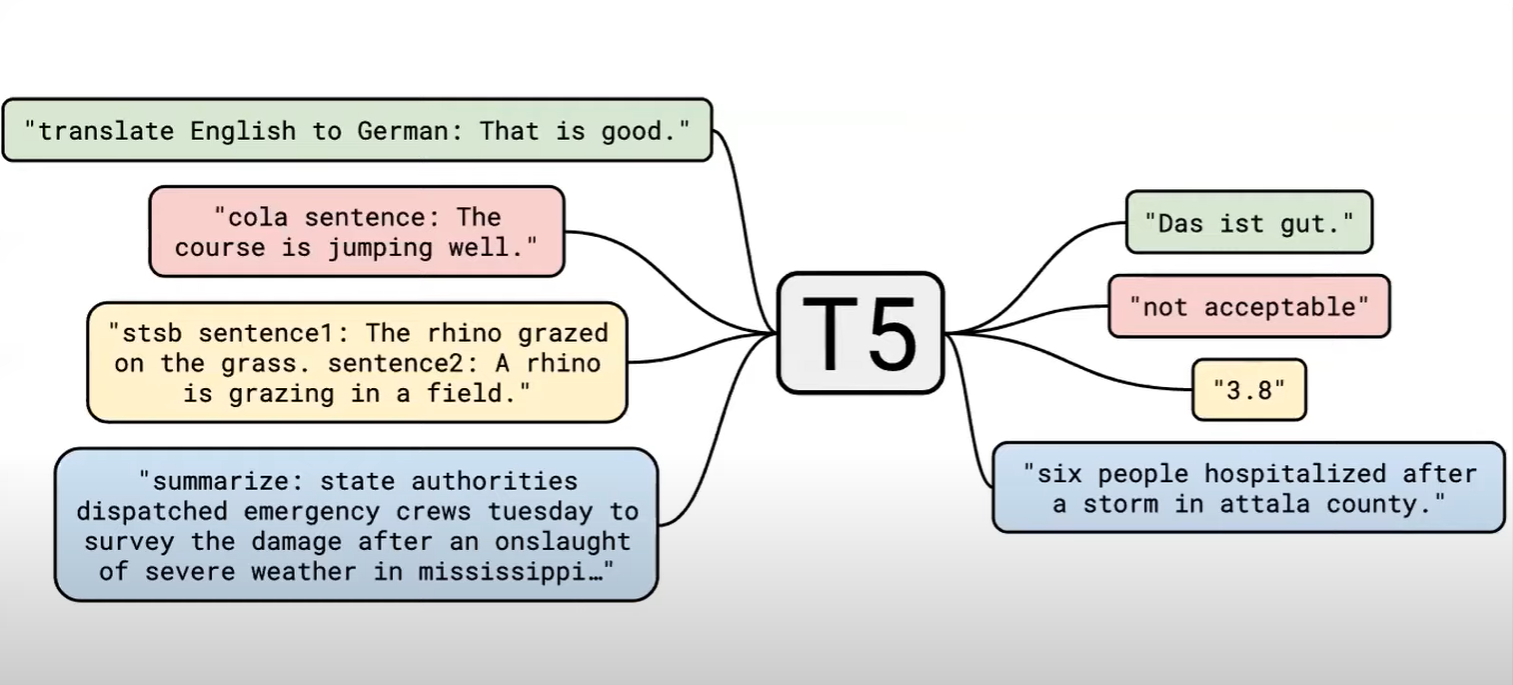
-> 번역, 분류, 회귀, 요약 등 다양한 task를 같은 방법으로 수행
이처럼 text-to-text, sequence-to-sequence format만을 사용해서 task를 해결했을 때,
original vanillia transformer만 사용하면 된다는 장점
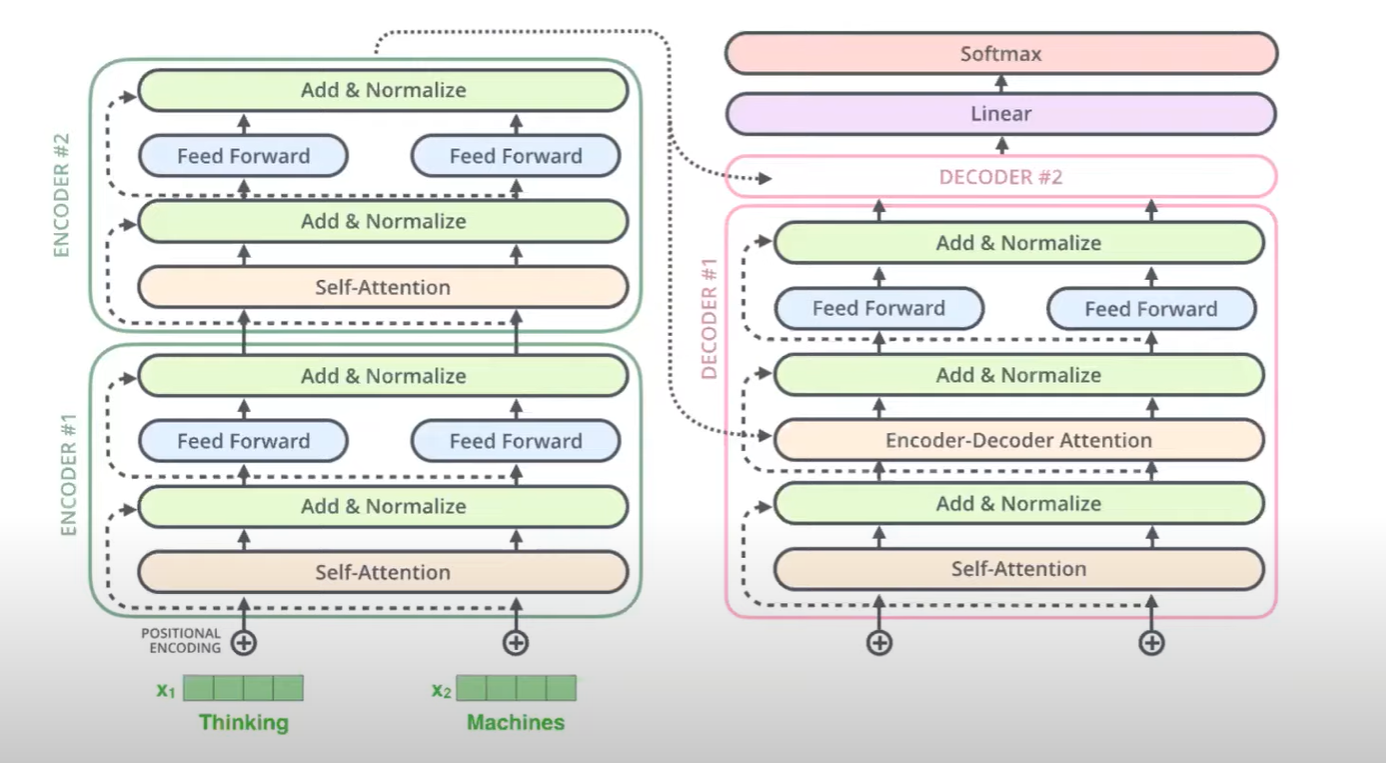
(다른 모델들은 조금씩이라도 standard transformer architecture 변형 필요)
T5 모델 학습 과정
data set 준비
1) web 크롤링을 통해 데이터를 가져오기
2) 방대한 데이터를 clean data로 만들기 (문장 부호 작업 등...)
C4 : tensorflow에서 제공하는 clean data 이용
data를 선정했다면 pre_train
pre_train
: 문장이 있으면 random하게 토큰을 골라서 drop
-> sentinel token(unique한 index를 갖는)으로 replace

모델의 목표 : sentinel token 자리에 들어갈 token을 추론하는 것
(BERT의 pre-train 방법으로 친숙한 방법)
pre-train 시 채택한 방법
- BERT-based size의 encoder-decoder 구조를 이용
- 다양한 task의 data set으로 fine tuning을 진행 (seperate하게)
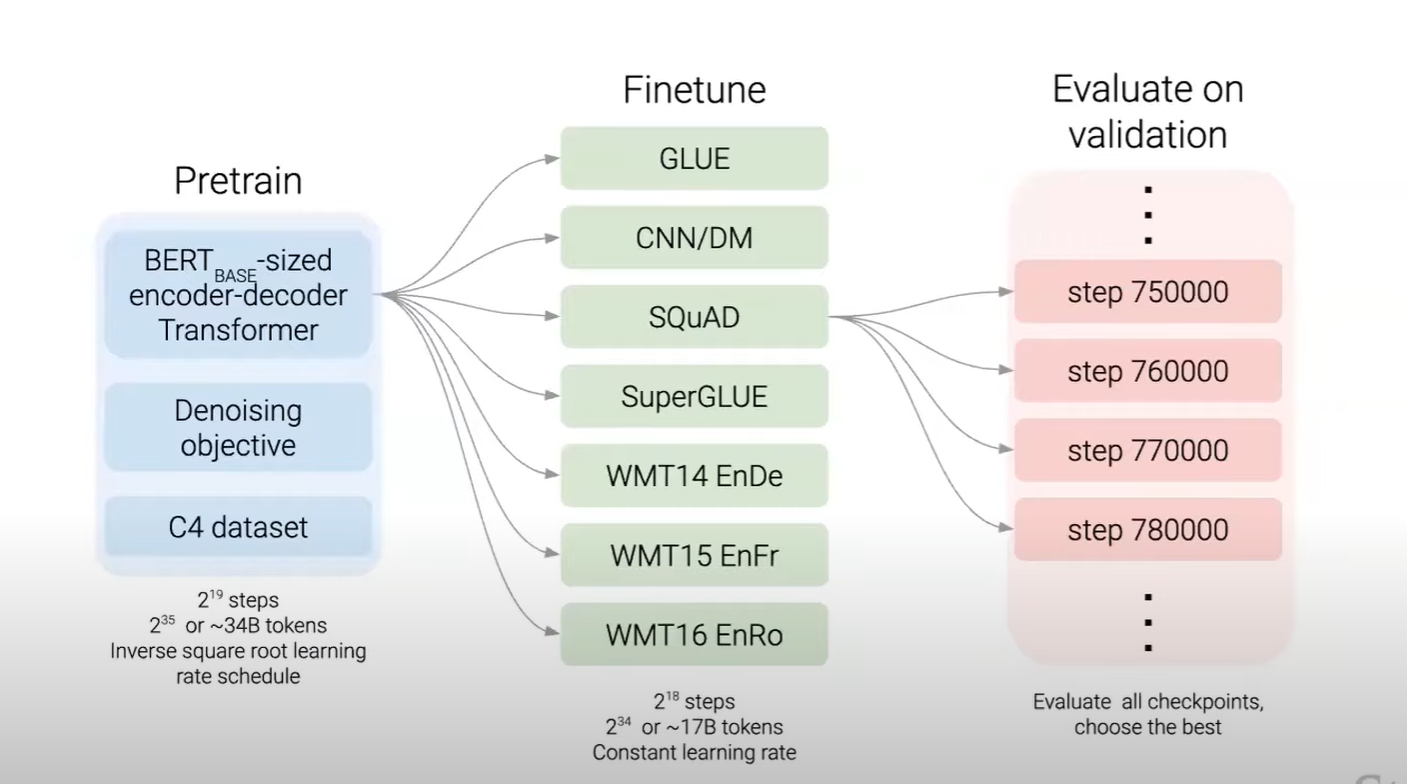
어떤 학습 방법을 채택하는 것이 유용한지에 대한 실험 결과
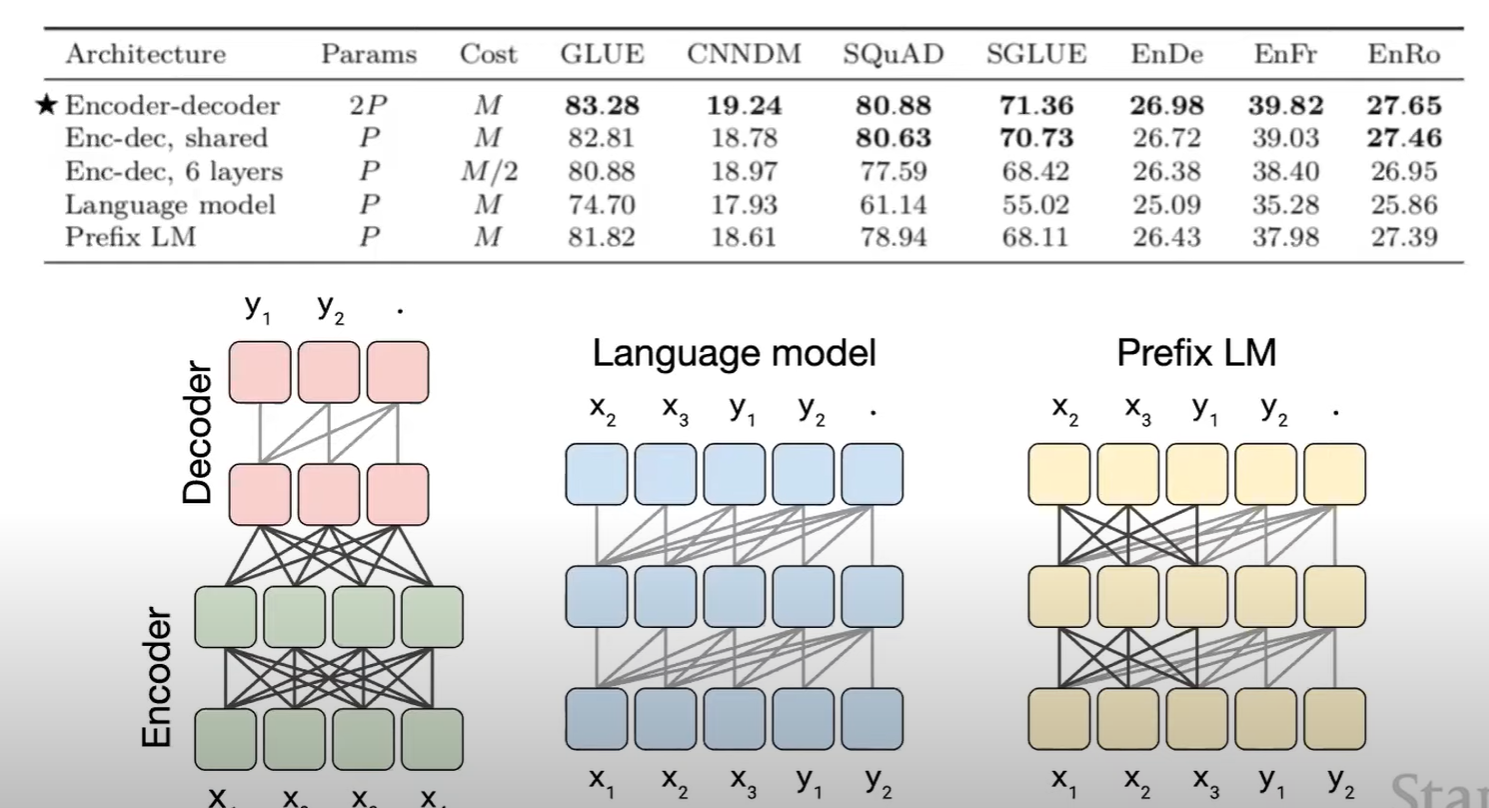
인코더-디코더 구조가 가장 효과적

replace corrupted span 방법이 가장 효과적
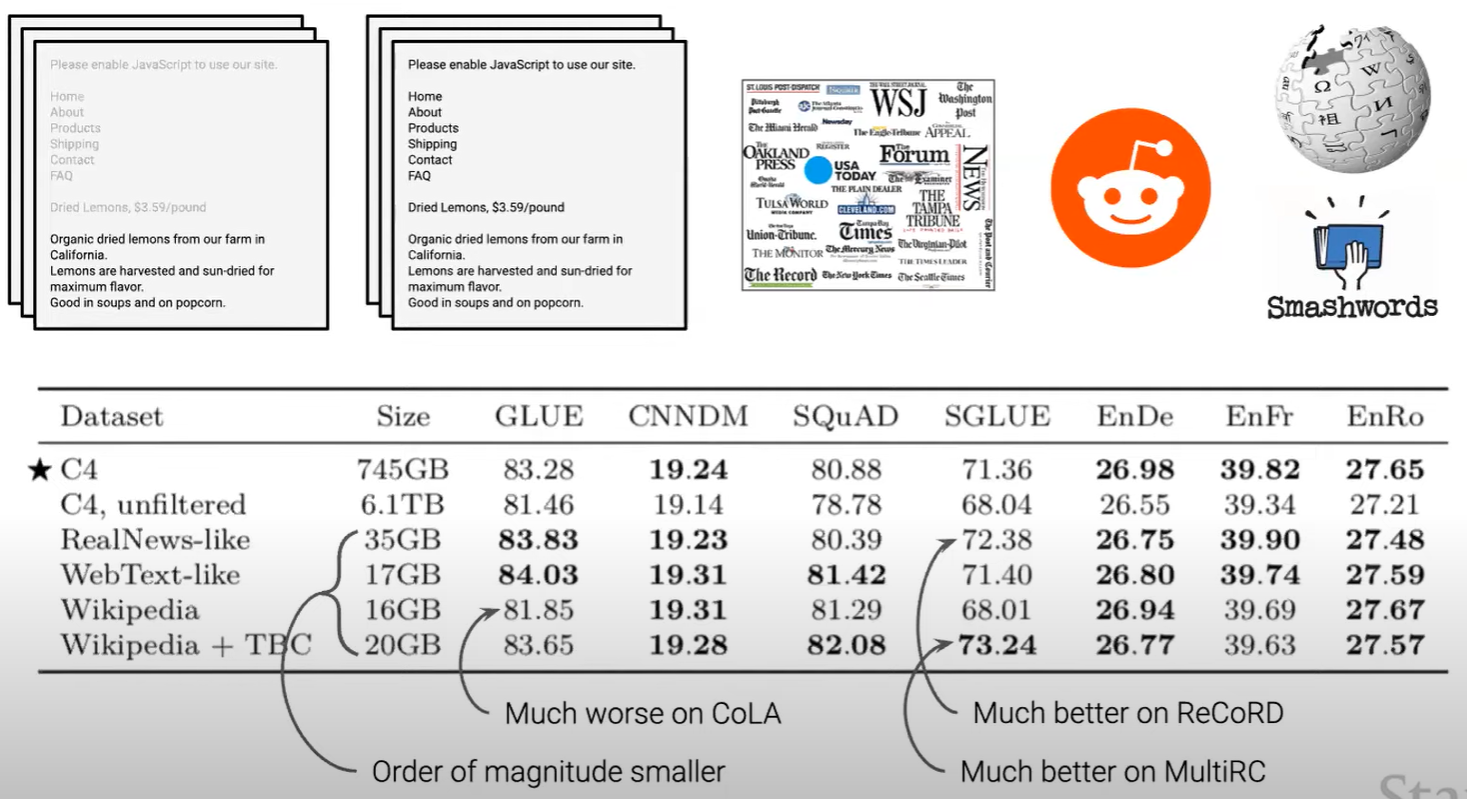
C4 데이터 그대로 사용하는 것이 효과적 / 다른 데이터들로 학습 시 특정 task에서만 성능이 잘 나오는 결과 나타남
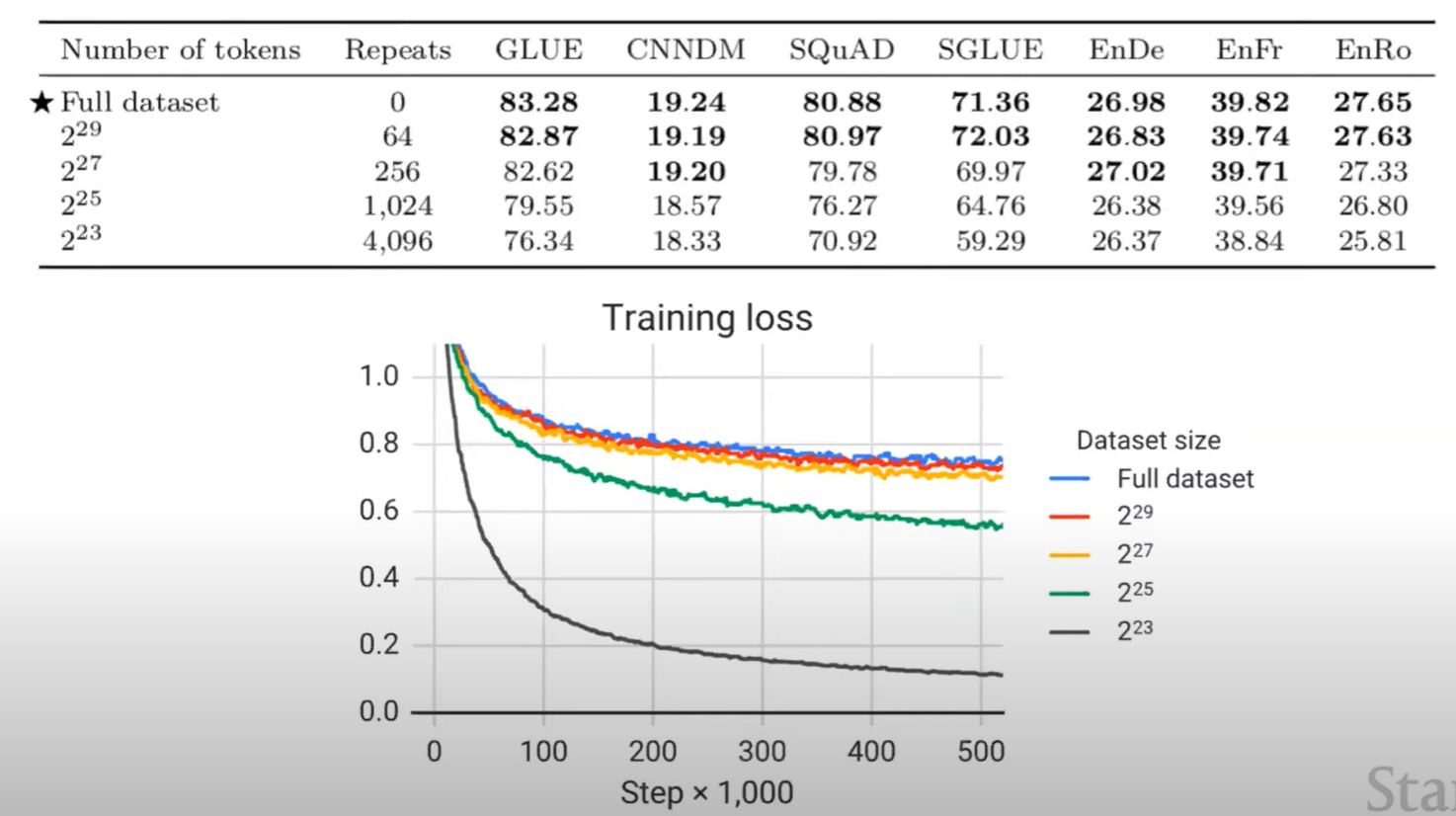
적은 양의 데이터로 너무 많은 횟수 사전 학습시키면 성능 악화
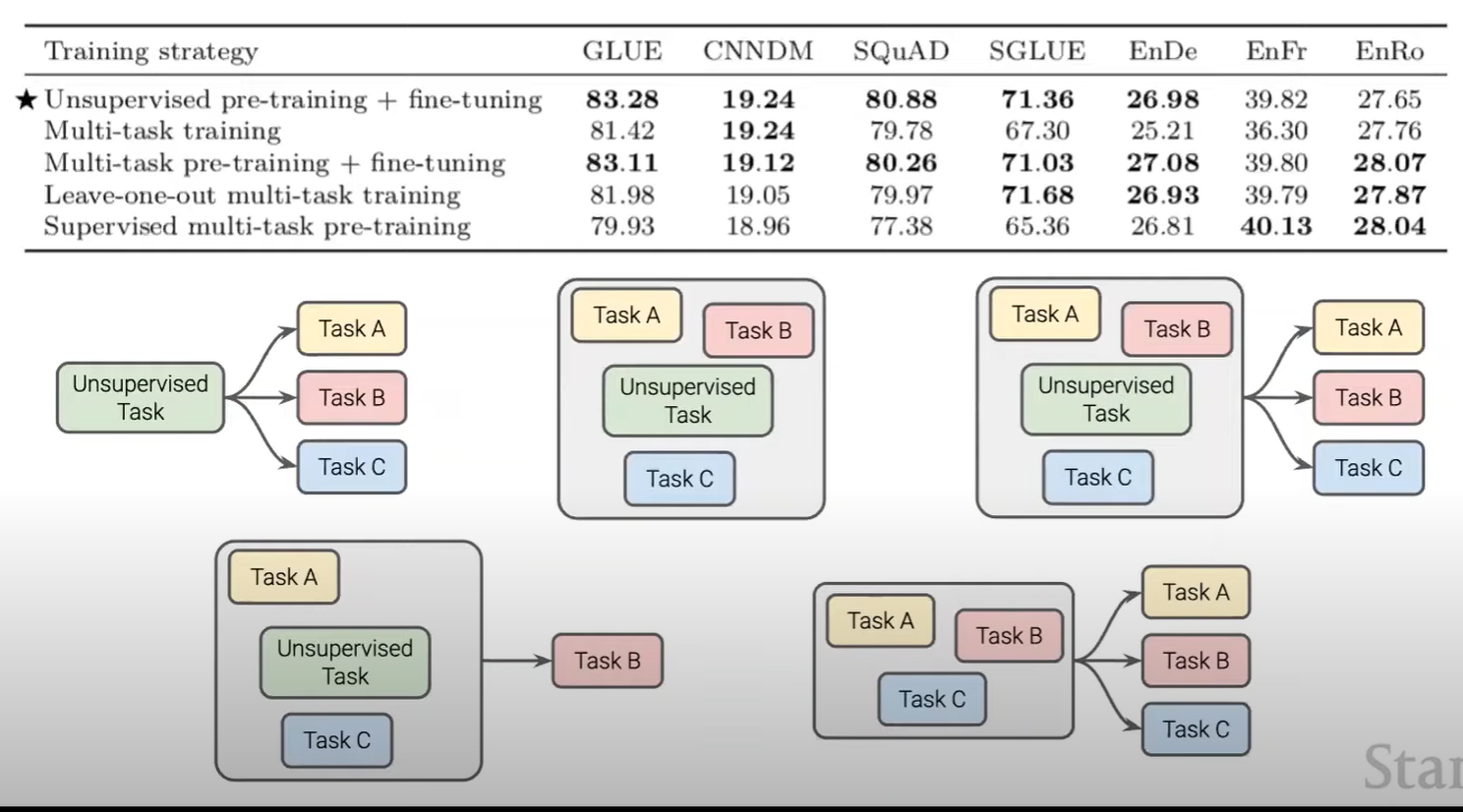
multi task data를 한번에 pretraining 시키고, 특정 task를 수행할 때는 그 task에 대해 각각 따로 fine-tuning 시켜서 사용하는 것이 효과적이라고 판단
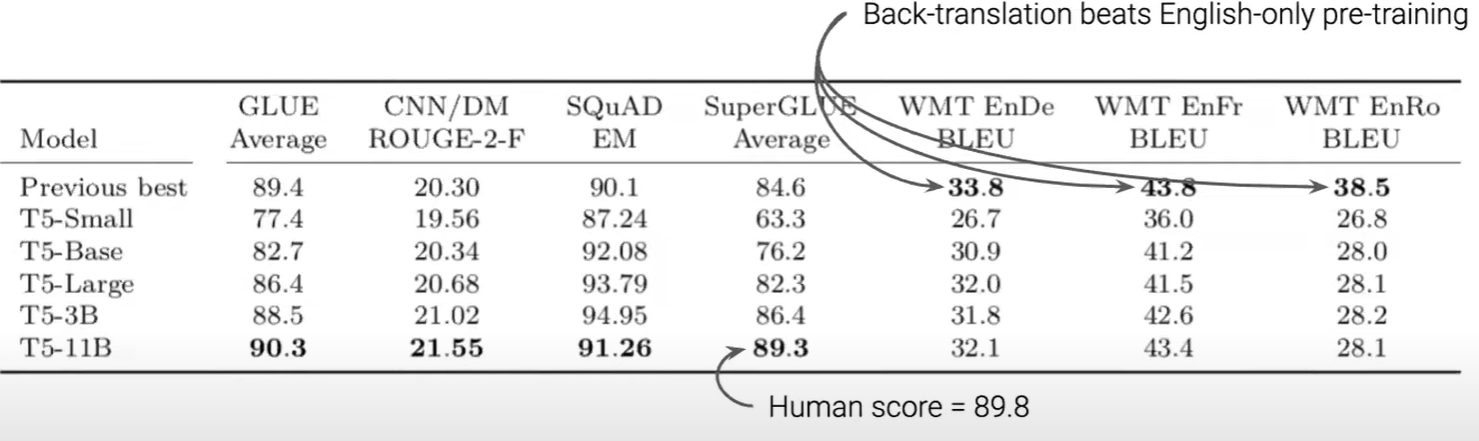
대다수의 모델이 그런 것 처럼, 모델크기가 클수록 오래 학습시킬수록 좋은 성능이 나온다는 것을 확인 가능
정리
- 인코더 - 디코더 구조
- sentinel token을 추론하는 방법
- C4 데이터셋 이용
- multi task pre-training
- bigger model
T5 모델의 활용 / 발전
mT5 : multi language T5

-> C4 데이터를 기반 + 크롤링 데이터를 더 더함 (101개의 언어 포함)
Reading comprehension
: 질문과 질문의 답을 찾을 수 있는 context가 주어질 때, 적절한 답을 찾는 task
(문장을 잘 이해하고, 질문에 대한 적절한 답을 찾는 것이 중요)
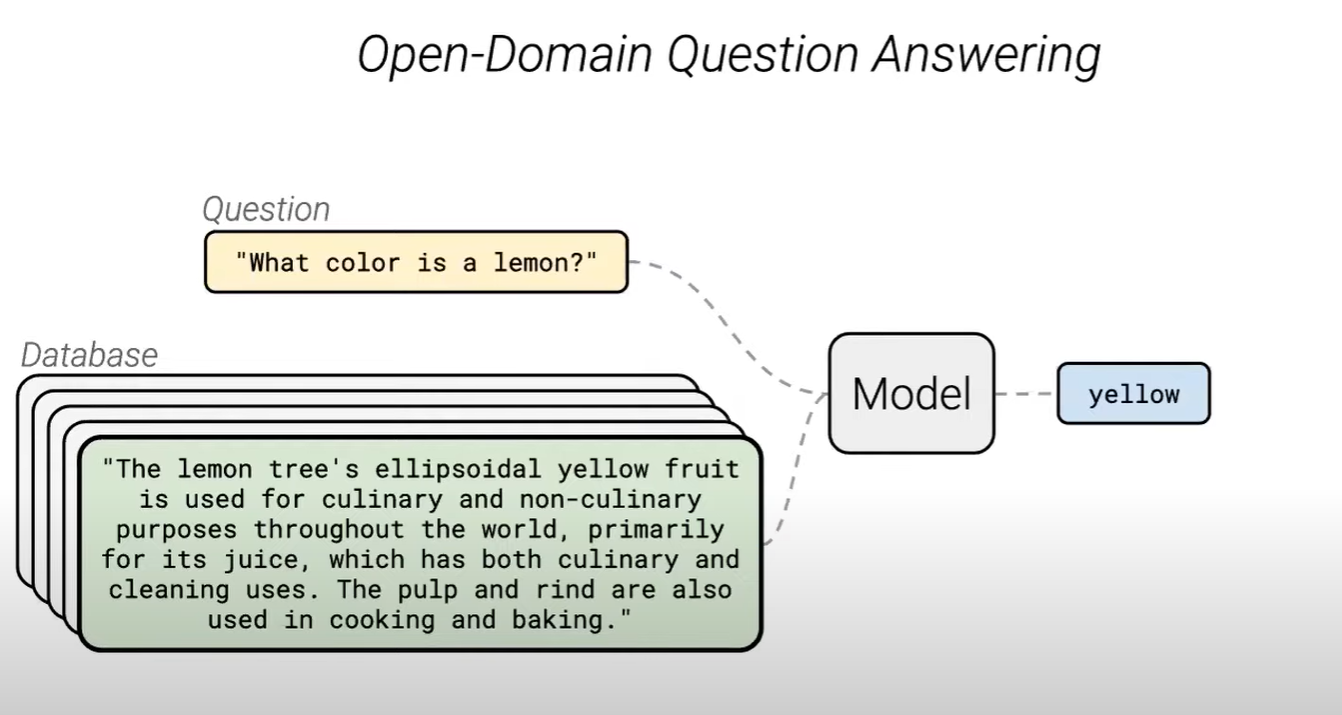
open domain에서 적절한 답을 찾아낼 수 있는 QA
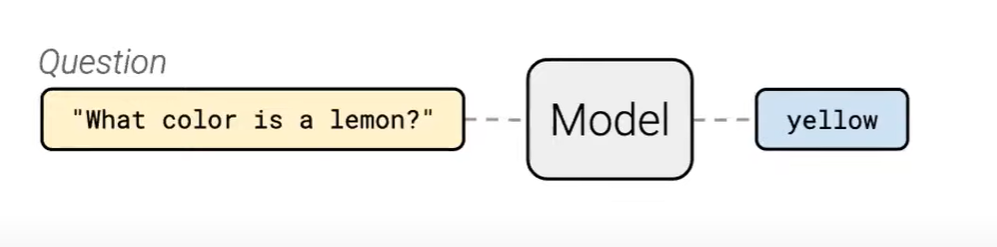
context 없이도 질문에 대한 답을 찾을 수 있음 (T5는 사전학습 시 대량의 데이터로 학습이 되어있기 때문에)
** 주의 : web 기반으로 학습할 시 개인정보일 가능성이 높다는 점 이슈
