[CS224n] Lecture 12 : Natural Language Generation
1) NLG
- 주어진 입력에 대한 새로운 text를 생성하는 것
- Machine Translation, Dialogue System, Summarization, Data-to-Text Generation, Visual Description 등 사람의 편의를 위해 text를 생성하는 업무
2) Basics of Natural Language Generation

- Autoregressive 형태의 일반적인 NLG모델은 예측해야할 단어의 이전까지의 단어 {y} 를 입력으로 다음 단어 생성
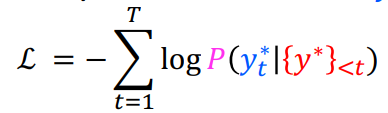
- 학습시 Negative Loglikelihood를 loss로 사용하여 loss를 minimize
Teacher Forcing
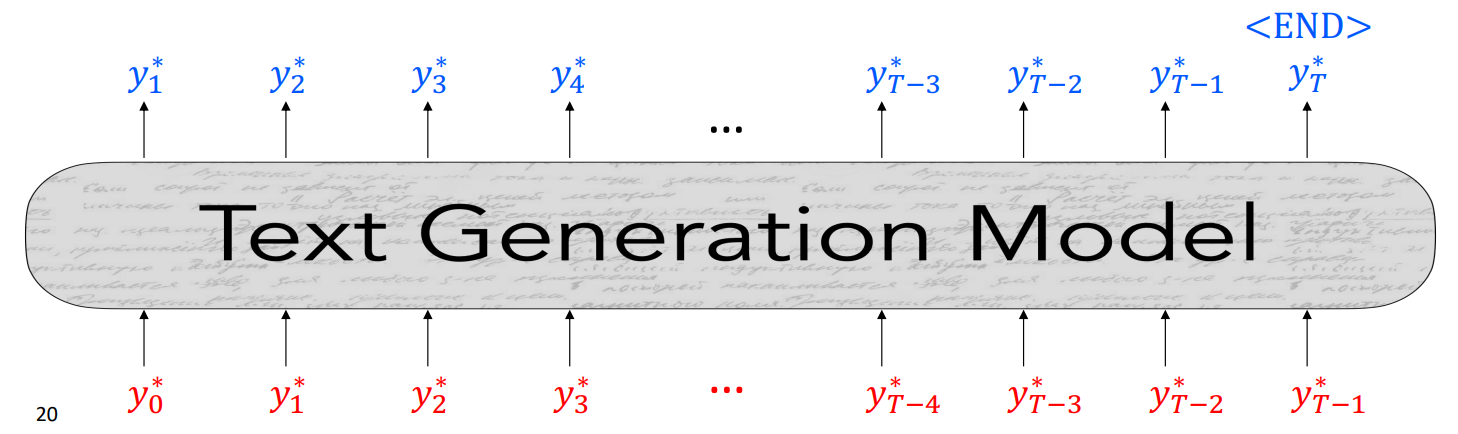
- 모델이 예측한 토큰 대신 실제 문장 토큰을 다음 예측의 입력으로 사용
- 이전 잘못 예측된 단어로 계속하여 잘못된 단어가 예측되는 현상을 예방

- decoding시에는 예측된 단어를 다음 예측의 입력으로 사용
3) Decoding from NLG models
Greedy Methods
- 완전 탐색이 어려운 vocab 크기가 어마어마하게 큰 경우, 휴리스틱한 탐색 방법인 Decoding Algorithm을 사용
[Argmax Decoding]
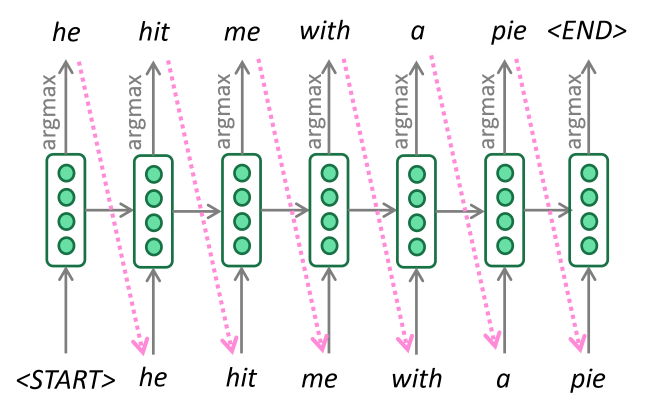
- 매 단계마다 가장 확률이 높은 단어를 선택
- Backtracking이 없어 performance가 떨어진다는 단점이 존재
[Beam Search Decoding]
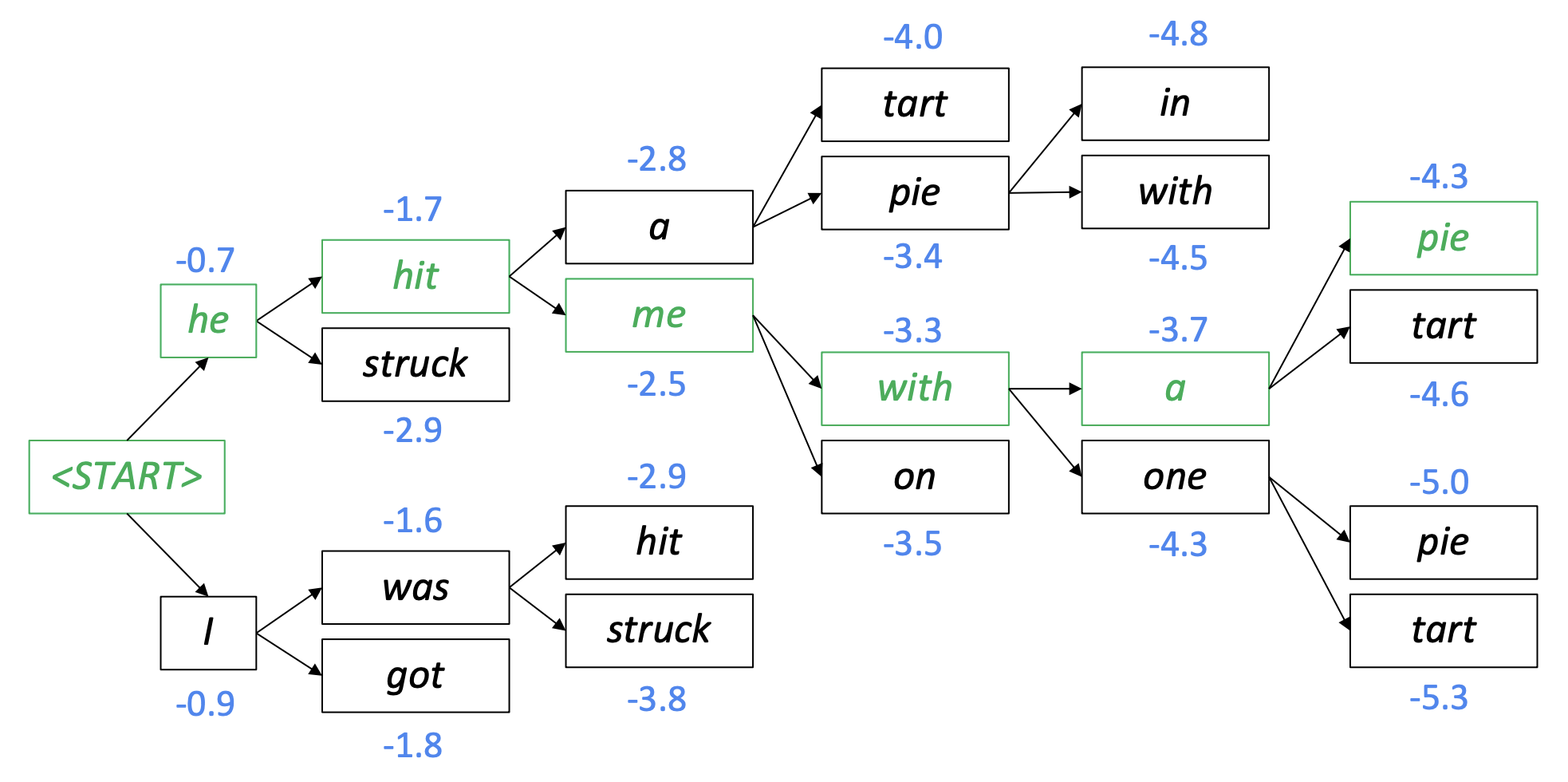
- decoder의 매 단계마다 k개의 가설을 두고 decode 후 가장 높은 확률을 갖는 문장을 찾는 방법
- Argmax Decoding보다 좀 더 많은 k개의 후보를 비교
- k : beam size
- small k : 주제에는 가깝지만 말이 안되는 답변을 뱉음
- big k : 너무 일반적이고 짧은 답변을 뱉음
Greedy Methods의 단점

- 동일한 말이 반복될수록 같은 말에 대한 loss가 낮아지기 때문에 모델의 confidence가 높아져 잘못된 단어의 반복이 생성될 수 있음.
Greedy Methods의 단점을 보완하기 위한 방법
[Random Sampling]

- 모델이 예측한 token distribution을 가중치로 사용하여 sampling
- 이전 greedy 방식보다 다양한 sentence 예측 가능
[Top-k Sampling]
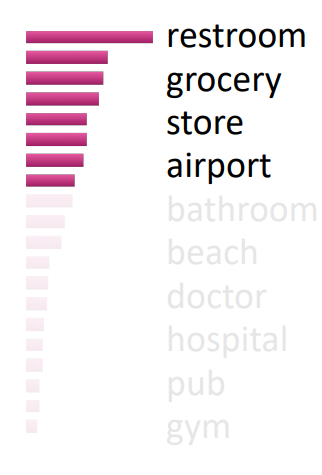
- 모델이 예측한 token distribution에서 상위 k개에서만 sampling
- small k : 한정되었지만 자연스러운 문장
- large k : 다양하지만 부자연스러운 문장
[Top-p Sampling]
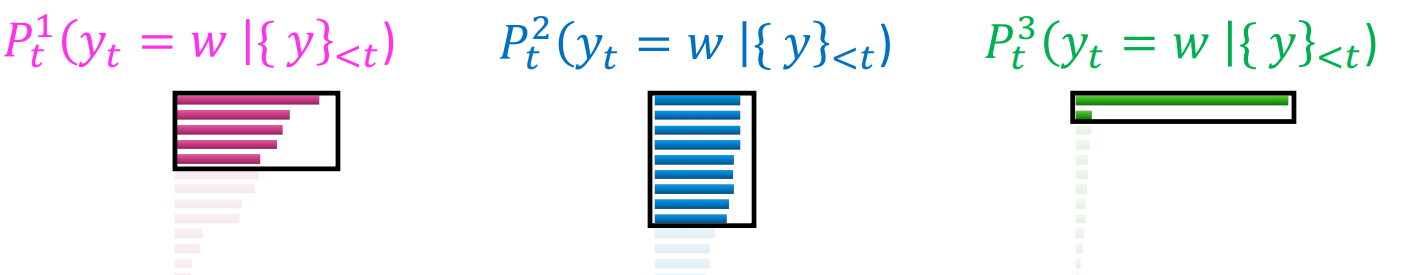
- 누적확률값이 p보다 작은 상위 토큰들만 샘플링에 사용
- 마찬가지로, 작은 p일때는 generic하고 safe한 결과를 갖고, 높은 p일때는 다양하지만 risky한 결과를 갖는다.
[Scaling randomness: Softmax temperature]
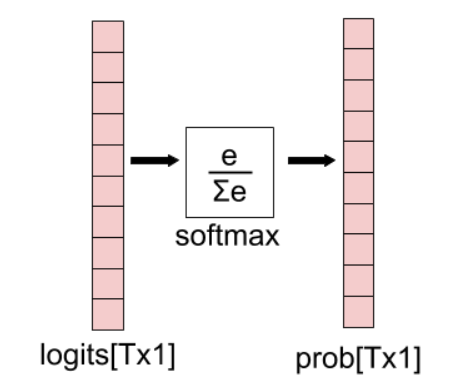
- softmax 전 output을 일정 상수(T)로 나누어 distribution을 scaling 하는 방법
- large t : 분포가 고르기 때문에 다양한 문장
- small t : 분포의 차이가 커 안정적인 문장 생성 가능
[Re-balancing : kNN-LM]
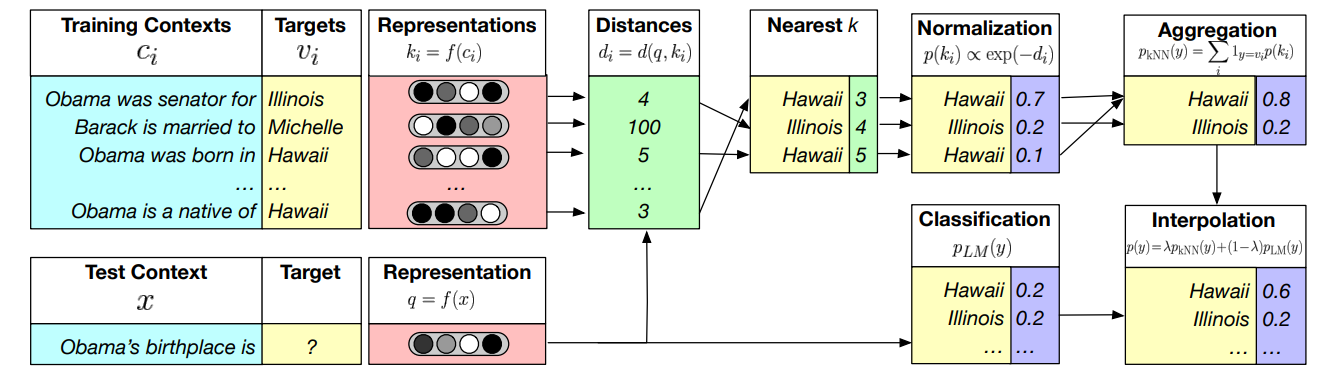
- training context의 representation을 저장해두고, 평가시 저장해둔 representation과 비교하여 모델의 토큰 distribution을 보정
- 거리가 가까운 k개의 representation 문장의 target값을 이용
- 기존 학습의 디코딩 방법만 수정하는 것이기에 간단히 적용할 수 있음
[Re-balancing : PPLM]
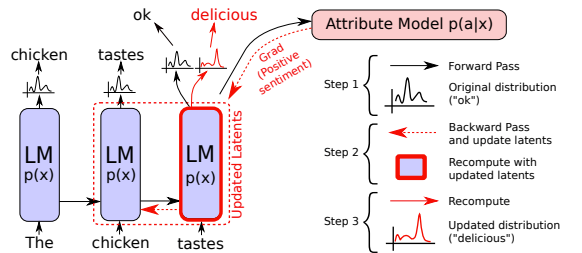
- 추가 모델을 사용하여 언어모델의 distribution 조정
- Attribute Model의 gradient를 사용하여 기존 latent vector를 업데이트하며 새로운 단어가 도출될 수 있도록 조정
4) Training NLG models
[Unlikelihood Training]
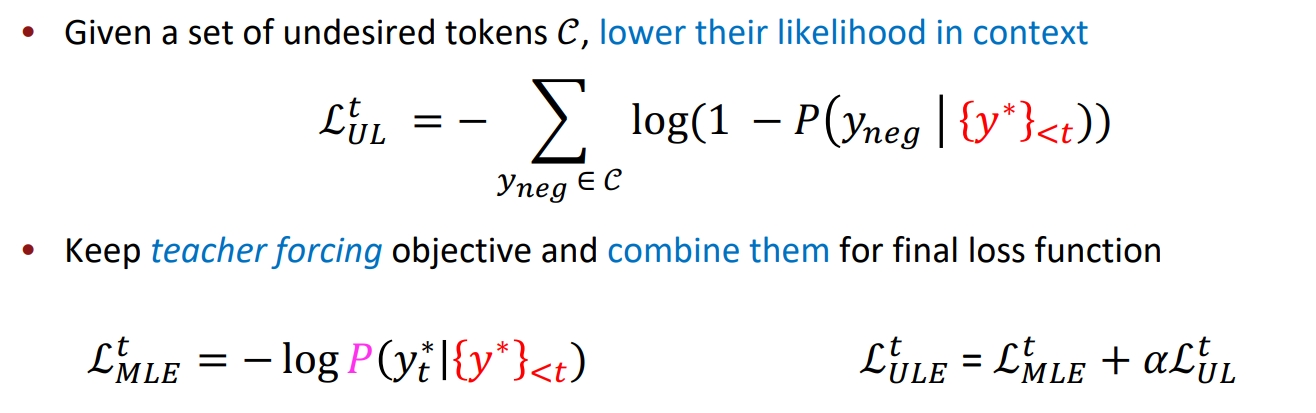
- 디코딩과정에서 비슷한 단어를 반복적으로 생성하는 문제는 이미 생성된 토큰이 생성될 확률을 낮추는 패널티를 추가함으로써 방지 가능
- 생성되는 text의 다양성을 증가시킬 수 있음.
[Exposure Bias Solutions]
- Exposure Bias : Teacher forcing으로 인하여 모델이 불필요한 bias까지 학습하는 overfitting의 현상을 말한다.
1) Scheduled sampling
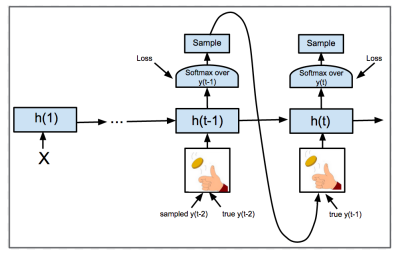
- teacher forcing을 랜덤하게 사용하는 방식
- p: 특정 시점에 teacher forcing을 사용할 확률
- 모델 성능이 올라갈수록 p값은 작은값을 사용한다. 즉, 모델의 예측토큰을 다음 스텝의 입력으로 이용하여 테스트처럼 만들어준다.
2) Sequence re-writing
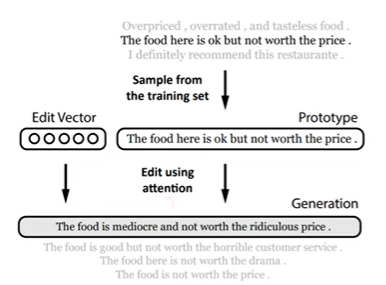
- 샘플링한 prototype을 사용하여 자연스러운 문장을 생성
- 실제문장을 적절히 변환하는 방식
- edit vector는 prototype을 adding, removing, modifying token 방법을 이용하여 변형
3) Reinforcement Learning
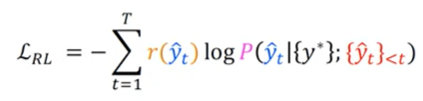
- 기존 잘 사용되는 BLEU같은 지표는 backprop 알고리즘을 사용할 수 없다.
- 언어모델을 Markov decision process로 구성한 후 강화학습 알고리즘을 사용할 시, BLEU, ROUGE와 같은 metric또한 reward로 사용가능하다.
- 의도하지 않은 shortcut을 모델이 학습하지 않도록 reward function을 잘 정의해야함.
5) Evaluating NLG models
1. N-gram overlap metric
1-1) BLEU (Bilingual Evaluation Understudy)

- Generated Sentence의 단어가 Reference Sentence에 포함되는 정도
- 실제 문장 대비 짧은 문장을 생성할 경우 패널티를 부여
- N-gram precision의 기하평균 사용
1-2) ROUGE (Recall-Oriented Understudy for Gisting Evaluation)

- N-gram Recall에 기반하여 계산
- 짧은 생성 문장에 패널티를 부여하지 않음

- 다음과 같이 n-gram별로 비교 가능
- N-gram overlap metric은 단어의 문맥적 의미를 반영할 수 없으며 사람의 평과와 상관성이 낮기 때문에 open-ended MT에서 적절한 지표가 될 수 없음
=> Sementic overlap metrics, model-based metrics
2. Model-based metrics : Word Distance Functions
2-1) Word Mover's Distance

- Generation text와 Reference text의 단어 또는 문장의 semantic similarity를 계산
- Document 1의 단어들과 Document 2까지의 최소 거리 합으로 계산
2-2) BERTSCORE
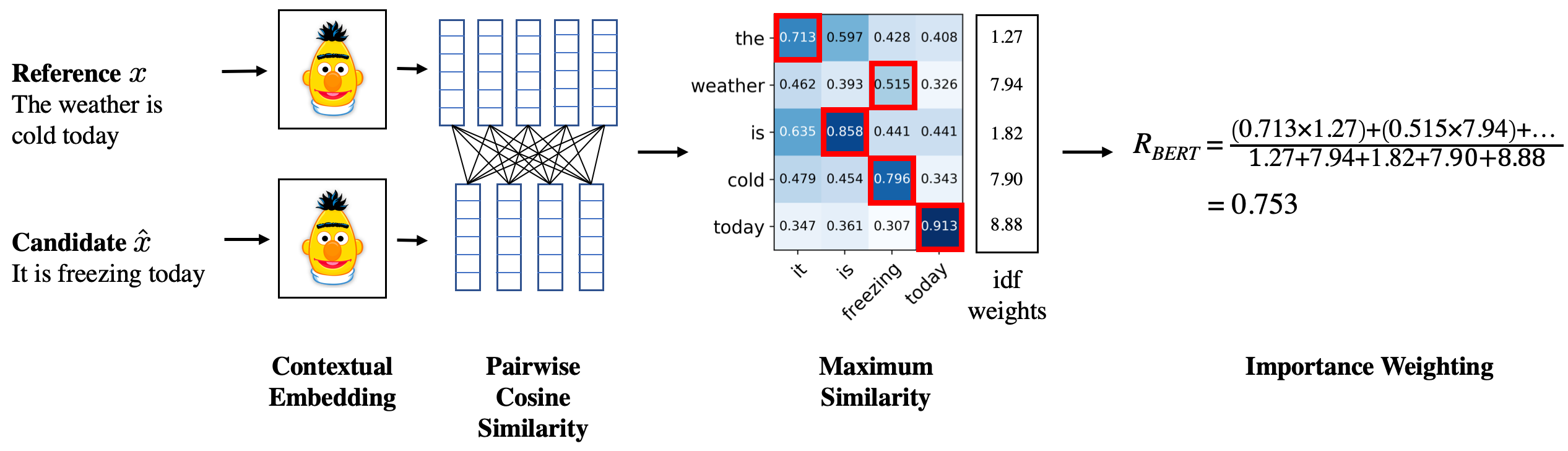
- 사전학습된 BERT를 사용하여 reference와 candidate의 contextual embedding 계산
- 모든 pair의 cosine similarity를 계산하고, greedy matching 후 weighted average 산출
- weight은 idf(Inverse Document Frequency score)를 사용
3. Model-based metrics : Beyond word matching
3-1) Sentence Movers Similarity
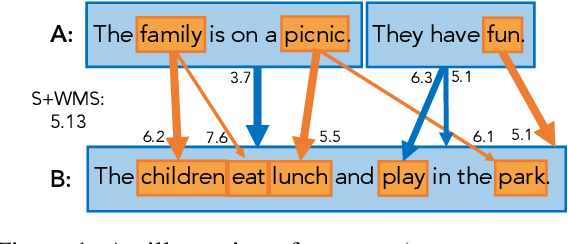
- sentence level과 word level에서 모두 similarity 계산
3-2) BLEUART
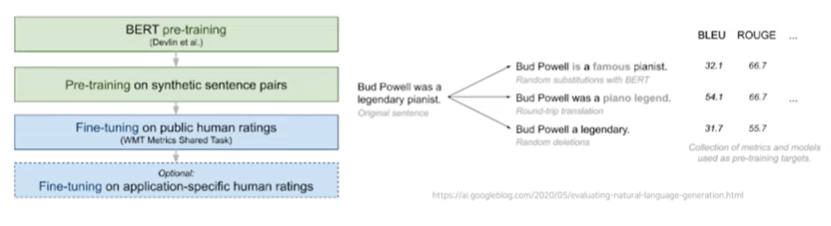
- 문장유사도를 예측하는 BERT 기반의 regression model을 학습
Reference
https://www.youtube.com/watch?v=1uMo8olr5ng&list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ&index=12
https://www.youtube.com/watch?v=RkCbFQ1W6_Q
https://wikidocs.net/31695
https://supkoon.tistory.com/26
