[CS224n] Lecture 4 : Dependency Parsing
Contents
- Syntactic Structure: Consistency and Dependency
- Dependency Grammar and Treebanks
- Transiton-based dependency parsing
- Neural dependency parsing
cs224n의 4번째 강의에서는 dependency parshing을 통해 문장 구조를 파악하고 이해하는 방법을 소개하고 있습니다.
목차 1에서는 문장의 구조를 분석하는 두가지 방법인 consistency parshing와 dependecy parshing에 대해 다루고
목차 2에서는 Dependency parsing에 대해 더 자세히 다루며
목차 3에서는 transition-based dependency parsing의 개념과 parsing 과정에 대해서 소개하며
목차 4에서는 neural network가 적용된 방법인 neural dependency parsing이 어떻게 문장 구조를 분석하는 지에 대해 설명합니다.
1. Syntactic Structure: Consistency and Dependency
Parsing이란 각 문장의 문법적인 구성 또는 구문을 분석하는 과정입니다. 구조를 파악하는 방법에 따라 Consitituency와 Dependency 둘로 나뉠 수 있는데 Consitituency parsing은 문장의 구성요소를 파악하여 구조를 분석하는 방법이며, Dependency parsing은 단어간 의존 관계를 파악하여 구조를 분석하는 방법입니다.
Consitituency parsing
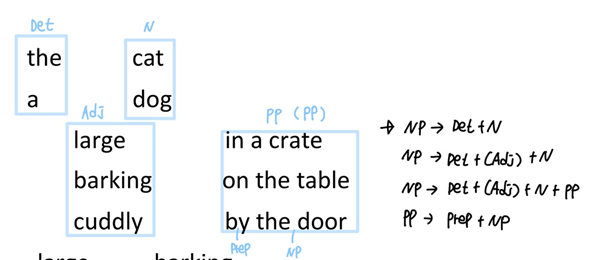
문장의 구조는 단어에서 시작하며, 단어끼리 결합해 구를 만들고, 구끼리 결합해 더 큰 구를 생성합니다

the(Det) + cuddly(Adj) + cat(N) -> the cuddly cat(NP)
the(Det) + door(N) -> the door(NP)
by(prep) + the door(NP) -> by the door(PP)
the cuddly cat(NP) + by the door(PP) -> the cuddly cat by the door(NP)
.
각 문법적 의미를 가지고 있는 단어들은 단어끼리 결합해서 어떠한 구(phrase)를 구성할 수 있으며, 구성된 구들끼리 결합해 문장을 구성할 수도 있습니다.
Dependency parsing
dependency structure는 어떤 단어가 어떤 다른 단어에 의존하는지 보여줍니다.
이는 문장을 이루는 단어 사이에 서로 영향을 미치는 어떠한 관계가 있음을 전제하며
수식을 하는 단어는 'head' 혹은 'governor', 수식을 받는 단어를 'dependent' 혹은 'modifier'이라고 합니다

why do we need sentence structure?
문장의 의미를 보다 정확하게 파악하기 위해서입니다. 인간은 복잡한 의미를 전달하기 위해 단어를 더 큰 단위로 조합하여 생각을 전달하기 때문에 문장의 구조가 무엇인지 이해해야 언어를 올바르게 해석할 수 있습니다.
Prepositional phrase attachment ambiguity
문장에 존재하는 구가 어떤 단어를 수식하는지에 따라 의미가 달라지는데
전치사구의 수식 모호성에 대한 예시만 설명하도록 하겠습니다.
San Jose cops kill man with knife
이 문장에서 with knife 전치사구는 두가지 방법으로 해석이 가능합니다

첫번째로는 san jose cops가 칼로 사람을 죽였다로 해석이 가능하며

두번째로는 san jose cops가 칼을 들고 있는 사람을 죽였다는 해석입니다.
이와 같이 전치사구가 있을 때 앞에 오는 명사를 수식할 지, 그 앞에 오는 동사를 수식할 지의 모호성이 상당히 많이 존재한다고 합니다
하지만 맥락에 따라 의미를 해석할 수 있는 인간은 보통 이러한 모호성을 잘 인식하지 못하지만 컴퓨터는 그러지 못하니 문장의 구성요소에 대한 분석과 이해가 필요합니다.
2. Dependency Grammar and Treebanks
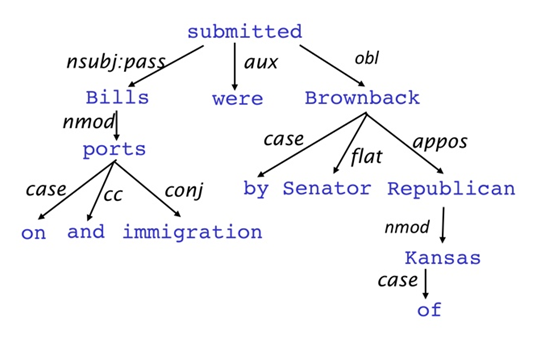
Dependecy grammar에서는 문장의 구문 구조가 단어 쌍간의 관계로 구성된다는 것이며 이는 이진 비대칭관계로 구성된다.
tree에서 화살표의 방향은 수식을 하는 쪽(head)에서 수식을 받는(dependent) 쪽으로
진행되며 화살표 위 라벨은 단어간 문법적 관계를 의미합니다.
보통 fake ROOT를 추가해 모든 단어들이 다른 하나의 단어와 1개의 dependent를 가지도록 설정합니다.
A->B, B->A cycle이 일어나면 안 된다.
Dependency Conditioning preferences
- Bilexical affinities: 두 단어 사이의 실제 의미가 드러나는 관계
- Dependency distance: 대부분의 dependencies가 주로 가까운 위치에서 형성
- Intervening material: 구두점을 넘어 dependent 관계가 형성되지는 않음
- Valency of heads : head의 좌우측에 몇 개의 dependents를 가질 것인가에 대한 특성
3. Transiton-based dependency parsing
Dependency Parsing의 방법으로는 Dynamic programming, Graph algorithms, Constraint Satisfaction, Transition-based parsing이 존재하지만
이 강의에서는 Transition-based parsing에 초점을 맞춰설명합니다
Basic transition-based dependency parser
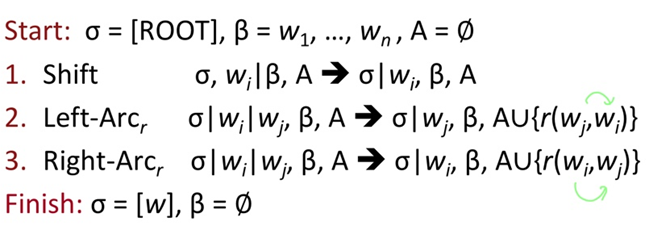
처음 시작할 때, ROOT만 들어있는 스택, 구문하려는 문장이 들어있는 Buffer, 아무것도 들어있지 않는 set of Arcs에서 시작합니다.
그리고 끝날 때는 Buffer의 단어가 없어야 한다.
각 시점에서 세가지 작업중 하나를 선택할 수 있습니다
1. Shift : 다음 단어를 스택으로 이동하는 작업으로
shift를 진행하게 되면 Buffer에 있던 단어가 스택으로 이동하게 됩니다
2. ,3. : 스택의 맨 위 두 항목을 가져와 그 중 하나를 다른 단어로 종속시키는 것
2. Left-Arc
스택에 wi, wj 단어가 존재하며 wi를 wj에 종속시키며, 종속된 단어인 wi가 STACK에서 제거가 되며 A에 dependecy arc가 저장된다.
3. Right-Arc
스택에 wi, wj 단어가 존재하며 wj를 wi에 종속시키며, 종속된 단어인 wj가 STACK에서 제거가 되며 A에 dependecy arc가 저장된다.
Arc-standard transition-based parser
I ate fish
(검은색 테두리 : STACK, 주황색 테두리 : Buffer)

STACK에 단어가 1개만 들어있으면 무조건 shift를 해야하기 때문에 'I'를 Buffer 에서 STACK으로 shift 해야합니다.
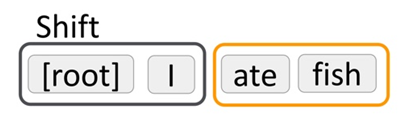
STACK에 단어가 두개라 "I"에게 Arc를 부여할 선택지도 있지만 "I"는 문장의 head가 아니기 때문에 또 다른 단어를 shift 해야합니다.
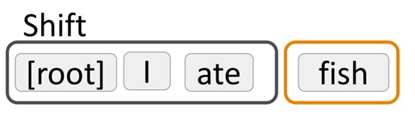

"ate"란 단어가 들어왔고 "ate"가 "I"를 종속시키므로 이는 Left-Arc고 종속된 단어 "I"는 STACK에서 제거됩니다.

Buffer에 마지막 남은 단어인 "fish"가 STACK으로 shift 하게 됩니다.

"ate"가 "fish"를 종속시키므로 이는 Right-Arc고 종속된 단어 "fish"는 STACK에서 제거됩니다.

마지막 단어인 fish는 root에 의존하기 때문에 stack에는 root만 남게되고 끝나게됩니다.
conventional Feature Representation
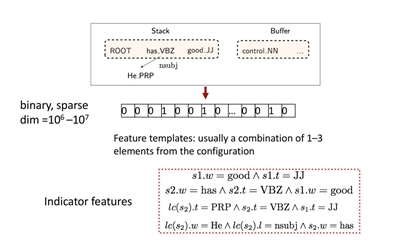
STACK에서 발생하는 어떠한 state를 기반으로 Decision(Shift, Left-Arc, Right-Arc)을 결정하기 위해서는 SVM, NN, maxnet과 같은 모델이 적용됩니다. 이 과정에서 state를 모델의 input으로 받기 위한 state 임베딩 과정이 필요하게 됩니다.
.
Indicator Features는 조건을 만족하면 1, 만족하지 못하면 0을 갖게 되며 일반적으로 1~ 3개의 요소가 결합되어있습니다.
state(c)를 embedding 하기 위해 indicator Features를 활용해 binary하고 sparse으로 표현한다.
(s1.w은 스택의 첫번째 단어이고 s1.t는 스택의 첫번째 단어의 pos-tag입니다.)
예를 들어 조건이 s1.w = good & s1.t = JJ일 때 어떠한 state에서 스택의 첫번째 단어가 good이었고 그에 해당하는 pos-tag가 JJ였다면 이는 조건을 만족하므로 1의 값을 가지게 됩니다.
이런 식으로 10^6 ~ 10^7의 벡터로 표현하는데 일반적이며 이는 parsing의 소요시간 중 95% 이상의 연산을 차지해 계산비용이 매우 높습니다.
그리고 True/False로 표현을 하기 때문에 어떤 단어가 어떤단어와 유사한지, 혹은 pos-tag 간의 유사성이 있는데 이러한 유사성이 있는지의 의미를 전혀 반영하지 못합니다.
Evaluation of Dependency Parsing
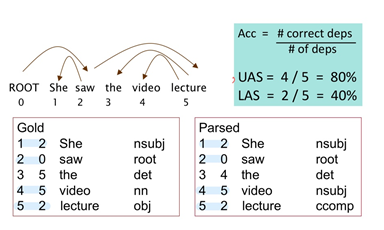
UAS (Unlabled Acuuracy score) : 5개중 4개의 종속 관계의 결과가 같으므로 80 %
LAS (labled Acuuracy score) : 5개 중 2개가 종속 결과 + 레이블된 품사도 같으므로 40% 이다.
4. Neural dependency parsing
neural net 을 이용해서 문장의 dependency 를 파악하는 방법

앞서 사용한 임베딩 방법은 다양한 규칙을 기반으로 dependency 를 찾아내는데, 이러한 규칙들에는 문제가 있습니다
- 실제로 사용되는 것은 매우 적습니다.
- 가장 큰 문제는 관계를 계산하는데 비용이 많이 듭니다.
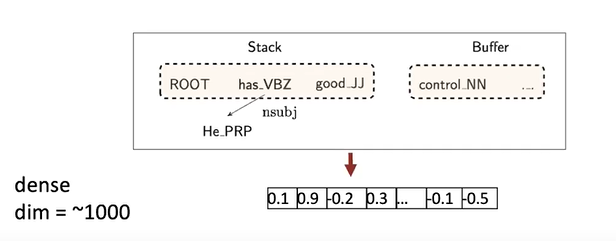
이 구성을 대략 천개 정도의 dense 벡터로 요약하게 되며
Neural approach로 이러한 dense feature를 학습하게 됩니다.
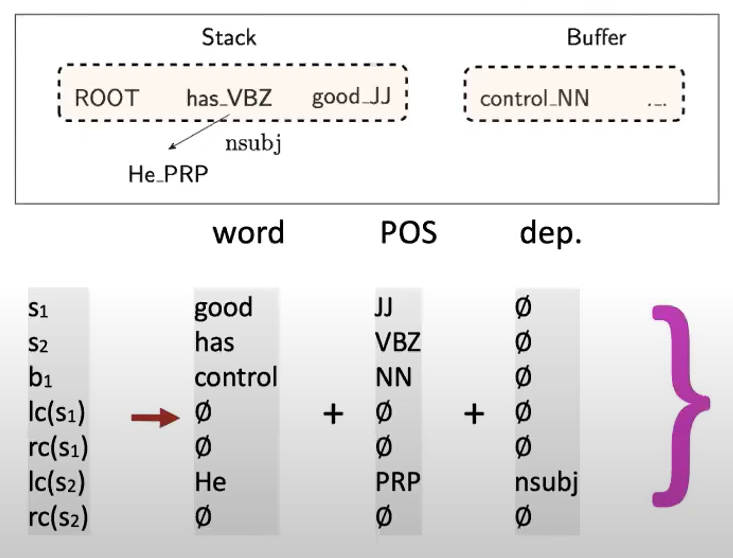
stack에는 단어_품사의 형태로 들어가 있으며 스택에 있는 단어의 왼쪽과 오른쪽에 있는 종속항목을 볼 수 있는 기능이 추가되었다.
word embedding, pos-tag embedding, dependencey labels embedding 을 이용해 nueral representation of a configuration을 생성합니다.
word embedding과 같은 dense vector를 사용하므로 words, pos-tag와 dependency labels 각각 의미가 비슷할수록 가깝게 위치합니다.
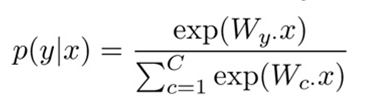
x가 d차원 벡터이고 c 클래스에 해당하는 y가 있으면 우리는 softmax classifier를 사용할 수 있습니다.

c by d 의 가중치 행렬을 기반으로 클래스를 결정하고
가중치 행렬의 값을 훈련합니다
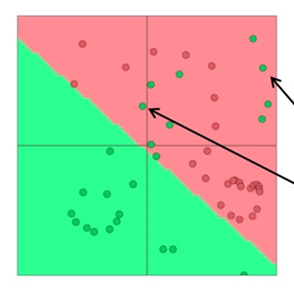
전통적인 ML classifiers(Naive Bayes, SVM, logistic regression, softmax)는 강력한 분류기는 아닙니다. 그들은 선형결정경계만 제공하는 분류기입니다
위의 그림과 같은 어려움이 있다면 단순히 직선을 그리는 것 만으로는 녹색점과 빨간색 점을 구분할 수 없습니다
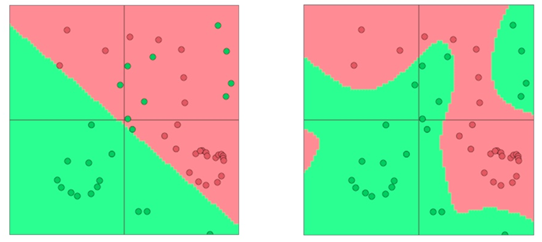
Neural Networks의 가장 큰 장점은 nonlinear decision boundaries를 제공한다는 것입니다
오른쪽 그림과 같은 작업을 통해 초록색과 빨간색의 점을 구분할 수 있게 됩니다.

전체적인 Neural dependency parsing의 과정을 보게 된다면
이는 처음에 입력 벡터로 시작을 하게 됩니다. 비선형이 뒤따르는 행렬곱을 사용해 은닉층 h를 통과하게 되고 output을 softmax에 넣고 분류 결정을 내리는 softmax probablilities를 얻을 수 있다.
그리고 이 확률이 올바른 클래스에 할당하지 않는다면 log loss인 cross-entropy loss를 얻게됩니다
