[CS224n] Lecture 9 : Self-Attention and Transformers
Lecture Plan
1. From reccurence(RNN) to attention-based NLP models
2. Introducing the Transformer model
3. Great results with Transformers
4. Drawbacks and variants of Transformers
1. From recurrence RNN to Attention-based NLP models
RNN's structural problems
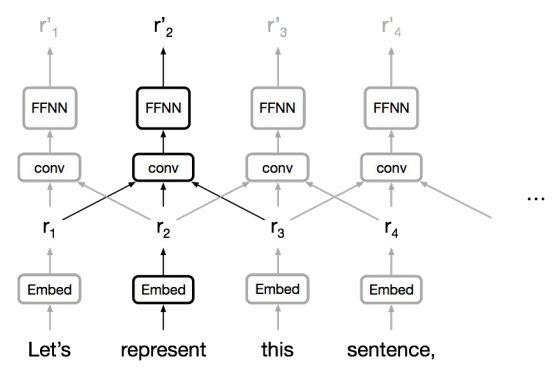
(1) Linear interaction distance
: 멀리 떨어져있는 단어 사이의 상호작용이 어려움
- 가까운 단어일 경우, 상호작용이 용이함
- 멀리 떨어진 단어일 경우, gradient problem으로 dependency 반영이 어려움
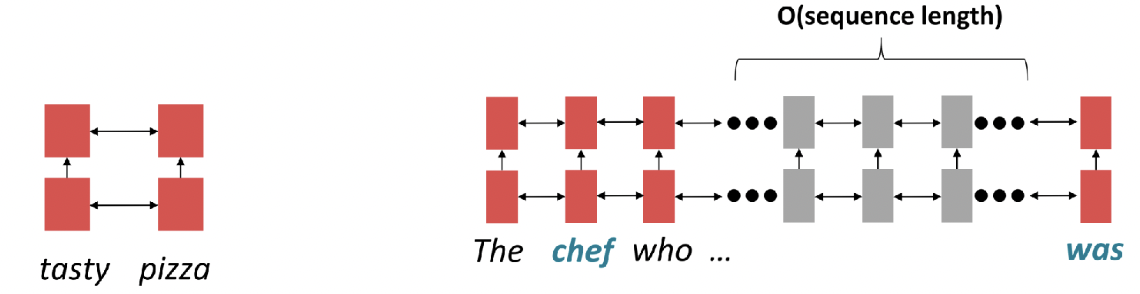
(2) Lack of Parallelizability
: 병렬 연산이 불가능함
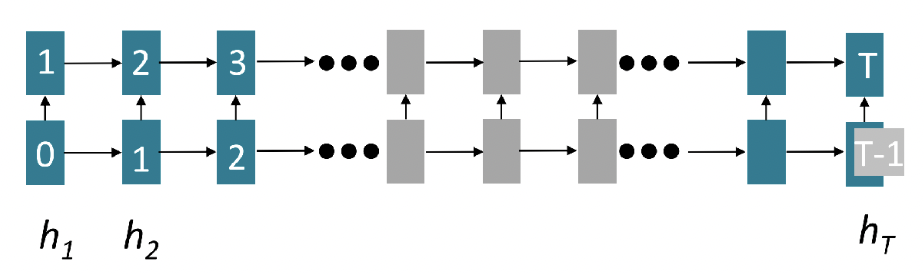
- 모델이 복잡해질수록, 데이터 양이 많아질수록 더 큰 약점으로 이어짐
RNN은 Building Block으로 문제가 있다. 다른 대안이 없을까?
Alternative of RNN
1. How about Word Window?
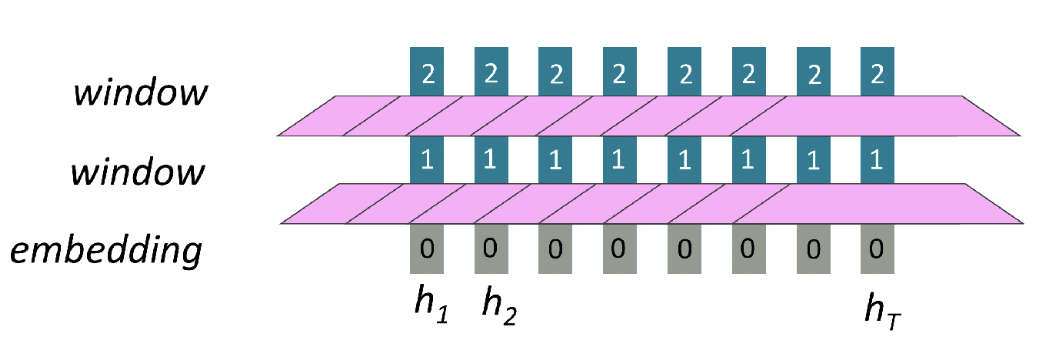
- Sequence length가 증가해도, 병렬 처리가 불가능한 연산의 수가 증가하지는 않음!
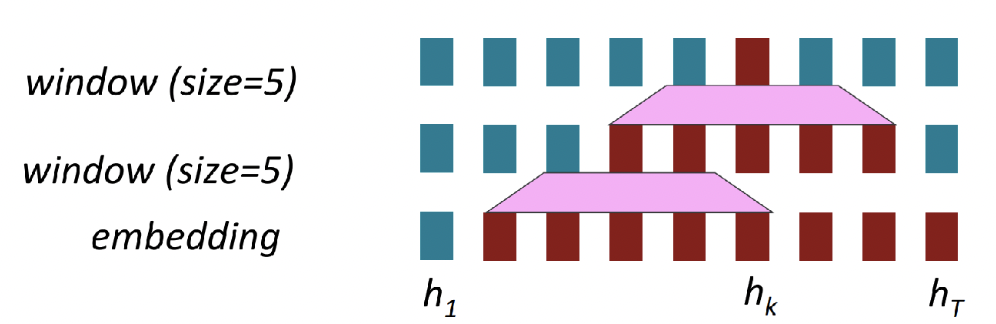
- long-distance dependency 문제는 해결하지 못함
-> 단어 사이의 상호작용이 어려움
2. How about Attention?
Attention : Decoder에서 Encoder로 중복해야할 부분을 파악하는 방식
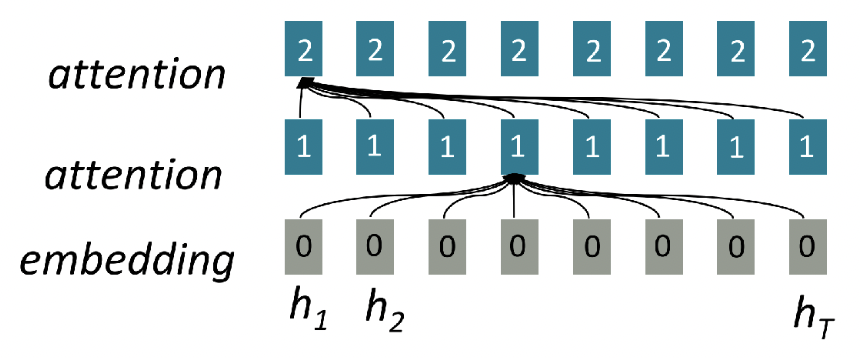
- sequence에 대해 병렬 연산이 가능함

- O(1) 연산만으로 상호작용 가능함
-> 병렬 연산 가능, long-distance dependency 문제 해결!
Self-Attention
Self Attention : Decoder와 Encoder 사이가 아닌 한 문장 안에서 attention을 고려하는 방식
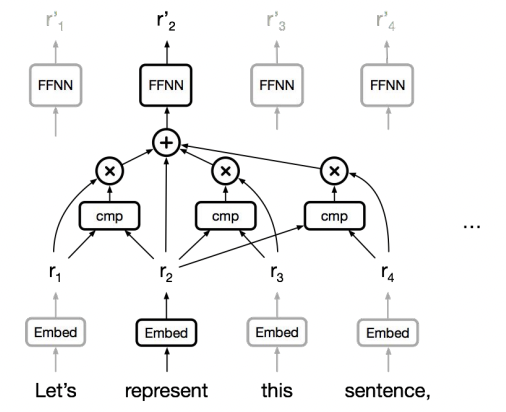
- sequential operation
- Maximum Path length
Self-Attention은 새로운 Building Block으로 적절하다!
Query, Key, Value
Query : 현재 보고있는 단어의 representation (다른 단어를 평가하는 기준)
Key : Query와 관련이 있는 단어를 찾을 때 label처럼 활용되는 vector
Value : Query와 Key를 통해 탐색하여 실제로 사용할 값
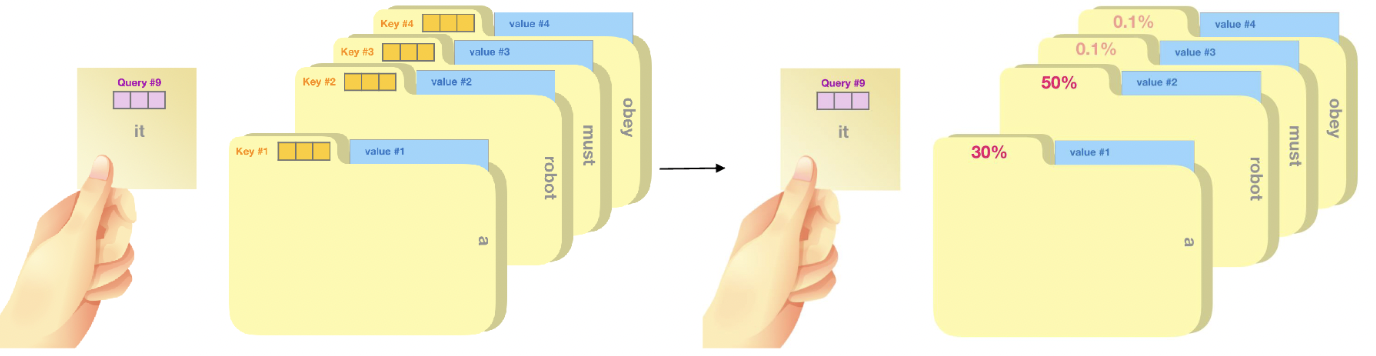
Self-Attention vs. Attention

Self-Attention
- Query = Key = Value = input vector x
- 한 문장 안에서 일어나므로, s, h 구분 없이 용도에 따라 vector를 구분함
Attention
- s : Decoder의 hidden state
- h : Encoder의 hidden state
-> 두 식은 완전히 같음
그러면 Self-Attention을 단순히 쌓기만하면 될까?
Problem with Self-Attention
1. Doesn’t have an inherent notion of order!
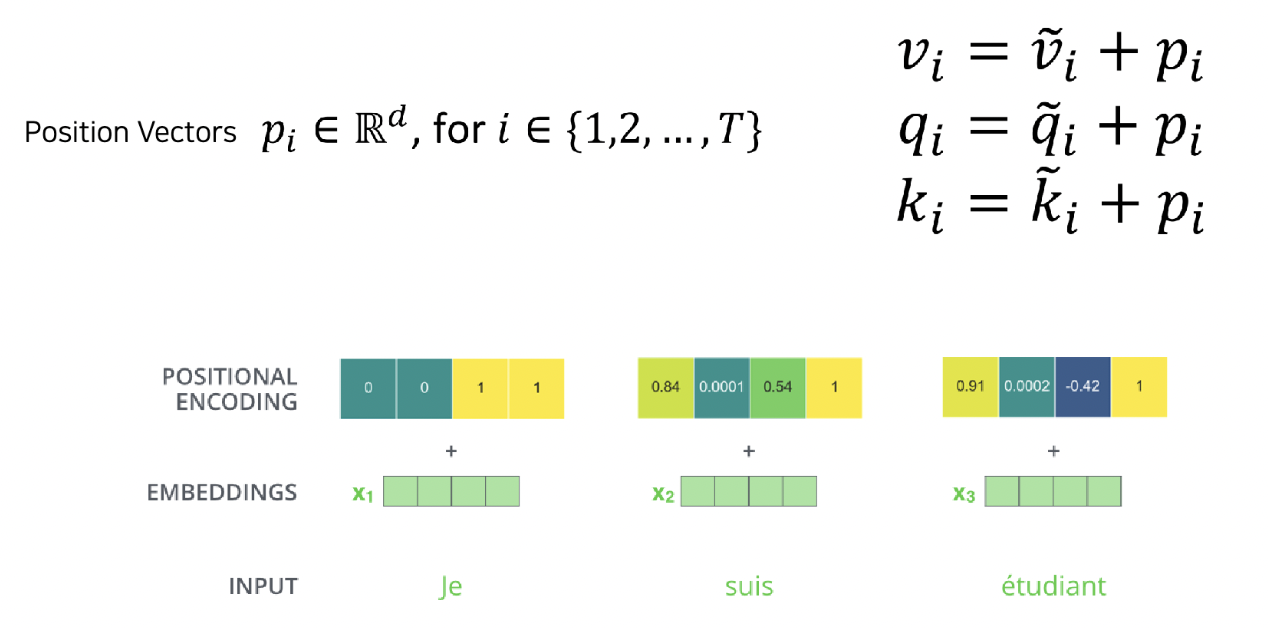
- 순서에 대한 정보가 없으므로 위치 정보가 필요함
위치 정보를 포함하는 position vector를 만들자.
-The further the two positions, the larger the distance!

In Transformer Thesis..

Sinusoidal position vector
: sin, cos을 조합하여 다른 index일때 다른 값을 가지는 벡터
- 장점 : 상대적인 위치 비교를 통해 함수의 주기보다 input하는 sequence의 길이가 길어도 위치하는 위치 정보를 잃지 않음
- 단점 : 학습할 수 있는 parameter가 없으므로 데이터에 맞게 다른 위치 정보를 포함하지 못함
position vector가 학습 가능하도록 하려면?
- 상대적인 위치를 적용한 방식
- 상대적인 위치 + 구조적인 정보까지 추가한 방식
-> 본인의 데이터에 맞게 학습 가능하나, 정해놓은 length 이상의 문장은 처리할 수 없음
2. No nonlinearities for deep learning magic! It’s all just weighted averages
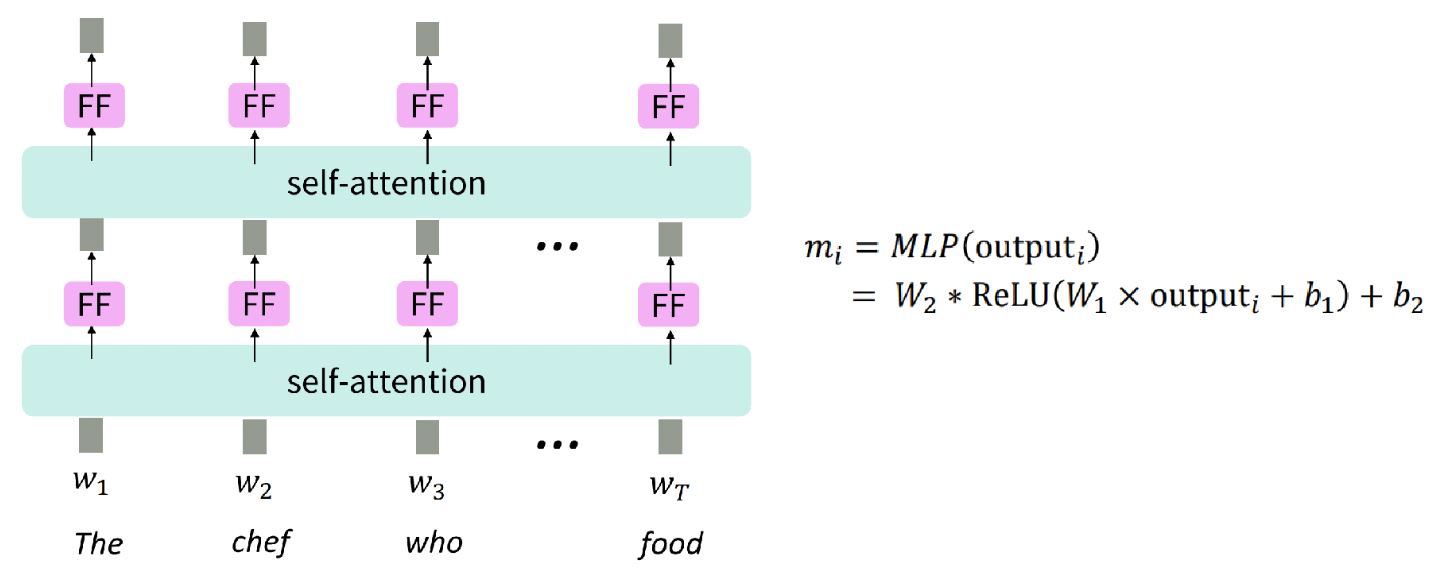
- 선형 결합만 있으므로, Nonlinear Function이 필요함
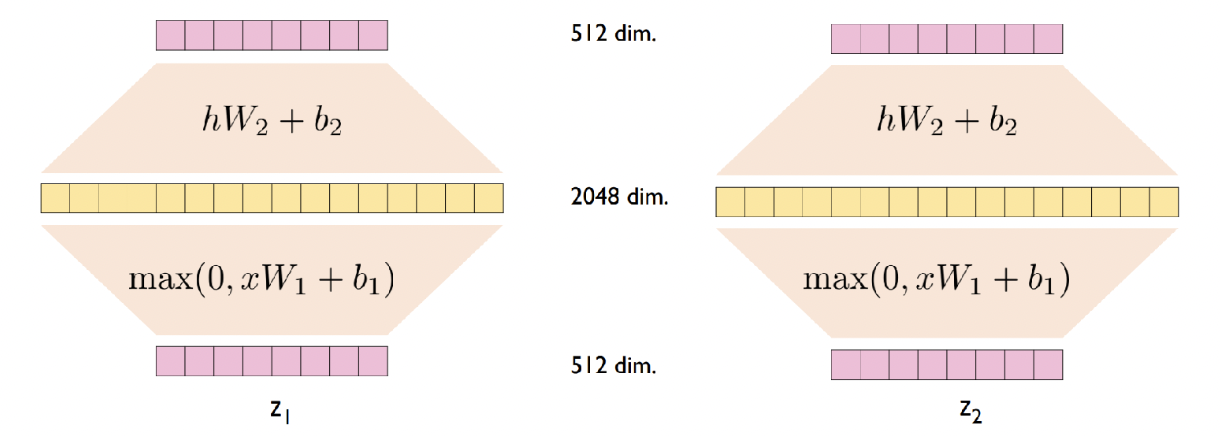
각각의 attention output vector에 feedforward network (ReLU) 를 추가하자.
3. Need to ensure we don’t “look at the future” when predicting a sequence
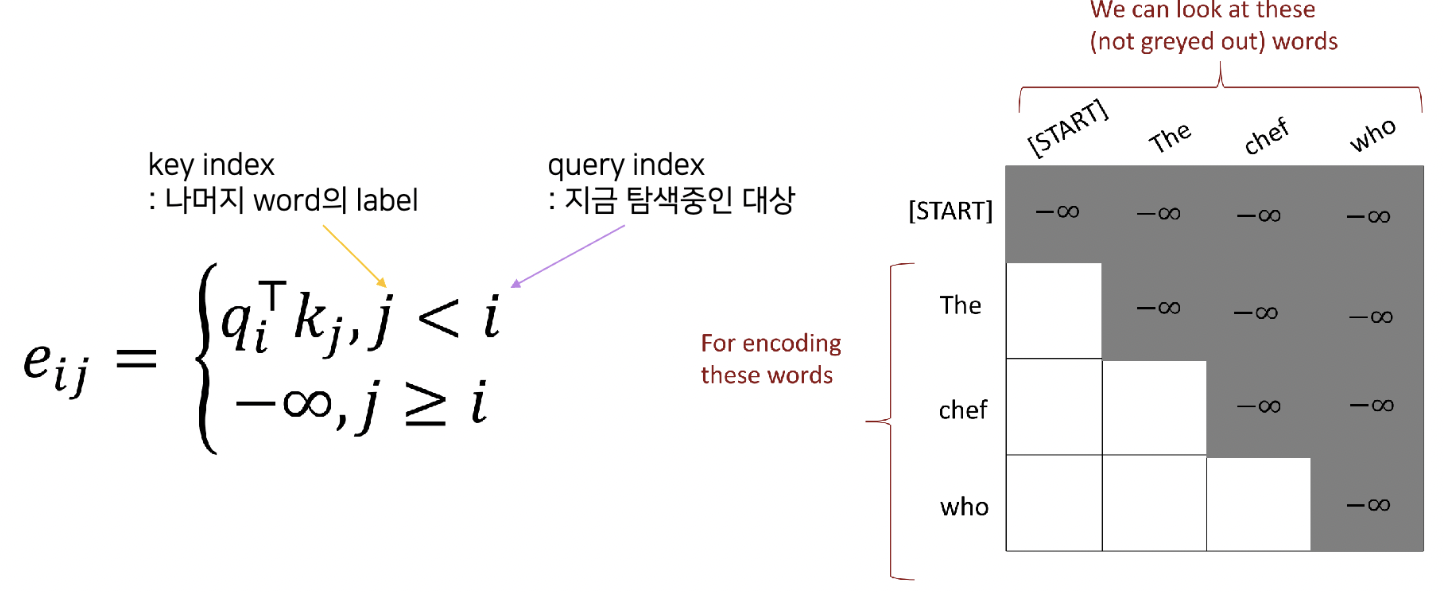
- Future sequence data를 활용 가능하므로, future sequence info를 보지 못하도록 해야함
Masking을 하자.
2. Introducing the Transformer model
Encoder & Decoder
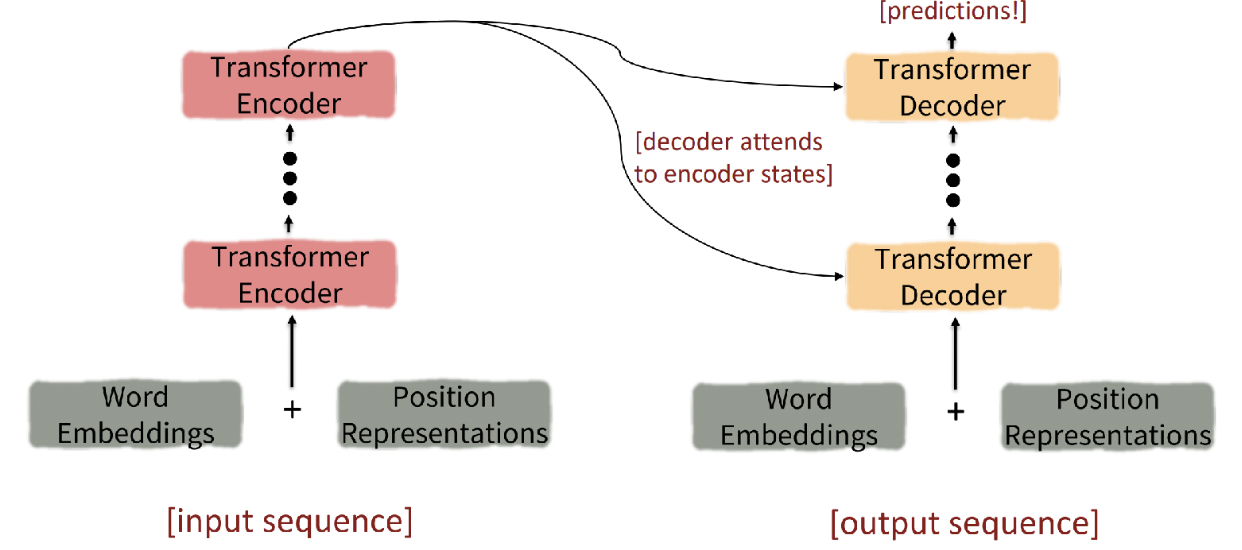
- Encoder : self attention + feedforward network
- Decoder : masked self attention + encoder-decoder attention + feedforward network

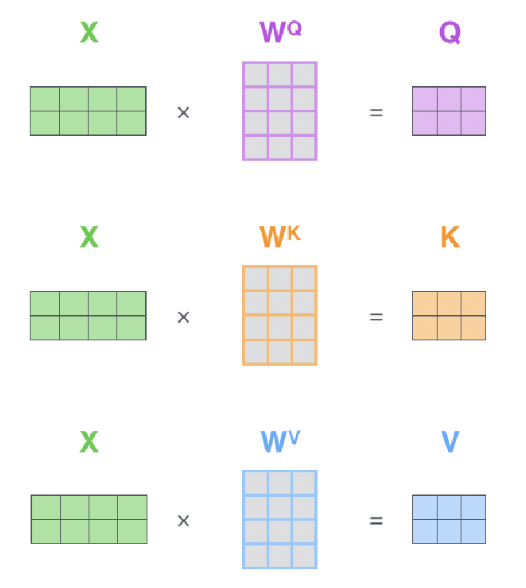
Self-Attention
: Query, Key, Value = input vector x
Transformer
: Query, Key, Value = K,Q, V 행렬 (학습하는 대상) * input embedding vector x
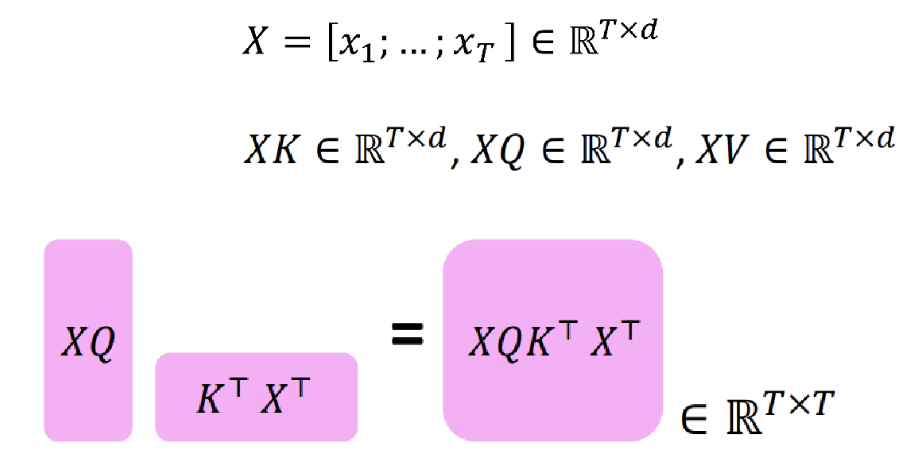
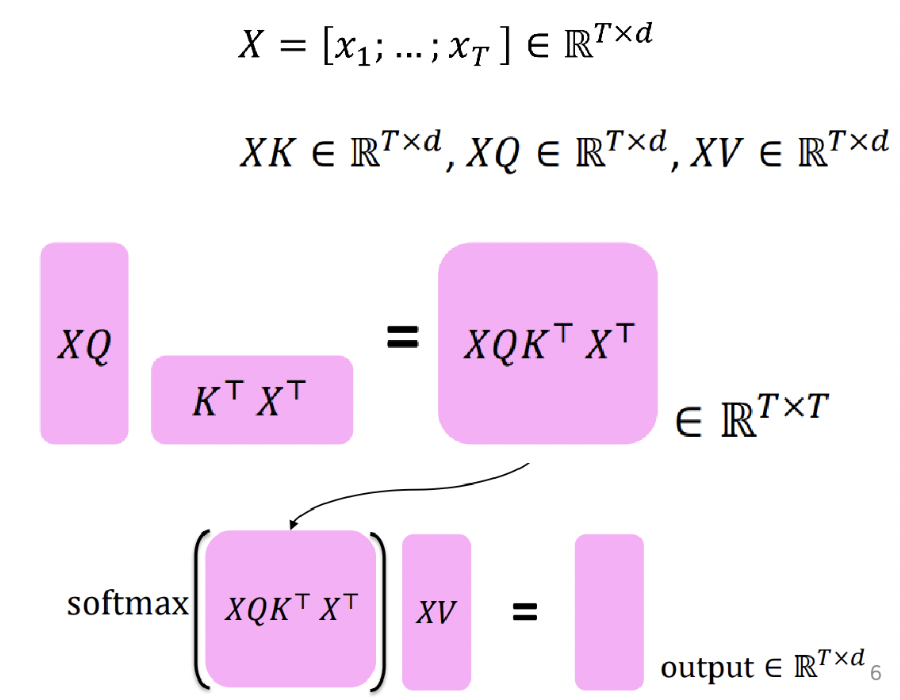
- self attention output을 구하는 과정
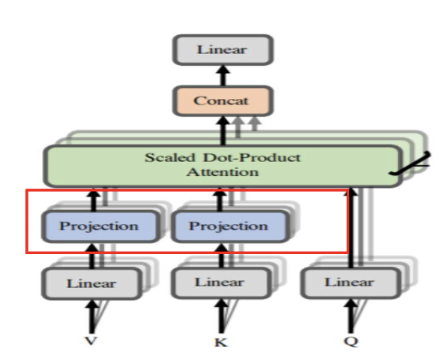
Multi-head Attention
: Transformer가 한번에 여러 부분에 집중할 수 있도록 함
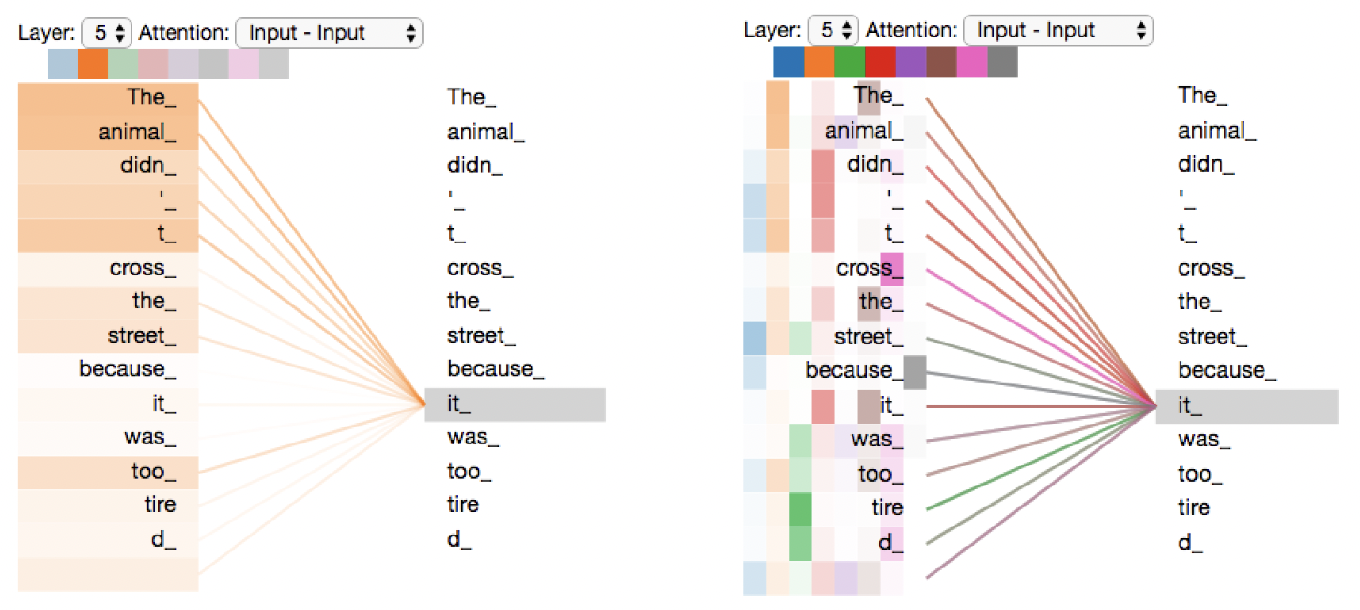

- Single-head Attention : 한 가지의 색상으로 하나의 집중도를 나타냄
- Multi-head Attention : 다양한 색상으로 각각 다른 여러 개의 집중도를 나타냄
Self-Attention에서 Multi-head Attention을 사용하므로, 다양한 특징을 학습하도록 한다.
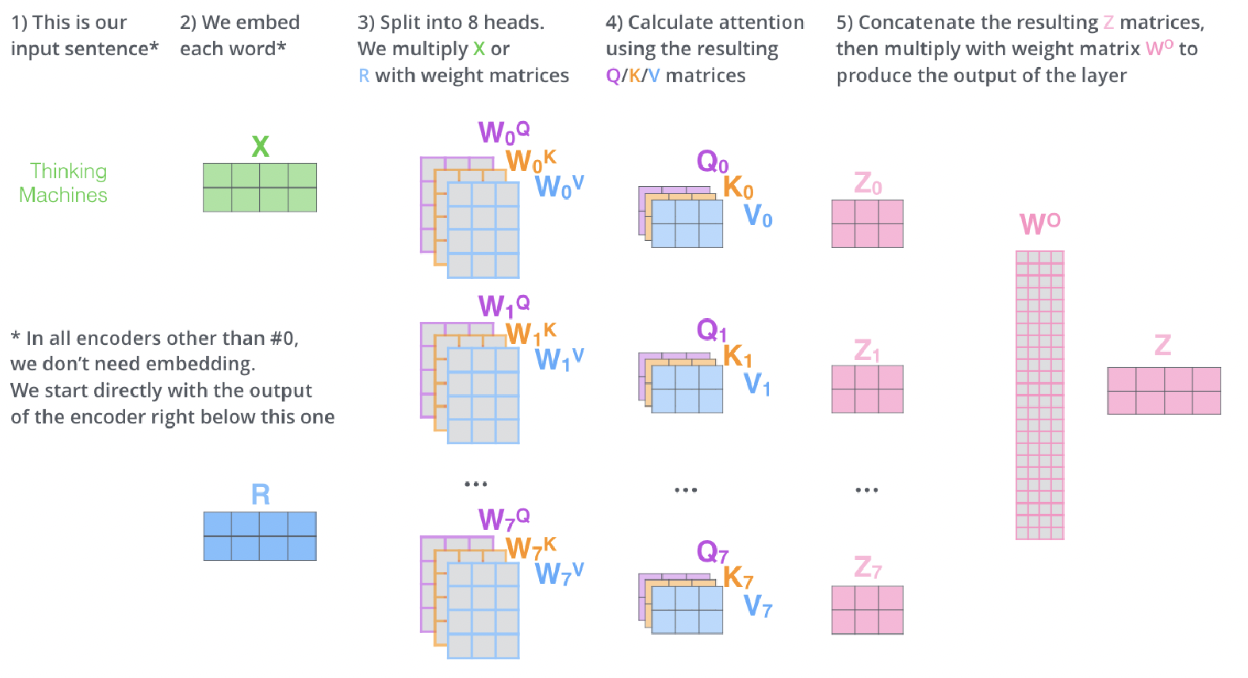
(1) Head의 수만큼 다른 weight matrix를 통해 Query, Key, Value 행렬을 구함
(2) 최종 self attention output을 산출함
(3) Self attention output을 concat하여 처음과 동일한 차원의 output을 구함
(4) 마지막 weight matrix W0와 곱하여 최초의 input vector X와 같은 차원의 최종 output을 얻음
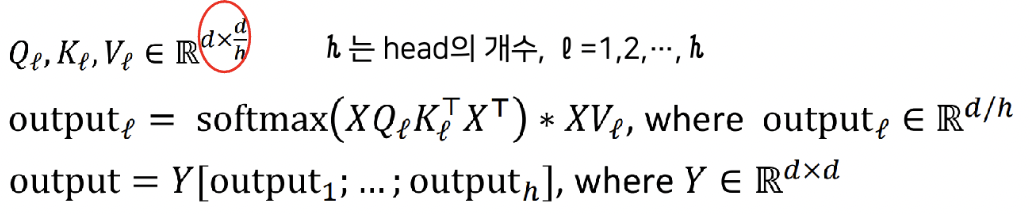
-> 식을 살펴보면, 모든 head에 대하여 전체 input sequence가 사용되어 모두 사용되게 됨
-> 연산량의 측면에서도 그림에서 확인할 수 있듯이 결국 완전히 같은 양의 연산만으로 동시에 여러 부분에 집중할 수 있게됨
3. Great results with Transformers
Residual Connection
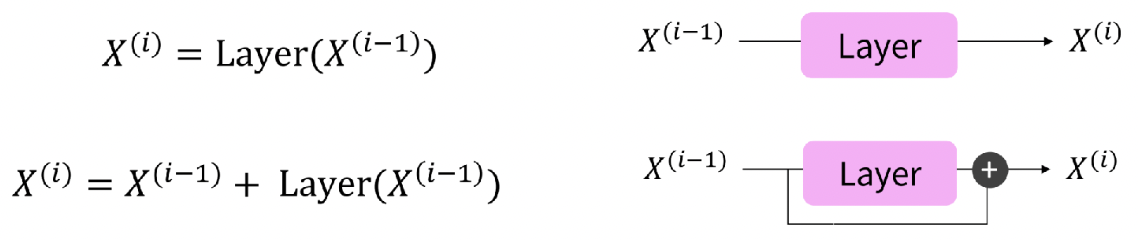
- 미분 결과값이 너무 작아 gradient 전달이 원활하지않은 경우, residual connection을 통해 기울기에 1이 더해지는 꼴이 되어 아주 작은 gradient라도 보전해주는 역할을 함
Layer Normalization

- 한 layer에서 하나의 input sample x에 대해 모든 feature에 대한 평균과 분산을 구해 normalization하므로 gradient normalization을 해줌
Scaling the dot product
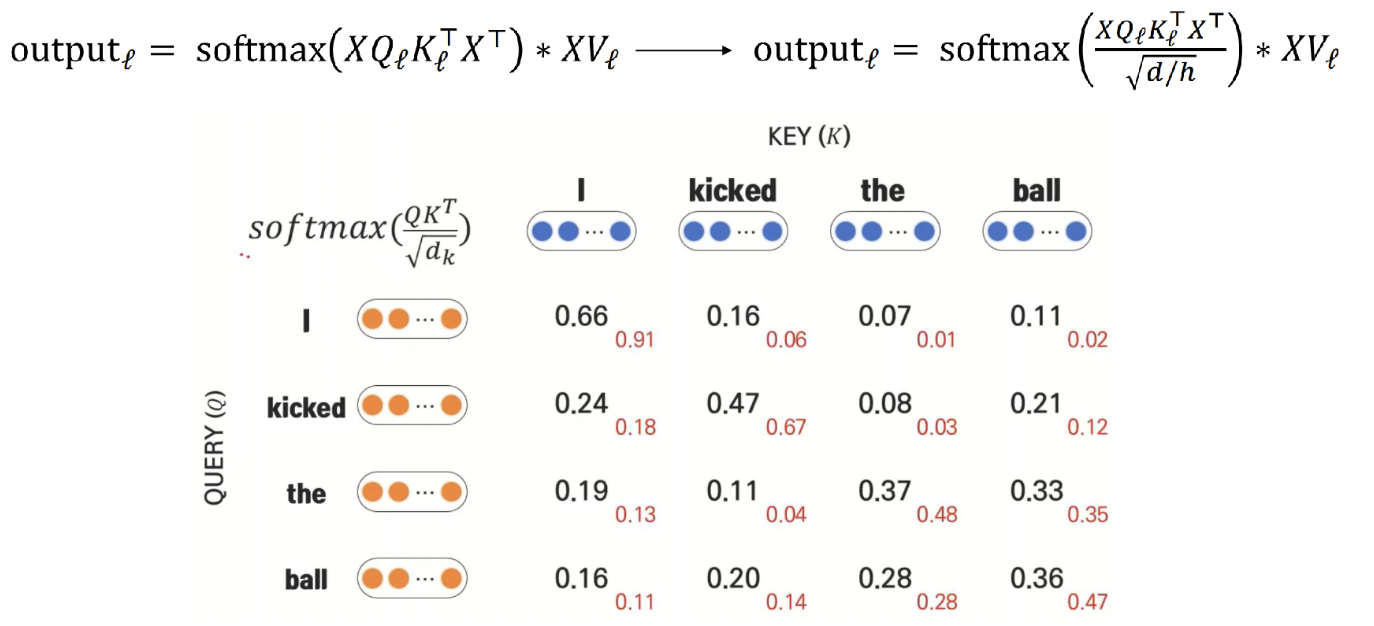
- Attention score을 좀 더 다양한 벡터들에 분배시켜줌
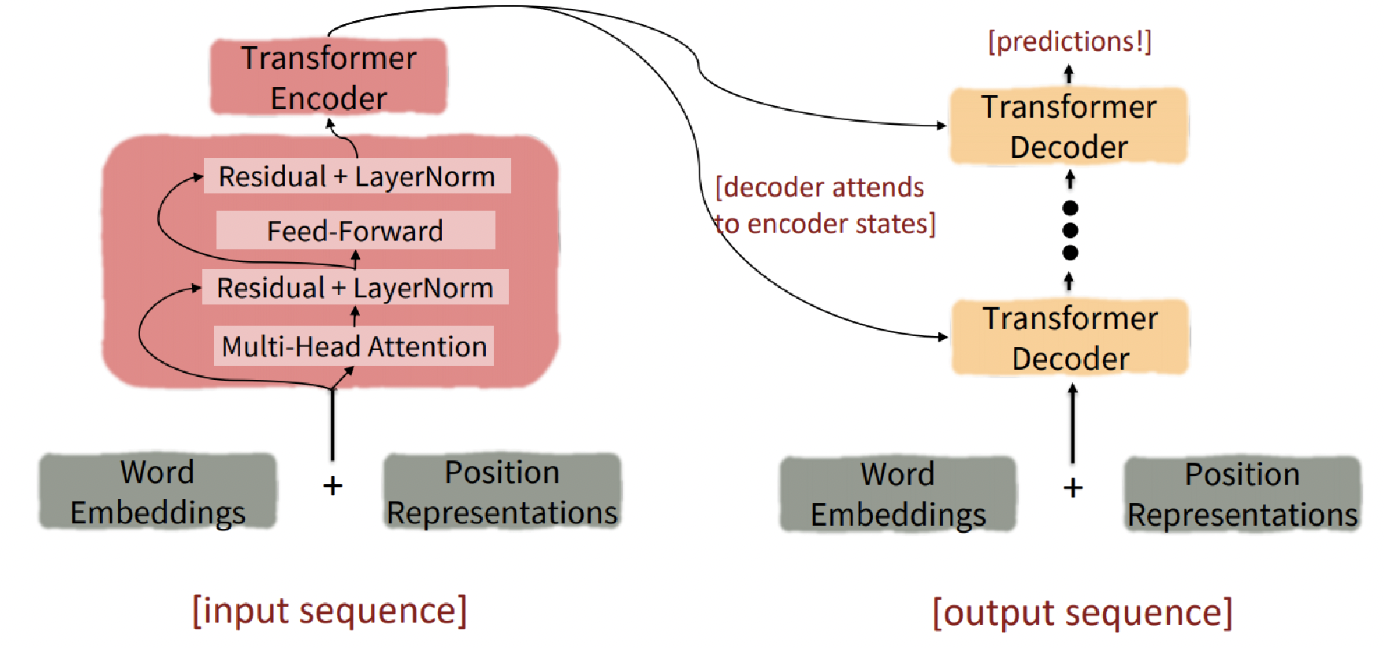
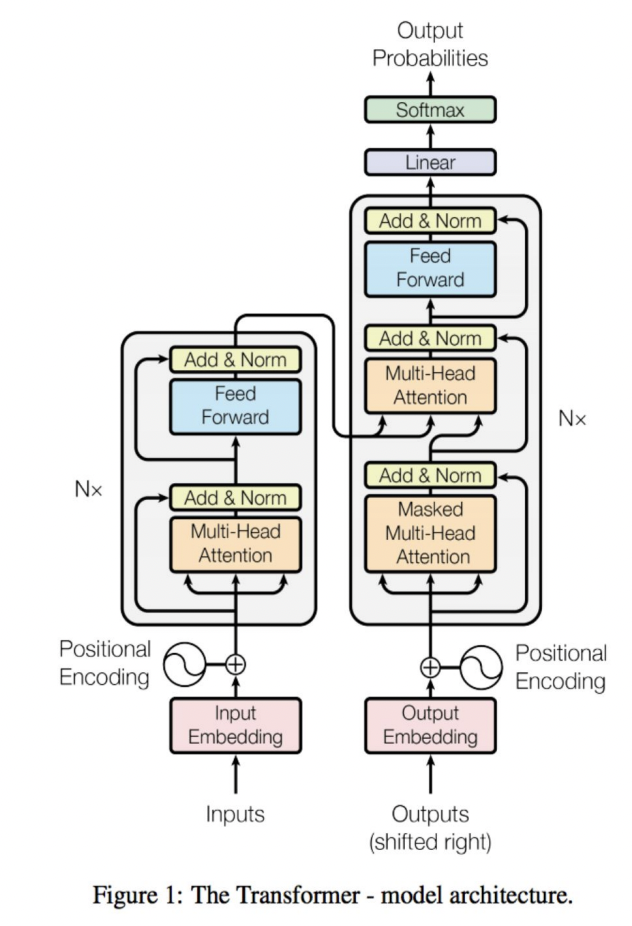
Transformer Structure
Encoder
Feedfoward Network
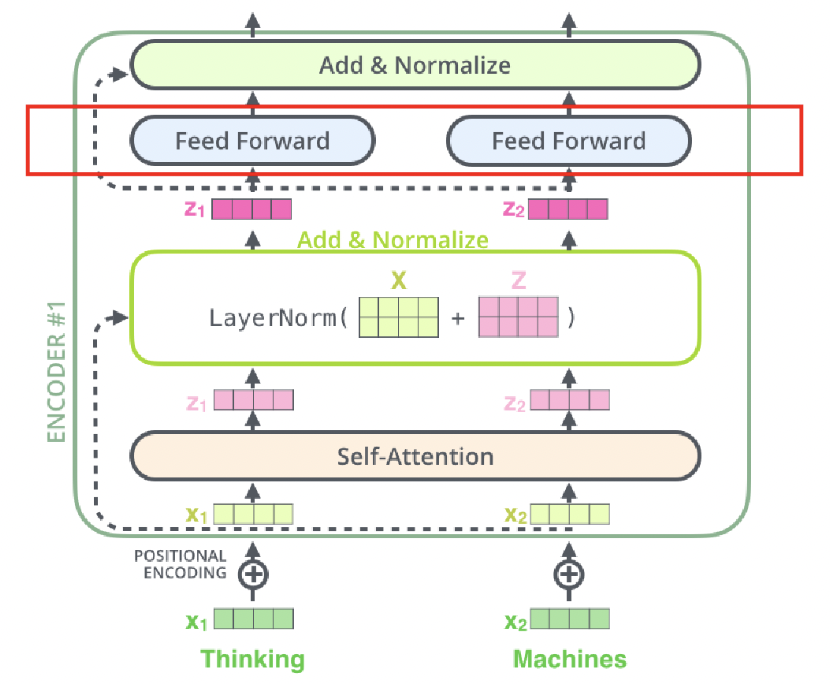
- Sequence마다 독립적으로 적용됨
- 하나의 layer 안에서 동일한 weight parameter를 공유함
- 다른 layer에서는 다른 weight parameter를 사용함
Decoder
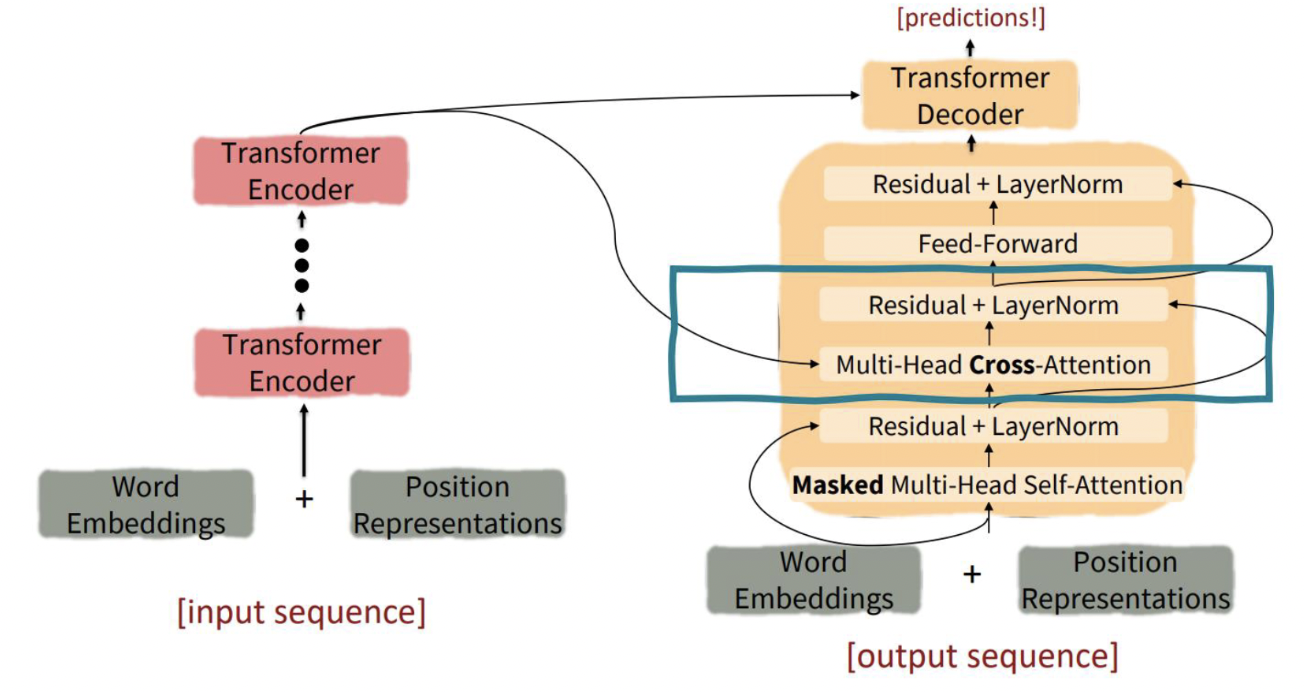
- multi head cross attention : 인코더와 디코더 사이를 오가는 attention
Calculation
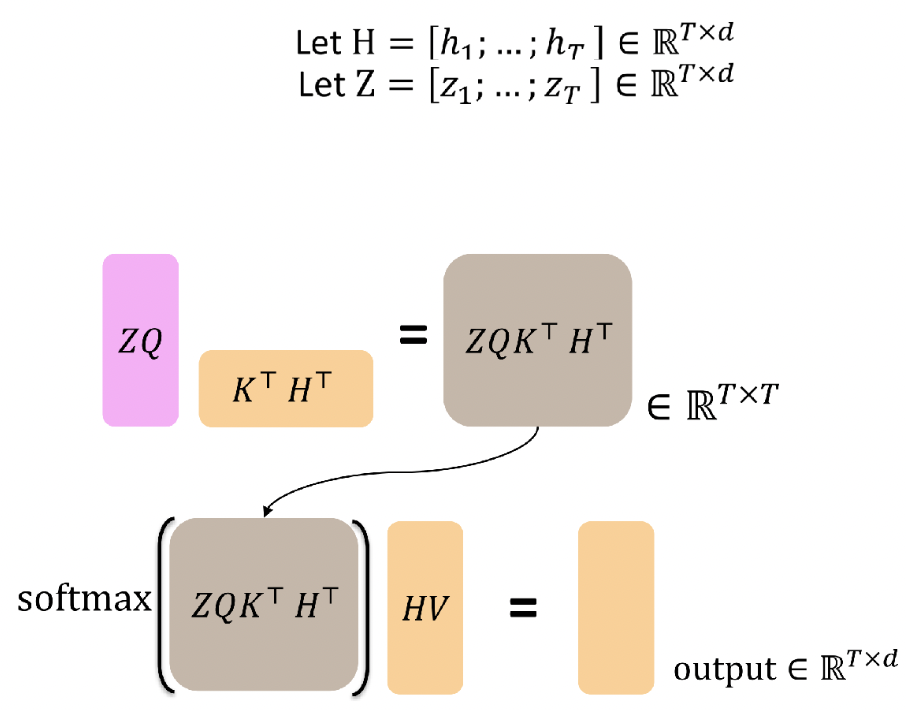
- 기존의 Attention과 계산 과정이 동일하고, Self-Attention과 완전히 동일한 형태를 가짐
- Decoder에서 Query, Encoder에서 Key, Value를 가져온다는 점만 다르고 과정은 동일함
Summary
Performance of Transformer
(1) machine translation
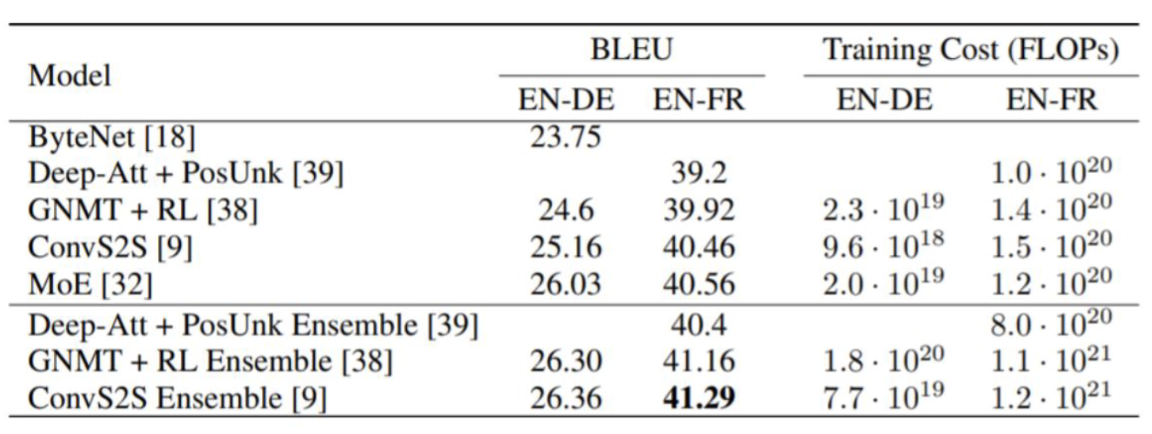
- 기존 모델들 보다 훨씬 높은 성능을 보임
(2) document generation
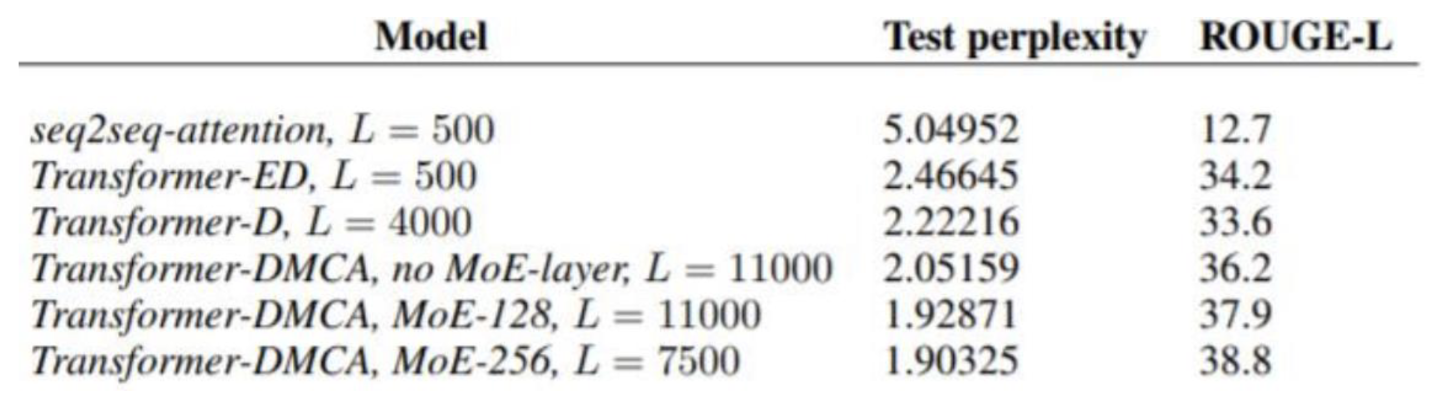
- 기존의 기준보다 훨씬 낮은 test perplexity를 보이며 높은 성능을 보여줌
(3) aggregate benchmark
- GLUE 순위, TOP 6 model이 모두 트랜스포머거나 트랜스포머에서 파생된 모델임
4. Drawbacks and variants of Transformers
1. 문장의 길이에 따라 계산량이 2차로 증가한다.
: sequence length가 증가함에 따라 계산량이 2차로 증가한다
(1) linformer
- sequence length의 차원을 낮춰 계산량을 줄이도록 시도함
(2) BigBird
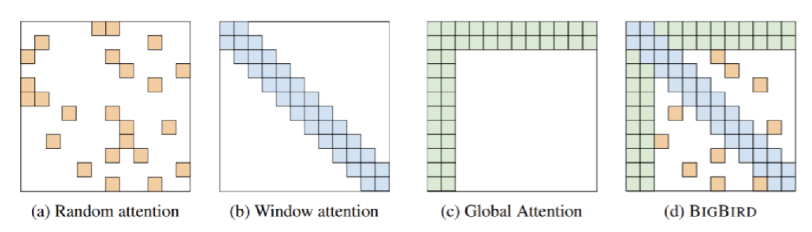
- Attention 계산을 모두 하는 것이 아니라 최적의 조합만큼만 계산함
2. Sinusoidal position representation에 개선의 여지가 있다.
: 절대적인 위치를 표현한 것이므로 이를 대체해서 상대적인 위치로 학습가능한 다양한 방법들이 제시되어있고 이미 많은 모델들이 대체안을 사용하고 있음
