[CS224n] Lecture 11: Convolutional Networks for NLP
작성자: 16기 주지훈
Contents
- Intro
- 1D Convolution for Text
- CNN for classification
- Toolkits
- Deep CNN for Text Classification
- Quasi-Recurrent Neural Network
1. Intro
RNN의 단점
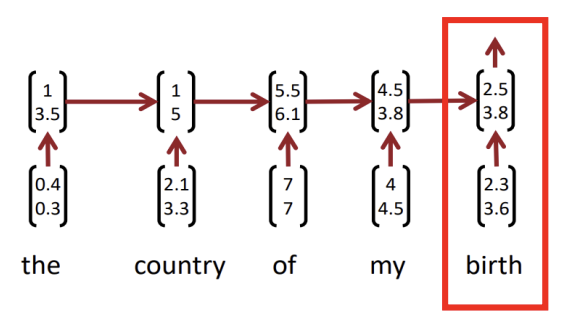
- Perfix context(the, of) 없이는 phrase를 캡쳐할 수 없습니다.
- 보통 softmax가 마지막 step에서만 계산되기 때문에 마지막 단어에 영향을 많이 받습니다.
CNN for Text
핵심 아이디어는 "모든 가능한 어절을 벡터로 계산하면 어떨까?"입니다.
 위의 예시는 window size가 3인 tri-gram으로 계산한 것입니다. 이렇게 CNN을 텍스트에 도입했을 때, 해당 구문이 문법적으로 옳은지 판단이 불가하고 언어학적으로 맞지 않는 것처럼 보인다는 단점이 있습니다.
위의 예시는 window size가 3인 tri-gram으로 계산한 것입니다. 이렇게 CNN을 텍스트에 도입했을 때, 해당 구문이 문법적으로 옳은지 판단이 불가하고 언어학적으로 맞지 않는 것처럼 보인다는 단점이 있습니다.
2. 1D Convolution for Text
filter의 이동방향이 위아래밖에 없는 것을 1D Convolution이라고 합니다. 위의 예시와 똑같이 "tentative deal reached to keep government open"이라는 문장에 convolution 연산을 적용해보겠습니다.
 input은 4차원으로 임베딩 되어 있는 각 단어의 벡터이고 filter의 size는 3입니다. filter가 움직이면서 내적을 하면 74의 input이 51로 계산됩니다.
input은 4차원으로 임베딩 되어 있는 각 단어의 벡터이고 filter의 size는 3입니다. filter가 움직이면서 내적을 하면 74의 input이 51로 계산됩니다.
그런데 이러면 input과 output의 길이가 달라지기 때문에 길이를 맞춰주기 위해 Padding을 적용합니다.

input의 위와 아래에 모든 열이 0인 행을 추가하면 input의 길이와 output의 길이가 같아집니다.
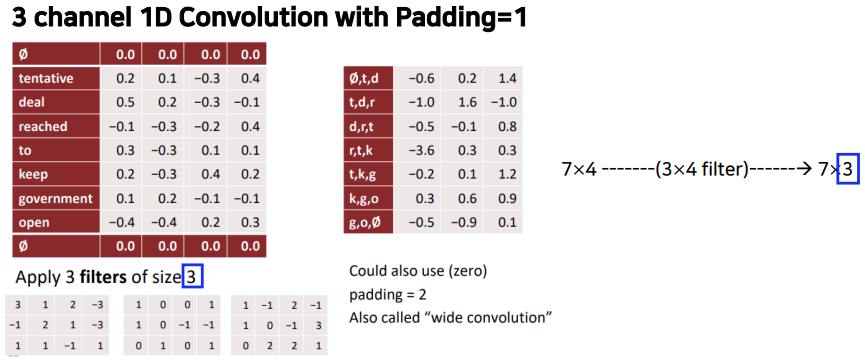 3개의 filter를 사용하면 output이 7*3의 matrix가 됩니다.
3개의 filter를 사용하면 output이 7*3의 matrix가 됩니다.
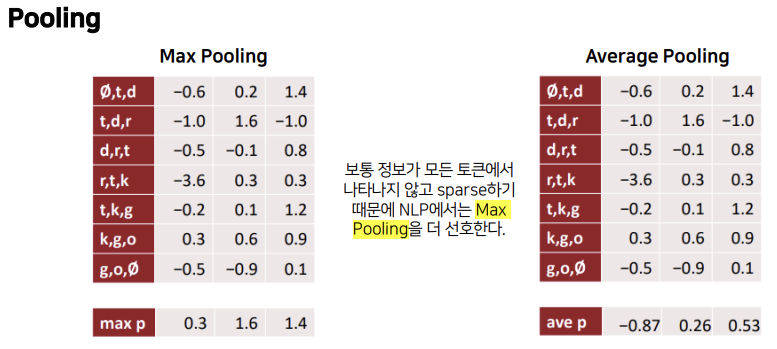 특징들을 요약하는 Pooling은 Max Pooling과 Average Pooling 등이 있습니다. NLP에서는 보통 정보가 모든 토큰에서 나타나지 않고 sparse하기 때문에 Max Pooling을 더 선호한다고 합니다.
특징들을 요약하는 Pooling은 Max Pooling과 Average Pooling 등이 있습니다. NLP에서는 보통 정보가 모든 토큰에서 나타나지 않고 sparse하기 때문에 Max Pooling을 더 선호한다고 합니다.
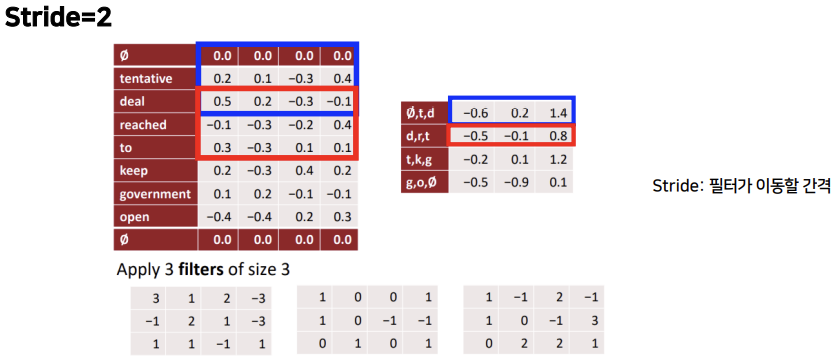 stride는 필터가 이동할 간격을 의미합니다. stride=2이면 두 칸씩 건너뛰며 이동합니다.
stride는 필터가 이동할 간격을 의미합니다. stride=2이면 두 칸씩 건너뛰며 이동합니다.
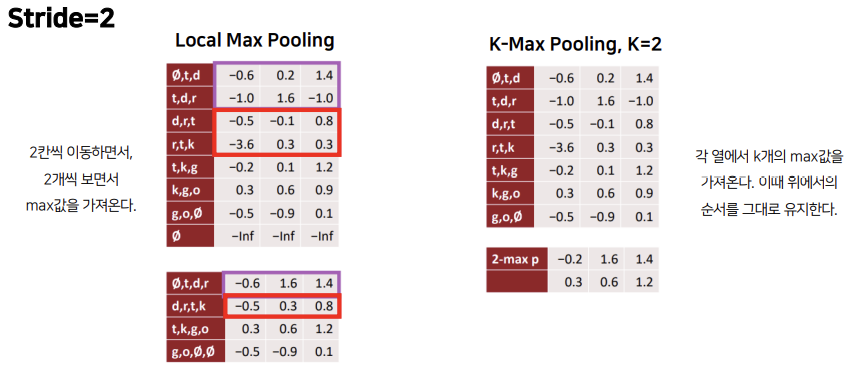 stride=2, Local Max Pooling은 2개의 행씩 보면서 max값을 가져오는 것인데, 이때 두 칸씩 건너뛰며 이동합니다.
stride=2, Local Max Pooling은 2개의 행씩 보면서 max값을 가져오는 것인데, 이때 두 칸씩 건너뛰며 이동합니다.
K-Max Pooling은 각 열에서 K개의 max값을 가져오는 것인데, 이때 순서는 위에서의 순서와 동일하게 가져옵니다.
 원래 문장에 filter를 적용해서 나온 오른쪽 matrix의 각 행에 번호를 붙였을 때, dilation=2라는 것은 2씩 차이가 나는 행끼리 묶어서 다시 filter를 적용시키는 것입니다. 이는 넓은 범위를 적은 파라미터로 커버할 수 있게 해줍니다.
원래 문장에 filter를 적용해서 나온 오른쪽 matrix의 각 행에 번호를 붙였을 때, dilation=2라는 것은 2씩 차이가 나는 행끼리 묶어서 다시 filter를 적용시키는 것입니다. 이는 넓은 범위를 적은 파라미터로 커버할 수 있게 해줍니다.
문장의 의미를 더 많이 이해하기 위해서는
- Filter의 크기 증가시키기
- Dilated Convolution을 사용하여 한 번에 보는 범위 늘리기
- CNN의 depth 증가시키기
등의 방법을 사용하면 됩니다.
3. CNN for Classification
논문 "Yoon Kim(2014): Convolutional Neural Networks for Sentence Classification. EMNLP 2014."를 살펴보겠습니다.
 input은 word vector이고, word vector를 concat한 sentence를 통해 연산이 이루어집니다.
input은 word vector이고, word vector를 concat한 sentence를 통해 연산이 이루어집니다.
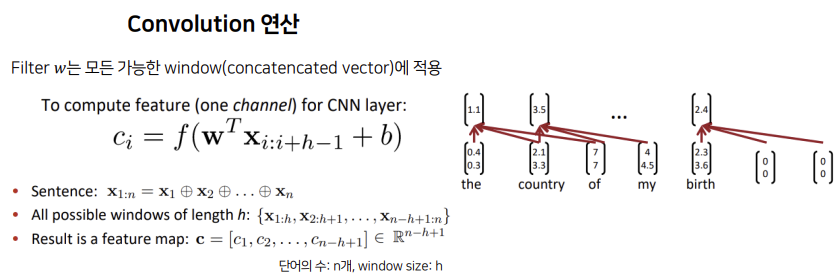 모든 단어의 개수가 n개, window size는 h라고 할 때, feature map은 모든 가능한 window에 filter W를 적용시켜서 나온 벡터입니다.
모든 단어의 개수가 n개, window size는 h라고 할 때, feature map은 모든 가능한 window에 filter W를 적용시켜서 나온 벡터입니다.
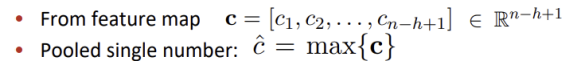 Feature map 결과에 pooling을 적용합니다. Mutiple filter weights W를 사용하며, Max pooling은 c의 길이에 상관이 없으므로 filter size의 변화와 다양한 문장 길이에 대해 유연한 대처가 가능합니다.
Feature map 결과에 pooling을 적용합니다. Mutiple filter weights W를 사용하며, Max pooling은 c의 길이에 상관이 없으므로 filter size의 변화와 다양한 문장 길이에 대해 유연한 대처가 가능합니다.
 실제 모델에서는 위와 같이 세팅했다고 합니다. 해당 모델은 간단한 single layer CNN으로 유의미한 분류 결과를 낸 것에 의의가 있습니다.
실제 모델에서는 위와 같이 세팅했다고 합니다. 해당 모델은 간단한 single layer CNN으로 유의미한 분류 결과를 낸 것에 의의가 있습니다.
4. Toolkits
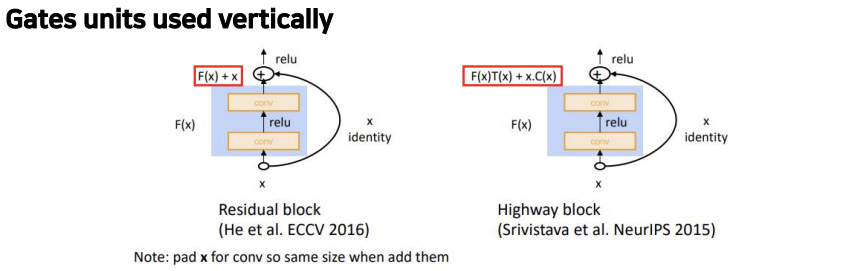 Residual block과 Highway block은 모두 convolution layer를 지나온 결과에 x에 대한 정보를 더해주는 shortcut connection 개념이라는 점에서 공통점이 있습니다. 다만 Residual block에서는 F(x)만 사용하고, Highway block에서는 Transform gate인 T(x)와 Carry gate인 C(x)를 사용한다는 점에서 차이가 있습니다. T(x)와 C(x)는 output이 input에 대하여 얼마나 변환되고 옮겨졌는지를 표현합니다.
Residual block과 Highway block은 모두 convolution layer를 지나온 결과에 x에 대한 정보를 더해주는 shortcut connection 개념이라는 점에서 공통점이 있습니다. 다만 Residual block에서는 F(x)만 사용하고, Highway block에서는 Transform gate인 T(x)와 Carry gate인 C(x)를 사용한다는 점에서 차이가 있습니다. T(x)와 C(x)는 output이 input에 대하여 얼마나 변환되고 옮겨졌는지를 표현합니다.
Batch Normalization
- CNN에서 자주 사용
- Batch별로 평균은 0, 분산은 1로 정규화
- parameter initialization에 훨씬 덜 민감
- Learning rate tuning이 더 쉬워짐
1*1 Convolutions
- 1*1 convolutions are convolutional kernels with kernel_size=1
- 더 작은 채널로 축소할 때 사용할 수 있음
- 매우 적은 추가 파라미터로 추가적인 neural network layer를 추가할 수 있음
CNN application: Translation
Kalchbrenner and Blunsom (2013): Recurrent Continuous Translation Models
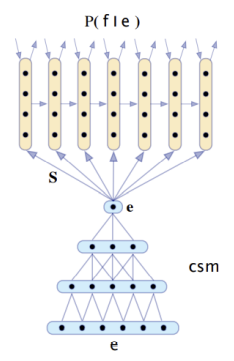
seq2seq 이전에 나온 translation 모델로, 인코딩에 CNN을, 디코딩에 RNN을 사용하였습니다.
또한 아래와 같은 모델들도 있습니다.
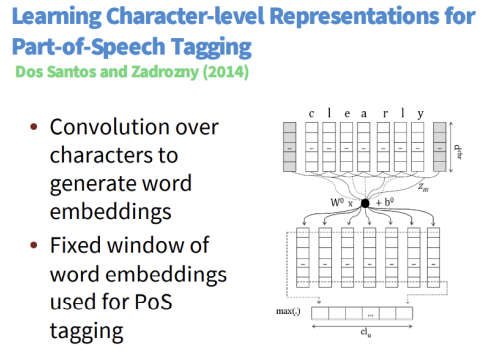
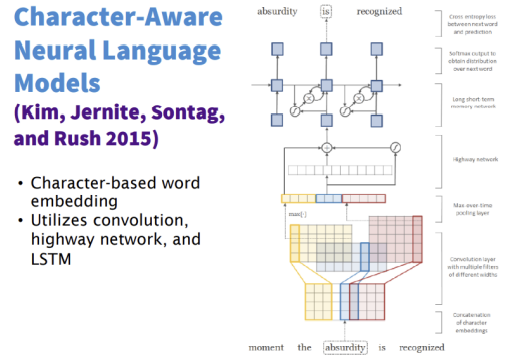
5. Deep CNN for Text Classification
Conneau, Schwenk, Lecun, Barrault(2017): Very Deep Convolutional Networks for Text Classification. EACL 2017.
VD-CNN architecture
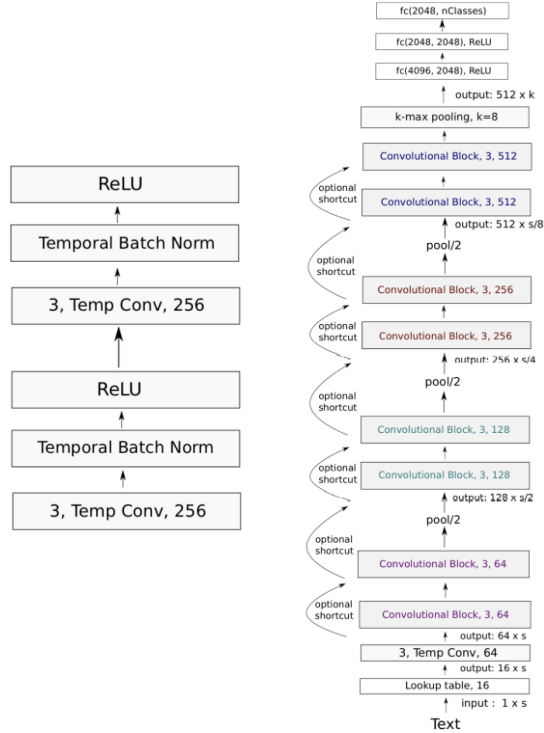

 각 convolutional block은 두 개의 convolutional layer로 이루어져 있고, 각 layer는 batch norm과 ReLU를 거칩니다. Convolution의 size는 3이고, padding으로 input 길이를 고정시킵니다. VGGnet 또는 ResNet과 비슷한 구조를 가지지만, 이미지처럼 신경망이 매우 깊지는 않습니다.
각 convolutional block은 두 개의 convolutional layer로 이루어져 있고, 각 layer는 batch norm과 ReLU를 거칩니다. Convolution의 size는 3이고, padding으로 input 길이를 고정시킵니다. VGGnet 또는 ResNet과 비슷한 구조를 가지지만, 이미지처럼 신경망이 매우 깊지는 않습니다.
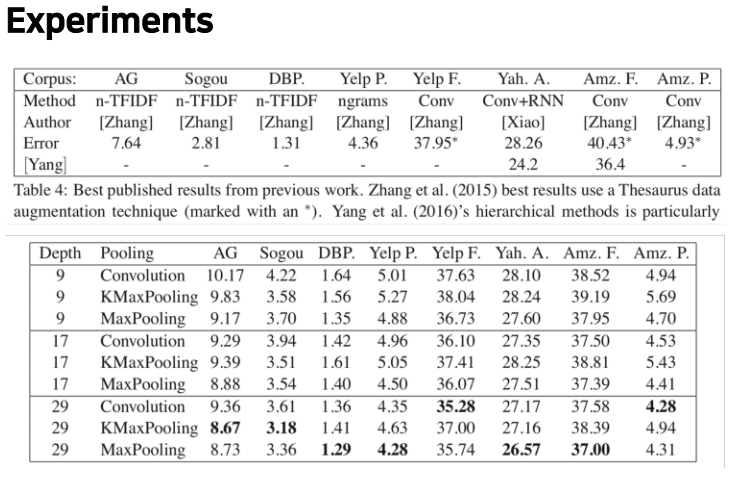 depth가 29일 때 성능이 가장 좋았으며, 표에는 나와있지 않지만 depth가 47일 때가 29일 때보다 성능이 낮았다고 합니다.
depth가 29일 때 성능이 가장 좋았으며, 표에는 나와있지 않지만 depth가 47일 때가 29일 때보다 성능이 낮았다고 합니다.
6. Quasi-Recurrent Neural Network
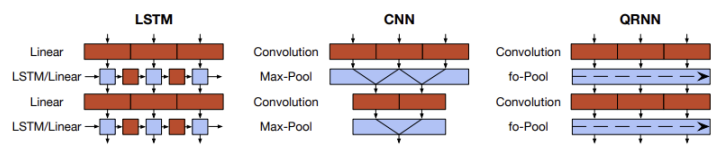 RNN은 병렬 입력이 되지 않기 때문에 속도가 느립니다. 이를 개선하기 위해 병렬 작업이 쉬운 CNN과 결합한 것이 Quasi-Recurrent Neural Network입니다. convolution과 pooling을 통해 sequential data를 병렬 처리하였고, sentiment classification을 했을 때 LSTM과 성능은 비슷하지만 속도는 3배 빨랐다고 합니다.
RNN은 병렬 입력이 되지 않기 때문에 속도가 느립니다. 이를 개선하기 위해 병렬 작업이 쉬운 CNN과 결합한 것이 Quasi-Recurrent Neural Network입니다. convolution과 pooling을 통해 sequential data를 병렬 처리하였고, sentiment classification을 했을 때 LSTM과 성능은 비슷하지만 속도는 3배 빨랐다고 합니다.
Reference
- CS224 Winter 2019: Natural Language Processing with Deep Learning
- https://velog.io/@tobigs-text1415/Lecture-11-Convolutional-Networks-for-NLP
- https://velog.io/@tobigs-text1314/CS224n-Lecture-11-ConvNets-for-NLP
{kind=link}

3개의 댓글

이전 강의들에서는 NLP에 주로 사용되는 RNN기법의 장기기억 단점을 언급하며 LSTM,GRU 와 같은 long term model들을 언급했습니다. 본 강의에서는 모든 input값에 다른 가중치(?)가 주어진다는 문제점을 해결하기 위해서 CNN을 text task에 맞기 사용한 예시들과 설명을 배웠습니다. 우선 text에 CNN을 사용하기 위한 main idea는 가능한 모든 token으로 나눠 벡터화시키는 것입니다. 이후 CNN의 filter를 조정해가면서 gram별 vector를 얻습니다. 이렇게 만들어진 embedding vector를 통해서 text, sentence로 변형하며 다양한 모델에 적용을 할 수 있습니다.

16기 이승주
RNN의 단점은 Perfix context(the, of) 없이는 phrase를 캡쳐할 수 없으며 softmax가 마지막 step에서만 계산되기 때문에 마지막 단어에 영향을 많이 받는다는 점입니다. CNN for Text에서는 모든 가능한 어절을 벡터로 계산하고 문장의 의미를 더 많이 이해하기 위해서는 Filter의 크기 증가시키기, Dilated Convolution을 사용하여 한 번에 보는 범위 늘리기, CNN의 depth 증가시키기 등의 방법을 사용합니다. CNN for Classification에서는 input은 word vector이고, word vector를 concat한 sentence를 통해 연산이 이루어집니다. 모든 단어의 개수가 n개, window size는 h라고 할 때, feature map은 모든 가능한 window에 filter W를 적용시켜서 나온 벡터입니다.
RNN은 병렬 입력이 되지 않아 느린 속도를 개선하기 위해 병렬 작업이 쉬운 CNN과 결합한 것이 Quasi-Recurrent Neural Network입니다. convolution과 pooling을 통해 sequential data를 병렬 처리하였고, sentiment classification을 했을 때 LSTM과 성능은 비슷하지만 속도는 3배 빨랐다고 합니다
15기 김현지
RNN의 단점
perfix context 없이는 phrase를 캡쳐할 수 없고, 대부분 softmax가 마지막 step에서만 계산되기 때문에 마지막 단어에 영향을 많이 받는다.
CNN for Text
CNN for Classification
input은 word vector이고, word vector를 concat한 sentence를 통해 연산이 이루어진다.
Deep CNN for Text Classification
VGGNet 또는 ResNet과 비슷한 구조를 가지지만, 이미지처럼 신경망이 매우 깊지는 않는다.
Quasi-Recurrent Neural Network