Week 04 | Self-Supervised Learning
Types of learningㅉ
- Supervised learning : 정답이 있는 데이터를 이용. ex) classification, regression
- Unsupervised learning : 정답 label이 없는 데이터를 이용. 좋은 representation vector를 얻는 것이 목표 ex) clustering, self-supervised learning, GAN
Self-supervised learning
- self-supervised learning에 대한 Yann LeCun의 정의
"The machine predicts any parts of its input for any observed part"
= 기계가 관측치를 이용한 입력값의 일부를 예측하는 것
- 일종의 자동화된 과정을 통해 데이터 내에서 레이블을 생성 -> 데이터의 다른 부분을 이용한 일부분을 예측
Self-supervised learning의 등장 배경
- Computer vision에서의 pre-trained model과 transfer learning
- Supervised learning 방식이 downstream task(target task)에서 효과적인 feature를 학습하는 데에 효과적인가?

- 기존 CNN이 학습하는 방식과 사람의 학습 방식의 비교
- 다양한 의자들을 모두 같은 것이라고 가정하고 출발하는 것이 인간의 학습방식과는 맞지 않다
=> 딥러닝 모델도 각 이미지에 대한 특성을 잘 파악할 수 있도록 학습시키는게 우선이다. 해당 이미지들이 무엇인지 학습하는게 아닌, 해당 이미지들이 무엇과 유사한지를 살펴보는 것이 인간의 학습관점에 더 맞다
Self-supervised learning의 분류
- Generative / Preditive method : encoder가 입력 데이터를 받아 latent vector z를 생성, 이를 원래 데이터로 reconstruct

- Contrastive method : encoder가 여러 입력 데이터를 받아 latent vector z를 생성, 이를 이용해 유사도를 측정. cosine similarity metric 사용
1. GAN-based self-supervised learning
(1) AE(AutoEncoder) based approaches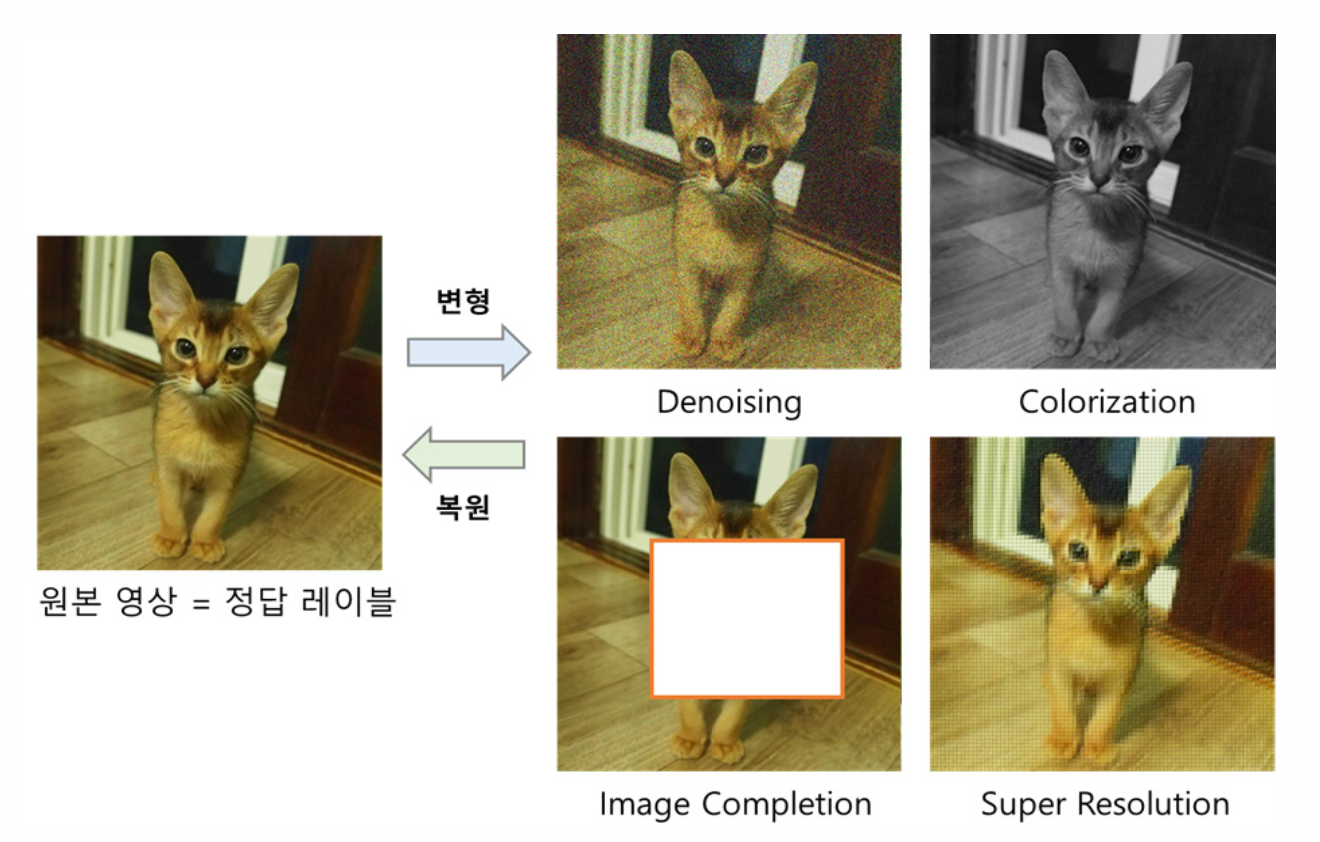
- Denoising : 이미지에 random noise 주입 뒤 복원하도록 학습
- Colorization : 1 channel image -> 3 channel image 생성
- Image Completion : 이미지에 구멍 뚫고 그 영역 복원하도록 학습
- Super Resoltion : low quality image -> high quality image
(2) SSGAN(Self-Supervised GAN)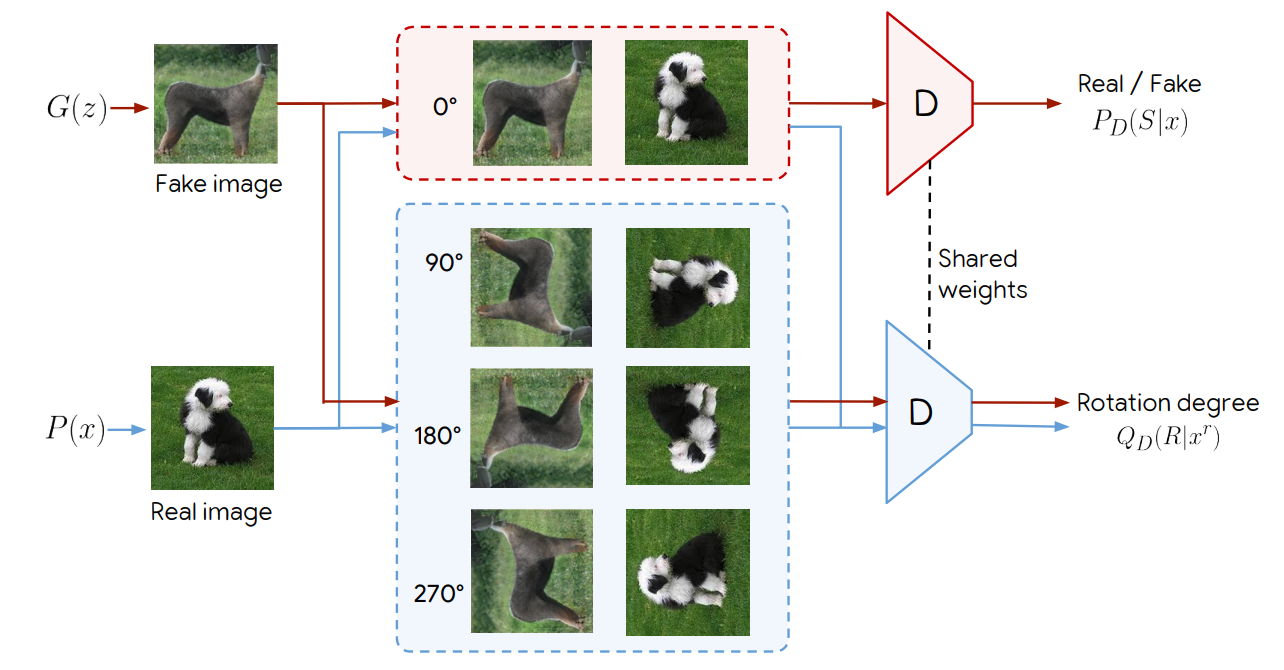
- Discriminator는 이미지의 real/fake와 rotation degree(0, 90, 180, 270) 총 2가지를 구분
- Generator가 만든 이미지를 rotation
- 얼마나 rotate 했는지 cross entropy loss로 만들어서 GAN loss에 더함
- identity(회전 x) 이미지에 대해서 real/fake 구분, 나머지 이미지에 대해서는 rotation angle 학습
GAN 기반 방법론의 한계
- 픽셀 단위로 복원 or 예측하기에 계산 복잡도 높다
2. Pretext task-based self-supervised learning
- "사용자가 새로운 문제를 정의한다"
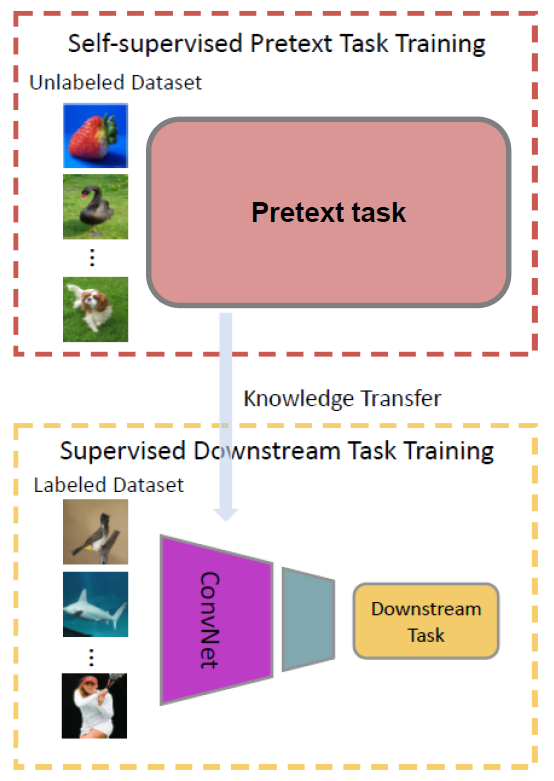
- Pre-trained model 생성
: pretext task 학습(unsupervised) -> 데이터 자체에 대한 모델의 이해 높임 (pretext task가 잘 짜여졌다면 input을 효과적으로 representation 할 것이라는 가정) - Downstream task
: pre-trained model을 downstream task에 적용(supervised)- pretext task : 사용자가 정의한 문제 (ex. downstream task를 위해 시각적 특징을 배우는 단계)
- downstream task : Unlabeled data를 이용한 pretrained model이 뽑은 feature가 잘 학습되었는지 판단하며, 최종적으로 이루고자하는 task (ex. classification)
(1)Exemplar (2014 NIPS)
- 이미지에서 분할 추출(=seed patch), transformation(변형)
- 하나의 seed patch로부터 생성된 patch들을 모두 같은 class로 구분하도록 학습
- 장점 : N개의 exemplar에 N개의 클래스 존재 → fine-grained(세밀한) 정보 보존 가능
- 단점 : N개의 exemplar에 N개의 클래스 존재 → 파라미터 수 ↑ & 소요 시간 ↑
(2)Context Prediction (2015 ICCV)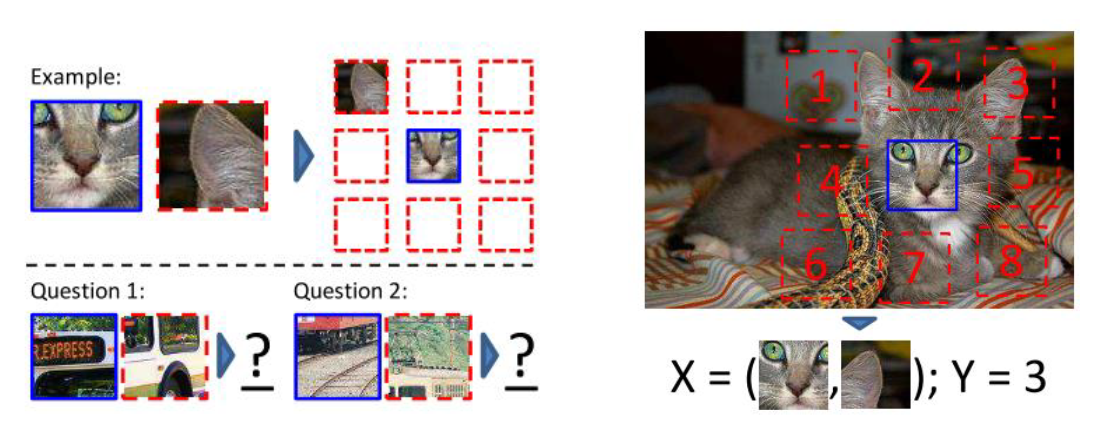
- object 부분을 인지하여 공간적 관계를 파악하는 것을 학습
- 장점 : 최초의 self-supervised learning 방법으로 object 부분에 대하여 학습하게 하는 직관적인 task
- 단점 :
1. 이미지의 representation(대표성)이 목적이지만 patch를 학습한다.
2. 중심 patch 외 8개의 선택지 뿐이라 output space가 적다.
(3)Jigsaw puzzle (2016 ECCV)
- 이미지를 패치로 분할하고 순서를 바꾼다.
- 뒤죽박죽 섞어 놓고 원래의 배치로 돌아가기 위한 permutation을 예측하는 문제
- 100-class classification을 학습시키도록 변화를 줌
(4)Rotation prediction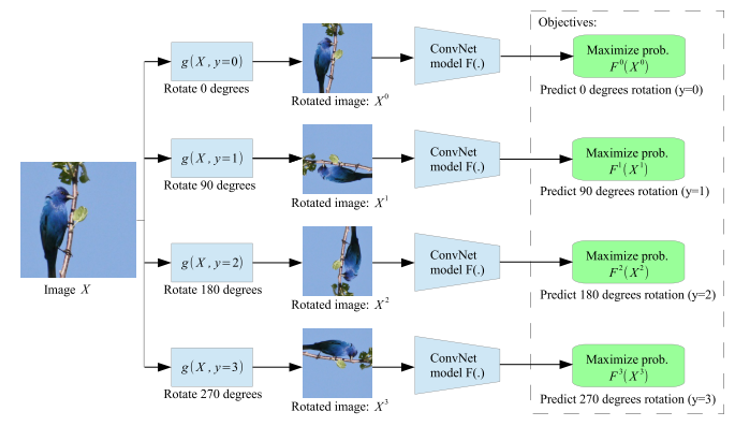
- 0도, 90도, 180도, 270도 회전을 random하게 줌
- 몇도 rotate됐는지를 구분 (4-class classification)
- 사람이 취득한 이미지는 up-standing하게 찍힌 경우가 많다
3. Contrastive learning-based self-supervised learning
Contrastive learning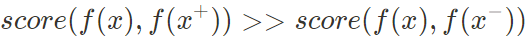
- x+ : 데이터 포인트 x와 유사하거나 똑같은 데이터 포인트, positive sample
- x- : 데이터 포인트 x와 다른 데이터 포인트, negative sample
- x : anchor 데이터 포인트
- score : 두 feature 간의 similarity를 측정하는 metric (아래 식에서는 내적)
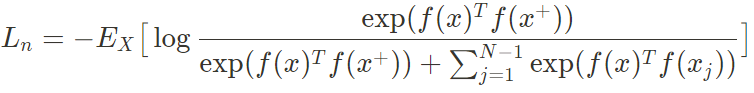
: contrastive learning에서의 InfoNCE loss
- InfoNCE loss 최소화 -> f(x)와 f(x+)의 mutual information에 대한 lower bound 최대화 (참고)
(1) CPC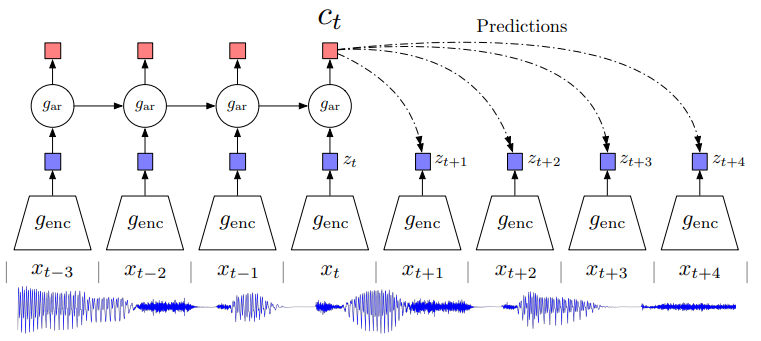
- 텍스트, 음성, 비디오, 이미지와 같이 정렬된 순서로 표현할 수 있는 모든 형태의 데이터에 적용할 수 있는 contrastive method
- 여러 시간 간격으로 떨어져 있는 데이터 포인트들에서 공유되는 정보를 인코딩하여 representation을 학습, 이러한 feature들을 'slow features(시간이 빠르게 지나도 변하지 않는 feature)'라고 부름. ex)오디오에서의 speaker identity, 비디오에서의 action
- 현재 시점에서 먼 시점일수록 연관성이 사라지기 때문에 모델이 shared information(high-level information 추출을 위한)에 집중하면서 학습
(2) SimCLR (2020 ICML)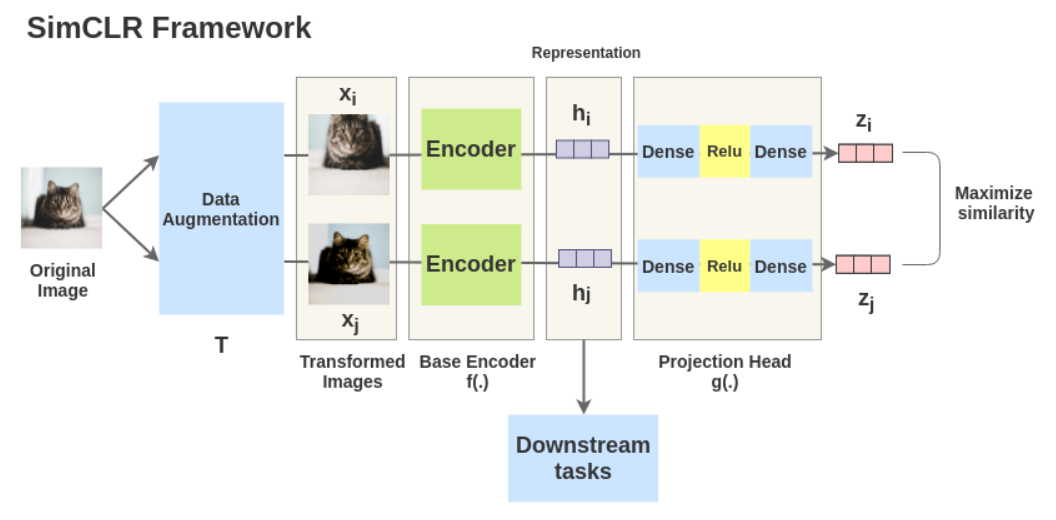
- original image에서 2개의 augmented image 생성 (random cropping & color distortion 적용 시 성능 제일 좋았다고 함)
- ResNet(BaseEncoder)을 통해 representation vector 뽑아냄
- MLP(projection head)를 통해 contrastive loss의 latent space로 변환
- Positive pair간의 similarity ↑, negative pair 간의 similarity ↓
- batch_size=N -> posi

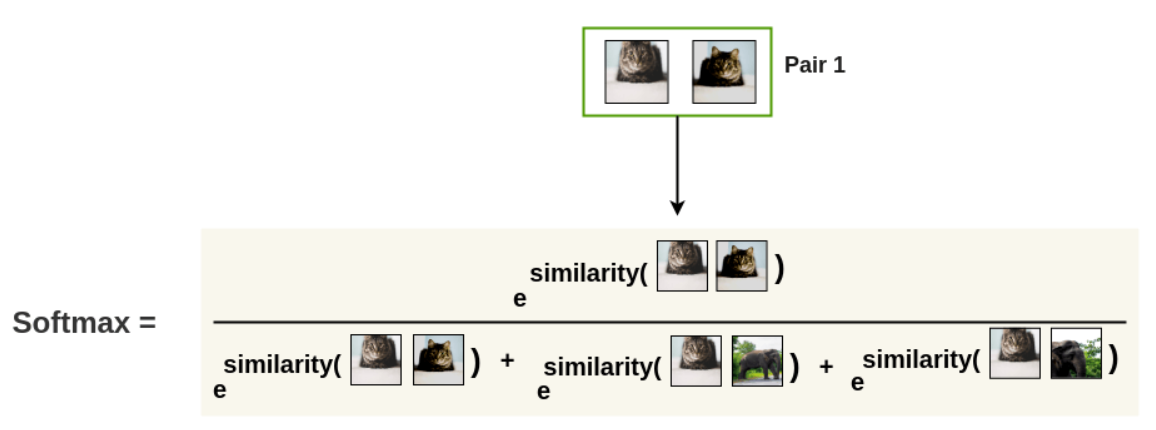
- Contrastive loss (NT-Xent(Normalized Temperature-scaled Cross Entropy))
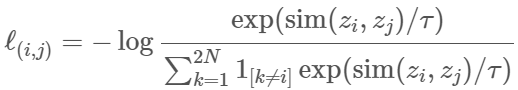
(3) SimCLR V2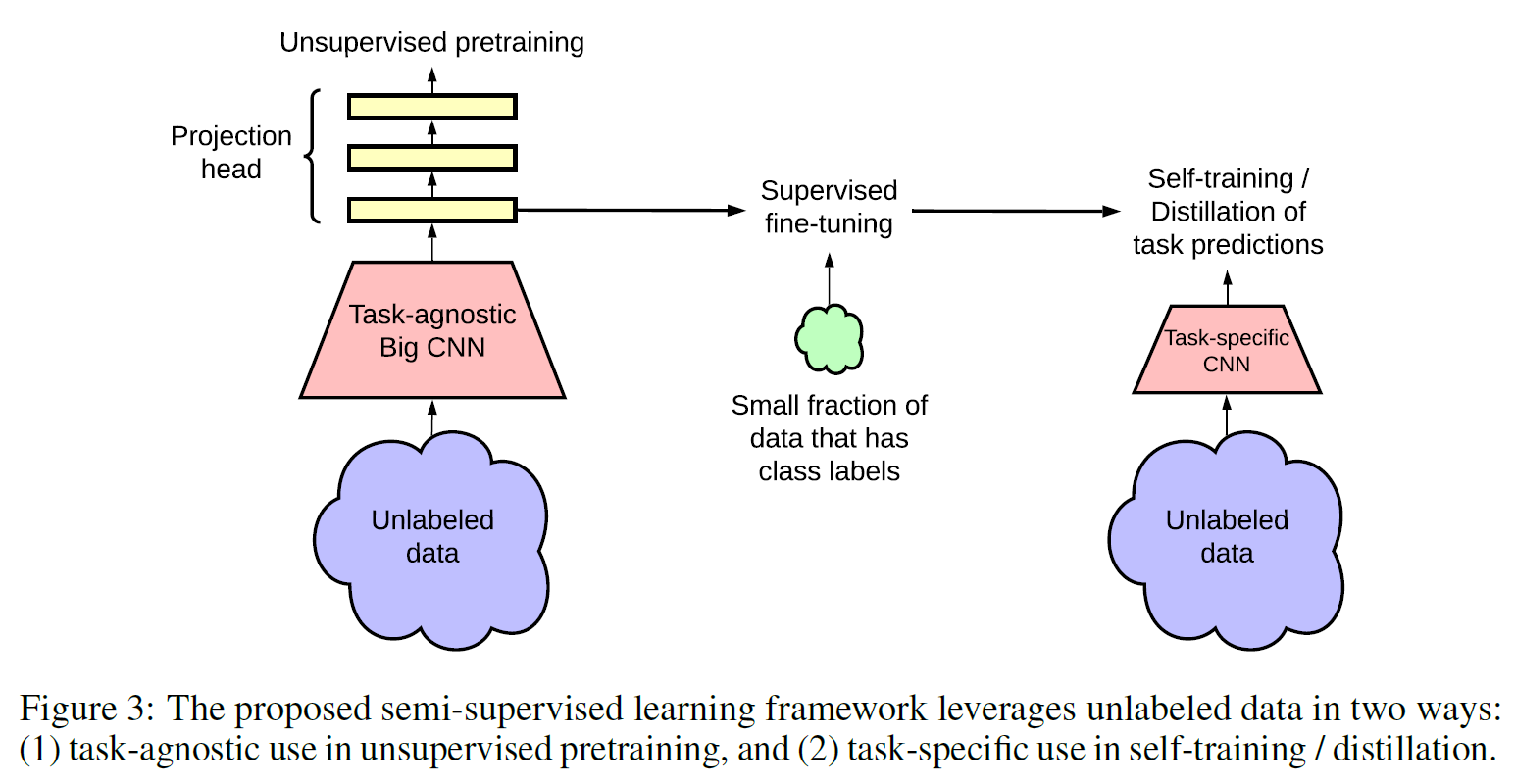
- 기존 SimCLR 모델 개선
- Knowledge distillation
(3) MoCo V1 (2020 CVPR), V2
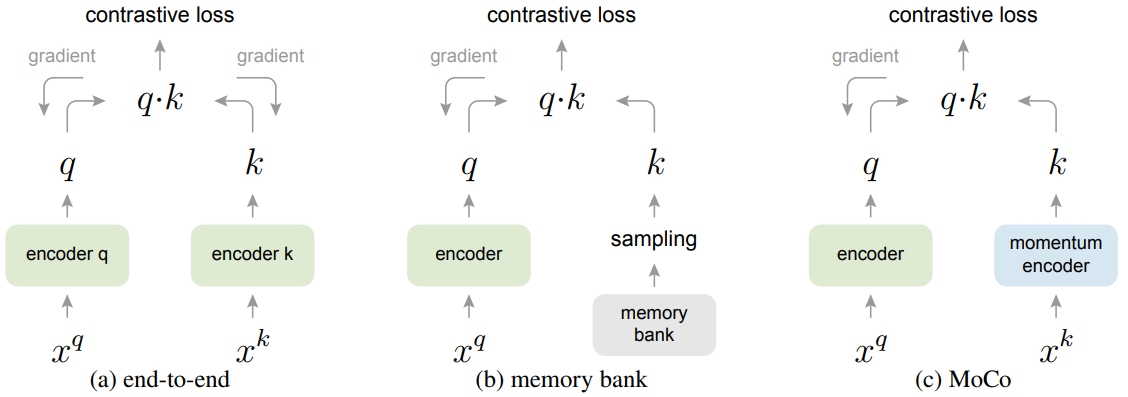
Contrastive learning 기반 방법론의 한계
- negative pair를 잘 선택 해야 함
- 큰 batch size에서 학습시켜야함
- 학습에 사용한 image augmentation option에도 성능 편차가 큼
=> BYOL(negative pair 안씀), ...
Self-supervised learning의 성능 측정 방법
- Unsupervised pre-training을 통해 단순히 pretext task를 잘 푸는 것이 아닌, downstream task에서 좋은 성능을 내는 것이 목표!
- Pre-trained weight를 freeze, 마지막 layer에 linear classifier를 붙여서 downstream task 학습(supervised)
- 모델 뒷단에 linear layer만을 붙임으로써 pre-trained model의 feature extractor로써의 성능을 평가할 수 있음
Self-Supervised learning 연구 흐름
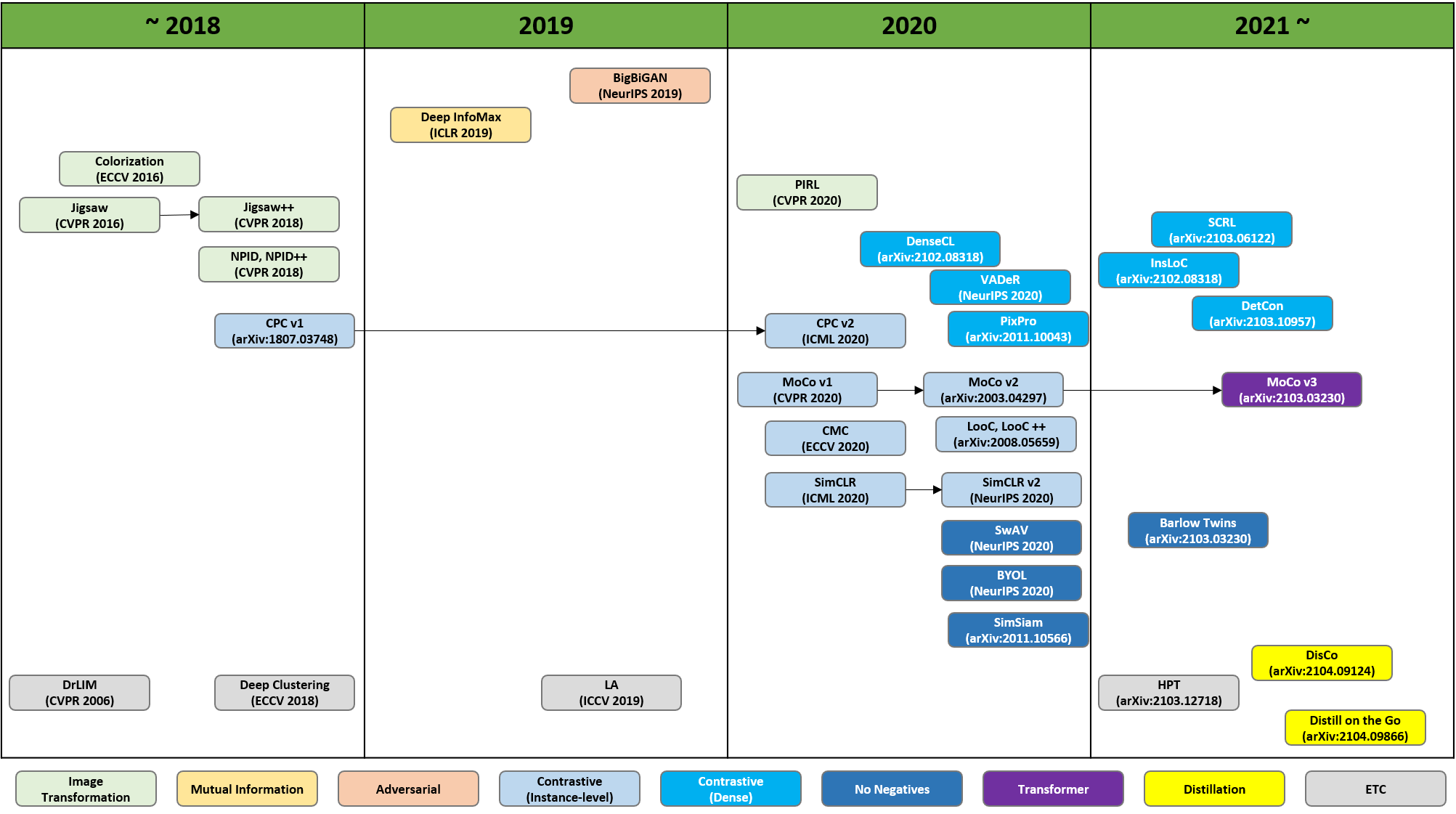
- pretext task 기반 방법론의 한계
- pretext task를 잘 풀게끔 학습되었을 뿐 이미지의 일반적인 시각적 특징을 잡아내지는 못함
- pretext task 기반 -> contrastive learning 기반 -> ...
NLP에서의 self-supervised learning
BERT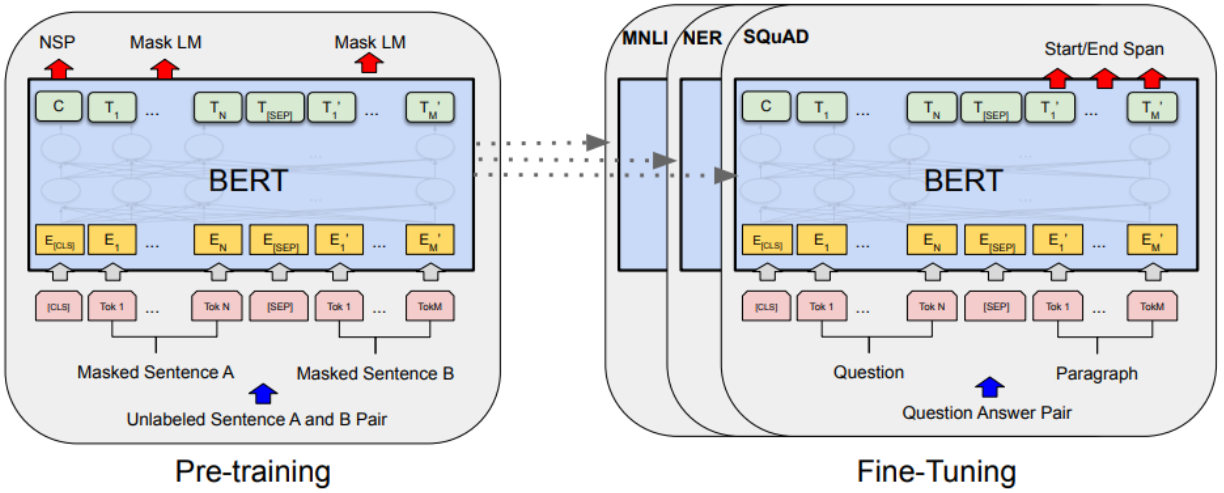
(1) Masked Language Modeling
- 데이터가 주어지면, 이 문장 데이터 중 일정 비율을 masking
- 나머지 단어들만을 가지고 이를 맞추는 연습을 한다. (앞 뒤 문맥 모두 고려)
(2) Next Sentence Prediction
- 두 문장을 뽑아 구분자 [SEP]을 문장끝에 넣은 뒤, 연속적으로 문장들을 잇는다
- [CLS] 토큰을 이은 문장 가장 앞에 넣어 만든 시퀀스를 가지고, 두 문장이 서로 인접한(다음에 오는) 문장인지, 아니면 관계가 없는 문장인지 판단하는 이진분류 수행
Speech에서의 self-supervised learning
Wav2Vec 2.0
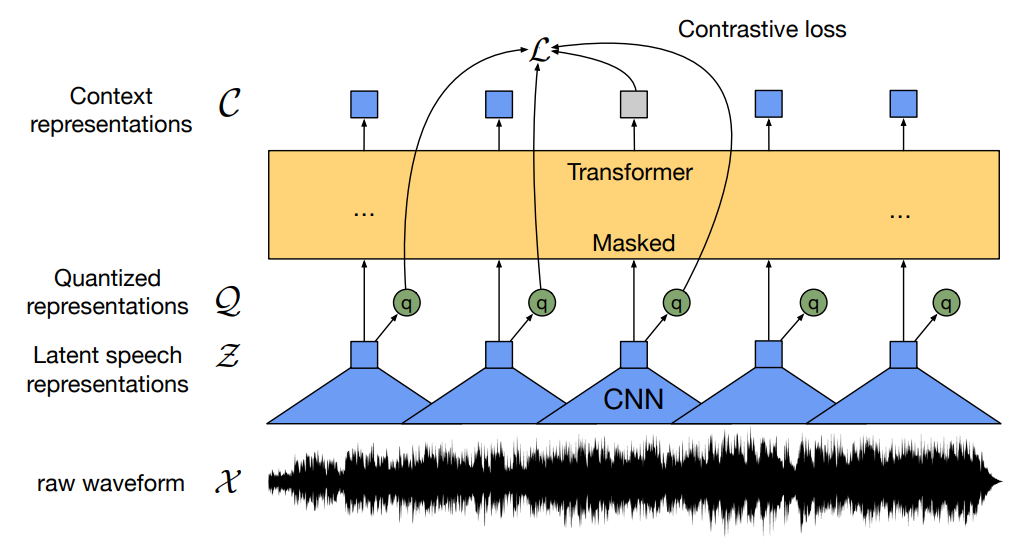
TERA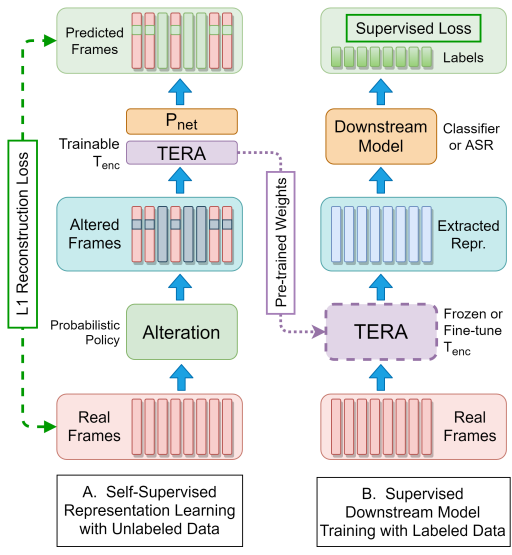
- input 데이터에 alteration 적용
- L1 reconstruction error 최소화
Self-supervised learning의 장점
- 데이터의 서로 다른 부분이 상호 작용하는 방식을 관찰하여 데이터 표현을 학습
- 많은 양의 human-annotated data 없이도 준수한 성능
- 단일 데이터 샘플과 연관될 수 있는 여러 modality에 활용 가능
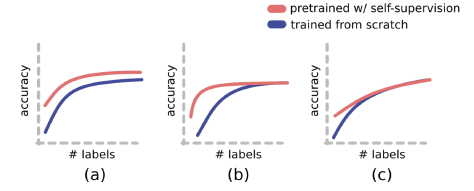
- 실제로 지도학습과 성능을 비교했을 때 (c)의 상황이 발생
- 레이블링 된 데이터가 어느정도 수준 이상으로 확보된 상태에선 지도학습과 더이상 성능차이를 보이지 못하면서 학습됨
- 기존의 지도학습이 의도치않은 패턴을 학습하거나, OOD 문제에 취약한 것에 비하면 SSL은 안정적인 모델을 만들 수 있다는 점에서 매력적

1617생성 심화 세미나