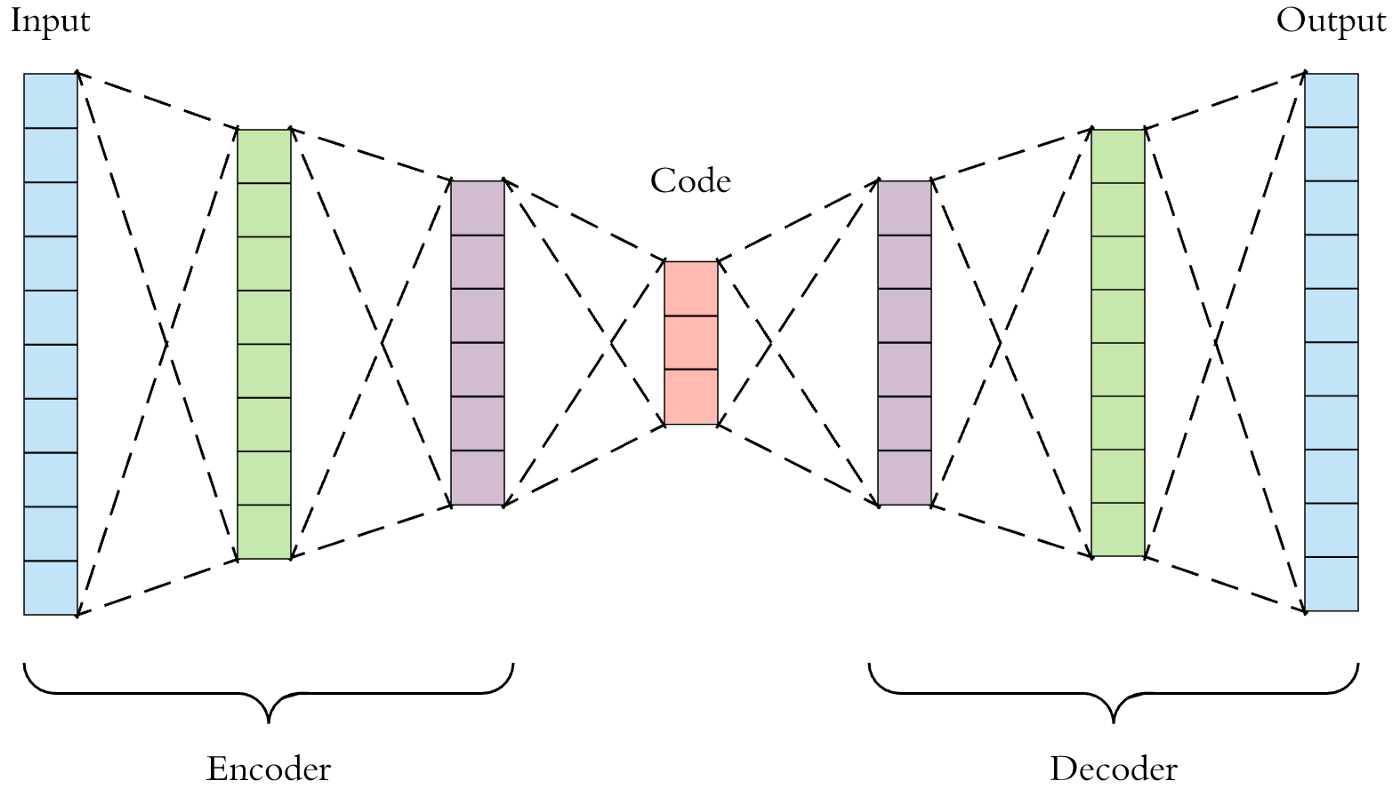
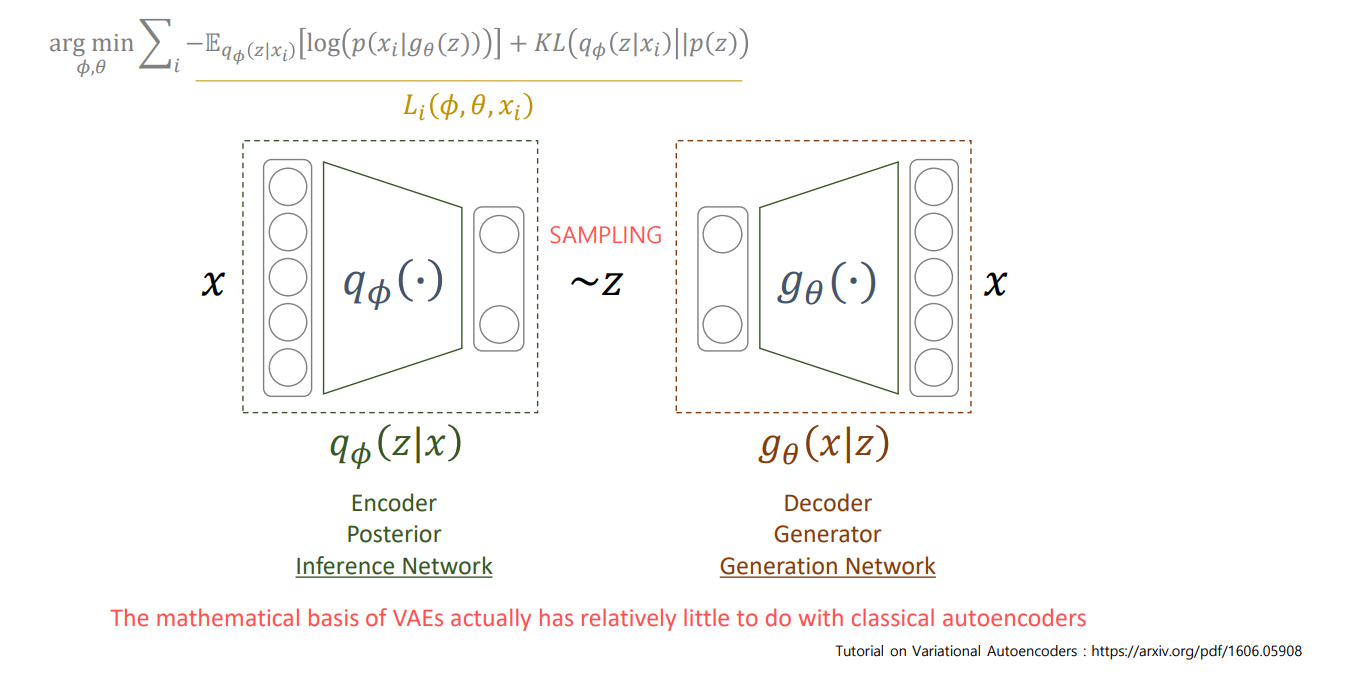
For trained Auto Encoder, encoder part is used to reduce dimension (Manifold Learning) and decoder part used to generate (Generate model learning).
Manifold?
2. Loss with BP
Two assumptions are required to use backpropagation.
First. Total loss of DNN over training samples is the sum of loss for each training sample.
We could calculate loss as sum of squares for every individual data, but we don't.
If we do so, between updating paramters with total loss and individual loss will be different due to differnet gradient.
Second one is
Loss for each training example is a function of final output of DNN.
GoogLeNet and weight decay is not couter examples.
3. Gradient Descent
Then how we update parameters?
We think it's so obvious that θk+1←θk=η∇L(θk,D)
For details.
By Taylor series at point θ L(x)≈L(θ)+L′(θ)(x−θ) Letx=θ+Δθ ThenL(θ+ΔΘ)−L(θ)≈∇LΔθ
Thus it should be negative.
Because loss have to be lowered after update.
$Let \;\; \Delta\theta == -\eta \Delta L $
ML관점은 분포 가정이 필요합니다.
ML을 한줄로 표현하면 어떤 R.V가 어떠한 분포를 따르는데 sampling이 given인 상황에서 그것들을 다 곱하여 log한 후 maximizer를 구하는 방식입니다.
그리고 그 어떤 분포는 사전에 정의 되어야 하고 그 분포의 모수 parameter를 찾는 것이 목표 입니다.
예를들어 정규분포와 베르누이 분포라면 N(μ,σ2),Ber(p)입니다.
이를 DL Model에 접목해보겠습니다.
4.2 Loss with ML
예를들어 강아지 사진 x1가 있고 이에 해당하는 y1은 1 이라고 해봅시다.
( 실제로는 class의 개수가 여러개지만 하나만 생각합니다. 그래야 이해가 됩니다. )
그러면 model의 output은 fθ(x1)이 됩니다. 이게 1에 가까울 수록 좋습니다. 그렇게 θ를 학습해야 합니다.
이때 ML관점에서의 given sample은 (x1,y1)입니다. 이러한 강아진 사진이 N장 있다고 한다면 총 N개의 observation이 있는 겁니다.
이제 우리의 목표는 model의 θ를 찾는 것입니다.
이때 주의할 점이 모델의 θ가 ML에서 찾고자 하는 parameter라고 생각하면 힘들어 집니다.
(결론적으로 의미는 같으나 엄밀하게는 다르다고 생각하는 편이 좋음.)
여기서 잘못된? 생각 때문에 이해가 안되었던 부분이 있었는데 해당내용도 적어 보자면 우선 x1라는 data가 주어지고 이의 output인 fθ(x)가 어떤한 분포를 따르는 R.V이다.
다시 ML로 돌아가 생각해보면 어떠한 R.V와 그것이 따르는 distribution이 필요합니다.
이때 R.V는 y라고 할 것이고 그것이 따르는 분포는 gaussian과 bernoulli가 있고 이때의 평균을 fθ(x)라고 할겁니다.
이게 엄청 헷갈립니다. 어떻게 y가 R.V인가?? 고전적 statistical estimation 관점에서 보면 우리가 궁금한 것은 θ이고 이를 추정 하려면 이를 Random variable로 보고 distribution을 찾던가 아니면 가정한다음에 모수를 찾던가 해야 하는데 여기서는 궁금한것이 θ이지만 이를 직접 찾는 것이 아니라간접적으로 찾습니다.
여기서 분포 가정을 한다는 것은 label y에 대한 분포 가정이며 이것이 R.V입니다. 물론 R.V가 아닙니다. 근데 그냥 그렇게 보겠다는 겁니다.
(주의할점 하나는 y는 output이 아니라 target이라는 것입니다.)
여기서도 헷갈립니다. 어째든 y는 그냥 label이고 이건 그냥 1인데 이걸 왜 추정하지??!!
라는 생각을 하는 것이 당연합니다.
이는 다음과 같이 설명할 수 있습니다.
ML관점에서는 y를 추정하는 것이 맞습니다. 하지만 우리는 이미 y를 알고 있습니다. 다시 이를 추정하는 방법을 생각해 보겠습니다.
y를 추정 한다는 것은 y의 distribution을 추정하는것 입니다. 정확히는 어떤 distribution인지는 정했으니 이의 parameter를 추정하는 것입니다. 근데 이때 parameter중에서 모평균을 fθ(x)라고 한다면 우리는 fθ(x)를 추정하는 것이고 이는 곧 model의 parameter인 θ를 추정하는 것입니다.
정리하자면 이미 우리는 y∼(1)이라는 것을 알고 있는데 1이라는 것을 model의 θ로 paramiterize하여 이를 추정하겠다는 것입니다.
따라서 data의 label인 y를 ML로 추정한다는 것은 곧 y의 parameter인 fθ(x)를 추정하는 것이고 이는 model의 θ를 추정하는 것입니다.
방금 모평균이라고 했습니다.
이를 더욱 자세하게 설명하면 다음과 같습니다.
우리는 y가 정확히 1인 분포라는 것을 알고 있고 따라서 모평균이 1 입니다.
근데 모평균을 fθ(x)라고 하여 ML추정을 하면 θ가 fθ(x)가 1이 되게끔 학습 되는 것입니다.
정리하면 다음과 같습니다. y∼(fθ(x))라고 하여 ML추정을 진행하면 (N=1)
우리가 찾고자 하는 θ는 argmin(−log(p(y∣fθ(x)))) 입니다.
여기서 P(y∣fθ(x))는 모평균이 fθ(x)인 random variable y이 y일 확률입니다.
( 이거 이렇게 보는 것보다 그냥 f써서 pdf로 보는 편이 휠씬 편합니다. )
정확히 해석하면 P(y∣fθ(x))는 R.V y가 y일 확률인데 이게 정확히 말하면 label이 y일 확률이라고 해석해야 하는데 이거 이해하는게 생각보다 헷갈립니다. 왜냐면 또 다시 아니 y는 무조건 1인데 그럼 y=1일 확률은 무조건 1 아니냐 라고 할 수 있는데 y는 평균이 fθ(x)인 R.V이므로 아니라고 봐야합니다.
여기까지 왔으면 다 왔습니다.
지금까지는 P(y∣fθ(x)) 도대체 무엇인가에 대한 설명 이었습니다.
이 관점에서 해석하면 가능도 함수는 P(y∣fθ(x))이므로 이를 최대화 한다. 라고 해석하면 되고 이것이 ML이며 곧 MSE와 CEE입니다.
다시 정리하면 핵심은 두가지로 추려집니다.
첫번째.
label y를 R.V로 보고 추정하겠다.
근데 이를 추정한다는 것은 y의 분포를 추정하는 것이고 일단은 모평균만 추정하겠다.
그리고 이 모평균을 θ로 paramiterize하겠다.
즉, y는 모평균 fθ(x)을 따르는 R.V이다.
그리고 given data를 이용하여 ML방법을 사용하면 MSE와 CEE가 된다.
두번째.
따라서 P(y∣fθ(x))가 가능도 함수이다.
이를 최대화 시키는 θ를 찾는 것이 ML이다.
쫌더 해석해보면 output(평균)이 fθ(x)로 나왔을때 label y의 가능도 이다.
엄밀하게 가능도이기 이전에 이는 y의 pdf가 맞습니다. 위에서 y가 R.V라는 것을 remind해보세요.
즉, L2 ( MSE )를 Loss로 하여 이를 최소화 시키는 방향으로 parameter를 update ( train )하는 것은 MLE방법과 같다. 또한 위의 링크에 설명 되어 있을텐데 MLE방법은 sampling data를 이용하여 모집단의 분포 즉, parameter를 추정하는 좋은 방법이므로 L2 Loss의 정당성을 얻을 수 있다.
4.4 CEE MLE
마찬가지로 CEE의 정당성도 확인 가능합니다.
CEE는 범주형 즉, 이산형일때 사용하는 Loss입니다.
따라서 위에서 분포가정을 Gaussian→Bernoulli 로 바꾸어봅시다.
lety^=softmax(f(x∣θ))thenitmeansprobability lett∼Ber(y^) thenpdfoft:ft(t∣y^)=(y^)x(1−y^)1−x usinggivendatasetD={(x1,t1),(x2,t2),…(xN,tN)}wecanmakelikelthoodfunctions.t. L(θ∣D)=i=1∏N{(yi^)ti(1−yi^)1−ti} letnumberoftarget==1MthenL(θ∣D)=i=1∏M{yi^ti} ∴negativelog=−i=1∑Mtilog(yi^)
이는 CEE이다.
따라서 CEE에 대한 통계적 정당성도 확보된다.
4.5 Weight decay MAE
MLE는 가능도함수를 최대화 시키는 방법입니다. MAE는 Posterior를 최대화 시키는 방법입니다. ( 베이즈에서 다시 정리 )
Posterior를 최대화 하는 이유는 식을 보면 알지만 data가 주어졌을때의 parameter의 확률(분포)입니다. 당연히 최대화 시켜야 합니다. Posterior=P(w∣D)=∫P(D∣w)P(w)dwP(D∣w)P(w) letρ=∫P(D∣w)P(w)dw1thenP(w∣D)=ρP(D∣w)P(w)
여기서 우리는 한가지 사실을 알고 있습니다.
model의 overfitting을 방지하기 위해서는 parameter인 w의 크기 ( abs or square )를 제한해야 합니다.
따라서 prior로 이 논리를 사용합니다.
크기를 감소시키기 위해서는 w의 값들을 0에 많이 분포시키도록 학습하면 됩니다.
앞에서 학습하는 방향은 Loss가 정해준하고 하였습니다. 즉, w를 0쪽에 많이 분포시키는 것을 Loss에 적용하면 됩니다. w를 0쪽에 많이 분포시키는 방법으로는 w∼N(0,σw2)를 prior로 주는 방법을 사용합니다.
즉, p(w)=σw2π1exp{−2σw2w2} 입니다.
다시한번 생각해 보면 어째든 목표는 poterior를 최대화 하는 parameter w를 찾는 것이다.
따라서 W=argmaxw{log(P(w∣D))}=argmaxw{log(ρP(D∣w)P(w))} =argmaxw{log(ρ)+log(D∣w)+log(P(w))} log(D∣w)를 최대화 하기 위해서는 Loss=i=1∑N((ti−f(xi∣θ))2)을 최소화 하면 된다고 위에서 다루었습니다.
따라서 마지막항을 p(w)=σw2π1exp{−2σw2w2}임을 이용하여 전개하면 다음과 같습니다. W=argmaxw{log(ρ)−i=1∑N((ti−f(xi∣θ))2)−log(σw2π)−2σw2w2}
이제 contant를 제거하면. W=argmaxw{−i=1∑N((ti−f(xi∣θ))2)−2σw2w2} 이므로 Loss={i=1∑N((ti−f(xi∣θ))2)+2σw2w2} 가 됩니다.
따라서 MAP에 의해 posterior를 최대화 하는 것은 위의 Loss를 최소화 하는 것과 같습니다.
한번더 왜 y를 R.V로 보는지 매우 직관적으로 설명해 보겠습니다.
일단 고정관념 하나를 깨 부셔야 합니다.
보통 input이 model로 들어가서 target이랑 비슷하게 되는 모수를 찾자 가 ML또는 DL의 개념입니다. 근데 이 관념을 분포를 추정한다는 것으로 볼 수 있습니다.
즉, output이 어떠한 분포를 따른다고 생각하고 이 분포를 target의 분포와 같게 학습 시키겠다로 해석할 수 있습니다. 그러면 말도 안되지만 target이 정확히 하나의 class만을 같는 즉, 모분산이 0인 분포라고 생각할 수 있고 결국 모평균만 추정하면 됩니다. 그니까 target을 분포로 볼 수 있는 것이고 우리가 추정하는 model의 parameter는 target의 distribution과 최대한 비슷한 distribution을 만들어 주는 parameter라고 생각하면 됩니다.
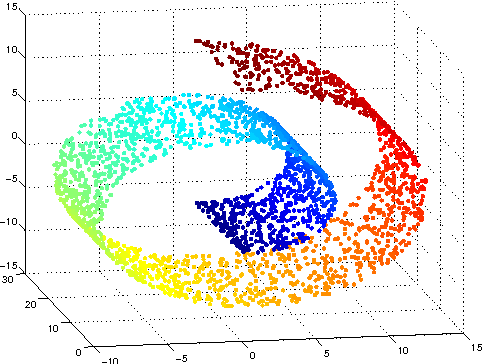
5. Manifold Learning
Two assumptions.
Natural data in high dimensional spaces concentrates close to lower dimensional manifolds.
Probability density decreases very rapidly when moving away from the supporting manifold.
쉽게 생각하면 예를들어 100×100×3의 세상의 모든 사진이 해당 차원의 공간에 고르게 분포한다고 가정하는 것은 틀렸습니다.
이는 쉽게 틀린것을 알 수 있는데 random하게 plot하면 그냥 noise처럼 보일겁니다.
즉, 우리는 100×100×3차원의 공간상에서 실제로 존재하는 사진들은 어딘가에 high density로 있을 것이고 그것이 class별로 더욱 그러하며 같은 class라면 비슷한 곳에 존재한다고 쉽게 생각 할 수 있습니다.
따라서 Manifold를 잘 찾아야 sampling했을때 원하는 결과를 얻을 수 있습니다.
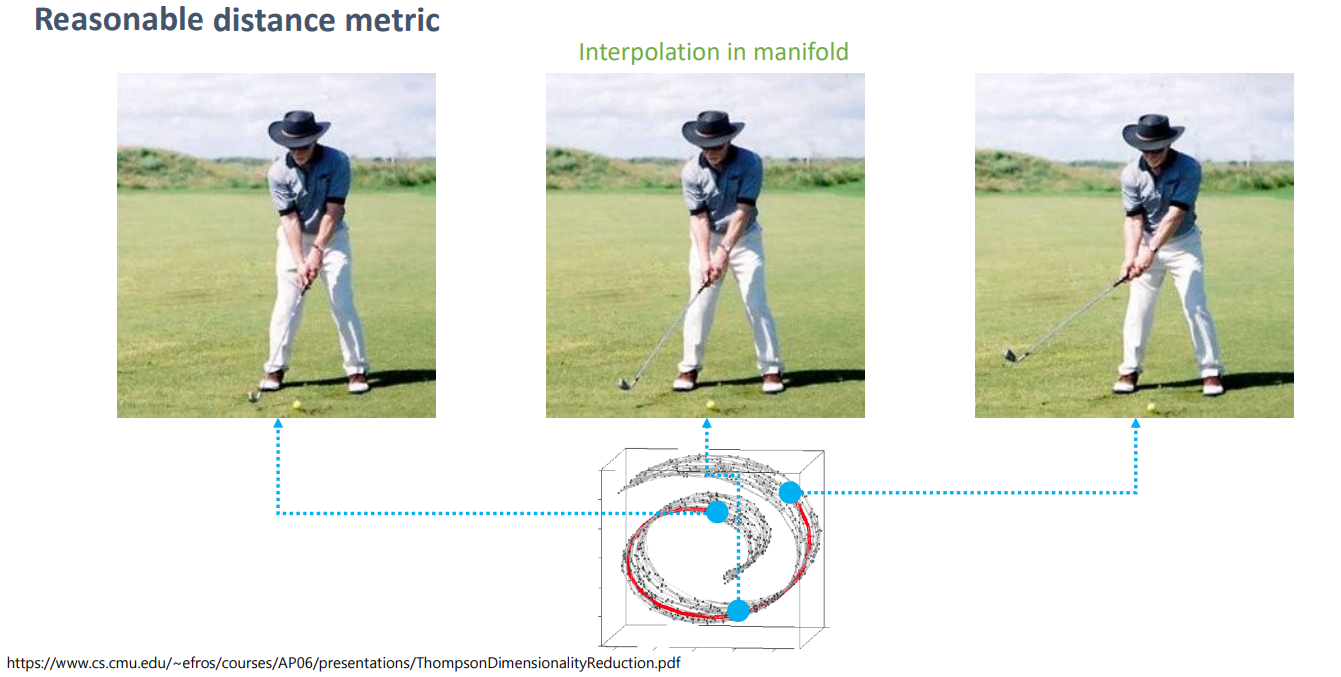
아래 예를 보겠습니다.
즉, 위사진은 경우 pixel-wise로 양쪽의 사진을 합치면 내가 원하는 manifold상이 아니므로 원하는 이미지가 나오지 않습니다.
우리가 원하는 manifold는 저 스윙이 시간순서로 있는 사진인 것이고 그러만 manifold를 찾는 것은 중요합니다.
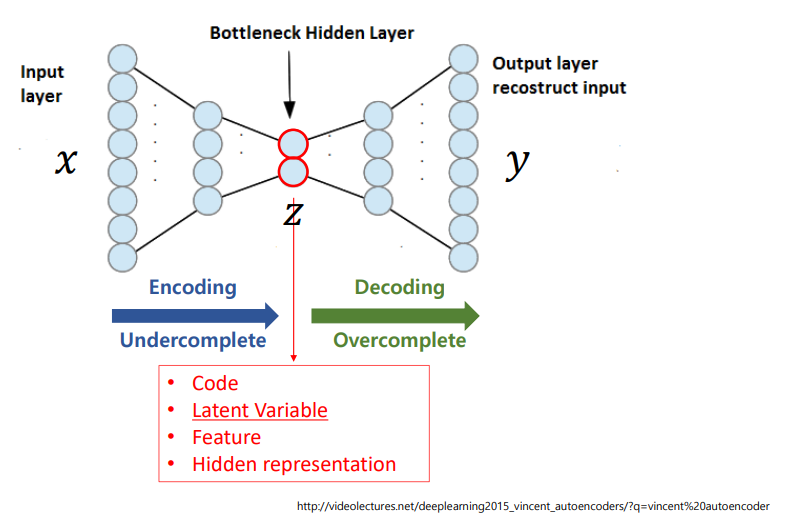
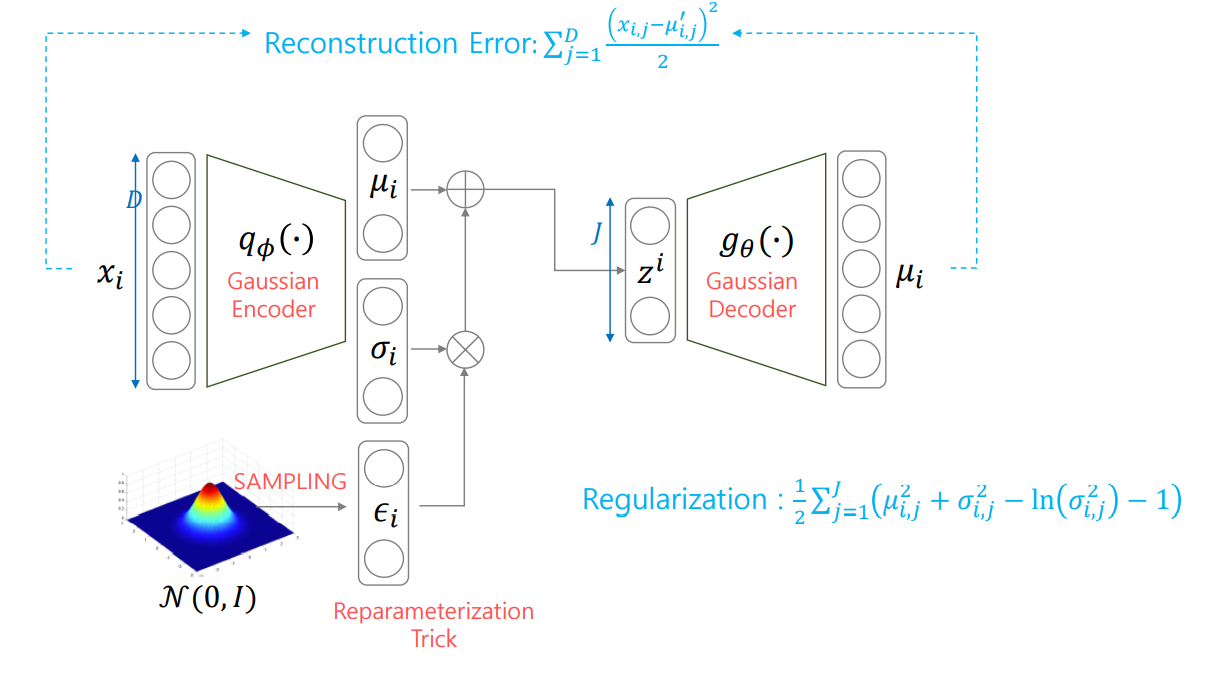
6. Auto Encoder
이때 x->z만 있으면 unsupervised입니다. target이 없기 때문이죠. 근데 x->z->y를 보면 supervised로 바뀝니다.
z는 x를 잘 압축한 latent vector가 됩니다. 이는 위에서 말한 manifold라고 봐도 됩니다.
위의 사진이 가장 기본이고 이게 다 입니다.
7. Variation Auto Encdoer
AE는 목적이 minifold learning입니다.
즉, Encoder를 supervised로 학습하기 위해 decoder가 붙었다면
VAE는 반대로 generation이 목적이고 따라서 Decoder를 학습하기 위해 encoder가 붙습니다.
둘은 완전히 다르지만 architecture가 같습니다.
자 이제 설명해 봅시다.
큰 흐름은 다음과 같습니다.
위 그림이 Generator이고 z를 generator를 지나게 하여 x를 만들고 싶습니다.
즉, 하나의 관점을 추가하자면 generative model이므로 우리가 진짜 궁금한 것은 실제 data x가 어떠한 분포를 갖냐 입니다. 즉, 고차원 상에서 어떠한 manifold를 찾고 잘 찾았다면 그 manifold에서 sampling하면 data에 없지만 실제 있을법한 image들이 generate될 것입니다.
따라서 우리는 가능도 함수 P(x∣gθ(z))를 최대화 해야합니다.
이때 한가지 생각할 수 있는 사실이 있는데 앞의 manifold부분에서 latent는 완전 random이 아니고 특정 부분에 모여있는 즉, manifold가 있는 것을 직관적으로 이해했습니다.
즉, latent z를 특정 한 부분에 집중시켜야 하는데 random이므로 이것이 문제가 될수도 있다고 생각할 수 있는데 이는 Generator의 low-level layer에서 알아서 manifold 찾아주므로 문제되지 않습니다.
7.1 Problem
하지만 진짜 문제가 있습니다.
만약 x∣gθ(z)∼N(gθ(z),σ2)이라면
(a)가 x일때 gθ(z)가 (b)일때의 가능도가 (c)일때의 가능도 보다 높습니다.
즉, (c)는 단순한 shift인데 (b)가 나오도록 학습됩니다.
( 왜 (b)가 더 높은지는 직관적으로 확인 가능한데 gaussian이므로 MSE이고 이를 poxel-wise로 보면 됩니다. )
일단 직관적으로는 해석이 되었습니다.
이제 여기서 정확히 어디가 문제인지 보겠습니다.
앞에서 z 역시 R.V라고 했습니다.
따라서 By Monte Carlo method p(x)=i∑p(x∣gθ(zi))p(zi)입니다.
즉, 이제 가능도를 p(x∣gθ(z))라고 쓰겠습니다. 그리고 log(p(x∣gθ(z)))를 최대화 하는 θ 찾는 것이 목표 입니다.
(앞과 동일)
여기서 prior인 p(zi)가 문제 입니다. 즉, 결론은 latent가 잘 되어야 한다.
쉽게 말하면 z를 그냥 N(0,1)했더니 잘 안된다. 그러면 어떤 분포를 줘야 하는가 입니다.
따라서 이 latent를 잘 sampling하기 위해 VAE가 나옵니다.
7.2 Sampling method
학습된 model이 있다면 z가 따르는 분포를 이용하여 z를 사용하여 generator에 넣고 image를 generate할 것이므로 sampling이라고 합니다.
앞에서 보았듯 이 sampling이 중요합니다. 즉, x의 가능도를 높여주는 z의 distribution을 찾아야 합니다.
아마 z는 상당히 복잡한 pdf를 가질 것입니다. 하지만 실제로 sampling 해야 하므로 이는 gaussian으로 가정하겠습니다.
이때 z의 distribution을 찾을때 사용하는 방법이 Variation inference입니다.
7.3 Variational Inference
z∼ϕ라고 하겠습니다. 이때 ϕ=(μ,σ)입니다. 즉 z∼N(μ,σ) 라고 하겠습니다.
당연히 이 이상적인 distribution은 gaussian은 아닙니다.
하지만 계산을 위해 gaussian을 가정하고 KL divergence를 이용하면 됩니다.
KL divergence란 쉽게 이해하자면 두 distribution간의 거리라고 해석 가능합니다. KL(p∣∣q)=−∫p(x)logp(x)q(x) 이고 이는 weight sum으로 해석 가능하며 p(x)가 높은 곳에서는 q(x)도 높아야 한다로 해석 가능합니다.
즉, x를 잘 나오게 하는 이상적인 우리가 모르는 복잡한 sampling function을 p(z∣x)라고 하겠습니다. 즉, x를 보여주고 이걸 잘 만들어 주는 z는 어떤 분포일까 라는 의미입니다.
p(z∣x)을 모르니 variational inference를 사용하여 qϕ(z∣x)를 대신 사용하여 z를 sampling합니다.
즉, 정리하자면 이상적인 gaussian qϕ(z∣x)를 KL divergence를 이용하여 p(z∣x)와 가깝게 만들어 주고 qϕ(z∣x)에서 sampling 하겠다 입니다. 즉, KL divergence를 minimize하는 ϕ를 찾으면 됩니다.
그럼 이제 두가지를 생각할 수 있습니다.
첫번째는 log(p(x∣gθ(z)))를 최대화 하는 θ를 찾기
두번째는 KL−Divergence를 최소화 하는 ϕ 찾기
그래서 다음과 같은 object function이 자연스럽고 AE와 같은 architecture를 갖는 다는 것 역시 직관적입니다.
근데 이건 직관적으로 loss를 유도한것일 뿐 입니다.
예를들어 KL에 weight가 5가 걸릴수도 있습니다. 직관적으로 KL과 ML이 같은 weight를 갖는다는 것은 알 수 가 없습니다. 그래서 앞에서 ML은 곧 MSE와 CEE다를 유도한것 처럼 수식의 유도가 필요 합니다.
조금 더 논리적으로 접근해 봅시다.
다시 처음으로 돌아간다면 어째든 우리가 원하는 것은 p(x∣gθ(zi)을 ML에 입각하여 최대화 시키는 θ를 찾는 것입니다.
하지만 문제가 있었죠. 그래서 qϕ(z∣x)라는 것을 도입하기로 했습니다.
딱 여기까지만 사용해야 합니다. 다시 말하면 qϕ(z∣x)을 사용하는데 KL을 사용하는것 조차 직관입니다. 이는 유도되어야 합니다.
7.4 Induction
가능도 함수 p(x)를 이상적인 분포 p(z∣x)와 이를 gaussian으로 근사하여 대신할 qϕ(z∣x)으로 분리하면 됩니다.
(강의에서는 관계를 본다고 하는데 같은 말입니다.)
다시 처음으로 돌아가보면 우리는 두가지에 대한 optimization이 필요합니다.
첫번째는 log(p(x∣gθ(z)))를 maximize하는 것이고
두번째는 KL(qϕ(z∣x)∣∣p(z∣x))을 minimize하는 것입니다.
여기서 KL(qϕ(z∣x)∣∣p(z∣x))을 minimize하는 것은 ELBO(ϕ)의 maximize이고 이는 Eqϕ(z∣x)(log(p(x∣z)))−KL(qϕ(z∣x)∣∣p(z)) 의 maximize입니다.
그런데 Eqϕ(z∣x)(log(p(x∣z)))−KL(qϕ(z∣x)∣∣p(z))에서 Eqϕ(z∣x)(log(p(x∣z)))는 결국 가능도 함수이고 따라서 다시 KL을 minimize하는데 가능도 함수를 최대화 한다는 term이 따라 옵니다.
여기서 notation이 또한번 헷갈립니다. p(x∣z)가 왜 갑자기 가능도 함수라고 할까요?
정확히는 p(x∣z)이 가능도가 아니라 p(x∣z)의 expectation이 가능도 입니다.
앞에서 몬테카를로 방법을 사용하여 가능도 함수 p(x)를 i∑p(x∣gθ(zi))p(zi)으로 근사했습니다.
그리고 여기서 monotone function인 log를 사용하면 i∑logp(x∣gθ(zi))p(zi)를 maximize하는 것입니다.
또한 Eqϕ(z∣x)(log(p(x∣z)))는 z에서 sampling한것들의 기댓값이다 라는 의미이므로 둘이 같은 식입니다.
최종적으로 정리해봅시다.
우리가 원하는 것은 가능도 함수 log(p(x∣gθ(z))의 maximize입니다.
하지만 몬테카를로 방법에 의해 p(x)=i∑p(x∣gθ(zi))p(zi)을 계산하여 maximize하면 우리가 원하는 결과가 안나오는데 이는 sampling distribution인 p(z)가 문제가 됩니다.
이때 우리는 우리가 원하는 결과가 잘 나오게 해주는 sampling distribution인 p(z∣x)를 가정할 수 있습니다.
하지만 이를 찾는것은 매우 어렵죠. 또한 계산도 복잡합니다.
그래서 우리는 이 이상적인 distribution와 가장 비슷하며 gaussian인 distribution을 대신 사용할 겁니다.
그리고 비슷하다는 metrix으로는 LK Divergence를 사용합니다.
그러면 이제 두가지의 optimization 문제로 바뀌었습니다.
첫번째는 θ를 찾는 것이고 두번째는 ϕ를 찾는 것입니다. ϕ를 KL의 minimize로 찾아보겠습니다. log(p(x))=∫log(qϕ(z∣x)p(z,x))qϕ(z∣x)dz+∫log(p(x∣z)qϕ(z∣x))qϕ(z∣x)dz =ELBO(ϕ)+KL(qϕ(z∣x)∣∣p(z∣x)) 이므로 KL을 minimize하는 것은 ELBO(ϕ)를 maximize하는 것이고 ELBO(ϕ)=Eqϕ(z∣x)(log(p(x∣z)))−KL(qϕ(z∣x)∣∣p(z)) 이므로
첫번째 optimization인 가능도 함수의 maximize가 따라 나옵니다.
따라서 우리는 ELBO(ϕ)에 대해 ϕ와 θ를 모두 maximize하는 task를 생각하면 두개의 optimization이 한번에 해결 됩니다.
여기서 ϕ를 찾는다는 것은 μ,σ를 찾는 것입니다.
즉, 이를 한번에 표현한다면 다음과 같습니다.
Object Function argmin(θ,ϕ)i∑(−Eqϕ(z∣xi)(log(p(xi∣gθ(z))))+KL(qϕ(z∣xi)∣∣p(z))) 이 됩니다.
이렇게 하다 보니 AE의 architecture를 그대로 따르게 된다 입니다.
여기서 ϕ에 대한 계산은 sampling함수를 찾는 것이고 θ의 계산은 ML입니다.
이를 베이지안으로 해석할 수 있습니다. qϕ(z∣x)과 p(z∣x)는 x를 보여준 상태에서의 z의 분포라고 해석했습니다.
즉, 이는 Prior p(z)와 Evidence p(x)를 이용한 Posterior가 됩니다.
이는 다시 처음으로 돌아가서 해석하자면, p(z) 가 문제였으니 이를 Prior로 보고 x를 Evidence즉, Observation으로 주어 Posterior p(z∣x)을 사용할 것이고 이를 간단하게 만들어 주면 좋으니 qϕ(z∣x)을 근사해서 posterior로 사용하겠다는 의미입니다.
이를 식으로 쓰면 qϕ(z∣x)≈p(z∣x)=p(x)p(z)p(x∣z)이고 p(z)는 x를 만들기 위한 z의 distribution입니다.
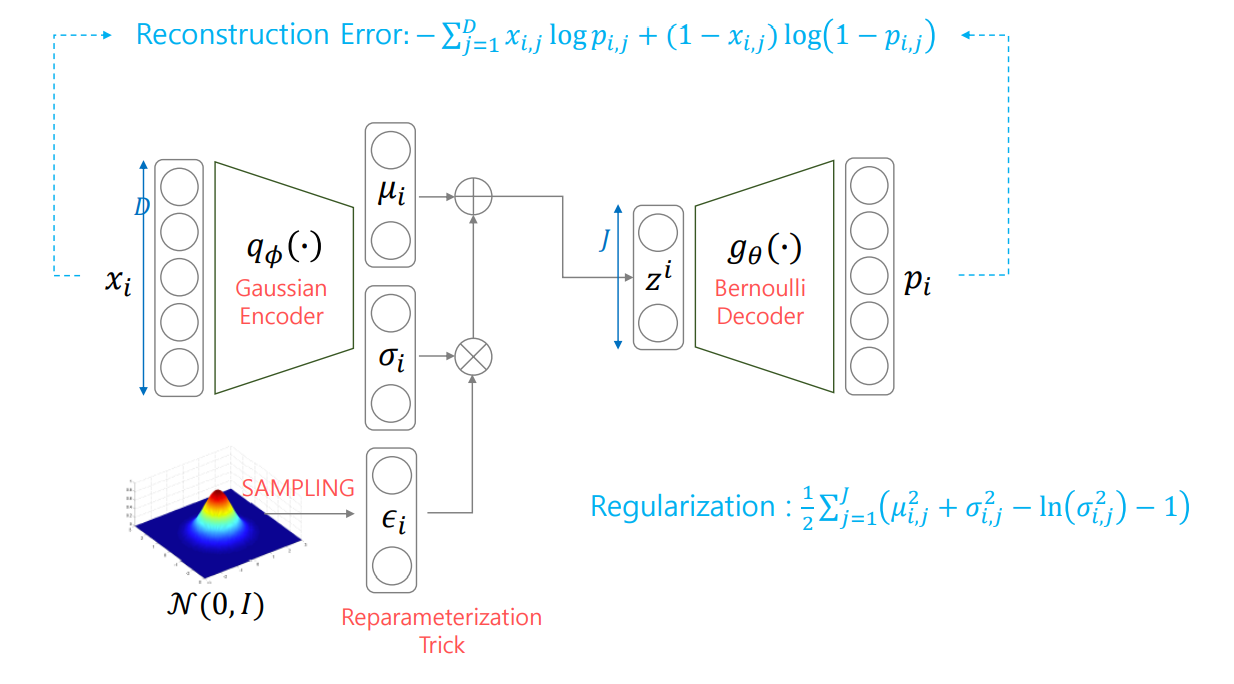
그런데 여기서 p(z)는 z∼N(0,I)라고 제한합니다.
또한 앞에서도 언급했지만 qϕ(z∣xi)∼N(μi,σi2) 라고 제한합니다.
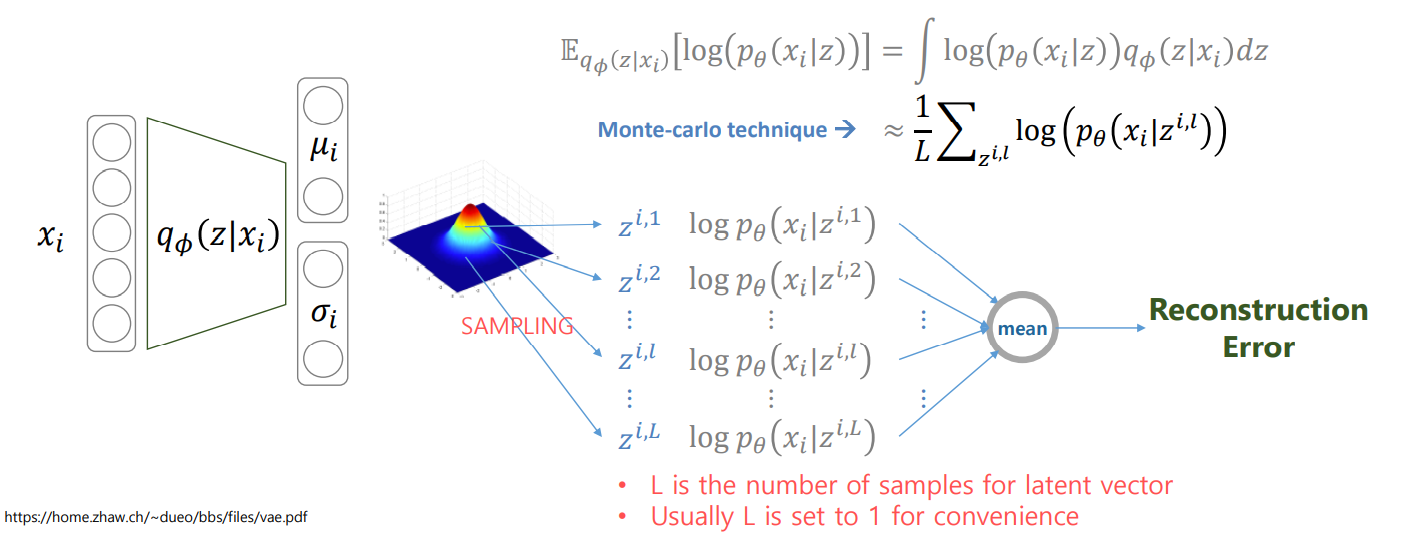
이제 ML부분을 보겠습니다. Eqϕ(z∣xi)(log(p(xi∣gθ(z))))=∫log(pθ(xi∣z))qθ(z∣xi)dz 이고 모테카를로 근사를 하면 ≈L1zi,l∑log(pθ(x∣zi,l)) 입니다.
즉, 이는 KL-term에서 μi,σi가 추정 되었고 이는 즉, sampling함수를 뜻하고 그 함수에서 표본추출한다는 의미입니다.
여기서 문제가 생깁니다. μi,σi는 우리가 추정해야할 parameter이고 따라서 backpropagation을 수행해야 하는데 random node이므로 불가능 합니다.
따라서 Reparameterization Trick을 사용합니다.
이때 다시 L1zi,l∑log(pθ(x∣zi,l))를 보겠습니다.
이는 추정된 μi,σi으로 부터의 sampling인데 대부분 하나만 sampling 합니다.
즉, ≈log(pθ(xi∣zi))입니다.
7.5 Conclusion
드디어 나왔습니다.
앞에서 gaussian이면 MSE, bernoulli이면 CEE라고 보였던 부분입니다.
그럼 이제 3가지 case가 나옵니다.
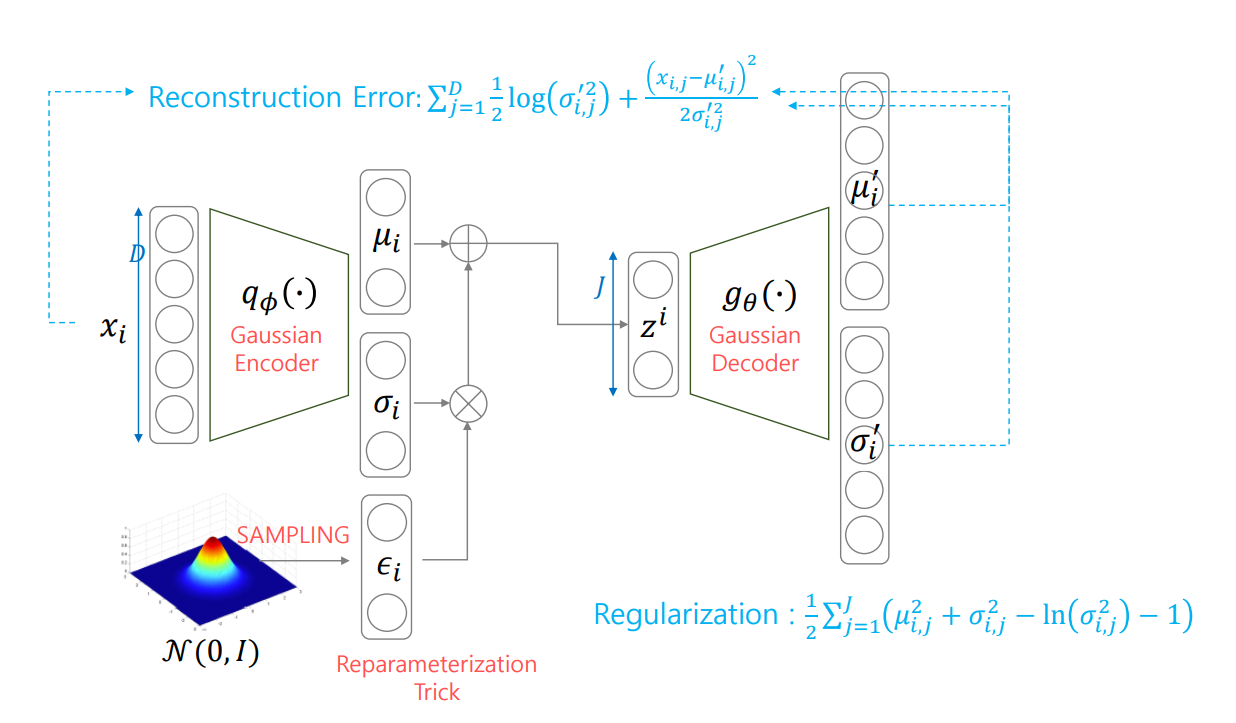
1. Gaussian인데 μi,σi을 둘다 추정하면 log(pθ(xi∣zi))=−j=1∑D(21log(σi,j2)+2σi,j2(xi,j−μi,j)2)
2. Gaussian인데 μi만 추정하면 log(pθ(xi∣zi))∝−j=1∑D(xi,j−μi,j)2
3. Bernoulli이면 log(pθ(xi∣zi))=j=1∑Dxi,jlogpi,j+(1−xi,j)log(1−pi,j)
위 그림이 직관적으로 이해가기가 좋습니다.
위 그림을 보고 다시 한번 의미를 생각해 보면 다음과 같은 생각을 얻을수 있습니다.
단순한 램덤으로 latent를 만들면 안좋으니 target을 보여줄거다. 그러면 target 보고 다시 latent를 만들어 봐라. 그런데 그냥 막연하게 만들어라 하면 힘들테니 gaussian인것 까지는 알려줄께 그러면 target을 보고 gaussian의 모평균과 모분산 정도는 학습이 잘되는 방향으로 만들어 봐라 입니다.
AE랑 KL빼고 완전 같습니다.
근데 VAE는 학습이 끝나면 결국 prior p(z)가 이상적인p(z∣x)랑 같아집니다.
그러므로 새로운 generate를 할때 그냥 p(z)에서 sampling하면 되는거고 이걸 앞에서 N(0,I)로 제한했습니다. 따라서 새로운 image를 만들때 latent vector를 쉽게 만들 수 있습니다.
또한 학습된 generator는 prior를 잘 해석한다고 이해할 수 있습니다.
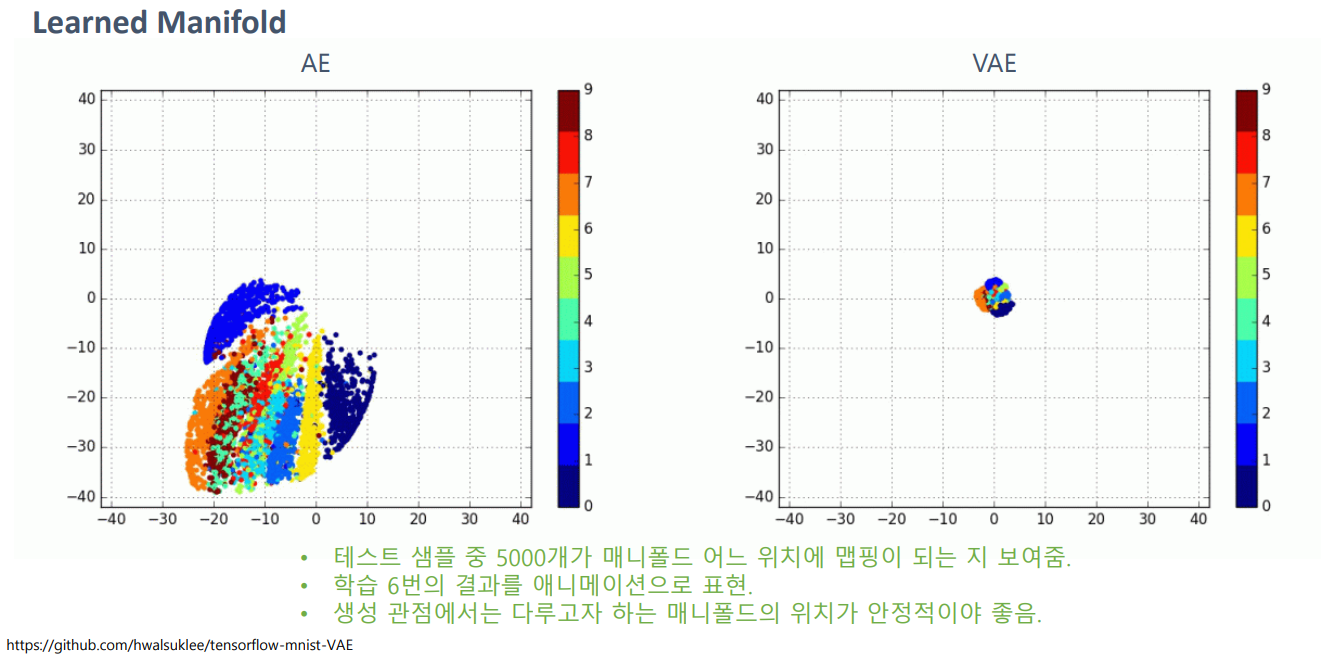
가장 결정적인 차이는 다음과 같습니다.
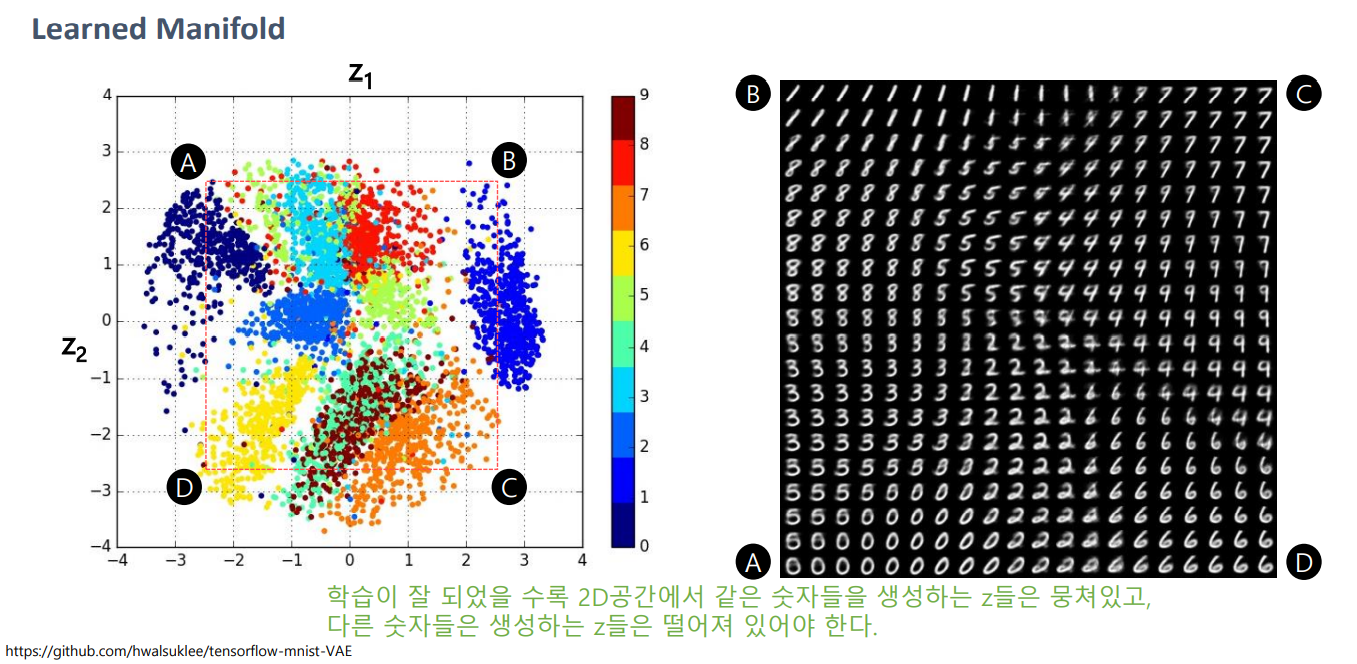
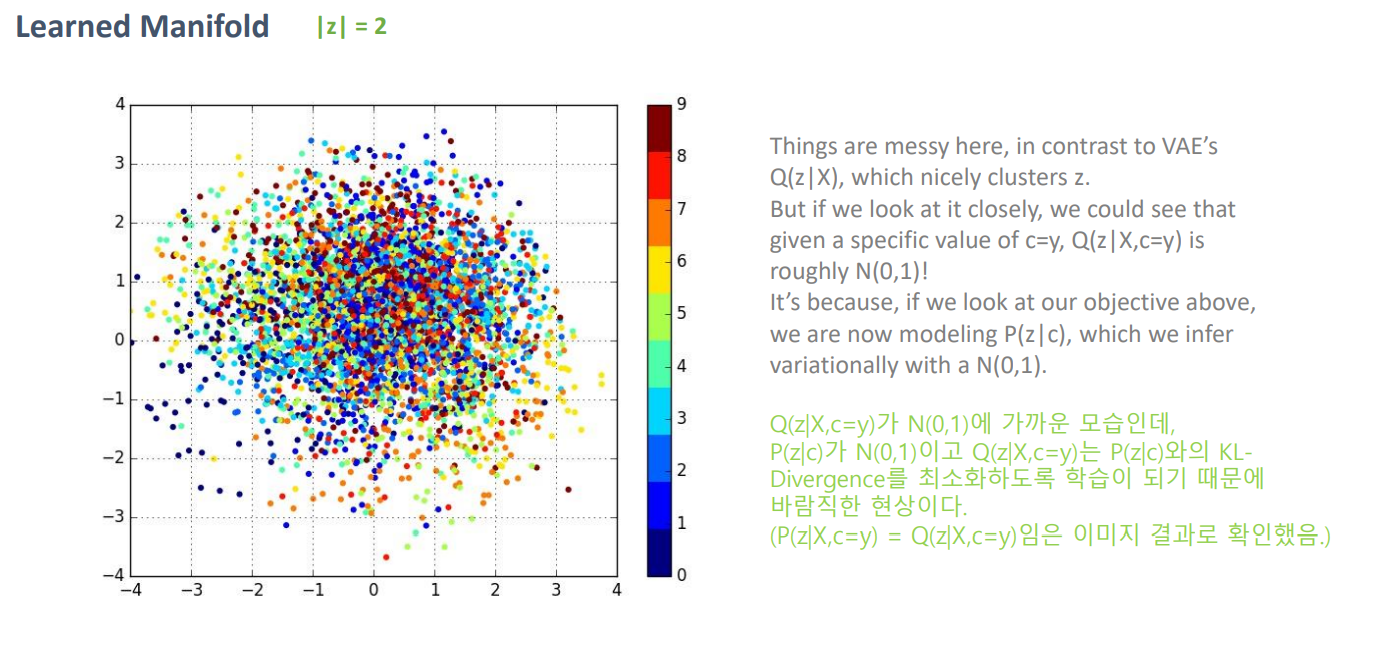
위 그림은 latent vector 즉, manifold를 시각화 한것입니다.
AE를 해석해보면 학습된 AE는 Encoder에서 만들어 지는 manifold가 일정하지 않습니다. 즉, 같은 image dataset이여도 manifold가 달라지는 것입니다.
이와는 다르게 VAE는 manifold를 N(0,I)로 제한되게 학습됩니다. 이게 KL의 역할이죠.
즉, 학습된 VAE으니 Encoder는 manifold를 우리가 알기 쉬운 N(0,I)으로 mapping해주는 역할을 합니다. 이를 위의 object function에서 보자면 μi,σi가 각각 0과 I가 되게끔 학습 된다는 것입니다. 따라서 Generator의 range가 상대적으로 쉬워지며 새로운 image를 generate할때 manifold를 찾는 것이 중요한데 그 manifold를 우리가 미리 정한 Gaussian으로 되게끔 학습 한다는 의미입니다.
따라서 결과는 다음과 같습니다.
Q : 앞에서 (a, b, c)예제에서 (c)로 나와야 하는데 z가 문제였고 그래서 위와 같이 KL-term이 나왔다고 했습니다. 그럼 진짜 KL만 추가했더니 (b)가 나오는대신 (c)가 나오게 학습되나요? 그걸 어떻게 해석할 수 있나요?
엄청 좋은 질문이라고 생각합니다.
우선 답은 맞습니다. 근데 왜 (c)가 나올까요? 이건 manifold로 해석하면 됩니다. KL-term을 추가한다는 것은 바로 위 그림에서 알 수 있듯 manifold를 원하는 모양으로 할 수 있다는 의미이며 또한 올바른 manifold가 잡힌다는 의미입니다. 그리고 올바른 manifold가 잡혔다면 앞선 골프 사진처럼 pixel-wise mean이 아닌 manifold상에서 generate되기 때문에 (b)대신 (c)가 나오는 겁니다.
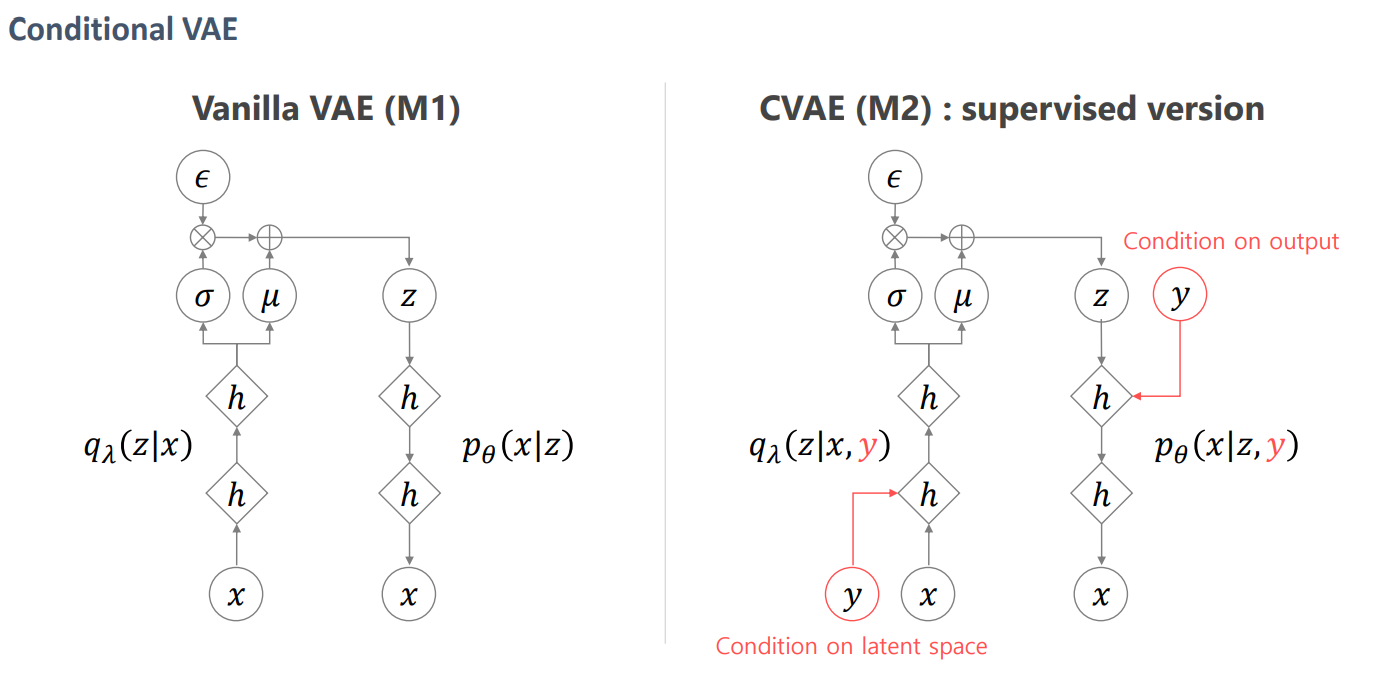
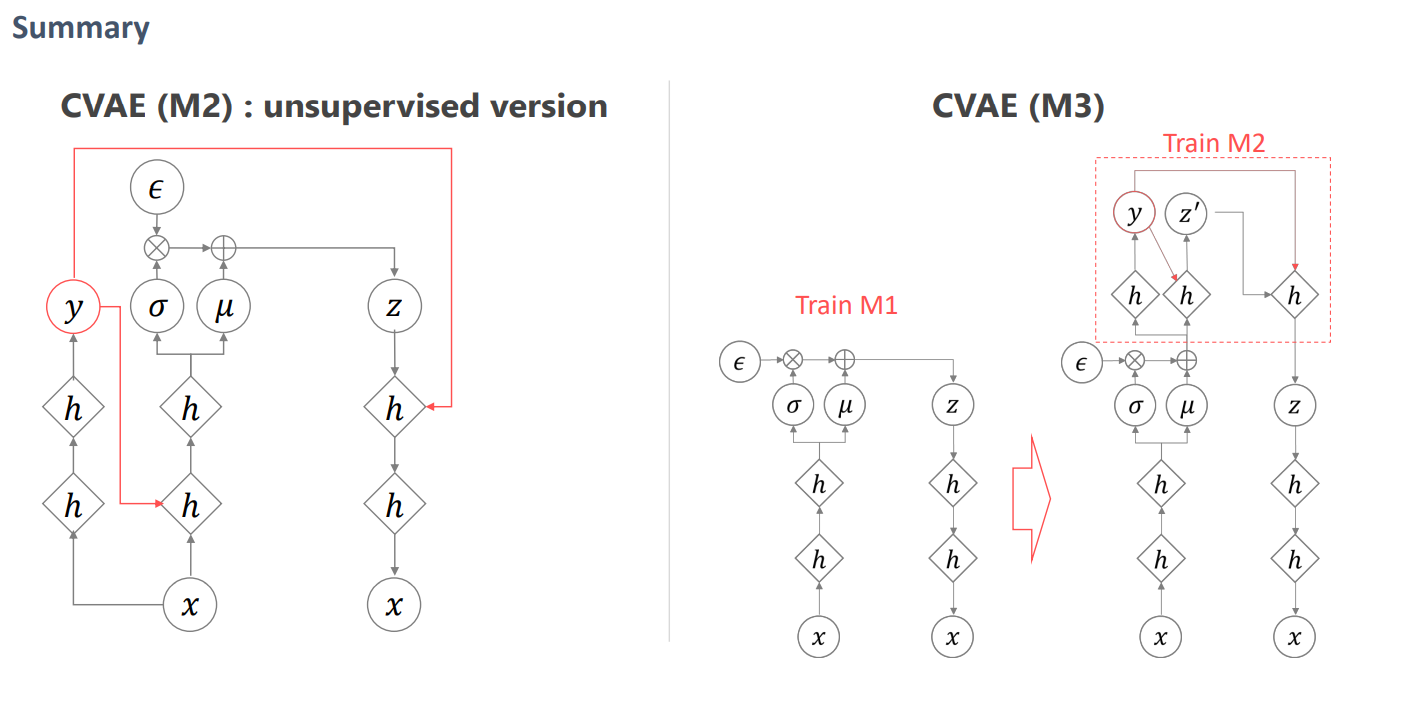
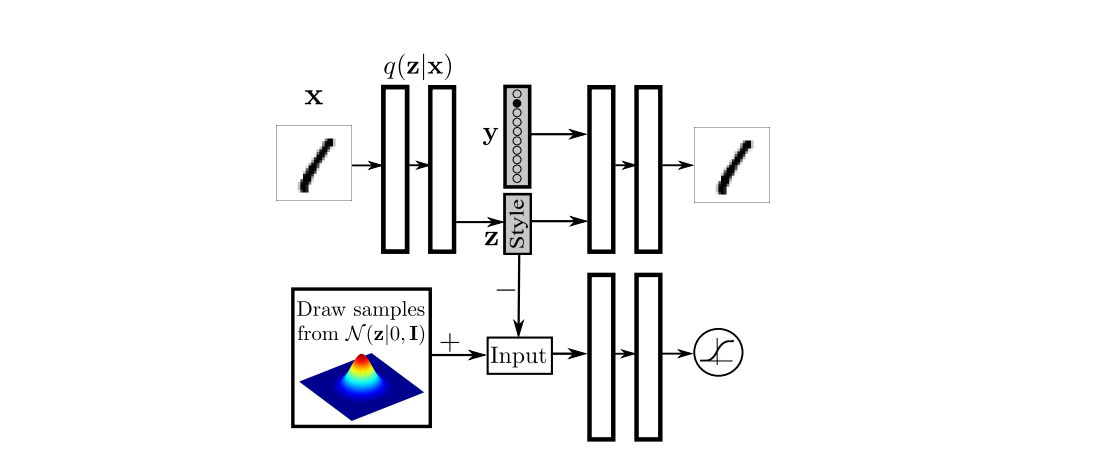
7.6 CVAE
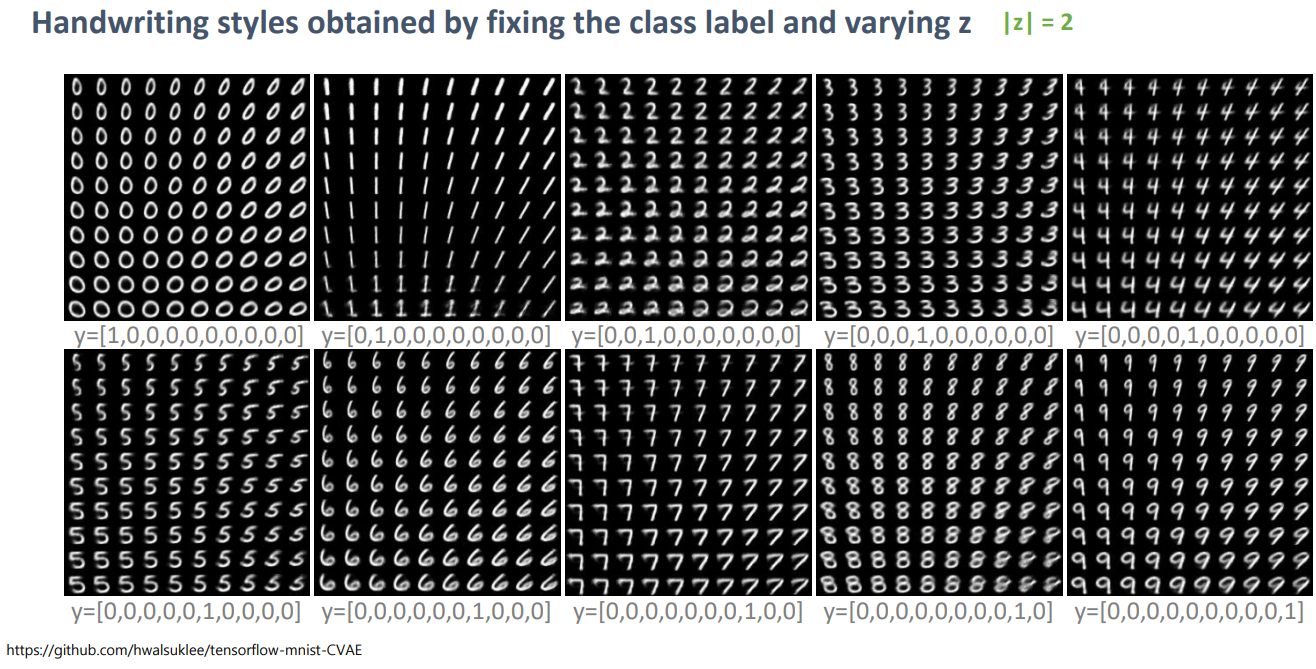
condition을 조정한 상태에서 z를 다르게 했을 때
직접 쓴 글씨를 Encoder에 넣어 z를 얻고 condition을 다르게 하면 z는 style만을 갖는다.
VAE라면 망한 결과 이지만 CVAE라면 오히려 같은 style를 잘 묶은 것이므로 잘되었다고 해석 가능합니다.
즉, condition은 숫자 z는 style이라고 해석하면 됩니다.
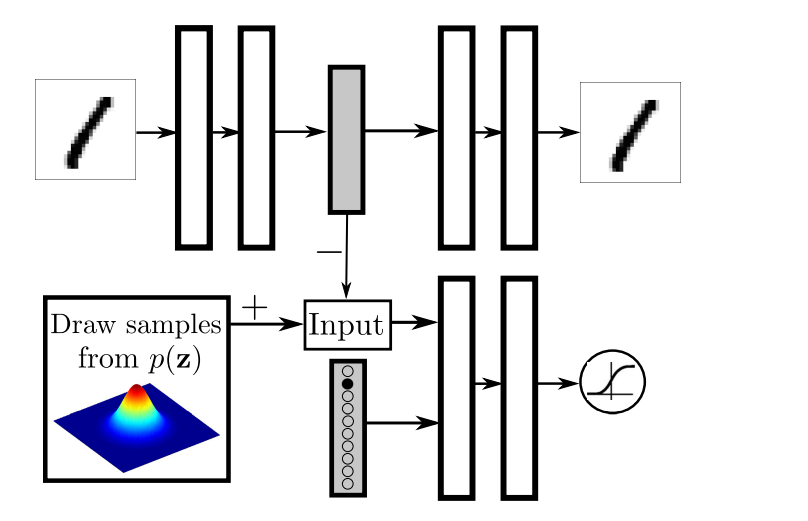
8. Adversarial Autoencoder
AE에서 KL-term을 추가하면 VAE가 되고 ML관점에서 x의 분포를 추정하는것이 되는데 이때 x를 Bernoulli로 하여 p를 추정할지 또는 Gaussian으로 하여 μ 또는 μ,θ를 추정할지에 따라 세가지의 Loss function이 나왔습니다. 그리고 이 세가지 에서 KL은 모두 두 gaussian의 계산으로 공통이었습니다.
이유는 두 Gaussian의 KL이 쉽기때문이고 따라서 여기에는 제한을 주었습니다.
즉, Decoder는 바꾸었지만 Encoder를 바꿀수 없었고 이를 바꾼것이 AAE입니다.
다시 Loss function을 보겠습니다. −Eqϕ(z∣xi)(log(p(xi∣gθ(z))))+KL(qϕ(z∣xi)∣∣p(z))
여기서 오른쪽 KL이 문제가 되므로 이를 다른것으로 대신 계산할 겁니다.
그리고 KL을 해석해보면 qϕ(z∣xi)와 p(z)를 같게 만들어 준다는 의미이고 이는 GAN과 같습니다.
여기서 헷갈리는게 하나 더 나옵니다. KL(qϕ(z∣xi)∣∣p(z))과 KL(qϕ(z∣xi)∣∣p(z∣x))의 차이를 분명하게 하고 갈 필요가 있습니다.
다시 돌아가보면 후자를 minimize하기 위해 수식을 전개해보면 전자를 minimize한다는 의미가 나왔습니다.
그리고 qϕ(z∣xi)은 x를 evidence로 주었을 때 이상적인 분포이 p(z∣x)를 근사시킨 분포이고 p(z)는 x를 evidence로 주지 않았을때 z의 분포 입니다.
이는 앞에서 N(0,I)라고 제한했었죠.
즉, 전자는 실제 우리가 학습이 끝난뒤 sampling할 z의 분포와의 거리가 되고 후자는 이상적으로 x를 보여주었을 때의 z와의 거리가 됩니다.
그래서 둘의 차이가 있는겁니다.
또한 앞선 결론을 다시 상기해보면 최종 loss의 식을 보면 전자가 있는 것이고 이때 p(z)를 평균이 0 분산이 1 인 쉬운 gaussian을 제한해버리면 결국 Encoder의 output distribution인 qϕ(z∣x)가 해당 gaussian을 따르게 되는 것이므로 우리는 쉬운 manifold를 얻었다고 생각할 수 있습니다.
근데 이 부분이 사실 GAN이 학습하는 방법입니다.
즉, Gaussian이 아니면 KL을 사용하기 어려운데 사실 KL이 GAN의 loss와 같고 GAN은 gaussian가정이 굳이 필요 없으므로 GAN으로 대체하면 Gaussian일 필요가 없다 입니다.
8.1 GAN
GAN을 먼저 보고가겠습니다.
위에서와 마찬가지로 model이 학습 되다는 의미를 target distribution과 최대한 가까운 distribution을 찾는다 로 해석이 가능합니다.
GAN의 Generator는 Discriminator를 속여야 하니 결국 real image와 같은 Distribution을 만들어 줘야 합니다.
이때 GAN은 Real Image의 Distribution을 만드는데에 Generator를 사용하지만 이를 VAE의 Encoder부분에 사용하여 gaussian이 아닌 다른 prior distribution을 만들 수 있게 학습하려고 사용합니다.
아래서 더 자세하게 설명합니다.
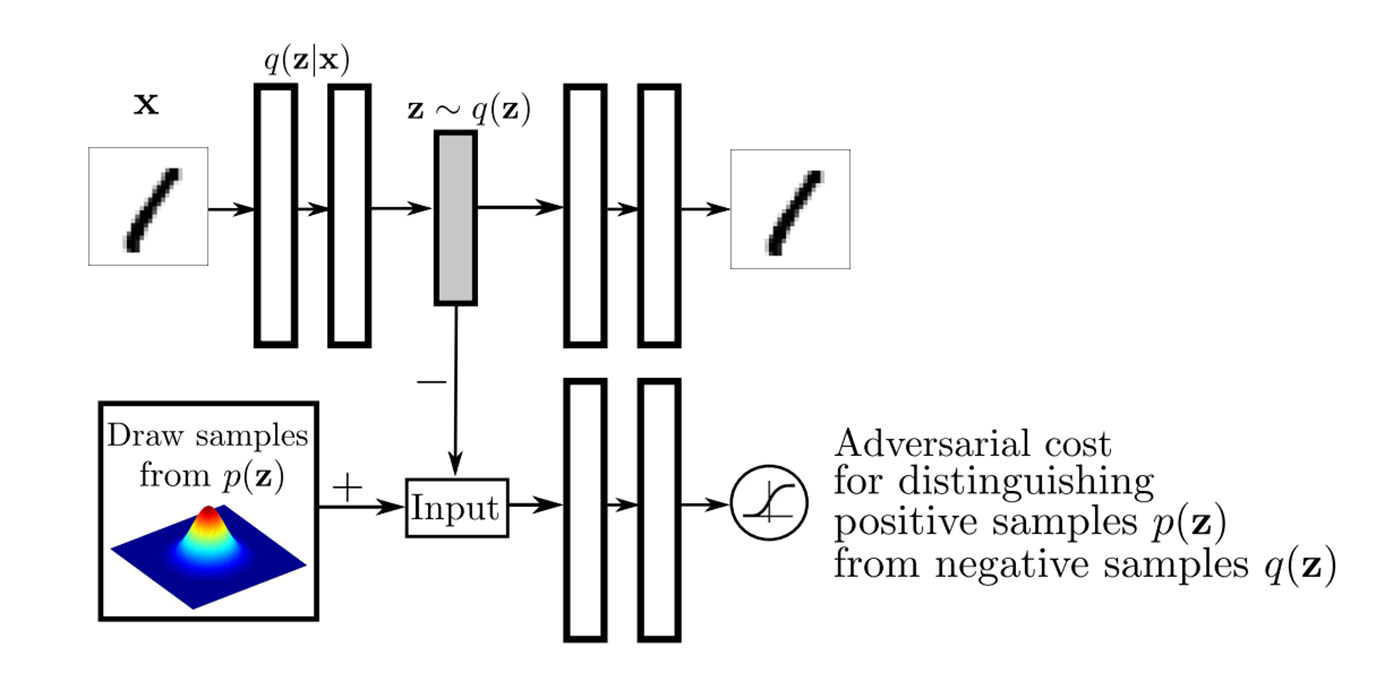
8.2 Adversarial AutoEncoder
위 그림의 AAE입니다.
쉽게 말하면 GAN + AutoEncoder라고 표현 할 수 있고
다르게는 VAE의 KL을 GAN으로 대체한다고 표현 가능합니다.
KL을 다시 생각해 보면 qϕ(z∣x)와 p(z)사이의 거리이고 이는 Gaussian일때만 계산이 쉬우니 제한이 걸려있었죠. 그래서 KL을 다른것으로 대체하겠다는 겁니다.
KL이 두 분포간의 거리이고 이를 낮추게끔 학습하는 것이므로 결국 KL을 사용하지 않으면서 계산이 어렵지 않고 또한 두 분포상의 거리를 줄일 수 있는 방법을 찾아야 합니다.
그 방법이 GAN입니다.
GAN이 목적은 real image distribution과 가까운 분포를 찾는 것이고 그게 generator입니다. 이를 VAE에 적용할때는 image를 만드는 것이 아니라 hidden code vector를 만드는데 사용합니다.
그렇게 되면 정확히 KL이 하는 역할을 대신하게 되죠. 장점은 gaussian제한이 없어진다는 것입니다. 그냥 NN으로 학습하면 됩니다.
그럼 이제 더 자세하게 보겠습니다.
Notations
p(z) : prior q(z∣x) : Encoder의 distribution 이며 posterior로 보면 되겠죠 p(z∣x) : Decoder의 distribution pd(x) : Real data의 distribution p(x) : model의 distribution q(z)=∫xq(z∣x)pd(x)dx : aggregated posterior distribution 그냥 가능한 모든 posterior의 합정도로 생각하면 쉽습니다.
즉, 여기서 q(z)를 우리가 사전에 정의한 p(z)로 가깝게 학습하는것이 됩니다.
그럼 실제 training이 어떻게 되는지도 보겠습니다.
8.3 Training AAE
VAE는 한번에 parameter update가 가능했죠
그런데 GAN이 들어오면서 alternative하게 학습을 해야 합니다.
정리해보면 다음과 같습니다.
q(z∣x)는 x에 대한 determistic function이다.
따라서 q(z)의 확률성은 data distribution pd(x)에만 의존된다.
q(z∣x)는 Gaussian을 따른다. 이때 parameter는 zi∼N(μi(x),σi(x))이다.
이때 q(z)의 확률성은 data distribution pd(x)과 encoder의 output의 gaussian ramdomness를 따릅니다.
Reparameterization trick을 사용해야 합니다.
Encoder를 noise η도 input으로 하는 즉, f(x,η)라고 가정합니다.
그러면 q(z)의 확률성은 data distribution pd(x)과 noise η에 의존합니다. 단 noise는 gaussain정도로 이해하면 됩니다.
따라서 p(z)는 noise η에 대해 한번더 적분해줘야 합니다.
즉, q(z∣x)=∫ηq(z∣x,η)pη(η)dη 이고
따라서 q(z)=∫x∫ηq(z∣x,η)pη(η)pd(x)ηdηdx입니다.
논문에서는 이렇게 세가지 방법을 사용했을때 차이가 거의 없어 그냥 첫번째 방법만 사용하기로 했습니다.
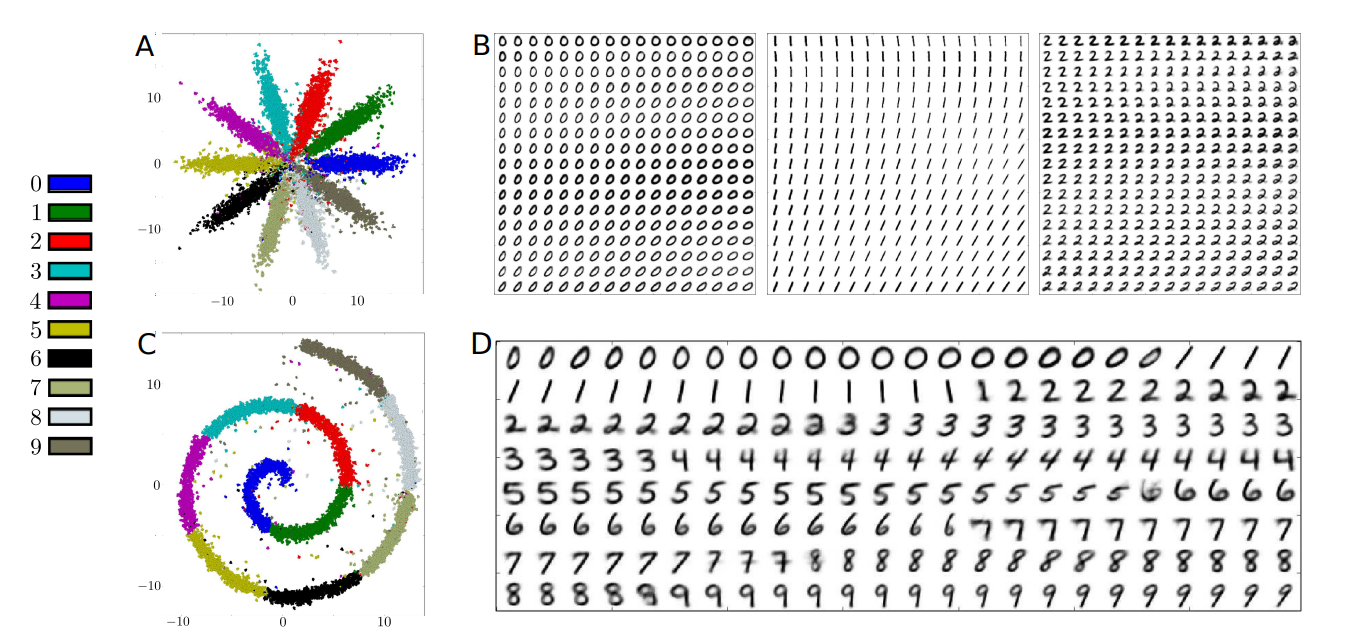
8.5 Results
(A), (C)는 순서대로 AAE와 VAE를 prior를 gaussian으로 했응ㄹ때 manifold입니다.
두 결과 모두 잘된것을 알 수 있으나 AAE가 쫌 더 잘되었다고 생각됩니다.
(A)가 (C)보다 prior에 더 가깝게 만들어진 이유는 GAN Loss를 사용해서라고 생각할 수 있습니다.
둘의 차이는 (B), (D)에서 확실하게 보입니다.
(B)는 prior에 잘 근사된것을 볼 수 있지만 (D)는 잘 안됩니다. 이는 정확히 말하면 KL의 계산이 불가능 하기때문에 KL에서는 그냥 Gaussian을 준 상태입니다.
그래서 ML에 prior가 있기때문에 어느정도의 모양의 나오기는 합니다.
앞에서 CVAE 기억나시나요?
AAE에서 condition으로 label을 줄겁니다.
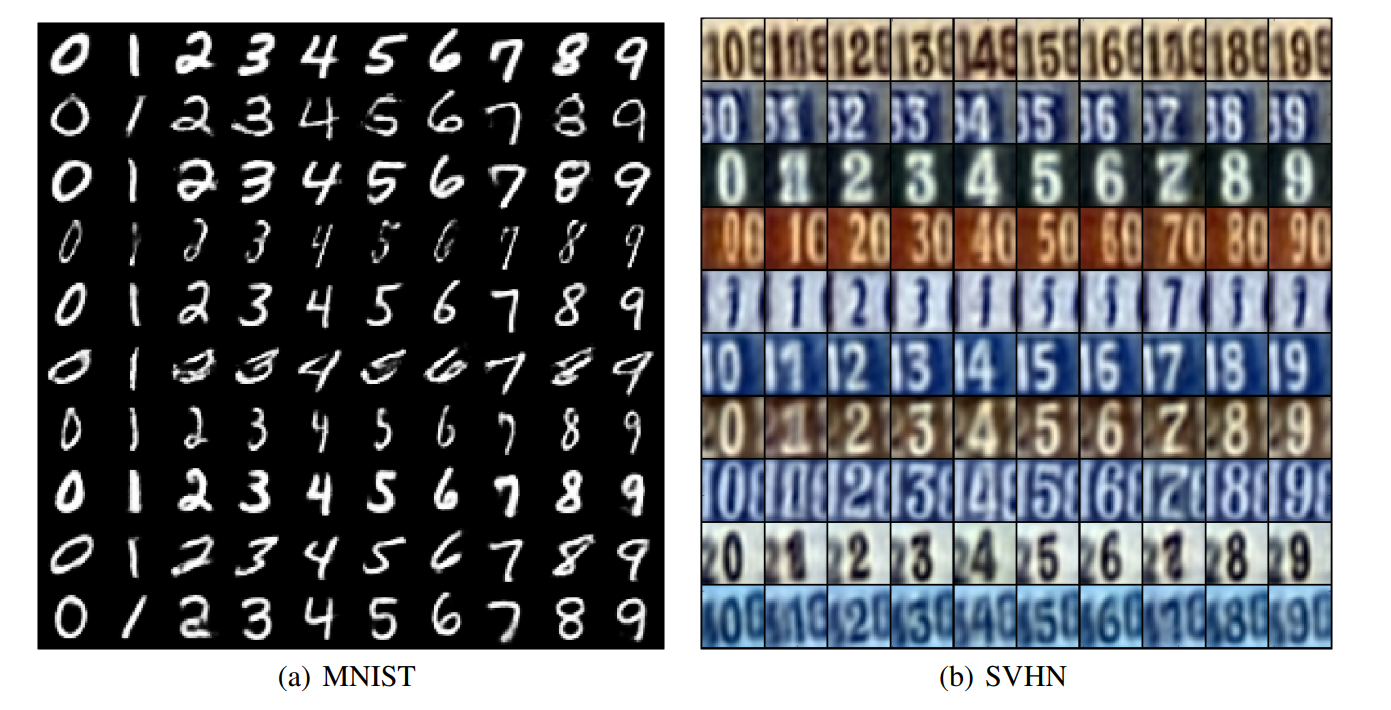
8.6 Incorporating Label Information in AAE
우리는 계속 분포를 추정한다고 생각하고 있죠. 또한 AAE의 장점은 미리 설정한 prior에 manifold를 mapping 할 수 있다는 거죠.
그 관점으로 이를 쉽게 해석할 수 있습니다.
우선 결과부터 보겠습니다.
위 결과를 해석해보면 condition으로 label을 주었을 때 내가 원하는 manifold에 mapping되었다 라고 해석할 수 있습니다. 즉, Mnist의 숫자별로 다른 위치에 mapping한거죠.
다시 위의 구조를 보시면 label을 넣어주는 위치가 discriminatoe바로 앞인데 이 이유가 이해가 되시나요?
예를들어 1을 생성하고 싶다면 1의 image를 evicdence로 넣어주어 encoder에서 manifold를 생성하는데 이걸 우리가 원하는 prior상에 나타나게 만드고 싶다. 그런데 이때 label별로 다른 위치로 보내야 하니 1 image가 들어왔을때는 1로 하고 싶은 manifold만 True라고 판단하고 나머지는 False라고 판단하여 그쪽으로 못가게 학습하라 라는 의미입니다.
즉, 거의 완벽하게 control할 수 있습니다.
8.7 Supervised Adversarial AutoEncoders
이는 Image style information으로 부터 class label information을 분리할 수 있는 구조 입니다.
Label 정보를 합치기 위해 one-hot vector를 Decoder에 보내줍니다.
그러면 z에서는 label정보가 아닌 style의 정보만이 manifold에 mapping되는 거죠.
결과를 보시면 학습이 끝나 Decoder에 z는 고정한 상태에서 label을 바꿔준 결과입니다.
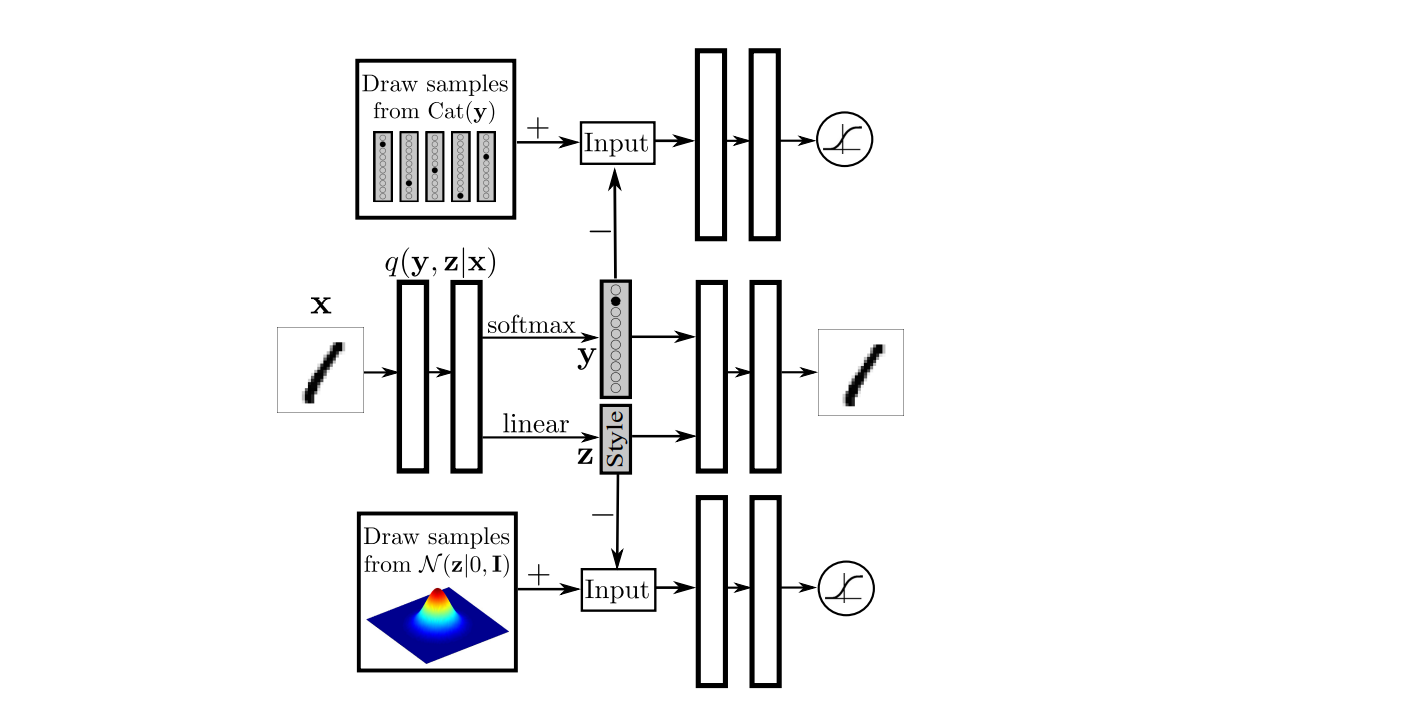
8.8 Semi-Supervised Adversarial AutoEncoders
p(y)=cat(y) y는 label입니다. p(z)=N(z∣o,I) z는 latent 입니다.
그럼 이제 Encoder는 q(z,y∣x) 가 됩니다.
이제 y와 z를 둘다 예측해야 합니다.
즉, 두가지의 adversarial network가 있습니다.
위쪽은 label을 만들고 아래는 style만 가지고 있는 manifold를 생산한다고 볼 수 있습니다.
8.9 Unsupervised Clustering
이는 아예 label이 없는 경우이므로 위의 구조에서 label이 있는 경우의 학습을 제거하면 됩니다.
결과는 위와 같은데, 왼쪽의 숫자를 고정시키고 style z를 변화했을 때 오른쪽의 그림이 나옵니다.