[CS224n] Self- Attention and Transformers
본 lecture에서는 다음과 같은 순서로 진행됩니다.
- From recurrence(RNN) to attention-based NLP models
- Introducing the Transformer model
- Great results with Transformers
- Drawbacks and variants of Transformers
From recurrence(RNN) to attention-based NLP models
Linear interaction distance
먼저 RNN의 model의 구조적 한계점을 지적합니다. 기존 RNN model은 왼쪽에서 오른쪽으로, present time step의 hidden state에서 future time step hidden state으로, 즉 순차적으로 연산이 이루어집니다. RNN은 linear locality를 encoding하기 때문에 가까운 단어들에 의미에 대해서 영향을 많이 주고받습니다. 또한 word embedding 결과에도 잘 반영됩니다.
그렇다면 여기서 발생하는 문제점은 input sequence의 길이가 길어질수록, 즉 먼 거리의 단어일수록 상호작용이 어렵습니다.
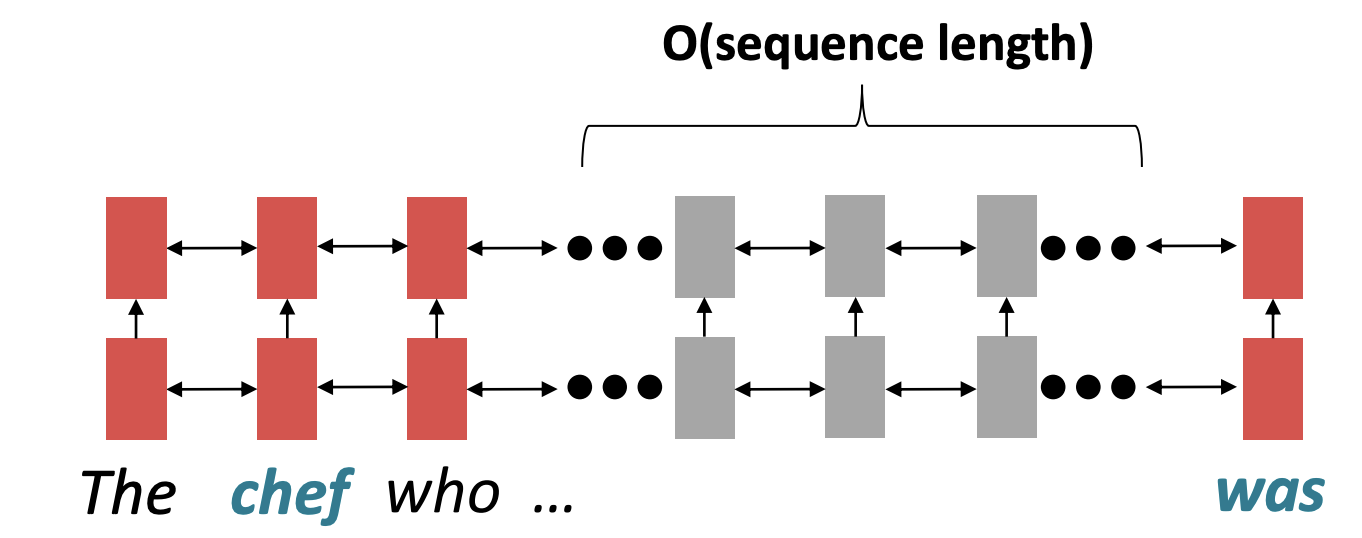
위 문장에서 'chef'의 동사는 'was'이지만 관계대명사 'who'로 인해 서로 멀리 떨어져있습니다. 이 한쌍 ('chef' - 'was')이 상호작용을 하기 위해서는 그 사이의 sequence length만큼의 연산이 이루어져야하는데 그러면 gradient vanishing의 문제로 dependency를 학습하기는 어렵습니다.
2. Lack of parallelizability
다음 문제점은 RNN은 순차적으로 연산이 이루어지기 때문에 병렬 연산이 불가능하다는 점이다.(GPU를 활용한 병렬연산이 불가능합니다.)
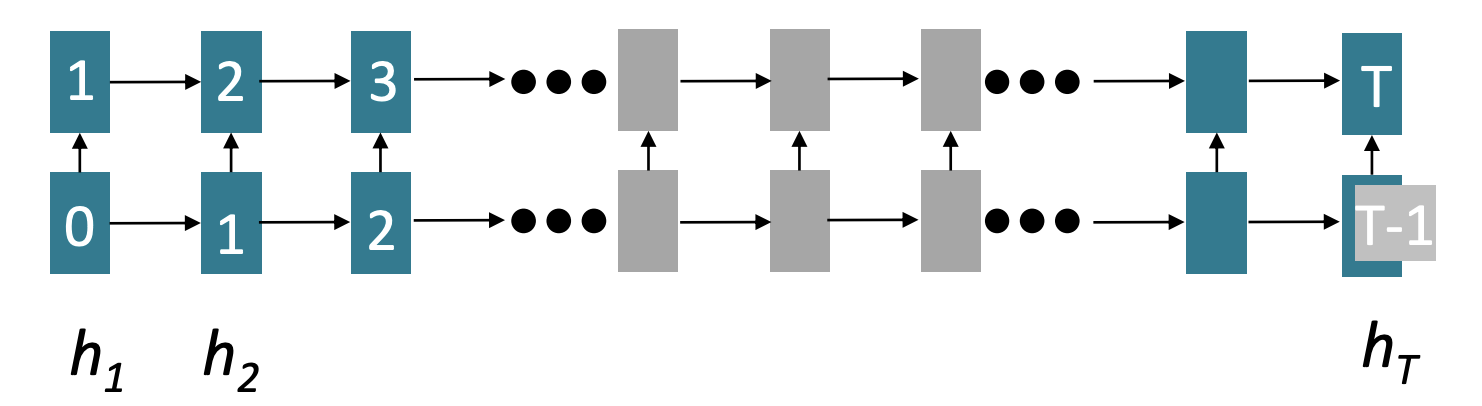
위 그림 cell안에 적혀져 있는 숫자는 해당 hidden state가 연산되기까지의 최소 연산 횟수입니다. RNN model은 그림의 화살표처럼 순차적으로 연산이 이루어지며 hidden state의 마지막 cell은 input sequence length만큼의 연산이 필요합니다. 그러므로 Model이나 data가 커질수록 더 큰 약점이 됩니다.
How about word windows?
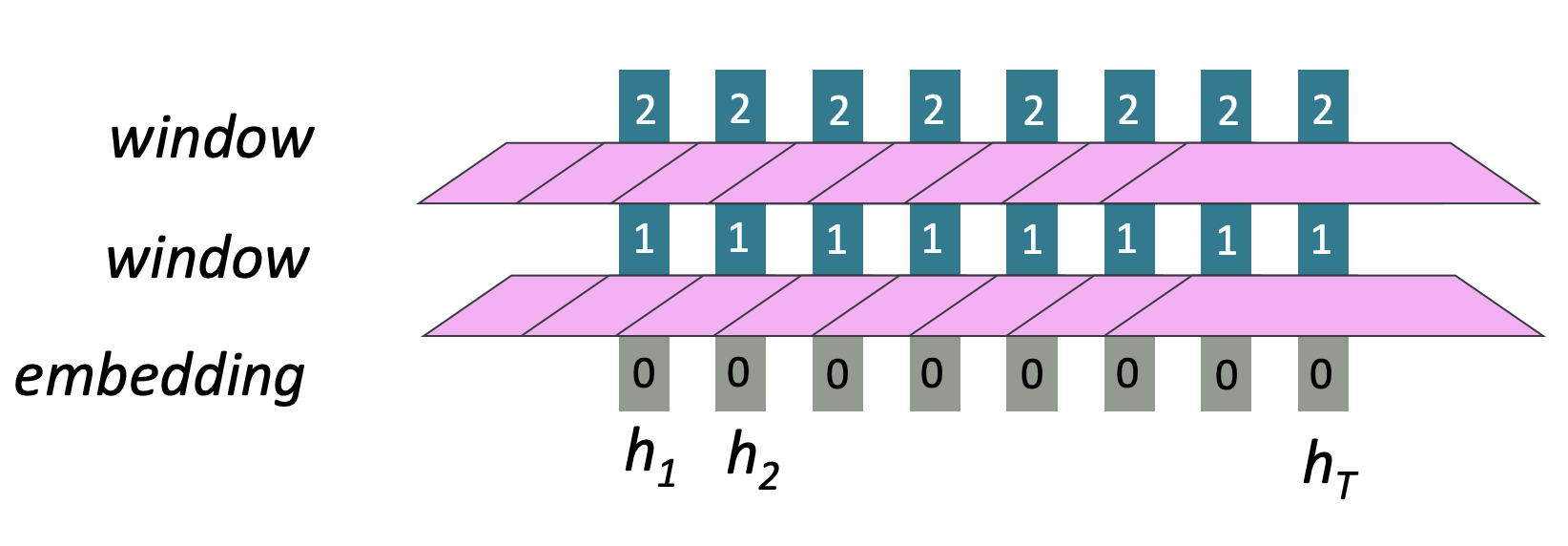
Word window model은 local context를 통합한 구조를 가집니다. Word2vec은 window size만큼의 연산이 이루어지기 때문에 local context라고 이해했습니다. 즉, sequence length가 증가해도 병렬처리가 불가능한 연산은 증가하지 않습니다. Embedding layer에서 독립적으로 연산이 이루어지고 window layer를 거쳐도 각각 연산이 한번씩 이루어지기 때문에 RNN이 가지고 있는 연산에 관한 문제점은 가지고 있지 않습니다.
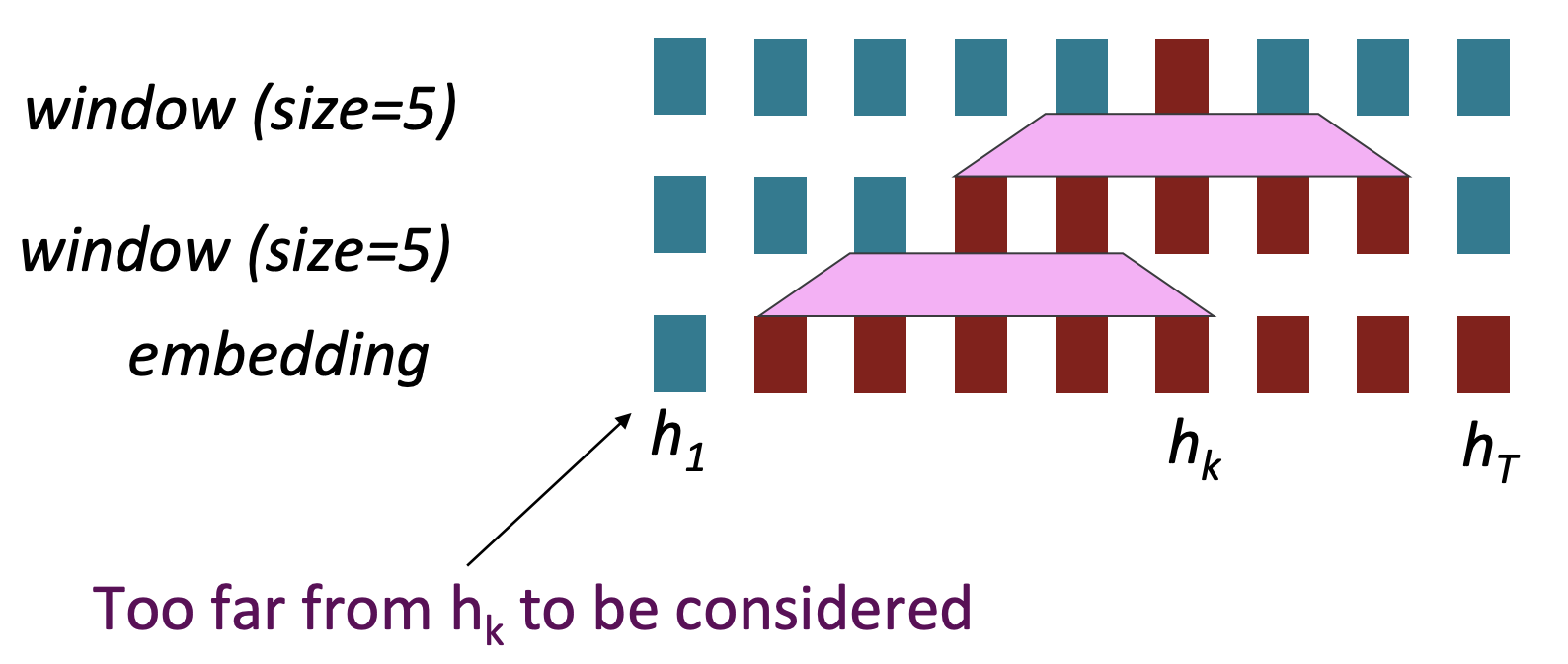
그러나 RNN이 가지고 있는 또 하나의 문제점인 long-distance dependency의 문제점은 가지고 있습니다. Word window는 parameter인 window의 수 만큼만 반영하기 때문에 멀리 떨어져 있는 단어와의 dependency를 반영하기 위해서는 window layer를 더 높게 쌓아야합니다. 하지만 상호작용할 수 있는 최대 길이는 전체 sequence의 length / window size이기 때문에 아무리 높게 쌓아도 한계점이 존재합니다.
How about attention?
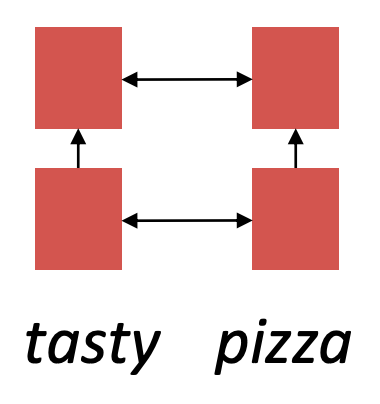
기존 attention은 decoder에서 encoder로 query를 날려 주목해야될 부분을 파악하는 mechanism입니다. 그리고 self attention은 한 문장안에서 attention을 고려하는 것으로 차이가 있습니다.
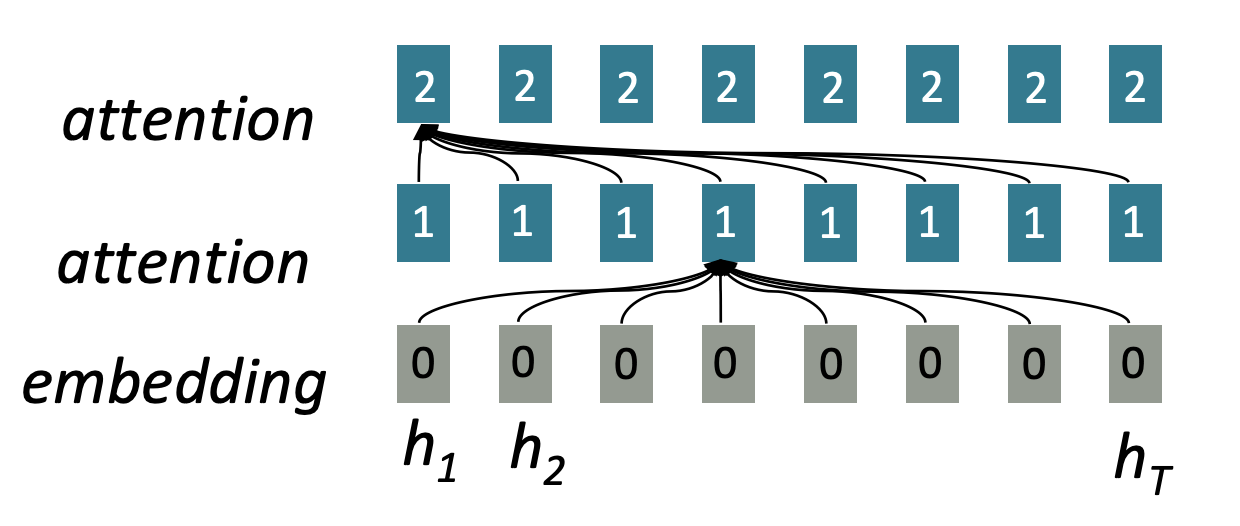
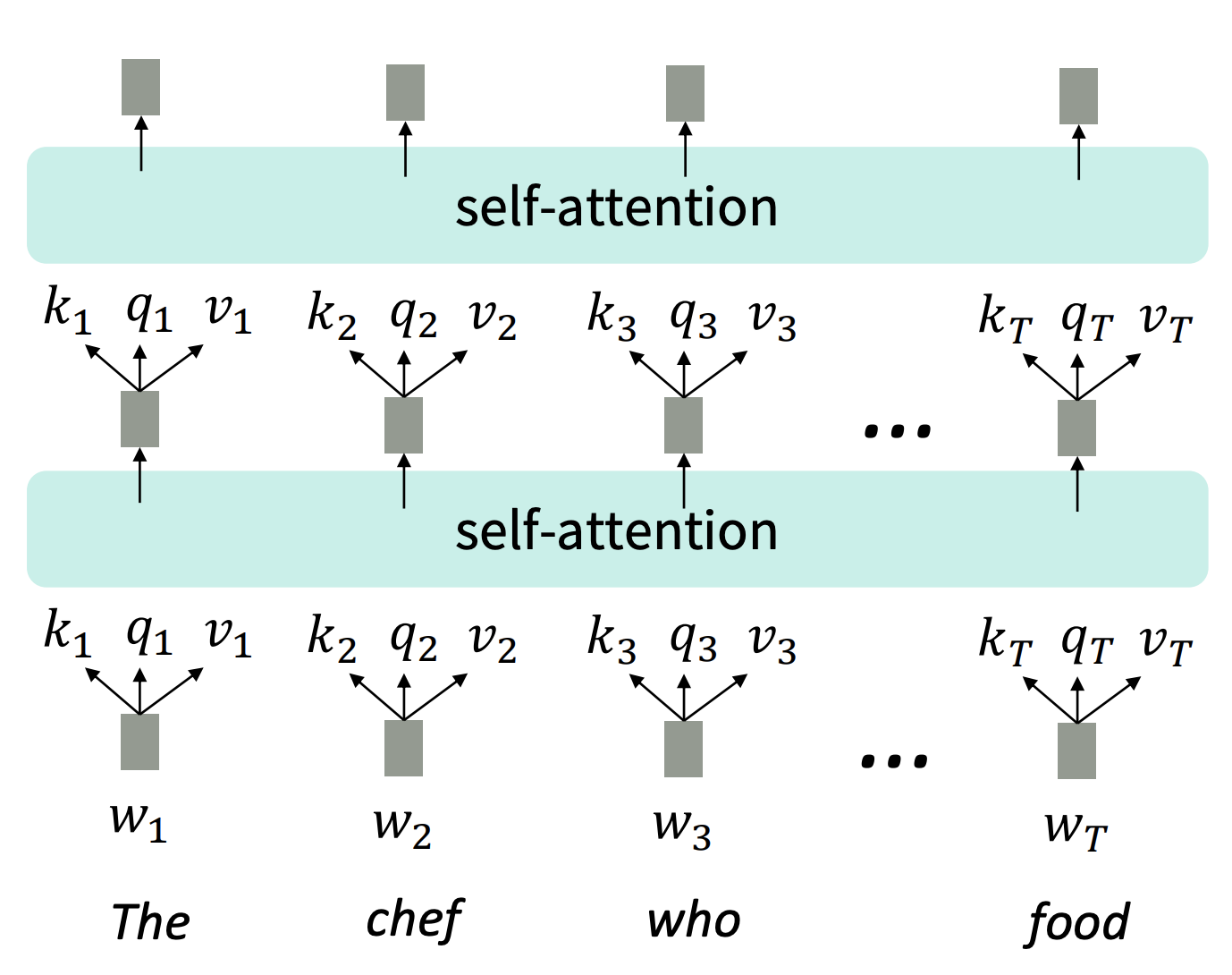
Input sequence의 길이가 증가하여도 병렬 연산처리가 가능한데 그 이유는 input sequence에 대해서 output을 계산하기전에 병렬로 attention 계산을 미리 끝내놓고 output 단어를 계산할 때, 출력 이전 단어들의 attention과 미리 계산한 input의 attention을 이용해 다음 단어를 예측한다. 또한 위의 그림을 보면 각 layer를 지날때마다 모든 state가 attention으로 연결되어 있어 단어가 아무리 멀리 떨어져 있어도 상호작용이 가능합니다.
Self-Attention
다음은 self-attention이 어떤 mechanism을 가지고 있는지에 대해 알아보겠습니다. 만약 지시대명사가 문장안에 존재할 경우 model이 무엇을 가르키는지 어떻게 알수있을까? Self-head attention을 이용하면 알 수 있습니다. Model이 입력 문장 내의 단어를 처리하면서 self-attention을 이용해 문장 내의 다른 위치에 있는 단어들을 보고 연관이 있는 단어를 찾아줄 수 있습니다.
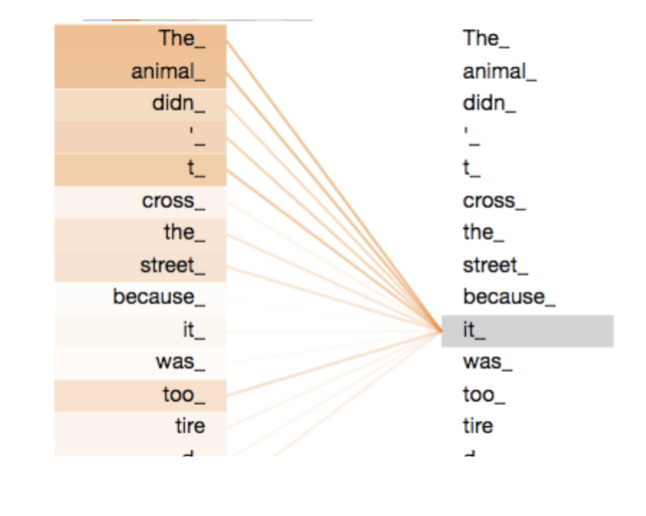
Self-Attention mechanism을 이용해 'it'이라는 단어가 'animal'에 attention을 많이 받는것을 알 수 있습니다.
Self-attention의 첫번째 단계는 encoder에 입력된 vector들에게서 3개 vector를 만드는 것이다. 단어의 Query vector, Key vector, Value vector를 만듭니다.
Query : 현재 단어의 representation
Key : Query와 비교할 단어의 representation
Value : attention mechanism을 이용해 가져올 representation
이 vector들은 각 3개의 가중치 행렬과 곱함으로써 생성됩니다. 여기서 input vector의 차원보다 이 3개의 vector들의 차원이 낮게 설정되는데 그 이유는 Multi-head Attention의 각 head에서 연산된 결과를 concat할 때 계산 복잡도를 낮게해주기 위함입니다.
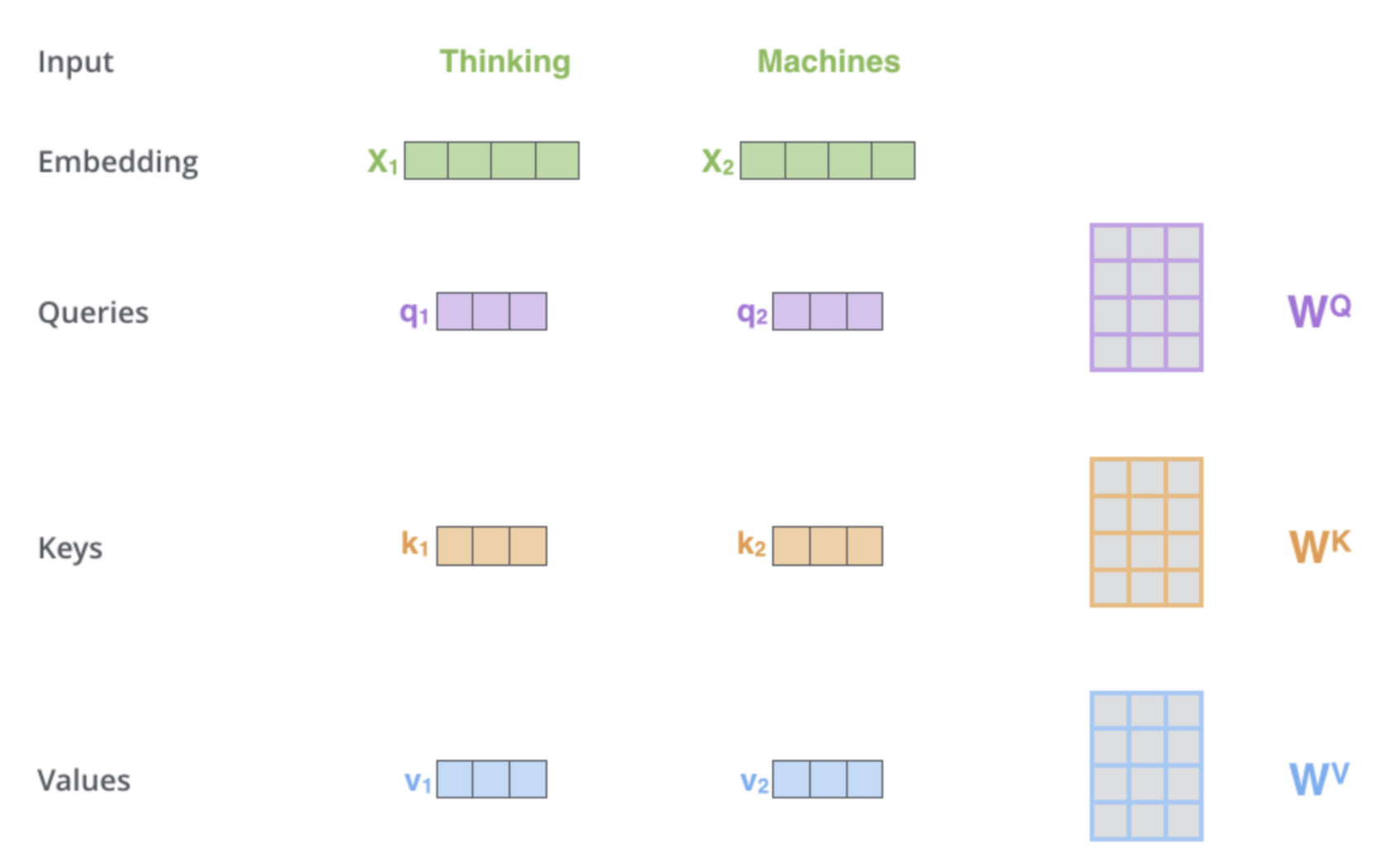
X1에 weight matrix인 를 곱해 query vector인 을 생성한다. 그리고 다른 input
vector인 X2와 를 곱해 를 생성한다.이러한 방법으로 query, key, value vector를 생성할 수 있습니다.
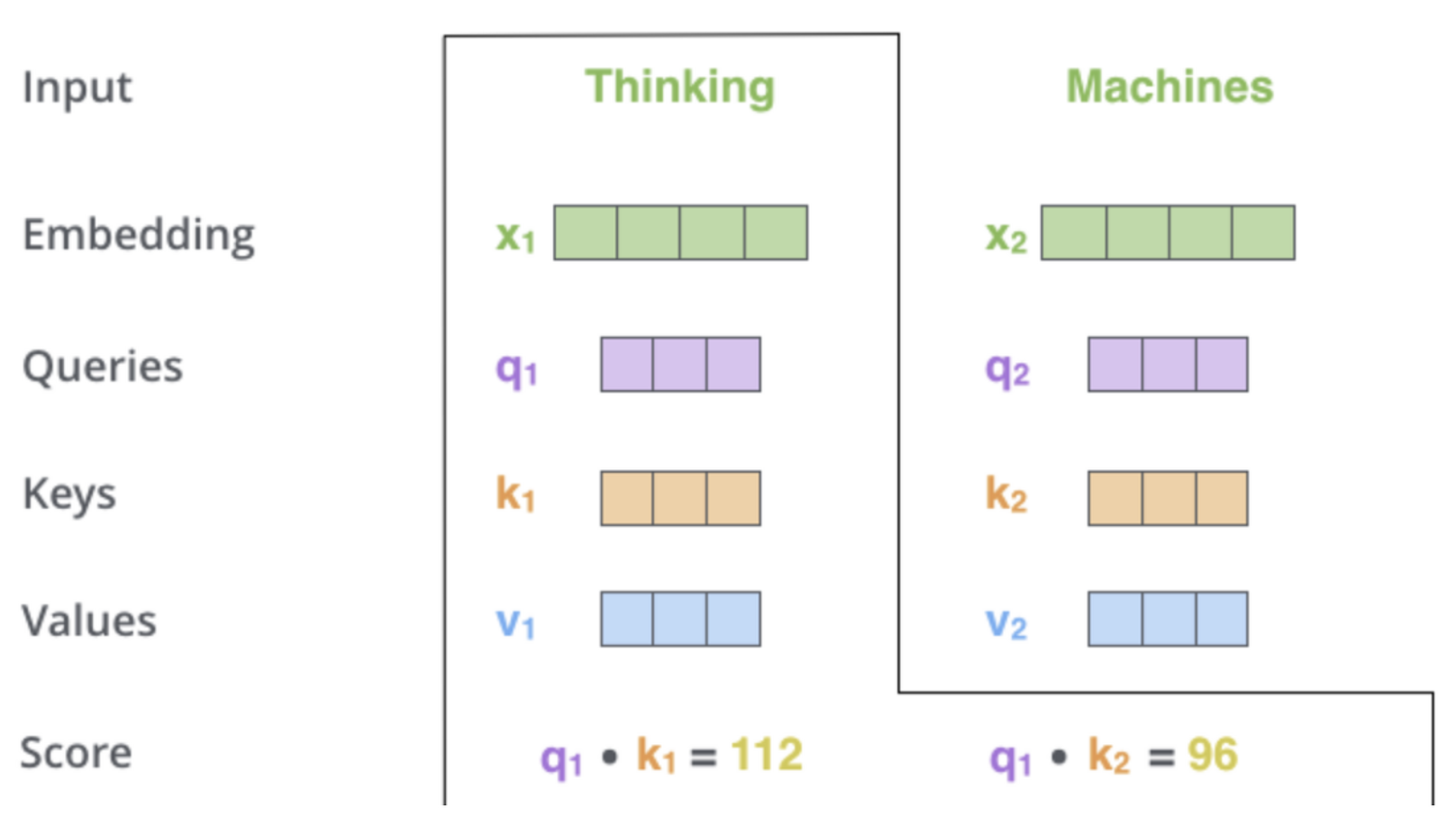
두번째 단계로는 attention score를 계산하는 단계입니다. 우리는 모든 문장안에 존재하는 단어들의 점수를 각각 계산해야됩니다. 이때 이 attention score는 현재 단어의 query vector와 비교할 단어의 key vector의 내적으로 계산됩니다. 그렇다면 첫번째 attention score는 과 의 내적값일 것입니다. 그리고 두번째 attention score는 과 의 내적값입니다.
세번째 단계는 이 점수들을 로 나누는 것입니다. 이러한 scaling을 통해 안정적인 gradient를 가질 수 있습니다.
네번째 단계로는 softmax 함수를 통과시켜 모든 점수들의 합을 1로 만들어줍니다.
다섯번째는 softmax를 거쳐 나온 점수를 value vector와 곱하는것입니다. 그렇게되면 attention score값이 높은 단어는 남게되고 없는 단어는 아주 작은값으로 표현됩니다.
마지막 단계는 이렇게 나온 weighted value vector 들을 다 합하는것입니다. 이것이 self-attention layer의 최종 output입니다.
Barriers and solutions for Self-Attention as a building block
Doesn’t have an inherent notion of order!
다음으로는 self-attention을 이용해 block을 쌓았을 때 문제점입니다. 먼저 순서정보가 없다는 문제점입니다.
아까 봤던 query, key, value에는 index가 존재하지 않았습니다. 그러므로 위치정보를 포함하고 있는 새로운 query, key, value를 만들어야합니다. 이에 필요한 position vector를 아래와 같이 정의합니다.
, for {1,2,...,T}
이렇게 정의한 position vector를 각 query, key, value에 더해서 위치정보를 부여합니다.
Position vector은 두개의 함수, cos함수와 sin함수를 이용하여 홀수, 짝수에 따라 사용한다.
절대적 위치가 아닌 상대적인 비교를 통해 위치를 나타내므로 sequence가 아무리 길어도 정보를 잃지 않는다는 장점이 있지만 고정된 함수를 사용하기 때문에 학습이 불가능하다는 단점이 있습니다.
No nonlinearities for deep learning! It’s all just weighted averages
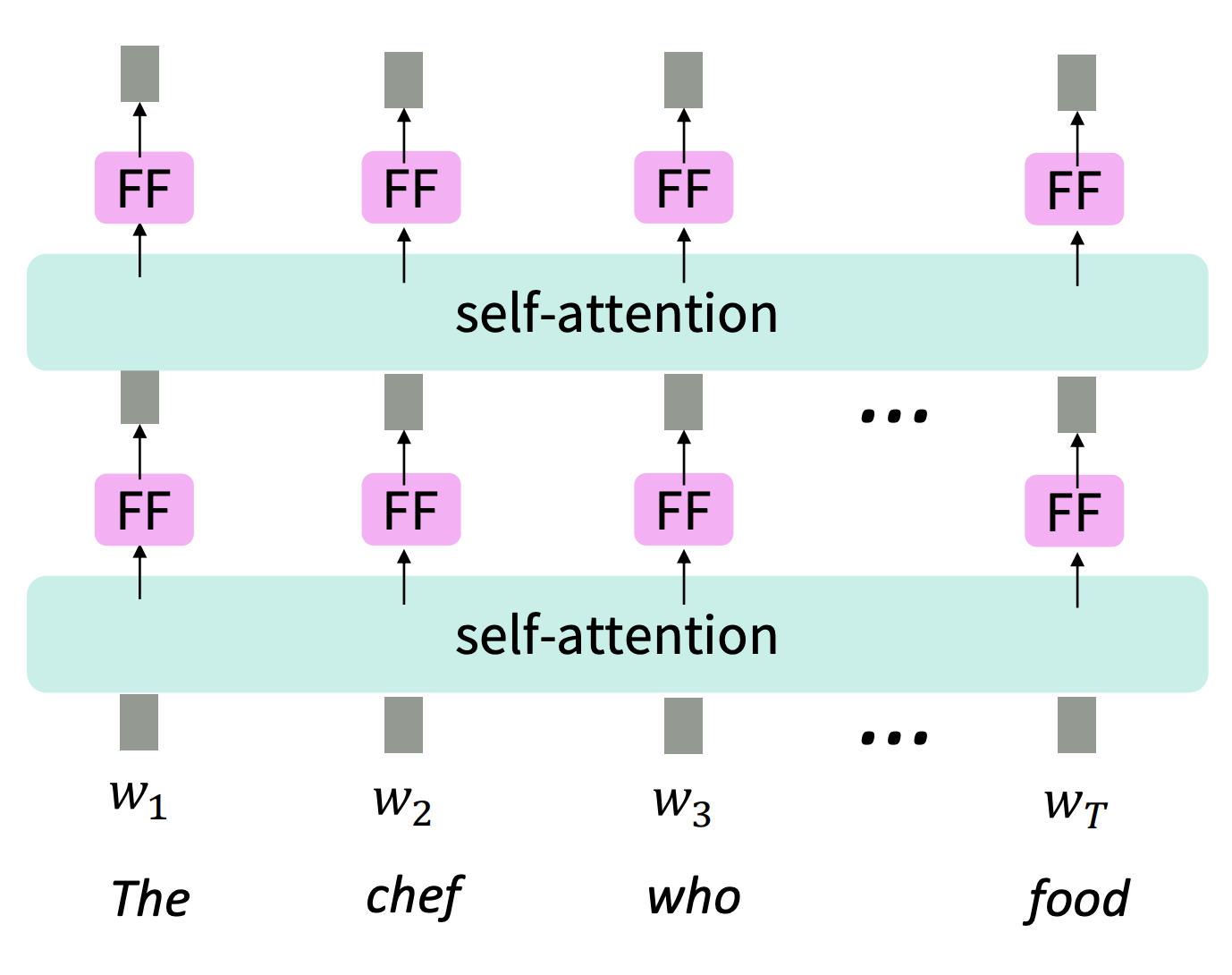
다음 문제점은 self-attention은 단순 가중합 형태의 선형결합이기 때문에 feed-foward network를 추가합니다. 이때 feed-foward network는 ReLu라는 비선형함수를 추가하고 각각 layer들은 다른 parameter를 갖습니다.
Need to ensure we don’t “look at the future” when predicting a sequence
다음 문제점은 병렬로 계산이 이루어져 미래의 sequence 단어를 연산에 활용할 수 있기 때문에 밑에 그림의 회색 부분처럼 masking을 해줍니다.
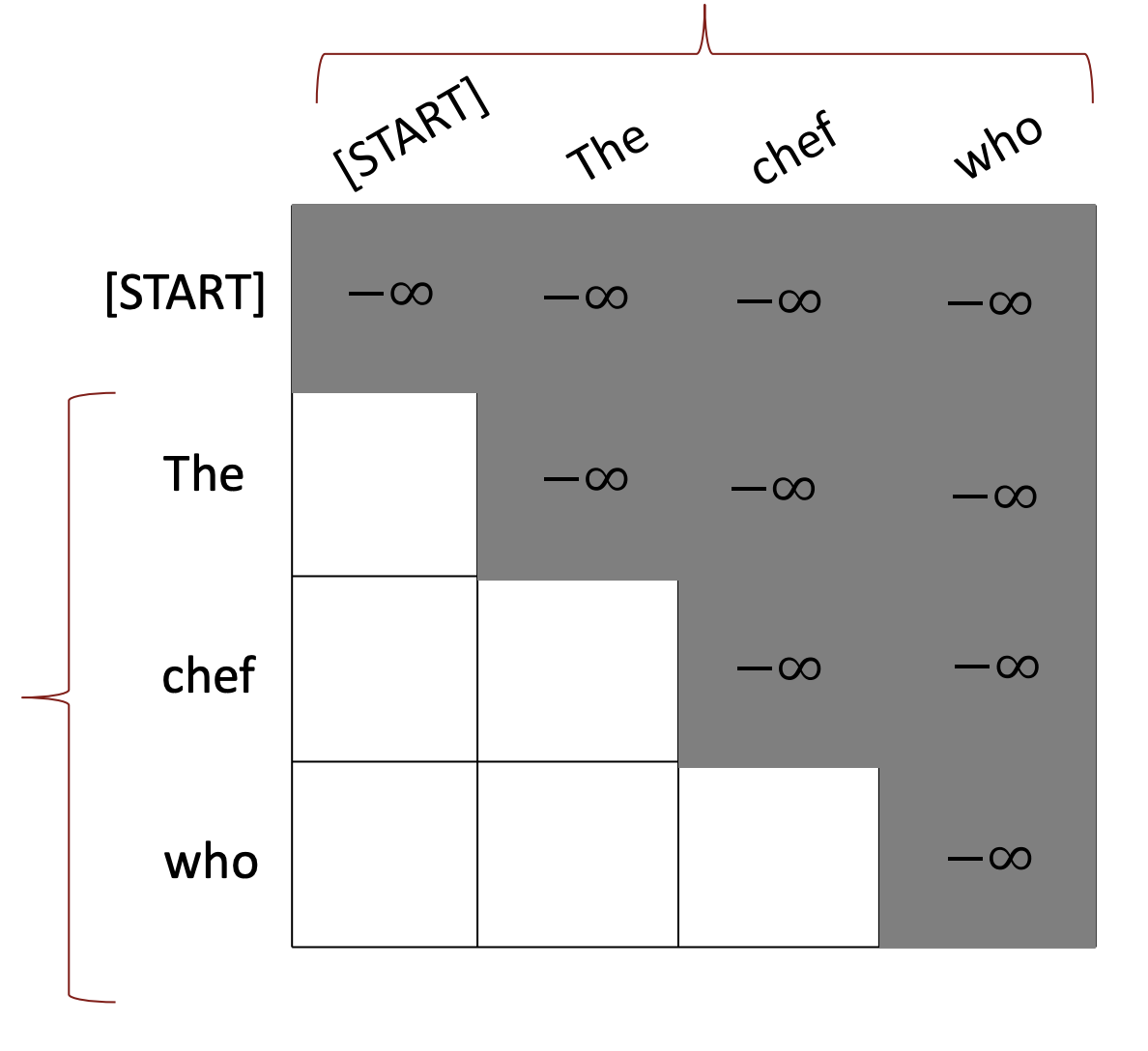
이때 아래와 같은 식을 통해 처리를 해줍니다.
위의 식을 보면 query의 index인 가 key의 index인 보다 클 경우 값을 계산하고 아니면 가 됩니다. Query는 현재 처리해야될 단어이므로 query index보다 key index가 클 경우 masking을 해줍니다.
Introducing the Transformer model
지금까지 self-attention에 대해서 알아봤고 이제 transformer model에 대해 설명하겠습니다.
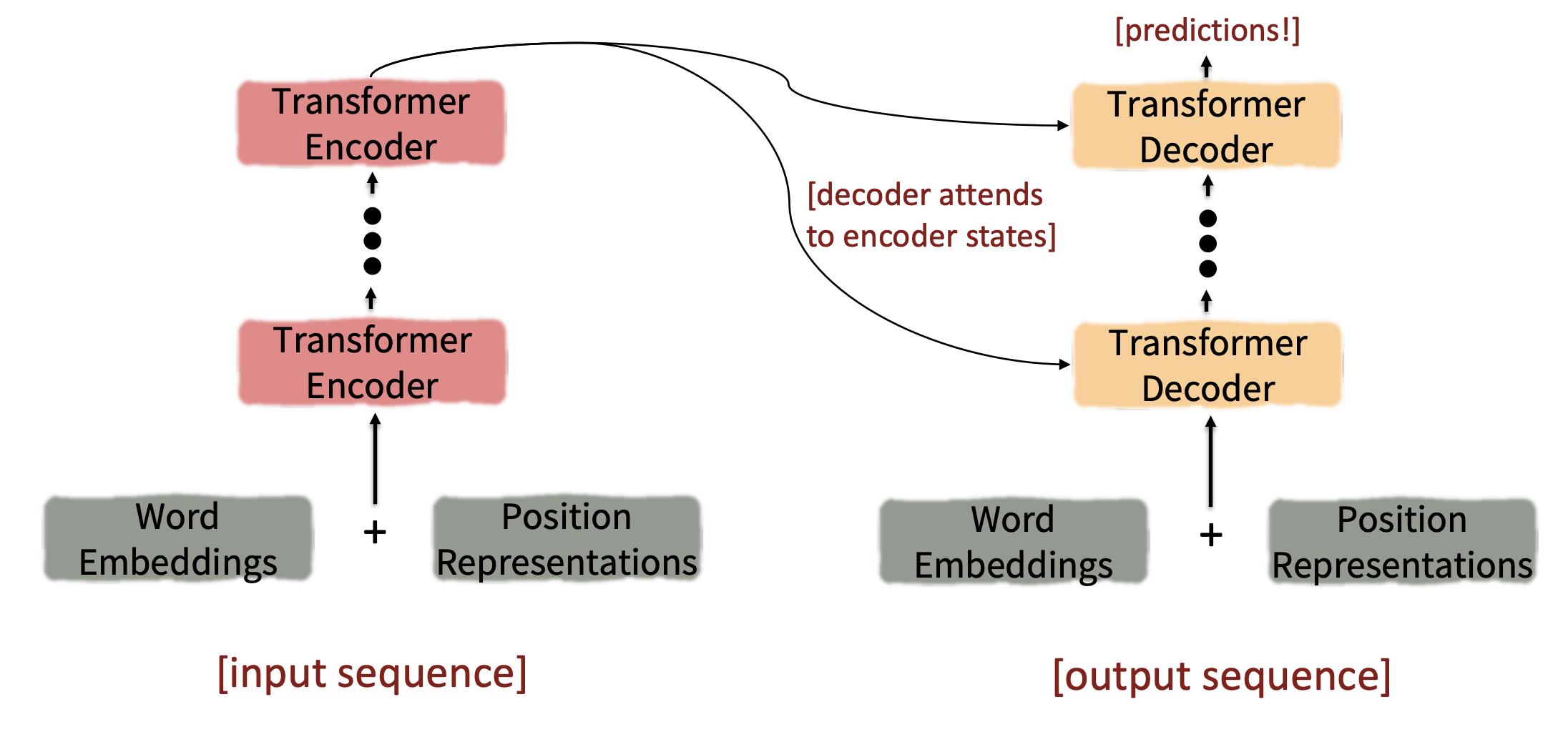
기존 seq2seq의 encoder와 decoder의 구조는 그대로 유지했고 각 encoder와 decoder block안에 있는 구성물이 달라졌습니다.
Transformer Encoder
이제 각 transformer encoder와 decoder block 안에 대해 자세히 들여다보겠습니다.
Mulit-headed attention
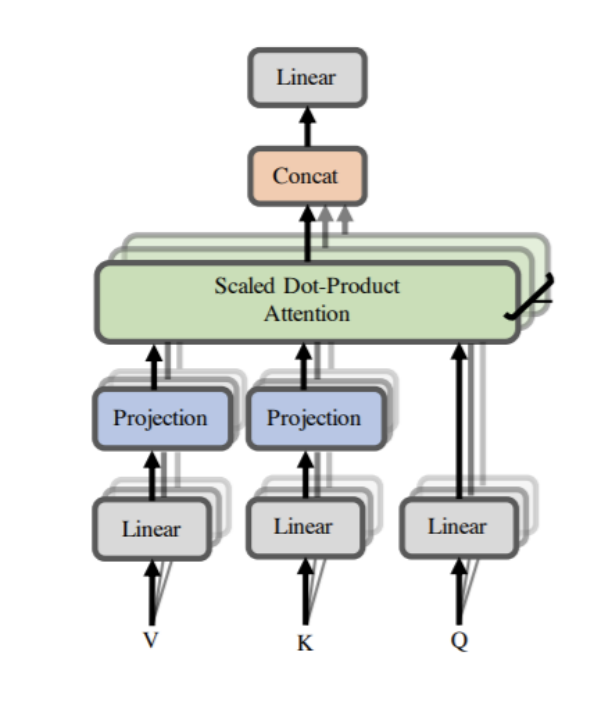
먼저 transformer에는 self-attention뿐만 아니라 multi-headed attention이 존재합니다. 이를 통해 다양한 관점을 가질 수 있게 해줍니다.
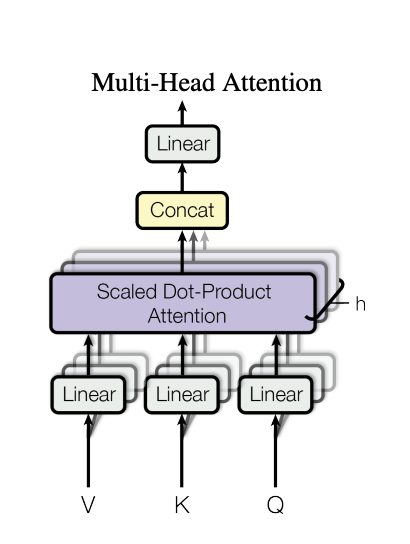
위의 그림과 같이 multi-head attention은 앞서 설명한 self-attention을 여러번 수행하는것으로 다양한 특징을 학습할 수 있습니다. 각 head에서는 다른 query, key, value를 산출하고 각 head마다 output을 생성합니다. 그리고 각 head의 output을 concat한 값과 마지막 weight matrix와 곱하여 처음 input의dimension과 똑같이 만들어줍니다.
그리고 각 head의 query, key, value의 vector를 표현하면 아래와 같습니다.
여기서 주목해야할것은 바로 각 차원인데 우리가 각 head의 output을 concat했을때, input과 똑같은 차원을 가질 수 있다. 여기서 input sequence가 각 head로 쪼개져서 들어간다고 생각할 수 있는데 모든 head에 대해 전체 input sequence가 사용됩니다.
Residual connections
다음은 residual connections입니다.

Residual의 개념은 ResNet에서 나온 개념으로 비선형함수를 통해 나온 output에 기존 input을 더해줍니다. 예를 들어, f(x)는 layer를 많이 거칠수록 gradient가 vanshing이 되는데 f(x) + x의 형태를 가지면 1의 gradient는 보장되기 때문에 보다 안정적인 학습이 가능합니다.
Layer normalization
Residual connection을 통과한 후 layer normalization으로 이어지는데 이는 모든 feature에 대해 평균과 분산을 구하여 각 input을 정규화해줍니다. 이 과정을 통해서 gradient를 안정화 시킬 수 있다고 합니다.
Scaled Dot Product
Dimension이 커지면 vector의 dot product의 결과도 커지는 경향이 있습니다. Transformer의 최종 output은 softmax를 통해 산출이 됩니다
기존 attention의 연산을 통해 만든 score를 생각했을때, softmax의 값이 쏠린다는 것은 특정 단에만 강하게 attention이 가해지는것이기 때문에 값이 작으면 연결이 끊기는것을 알 수 있습니다. 그러므로 gradient를 잘 흘리기 위해서는 dot product의 결과가 너무 커지지 않게 scaling을 취해줍니다.
Looking back at the whole model, zooming in on an Encoder block
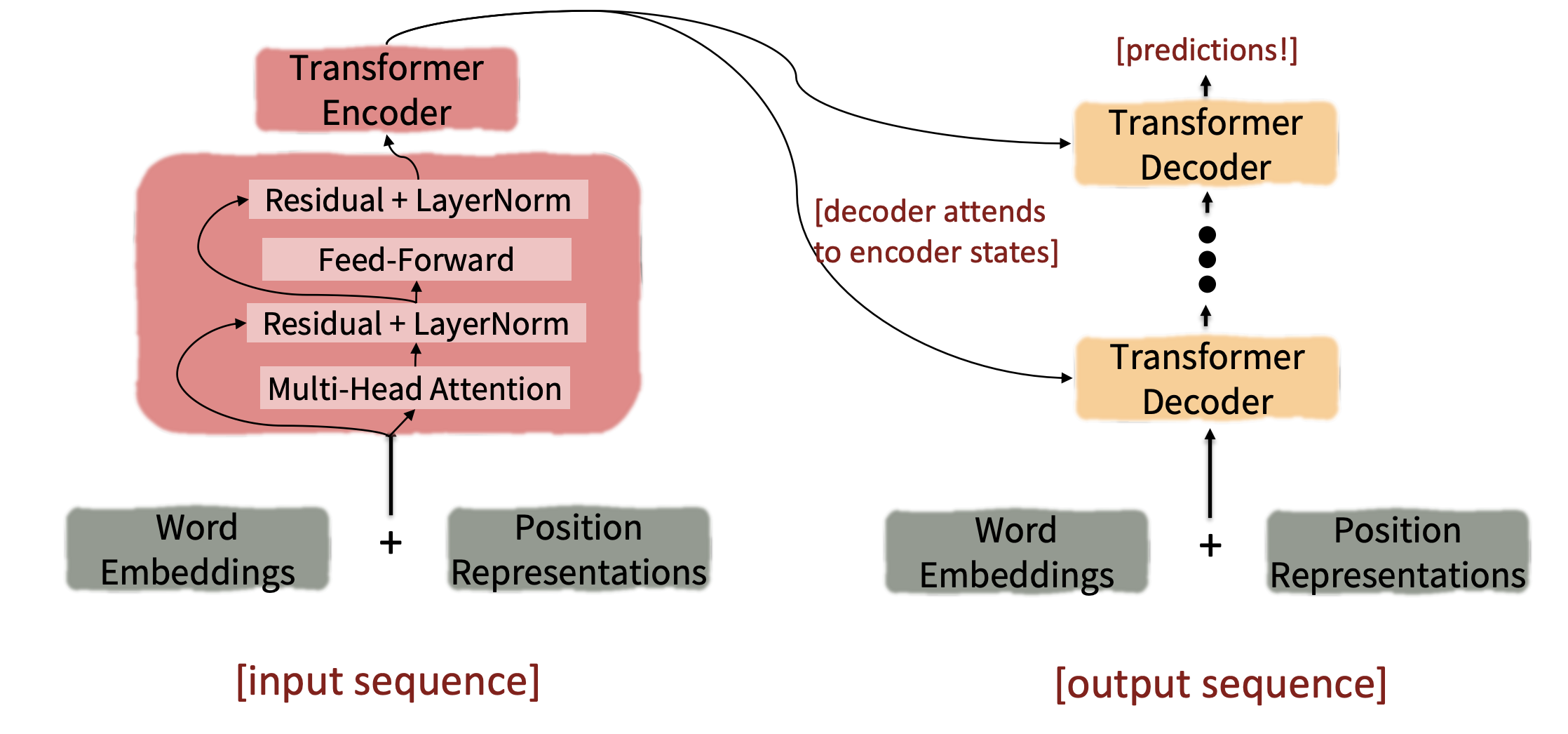
다시 transformer의 encoder block을 훑어보면, input word embedding이 들어오면 positional encoding 값과 더해져 multi-head attention layer로 들어갑니다. Self-attention을 거쳐 새로운 representation으로 변환되고 이를 residual connection을 수행한 뒤, layer-normalization을 거쳐 feed-foward network로 들어가게됩니다. 화살표를 보시면 왼쪽으로 빠져나온것을 볼 수 있는데 이는 residual connection이 있는 layer로 자기 자신의 값(input)이 들어가는것을 확인할 수 있습니다.
The Transformer Decoder
다음은 transformer decoder block에 대해 설명하겠습니다.
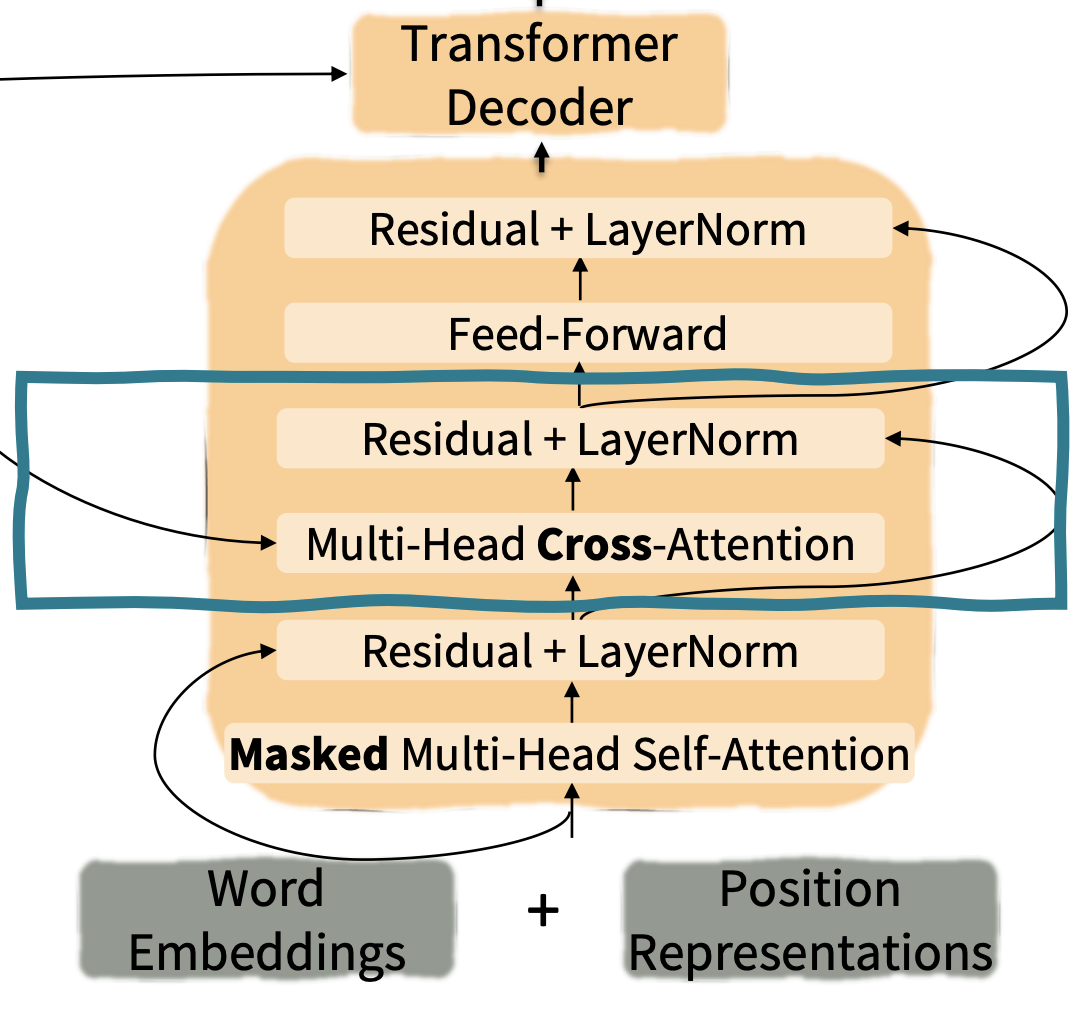
마지막 Encoder block이 종료된다면, decoder로 넘어가게됩니다. Decoder도 encoder와 비슷한 구조를 가지고 있고 처음으로는 encoder와 동일하게 word embedding과 positional encoding값이 더해져 masked multi-head attention으로 들어가게됩니다. Encoder와는 다르게 decoder에서는 해당 step의 다음 시점을 참고하면 안되기 때문에 masking을 사용합니다. 그 다음으로는 encoder와 동일하게 residual과 layer normalization을 거쳐 multi-head cross-attention으로 들어가게 됩니다.
Cross-attention
Multi-head cross-attention은 seq2seq model에서의 attention과 많이 유사합니다. Seq2seq model의 decoder에서의 query를 이용하여 encoder의 어떤 부분을 참고할지를 탐색합니다.
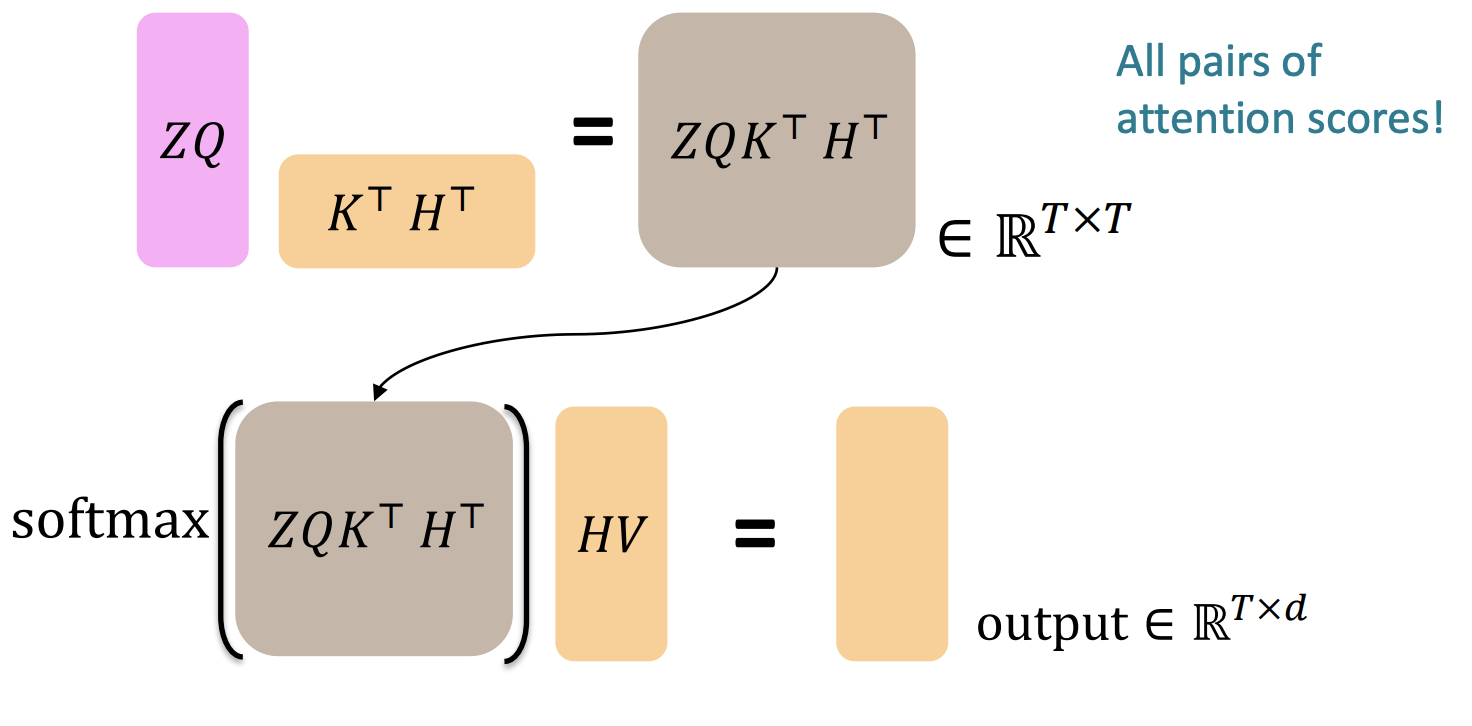
기존 attention의 연산 과정과 똑같지만 decoder의 input vector인 와 query weight matrix를 사용한다는 점이 다릅니다.
Great results with Transformers
Transformer model은 당시 SOTA를 갈아치웠다고 합니다.
Drawbacks and variants of Transformers
Transformer는 두가지 약점을 가지고 있다고 했는데 먼저 sequence length가 증가함에 따라 계산량이 로 증가한다는 점입니다.
그 다음으로는 position representations의 개선여지가 많다고 합니다.
본 lecture에서는 첫번째 문제점에 대해 두가지 solution(?)을 제시했습니다.
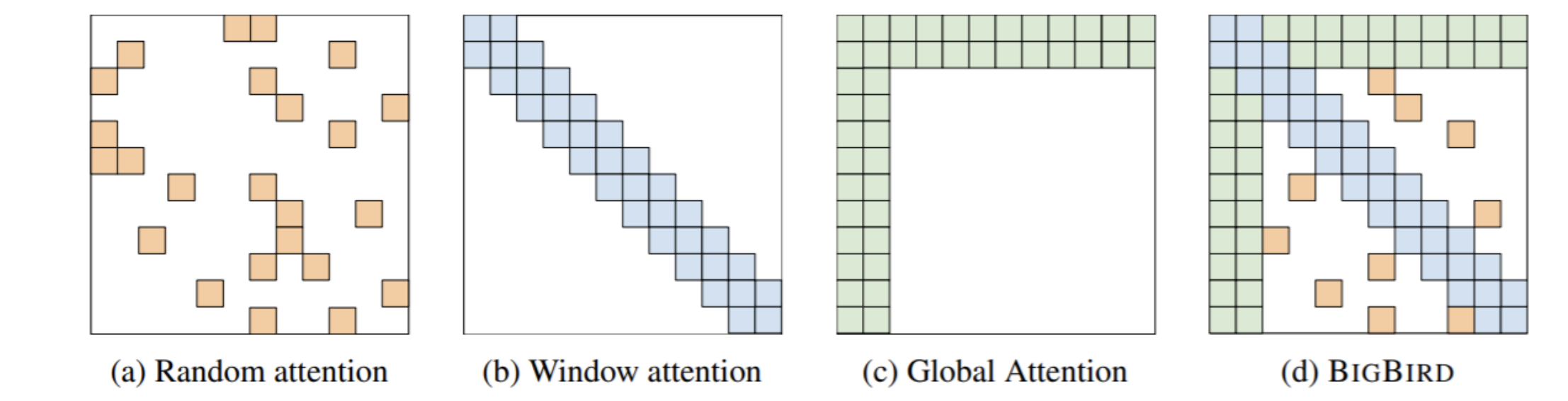
Recent work on improving on quadratic self-attention cost
먼저 projection을 이용해 sequence의 dimension을 낮추어 계산량을 낮춘 linformer를 소개했습니다.
두번째로는 모든 attention을 계산하는것이 아닌 아래와 같은 attention mapping을 적절히 사용하여 bigbird의 형태로 계산하여 계산량을 줄이는 방법입니다.