작성자: 투빅스 15기 김태희
Contents
- Introduction
- Objective
- Model Architecture
- Training Strategy
[9주차] 강의들에서 나온 N-Shot Learning을 할 때 사용하는 Episodic Learning을 제안한 Matching Networks for One Shot Learning 논문 리뷰이다.
0. Introduction
딥러닝 모델은 데이터의 양에 비례해 그 성능을 보여주는 경향이 있다. Neural Neet 구조가 깊어질수록 더 많은 파라미터들을 학습해야 하기 때문에 뛰어난 성능을 위해서는 더 큰 규모의, 양질의 데이터와 모델을 훈련시킬 수 있는 컴퓨팅 자원 여부가 필수적이다. 현실에서는 양질의, 균등한, labelled된 데이터를 구축하는 비용이 많이 들기도 하고 또 데이터가 균등하게 분포하는 것이 거의 불가능하기 때문에 데이터가 적은 class들을 잘 구별하지 못하는 overfitting 문제들이 빈번하게 발생하게 된다.
이를 해결하기 위해 다양한 Data Augmentation 방법들과 weight decay 등을 통한 Regularization 방법들이 연구 되었지만, 다량의 데이터를 학습시키는 시간적인 비용이 많이 든다는 점은 변하지 않는다. 해당 논문에서는 수백만개의 파라미터들을 천천히 학습하는 딥러닝 모델의 parametric한 성질을 해결하고자 하며, non-parametric 방법을 응용해 적은 양의 데이터로 빠르게 학습을 진행하는 방법을 모델 구조와 학습 방법의 관점에서 제안한다.
Non-Parametric Model
말 그대로 파라미터가 정해져 있지 않은 모델이다. 신경망 모델을 학습한다고 했을 때, 보통의 경우 학습을 진행하며 업데이트 해 나가야 하는 파라미터의 종류와 수는 정해져 있다. 이는 데이터의 적고 많음을 떠 학습해야 하는 파라미터의 수가 정해져 있는 것이다.
그러나 KNN 과 같은 Non-Parametric Model은 데이터의 분포를 가정하고 시작하지 않기 때문에 모델을 학습할 때 튜닝해야 하는 파라미터들이 정해져있지 않다.
N-Shot Learning 은 limited data를 가지고 학습을 진행하고자 나온 방법이다. N은 하나의 class 에 대해 학습할 수 있는 데이터가 N 개만 있을 때를 의미한다.
- Zero-Shot Learning: class에 해당하는 데이터가 존재하지 않을 때
- One-Shot Learning: class당 1개의 데이터가 존재할 때
- Few-Shot Learning: class 당 2-5개의 데이터가 존재할 때
N-Shot Learning과 같이 메타러닝은 한 사람이 비슷한 그림 몇 개를 통해 그 특징을 파악하고, 유사한 그림들을 분별하는 방식을 기계에 적용하기 위해 연구되고 있는 분야이다.
해당 논문에서는 적은 수의 데이터, 한 클래스 당 하나의 데이터가 있는 one-shot learning을 설명한다.
1. Objective
- 거리 기반 모델 architecture 제안
- 대부분 메타러닝에서 학습 방법으로 많이 쓰는 Episodic Training 제시
- 대량의 큰 ImageNet 데이터셋을 가공하여 miniImageNet 제공
2. Model Architecture
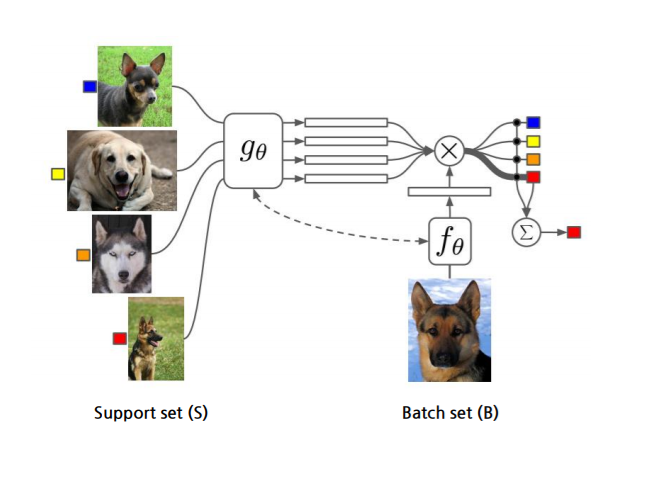
다음은 이 논문에서 제시한 Episodic Training을 4-way 1-shot으로 진행하는 모습을 나타낸 그림이다.
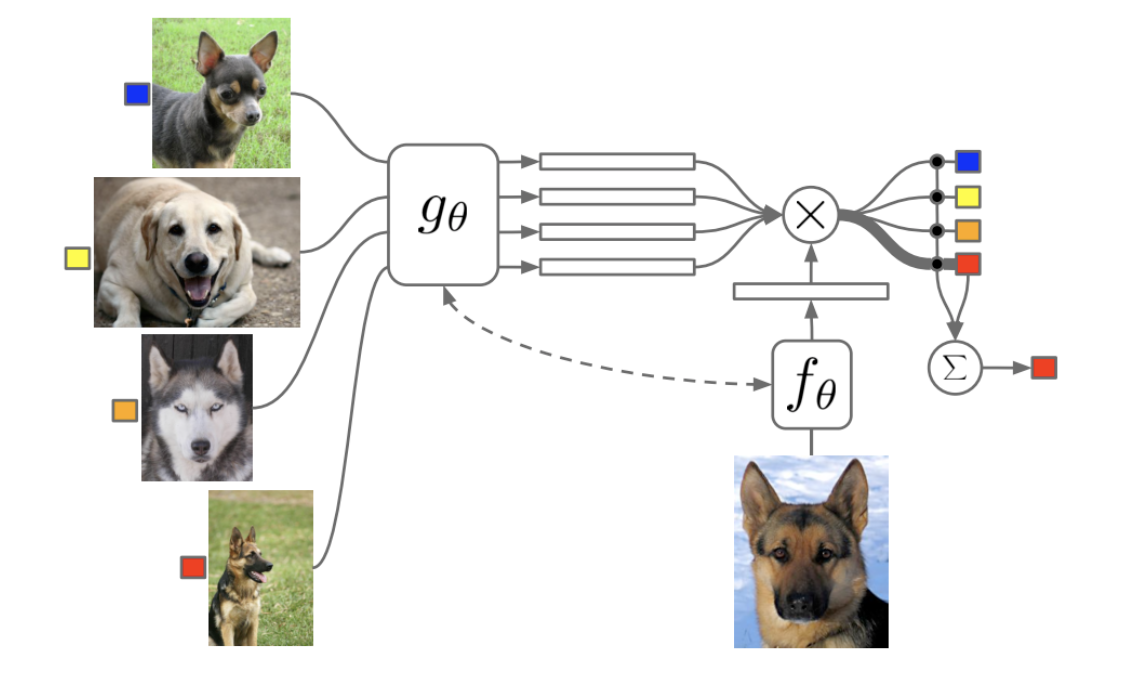
왼쪽의 그림 4가지가 학습시 사용하는 Support Set, 오른쪽 하단의 이미지가 test시 사용하는 Batch set에 해당한다. Batch set이 어떤 label인지 attention값을 통해 가중치를 주며, 가장 높은 가중치에 대해 확률값을 구해 classification 을 진행한다.
위의 모델을 뜯어보면 크개 Matching Networks, Attention Kernel, Full Context Embedding으로 이루어진다.
Matching Networks: External memory를 추가한 neural network구조이다.
ex) attention mechanism을 적용한 seq2seq, memory network, pointer network
위는 Support set과 batch set을 input으로 넣어주었을 시 batch set에 어떤 label을 부여할지 확률 값을 구하는 식이다. 먼저 Support set의 데이터 와 Batch set의 에 대해 Kernel Density Estimator로 거리 기반의 값을 계산한다. 그 다음 Support set 에 대해 mapping 함으로써 확률을 구한다.
Kernel Density Estimator는 Attention Kernel(a) 을 통해 와 의 유사도를 구한다.
해당 논문에서 와 의 유사도를 구한 식은 위와 같다. 임베딩 function들로 , 가 각각 batch, support set에 대해 feature를 뽑는다. 이들의 코사인 유사도를 계산한 후, softmax 함수를 통해 kernel density estimator를 구하게 된다.
임베딩 function ,
- 동일하게 설정 가능
- 별도로 학습 진행해도 가능 (from scratch)
- Pretrained 모델 이용 가능 (VGG, ResNet, ...)
Full Context Embedding
위와 같이 , 로 임베딩을 진행할 시 각각의 support set에 대해 임베딩을 진행한 후 distance를 계산하기 때문에 전체 support set이 고려되지 않는다. 이 문제를 해결하기 위해 ,를 , 로 수정해 전체 support set을 고려하도록 설계하였다.
Support set 내부적으로는 서로 서로 유사한 와 가 있을 때 이를 고려하며 각각을 임베딩할 수 있으며, batch set을 임베딩하는 가 를 고려하도록 다음과 같은 LSTM 구조를 사용하였다.
3. Training Strategy
일반적으로 지도학습에서는 Batch Training을 많이 사용한다. 그러나 적은 데이터로 학습을 진행할 때에는 overfitting이 쉽게 일어나 학습이 잘 일어나지 않게 된다. 이 현상을 해결하기 위해 논문에서는 Episode Training 방식을 제시한다.
- Training시 Test할 때와 유사한 episode를 구성해 overfitting을 방지한다.
- Training set: Support Set()와 Batch Set()으로 구성
위 그림은 2-way 4-shot learning의 예시이다.
학습 데이터셋 안에서 학습할 Support Set()과 Test로 가정하는 Batch Set으로 구성이 되어 있으며, Support Set()에서는 하나의 class당 4개(4-shot)의 sample들을 가지고 있다.
첫 번째 episode에서 고양이와 새에 대해, 다음 episode에서는 꽃과 새에 대해 학습을 한 후 해당하는 batch가 어떤 class인지 맞추는 식으로 학습을 진행한다. 최종적으로 test할 시 한 번도 보지 못한 개와 수달에 대해 2-way 4-shot task를 진행하게 되고, 학습 중 한 번도 보지 못한 '개'라는 class에 대해 classification을 진행하게 된다.
N-way, k-shot
- N: class 수
- k: sample 수
- kN: Episode에서의 데이터 수
- Support Set
- Batch Set
- : Label
- : Task
- Task으로부터 어떤 Label을 할 지 sampling
- 해당하는 label을 가지는 와 를 구성
- 에 있는 데이터를 통해 에 있는 데이터의 라벨값을 예측
- 예측한 확률 값으로부터 계산된 loss로 meta learner 업데이트
위 과정으로 학습을 진행할 시 각 episode에서는 test할 때의 환경과 유사한 환경에서 학습을 진행하게 된다. 이 때문에 Meta Learning은 Learning to Learn이라고도 불려진다.
참고자료:
Matching Networks for One Shot Learning
고려대학교 DSBA Seminar
https://github.com/karpathy/paper-notes/blob/master/matching_networks.md
