0. Introduction
베이지안 통계(Bayesian Statistics)는 확률이 사건에 대해 특정한 정도의 ‘신뢰’를 제공하는 확률의 베이지안적 해석(Bayesian interpretation)을 기반으로 하는 통계 분야이다. 베이지안적 해석은 고전적인 통계와 관련된 빈도론자(Frequentist)의 해석과는 다른데, 빈도론적 해석은 수많은 시행 끝에 발생하는 상대적인 ‘빈도’를 토대로 확률을 해석하는 반면 베이지안적 해석은 현재 발생한 시행과 사전분포를 이용해 사후분포를 추정하는 등 관점의 차이가 존재한다.
이렇듯 ‘확률’에 대한 베이지안적 해석을 토대로 하는 베이지안 통계는 마르코프 체인 몬테 카를로, 근사적 베이지안 연산, 베이지안 회귀 등의 기법과 베이지안 딥러닝, 베이지안 메타러닝 등의 분야에 널리 쓰이고 있다. 특히, 전 세계에 인공지능의 부흥을 불러 일으킨 구글 딥 마인드의 바둑 인공지능 ‘AlphaGo’ 또한 딥러닝 모델과 함께 베이지안 기반 기법 중 Monte Carlo Tree Search를 사용해 인공지능의 괄목할 만한 성능 향상을 보여주기도 했다.
1. Basic of Probability
1.1 확률변수란?

쉽게 말하면, 일반적으로 자주 쓰이는 확률변수(X)는 사건이 존재하는 표본공간(S)에서 실수(R)로 대응하는 함수로 정의된다.
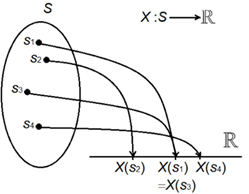
이 때, 확률(P)은 사건이 존재하는 표본공간(S; sample space)에서만 정의되기 때문에 아래와 같은 식으로 확률변수에 대한 확률을 정의할 수 있다.
즉, 확률변수는 정의역이 표본공간이고 공역이 실수인 함수이며, 공역의 종류에 따라 이산확률변수 또는 연속확률변수로 나뉜다.
이산확률변수
- 확률변수에서 공역이 셀 수 있는(countable) 집합인 경우
Ex) 동전의 앞/뒤, 교통사고 건수, 성공 횟수 등
예를 들어, 확률변수 가 서울 시내에서 발생하는 하루에 교통사고 건수를 나타낸다고 가정해보자. 이 때 는 이산형 분포인 포아송 분포를 따른다고 가정할 수 있다.
~
연속확률변수
- 확률변수에서 공역이 (실수에서) 일정 구간의 모든 값을 가질 수 있는 경우
Ex) A공장에서 생산한 전구의 사용 기간, 키, 몸무게 등
예를 들어, 확률변수 X가 한국 남자의 키를 나타낸다고 가정해보자. 이 때는 X가 정규분포를 따른다고 가정할 수 있다.
~
1.2 베이즈 정리
조건부 확률
두 사건 A,B에 대해 사건 B가 이미 일어났을 경우, 사건 A가 일어날 조건부 확률은 아래와 같이 정의된다.
확률의 곱법칙
조건부 확률의 정의를 이용하면 아래와 같이 성립함을 쉽게 확인할 수 있다.
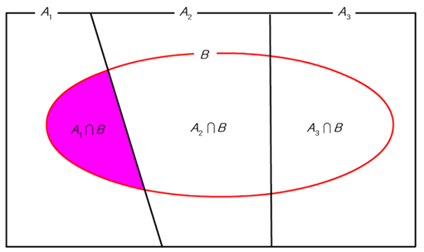
표본공간의 분할
k개의 사건들의 집합인 가 다음의 두 성질을 만족할 때 가 표본공간 의 분할(partition)이라 한다.
- 가 서로 배반
베이즈 정리
기본적으로 가능한 사건들({A_1,…,A_k})가 분할일 때, 조건부 확률의 정의와 확률의 곱법칙을 이용하면 베이즈 정리가 성립함을 알 수 있다.
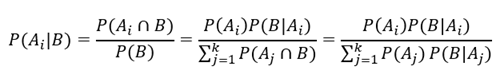
(베이즈 정리를 한 눈에 나타낸 그림)
베이즈 정리의 예로, 고등학교 수학 과정인 확률과 통계에서 자주 나오는 문제를 들 수 있을 것 같다.
문제
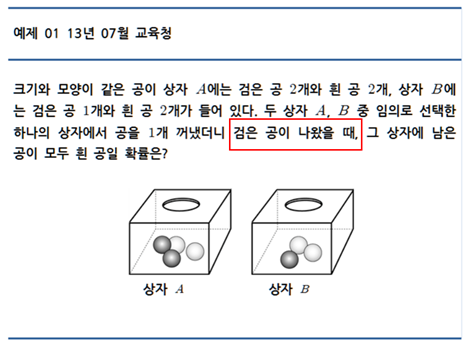
풀이

위의 베이즈 정리는 기본적으로 사건의 관점에서 서술된 식이다. 이 때, 매개변수 θ를 추론하는 데 데이터 X를 이용하는 통계적 추론을 생각해보자. 그러면 위 식을 아래의 식으로 간단하게 나타낼 수 있다.
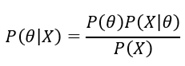
즉, ‘데이터 X가 주어졌을 때 매개변수 θ를 추정하는 문제(P(θ|X))’와 같은 어려운 task를 ‘매개변수 θ가 주어졌을 때 데이터 X의 분포를 활용(P(X|θ))’하는 상대적으로 쉬운 task를 통해 해결할 수 있는 것이다.
이 때, P(θ|X)는 데이터가 주어진 이후의 θ의 분포를 뜻하는 사후 분포, P(θ)는 데이터가 주어지기 이전의 θ의 분포를 뜻하는 사전분포로 정의한다.
2. Classical Statistics vs Bayesian Statistics
베이지안 통계(Bayesian Statistics)는 기존의 고전적인 통계(Classical Statistics)의 몇 몇 문제(?)를 해결하기 위해서, 또는 통계적 추론에 있어서 고전적인 통계를 사용하는 빈도 확률론자(frequentist)의 관점에서 벗어나 다른 태도를 취하기 위해 생겨난 철학으로 여길 수 있을 것 같다. 고전적인 통계는 물론이고 베이지안 통계 또한 베이지안 통계추론, 베이지안 딥러닝, 베이지안 메타러닝, 베이지안 최적화 등 수 많은 세부 분야들이 존재하기에 고전 통계와 베이지안 통계를 명확히 구분 지을 수는 없지만, 본 글에서는 아래와 같은 특성들을 기반으로 둘을 나눠보려 한다.
고전적 통계: 결정적, 상수, 확실성, 많은 데이터, 이론적, 전수조사
베이지안 통계: 비결정적, 변수, 불확실성, 적은 데이터, 근사적, 샘플링, 신뢰도
위와 같은 특성들을 기반으로 베이지안 통계(Bayesian Statistics)가 기존의 고전적인 통계(Classical Statistics)와 어떤 차이점이 있는 지 다양한 예시를 들어 살펴보도록 하자.
2.1 고전적 추론 vs 베이지안 추론
통계추론의 핵심 중 하나는 주어진 데이터(: 확률변수, : 관측치)를 이용하여 미지의 관심 모수 를 추정하는 것이다. 를 미지의 관심 모수 에 의존하는 확률변수 의 분포의 밀도 함수라 가정하자.
고전적 추론 – MLE
고전적 추정의 대표적인 방법 중에는 최대 우도 추정(Maximum Likelihood Estimation; MLE)가 있다. 데이터()가 주어진 경우 매개변수()의 가능도를 나타낸 가능도 함수 는 아래와 같이 정의된다. 가능도 함수는 일종의 사후분포라 할 수 있다.
=
즉, 데이터 가 에 대한 정보를 가지고 있을 것이기에, 데이터 를 통해 매개변수 를 추측하는 것이다. 단, 이 때 가 의 분포를 결정하지, 가 의 분포를 결정하는 것은 아니다. 이 때 최적의 매개변수를 뜻하는 최대 우도 추정량()은 아래와 같이 정의한다.
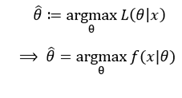
베이지안 추론 – prior distribution
이에 대응하는 베이지안 추론은 큰 틀은 비슷하지만, 베이즈 정리를 이용한다는 점에서 큰 차이가 있다.
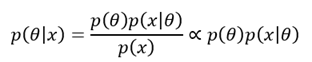
즉, 관측치 가 주어진 이후 매개변수 의 확률 분포인 , 즉 사후분포를 얻기 위해 사전분포인 와 데이터 를 모두 활용하는 것이다.
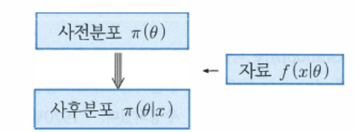
(베이지안 추론의 개념도)
2.2 신뢰 구간 vs 신용 구간
고전적 추론 – 신뢰구간(Confidence Interval)
고등학교 확률과 통계에 나온 신뢰구간이 여기서의 Confidence Interval에 해당한다. 추론하고자 하는 의 신뢰도를 갖는 신뢰구간은 아래와 같은 방식으로 정의된다.
즉, 특정 를 추정하기 위해, 를 상수로 가정한 후 신뢰도 를 갖는 신뢰 구간을 정의한다. 그 후, 데이터가 로 관측됐을 때 위 식에 ‘대입’하여 관측 값에 대한 신뢰구간을 사용한다. 예를 들어, 95%의 신뢰도로 매개변수 (여기서는 모평균 )를 추정한다고 가정해보자. 이 때 신뢰구간은 아래 그림과 같은 의미를 가진다.
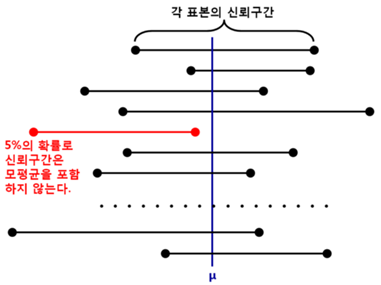
위의 그림은 95%의 신뢰도로 를 추정한다는 것은 가 해당 신뢰구간에 포함될 확률이 95%라는 것이 아니라, 를 포함하는 신뢰구간이 약 100개 중 95개에 해당할 것이라는 사실을 보여준다. 즉, 신뢰 구간은 데이터가 로 관측될 때, 가 해당 신뢰구간에 포함될 확률은 아래와 같이 이산적으로 나타난다.
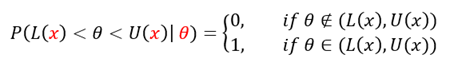
고전적 추론의 관점에서는 를 추정하는 데 를 이미 상수로 가정하고 신뢰구간을 구한 다음, 관측치 를 대입함으로써 신뢰구간을 구하기 때문에 추론에 있어서 직관적이지 못한 것을 알 수 있다.
베이지안 추론 – 신용구간(Credible Interval)
베이지안 추론에서의 신용구간은 위와 같이 추정하고자 할 를 상수로 가정하지 않고 확률변수로 가정한다. 이를 토대로 데이터 가 관측됐을 때, 신뢰구간은 아래와 같이 정의된다.
이를 통해, θ가 구간 (L(x),U(x))에 놓일 확률은 정확히 1-α가 된다.
다시 신뢰구간과 신용구간을 비교하면 아래와 같다.
신뢰구간
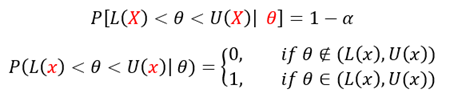
신용구간
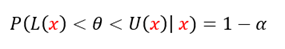
즉, 고전적 추론에서 편이, 분산, 신뢰구간, 가설검정 등의 오차확률은 모든 가능한 X값에 대하여 적분, 합 등의 형식을 취한다. 그렇기 때문에 위의 신뢰구간도 현재 주어진 관측치가 아닌 표본조사를 무한히 반복했을 때 발생할 모든 관측치들을 고려해서 얻어진 것이다. 베이지안 통계추론은 단순히 현재 주어진 관측치에만 의존하기 때문에 빈도론자들의 통계추론(고전적 통계추론)과는 관점이 다른 것을 알 수 있다.
2.3 Simulated Annealing vs Markov Chain Monte Carlo
담금질 기법(SA; Simulated Annealing Method)과 마르코프 체인 몬테 카를로(MCMC; Markov Chain Monte Carlo Method)은 특정 model의 매개변수 벡터 θ를 추정하기 위한 최적화(Optimization) 기법들이다. 이를 고전적 추론과 베이지안 추론을 구분 짓는 잣대를 위한 예시로 사용한 이유는 담금질 기법은 매개변수 θ를 결정적으로 추정하고 몬테 카를로 마르코프 체인은 매개변수 θ를 비결정적으로 추정하는 데에 있다.
이를 위해 담금질 기법을 사용해 매개변수를 추정했던 본인의 연구를 예시로 들어보자.

해당 연구에서는 한국 내의 코로나19 감염병의 전파를 기술하기 위해 아래와 같은 모델을 정의한 후, 2020년의 보건 복지부 데이터(신규 확진자, 격리자, 회복자, 격리 기간, 무증상 확진율 등)을 이용해 매개변수를 추정(최적화)하는 과정이 포함되어 있다.
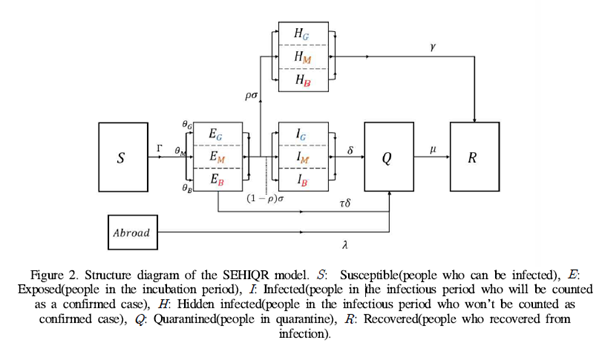
(감염병 전파를 위한 모델)
위 그림에 나타나 있는 매개변수들은 예측 확진자와 실제 확진자의 차이(MSE)를 줄이는 방향으로 최적화된다.
2.3.1 담금질 기법(Simulated Annealing)을 이용한 최적화

담금질 기법은 실제 금속공학에서 쓰이는 담금질에서 모티브를 얻어 최적화 문제에 적용된 기법이며, 실제로는 아래와 같이 매우 어려운 조합 문제인 Travelling salesman problem을 해결하기 위해 도입된 것으로 알려졌다.
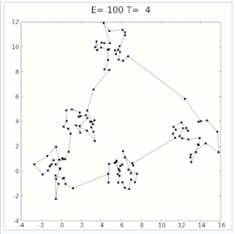
https://en.wikipedia.org/wiki/File:Travelling_salesman_problem_solved_with_simulated_annealing.gif
{kind=link}
이런 조합에 관한 문제 외에도 연속적인 매개변수를 추정하기 위해 쓰이기도 한다.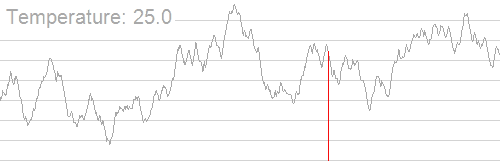
https://en.wikipedia.org/wiki/File:Hill_Climbing_with_Simulated_Annealing.gif
{kind=link}
한 마디로, 온도가 높을 때에는 매개변수 공간(parameter space)를 넓은 보폭으로 전역적으로 탐색해 전역 최적점을 근사적으로 살펴본 다음, 온도가 낮아짐에 따라 좁은 보폭으로 지역적인 최적점을 향해 나아가는 방법이다.


(코로나19 연구에 사용된 담금질 기법 기반 알고리즘)
Parameter 추정 결과
이 기법을 통해서 추정된 모든 매개변수들은 결정적으로(즉, 상수로) 정해진다.
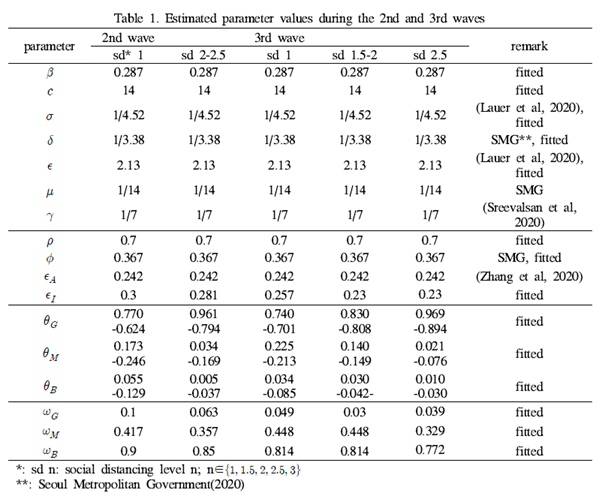
즉, 담금질 기법은 어느 정도 주어진 problem에 대해 매개변수 벡터인 θ에 대한 근사적인 전역 최적 값(Global optim)을 제공한다. 하지만 이 방법 또한 근사적인 방법이기 때문에 전역 최적 값이라는 보장은 없으며, 매개변수가 많아짐에 따라 전역 최적 값에 근사하는 매개변수 조합이 많아 지기 때문에 추정된 매개변수가 진정 옳은 지에 대한 통찰은 주지 못한다. 즉, 추정된 매개변수의 신뢰도와 관련해서는 어떠한 정보도 주지 못하는 것이다. 그렇기에 다른 방법을 활용해 매개변수의 신뢰도를 제고할 필요성이 있다.
2.3.2 마르코프 체인 몬테 카를로(MCMC)를 이용한 최적화
기본적으로 매개변수 추정과 관련해 현존하는 연구들은 상당히 많은 수가 (베이지안적 관점의) MCMC 기법을 사용하며, 쓰이는 알고리즘이 변형되더라도 기존의 큰 틀은 벗어나지 않는다.

(상당히 많은 수의 연구가 MCMC 기반 기법들을 사용한다.)
몬테 카를로와 관련해서는 후술하기로 하고, MCMC 기법의 결과에 대해서만 간단히 알아보자.
(위키디피아에서의 MCMC)
MCMC는 간단히 말하면 샘플링을 통해 구하고자 하는 매개변수의 분포를 모사하는 기법이다.
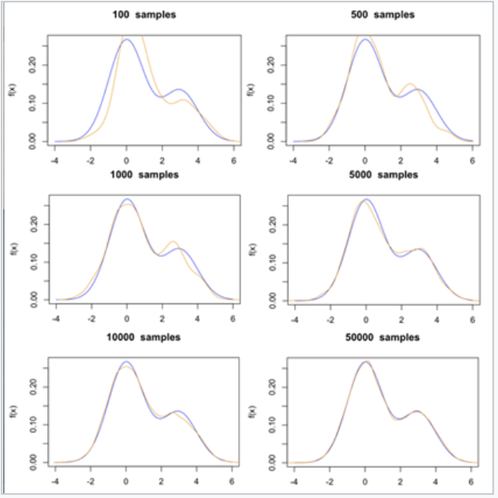
(샘플이 많아짐에 따라 목표 매개변수(파란 선)의 분포를 모사하는 모습)
MCMC기법을 활용해서 매개변수 θ의 분포를 추정한다면 해당 매개변수가 비결정적으로 정해지며, 신용구간 또한 구할 수 있는 장점이 존재한다. 이 장점으로 인해 매개변수를 추정(최적화)하는 대부분의 연구에서는 매개변수의 최적 값 외에도 95% C.I(Credible Interval)을 포함하는 것으로 보인다.
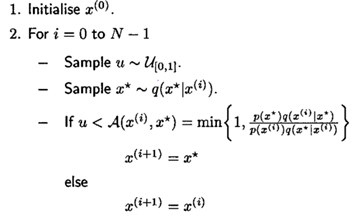
(MCMC 알고리즘 중 대표격인 MH(Metropolis-Hastings) 알고리즘)
Parameter 추정 결과
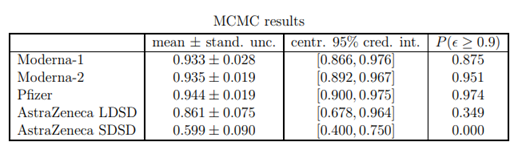 (MCMC기법은 최적 값 뿐만 아니라 95%의 신용구간 또한 구할 수 있다.)
(MCMC기법은 최적 값 뿐만 아니라 95%의 신용구간 또한 구할 수 있다.)
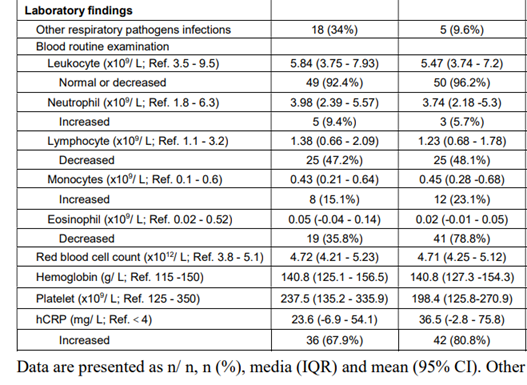
(MCMC기법이 아니여도 보통 특정한 수치를 추정할 때에는 95% CI를 포함한다.)
2.3.3 문제 예측 - 결정적 최적화 vs 비결정적 최적화
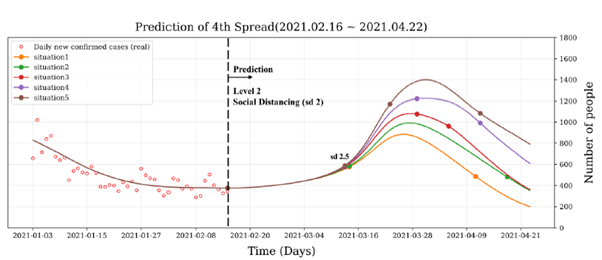
(담금질 기법의 결정적인 매개변수의 경우)
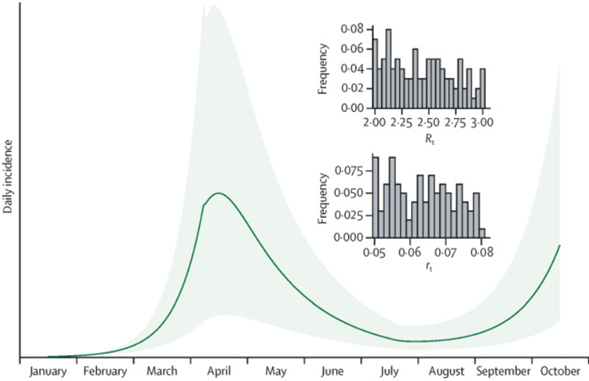
(MCMC 관련 기법의 비결정적인 매개변수의 경우)
위 그림의 차이와 같이, 매개변수가 결정적으로 정해진다면(즉, 상수로 여겨진다면) 목표 통계량(여기서는 신규 확진자)에 대해 (다양한 상황을 가정하지 않는 한) 하나의 결과만을 나타낼 수 있지만 매개변수 비결정적으로 정해진다면(즉, 분포로 여겨진다면) 같은 통계량에 대해서 95% 신용 ‘구간’을 나타낼 수 있게 된다. 이처럼 베이지안 기반 통계는 매개변수나 통계량 자체에 ‘신뢰도’, 혹은 ‘오차’ 등에 대한 정보를 제공함으로써 보다 풍부한 추론을 가능케 한다.
3. 베이지안+ 딥러닝 + 강화학습 = AlphaGo
3.1 몬테카를로
몬테카를로(Monte-Carlo)는 도시국가인 모나코 북부에 있는 지역으로 카지노, 도박으로 유명한 곳이다. 수학의 확률이론 자체가 도박에서 비롯되었기에 도박 도시의 대명사였던 몬테카를로 역시 확률론과 밀접한 관계가 있는 방법론을 지칭하기도 한다.
즉, 몬테카를로 방법이란 무작위 추출된 난수를 이용해 함수의 값을 계산하는 통계학적 방법으로, 수치적분이나 최적화 등에 널리 쓰인다.

적분 문제 중 면적 계산을 예로 들어보자. 위 그림에서 검은 실선에 의해 구분되는 파란색 영역의 넓이를 구하고자 할 때, 함수로 표현하기 힘들거나 이론적인 적분 값을 구하기 힘든 경우 몬테카를로 기법을 사용할 수 있다. 이 때, 정사각형으로 이루어진 영역의 상태 공간에서 임의로 샘플(데이터)을 뽑는다. 정사각형의 넓이는 알고 있기 때문에 정사각형 내부의 총 샘플 수와 파란색 영역에 속하는 샘플 수의 비율을 이용하면 파란색 영역의 넓이 또한 근사적으로 알 수 있게 된다.
오늘날 인터넷 상에는 적분 계산기(Wolfram Alpha 등)가 많이 존재하므로 특정 방정식에 대해 이론적인 면적을 계산하지 못하는 경우가 많지는 않다. 하지만 특정 영역에서는 이론적인 적분을 하지 못하는 경우가 존재하며, 가능하더라도 실행의 용이성 및 연산의 효율성 등의 이유로 몬테카를로 샘플링을 주로 이용하곤 한다.
베이지안 통계 추론에서는 가령 데이터가 주어졌을 때 사후 분포를 구하고, 이로부터 사후 평균이나 분산 등을 구하고자 할 수 있다. 이 경우 평균, 분산과 같은 통계량을 수리적으로 구하기는 어렵지만 사후 분포로부터 표본을 생성할 수 있는 경우가 종종 발생한다.
즉, 아래와 같은 적분 값
을 구하기 힘들 때,
라는 밀도 함수로부터 여러 개의 샘플()을 얻을 수 있다고 가정해보자
이 때 확률에서 기댓값의 정의에 따라 로 나타낼 수 있다.
즉, 로 부터 샘플 를 많이 얻을 수 있다면, 위의 적분 값(또는 이론적 기댓값)은 아래와 같이 n개의 샘플 을 통해 근사적으로 구할 수 있게 된다.
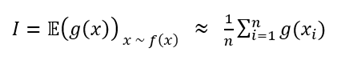
이처럼 샘플(난수)의 개수를 더욱 많이 발생시킬수록 더욱 정확한 값을 얻을 수 있겠지만, 확률적인 방법론이기 때문에 어느 정도 오차가 발생할 수밖에 없다.
다양한 컴퓨터 시뮬레이션, 예측 등에 쓰이지만 역사적으로 가장 중요한 사례로 미국의 원자폭탄 개발 계획인 ‘맨해튼 프로젝트’를 들 수 있다.

폴란드 출신의 수학자 스태니슬로 울람은 그 유명한 폰 노이만과 함께 맨해튼 프로젝트에 참가하였다. 울람은 새로운 수학적 방법론을 도박의 도시 이름을 따서 몬테카를로 방법이라 명명하였고, 이 방법은 중성자가 원자핵과 충돌하는 과정을 이해하고 묘사하는 데 결정적 역할을 하였다.
즉, 핵분열의 과정에서 우라늄 원자핵과 충돌한 중성자 1개가 다시 중성자 3개를 방출하는데, 이 연쇄반응에서 중성자들은 마치 분기하는 나뭇가지들처럼 복잡한 경로를 보인다. 몬테카를로 방법을 적용한 확률적 시뮬레이션을 통해 이 경로를 파악하고 결과를 ‘추정’할 수 있는 것이다.
3.2 알파고
알파고를 개발한 구글의 딥마인드는 <딥러닝 신경망과 트리 검색으로 바둑 마스터하기(Mastering the game of Go with deep neural networks and tree search)>라는 제목으로 네이처 논문에 알파고의 기반 기술과 알고리즘을 자세히 설명해 놓았다. CPU 1,202개, GPU 176개 등 분산 컴퓨터, 정책망 및 가치망으로 이루어진 신경망, 과적합 방지를 위한 지도학습과 강화학습의 결합, 고속 시뮬레이션, 롤아웃 등 중요한 요소 또한 존재하지만 여기서는 핵심적인 알고리즘인 몬테카를로 트리 서치의 기본 구조만을 나타내었다.
몬테카를로 트리 서치
바둑은 가로세로 19줄로 이루어진 바둑판 위에 흑돌과 백돌이 서로의 집을 만들고 세력 다툼을 하는 개념의 게임이다. 숫자로 계산해보면 바둑에서 착수가 가능한 모든 패턴은 약 10^171 가지로, 우주의 모든 원자 개수인 약 10^81보다도 훨씬 많다. 그렇기에 컴퓨터의 연산 능력이 아무리 좋아져도 바둑은 절대 인간을 이길 수 없다는 의견이 지배적이었는데, 알파고 기반 인공지능은 어떻게 인간을 압도하는 성능을 가지게 됐을까?
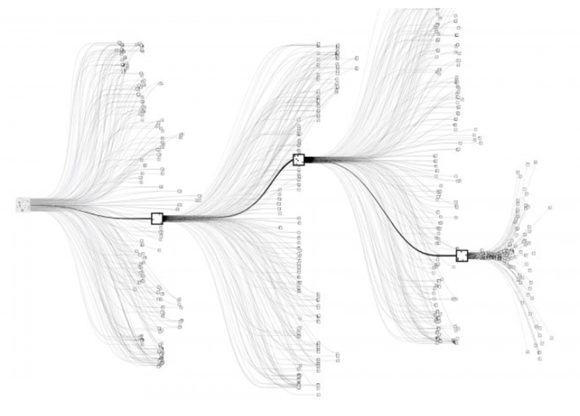
몬테카를로 트리 서치는 Min-max 알고리즘의 성능을 개선한 알고리즘으로, 모든 경로를 탐색하기 불가능한 상황에서 효율적이다. 간단히 말해 ‘경우의 수가 너무나도 많을 때 순차적으로 시도하는 것이 아닌 랜덤하게 시도하는 것’ 이다.
바둑은 착수 후 상대방이 어디에 둘 것인지, 또 그 다음 수는 어디에 둬야할 지 계속해서 선택과 경우의 수가 굉장히 많이 발생한다. 그렇기 때문에 무작위로 일정 횟수만큼 착수를 한 다음, 그 중 가장 승률이 높은 수를 두게 되는 것이다. 이를 위해 고속 시뮬레이션, 롤아웃, 분산 컴퓨팅 등 다양한 보조 기법들이 사용되었다.
4. 베이지안 딥러닝 / 메타러닝
4.1 베이지안 뉴럴 네트워크(BNN)
기존의 뉴럴 네트워크는 뉴런들 사이에 존재하는 layer들의 parameter가 상수로 부여되는 반면, 베이지안 뉴럴 네트워크는 그 parameter 자체를 하나의 분포로 생각한다. 즉,학습을 할 때에는 parameter의 확률 분포에 해당하는 모수(예를 들어 정규분포에서는 평균과 분산)를 학습하고, 예측을 할 때에는 그 분포로부터 샘플링을 통해 얻음으로써 95% 신뢰도를 부여한 불확실한 예측을 하는 것이 베이지안 뉴럴 네트워크의 특징이다.
즉, 불확실성(Uncertaintiy)를 다루기 위해 ‘모르는 건 모른다고 하는 모델’을 만드는 것이다. 가령, 이미지 분류 모델에서 개와 고양이를 대상으로 학습을 시킨 다음, 자동차를 분류 예측에 사용한다면 자동차 이미지는 개 또는 고양이에 해당하는 결과를 낼 것이다. 베이지안 뉴럴 네트워크는 이처럼 어떻게든 결과를 내는 것이 아니라, 만약 자동차 이미지의 분류 결과가 고양이일 확률 40%, 강아지일 확률 60%의 분포를 갖는다면, 모델로 하여금 ‘모르겠다’ 라는 반환 값을 내놓게끔 설계된 것이다.
이러한 불확실성은 신뢰도가 필요한 분야(의학, 자율주행) 등에서 활용될 수 있다. 예를 들어 운전을 할 경우에는 언제 어떤 사고가 일어날 지 모르기 때문에 초록 불이라 해서 그냥 속도를 계속 내서는 안 된다. 차가 갑자기 들어올 수도, 갑자기 빨간 불이 될 수도 있기 때문에 항상 불확실성을 염두에 두고 판단을 내려야 하는 것이다.
이러한 BNN과 유사한 역할을 수행할 수 있는 것이 흔히 알려진 Dropout이다. 가령, Dropout을 학습 때만 적용하고 Evaluation 단계에서는 사용하지 않는 것이 보통이지만, Evaluation 때에도 dropout을 사용한다면 시행마다 결과가 조금씩 다를 것이고, 이로부터 불확실성(Uncertainty)를 추정할 수 있게 된다(Monte Carlo Dropout 등).
베이지안 딥러닝(베이지안 뉴럴 네트워크)가 보여준 것처럼 인공지능 모델의 블랙박스 특성에 대해 고찰하고, 신뢰도 등을 제고하려는 노력은 이 네트워크가 큰 그림에서 볼 때 XAI(eXplainable AI, 설명가능한 인공지능)에 속할 수 있다는 것을 암시한다.
국내 인공지능 솔루션 스타트업 중 하나인 에이아이트릭스(AITRICS) 또한 인공지능의 해석 가능성을 높이기 위해 ‘해석 모듈(Interpretation module)’과 결과에 대한 불확실성을 계산하여 신뢰도를 제공하는 ‘베이지안 뉴럴 워크(Bayesian neural networks)’ 기술을 도입했다고 한다.
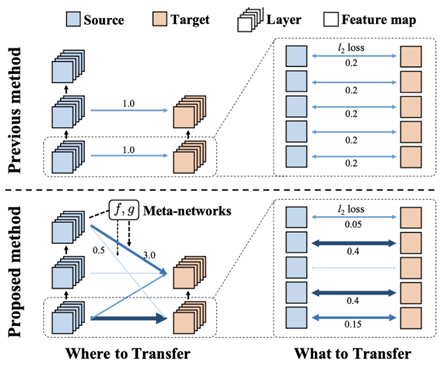
(에이아이트릭스 메타트랜스퍼(AITRICS metatransfer) 방법, 메타 네트워크 f와 g는 채널의 중요도에 따라 두 네트워크의 레이어 사이에 전달할 지식의 양을 결정한다.)
이에 추가로 베이지안 뉴럴 네트워크와 시계열 모델(attention)을 결합해 시계열 데이터에서 불확실성을 고려한 의사 결정을 할 수 있는 ‘Uncertainty-awre attention mechasim’, 전이 학습(transfer learning)의 전이 방식이 해석하기 까다롭다는 문제를 해결하기 위해 ‘meta learning method’ 등을 제안하였다. 메타러닝 방법론을 이용해 특정 task를 해결하기 위해 어떠한 task에서 얼마만큼의 지식을 끌어와야 하는지, 또 그런 지식들이 현재 문제를 풀기위한 딥 네트워크의 어떠한 파라미터를 최적화하는 데 주로 사용되어야 하는지를 학습하는 방법론으로, 결과의 근거를 유추하여 해석을 가능하게 하며 전이 학습의 효율성을 증대시켜, 예측 성능을 큰 폭으로 향상시킬 수 있다고 한다.
4.2 Meta-Learning is All You Need
메타러닝의 전반적인 지식과 블랙박스 메타러닝, 최적화 기반 메타러닝, 비모수(Non-parametric) 메타러닝 등을 살펴본 논문으로, 여기서도 베이지안 기반 메타러닝에 관한 내용이 소개되었다.



(메타러닝 문제는 대략적으로 결정적 관점과 확률적 관점 두 가지로 나뉜다.)
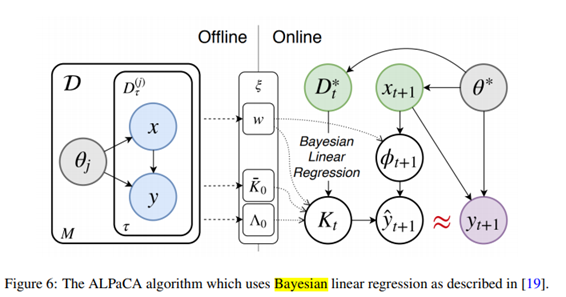
(베이지안 선형 회귀를 사용한 ALPaCA 알고리즘)
특히, 저자는 글의 마지막에도 메타러닝에는 베이지안 메타러닝과 메타 강화학습 등과 같은 흥미로운 분야가 많다고 얘기하며, 메타러닝을 사용해 헬스케어나 제조업 등 다양한 실생활 분야에 적용하기를 기대한다며 논문을 끝마치기도 한다.
이처럼 베이지안 관련 통계 기법들은 반 세기 전 원자폭탄부터, 최근 인공지능 분야까지 폭 넓게 쓰이고 있다. 앞으로 더욱 완벽한 인간 중심 인공지능을 개발하기 위해 설명 가능 인공지능, 강화 학습 등이 끊임 없이 발전하고 있는 상황에서 베이지안-식 관점을 가지고 문제를 바라본다면 이전 보다 흥미로운 접근이 가능할 것이라고 생각한다.
5. Ref
Predictability of case evolution of COVID-19 using MCMC | by Thomas Vergote | Medium
What is the probability that a vaccinated person is
shielded from Covid-19?
Simulated annealing - Wikipedia
Markov chain Monte Carlo - Wikipedia
모평균의 구간추정 예시 : 네이버 블로그
최근 머신 러닝 핫한 연구 분야 (1/3) :: 취미생활하는 공대생 (tistory.com)
머신러닝 메타러닝(Learning To Learn) (tistory.com)
베이지안 메타 학습 만 있으면됩니다 (ichi.pro)
닥터박 :: 알파고, 몬테카를로 트리탐색 (tistory.com)
몬테카를로 방법과 인공지능 – Sciencetimes
일부 이론 : 베이지안 통계학, 2021년 서울시립대학교 통계학과 전공 수업
