이번 주차에서는 지난 주차의 디지털 신호처리에 이어 음성 모델링 방식인 Source Filtering 모델을 살펴본 후, 딥러닝 이전에 많이 사용된 음성 합성 모델인 Unit-Selection과 HMM 모델을 살펴보고자 합니다.
1. Source Filtering
Source-Filtering 모델은 사람이 말을 하는 과정을 그대로 수학적으로 모델링하는 방식입니다. 사람의 음성은 폐에서부터 신호가 발생기관을 통과하면서 주기적 신호로 만들어 지고, vocal tract을 거치며 조음을 통해 만들어 지게 됩니다.
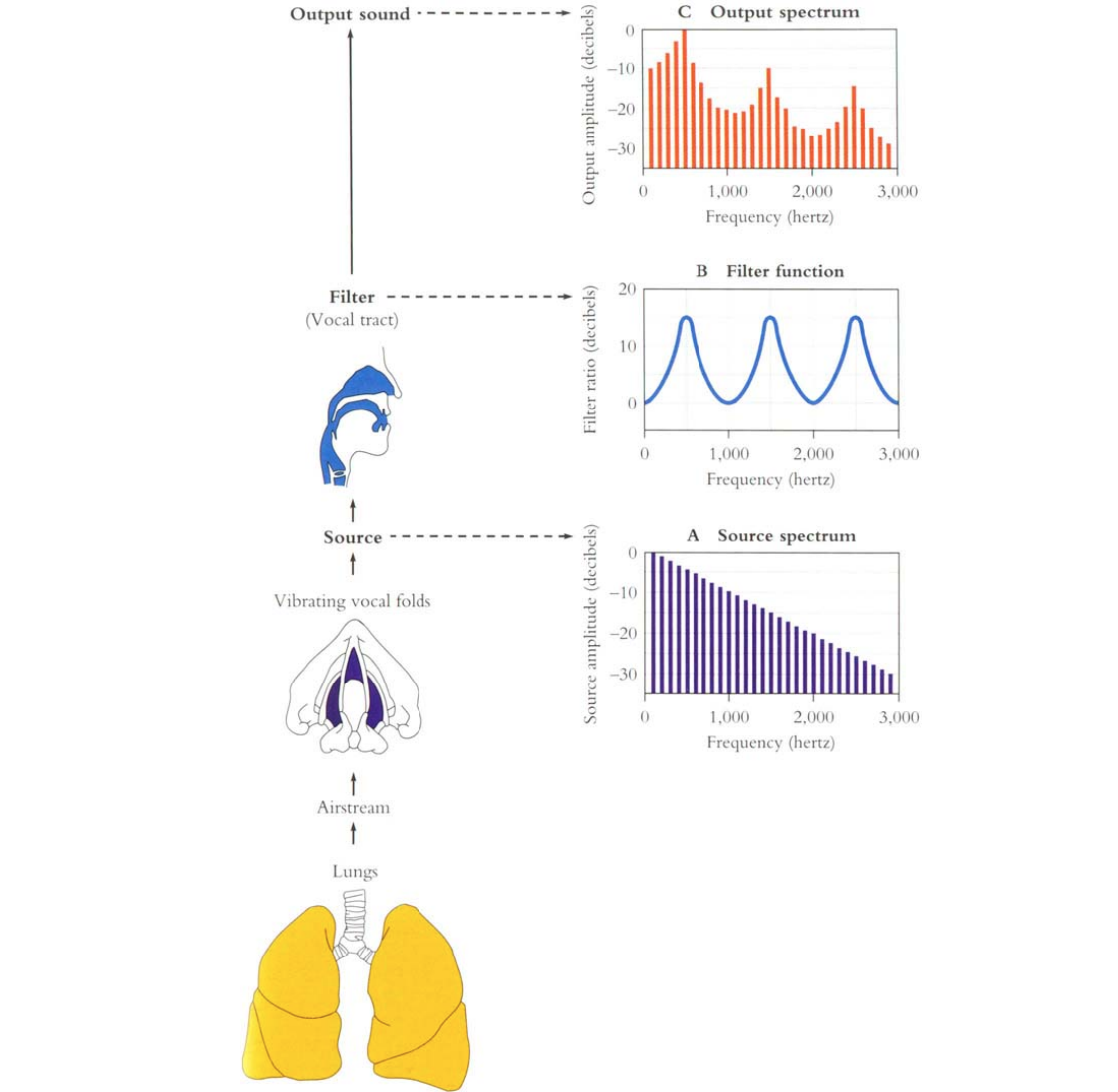
- Vocal Fold는 진동을 하며 harmonics와 noise를 만들게 되고, 이때 harmonics 는 voiced sound, noise를 unvoiced sound라고 합니다.
위 그림에서 vocal fold로부터 발생한 source spectrum을 살펴보면 가장 큰 amplitude를 가진 주파수가 fundamental frequency(), 그 이후는 fundamental frequency의 배음들인 harmonics입니다. 이후 신호들은 발음기관의 특성에 따라 고주파로 갈 수록 그 크기가 작아진다는 것을 볼 수 있습니다. - Vocal Tract의 경우, vocal fold에서 생성된 source를 통과시켜 보낼 때 해당 조음기관의 형태에 따라 말하고자 하는 음성의 형태를 결정합니다. 이러한 특성 때문에 vocal tract는 수학적으로 filter의 역할을 가집니다. 해당 transfer function을 가지는 vocal tract를 통해 주파수 성분의 모양이 결정되기에 envelop 이라고도 합니다.
- Output Spectrum은 source spectrum이 filter function을 거쳐서 만들어 집니다. 성대에서 만들어지는 'source'모델, 각 vocal cord의 'filter'를 통해 얻어지기에 이를 합쳐 Source-Filter Model이라 합니다.
1.1 Source: Glottal Waveform
Source-Filter 모델에서의 source가 어떻게 얻어지는지 살펴봅시다.
Vocal fold로부터 나온 voiced 성분의 경우 주기적인 harmonics를 가지게 됩니다. 이때 가장 기본적인 주파수를 fundamental frequency()라 합니다.
fundamental frequency는 사람이 느끼는 음의 높낮이와는 조금 차이가 있으며, 높은 주파수에서보다 낮은 주파수에서 음의 변화를 잘 구분하는 인간의 귀에 맞추어 변환을 시킨 것을 pitch라고 합니다.
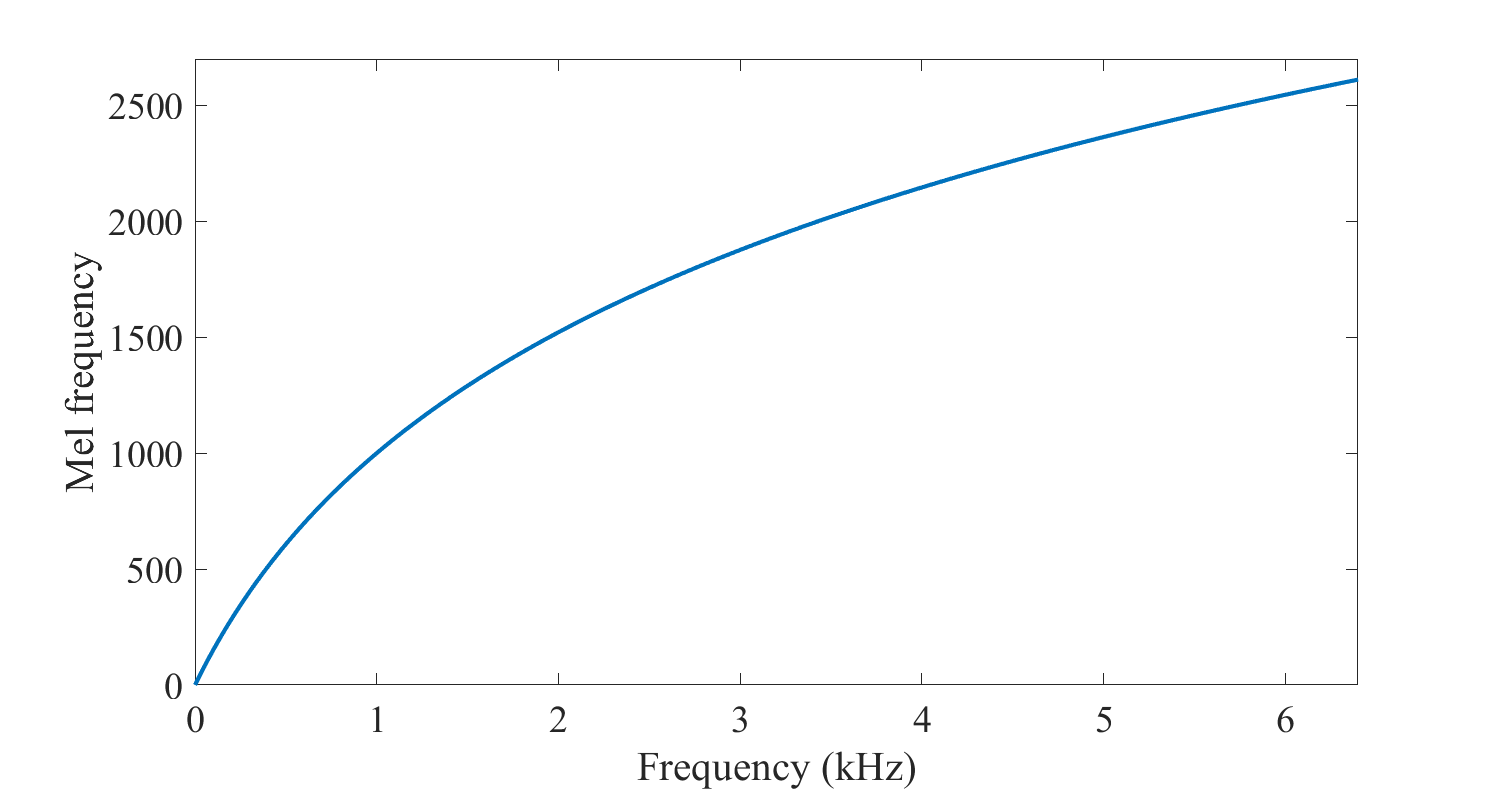
Pitch는 를 mel scale변환함으로서 얻을 수 있는데 이때의 mel scale은 위의 그림과 같이 로그 함수적인 모습을 가지게 됩니다. 이는 인간의 청각이 절대적인 주파수와 linear 하게 음의 높낮이를 구분하지 않다는 것을 반영한 것이라 볼 수 있습니다.
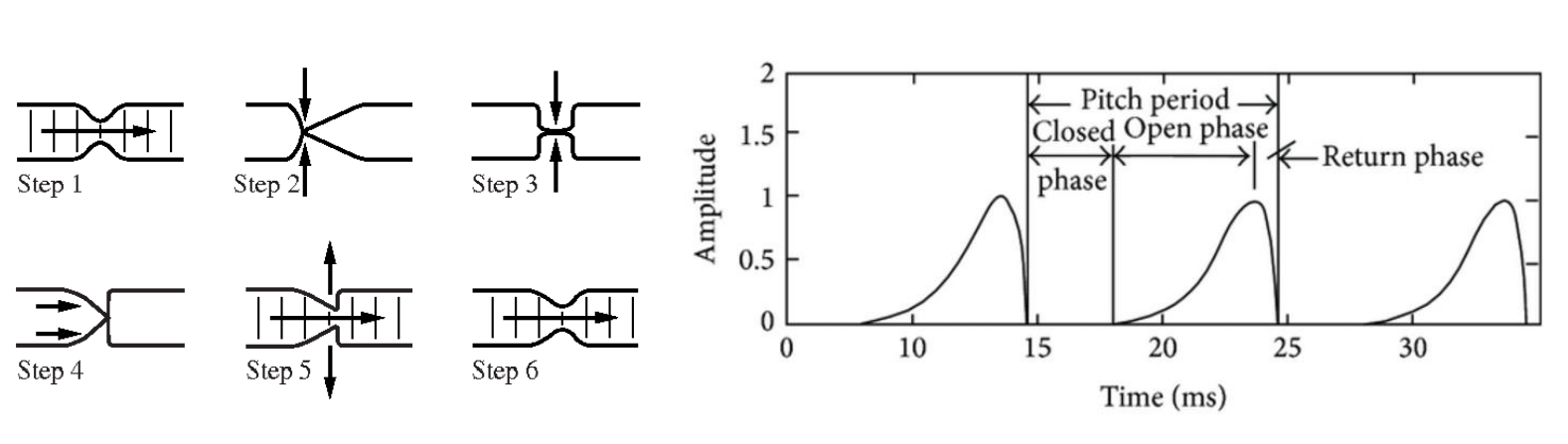
위의 그림은 voiced sound를 만들 때 성대의 모습과 그 때의 소리를 표현한 것입니다. 성대가 열리고 닫히는 과정에서의 통과하는 공기를 시간에 따라 바라본 것인데 time domain에서 각 주기별 glottal(glot: 성문) wave form이 어떻게 형성되는지 볼 수 있습니다.
Pitch Period: 한 주기
Closed Phase: 성대가 닫혀 있을 때
Open Phase: 성대가 열려 있을 때
성대가 열리고 닫히는 하나의 pitch period를 기반으로 전체 glottal wave form은 다음과 같이 수학적으로 모델링이 가능합니다
- : 한 주기의 glottal wave from
- : impulse train
Impulse train 과 한 주기의 glottal wave 을 convolution 함으로서 glottal wave form을 얻을 수 있습니다.
이를 주파수 영역으로 푸리에 변환 시 convolution은 곱으로 되어 아래와 같이 나타낼 수 있습니다.
Time domain, frequency domain으로 나타낸 신호를 보았을 때 impulse function으로부터 나온 impulse response가 주기적으로 나오는 것을 볼 수 있습니다.
1.2 Filter
Source-Filter 모델에서 filter 역할을 하는 vocal tract에 대해 살펴봅시다.
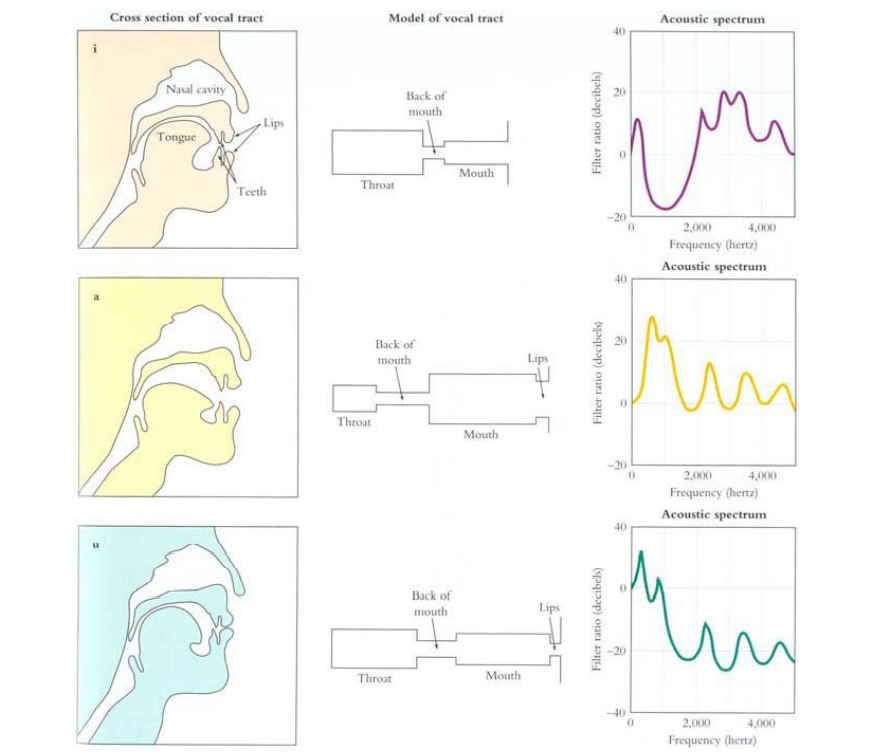
Vocal tract를 위와 같은 tube 형태로 근사시켰을 때, 각 tract의 형태에 따라 공진주파수(resonance frequency)가 변화하게 됩니다. 각 필터의 형태는 극점들만을 이용한 all-pole 모델로 근사가 가능하게 되는데 이때의 transfer function의 각 극점들을 통해 formant를 측정할 수 있습니다
formant: 소리가 공명되는 특정 주파수 대역
Q. formant vs fundamental frequency?
- fundamental frequency: 음의 높낮이에 영향
- formant: 음의 높낮이에는 영향을 주지 않음, 어떤 소리를 만드은지에 영향
Source로부의 신호가 filter를 거치는 과정은 다음과 같이 나타낼 수 있습니다.
- : source로부터의 excitation
- : vocal tract 에서의 impulse response
푸리에 변환을 통해 이를 frequency doain에서 볼 때 위의 convolution은 다음과 같이 나타납니다.
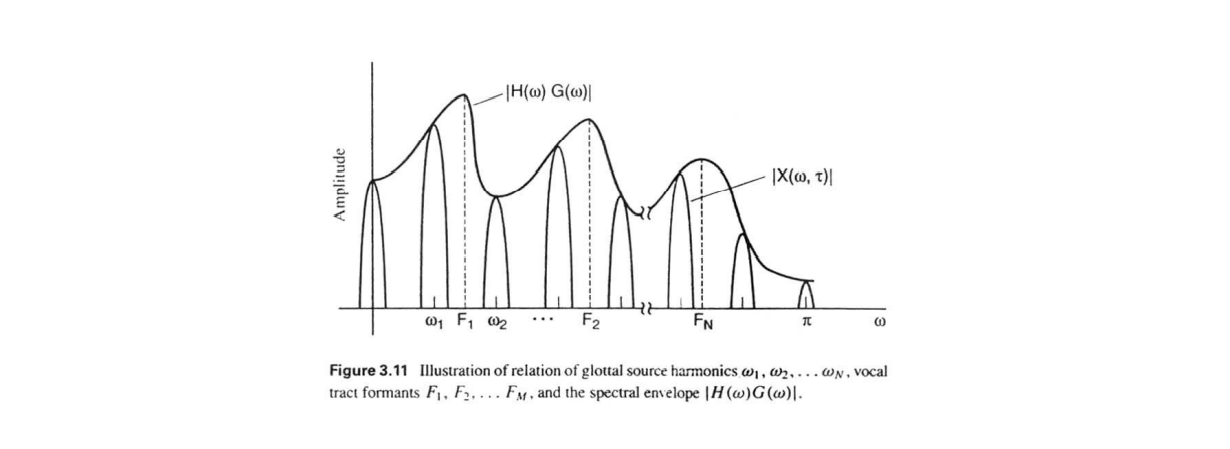
1.2.1 Linear Predicton Analysis
Source-Fiter 모델의 filter를 linear prediction analysis를 통해 구하는 방법입니다.
앞에서 filter는 all-pole 모델로 근사가 가능하며 각각의peak들로 인해 formant가 구성된다는 것을 보았습니다. Pole zero 모델에서 영점인 zero는 입술로 인한 진동, 비음 등의 상대적인 noise 정보를 가지게 됩니다. 때문에 all-pole 모델을 사용해 근사를 하는 Linear Prediction Analysis 는 비음, 파열음 등을 표현하는 데에 약점을 가지고 있습니다.
All-pole 모델을 통해 filter 값을 추정하는 방법은 다음과 같이 수학적으로 계산됩니다.
- : excitation
모델을 시간 영역에서 나타낸 의 현재 값은 이전 시간대들의 linear 결합을 통해 계산된다는 것을 볼 수 있습니다. 이와 같이 현 시점의 샘플을 이전 시간들의 관계값으로 나타내는 것을 auto-regressive 모델 형태라 부릅니다.
LPC에서는 에서의 을 추정하는 predictor를 기반으로 prediction error를 줄여나가는 방향으로 envelop function을 추정하게 됩니다.
추정 error를 줄이기 위해서 기본적으로 추정 Mean Squared Error를 최소화시키는 방법을 사용합니다. 미분시 0이 되는 지점 찾아가는 방법이며 이를 행렬로 나타냈을 때 다음과 같은 식이 도출됩니다.
추정 대상인 는 matrix 의 역행렬을 이용해 구할 수 있습니다.
역행렬을 구하는 대표적인 방법으로는 Auto Corrrelation이 있습니다. Auto correlation 방법은 계산이 비교적 간단하고 안전하기에 linear prediction에서 자주 쓰이는 방법입니다.
Auto Correlation의 Phi 행렬 수식을 보면 자기 자신과, 자기 자신의 시간 차이만을 고려한 형태라는 것을 알 수 있습니다. 이는 곧 현재 상태와 의 연관성을 비교한다는 뜻이며, 시간 차이가 0일 때 현재의 상태와 가장 연관성이 높게 되므로 최대값을 가지게 됩니다.
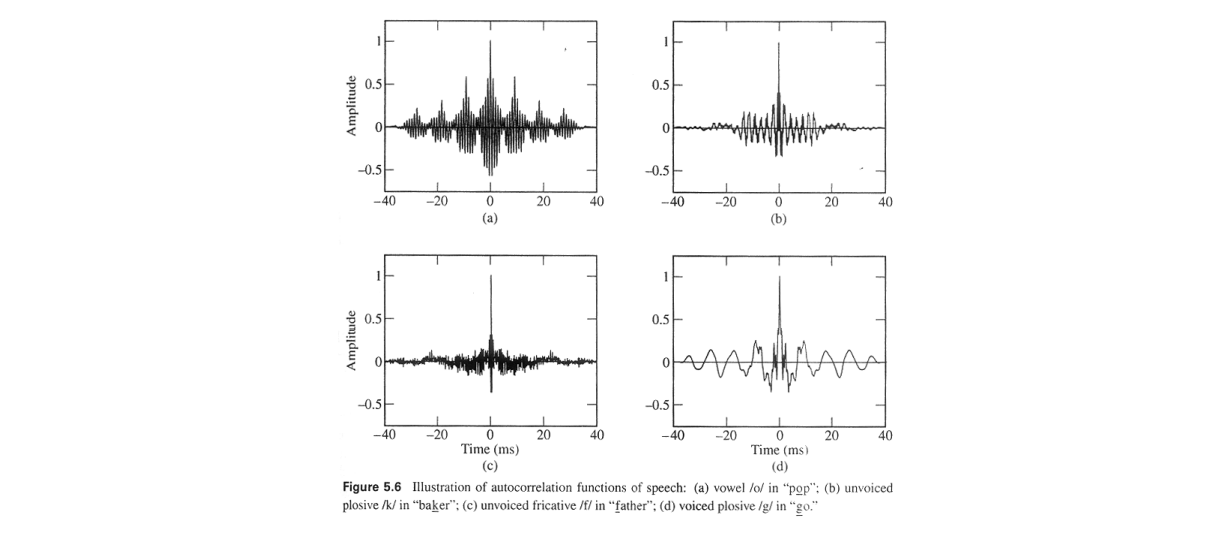
위의 그림은 auto correlation 예시를 주기적 신호(voiced)와 비주기적 신호(unvoiced)의 경우입니다. 주기적 신호의 경우 주기성을 가지고 반복하는 형태를 보이지만, 주기성이 없는 신호의 경우 차이가 없을 때(시간차 = 0) peak가 나타나게 되고 나머지 시간들에서는 잘게 진동만 하며 impulse signal과 비슷한 모양새를 보입니다.
그래서 얼마나 많은 시간들을 볼 것인가?
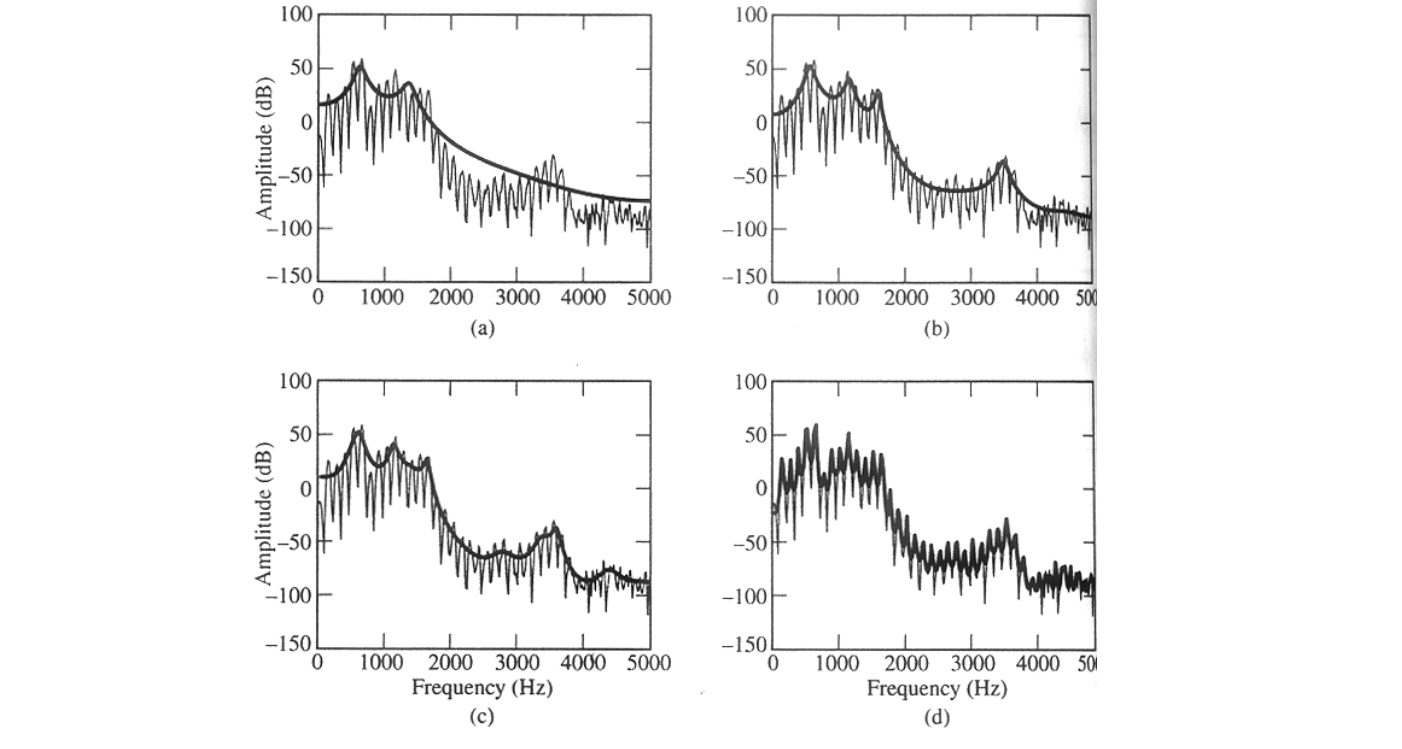
Linear Prediction을 통해 vocal tract의 envelop을 추정할 때에는 현재 시간의 몇 차 전까지 볼 것인지를 정하게 됩니다.
일반적으로 앞의 step들을 많이 볼 수록 성능이 좋을 것이라 생각하기도 하지만 LPC의 차수가 너무 커지게 될 시 배음들인 harmonics 까지 모델링하게 된다는 단점이 있습니다.
이 때문에 보편적으로 높은 차수의 LPC를 보기 보다 10-20 차수의 LPT를 가지고 spectral envelop을 추정하게 됩니다.
1.2.2 Cepstrum Analysis
Source-Fiter 모델의 filter를 cepstrum analysis를 통해 구하는 방법입니다.
앞서 souce-filter 모델이 계산되는 과정에서 source와 filter는 서로 convolution을 통해 합쳐져 있는 형식으로 나타냈었습니다.
Cepstrum analysis는 convolution으로 합쳐셔 있는 혼합된 신호를 두 신호의 덧셈으로 변경하는 homomorphic system을 수행하는 방법입니다.
LP analysis 의 경우 all pole 모델을 가정함을 통해 비음이나 noise 등의 변수에 취약하다는 단점이 있었는데 cepstrum analysis의 경우 그런 가정이 없어 해당 문제로부터 자유롭다는 장점이 있습니다.
Cepstrum 은 신호의 로그에 역 변환을 계산해서 얻을 수 있으며 그 과정은 다음과 같습니다.
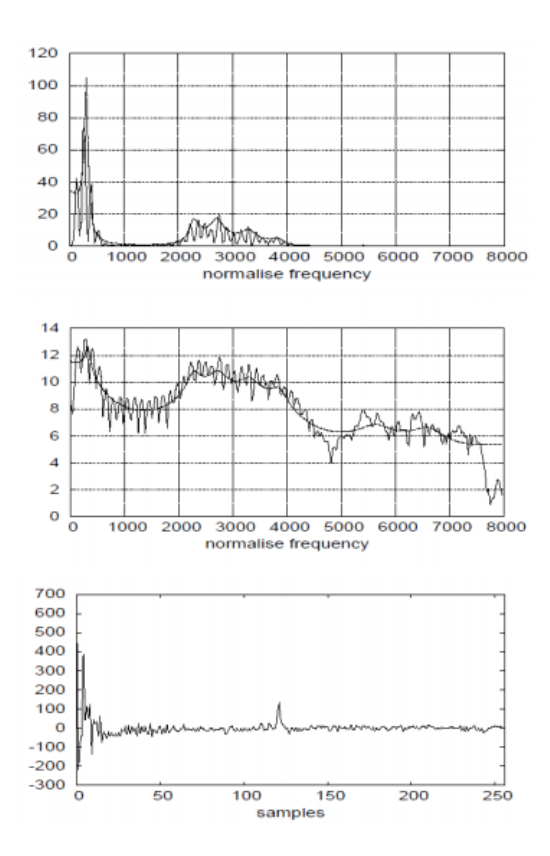
- 주파수 성분들을 보았을 때 고주파로 갈수록 harmonics성분들의 크기가 작아집니다. 이 상태에서는 뒤로 갈수록 전체적인 크기가 작아지기 때문에 excitation 성분을 분리하기 어렵다는 문제가 생깁니다.
- dynamic range를 적절히 맞추어주기 위해 waveform을 log변환 시킵니다. 이때 전체적인 흐름을 envelop, 구간별 빠르게 변화하는 자잘한 성분들을 harmonics로 볼 수 있습니다
- log 변환된 waveform을 inverse DFT 시켜 Cepstrum을 구합니다. 앞쪽의 변화가 큰 쪽이 envelop, 그 이후 뒤쪽에 위치하는 peak 성분들이 각각의 harmonics 를 나타나게 되고 이 상태에서 harmonics를 제거하고 envelop만 남기는 과정을 Lifting이라 합니다.

간단하게 살펴보았을 시 들어온 입력 신호에 대해 DFT를 수행하고 로그 변환을 취한 후, magnitude를 구해 real 값에 대해서 inverse fourier transform을 통해 원하는 filter를 구하는 방법입니다.
1.2.2.1 MFCC
MFCC는 Cepstrum analysis를 통해 얻어져 음성 인식 쪽에 많이 사용되는 feature입니다.
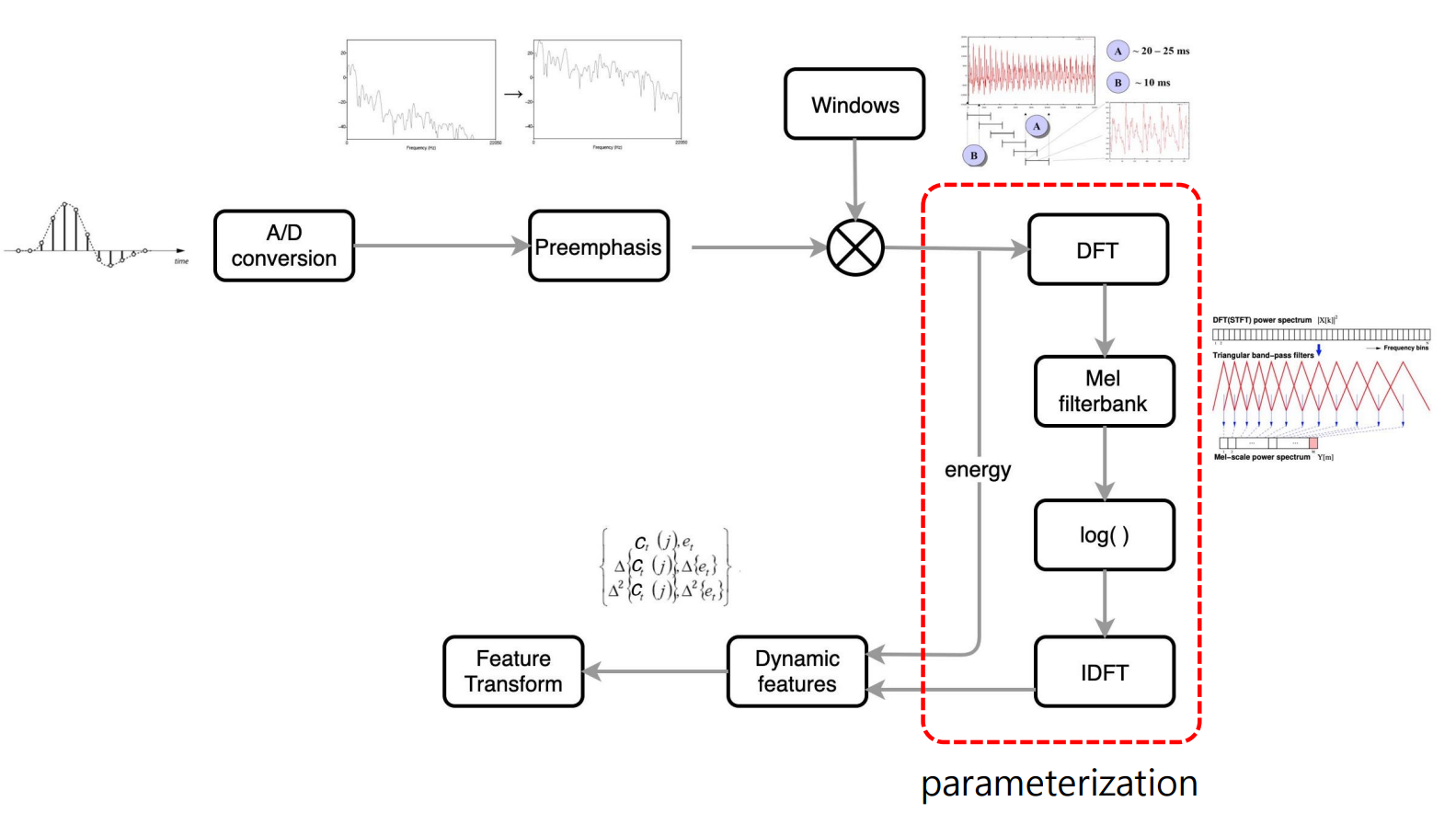
Preemphasis :
대부분의 경우 고주파로 갈수록 신호가 기울어지는 spectral tilt를 보이게 됩니다. 이때 pre-emphasis는 고주파 에너지를 boosting시켜 높은 차수의 formant 정보를 시스템이 활용할 수 있도록 합니다.
1.2.2.1 MGC (Mel Generalized Cepstrum)
MGC는 음성 합성에서 주로 이용하는 feature로 all-pole 모델의 linear prediction과 ceptral analysis 방식을 모두 사용하고자 하는 모델입니다.
음성 합성의 특성 상 최대한 많은 feature를 가지고 있어야 신호 복원시 유리하기에 두 가지 모델을 모두 사용하여 각각의 장점을 취하고자 한 모델입니다.
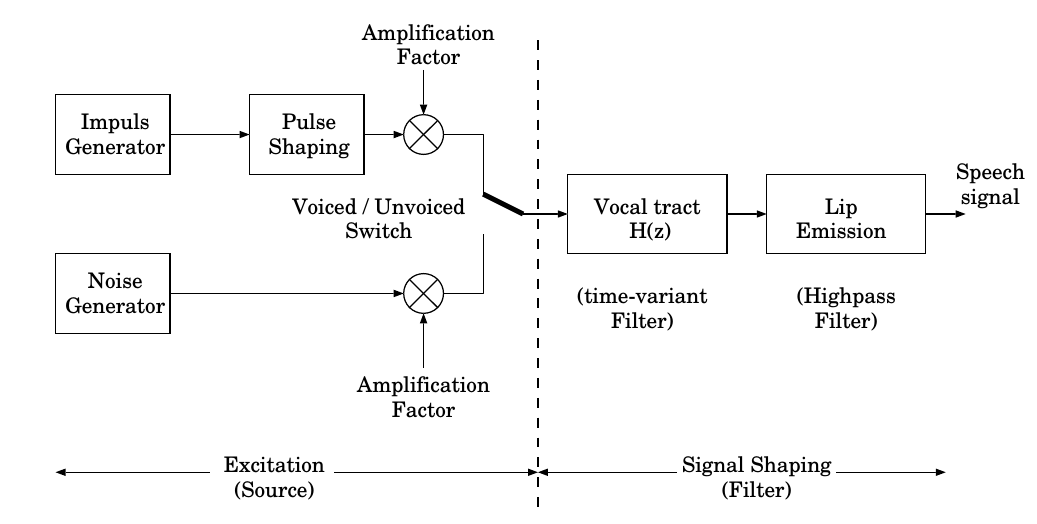
Source-filtering 모델의 전체적인 구조입니다.
Source excitation 은 pulse train과 white noise를 통해 표현이 되며 이후 vocal tract 의 공명주파수에 기반해 filter 함수가 만들어지게 됩니다. 이때의 filter 함수는 LPC, Cepstrum analysis를 통해 얻을 수 있습니다.
2. Speech Synthesis
음성 합성은 text가 주었을 때 그것을 음성으로 변환해 주는 system입니다.

기본적으로 text 보다는 speech가 정보량이 훨씬 더 많으므로 speech synthesis는 정보량이 적은 것으로부터 큰 것을 생성해 내야 하는 어려움이 있습니다.
음성 합성의 목표
- Intelligibility - 얼마나 또박또박 발음하는지
- Naturalness - 얼마나 사람의 목소리와 유사한지
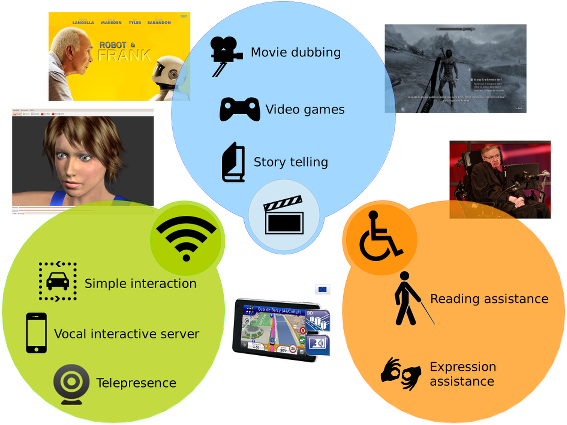
게임 소리, 스마트폰 ai비서, 장애인 안내, 이북 등 음성 합성은 매우 다양한 분야에서 활용되고 있습니다.
기존의 음성 합성 방법들은 크게 rule based 방식, 데이터베이스 방식, 통계적 방식, 딥러닝 방식이 있는데 이번 주차에서는 딥러닝 이전 초기 방식들인 데이터베이스 방식과 통계적 방식을 살펴봅니다.
2.2 Unit Selection
Unit-Selection 방식은 concatenated synthesis라고도 부르며 실제 speech 데이터베이스를 기반으로 음성 합성을 하는 방식입니다.
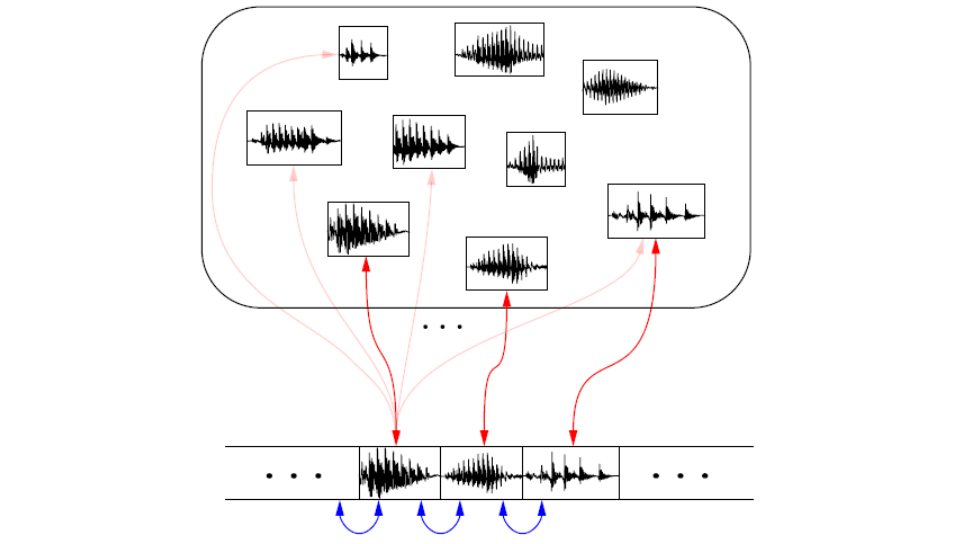
실제 음성을 사용하기 때문에 음질의 퀄리티 측면에서는 좋은 결과를 보이지만 데이터가 커야지만 다양한 발화를 할 수 있게 되며 감정부여, 의문문/평서문 등 어조의 면화를 주어야 하는 경우 이를 실현시키기가 어렵다는 단점을 가지고 있습니다.
Unit selection에 사용되는 데이터는 긴 길이의 syllable부터 두 개의 phone을 이어붙인 diphone조각들까지도 가능합니다.
다양한 길이의 음성 unit들은 greedy search, beam search 등의 알고리즘을 통해 최종 사용할 unit들의 경로를 찾아가게 됩니다. 이때 효율적인 경로를 찾기 위해 각 선택에 대한 cost 값을 두 가지 관점에서 계산합니다.
- Target Cost: 현재 연결하는 cost가 target과 얼마나 차이가 있는지
- Concatenation Cost: 음성 합성의 naturalness를 높이기 위해 직전의 unit과 현 unit의 연결점이 얼마나 잘 이어지는지
현재는 정해져 있는 데이터를 짜집기하는 방법의 특성 상 naturalness, flexibility, 데이터 용량 면에서의 단점들로 인하여 자주 사용되고 있지 않습니다.
2.3 HMM(Hidden Markov Model)
HMM 방법은 통계적 SPSS(Statistical parametric speech synthesis) 음성합성 방법으로 여러가지 모듈을 거쳐서 이루어지게 됩니다.
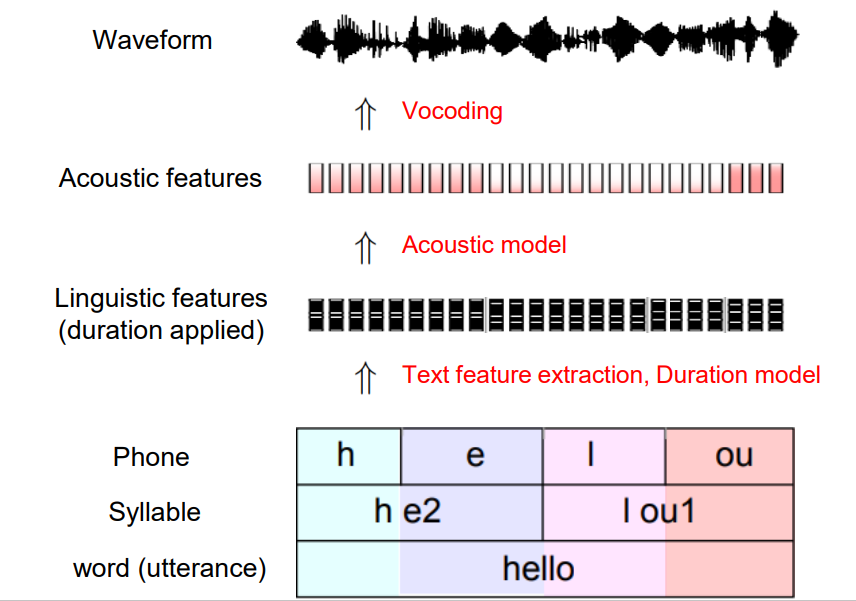
먼저 text analysis 모델로부터 각 텍스트에 대해 실제 speech에서의 duration을 맞추어 주는 alignment를 수행합니다. Alignment된 데이터는 acoustic model으로 인해 음성 feature들이 추출되게 되고, 이는 vocoding을 통해 waveform으로 복원이 됩니다.
HMM은 확률 모델로서 두 가지 가정 위에서 동작됩니다.
첫 번째는 First-order Markov Assumption으로, 현재 state는 바로 직전의 state에만 영향을 받는다는 가정입니다.
두 번째는 Output Independence Assumption으로, 현재의 observation은 현재의 state에만 영향을 받는다는 가정입니다.
이 가정들은 모델링을 간편하게 만들어 주고 계산을 편리하게 해준다는 장점이 있지만 음성의 특성들이 많이 무시되게 되어 HMM 기반의 음성합성 품질이 많이 떨어지게 된다는 단점이 있습니다.
구성 요소
- State transition probability
- Output probability
- initial state distribution
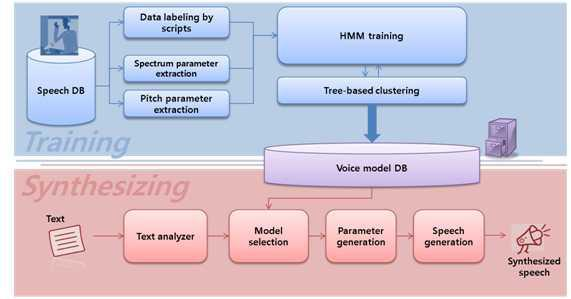
위 그림은 HMM 시스템의 전반적인 모습을 나타낸 것입니다.
- 학습 단계에서의 speech 데이터, text 데이터를 가공한 후 HMM 모델을 학습
- 데이터 라벨링을 할 시 text 데이터와 speech 데이터 alignment
- Decision Tree Clustering을 통해 없는 발음들에 대해 대비할 수 있도록 합니다. Clustering을 통해 text의 context 정보를 넣어주기도 합니다.
Inference 시나리오
- Text analysis를 통해 feature 추출
- Duration model을 통해 align 방식 정하기
- Align 된 정보들로부터 현재의 feature가 어떤 음성 feature에 매핑이 되는지 판단, model construction
- Feature 파라미터 생성 후 vocoder를 통해 음성 합성


3개의 댓글

[15기 황보진경]
Q. 혹시 all-pole model을 어떻게 이해하셨나요? 검색해봐도 뭔가 직관적으로 이해가 잘 되지 않습니다.
Source-Filter Model
폐에서 Impulse가 발생하면 Vocal trat을 거쳐 Filter를 씌운 형태로 음성의 발생 과정을 해석하는 방법이다. Filter를 얻는 방법은 LPC를 이용한 방법과 Cepstrum을 이용한 방법이 있다.
- LPC: 이전 샘플들을 이용하여 다음 샘플을 예측하는 AR기반 모델로, 보통 10~20차 정도를 사용한다.
- Cepstrum: DFT -> log -> Liftering -> IDFT의 과정을 거친다.
Conventional Speech Synthesis
- Unit Selection: 데이터베이스에서 실제 음성을 greedy search 등의 방법으로 찾아서 concatenate하는 방식이다. 데이터 용량이 매우 커야 하며, naturalness와 flexibility가 떨어지기 때문에 자주 사용되지는 않는다.
- HMM: First-order Markov, Output Independence라는 가정 하에 alignment, duration 등을 고려하여 text로부터 speech feature를 mapping시키는 방식이다. 이후 vocoding을 통해 waveform을 복원한다.

[15기 안민준]
- Source-Filter Model 에서 발생한 스펙트럼중에서 f0만 filter가 적용되고 나머지 harmonics 들은 처리에서 무시되는게 맞나요?
- Pole-zero 모델과 all-pole 모델의 정의를 짚어 주실 수 있을까요?
[15기 이성범]
Source-Filter Model : 사람이 말을 하는 과정을 그대로 수학적으로 모델링하는 방식 (Source Filtering 방식)
Speech Synthesis : Text가 주었을 때 음성으로 변환해 주는 Task