
Background
- AWS Managed Flink 앱으로 배포하기 전 Apache Flink ver 1.19.0 을 Mac OS M1 로컬 환경에서 작업할 수 있도록 개발 환경을 구성하고 간단한 예제를 통해 테스트 하는 방법을 기록한다.
Spec
| Service | Version |
|---|---|
| Python | 3.11.5 |
| Apache Flink of Python package | 1.19.0 |
| AWS Managed Flink | 1.19 |
| AWS MSK (Kafka) | 3.5.1 |
| Local OS | Mac OS M1 (Silicon Chip) |
| Java | 11 |
| Maven | 3.9.9 |
1. AWS Managed Flink Components 구성하기
Amazon Managed Service for Apache Flink 1.19 문서를 참고하여
Python 3.11,Java 11,Maven latest버전을 로컬에 설치 한다.
1-1. Java 11 설치하기
Maven 패키징 시 사용하기 위해
Java 11을 미리 설치한다.
# Java 11 버전 설치
$ brew install openjdk@11
# 설치된 Java 버전 확인
$ java -version
>>
The operation couldn’t be completed. Unable to locate a Java Runtime.
Please visit http://www.java.com for information on installing Java.
# 위와 같이 java 버전 검색이 안 될 경우 아래와 같이 symlink 를 설정해준다.
# For the system Java wrappers to find this JDK, symlink it with
$ sudo ln -sfn /opt/homebrew/opt/openjdk@11/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk-11.jdk
# PATH 에 java 경로 추가
$ echo 'export PATH="/opt/homebrew/opt/openjdk@11/bin:$PATH"' >> ~/.zshrc
$ source ~/.zshrc
# 다시 java 버전 확인
$ java -version
>>
openjdk version "11.0.24" 2024-07-16
OpenJDK Runtime Environment Homebrew (build 11.0.24+0)
OpenJDK 64-Bit Server VM Homebrew (build 11.0.24+0, mixed mode)1-2. Maven 설치하기
차후 AWS Managed Flink 에 App 배포 시 Pyflink
main()메서드가 실행 되는 파일과 종속성 패키징 된jar파일을 mvn 명령어를 통해 만들기 때문에 설치한다.
# maven 설치
$ brew install maven
# maven 버전 확인
$ mvn -v
>>
Apache Maven 3.9.9 (8e8579a9e76f7d015ee5ec7bfcdc97d260186937)
Maven home: /opt/homebrew/Cellar/maven/3.9.9/libexec
Java version: 22.0.2, vendor: Homebrew, runtime: /opt/homebrew/Cellar/openjdk/22.0.2/libexec/openjdk.jdk/Content
Default locale: ko_KR, platform encoding: UTF-8
OS name: "mac os x", version: "14.6.1", arch: "aarch64", family: "mac1-3. Python 3.11 가상환경 생성 및 Flink 패키지 설치하기
# python 3.11 버전 설치
$ pyenv install -v 3.11
>> Installed Python-3.11.10 to /Users/kimjaemin/.pyenv/versions/3.11.10
# pyflink_env_311 이름의 가상환경 생성
$ pyenv virtualenv 3.11 pyflink_env_311
# 작업 경로 생성
$ mkdir -p ~/Study/Flink
$ cd ~/Study/Flink
# flink 작업 경로에서 pyflink_env_311 가상환경 활성화를 기본으로 적용
$ pyenv local pyflink_env_311
$ python3 -m pip install --upgrade pip wheel
$ python3 -m pip install apache-flink==1.19.01-4. PYFLINK_HOME 경로 탐색 및 환경변수 선언하기
$ python3 -c "import pyflink;import os;print(os.path.dirname(os.path.abspath(pyflink.__file__)))"
>> ~/.pyenv/versions/pyflink_env_311/lib/python3.11/site-packages/pyflink
$ export PYFLINK_HOME=$(python3 -c "import pyflink;import os;print(os.path.dirname(os.path.abspath(pyflink.__file__)))")
$ export IS_LOCAL=True
# 또는
$ vim ~/.zshrc
>> 아래 줄에 추가
export PYFLINK_HOME=~/.pyenv/versions/pyflink_env_311/lib/python3.11/site-packages/pyflink
export IS_LOCAL=True
$ source ~/.zshrc📌 pyflink main() 메서드가 실행될 run.py 에서 로컬 개발 환경에서만 동작하는 코드를 분기 시키기 위해 IS_LOCAL 환경변수도 같이 추가 하
였다.
1-5. pyflink log 확인하는 방법
- 위와 같이 PYFLINK_HOME 환경변수를 등록 하였다면 차후 개발 시
- $PYFLINK_HOME/log 경로에 생기는 .log 파일을 이용하여 디버깅 하는 것이 좋다.
- 참고 문서: Create and run a Managed Service for Apache Flink for Python application - Inspect application logs locally

1-6. Flink 작업 디렉토리 구조 세팅
- 나중에 문서 확인 시 작업 구조를 한 번에 파악할 수 있도록 아래와 같이 작업 구조를 미리 만들어 두고 시작한다.
- 단, 로컬에서 작업 시 아래와 같은 경로 이름이나 디렉토리 구조로 고정할 필요는 없다.
- 단순히 공식 문서 또는 Github amazon-managed-service-for-apache-flink-examples 저장소에 있는 예제 코드 구조를 참고하여 진행하는 것이다.
$ cd ~/Study/Flink
$ mkdir lib plugin config assembly # .jar, .json .xml 파일이 위치할 디렉토리
$ touch run.py # main() 메서드가 실행될 pyflink app python 파일
$ touch pom.xml # 차후 AWS Managed flink app 에 배포하기 위한 maven 빌드용 xml 파일
# ~/flink/ 작업 경로 구조
$ tree ./
./
├── assembly
├── config # 차후 aws managed flink 에서 런타임 속성을 관리하는 application_properties.json 파일이 존재할 경로이다.(우선, 로컬 테스트에서는 사용하지 않는다.)
├── lib
├── plugin
├── pom.xml
└── run.py2. Kafka Connector 사용을 위한 jar classpath 종속성 해결
- Apache flink 설치 시 모든 connector 사용이 가능하도록 자체적으로 모든 class 가 패키징 되어 있지는 않다.
- 때문에, 필요에 따라 connector 사용을 위한 jar classpath 를 추가하여 종속성 해결을 해야한다.
- PyFlink 에서 Table api 로 kafka connector 를 사용하기 위해서는 아래 세 개의 파일을 다운로드 받아야 한다.
- flink-connector-kafka-3.2.0-1.19.jar 다운로드
(Pyflink 에서 datastream api 를 사용한다면 sql 없이 해당 파일과 클라이언트만 있어도 되는 것 같다.) - flink-sql-connector-kafka-3.2.0-1.19.jar 다운로드
(Pyflink table api 를 이용하여 kafka connector 를 사용하기 위한 jar 파일) - kafka-clients-3.2.0.jar 다운로드
📌 Kafka client 를 3.2.0 버전으로 다운로드 했다면, connector jar 도 kafka client 버전은 3.2.0 버전으로 선택하고 Flink 버전은 현재 사용중인
Flink 버전으로 다운로드 받으면 된다.
이제 다운로드 받은 jar 파일들을 앞에서 생성해 두었던
~/Study/Flink/lib경로에 위치 시키자.
# 파일은 내 로컬 ~/Downloads 경로에 다운로드 되었다.
$ cd ~/Downloads
$ ls | grep kafka
>>
flink-connector-kafka-3.2.0-1.19.jar
flink-sql-connector-kafka-3.2.0-1.19.jar
kafka-clients-3.2.0.jar
# Kafka 관련 jar 파일들은 ~/Study/Flink/lib 로 복사
$ cp ~/Downloads/kafka-clients-3.2.0.jar ~/Study/Flink/lib
$ cp ~/Downloads/flink-connector-kafka-3.2.0-1.19.jar ~/Study/Flink/lib
$ cp ~/Downloads/flink-sql-connector-kafka-3.2.0-1.19.jar ~/Study/Flink/lib
- 위와 같이 Kafka connector 사용 시 필요한 jar 파일을 모두 다운로드 하였다면, 코드상에서 jar 경로를 pyflink 의
TableEnvironment객체에pipeline.jars라는 속성 값으로 넘겨주면 된다.- 자세한 내용은 페이지 아래에 위치할 코드 부분을 보면 이해 될 것이다.
- 참고 문서: Flink docs - Dependency Management
2-1. Table api 으로 kafka connector 사용시 Error 가 발생할 경우 대응 방법
장애 1)
- 장애 메시지
📍 org.apache.flink.table.factories.DynamicTableFactory Error py4j.protocol.Py4JJavaError: An error occurred while calling o8.executeSql.
: org.apache.flink.table.api.ValidationException: Unable to create a source for reading table 'default_catalog.default_database.table_kafka_source'.
...
Caused by: org.apache.flink.table.api.ValidationException: Cannot discover a connector using option: 'connector'='kafka'
at org.apache.flink.table.factories.FactoryUtil.enrichNoMatchingConnectorError(FactoryUtil.java:807)
at org.apache.flink.table.factories.FactoryUtil.discoverTableFactory(FactoryUtil.java:781)
at org.apache.flink.table.factories.FactoryUtil.createDynamicTableSource(FactoryUtil.java:224)
...
Caused by: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'kafka' that implements 'org.apache.flink.table.factories.DynamicTableFactory' in the classpath.-
장애 원인: 앞에서 설명한 것 처럼 flink connector 사용 시 필요한 jar 종속성 대응이 되어 있지 않다면, 위와 같은 장애가 발생할 수 있다. 해당 장애는 kafka connector 사용 시 필요한 class 를 참조하지 못했기 때문에 발생한 장애이다.
-
장애 대응 방법
- 첫 번째:
flink-sql-connector-kafka-3.2.0-1.19.jar,flink-connector-kafka-3.2.0-1.19.jar,kafka-clients-3.2.0.jar파일을 다운로드 받고 아래 코드와 같이TableEnvironment객체에pipeline.jars속성으로jar classpath를 선언해주면 된다.
(단, 해당 방법은 로컬 테스트 환경에서만 사용하는 것을 추천한다. aws managed flink app 배포 시에는 pom.xml 파일을 이용해서 maven 패키징 된 zip 파일을 업로드 하는 것이 종속성 관리에 더 좋다. 이 말은 차후 게시할 AWS Managed Flink 앱 배포하는 방법 문서에서 다룰 예정이다.) - 두 번째: 다운로드 받았던 jar 파일을
$PYFLINK_HOME/lib경로에 위치 시켜 주고 다시 실행 하면 Job manager 가 실행 되면서 해당
경로에 위치한 jar 파일들을 읽어서 종속성 문제가 해결 된다.
- 첫 번째:
3. FileSystem(S3) Connector 사용을 위한 jar classpath 종속성 해결
- FileSystem(s3) connector 종속성 대응 방법은 kafka connector 와 조금 다르다.
- Flink-Docs-FileSystem-Overview, Flink-Docs-FileSystem-AWS-S3 문서를 참고 해보면, FileSystem(S3, OSS, Azure Blob, GCS) 은 플러그인으로 취급하여
$PYFLINK_HOME/lib이 아닌$PYFLINK_HOME/plugins경로에서 다뤄야 한다고 한다.
(아직, Lib 과 Plugin 에 대한 구분 개념을 정확히 파악하지는 못했다.)- 그러나 이 방법으로 로컬 환경 테스트를 하거나 AWS Managed Flink 앱으로 배포하게 되면 정상 동작하지 않는다.
- FileSystem connector for s3 를 위한 jar 경로를
TableEnvironment객체pipeline.jars속성으로 선언해 주어도 인식하지 않는다.- 로컬 테스트 시 FileSystem connector for s3 를 위한 jar 파일은
$PYFLINK_HOME/lib경로에 직접 위치 시키면 정상적으로 동작한다.- 단, FileSystem 관련 jar 는
TableEnvironment객체pipeline.jars속성으로 경로를 선언하면 안 되고$PYFLINK_HOME/lib경로에만 위치 시켜야 한다. 둘 다 적용할 경우 역시 장애가 발생할 수 있다.- 우선 아래 링크에서
flink-s3-fs-hadoop-1.19.0.jar파일을 다운로드 받자.
- flink-s3-fs-hadoop-1.19.0.jar 다운로드
flink-connector-files-1.19.0.jar파일도 필요하지만,apache-flink==1.19.0패키지를 설치하면$PYFLINK_HOME/lib경로에 이미 존재한다.
이제 다운로드 받은 jar 파일을 $PYFLINK_HOME/lib 경로에 위치 시키자.
<# 파일은 내 로컬 ~/Downloads 경로에 다운로드 되었다.
$ cd ~/Downloads
$ ls | grep s3
>>
flink-s3-fs-hadoop-1.19.0.jar
# flink-s3-fs-hadoop-1.19.0.jar 파일을 $PYFLINK_HOME/lib 경로에 위치 시킨다.
$ cp ~/Downloads/flink-s3-fs-hadoop-1.19.0.jar $PYFLINK_HOME/lib3-1. Table api 으로 FileSystem(s3) connector 사용시 Error 가 발생할 경우 대응 방법
장애 1)
- 장애 메시지
📍 org.apache.flink.core.fs.UnsupportedFileSystemSchemeException Error Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 's3a'.
The scheme is directly supported by Flink through the following plugin(s):
flink-s3-fs-hadoop. Please ensure that each plugin resides within its own subfolder within the plugins directory. See https://nightlies.apache.org/flink/flink-docs-stable/docs/deployment/filesystems/plugins/ for more information.
If you want to use a Hadoop file system for that scheme, please add the scheme to the configuration fs.allowed-fallback-filesystems.
For a full list of supported file systems, please see https://nightlies.apache.org/flink/flink-docs-stable/ops/filesystems/.
...
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:514)
at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:408)
...
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:751)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:566)
at java.base/java.lang.Thread.run(Thread.java:829)-
장애 원인: 앞에서 설명한 것 처럼 flink connector 사용 시 필요한 jar 종속성 대응이 되어 있지 않다면, 위와 같은 장애가 발생할 수 있다. 해당 장애는 filesystem connector 사용 시 필요한 class 를 참조하지 못했기 때문에 발생한 장애이다.
-
장애 대응 방법
- 첫 번째: 다운로드 받았던 jar 파일을
$PYFLINK_HOME/lib경로에 위치 시키고 다시 실행 하면 Job manager 가 실행 되면서 해당 경로에 위치한 jar 파일들을 읽어서 종속성 대응이 가능하다.
- 첫 번째: 다운로드 받았던 jar 파일을
-
⚠️ 주의사항:
flink-s3-fs-hadoop-1.19.0.jar파일을$PYFLINK_HOME/lib경로에 위치시키고 동시에~/Study/Flink/lib경로에도 위치 시킨 후TableEnvironment객체pipeline.jars속성으로jar classpath를 선언 해주면 장애가 날 수 있으니 로컬 작업 시$PYFLINK_HOME/lib경로에만 위치 시키길 바란다.(apache flink version 1.19 버전 기준)
장애 2)
- 장애 메시지
📍 com.amazonaws.SdkClientException ErrorCaused by: com.amazonaws.SdkClientException: Unable to load AWS credentials from environment variables (AWS_ACCESS_KEY_ID (or AWS_ACCESS_KEY) and AWS_SECRET_KEY (or AWS_SECRET_ACCESS_KEY))
at com.amazonaws.auth.EnvironmentVariableCredentialsProvider.getCredentials(EnvironmentVariableCredentialsProvider.java:49) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]
at org.apache.hadoop.fs.s3a.AWSCredentialProviderList.getCredentials(AWSCredentialProviderList.java:177) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.getCredentialsFromContext(AmazonHttpClient.java:1269) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.runBeforeRequestHandlers(AmazonHttpClient.java:845) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:794) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]-
장애 원인: jar 종속성이 해결 된 후 위와 같이
AWS credentials관련 장애가 발생할 경우, AWS S3 접근을 위한 인증 권한이 없기 때문에 발생한 장애이다. -
장애 대응 방법
- 첫 번째:
AWS ACCESS KEY,SECRET KEY를 환경변수로 등록해주면 Flink job manager 가 실행 될 때, 아래 이름의 환경변수 이름을 찾아서 init 된다. - 두 번째:
$PYFLINK_HOME/conf/config.yaml파일에 인증 정보를 아래와 같이 추가할 수 있다.
(참고 문서: Flink Docs - Amazon S3 Configure Access Credentials
- 첫 번째:
<# 장애 2) 첫 번째 대응 방법
$ export AWS_ACCESS_KEY_ID="my-access-key"
$ export AWS_SECRET_ACCESS_KEY="my-secret-key"or
<# 장애 2) 두 번째 대응 방법
# $PYFLINK_HOME/conf/config.yaml
$ vim $PYFLINK_HOME/conf/config.yaml
>>
s3.access-key: your-access-key
s3.secret-key: your-secret-key4. 데이터 소싱용 Flink App(run.py) 개발
- 나는 테스트를 위해 MSK(Kafka) 에
test-topic토픽으로 아래와 같은 스키마로 json 데이터를 프로듀싱 중이다.- id: 랜덤 아이디 문자열
- city: 랜덤 도시 문자열
- number: 랜덤 숫자 문자열
- ins_time: 랜덤 yyyyMMddHHmmss 포맷의 문자열
- 데이터 예시:
{"id":"52862a5d-3392-4d65-955f-c212eb4c9e73", "city":"SanFrancisco", "number":"4836", "ins_time":"20240917134401"}
4-1. Kafka 데이터 소싱 코드 개발
- 아래와 같이 개발하여 kafka 데이터를 소싱할 수 있다.
- Kafka 속성 값은 각자 사용하는 Kafka 환경에 맞게 기입하면 된다.
- 로컬 테스트 환경에서
TableEnvironment객체에서 스트리밍 모드를 사용하려면set_checkpoint()함수 내용과 같이 반드시checkpoint설정을 활성화 해야한다.
import pyflink
import os
import json
import logging
from pyflink.table import EnvironmentSettings, TableEnvironment
def set_checkpoint(table_env: TableEnvironment):
''' Flink checkpoint 설정하는 함수 '''
# Set Flink stream checkpoint
table_env.get_config().get_configuration().set_string("execution.checkpointing.mode", "EXACTLY_ONCE")
table_env.get_config().get_configuration().set_string("execution.checkpointing.interval", "1 min") # 60초마다 체크포인트
def set_jar_classpath(table_env: TableEnvironment, current_dir: str):
''' 로컬 환경 테스트 시 Flink connector 관련 종속성 해결을 위한 jar 경로 선언하는 함수 '''
libs_dir = os.path.join(current_dir, "lib")
jar_files = [f"file:///{os.path.abspath(os.path.join(libs_dir, jar))}" for jar in os.listdir(libs_dir) if jar.endswith(".jar")]
jar_files_str = ";".join(jar_files)
table_env.get_config().get_configuration().set_string("pipeline.jars", jar_files_str)
for jar in jar_files_str.split(";"):
print(jar)
def main(table_env: TableEnvironment):
''' Flink Job 실행하는 함수 '''
table_env.execute_sql("""
CREATE TABLE source_kafka_table (
id STRING,
city STRING,
number STRING,
ins_time STRING
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'properties.bootstrap.servers' = 'my-bootstrap-server:9096',
'properties.group.id' = 'flink_test_group',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'SCRAM-SHA-512',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="my-username" password="my-password";'
)
""")
# Kafka source table 로 선언한 테이블 데이터를 조회할 수 있다.
# 단, 해당 코드는 반드시 로컬 테스트 환경에서만 사용하자.
kafka_records = table_env.execute_sql(f"""SELECT * FROM source_kafka_table""").collect()
for record in kafka_records:
print(record)
if __name__ == "__main__":
# Check ENV
IS_LOCAL = True if bool(os.environ.get("IS_LOCAL")) else False
# Get Directory path
CURRENT_DIR = os.path.dirname(os.path.realpath(__file__))
# Create Execution environment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# If Local
if IS_LOCAL:
print("IS_LOCAL=True")
logging.info("IS_LOCAL is True")
# Set flink stream checkpoint
set_checkpoint(table_env)
# Set JAR Dependencies
set_jar_classpath(table_env, CURRENT_DIR)
main(table_env)# run.py 실행 시 출력 결과
$ python3 run.py
>>>
IS_LOCAL=True
file:////Users/kimjaemin/Study/Flink/lib/flink-connector-kafka-3.2.0-1.19.jar
file:////Users/kimjaemin/Study/Flink/lib/flink-sql-connector-kafka-3.2.0-1.19.jar
file:////Users/kimjaemin/Study/Flink/lib/kafka-clients-3.2.0.jar
<Row('626c942d-6f54-4748-865f-9e61a461fb75', 'London', '1756', '20240917142333')>
<Row('645c2ce6-2766-434b-8649-79ef17b3fcb0', 'London', '336', '20240917142455')>
<Row('8c92db44-e7cc-4ca4-82e5-aeec0bbdb9f5', 'Mumbai', '7381', '20240917142447')>
<Row('bf0c7beb-d77e-421e-bad2-5032ec57ac36', 'Paris', '83', '20240917142441')>
...4-2. S3 데이터 싱크 코드 개발
- 위 코드에 이어서 FileSystem connector 를 이용해서 s3 에 json 파일을 업로드 하도록 하자.
- 반드시
$PYFLINK_HOME/lib경로에flink-s3-fs-hadoop-1.19.0.jar파일이 존재 해야하며AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY가 등록 되어 있어야 한다.
import pyflink
import os
import json
import logging
from pyflink.table import EnvironmentSettings, TableEnvironment
def set_checkpoint(table_env: TableEnvironment):
''' Flink checkpoint 설정하는 함수 '''
# Set Flink stream checkpoint
table_env.get_config().get_configuration().set_string("execution.checkpointing.mode", "EXACTLY_ONCE")
table_env.get_config().get_configuration().set_string("execution.checkpointing.interval", "1 min") # 60초마다 체크포인트
def set_jar_classpath(table_env: TableEnvironment, current_dir: str):
''' 로컬 환경 테스트 시 Flink connector 관련 종속성 해결을 위한 jar 경로 선언하는 함수 '''
libs_dir = os.path.join(current_dir, "lib")
jar_files = [f"file:///{os.path.abspath(os.path.join(libs_dir, jar))}" for jar in os.listdir(libs_dir) if jar.endswith(".jar")]
jar_files_str = ";".join(jar_files)
table_env.get_config().get_configuration().set_string("pipeline.jars", jar_files_str)
for jar in jar_files_str.split(";"):
print(jar)
def main(table_env: TableEnvironment, is_local: bool):
''' Flink Job 실행하는 함수 '''
table_env.execute_sql("""
CREATE TABLE source_kafka_table (
id STRING,
city STRING,
number STRING,
ins_time STRING
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'properties.bootstrap.servers' = 'my-bootstrap-server:9096',
'properties.group.id' = 'flink_test_group',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'SCRAM-SHA-512',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="my-username" password="my-password";'
)
""")
# # Kafka source table 로 선언한 테이블 데이터를 조회할 수 있다.
# # 단, 해당 코드는 반드시 로컬 테스트 환경에서만 사용하자.
# kafka_records = table_env.execute_sql(f"""SELECT * FROM source_kafka_table""").collect()
# for record in kafka_records:
# print(record)
table_env.execute_sql(f"""
CREATE TABLE sink_s3_table (
id STRING,
city STRING,
number STRING,
ins_time STRING,
`year` STRING,
`month` STRING,
`day` STRING,
`hour` STRING
) PARTITIONED BY (`year`, `month`, `day`, `hour`)
WITH (
'connector' = 'filesystem',
'path' = 's3a://my-s3-bucket/jaeminkim_test/',
'format' = 'json',
'sink.rolling-policy.file-size' = '32MB',
'sink.rolling-policy.rollover-interval' = '1 min',
'sink.rolling-policy.check-interval' = '1 min',
'auto-compaction' = 'false'
)
""")
table_insert = table_env.execute_sql(f"""
INSERT INTO sink_s3_table
SELECT *,
DATE_FORMAT(TO_TIMESTAMP(ins_time, 'yyyyMMddHHmmss'), 'yyyy') AS `year`,
DATE_FORMAT(TO_TIMESTAMP(ins_time, 'yyyyMMddHHmmss'), 'MM') AS `month`,
DATE_FORMAT(TO_TIMESTAMP(ins_time, 'yyyyMMddHHmmss'), 'dd') AS `day`,
DATE_FORMAT(TO_TIMESTAMP(ins_time, 'yyyyMMddHHmmss'), 'HH') AS `hour`
FROM source_kafka_table
""")
if is_local:
# 로컬 환경에서는 insert 하는 객체에 wait() 로 대기 명령을 해야 동작한다.
# 반드시 로컬 환경에서만 wait() 메서드를 사용하길 바란다.
table_insert.wait()
if __name__ == "__main__":
# Check ENV
IS_LOCAL = True if bool(os.environ.get("IS_LOCAL")) else False
# Get Directory path
CURRENT_DIR = os.path.dirname(os.path.realpath(__file__))
# Create Execution environment
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# If Local
if IS_LOCAL:
print("IS_LOCAL=True")
logging.info("IS_LOCAL is True")
# Set flink stream checkpoint
set_checkpoint(table_env)
# Set JAR Dependencies
set_jar_classpath(table_env, CURRENT_DIR)
main(table_env, IS_LOCAL)[ 코드 참고 ]
- source 테이블 기준에서 신규 컬럼을 추가 할 에정이라면, sink 테이블에서 신규 컬럼 스키마를 선언한 후 insert 하는 부분에서 신규 컬럼을 위한 데이터 전처리를 진행할 수 있다.
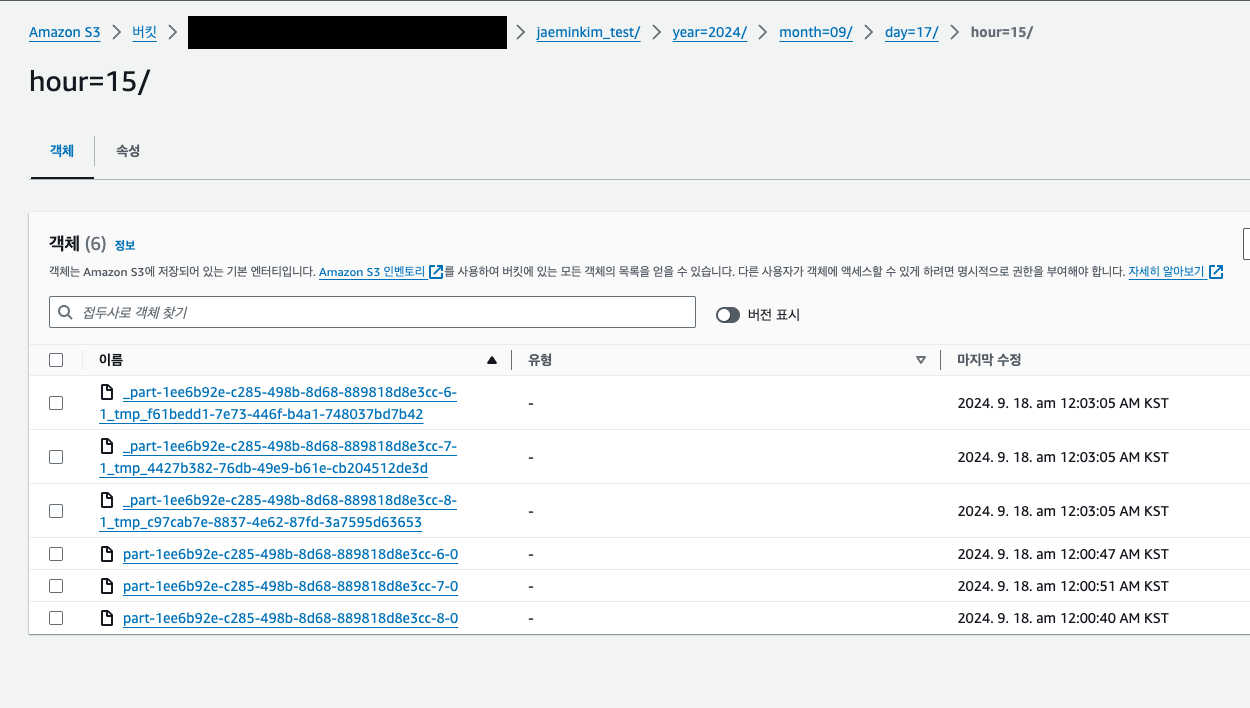
- filesystem connector 를 사용하는 테이블에서
PARTITIONED BY (year, month, day, hour)와 같이 파티셔닝을 선언할 경우 아래 이미지와 같이path하위에 지정한 컬럼 값대로 파티셔닝 되는 것을 알 확인할 수 있다.
해당 게시글에서 잘못된 내용이 있다면 언제든 댓글 or 메일 주시면 감사하겠습니다.🙇
이거 삽질 하느라 쿠버네티스 정리 또 밀렸네... 다시 정리 해야겠다..😢
