
Background
- EKS 환경에서 운영하던
NiFi일몰을 목표로 실시간 스트리밍 툴인Apache Flink도입을 위한 POC 를 진행 하였다. AWS MSK(Kafka) 로 들어오는 Json 데이터를 S3 에 파티셔닝 하기 위한 목적으로 사용하며, 복잡한 전처리 과정은 거치지 않고 단순 필드 추가 정도 작업을 포함한 스트리밍 Job 을 개발하고 AWS Managed Flink 에 배포 하였는데, 개발 과정에 필요한 내용을 테스트 버전으로 요약하여 포스팅 한다.- 이번 게시글에서는 Apache Flink 1.19.0 을 Mac os m1 로컬 환경에서 테스트 하는 방법을 정리한다.
(단, Docker 는 사용하지 않는다.)
Spec
- Python version: 3.11.5
- Local Apache flink version: 1.19.0
- AWS Managed Flink version: 1.19.0
- AWS MSK(Kafka) version: 3.5.1
- OS: Mac os m1(silicon chip)
- Java version: 11
- Maven version: 3.9.9
1. AWS Managed Flink Components 구성 하기
https://docs.aws.amazon.com/managed-flink/latest/java/flink-1-19.html 문서를 참고하여 Python 3.11, Java 11, Maven latest 버전을 로컬에 설치 한다.
1-1. Java 11 설치
# Java 11 버전 설치
$ brew install openjdk@11
# 설치된 Java 버전 확인
$ java -version
>>
The operation couldn’t be completed. Unable to locate a Java Runtime.
Please visit http://www.java.com for information on installing Java.
# 위와 같이 java 버전 검색이 안 될 경우 아래와 같이 symlink 를 설정해준다.
# For the system Java wrappers to find this JDK, symlink it with
$ sudo ln -sfn /opt/homebrew/opt/openjdk@11/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk-11.jdk
# PATH 에 java 경로 추가
$ echo 'export PATH="/opt/homebrew/opt/openjdk@11/bin:$PATH"' >> ~/.zshrc
$ source ~/.zshrc
# 다시 java 버전 확인
$ java -version
>>
openjdk version "11.0.24" 2024-07-16
OpenJDK Runtime Environment Homebrew (build 11.0.24+0)
OpenJDK 64-Bit Server VM Homebrew (build 11.0.24+0, mixed mode)1-2. Maven 설치
# maven 설치
$ brew install maven
# maven 버전 확인
$ mvn -v
>>
Apache Maven 3.9.9 (8e8579a9e76f7d015ee5ec7bfcdc97d260186937)
Maven home: /opt/homebrew/Cellar/maven/3.9.9/libexec
Java version: 22.0.2, vendor: Homebrew, runtime: /opt/homebrew/Cellar/openjdk/22.0.2/libexec/openjdk.jdk/Contents/Home
Default locale: ko_KR, platform encoding: UTF-8
OS name: "mac os x", version: "14.6.1", arch: "aarch64", family: "mac1-3. Python 3.11 가상환경 생성 및 패키시 설치
pyenv 를 이용한 가상환경과 작업경로 생성 후 apache-flink 패키지를 설치한다.
# python 3.11 버전 설치
$ pyenv install -v 3.11
>> Installed Python-3.11.10 to /Users/kimjaemin/.pyenv/versions/3.11.10
# pyflink_study_python3_11 이름의 가상환경 생성
$ pyenv virtualenv 3.11 pyflink_study_python3_11
$ mkdir -p ~/Study/Flink # 작업 경로 생성
$ cd ~/Study/Flink # 작업 경로로 이동
# ~/Study/Flink 경로 접근 시 pyflink_study_python3_11 가상환경이 기본 활성화 되도록 설정
$ pyenv local pyflink_study_python3_11
# 파이썬 패키지 설치
$ python3 -m pip install --upgrade pip wheel
$ python3 -m pip install apache-flink==1.19.01-4. PYFLINK_HOME 경로 검색 및 환경변수 등록하기
- flink 작업 시 connector 를 위한
.jar클래스를 추가로 확장 해야하는 경우가 있다.- flink lib 인 경우 추가할 jar 파일 위치를 pyflink 객체에
'pipeline.jars'런타임 속성으로 classpath 를 추가해줄 수 있다.- 그러나 flink plugin 인 경우 로컬 테스트 환경에서는
'pipeline.jars'런타임 속성에 추가하여도 동작하지 않는다.- 이유는 classpath 인식이 안 되거나 클래스 중첩 등의 이슈로 오류가 발생할 수 있다고 한다.
- 그래서 로컬 테스트 시 flink plugin 에 해당하는
.jar파일들은PYFLINK_HOME경로 하위에 존재하는lib경로에 직접 위치 시켜 테스트 하면 된다.- 위 내용을 위해 PYFLINK_HOME 환경 변수를 등록하는 것이다.
# 파이썬 pyflink home 경로 찾는 명령어
$ python3 -c "import pyflink;import os;print(os.path.dirname(os.path.abspath(pyflink.__file__)))"
# PYFLINK_HOME 환경 변수 등록
$ export PYFLINK_HOME=$(python3 -c "import pyflink;import os;print(os.path.dirname(os.path.abspath(pyflink.__file__)))")
# 환경변수 등록 확인
$ env | grep PYFLINK
>>
PYFLINK_HOME=/Users/gimjaemin/.pyenv/versions/pyflink_study_python3_11/lib/python3.11/site-packages/pyflink1-5. pyflink log 확인하는 방법
- 위와 같이 PYFLINK_HOME 환경변수를 등록 하였다면 차후 개발 시
$PYFLINK_HOME/log경로에 생기는.log파일을 이용하여 디버깅 하는 것이 좋다.- 참고 문서: Create and run a Managed Service for Apache Flink for Python application - Inspect application logs locally
$ tail -f $PYFLINK_HOME/log/<my-logfile-name>.log
1-6. Flink 작업 디렉토리 구조 세팅
로컬에서 작업 시 아래와 같은 경로 이름이나 디렉토리 구조로 고정 할 필요 없다.
단순히 공식 문서 또는 Github 저장소에 있는 예제 코드 구조를 참고하여 진행하는 것이다.
$ cd ~/Study/Flink
$ mkdir lib plugin config
$ touch run.py
$ tree ../Flink
>>
../Flink
├── config # application_properties.json 파일이 위치할 곳
├── lib # connector 관련 jar 파일이 위치할 곳
├── plugin # connector 관련 jar 파일이 위치할 곳(plugin)
└── run.py # pyflink 실행 될 코드2. AWS MSK(Kafka) 데이터 소싱
- 나는 Flink Concepts 공식 문서 를 참고 하여 Flink Table API 로 Kafka 데이터를 소싱 하였다.
- 객체 선언, 디렉터리 구조 등은 Github amzon-managed-service-for-apache-flink-examples 저장소를 참고하였다.
2-1. MSK(Kafka) 데이터 조회하기
🏷️ 작업 환경 참고 사항
- AWS MSK(Kakfa) 인증유형:
SASL/SCRAM(SHA-512)- AWS MSK(Kakfa) 엔드포인트:
퍼블릭 엔드포인트로 접근- Pyflink kafka connector 개발 참고 문서를 참고 하여
properties.security.protocol,properties.sasl.mechanism,properties.sasl.jaas.config속성을 아래 같이 추가 했다.
# run.py
from pyflink.table import EnvironmentSettings
from pyflink.table import TableEnvironment
# Flink 스트림 객체 선언
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# kafka 데이터 소싱용 테이블 생성
table_env.execute_sql(f"""
CREATE TABLE table_kafka_source (
id STRING,
name STRING,
city STRING,
event_time STRING
) WITH (
'connector' = 'kafka',
'topic' = 'my-topic',
'properties.bootstrap.servers' = 'my-bootstrap-servers:9096',
'properties.group.id' = 'my-consumer-group-id',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'SCRAM-SHA-512',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="my-username" password="my-password";'
)
""")
# kafka 데이터 소싱 결과 출력하기
# 반드시 collect() 또는 print() 메서드로 데이터를 출력하는 것은 로컬 환경 테스트에서만 동작하도록 하자.
for record in table_env.execute_sql(f"""SELECT * FROM table_kafka_source""").collect():
print(record)위와 같이 Kafka 데이터를 소싱 하는 코드만 기재한 후
run.py를 실행 시켜 보자.
그러면 아래와 같은 오류가 발생할 것이다.
2-1 org.apache.flink.table.factories.DynamicTableFactory Error 대응 방법
처음
run.py을 실행 시키면 아래와 같이 MSK(Kafka) 에서 Flink table api 를 이용하여 Kafka 데이터를 가지고 오기 위한org.apache.flink.table.factories.DynamicTableFactory클래스를 사용할 수 없어서 장애가 발생한다.
# run.py 실행
$ python3 run.py
>>
py4j.protocol.Py4JJavaError: An error occurred while calling o8.executeSql.
: org.apache.flink.table.api.ValidationException: Unable to create a source for reading table 'default_catalog.default_database.table_kafka_source'.
...
Caused by: org.apache.flink.table.api.ValidationException: Cannot discover a connector using option: 'connector'='kafka'
at org.apache.flink.table.factories.FactoryUtil.enrichNoMatchingConnectorError(FactoryUtil.java:807)
at org.apache.flink.table.factories.FactoryUtil.discoverTableFactory(FactoryUtil.java:781)
at org.apache.flink.table.factories.FactoryUtil.createDynamicTableSource(FactoryUtil.java:224)
...
Caused by: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'kafka' that implements 'org.apache.flink.table.factories.DynamicTableFactory' in the classpath.오류 대응을 위해 Use Apache Flink connectors with Managed Service for Apache Flink 문서를 참고하여 kafka connector 관련
.jar파일을 아래 기재 되어 있는 maven 서버 주소에 접속하여 다운로드 받은 후 작업 경로에 위치 시켜 보자.
# 아래 3개 파일을 모두 다운로드 해주자.
# flink-connector-kafka-3.2.0-1.19.jar 다운로드 URL: https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka/3.2.0-1.19
# flink-sql-connector-kafka-3.2.0-1.19.jar 다운로드 URL: https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka/3.2.0-1.19
# kafka-clients-3.2.0.jar 다운로드 URL: https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients/3.2.0
# 파일은 내 로컬 ~/Downloads 경로에 다운로드 되었다.
$ cd ~/Downloads
$ ls | grep kafka
>>
flink-connector-kafka-3.2.0-1.19.jar
flink-sql-connector-kafka-3.2.0-1.19.jar
kafka-clients-3.2.0.jar
# Kafka 관련 jar 파일들은 ~/Study/Flink/lib 로 복사
$ cp ~/Downloads/kafka-clients-3.2.0.jar ~/Study/Flink/lib
$ cp ~/Downloads/flink-connector-kafka-3.2.0-1.19.jar ~/Study/Flink/lib
$ cp ~/Downloads/flink-sql-connector-kafka-3.2.0-1.19.jar ~/Study/Flink/lib📌 주의사항
- 3개의 jar 파일 모두 같은 kafka client 버전으로 다운로드 해야 한다.
달라도 동작할 수 있지만, 다를 경우 오류가 발생하기도 했다. (나는 3.2.0 을 사용했다.) from pyflink.datastream import DataStream객체가 아닌TableEnvironment객체(table api)를 사용하기 때문에flink-sql-connector-kafka-3.2.0-1.19.jar파일이 꼭 필요하다.
위와 같이 kafka connector 관련
.jar파일을 작업 경로에 위치 시킨 후 아래와 같이 코드를 수정하여table env객체에pipeline.jars런타임 속성으로 classpath 를 추가해 주면 정상 동작한다.
import os
from pyflink.table import EnvironmentSettings
from pyflink.table import TableEnvironment
def set_jar_classpath(table_env: TableEnvironment):
''' Flink app - jar 클래스 패키지 종속성 설정 '''
# Get Directory path
CURRENT_DIR = os.path.dirname(os.path.realpath(__file__))
# Get flink app directory
LIBS_DIR = os.path.join(CURRENT_DIR, "lib")
# 여러개의 jar 파일을 선언할 경우 경로를 ; 구분자를 이용하여 문자열로 만들어주면 된다.
jar_files = [f"file:///{os.path.abspath(os.path.join(LIBS_DIR, jar))}" for jar in os.listdir(LIBS_DIR) if jar.endswith(".jar")]
jar_files_str = ";".join(jar_files)
# pipeline.jars 런타임 속성을 이용하여 선언 가능하다.
table_env.get_config().get_configuration().set_string("pipeline.jars", jar_files_str)
for jar in jar_files_str.split(";"):
print(jar)
# Flink 스트림 객체 선언
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# Flink connector jar classpath 확장
set_jar_classpath(table_env)
# kafka 데이터 소싱용 테이블 생성
table_env.execute_sql(f"""
CREATE TABLE table_kafka_source (
id STRING,
name STRING,
city STRING,
event_time STRING
) WITH (
'connector' = 'kafka',
'topic' = 'my-topic',
'properties.bootstrap.servers' = 'my-bootstrap-servers:9096',
'properties.group.id' = 'my-consumer-group-id',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'SCRAM-SHA-512',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="my-username" password="my-password";'
)
""")
# kafka 데이터 소싱 결과 출력하기
# 반드시 collect() 또는 print() 메서드로 데이터를 출력하는 것은 로컬 환경 테스트에서만 동작하도록 하자.
for record in table_env.execute_sql(f"""SELECT * FROM table_kafka_source""").collect():
print(record)# 코드 실행
$ python3 run.py
>>
file:////Users/kimjaemin/Study/Flink/lib/flink-connector-kafka-3.2.0-1.19.jar
file:////Users/kimjaemin/Study/Flink/lib/flink-sql-connector-kafka-3.2.0-1.19.jar
file:////Users/kimjaemin/Study/Flink/lib/kafka-clients-3.2.0.jar
<Row('1', 'jaemin', 'seoul', '20240909101500')>
<Row('2', 'minjae', 'incheon', '20240909101502')>
...3. AWS S3(FileSystem) 데이터 싱크
Flink Table API 에서
Filesystem connector를 이용하여 S3 에 데이터 싱크하는 방법과 Filesystem connector 사용을 위한.jar파일 확장 방법은 아래 기재 해둔 문서와 Github 코드의 주석을 참고 하였다.
- Flink Docs(Table & SQL Connectors): https://nightlies.apache.org/flink/flink-docs-release-1.19//docs/connectors/table/overview/
- Flink Docs(File Systems): https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/deployment/filesystems/overview/
- Flink Docs(Amazon S3 with Filesystmes plugins): https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/deployment/filesystems/s3/
- Flink Docs(Plugins): https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/deployment/filesystems/plugins/
- Github(aws flink S3Sink 예제 코드): https://github.com/aws-samples/amazon-managed-service-for-apache-flink-examples/blob/main/python/S3Sink/main.py
3-1. S3(FileSystem) 데이터 싱크 코드
- S3 에 데이터 싱크를 위한 테이블을 생성하고 INSERT INTO 명령문으로 데이터 흐름을 시작할 수 있다.
- Filesystem connector 를 로컬 환경에서 사용할 때에는 반드시 Flink 체크포인트 설정을 활성화 해주어야 한다.(아래 코드 참고)
# run.py
import os
from pyflink.table import EnvironmentSettings
from pyflink.table import TableEnvironment
def set_jar_classpath(table_env: TableEnvironment):
''' Flink app - jar 클래스 패키지 종속성 설정 '''
# Get Directory path
CURRENT_DIR = os.path.dirname(os.path.realpath(__file__))
# Get flink app directory
LIBS_DIR = os.path.join(CURRENT_DIR, "lib")
jar_files = [f"file:///{os.path.abspath(os.path.join(LIBS_DIR, jar))}" for jar in os.listdir(LIBS_DIR) if jar.endswith(".jar")]
jar_files_str = ";".join(jar_files)
table_env.get_config().get_configuration().set_string("pipeline.jars", jar_files_str)
for jar in jar_files_str.split(";"):
print(jar)
# Flink 스트림 객체 선언
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# 로컬 환경에서 Filesystem connector 사용 시 반드시 Flink 체크포인트 설정을 활성화 해주어야한다.
# 참고: https://github.com/aws-samples/amazon-managed-service-for-apache-flink-examples/blob/main/python/S3Sink/main.py
table_env.get_config().get_configuration().set_string(
"execution.checkpointing.mode", "EXACTLY_ONCE"
)
table_env.get_config().get_configuration().set_string(
"execution.checkpointing.interval", "1 min"
)
# Flink connector jar classpath 확장
set_jar_classpath(table_env)
# kafka 데이터 소싱용 테이블 생성
table_env.execute_sql(f"""
CREATE TABLE table_kafka_source (
id STRING,
name STRING,
city STRING,
event_time STRING
) WITH (
'connector' = 'kafka',
'topic' = 'my-topic',
'properties.bootstrap.servers' = 'my-bootstrap-servers:9096',
'properties.group.id' = 'my-consumer-group-id',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'SCRAM-SHA-512',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="my-username" password="my-password";'
)
""")
# kafka 데이터 소싱 결과 출력하기 -> 데이터 싱크 진행을 위해 해당 코드는 주석 처리
# for record in table_env.execute_sql(f"""SELECT * FROM table_kafka_source""").collect():
# print(record)
# s3 데이터 싱크용 테이블 생성
table_env.execute_sql("""
CREATE TABLE table_s3_sink (
id STRING,
name STRING,
city STRING,
event_time STRING
`year` STRING,
`month` STRING,
`day` STRING,
`hour` STRING
)
/*
PARTITIONED BY 를 아래와 같이 사용하면 지정해둔 path 를 기준으로
path/year={year}/month={month}/day={day}/hour={hour} 와 같이 적재 된다.
*/
PARTITIONED BY (`year`, `month`, `day`, `hour`)
WITH (
'connector' = 'filesystem',
'path' = 's3a://my-bucket/test',
'format' = 'json',
'sink.rolling-policy.file-size' = '128MB',
'sink.rolling-policy.rollover-interval' = '1 min',
'sink.rolling-policy.check-interval' = '1 min',
'auto-compaction' = 'true'
)
/*
sink.rolling-policy.file-size(128MB): 스트림에서 데이터 사이즈가 128MB 되면 업로드
sink.rolling-policy.rollover-interval: file-size 와 상관 없이 1분이 지나면 업로드
auto-compaction: 파일 자동 압축 여부
*/
""")
# 소스테이블 -> 싱크테이블 로 데이터 전달(INSERT)
insert_into = table_env.execute_sql(f"""
INSERT INTO table_s3_sink
SELECT
id,
name,
city,
event_time,
DATE_FORMAT(TO_TIMESTAMP(event_time, 'yyyyMMddHHmmss'), 'yyyy') AS `year`,
DATE_FORMAT(TO_TIMESTAMP(event_time, 'yyyyMMddHHmmss'), 'MM') AS `month`,
DATE_FORMAT(TO_TIMESTAMP(event_time, 'yyyyMMddHHmmss'), 'dd') AS `day`,
DATE_FORMAT(TO_TIMESTAMP(event_time, 'yyyyMMddHHmmss'), 'HH') AS `hour`
FROM table_kafka_source
""")
# wait() 메서드는 로컬 테스트 환경에서만 사용한다.
# 로컬 테스트 시 wait() 메서드를 사용하지 않으면 프로세스가 바로 종료 된다.
insert_into.wait()3-1. org.apache.flink.core.fs.UnsupportedFileSystemSchemeException Error 대응방법
- Kafka 설정 이후 Filesystem connector 를 사용하는 코드 추가한 상태에서
run.py을 실행 시키면 아래와 같이org.apache.flink.core.fs.UnsupportedFileSystemSchemeException오류가 발생한다.
이 역시, Flink filesystem connector 사용 시 필요한 클래스 패키지가 확장 되지 않아서 그렇다.
# run.py 실행
$ python3 run.py
>>
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 's3a'.
The scheme is directly supported by Flink through the following plugin(s):
flink-s3-fs-hadoop. Please ensure that each plugin resides within its own subfolder within the plugins directory. See https://nightlies.apache.org/flink/flink-docs-stable/docs/deployment/filesystems/plugins/ for more information.
If you want to use a Hadoop file system for that scheme, please add the scheme to the configuration fs.allowed-fallback-filesystems.
For a full list of supported file systems, please see https://nightlies.apache.org/flink/flink-docs-stable/ops/filesystems/.
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:514)
at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:408)
at org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink$RowFormatBuilder.createBucketWriter(StreamingFileSink.java:290)
at org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink$RowFormatBuilder.createBuckets(StreamingFileSink.java:300)
at org.apache.flink.connector.file.table.stream.AbstractStreamingWriter.initializeState(AbstractStreamingWriter.java:97)
at org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.initializeOperatorState(StreamOperatorStateHandler.java:134)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:285)
at org.apache.flink.streaming.runtime.tasks.RegularOperatorChain.initializeStateAndOpenOperators(RegularOperatorChain.java:106)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restoreStateAndGates(StreamTask.java:799)
at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$restoreInternal$3(StreamTask.java:753)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.call(StreamTaskActionExecutor.java:55)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restoreInternal(StreamTask.java:753)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restore(StreamTask.java:712)
at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:751)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:566)
at java.base/java.lang.Thread.run(Thread.java:829)
- 장애 대응 시 참고한 문서: https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/deployment/filesystems/overview/
- 위 문서를 참고하여 아래 기재 되어 있는 maven 주소에서
flink-s3-fs-hadoop-1.19.0.jar파일을 다운로드 받은 후$PYFLINK_HOME/lib경로에 위치 시키면 된다.
(단, 문서에서는$PYFLINK_HOME/plugins/s3-fs-hadoop/flink-s3-fs-hadoop-1.19.0.jar와 같이 위치 시키라고 소개하지만 이럴 경우 여전히 동작하지 않는데lib경로에 위치 시키면 정상적으로 동작한다.)
# flink-s3-fs-hadoop-1.19.0.jar 다운로드 URL: https://mvnrepository.com/artifact/org.apache.flink/flink-s3-fs-hadoop/1.19.0
# 파일은 내 로컬 ~/Downloads 경로에 다운로드 되었다.
$ cd ~/Downloads
$ ls | grep s3
>> flink-s3-fs-hadoop-1.19.0.jar
# PYTLINK_HOME 의 lib 경로로 이동
$ cd $PYFLINK_HOME/lib/
# Kafka 관련 jar 파일들은 ~/Study/Flink/lib 로 복사
$ cp ~/Downloads/flink-s3-fs-hadoop-1.19.0.jar $PYFLINK_HOME/lib/# 다시 run.py 실행
$ run.py
>>
2024-09-09 22:29:39,124 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl [] - Scheduled Metric snapshot period at 10 second(s).
2024-09-09 22:29:39,124 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl [] - s3a-file-system metrics system started
# Filesystem connector 실행 성공!!3-1. com.amazonaws.SdkClientException Error 대응방법
만약,
flink-s3-fs-hadoop-1.19.0.jar파일을$PYFLINK_HOME/lib경로에 위치 시킨 후
정상 동작하는가 싶다가 아래와 같이com.amazonaws.SdkClientExceptionError 가 발생하면
AWS S3 접근에 필요한 인증 권한이 없어서 발생한 오류일 것이다.
Caused by: com.amazonaws.SdkClientException: Unable to load AWS credentials from environment variables (AWS_ACCESS_KEY_ID (or AWS_ACCESS_KEY) and AWS_SECRET_KEY (or AWS_SECRET_ACCESS_KEY))
at com.amazonaws.auth.EnvironmentVariableCredentialsProvider.getCredentials(EnvironmentVariableCredentialsProvider.java:49) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]
at org.apache.hadoop.fs.s3a.AWSCredentialProviderList.getCredentials(AWSCredentialProviderList.java:177) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.getCredentialsFromContext(AmazonHttpClient.java:1269) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.runBeforeRequestHandlers(AmazonHttpClient.java:845) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:794) ~[flink-s3-fs-hadoop-1.19.0.jar:1.19.0]🏷️ 대응 방법은 두 가지 정도 있다.
첫 번째,
나의 경우 AWS SSO 로그인 중이기 때문에 세션 기간 마다 발급 되는 액세스키, 시크릿키, 토큰 정보를 아래와 같이 환경 변수로 등록해주었다.
Flink 에서 해당 환경변수 이름을 검색하여 알아서 인증에 사용하기 때문에 환경변수만 등록 해도 동작한다.
(차후 AWS Managed Flink 에 App deploy 할 경우 키 정보가 아닌 App 의 IAM Role 이 S3 버킷에 접근 가능하면 된다.)
$ export AWS_ACCESS_KEY_ID="my-access-key"
$ export AWS_SECRET_ACCESS_KEY="my-secret-key"
$ export AWS_SESSION_TOKEN="my-token"두 번째,
$PYFLINK_HOME/conf/config.yaml 파일에 키 정보를 입력 하면 된다.
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/filesystems/s3/ 문서 내용을 참고하여 config.yaml 에 아래와 같이 내용을 추가한 후 저장하면 된다.
# $PYFLINK_HOME/conf/config.yaml
s3.access-key: your-access-key
s3.secret-key: your-secret-key그리고 다시
run.py를 실행하면 아래와 같은 로그와 함께 S3 에 적재 된 파일을 확인할 수 있다.
2024-09-09 22:37:13,137 INFO org.apache.flink.fs.s3.common.writer.S3Committer [] - Committing test/year=2024/month=09/day=09/hour=22/compacted-part-3c1c3a8b-f216-48cc-8d02-891cf581a045-8-0 with MPU ID XvFXKrFF9tZXChNr7q6Xna_IEdkLl5lmFSpfIR3YhevWwF0zK6JGhe1bVIGd4tCcJz_RU8KfJsMdabbhw7FFEFUmxrBBoznivuwvxznppb8BRjXJB3KBx4mrsZdkpwVULx5.VN6WjA0nRxMxLM2H24m..WVNkByS3ctBmoL5rvA-
2024-09-09 22:37:13,416 INFO org.apache.flink.connector.file.table.utils.CompactFileUtils [] - Compaction time cost is '0.424S', output per file as following format: name=size(byte), target file is '{s3a://my-bucket/test/year=2024/month=09/day=09/hour=22/compacted-part-3c1c3a8b-f216-48cc-8d02-891cf581a045-8-0=125}', input files are '{s3a://my-bucket/test/year=2024/month=09/day=09/hour=22/.uncompacted-part-3c1c3a8b-f216-48cc-8d02-891cf581a045-8-0=125}'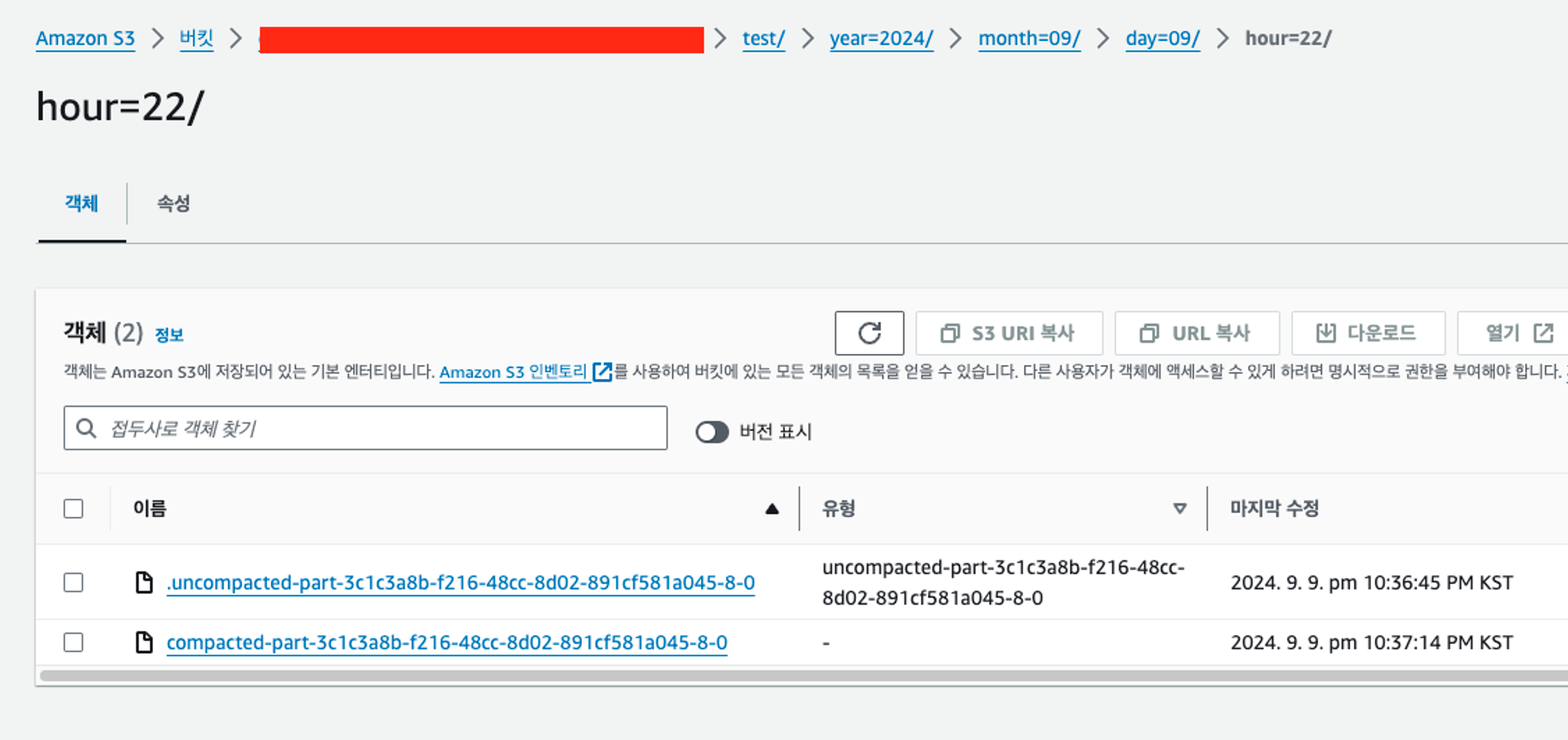
🏷️ 파일 이름에 prefix 로 compacted 가 붙은 파일은 압축이 완료된 파일이고 .uncompacted 는 압축이 미완료 된 파일이다.
참고 자료
- Flink FifleSystem - flink-s3-fs-hadoop-1.19.0.jar Maven 다운로드 주소
- pyflink 로깅하는 방법
- Python용 Apache Flink용 매니지드 서비스 생성 및 실행 애플리케이션
- Flink Docs(Table & SQL Connectors)
- Flink Docs(File Systems)
- Flink Docs(Amazon S3 with Filesystmes plugins)
- Flink Docs(Plugins)
- Github(aws flink S3Sink 예제 코드)
다음 게시글에서 로컬에서 테스트한 코드를 이용하여 AWF Manged Flink 에 App deploy 를 위한 문서도 정리할 예정이다.
