Refs
- Spark [Driver and Executor] Memory Management Deep Dive: https://www.youtube.com/watch?v=0ym8OJkA7x0
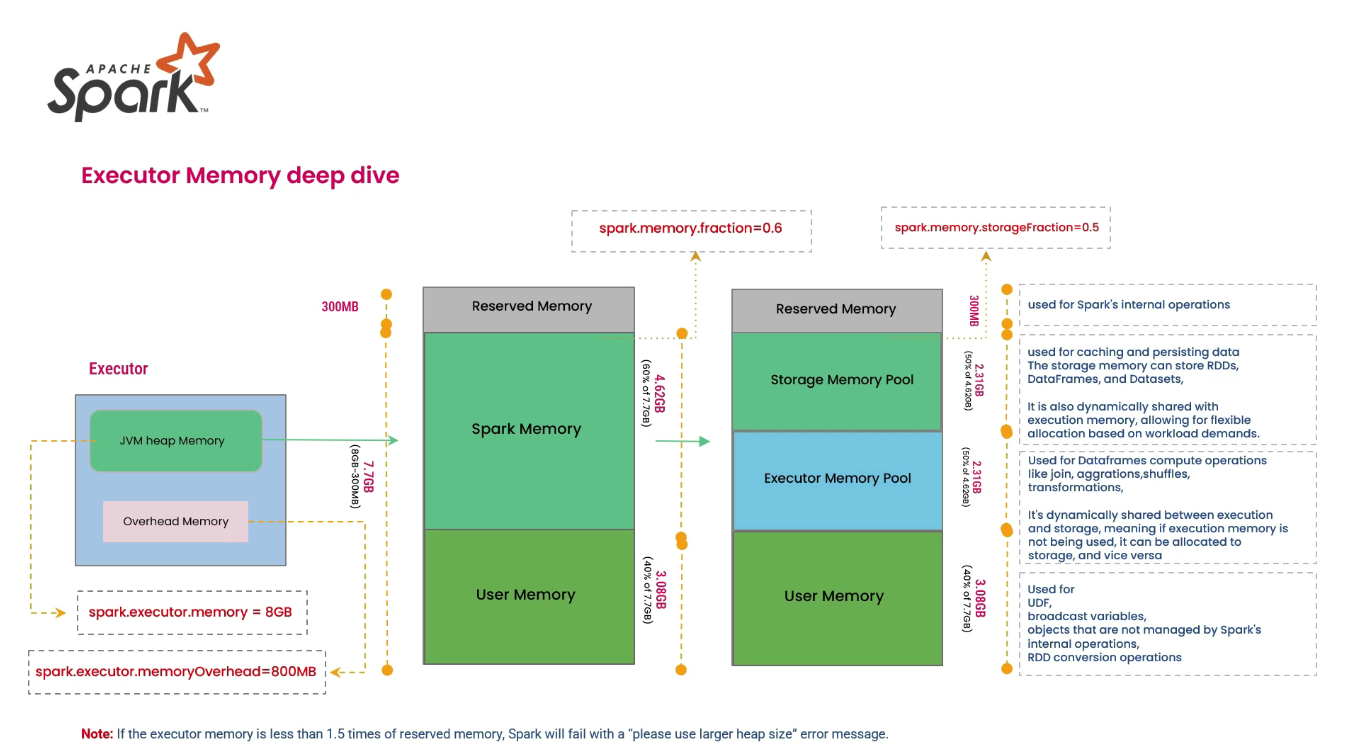
1. Spark Executor Memory 구조
Spark Executor의 메모리 관리는 Unified Memory Manager 모델(Spark 1.6+)을 따르며, JVM Heap 내에서 크게 3가지 영역으로 구분됩니다.
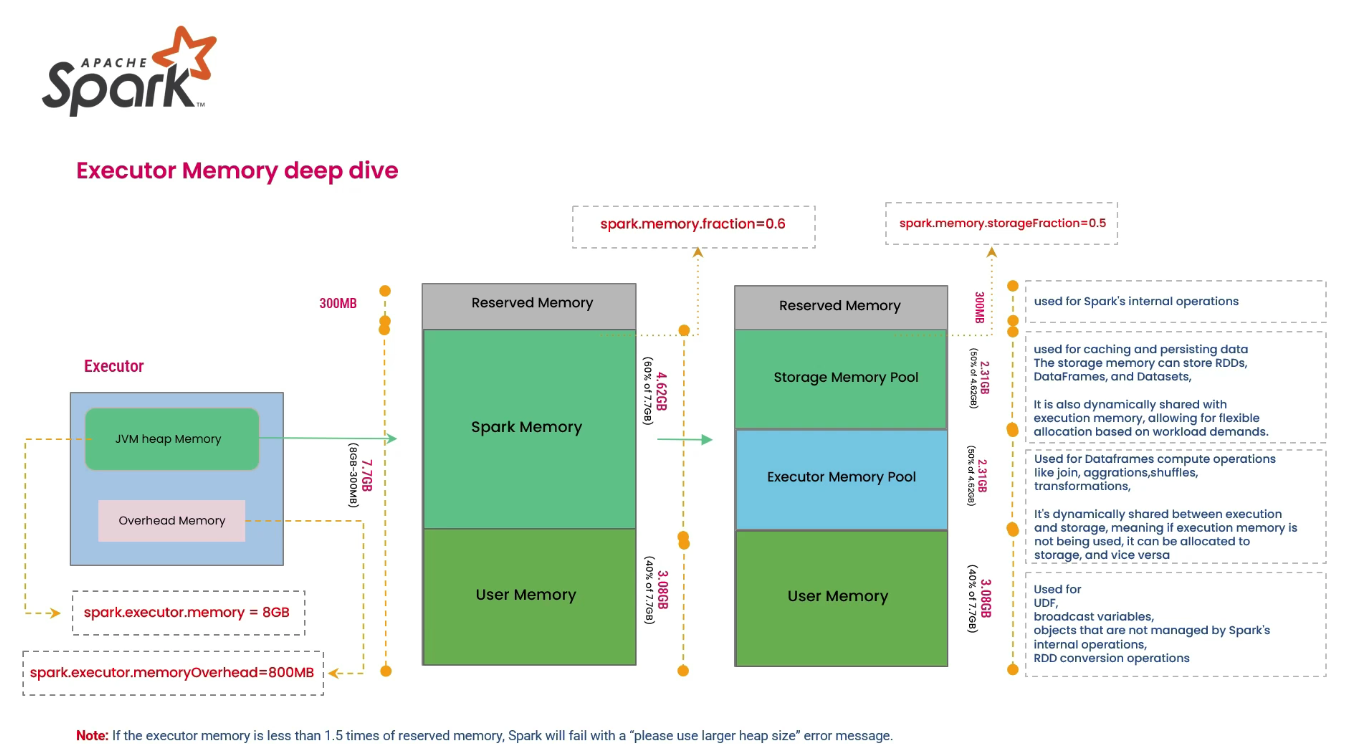
주요 메모리 영역 상세
| 영역 (Region) | 설명 (Description) | 계산식 / 특징 |
|---|---|---|
| Reserved Memory (예약 메모리) | Spark 엔진 자체 구동을 위해 예약된 필수 공간입니다. | • 기본값: 300 MB (고정) • 사용자 변경 불가 |
| User Memory (사용자 메모리) | 사용자가 작성한 코드(UDF, RDD 변환 등)에서 사용하는 데이터 구조나 메타데이터를 저장합니다. | • Calculation: (Java Heap - Reserved) * (1 - spark.memory.fraction)• Spark가 직접 관리하지 않음 |
| Unified Memory (통합 메모리) | Storage와 Execution이 공유하는 동적 공간입니다. | • Calculation: (Java Heap - Reserved) * spark.memory.fraction |
Unified Memory 내부 구분 (Storage vs Execution)
| 구분 | 역할 | Spill 여부 |
|---|---|---|
| Storage Memory | 캐싱된 RDD, Broadcast 변수 등이 저장 | 캐시 공간 부족 시 LRU 방식으로 Eviction 발생 (Disk로 이동 가능) |
| Execution Memory | Shuffle, Join, Sort, Aggregation 등 연산 시 필요한 버퍼 | 공간 부족 시 Spill 발생 (Disk I/O 유발) |
2. 메모리 계산 예시 (Case: 16GB Memory, 4 Cores)
실제 운영 환경에서의 메모리 할당 계산 과정을 살펴봅니다.
설정값 (Configuration)
spark.executor.memory: 16g (16384 MB)spark.executor.cores: 4spark.memory.fraction: 0.6 (기본값)
단계별 계산 (Step-by-Step Calculation)
| 단계 | 항목 | 계산 과정 | 결과 값 |
|---|---|---|---|
| Step 1 | Total Heap | spark.executor.memory | 16,384 MB |
| Step 2 | Usable Memory | Total Heap - Reserved Memory(300MB) | 16,084 MB |
| Step 3 | Unified Memory (Total) | Usable Memory * 0.6 | 9,650.4 MB (약 9.42 GB) |
| Step 4 | Execution Memory (Slot당 평균) | Unified Memory / spark.executor.cores | 2,412.6 MB (약 2.35 GB) |
| Step 5 | User Memory | Usable Memory * 0.4 | 6,433.6 MB (약 6.28 GB) |
인사이트: 16GB Executor를 사용하더라도, 실제 Task 하나가 셔플 연산에 안전하게 쓸 수 있는 메모리는 약 2.35GB 수준입니다. 이 단일 파티션 크기를 초과하면 Spill이 발생할 확률이 매우 높습니다.
3. Shuffle Write/Read와 Spill 발생 시나리오
Spill 발생 여부는 작업 성능에 치명적인 영향을 미칩니다.
3.1 Spill이 발생하지 않는 경우 (Ideal Case)
메모리(Execution Memory) 버퍼가 충분하여, 디스크 임시 쓰기 없이 데이터 처리가 완료되는 이상적인 상황입니다.
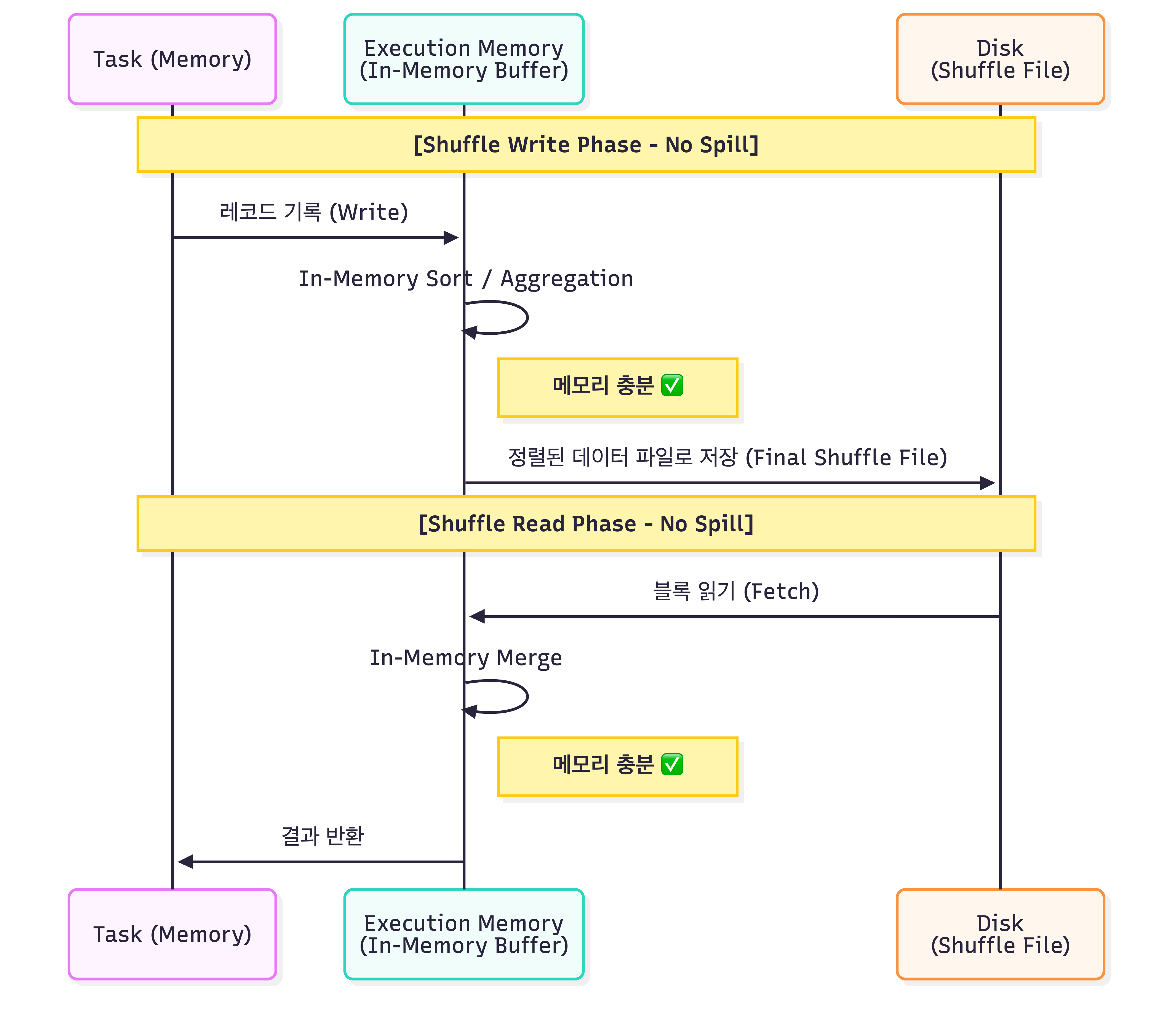
sequenceDiagram
participant T as Task (Memory)
participant EM as Execution Memory<br/>(In-Memory Buffer)
participant D as Disk<br/>(Shuffle File)
Note over T, D: [Shuffle Write Phase - No Spill]
T->>EM: 레코드 기록 (Write)
EM->>EM: In-Memory Sort / Aggregation
Note right of EM: 메모리 충분 ✅
EM->>D: 정렬된 데이터 파일로 저장 (Final Shuffle File)
Note over T, D: [Shuffle Read Phase - No Spill]
D->>EM: 블록 읽기 (Fetch)
EM->>EM: In-Memory Merge
Note right of EM: 메모리 충분 ✅
EM->>T: 결과 반환3.2 Spill이 발생하는 경우 (Spill Case)
Execution Memory 한계를 초과하여, 중간 결과(Temp File)를 디스크에 썼다가 다시 읽어야 하는 상황입니다. I/O 증폭이 발생합니다.
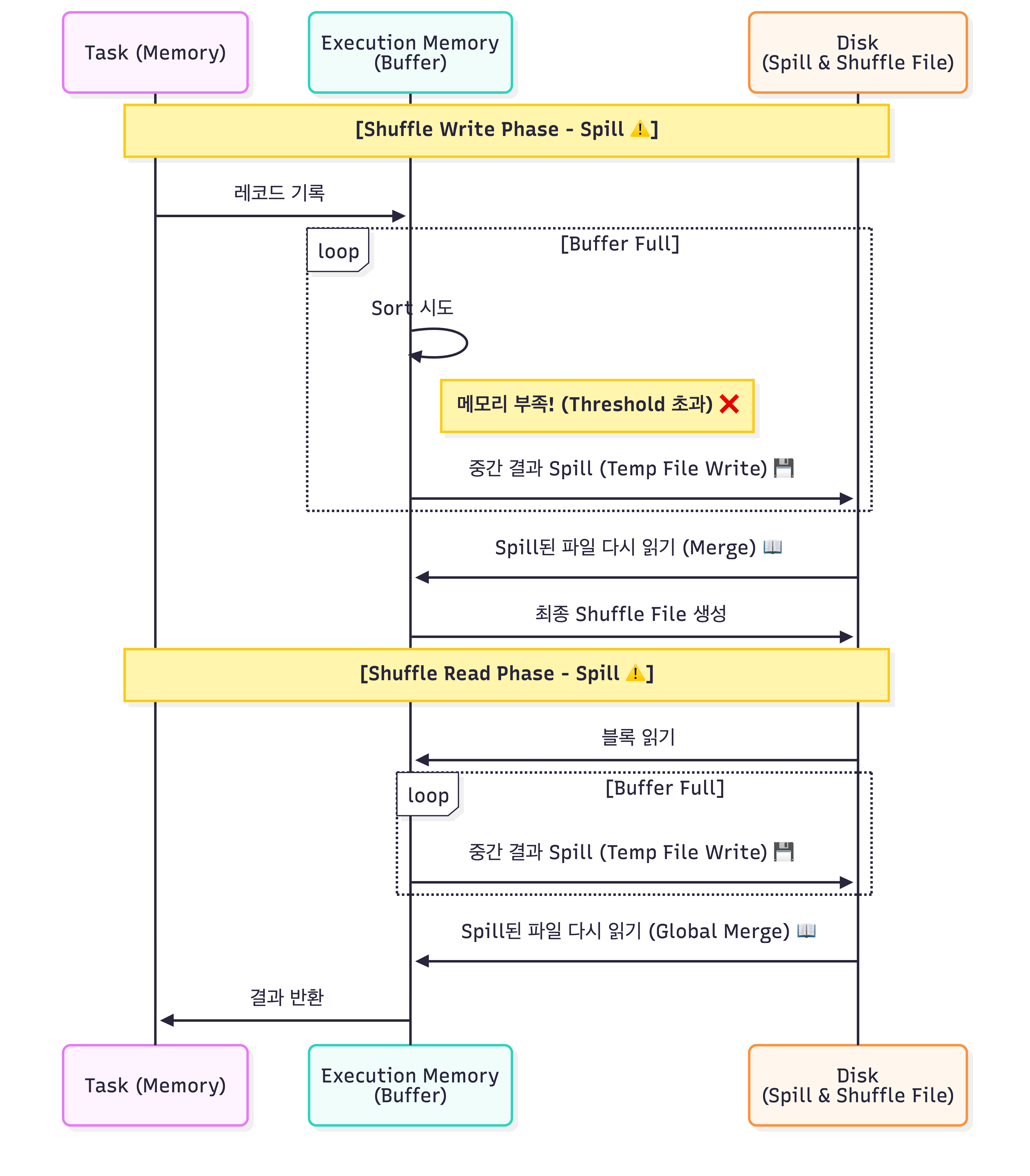
sequenceDiagram
participant T as Task (Memory)
participant EM as Execution Memory<br/>(Buffer)
participant D as Disk<br/>(Spill & Shuffle File)
Note over T, D: [Shuffle Write Phase - Spill ⚠️]
T->>EM: 레코드 기록
loop Buffer Full
EM->>EM: Sort 시도
Note right of EM: 메모리 부족! (Threshold 초과) ❌
EM->>D: 중간 결과 Spill (Temp File Write) 💾
end
D->>EM: Spill된 파일 다시 읽기 (Merge) 📖
EM->>D: 최종 Shuffle File 생성
Note over T, D: [Shuffle Read Phase - Spill ⚠️]
D->>EM: 블록 읽기
loop Buffer Full
EM->>D: 중간 결과 Spill (Temp File Write) 💾
end
D->>EM: Spill된 파일 다시 읽기 (Global Merge) 📖
EM->>T: 결과 반환4. Spill 유무에 따른 성능 및 동작 비교
| 비교 항목 | Spill 발생 안 함 (No Spill) ✅ | Spill 발생 함 (Spill) ⚠️ |
|---|---|---|
| 사용 자원 | RAM (Execution Memory) | RAM + Disk (Temp Space) |
| 동작 메커니즘 | In-Memory 연산 (Sort, GroupBy) | Memory Full → Disk Write (Spill) → Disk Read (Merge) |
| Disk I/O | 1회 Write / 1회 Read (최소화) | I/O 증폭 발생 (Spill File Write/Read 추가) |
| 성능 (Latency) | 빠름 (CPU/Memory 속도) | 느림 (Disk I/O 병목 + Serialization 오버헤드) |
| GC (Garbage Collection) | 안정적 | 객체 생성/해제 급증으로 GC 빈도 및 Pause 시간 증가 |
| 해결 방안 | - | • spark.executor.memory 증가• spark.sql.shuffle.partitions 증가 (Task당 데이터 크기 감소)• Skew 데이터 처리 |
핵심 요약
- 메모리 한계 인지: 16GB Executor 할당 시 Task당 가용 Execution Memory는 약 2.4GB에 불과합니다.
- Spill의 비용: Spill 발생 시 Disk I/O와 직렬화 비용으로 인해 성능이 급격히 저하됩니다.
- 튜닝 포인트: 파티션 크기를 Execution Memory 이내로 유지하도록
spark.sql.shuffle.partitions를 조절하거나 메모리를 증설해야 합니다.
제가 잘못 이해한 내용이 있다면 누구든, 언제든 댓글 부탁드립니다.🙇♂️

안녕하세요. 데이터 엔지니어 김재민 입니다.