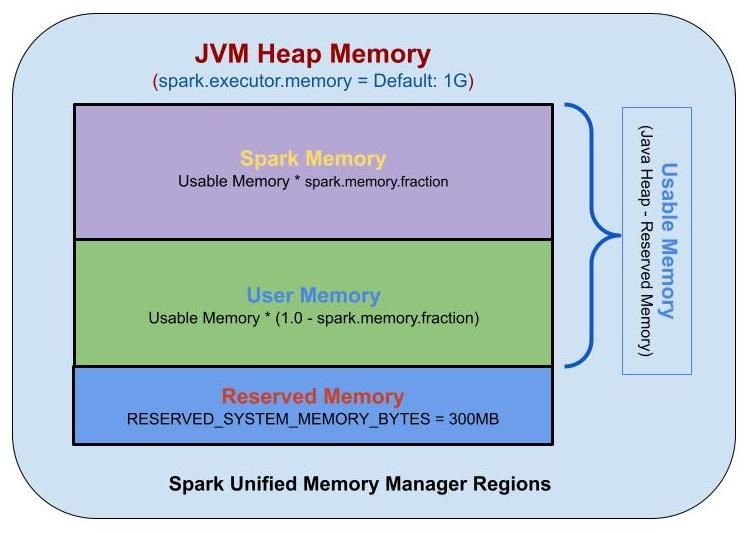
0. Background
이번 게시글에서는 Spark Executor Memory Architecture를 이해하고, Spark 메트릭을 참고하여 애플리케이션의 성격(Static vs Dynamic)에 맞는 리소스 산정 전략을 가이드합니다.
1. Executor Memroy Architecture
이미지 출처: https://www.youtube.com/playlist?list=PLCLE6UVwCOi1r-LnSDyM-efVK9NpWQMEt
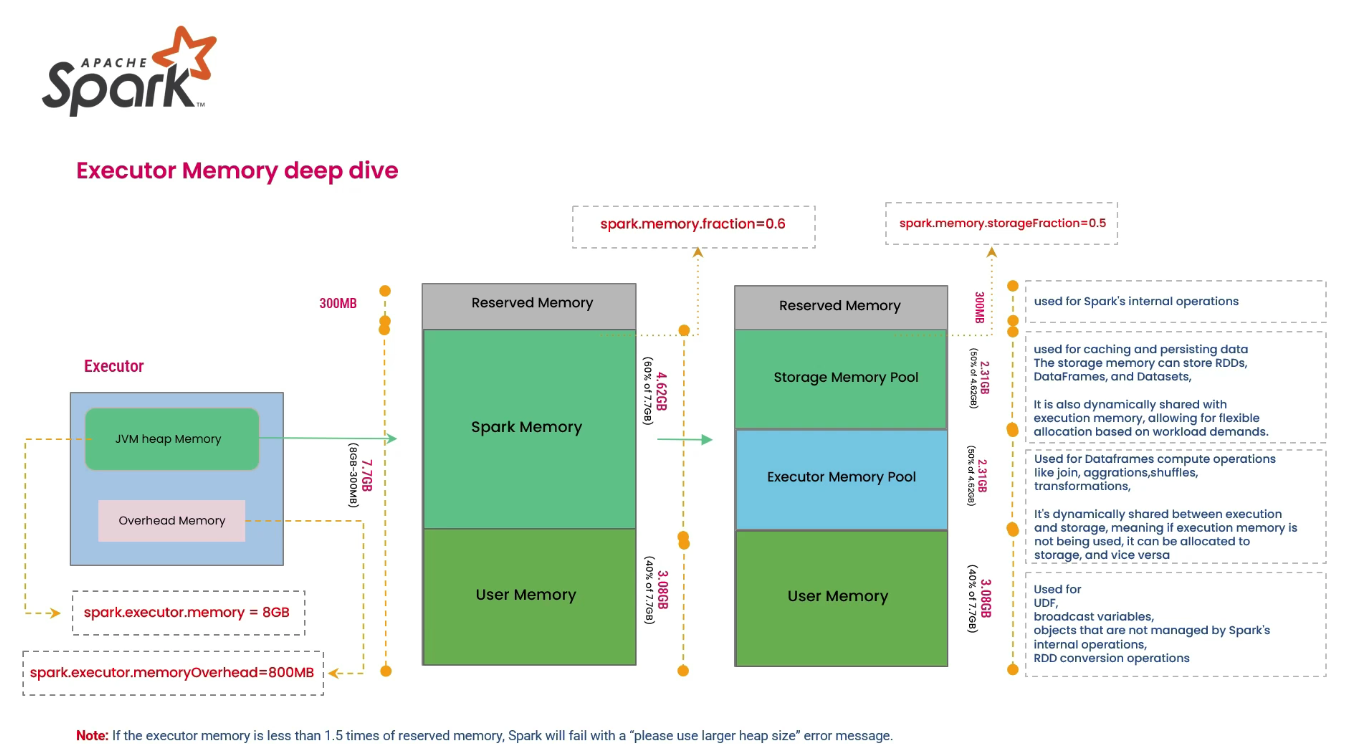
1-1. 메모리 영역별 사용 시점 정리
| 메모리 영역 (Unified Memory 기준) | 언제 쓰이나? (트리거/상황) | 대표 작업/연산 예시 | 부족하면 어떻게 되나? (동작 원리) | Spark UI에서 주로 오르는 지표/증상 |
|---|---|---|---|---|
| Storage memory (캐시/퍼시스트 풀) | RDD/DataFrame을 cache/persist 하거나, shuffle/연산 결과 블록을 BlockManager가 메모리에 유지하려 할 때 | cache(), persist(MEMORY_ONLY/MEMORY_AND_DISK), 반복 조회되는 dimension 테이블 캐시, intermediate 결과 캐시 | 1) 캐시 블록 eviction(퇴출) 발생 → 다시 계산/재읽기 증가 2) MEMORY_AND_DISK면 부족분을 디스크에 저장(storage-level spill) 3) Execution이 급하면 Storage가 빌려준 메모리를 회수당함(borrow/evict) | Storage 탭: RDD 캐시 사이즈/블록 수 감소, Dropped Blocks 증가(환경에 따라) / Executors 탭: Storage Memory Used가 꽉 차고 캐시가 들쑥날쑥 / 반복 실행 시 stage가 다시 길어짐(캐시가 안 남아있음) |
| Execution memory (연산 풀: sort/join/agg/shuffle) | 태스크가 연산 중 버퍼/해시맵/정렬 메모리 같은 “중간 상태”를 잡아야 할 때 (Spark SQL의 핵심 병목 지점) | groupBy/agg, distinct, orderBy/sort, window, join(SMJ/SHJ), repartition, sortWithinPartitions, shuffle read/write 병합/정렬 | 1) Execution 풀 부족 시 Spark는 OOM 대신 spill을 선택: ExternalSorter/UnsafeExternalSorter가 디스크로 런(run) 파일을 쓰고 merge 2) spill로 인해 디스크 I/O + (de)serialization + merge 비용 증가 3) 극단적이면 task 지연이 누적되어 tail latency(꼬리) 커짐 | Stages > Tasks: Spill (memory/disk) 증가, Peak Execution Memory 높음, Duration 증가 / (SQL 탭) 해당 연산자 주변 stage가 느려짐 / Shuffle Read/Write time 증가(merge/정렬 포함) / GC Time 증가(특히 on-heap 경로일 때) |
| User memory (Spark가 직접 관리하지 않는 heap 영역) | Spark 풀 밖의 JVM heap을 사용자 코드/라이브러리/객체가 사용할 때 | UDF/UDTF 내부 객체 생성, 큰 컬렉션(List/Map) 생성, JSON 파싱 객체, 커스텀 클라이언트 버퍼, collect()/toLocalIterator()로 로컬 객체 증가(Executor/Driver 모두) | 1) Spark는 User memory를 통제 못 함 → 부족하면 GC 압박이 먼저 오고 2) 계속 쌓이면 OutOfMemoryError 또는 Container killed(YARN) 같은 운영 사고로 이어질 수 있음 3) Execution/Storage가 남아도 User가 잡아먹으면 전체가 불안정해짐 | Stages > Tasks: GC Time 급증(특히 일부 task만) / Executors 탭: executor별 메모리 사용률/GC 편차가 큼 / 로그에 OutOfMemoryError, GC overhead limit exceeded / (YARN) 컨테이너 killed, exit code 137/143 등 |
1-2. 메트릭 판별 노하우
- Spill(memory/disk) + Peak Execution Memory가 같이 오른다 → 거의 항상 Execution memory pressure 신호
- cache/persist를 썼는데도 반복 실행이 빨라지지 않는다 → Storage eviction으로 캐시가 남지 않는 경우가 흔함
- Spill은 별로 없는데 GC만 튄다 → UDF/객체 생성 등 User memory pressure 가능성이 높음
2. Spark Event Log 분석
리소스 산정의 시작은 현재 애플리케이션의 리소스 사용 패턴을 파악하는 것입니다. 아래는 실제 운영 환경에서 수집된 Spark 애플리케이션의 주요 메트릭 샘플입니다. Spark History Server 또는 Dataflint같은 툴을 이용해 Job duration, Shuffle size 등 메트릭 정보를 파악할 수 있습니다.
2.1 Event Log Metric Sample
| App ID | Duration (s) | Idle Cores (%) | Peak Mem (%) | Total Spill (Disk) | Max Spill (Disk) | Max Shuffle Read | Max Shuffle Write |
|---|---|---|---|---|---|---|---|
| my_spark_2025-11-25 | 2202.9 | 76.05 | 89.18 | 157.55 GB | 157.55 GB | 1.0 TB | 1.0 TB |
| my_spark_2025-11-26 | 1319.7 | 27.81 | 87.11 | 2.36 TB | 217.56 GB | 0.98 TB | 0.98 TB |
Note:
Total Spill이 높거나Idle Cores가 높은 작업은 리소스 낭비나 병목이 발생하고 있다는 신호입니다. 또한, 병목 지점 Stage에서 수행되는 각 Task duration 및 GC time이 너무 길다면 Partition 최적화가 필요할 수 있습니다. 아래의 산정 가이드를 통해 내 작업에 맞는 최적의 설정을 찾아보세요.
3. Default Strategy: Static Allocation (균등한 데이터 패턴)
Input, Output, Shuffle Size가 비슷하고 데이터 분포가 고른 일반적인 배치 작업에는 Static Allocation이 적합합니다. Executor를 고정 할당하여 불필요한 컨테이너 요청/반납 오버헤드를 제거하고 안정적인 성능을 확보합니다.
3.1 기본 규칙 (Spec)
먼저 아래의 추천 기본값을 확인하세요. 128MB 파티션 크기와 4 Core Executor 조합은 HDFS I/O 처리량과 GC 효율성을 고려하여 Spark에서 추천되는 값입니다.
| 항목 | 설명 | 값 |
|---|---|---|
| allocation mode | 자원 요청 모드 | static |
| target.file.size | Write to HDFS 목표 파일 크기 | 256MB |
| target.shuffle.partition.size | 셔플 파티션 별 목표 크기 | 128MB |
| spark.memory.fraction | spark unified memory 비율 | 0.6(default) |
| spark.executor.memoryOverheadFactor | executor 메모리 오버헤드 비율(default: 0.1) - PySpark 사용 시 JVM-Python 통신 비용 고려하여 0.2로 상향 (Memory Spill 빈번 시 0.3~0.5) | 0.2~0.3 |
| core.per.executor | Spark Executor 당 추천 코어 수 | 4cores |
| waves.per.stage | 하나의 Stage 처리를 위해 Task가 병렬 수행되는 배수 (Waves) - e.g. 8000개 Task / 800 Total Cores = 10 Waves | 3-10회 |
| safety.factor | 메모리 산정 안전 계수 - 압축 해제 시 데이터 팽창, 직렬화 버퍼, Skew 등을 고려하여 여유 공간 확보 | 3-5 |
3.2 상세 산정 과정 (Step-by-Step)
이제 1TB 규모의 Shuffle 데이터가 발생하는 작업을 가정하고, 단계별로 계산해 보겠습니다.
| 항목 | 계산 과정 설명 | 산출 예시 |
|---|---|---|
| 1. 셔플 파티션 수 (spark.sql.shuffle.partitions) | MAX 셔플 크기를 목표 파티션 크기(128MB)로 나눕니다.Max Shuffle(1TB=1 * 1024 * 1024MB) / 128MB | 8,192 partitions |
| 2. 전체 필요 코어 수 (total.executor.cores) | 전체 파티션을 목표 Waves(10회)로 나누어 필요한 총 슬롯 수를 구합니다.8,192 partitions / 10회 = 819.2 ≒ 820cores | 820 cores |
| 3. Executor 인스턴스 수 (spark.executor.instances) | 총 필요 코어를 Executor 당 코어 수(4)로 나눕니다.820 cores / 4 | 205 개 |
| 4. Task 당 처리 데이터 (data.size.per.task) | 파티션 크기에 안전 계수(Safety Factor 3)를 곱해 메모리 버퍼를 확보합니다.128MB * 3 | 384MB |
| 5. Executor 연산 메모리 (execution.memory) | Task 당 데이터 크기에 병렬 처리 코어 수(4)를 곱합니다.384MB * 4cores | 1,536MB |
| 6. Executor 전체 메모리 (spark.executor.memory) | 연산 메모리(Execution)와 저장 메모리(Storage)를 5:5로 보고 2배를 한 뒤, Unified Memory 비율(0.6)로 나누어 역산합니다.(1,536MB * 2 / 0.6) + 300MB(Reserved) | 약 5.4GB → 6GB 설정 |
결론: 균등한 데이터 패턴일 때, 1TB 처리를 위해 4cores/6GB executor 205개로 대응할 수 있습니다. 물론,
target.shuffle.partition.size와waves.per.stage를 목표하는 상황에 맞춰 사용자에 맞는 리소스를 재구성할 수 있습니다. 예를 들어, 전체 Job Duration을 단축하기 위해waves.per.stage를 10에서 5로 계산하여 더 많은 Cores를 할당 시킬 수 있습니다. 한정된 자원 내에서 가능한 병렬성을 높여 작업하는 것이 좋습니다. 반대로, executor 별 메모리를 증가 시키고target.shuffle.partition.size를 너무 높이면 GC부하 등의 오버헤드로 오히려 비효율이 발생할 수 있으니 참고 하면 좋겠습니다.
Note: 상세 산정 과정 중 5번, 6번 단계가 어색할 경우
Spark Executor Memory 구조 및 Shuffle Spill 분석내용을 참고하면 좋습니다.
3.3 Write to HDFS 파티션 최적화 팁
input, output 크기가 일정한 배치 작업일 경우 HDFS 쓰기 단계 직전에 파티션을 Write size / target.file.size(256MB) 수만큼 조정하는 것이 좋습니다. 또한, write 시 partitionBy를 이용할 경우. 아래와 같이 repartitionByRange를 이용하여 최대한 하나의 파티션에 같은 파티션 데이터가 존재하도록 정렬하고, 하나의 Task에서 한 번의 write만 진행하도록 하는 것이 좋습니다.
repartitionByRange() 이용하기
from pyspark.sql.functions import rand
total_hdfs_file_size_mb = 25600
target_file_size_mb = 256
target_partitions = int(total_hdfs_file_size_mb / target_file_size_mb)
partition_keys = ['event_type', 'event_date']
df_result = df.repartitionByRange(target_partitions, *partition_keys, rand())
df_result.write.format("parquet")\
.mode("overwrite")\
.partitionBy(*partition_keys)\
.save(...)4. Advanced Strategy: Dynamic Allocation (불균등한 데이터 패턴)
join, explode 등으로 중간 셔플 데이터가 급증하거나, 실행 때마다 데이터 편차가 큰 경우 Dynamic Allocation을 사용합니다. 더 작은 파티션(64MB)을 사용하여 Data Skew에 유연하게 대처할 수 있습니다.
4.1 기본 규칙 (Spec)
파티션 크기를 64MB와 같이 줄이는 것이 핵심입니다. 이는 거대한 파티션이 생성될 확률을 낮춰 Spill, OOM(Out Of Memory)을 예방합니다. Yarn 클러스터를 이용하는 경우의 샘플 설정이며, 앞서 언급된 기본 규칙과 중복된 내용은 생략했습니다.
| 항목 | 설명 | 값 |
|---|---|---|
| allocation mode | 자원 요청 모드 | dynamic |
| spark.shuffle.service.enabled | 외부 셔플 서비스(ESS) 사용 활성화 | true |
| spark.dynamicAllocation.enabled | Executor 동적 할당 | true |
| spark.dynamicallocation.shuffletracking.enabled | K8S환경 추천 | false |
| target.shuffle.partition.size | 셔플 파티션 별 목표 크기 (Skew 저항성 강화) | 64MB |
| safety.factor | 메모리 안전 계수 (데이터 튐 현상 고려하여 상향) | 3-20 |
4.2 상세 산정 과정 (Step-by-Step)
동일한 1TB 셔플 작업이라도 Dynamic 환경에서는 더 보수적으로(안전하게) 계산합니다.
| 항목 | 계산 과정 설명 | 산출 예시 |
|---|---|---|
| 1. 셔플 파티션 수 (spark.sql.shuffle.partitions) | MAX 파티션 크기를 64MB로 줄여 개수를 2배 늘립니다.1TB / 64MB | 16,384 partitions |
| 2. 전체 필요 코어 수 (total.executor.cores) | 파티션이 늘어난 만큼 필요 코어 수도 증가합니다.16,384 partitions / 10회 | 1,639 cores |
| 3. Max Executors (spark.dynamicAllocation.maxExecutors) | 최대 확장 가능한 Executor 한계를 설정합니다.1,639 cores / 4 | 410 개 |
| 4. Task 당 처리 데이터 (data.size.per.task) | Skew가 심한 환경을 고려해 안전 계수를 10으로 높입니다.64MB * 10 | 640MB |
| 5. Executor 전체 메모리 (spark.executor.memory) | 높아진 안전 계수를 반영하여 메모리를 계산합니다.(640MB * 4cores * 2 / 0.6) + 300MB | 약 8.8GB → 10GB 설정 |
결론: 불균등한 데이터 패턴일 때, 4cores/10GB executor를 Dynamic Allocation 모드로 배포하면 작업 최적화에 도움이 될 수 있습니다. 만약, 할당 가능한 Max Executors가 부족할 경우
total.executor.cores를 10에서 20으로 높여 Max Executors를 205개로 낮출 수 있습니다. 다만, 그만큼 병렬성이 줄어들어 Job duration이 길어질 수 있습니다.
Note:
spark.dynamicAllocation.minExecutors과spark.dynamicAllocation.initialExecutors을 구하는 방법도 위3.2 상세 산정 과정을 응용할 수 있습니다. 각각 Min Suffle size, Median(or Avg) Shuffle Size를 이용하여 계산한total.executor.cores를core.per.executor(4)로 나누면 됩니다.
5. Reference: Spark Executor 메모리 구조별 상세 계산표 (Spec Sheet)
마지막으로, 다양한 메모리 옵션에 따른 실제 가용 메모리와 오버헤드를 정리한 표입니다.
(Spec: 4 Core, spark.memory.fraction=0.6, spark.executor.memoryOverheadFactor=0.1 기준)
| Executor mem (GiB) | Overhead (GiB) | Unified Memory (GiB) | Execution Memory (GiB) | Storage Memory (GiB) | Execution Memory per Core (GiB) | Storage Memory per core (GiB) | User Memory (GiB) | Reserved Memory (GiB) |
|---|---|---|---|---|---|---|---|---|
| 2 | 0.2 | 1.02 | 0.51 | 0.51 | 0.13 | 0.13 | 0.68 | 0.29 |
| 4 | 0.4 | 2.22 | 1.11 | 1.11 | 0.28 | 0.28 | 1.48 | 0.29 |
| 6 | 0.6 | 3.42 | 1.71 | 1.71 | 0.43 | 0.43 | 2.28 | 0.29 |
| 8 | 0.8 | 4.62 | 2.31 | 2.31 | 0.58 | 0.58 | 3.08 | 0.29 |
| 10 | 1.0 | 5.82 | 2.91 | 2.91 | 0.73 | 0.73 | 3.88 | 0.29 |
| 12 | 1.2 | 7.02 | 3.51 | 3.51 | 0.88 | 0.88 | 4.68 | 0.29 |
| 14 | 1.4 | 8.22 | 4.11 | 4.11 | 1.03 | 1.03 | 5.48 | 0.29 |
| 16 | 1.6 | 9.42 | 4.71 | 4.71 | 1.18 | 1.18 | 6.28 | 0.29 |
| 18 | 1.8 | 10.62 | 5.31 | 5.31 | 1.33 | 1.33 | 7.08 | 0.29 |
| 20 | 2.0 | 11.82 | 5.91 | 5.91 | 1.48 | 1.48 | 7.88 | 0.29 |
| 22 | 2.2 | 13.02 | 6.51 | 6.51 | 1.63 | 1.63 | 8.68 | 0.29 |
| 24 | 2.4 | 14.22 | 7.11 | 7.11 | 1.78 | 1.78 | 9.48 | 0.29 |
| 26 | 2.6 | 15.42 | 7.71 | 7.71 | 1.93 | 1.93 | 10.28 | 0.29 |
| 28 | 2.8 | 16.62 | 8.31 | 8.31 | 2.08 | 2.08 | 11.08 | 0.29 |
| 30 | 3.0 | 17.82 | 8.91 | 8.91 | 2.23 | 2.23 | 11.88 | 0.29 |
| 32 | 3.2 | 19.02 | 9.51 | 9.51 | 2.38 | 2.38 | 12.68 | 0.29 |
공식 (Formula)
Unified Memory=(Heap - 300MB Reserved) * 0.6Memory Overhead=Max(Heap * 0.1, 384MB)(PySpark 환경에서는Heap * 0.2이상 권장)
Summary
- Static Allocation: 128MB 파티션, 6GB 메모리로 오버헤드를 줄이세요. (안정적인 배치)
- Dynamic Allocation: 64MB 파티션, 10GB 메모리로 데이터 Skew를 방어하세요. (복잡한 셔플)
- Reference: 제공된 표를 참고하여 내 작업에 딱 맞는 메모리를 설정하세요.
제가 잘못 이해한 내용이 있다면 누구든, 언제든 댓글 부탁드립니다.🙇♂️
