
성능 개선 전에 테이블에 100만건의 데이터를 집어넣어야한다

더미 데이터 실제데이터처럼 만들어준다고해서 써봄!
낮은 확률로 중복이날 수 있다고 해서 닉네임 붙이고 뒤에 i값 넣으면 절대 중복이안일어나니 그렇게 사용했다.
처음 시도 – JPA saveAll()로 100만 건 넣기
Faker faker = new Faker();
List<User> users = new ArrayList<>();
for (int i = 0; i < 1_000_000; i++) {
User user = (new User(
faker.internet().emailAddress("user" + i),
faker.funnyName().name().concat(String.valueOf(i)),
"test_password"+i,
UserRole.ROLE_USER
));
users.add(user);
}
userRepository.saveAll(users);
실행하자마자 메모리 폭발 직전...
컴퓨터에서 비행기 소리남 ㄷㄷ
결국 OutOfMemory 에러로 실패
이유
- 100만 개를 한 번에 saveAll() 하면 EntityManager가 100만 개의 엔티티를 영속성 컨텍스트에 보관
- saveAll 함수도 뜯어보면 for문 돌리면서 save 갈기는건데, 100만건 insert문을 다 쏘고있으니깐 메모리가 터짐
개선 1 – 배치로 나눠 saveAll() + flush()
Faker faker = new Faker();
int batchSize = 5000;
long flushCnt = 0;
for (int i = 0; i < 1_000_000; i++) {
User user = (new User(
faker.internet().emailAddress("user" + i),
faker.funnyName().name().concat(String.valueOf(i)),
"test_password"+i,
UserRole.ROLE_USER
));
users.add(user);
if (i % batchSize == 0) {
userRepository.saveAll(users);
userRepository.flush(); // 즉시 DB 반영
users.clear(); // 메모리에서 제거
}
}- 훨씬 나아졌지만 여전히 JPA의 insert는 느림
- 성능에 민감한 상황에서는 한계
이거 엄청 오래 걸려서 처음에 오류나서 안되는줄알고 식겁했음
이유
개선된 점
-전체를 한 번에 처리하는 것보다 I/O 작업이 나뉘어 병렬성 또는 DB 처리 효율이 좋아짐.
- 한꺼번에 처리할 때보다 예상 가능하고 일정한 성능 유지 가능.
- batchSize (5000개) 단위로 flush() + clear()를 호출해 메모리 누수 방지.
문제점
- 여전히 5000개의 insert 쿼리
saveAll(users)가 5000개씩 묶어서 실행되더라도 insert 문이 5000개 나간다는 소리임
ㅇㅣ후로 시도에 하이버네이트에서 사용가능한 batch insert써보려고했는데,
Hibernate batch insert는 MySQL + IDENTITY 조합에서는 잘 안 된다고함..
지금 user의 id가 @GeneratedValue(strategy = GenerationType.IDENTITY)인데, 배치 insert 쓰려면 이 IDENTITY 부분을 바꿔줘야 해서 다른 방법을 찾기로함
최종 선택 – JdbcTemplate.batchUpdate() 활용
Faker faker = new Faker();
List<Object[]> batch = new ArrayList<>();
int batchSize = 5000;
for (int i = 0; i < 1_000_000; i++) {
batch.add(new Object[]{
faker.internet().emailAddress("user" + i),
faker.funnyName().name().concat(String.valueOf(i)),
"test_password"+i,
"ROLE_USER"
});
if ( i > 0 && i % batchSize == 0) {
jdbcTemplate.batchUpdate(
"INSERT INTO users (email, nickname, password, user_role) VALUES (?, ?, ?, ?)",
batch
);
batch.clear();
}
// 마지막 남은 데이터 처리
if (!batch.isEmpty()) {
jdbcTemplate.batchUpdate(
"INSERT INTO users (email, nickname, password, user_role) VALUES (?, ?, ?, ?)",
batch
);
}
}
처리 시간: 약 2~3분 안에 100만 건 insert 완료
application.properties에 아래 설정도 필수:
spring.datasource.url=jdbc:mysql://localhost:3306/spring_plus?rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=200
아니 ;;;;;;;;;;;;;;;;;;;;;;;
이거 게시글만 몇일전에 쓰던거라서 마무리하려고 사진 붙이는데
처리시간 다 찍어놓은거 원드라이브 삭제하면서 싹다날아감 실화에요?..................
ㄱ=....................................................
ㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠ
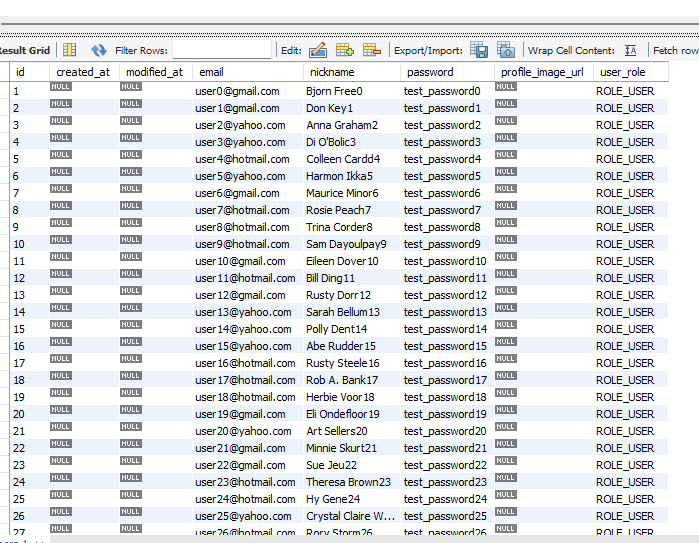
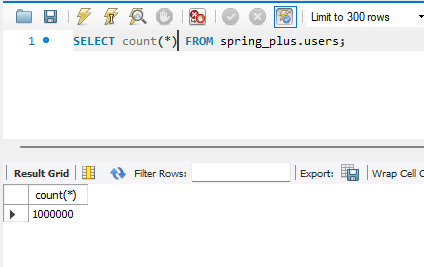
잘 들어왔음
배운점
- JPA는 쓰기 편하지만, 대용량 INSERT엔 맞지 않는다.
- 10만 건 이상이면 JdbcTemplate 같은 낮은 수준의 접근이 훨씬 빠름
flush(),clear()를 모르면 메모리 터질 수 있음- 사진은 제때제때 올려놓자..
추가로 JPA가 좋다고 무조건 쓰면 큰코다침 😇
탐색할때 인덱스 잘 타고있는지 확인도할수있음
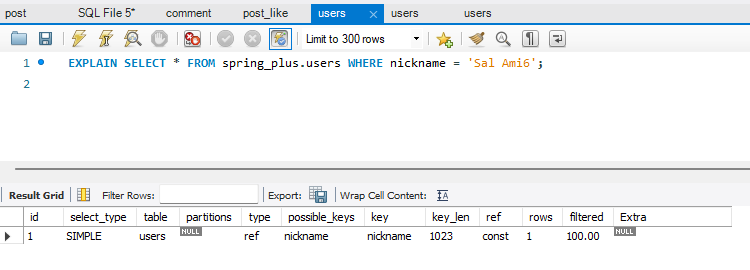

이거 넣는것도 너무 생각할게 많았어요 정말 ㅠㅠ