요즘 파이썬 기초 강의를 수강하며 판다스도 함께 배우고 있다.
판다스에서 랜덤 샘플링을 위한 작업으로 익힌 것을 유용하게 써먹을 수 있을 것 같아 기록해둔다.
주피터 노트북에서 작업했다.
1. 판다스 라이브러리 불러오기
테이블 작업을 위해 판다스를 불러온다. 'pd'라는 명칭으로 불러오는 것이 관례(?)라고 한다.
import pandas as pd2. 데이터 프레임 만들기
study라는 이름의 테이터 프레임을 아래와 같이 만든다.
아래는 아마 딕셔너리 표현방식으로 기재되었지만, 'group': 이나 'degeul':과 같은 정의 대신 아래와 같이 표현할 수도 있다.
columns = ["group", "degeul"]아무튼 아래와 같은 방식으로 데이터 프레임을 만들었는데,
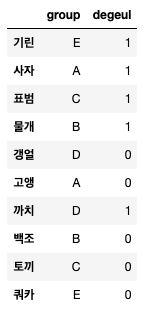
study = pd.DataFrame({'group': ["E", "A", "C", "B", "D",
"A", "D", "B", "C", "E"],
'degeul': [1, 1 , 1, 1, 0,
0, 1, 0, 0, 0],
},
index=["기린", "사자", "표범", "물개", "갱얼",
"고앵", "까치", "백조", "토끼", "쿼카"])그후 study를 입력하면 이렇게 나온다. (print(study) 입력하는 것보다 예쁨..)
3. 샘플링 함수 적용
여기서 아래와 같은 샘플링 작업을 하면 독립사건으로 2건을 랜덤추출할 수 있다.
study.sample(n=2)만일 세명을 하고 싶다면 n=2 대신 n=3을 입력하면 되고,
전체 비율의 50% 만큼 뽑고 싶다면 n 대신 frac=0.5를 입력하면 된다.
아무튼 한번 해봤더니 이렇게 나온다.
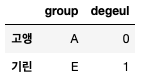
고앵씨가 진행, 기린씨가 서기하세요!
또 해봤더니 이렇게
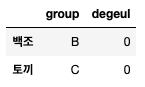
또
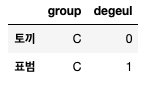
한 번 더
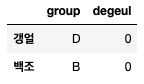
이런 결과에 따라 매 회의의 진행자, 서기를 정할 수 있다.
다만 이전의 사건이 다음 사건에 영향을 주지 않기 때문에,
누군가는 계속 할 수도(백조나 토끼처럼), 누군가는 한 번도 하지 않을 수도 있다.
그래서 이전 사건에 영향을 받도록 하는 방법도 궁금하다. 조만간 알아봐야지.
어쨌든 드디어 파이썬으로 랜덤추출을 해볼 수 있게 되어 기쁘다!

두려우면 시작하지 말고, 시작했으면 두려워하지 말자.