Graph-level Features and Graph kernels
1. Background
Graph-level features에 대해 알기 전에 사전 지식과 목표를 정의하고 넘어가 봅시다.
목표
전체 그래프 구조의 특징을 표현하는 features를 만들고자 합니다.
kernels methods
그래프와 그래프 사이의 similarity를 기반으로 feature vector대신 사용할 kernel을 디자인 합니다.
이렇게 디자인 된 kernel을 kernel SVM처럼 가공없이 바로 예측에 사용할 예정입니다.
2.Graph kernels
두 그래프 사이의 similarity를 측정하는 방법은 여러가지가 있지만 여기서는 두가지만 다루도록 하겠습니다.
- Graplet kernel
- Weisfeiler-Lehman kernel
Key Idea
핵심은 node를 word처럼 생각하여 Bag-of-Words를 구성하는 것 입니다.
예를 들어 보겠습니다.
그래프를 오직 노드의 갯수로만 따지면 위와 같은 사태가 벌어질 것 입니다.
여기에 degree 개념을 추가하여 각 degree에 해당하는 노드의 갯수를 세어 준다면 드디어 위 처럼 두 그래프를 구분 할 수 있게 됩니다.
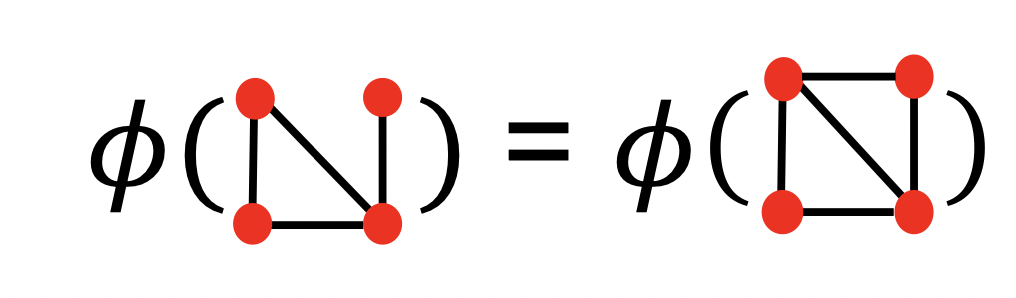
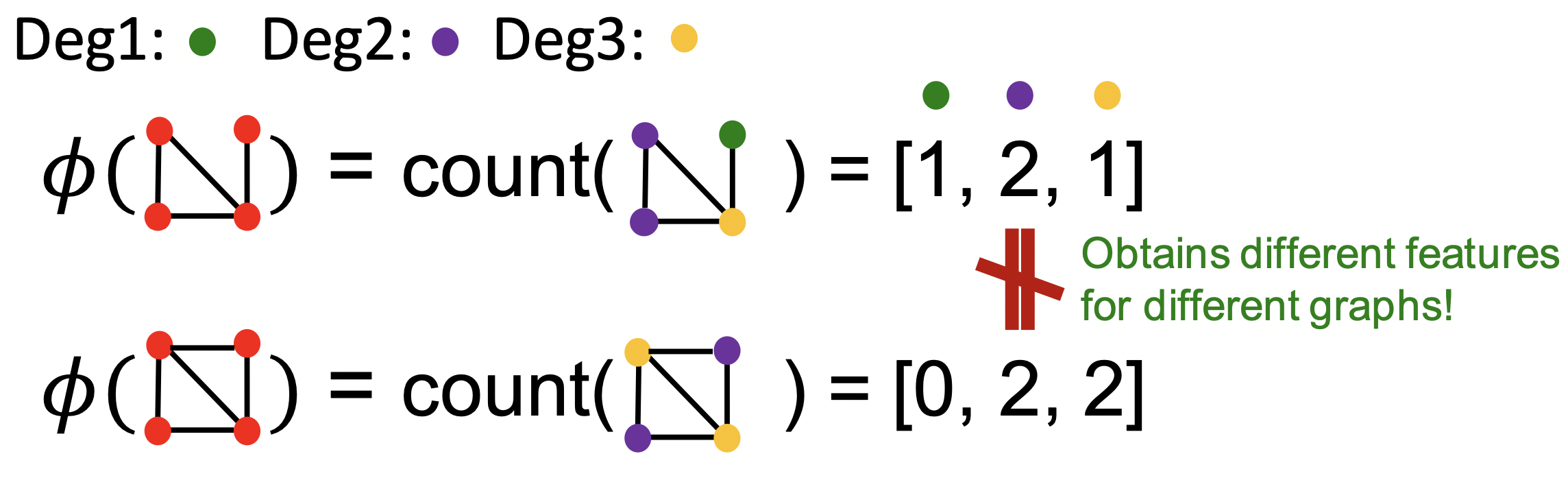
3. Graplet Features
간단하게 말해 그래프 상의 graplet의 갯수를 세어 주는 것 입니다.
예를 들자면 아래 와 같은 방식입니다.
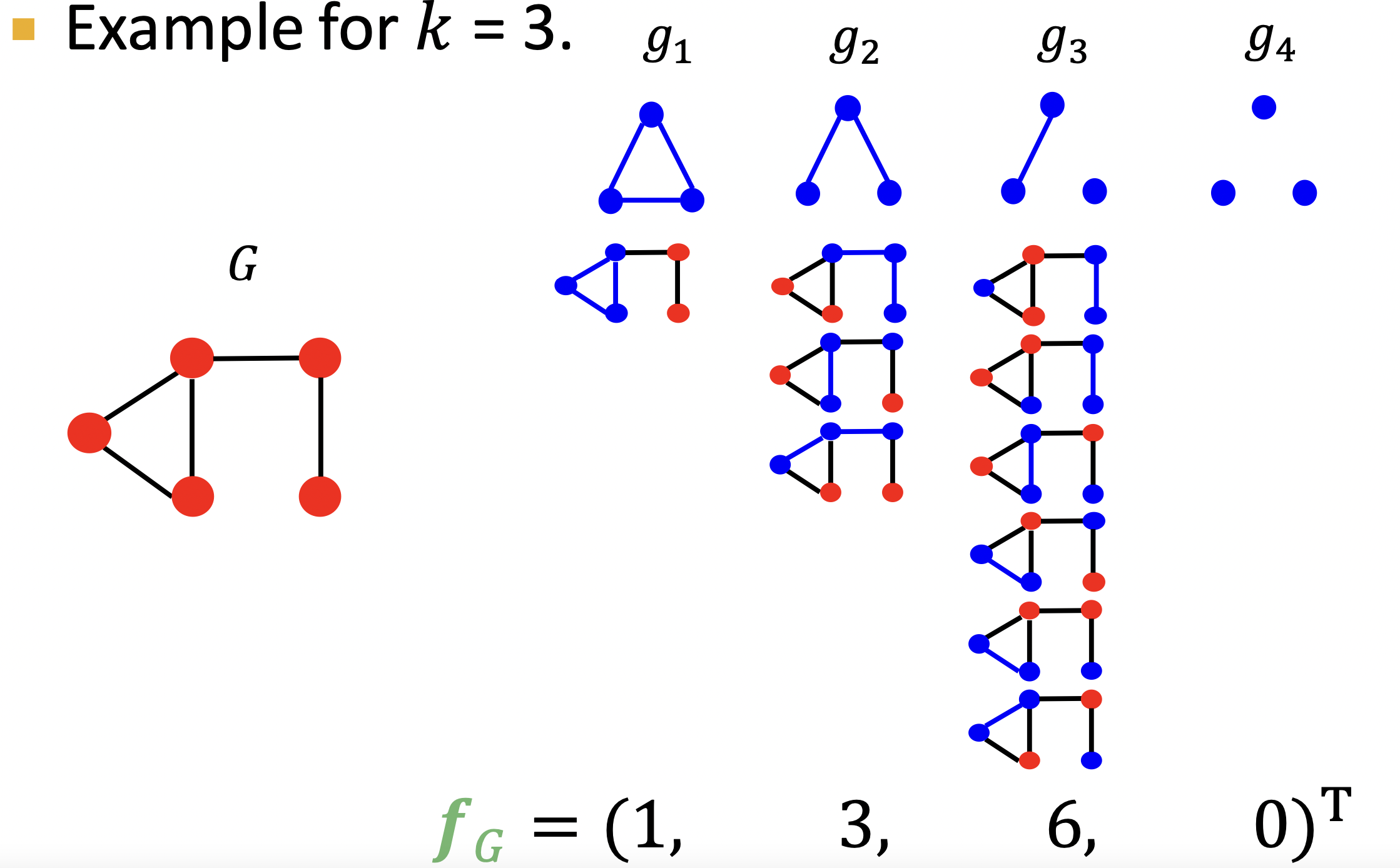
두 그래프 와 의 유사도는 아래와 같이 계산하게 됩니다.
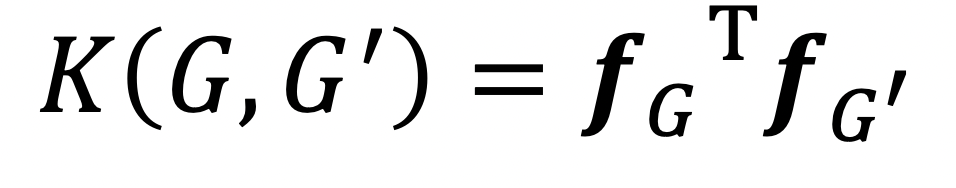
이 때 두 그래프 간에 scale차가 너무 많이 나게 된다면 값이 이상해 질 수 있으므로 아래와 같이 normarlization 해줍니다.
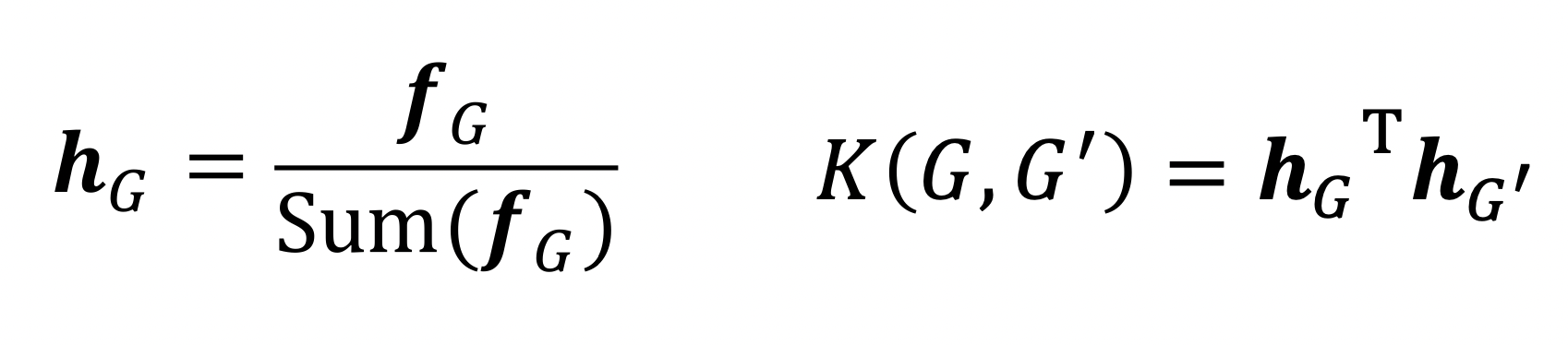
한계
Graplet을 계산하는게 너무 복잡합니다!
4. Weisfeiler-Lehman Kernel
Color refinement 라는 방법으로 좀 더 효율적인 graph feature를 나타내는 방법입니다.
Color refinement
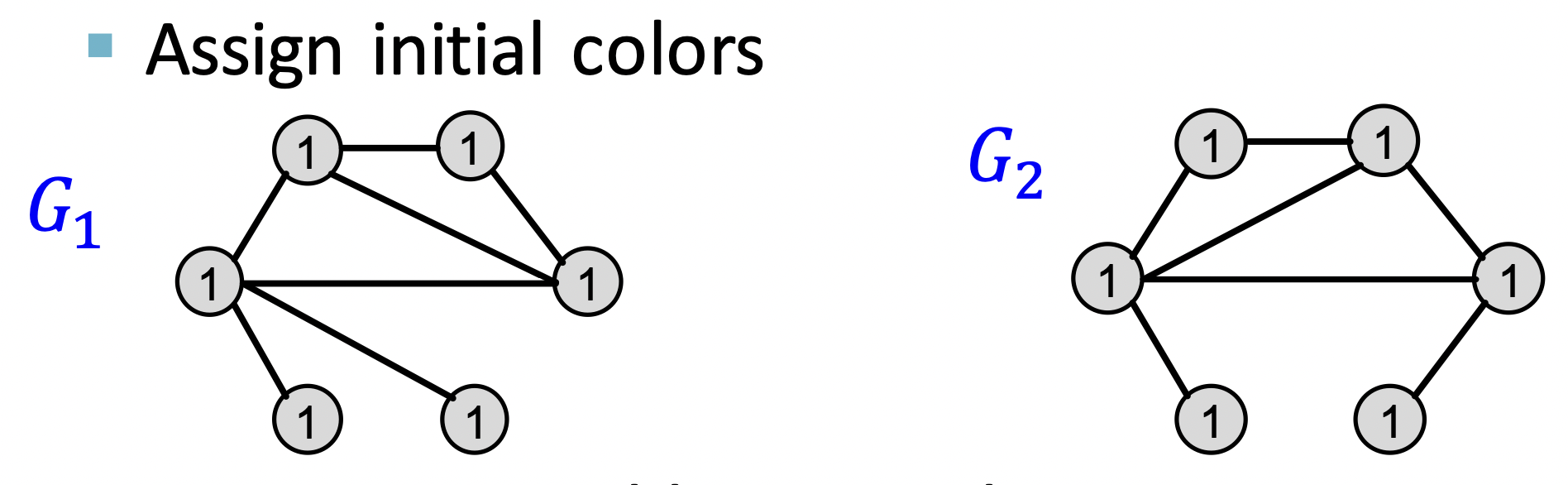
최초로 그래프의 모든 노드에 1이라는 color를 부여해 줍니다.
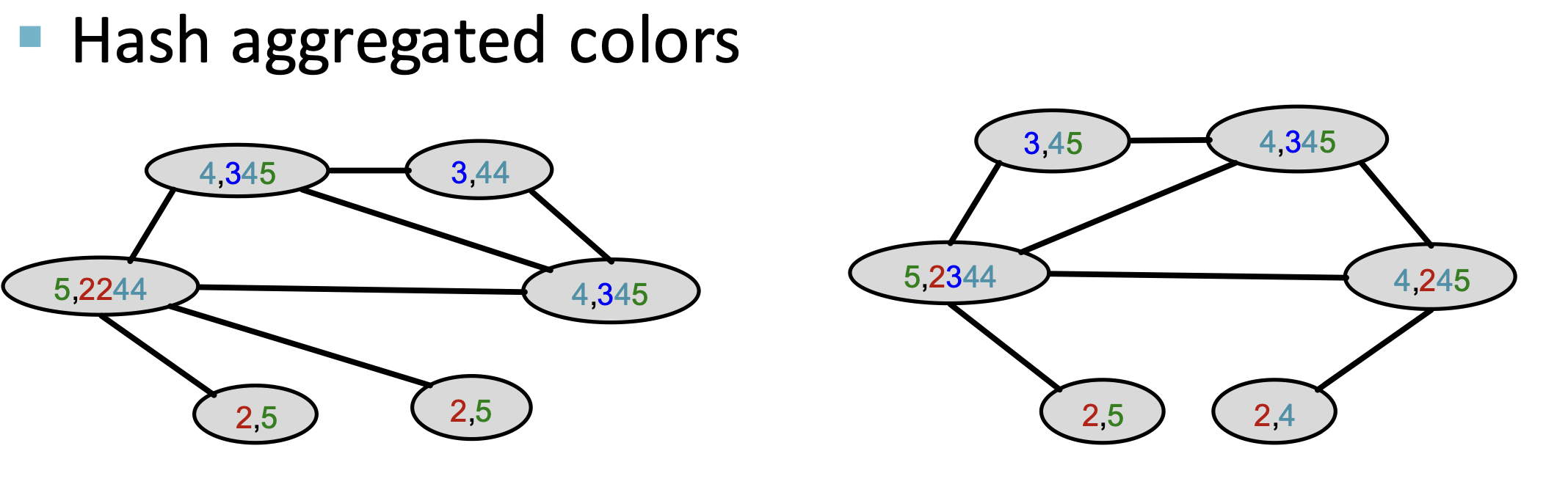
인접 노드에 자신의 color를 전파합니다.
전파된 color를 기반으로 새로운 color를 부여해 줍니다.
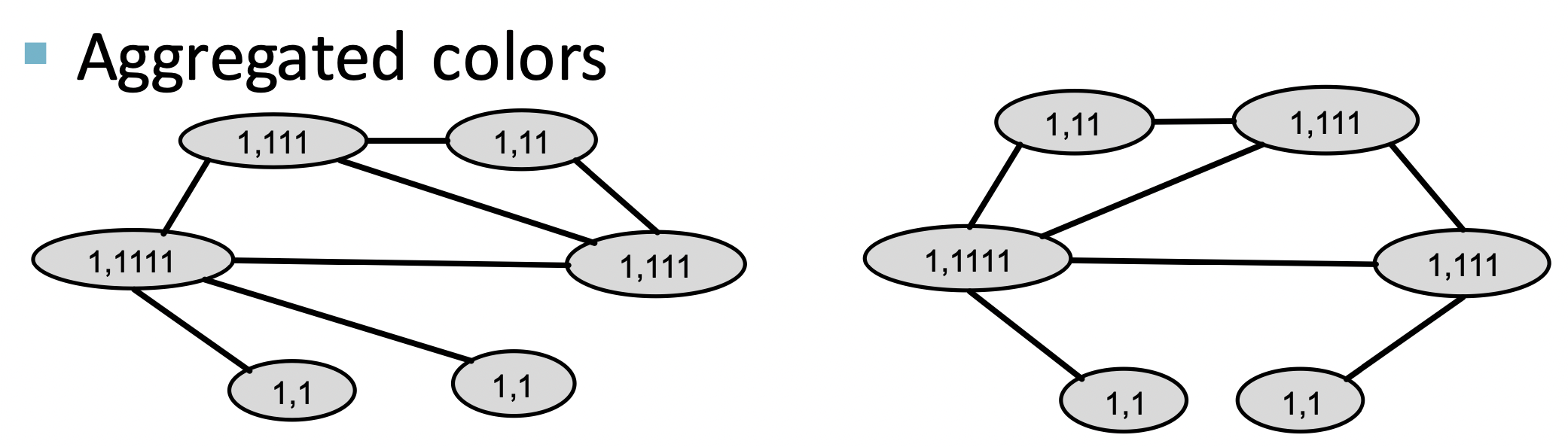
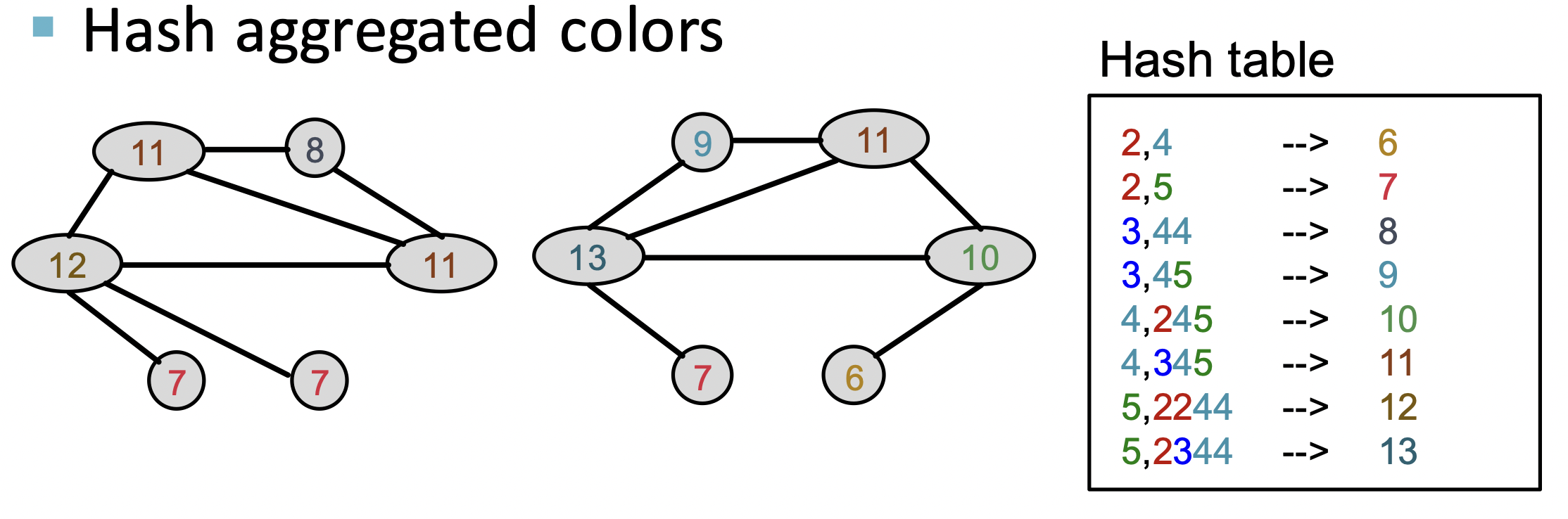
새로운 color를 기반으로 다시 전파합니다.
마찬가지로 다시 새로 전ㅍ된 color를 기반으로 새로운 color를 부여합니다.
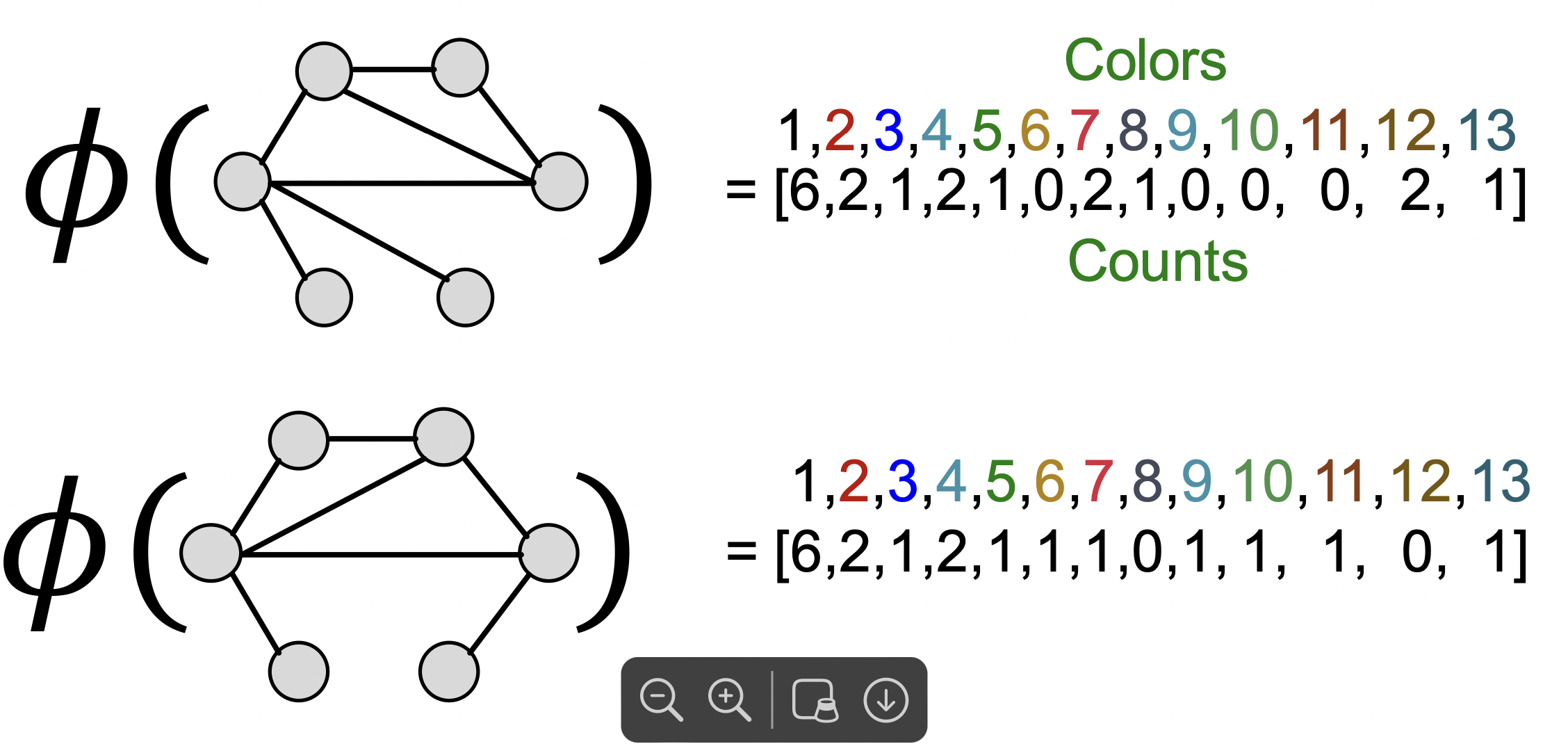
이 color를 Bag-of-Words에 담아 graph features로 표현합니다.
그러므로 kernel은 아래와 같이 계산합니다.
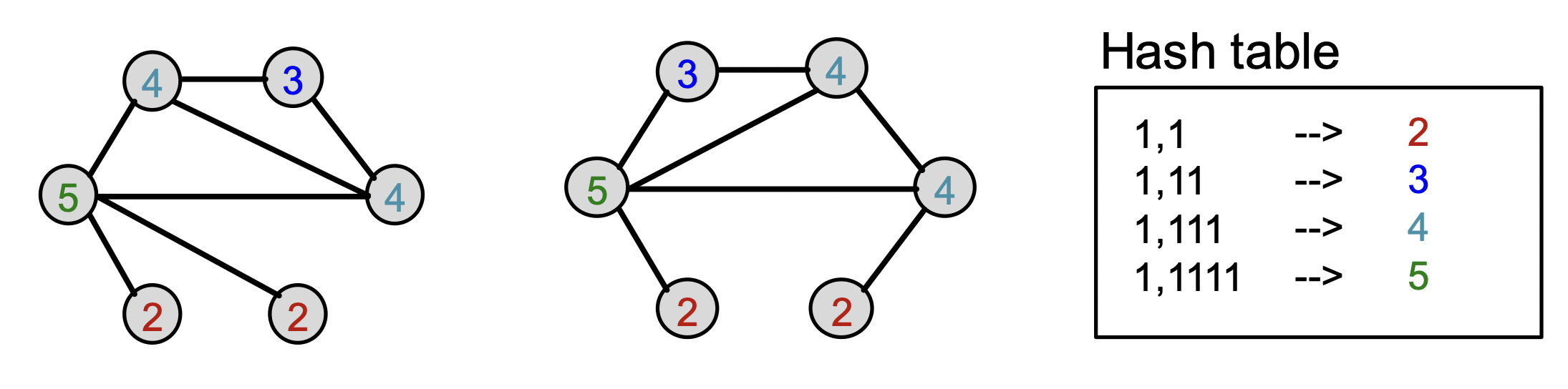
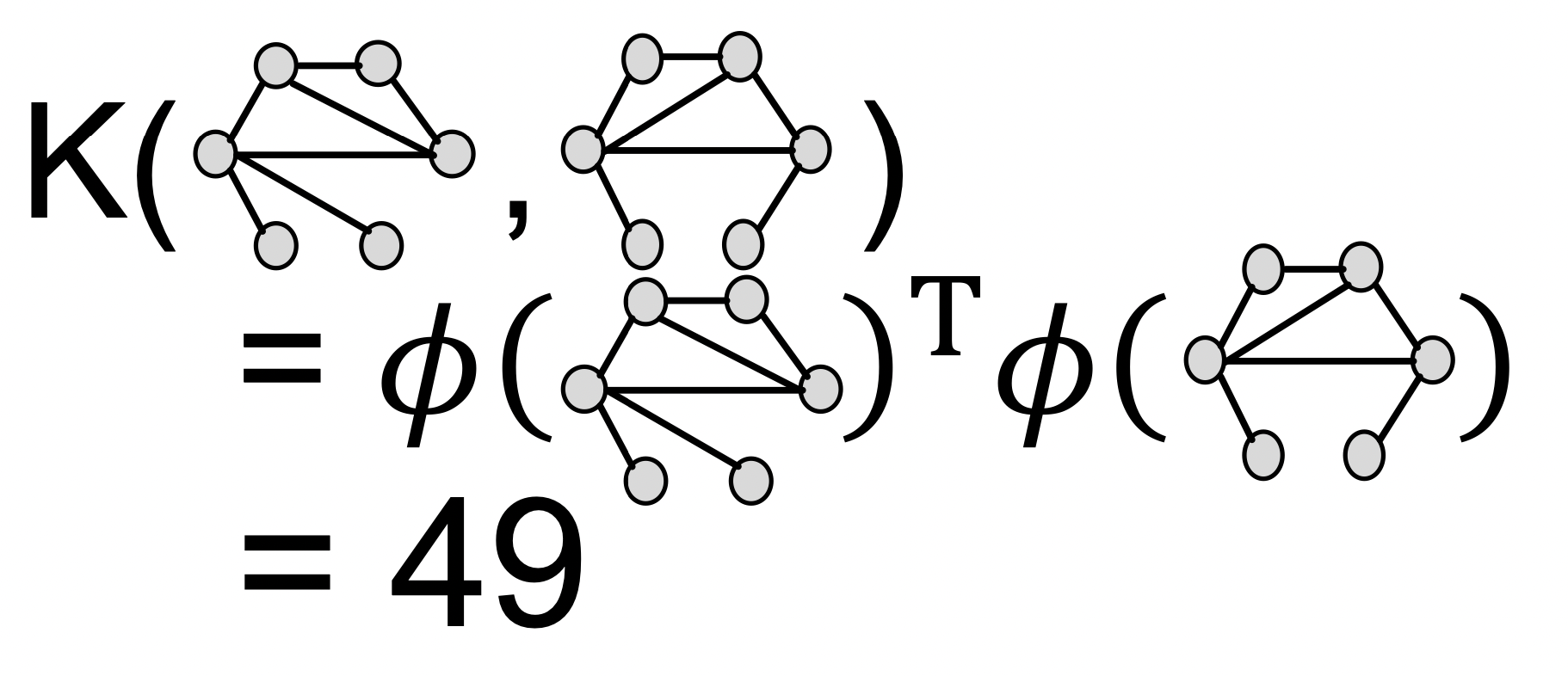
위의 예시는 2번의 refinement step을 거쳣기 때문에 로 표현합니다.
이렇게 계산한 kernel은 graplet kernel에 비교해서 효율적으로 계산 할 수 있으며 time complexcity 또한 edge 갯수에 linear합니다.
