[AFML] Standard Bar Sampling
AFML

Standard Bar Sampling
비정형 데이터에 머신러닝 알고리즘을 적용하기 위해서는 먼저 분석해야 하고(analyzing), 정보를 추출해야 한다(signaling). 이렇게 추출된 자료는 대개 관계형 데이터베이스 형태로 저장되어 있는데, 이 데이터의 행을 바(bar)라고 부른다. bar를 어떻게 샘플링하는가에 따라서 그 종류가 Time Bar, Tick Bar, Volume Bar, Dollar Value Bar로 나뉘는데, 오늘은 그 중 표준 바 샘플링(Standard Bar Sampling)에 대해서 간단히 다뤄보고자 한다
Advances in Financial Machine Learning(이하 AFML)의 저자 Prado 교수는 다음과 같은 이유로 보편적인 Time Bar 형태의 사용을 지양하기를 권장한다.
- 시장은 정보를 일정한 시간 간격으로 처리하지 않는다
- 시간에 따라 추출된 샘플은 종종 좋지 않은 통계적 성질을 보인다
오늘날의 금융 시장은 알고리즘 거래와 스마트폰 애플리케이션 기반의 GUI 거래가 증가하면서 장중 정보의 불균형은 더욱 심화되었다. 개장 직후의 1시간과 장마감 직전 30분의 거래량은 점심시간의 한 시간보다 훨씬 거래가 활발하다. 이는 즉 시장의 정보가 개장 직후와 장마감 직전에 쏠려 있다는 것을 의미한다.
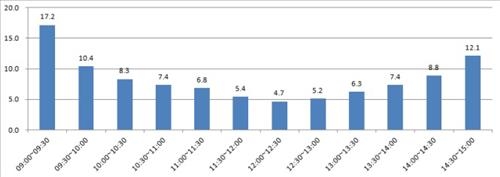
그림 1 : 장중 거래량 비교, 출처 : 연합뉴스
일정한 시간에 따라 추출된 샘플은 이러한 정보를 놓치기 쉬우며, 이러한 이유로 인해 샘플간 계열 상관과 이분산성, 비정규 분포성이 심하게 나타난다고 지적한다.
Time Bar의 대안으로 저자는 다음과 같은 3가지 형태의 샘플링 방법을 추출하는데, 오늘 포스팅에서는 이를 구현하는 방법에 대해서 소개하고자 한다
Tick Bar
Tick Bar의 기본적 아이디어는 매우 간단하다. 1 tick이 한 건의 거래 건수를 의미한다고 가정하면, 거래 건수가 사용자가 지정한 임의의 Threshold를 넘어갈 때 마다 추출하는 것이다. 이렇게 하면 정보의 도착과 표본 추출을 동기화할 수 있다.
만델브로와 테일러는 표본 추출을 거래 건수의 함수로 수행하면 표본이 바람직한 통계적 성질을 가진다는 것을 처음으로 발견한 사람 중 하나다. 이들의 논문 이후, 다수의 연구에서 거래 활동에 관한 함수로 표본 추출하면 IID 정규 분포에 근접한 수익률을 얻을 수 있다는 것이 확인되었다. 대다수의 보편적인 금융 연구에서 사용되는 Time Bar의 경우 높은 첨도와 양의 왜도를 가지는 것에 비해 표본의 정규성이 개선된다는 것은 머신러닝 및 계량적 접근에 있어서 더 좋은 추론이 가능하다는 것을 의미한다.
한 가지 주의해야 하는 점은, 바로 이상치(outlier)의 존재이다. 많은 거래소에서 장 시작과 마감에 대량 장외가 거래를 수행하는데, 이는 그 동안 거래 요청만 쌓이고 실제 거래는 일어나지 않는다는 의미가 된다. 동시 호가 후에 가격이 결정되면 동시에 청산이 되는데, 이 과정에서 대규모 거래가 발생한다. 이는 하나의 Tick으로 기록되지만 정보량만 따지고 보자면 수천개의 틱과 맞먹을 수 있다.
그림 2 : S&P 500 mini future series의 tick bar sampling (threshold = 600) 결과
Volume Bar
Tick Bar의 문제점 중 하나는 주문의 파편성으로 틱 수가 임의적이라는 점이다. 예를 들어, 대기 중인 주문의 크기가 10이라 가정하고, 이 주문이 10의 수요에 의한 하나의 거래로 기록되면 이는 하나의 틱으로 기록될 것이다. 반면에 크기가 1인 주문 10개가 쌓여 있다면 10개의 개별 거래로 기록될 것이다. 이에 더불어 거래 시스템의 프로토콜은 운영 편의성을 위해 하나의 주문 체결을 다수의 partial order로 분리하여 체결할 수 있다(동적 메모리 관리를 함으로써, 원할한 시스템 운영을 위함일 것이다).
volume bar는 이러한 문제를 미리 정의된 단위의 증권 거래량이 초과할 때마다 표본을 추출하여 해결한다. 예를 들어서, 틱의 개수에 상관없이 단지 거래량이 1000단위로 거래될 떄마다 가격 표본 추출을 할 수 있다. Clark는 1973년 논문 'A subordinated stochastic process model with finite variance for speculative prices'에서 거래량에 기반한 샘플링이 틱 바에 의한 샘플링보다 훨씬 더 나은 통계적 성질을 가진다는 것을 밝혔다.
volume based bar가 선호되는 또 다른 이유는 market microstructure분야에서의 몇몇 이론이 가격과 거래량 사이의 상호작용을 연구하기 때문에 유용하다. 데이터의 저장 기술이 진보하고 정보의 민주화와 증권거래의 보편화가 이뤄지면서 수많은 데이터가 쌓이는 최근 금융시장 분석에 있어서 거래량을 기반으로 샘플링을 하는 것은 굉장히 합리적이며 편리한 방법이다.
그림 3 : S&P 500 mini future series의 volume bar sampling (threshold = 10,000) 결과
Dollar Value Bar
Dollar value bar는 사전에 정해 둔 market value가 threshold를 넘을 때마다 샘플링을 하는 것이다. 여기서 dollar value는 거래되는 거래소가 발행한 화폐단위에 따라서 달라지는 것에 주의한다.
달러바를 활용하는 이론적 근거에 대해 알아 보자. 특정 기간 동안 100%의 가격이 상승한 주식을 분석하고자 한다. 해당기간 말에 그 주식을 1000달러 매도하려고 한다면 해당 기간 초에 1000달러 가치였던 주식의 절반만을 매도하면 된다. 즉, 거래된 주식 수는 실제로 시장에서 거래된 가치의 함수이다. 그러므로, tick이나 volume보다는 거래된 달러 가치로 표본을 추출하는 것이 더 합리적이며, 특히 큰 가격 변동을 분석하는 경우에 더욱 그렇다
dollar value bar가 다른 샘플링 방법에 비해서 더 흥미로운 두 번째 논거는 총 발행주식 수가 종종 기업 행위의 결과로 주식이 거래되는 동안 여러번 변경된다는 점이다. 액면 분할이나 병합으로 인해 주식의 총량이 조정되는 경우 tick 혹은 volume 샘플링에 대해 정보의 왜곡이 발생할 수 있다. dollar value를 기준으로 샘플링을 하는 경우 이러한 기업의 재무 활동에 대해 영향이 적은 경향이 있다.
dollar value bar의 또다른 아이디어는 시간에 따라서 threshold를 동적으로 조정함으로써 바를 추출할 수 있다. 이 경우에는 바의 크기를 시장에서 실제 거래되는 주식의 유동 시가 총액이나 발행된 부채 총량의 함수로 동적으로 조절할 수도 있다.
그림 3 : S&P 500 mini future series의 dollar value bar sampling (threshold = 1,000,000) 결과
example
다음은 Standard Bar를 구현하는 python code 예시이다.
def standard_bar_sampling(df, column, threshold, tick = False):
"""
Argument
----------------------------
df : getDataFrame 함수의 output을 입력으로 사용
column : 기준으로 사용할 column을 지정
'price' - time bar 사용
'v' - volume 사용
'dv' - dollar value 사용
tick : tick bar를 사용하고 싶은 경우 True로 변경
Hyperparameter
----------------------------
threshold : threshold를 넘길 때마다 Sampling
output
----------------------------
DataFrame 형태의 Sampling된 Data가 반환됩니다
"""
t = df[column]
ts = 0
idx = []
if tick:
for i, x in enumerate(t):
ts += 1
if ts >= threshold:
idx.append(i)
ts = 0
else:
for i, x in enumerate(t):
ts += x
if ts >= threshold:
idx.append(i)
ts = 0
return df.iloc[idx].drop_duplicates()