❌ Spring 프로젝트와 같은 컨테이너에 Redis 배포
현재 아키텍처에서는 쿠버네티스에 ArgoCD를 통해 Spring 프로젝트와 Redis가 같은 컨테이너 상에 위치하도록 배포하고 있다.
이를 위해서는 배포하는 .yaml 파일에 같은 컨테이너 상에 위치하도록 하여 배포하면 된다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: survey-back
spec:
replicas: 3
selector:
matchLabels:
app: survey-back
template:
metadata:
labels:
app: survey-back
spec:
containers:
- name: survey-back
image: hamgeonwook/survey-back:26
ports:
- containerPort: 8080
name: spring
# Redis를 도커 이미지를 통해 같은 컨테이너상 6379 포트로 실행
- name: redis-container
image: redis:latest
ports:
- containerPort: 6379문제점
위의 survey-back 서비스의 replicas: 3으로 설정되어 있기 때문에, 쿠버네티스는 survey-back 포드를 3개 생성하게 된다. 각 포드 내부에는 survey-back 컨테이너와 redis 컨테이너가 함께 배치되어 있으므로, 실제로 각각의 survey-back 인스턴스는 자신만의 독립된 redis 인스턴스를 사용하게 된다.
-
데이터 일관성 : 한 인스턴스에서 데이터를 업데이트하더라도 다른 인스턴스의
redis에는 반영되지 않아, 애플리케이션의 다른 부분에서는 업데이트된 데이터를 볼 수 없는 상황이 발생할 수 있다. -
리소스 비효율성 : 모든 인스턴스가 자체적인
redis인스턴스를 실행할 경우, 각 인스턴스의 리소스 사용량이 불필요하게 증가한다. -
데이터 복제 및 백업 어려움 : 독립된 여러
redis인스턴스를 관리할 때, 각 인스턴스에 대한 데이터 복제 및 백업을 일관되게 수행하기 어렵다. -
트랜잭션 관리 문제 : 여러
redis인스턴스에 걸친 트랜잭션을 관리하는 것은 매우 복잡하다. -
스케일링 문제 : 애플리케이션의 트래픽이 증가함에 따라, 각 인스턴스의
redis도 동일하게 스케일링되어야 한다. 이는 관리의 복잡성을 증가시키며, 각 인스턴스의 스케일링이 동일하게 이루어지지 않을 경우 성능 병목 현상을 발생할 수 있다.
이러한 배치는 각 인스턴스가 서로의 데이터에 영향을 주지 않도록 하고 싶을 때 개발이나 테스트 환경에서 사용할 수 있다.
그러나, 운용 환경에서는 일반적으로 모든 애플리케이션 인스턴스가 동일한 redis 인스턴스 또는 클러스터에 연결되도록 구성하는 것이 일반적이다.
해결 방안
위의 문제를 해결하기 위해 클러스터 모드를 사용하기로 하였다.
Redis 클러스터는 데이터 분할(sharding)과 고가용성을 제공한다. 여러 마스터와 슬레이브 인스턴스를 클러스터로 구성하여, 데이터를 분산 저장하고, 인스턴스 장애 시 자동 복구 기능을 제공한다. 클러스터 모드는 높은 가용성과 확장성이 요구되는 대규모 프로덕션 환경에 적합하다.
현재 아키텍처
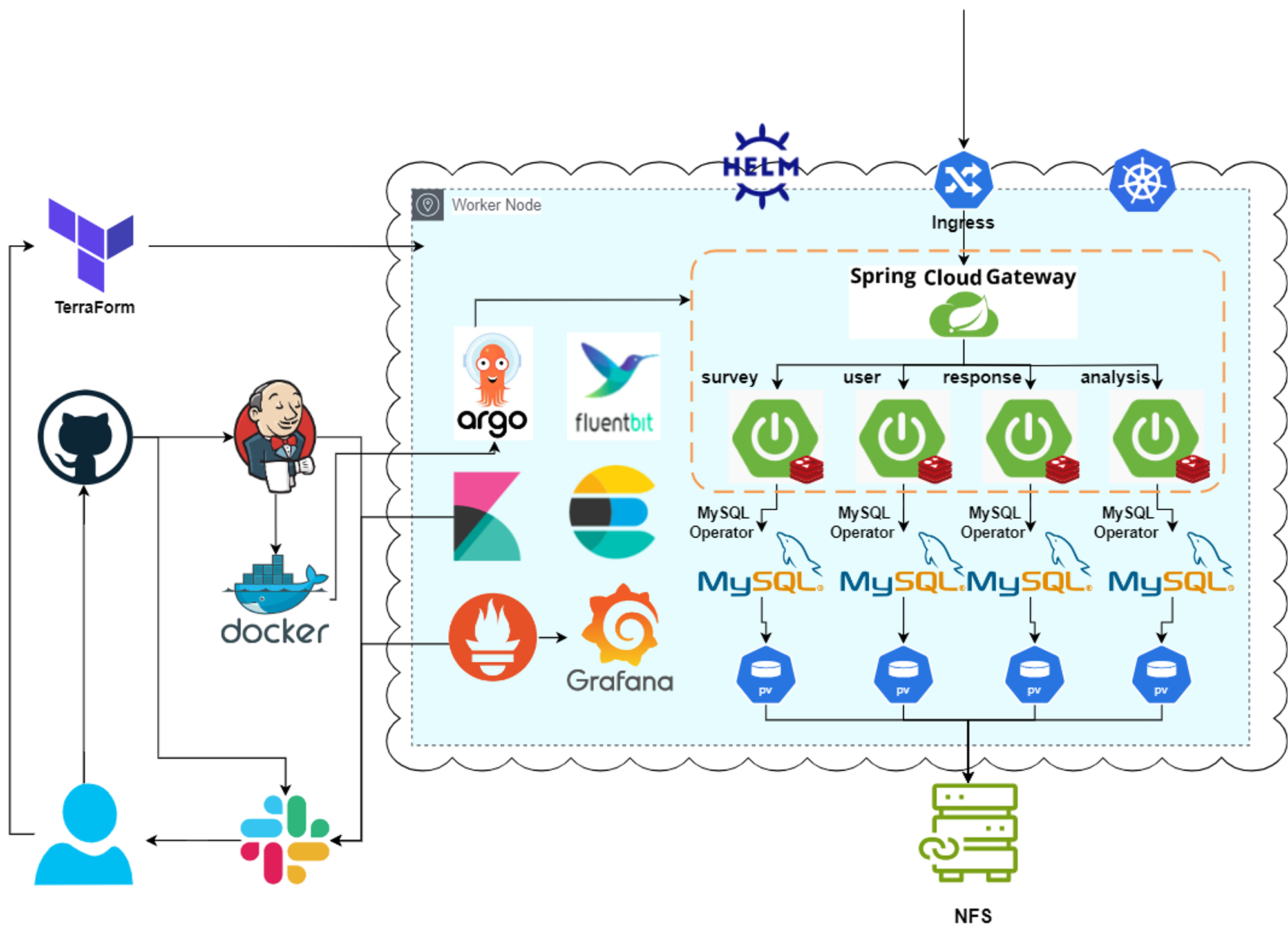
현재 아키텍처를 보면 각 서비스마다 독립된 redis 인스턴스를 사용하고 있다. 위의 redis를 제거하고, redis 클러스터를 배포하여 모든 백엔드 서비스들이 redis 클러스터를 사용하도록 수정할 것이다.
독립된 데이터베이스를 사용하는 서비스들이 같은 Redis 클러스터를 사용해도 되나?
위의 아키텍처 구조를 보면 user 서비스와 survey 서비스는 서로 독립된 데이터베이스를 사용하고 있다. 이에 따라 각 서비스의 데이터를 구분하기 위해 다른 데이터베이스 인덱스를 사용하거나, 키 네이밍 규칙을 통해 구분해야 한다.
키 네이밍 규칙
@GetMapping(value = "/survey-list/{id}")
@Cacheable(value = "survey", key = "'survey-' + #id", cacheManager = "cacheManager")
public ResponseEntity<SurveyDetailDto> readDetail(@PathVariable Long id) {
return new ResponseEntity<>(surveyService.readSurveyDetail(id), HttpStatus.OK);
}위의 코드는 survey 서비스에서 캐시를 사용할 때, 사용하는 코드이다. 위의 코드를 보면 key = "'survey-' + #id" 를 통해 캐시 키를 명시적으로 지정하여 사용한다. 이는 같은 redis 클러스터를 사용할 때 데이터 간섭을 방지하는데 도움을 준다. user 서비스 또한 키를 지정하여 데이터를 독립적으로 관리해야 한다.
Redis 클러스터 사용
helm으로Redis Cluster가져와서 설정
helm fetch bitnami/redis-cluster
tar -zxvf redis-cluster-9.0.5.tgz
vi redis-cluster/values.yaml자기 환경에 맞게 커스텀한다.
Redis Cluster생성
helm install -n test redis-cluster --set password=test /path/redis-clusterRedis Cluster가 사용할pv생성
vi redis-cluster-volume.yaml
kubectl apply -f redis-cluster-volume.yaml- 생성 확인
kubectl get svc -A
kubectl get po -A잘 생성되었는지 확인한다.
서비스에서 Redis 설정 변경
같은 컨테이너에서 사용했던 Redis 가 이제 Redis Cluster로 변경됨에 따라 Redis Cluster를 가리키는 svc로 설정을 변경해줘야 한다.
변경 전 application-server.properties
## Redis
spring.cache.type=redis
spring.cache.redis.time-to-live=3600
spring.cache.redis.host=localhost
spring.cache.redis.port=6379변경 전의 application-server.properties 를 보면 같은 컨테이너 내에 redis가 있었기 때문에 host 주소가 localhost 이었다.
변경 후 application-server.properties
## Redis
spring.cache.type=redis
spring.cache.redis.time-to-live=3600
spring.cache.redis.host=redis-cluster
spring.cache.redis.port=6379이제 쿠버네티스의 svc를 통해 Redis Cluster를 찾아야 하므로 host 주소가 redis-cluster 로 변경되었다.
최종 아키텍처
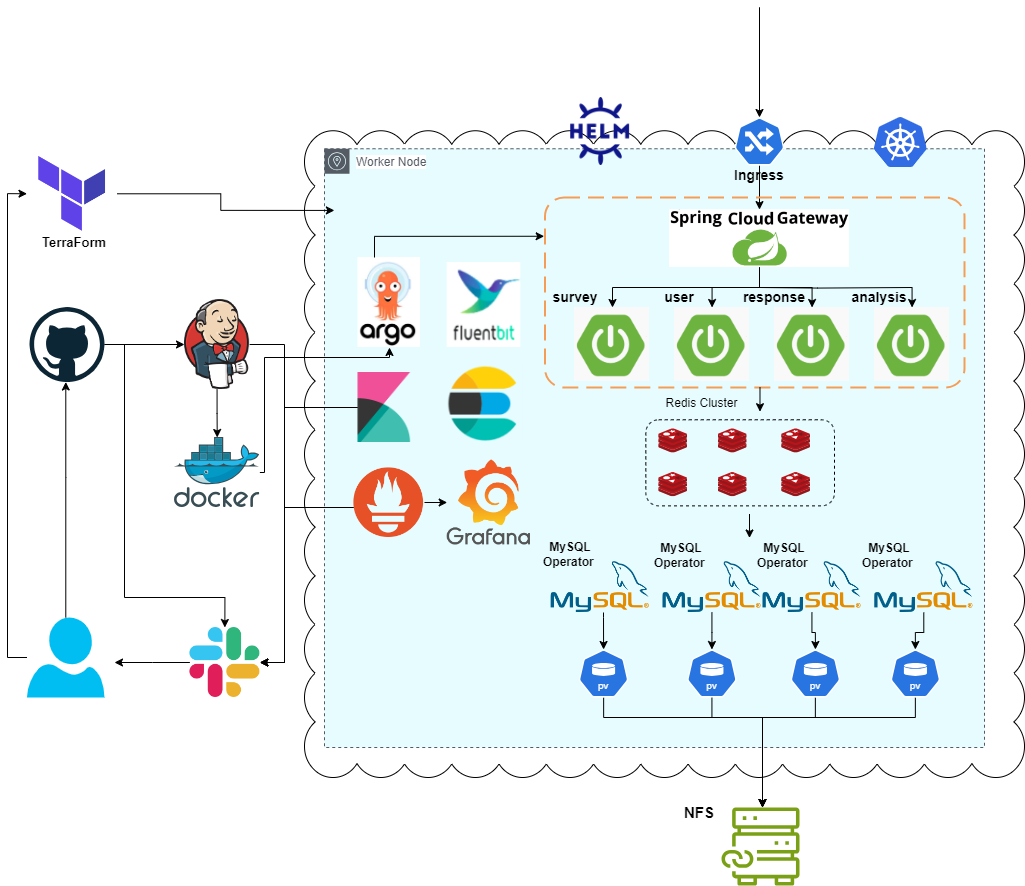
인메모리 DB 이점은 어디간거야?
위의 설명대로 Redis 를 별도의 Pod 로 배포하는 경우, 인메모리 데이터베이스의 성능 이점을 어떻게 유지할 수 있는지에 대한 의문이 생겼다. 이에 대한 답변이다.
-
네트워크 지연 최소화 : 쿠버네티스 클러스터 내에서
Pod간의 네트워크 통신은 매우 빠르다. 같은 노드 내에서 통신하는 경우, 네트워크 지연은 매우 낮아 인메모리 데이터베이스의 성능 이점을 크게 해치지 않는다. -
Redis클러스터 구성 :Redis를 클러스터로 구성하여 여러 노드에 분산시킬 수 있다. 이를 통해 데이터 접근의 병목 현상을 줄이고, 높은 가용성과 성능을 유지할 수 있다.
결론
Redis 를 별도의 Pod 로 배포하더라도 쿠버네티스 클러스터 내에서 네트워크 지연이 낮기 때문에 인메모리 데이터베이스의 성능 이점을 상당 부분 유지할 수 있다. 또한, Redis 클러스터 구성을 통해 성능 최적화와 데이터 일관성을 동시에 달성할 수 있다. 따라서, Redis 를 별도의 Pod 로 배포하는 것이 MSA 환경에서 더 효율적이고 관리하기 쉬운 방법이다.
