아키텍처
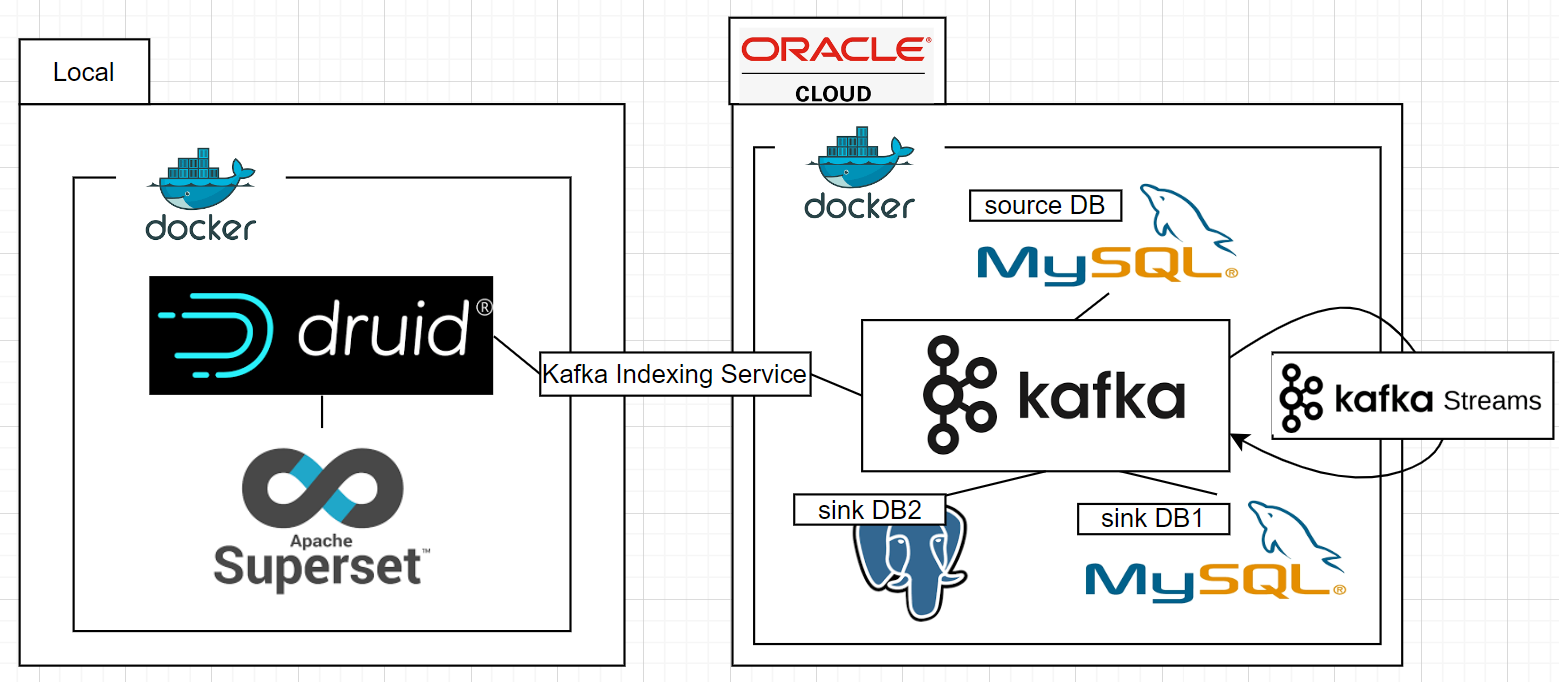
로컬 위에 도커를 설치하고 그 위에 드루이드와 슈퍼셋 설치
Oracle Cloud 위에 도커를 설치하고 kafka와 source DB로 Mysql과 sink DB1으로 Mysql을 sink DB2로 postgres를 설치
로컬 설정 (druid & superset)
도커 설치 (생략)
Druid 설치
- docker-compose.yml
volumes:
metadata_data: {}
middle_var: {}
historical_var: {}
broker_var: {}
coordinator_var: {}
router_var: {}
druid_shared: {}
version: "2.2"
services:
zookeeper:
container_name: zookeeper
image: zookeeper:3.5
ports:
- "2181:2181"
environment:
- ZOO_MY_ID=1
postgres:
image: postgres:latest
container_name: postgres
environment:
- POSTGRES_USER=druid
- POSTGRES_PASSWORD=FoolishPassword
- POSTGRES_DB=druid
volumes:
- metadata_data:/var/lib/postgresql/data
coordinator:
image: apache/druid:25.0.0
container_name: coordinator
volumes:
- druid_shared:/opt/shared
- coordinator_var:/opt/druid/var
depends_on:
- zookeeper
- postgres
ports:
- "8081:8081"
command:
- coordinator
env_file:
- environment
broker:
image: apache/druid:25.0.0
container_name: broker
volumes:
- broker_var:/opt/druid/var
depends_on:
- zookeeper
- postgres
- coordinator
ports:
- "8082:8082"
command:
- broker
env_file:
- environment
historical:
image: apache/druid:25.0.0
container_name: historical
volumes:
- druid_shared:/opt/shared
- historical_var:/opt/druid/var
depends_on:
- zookeeper
- postgres
- coordinator
ports:
- "8083:8083"
command:
- historical
env_file:
- environment
middlemanager:
image: apache/druid:25.0.0
container_name: middlemanager
volumes:
- druid_shared:/opt/shared
- middle_var:/opt/druid/var
depends_on:
- zookeeper
- postgres
- coordinator
ports:
- "8091:8091"
- "8100-8105:8100-8105"
command:
- middleManager
env_file:
- environment
router:
image: apache/druid:25.0.0
container_name: router
volumes:
- router_var:/opt/druid/var
depends_on:
- zookeeper
- postgres
- coordinator
ports:
- "8888:8888"
command:
- router
env_file:
- environment- environment
# Java tuning
DRUID_XMX=1g
DRUID_XMS=1g
DRUID_MAXNEWSIZE=250m
DRUID_NEWSIZE=250m
DRUID_MAXDIRECTMEMORYSIZE=6172m
druid_emitter_logging_logLevel=debug
druid_extensions_loadList=["druid-kafka-indexing-service", "druid-histogram", "druid-datasketches", "druid-lookups-cached-global", "postgresql-metadata-storage", "druid-multi-stage-query"]
druid_zk_service_host=zookeeper
druid_metadata_storage_host=
druid_metadata_storage_type=postgresql
druid_metadata_storage_connector_connectURI=jdbc:postgresql://postgres:5432/druid
druid_metadata_storage_connector_user=druid
druid_metadata_storage_connector_password=FoolishPassword
druid_coordinator_balancer_strategy=cachingCost
druid_indexer_runner_javaOptsArray=["-server", "-Xmx1g", "-Xms1g", "-XX:MaxDirectMemorySize=3g", "-Duser.timezone=UTC", "-Dfile.encoding=UTF-8", "-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager"]
druid_indexer_fork_property_druid_processing_buffer_sizeBytes=256MiB
druid_storage_type=local
druid_storage_storageDirectory=/opt/shared/segments
druid_indexer_logs_type=file
druid_indexer_logs_directory=/opt/shared/indexing-logs
druid_processing_numThreads=2
druid_processing_numMergeBuffers=2
DRUID_LOG4J=<?xml version="1.0" encoding="UTF-8" ?><Configuration status="WARN"><Appenders><Console name="Console" target="SYSTEM_OUT"><PatternLayout pattern="%d{ISO8601} %p [%t] %c - %m%n"/></Console></Appenders><Loggers><Root level="info"><AppenderRef ref="Console"/></Root><Logger name="org.apache.druid.jetty.RequestLog" additivity="false" level="DEBUG"><AppenderRef ref="Console"/></Logger></Loggers></Configuration>druid_extensions_loadList에"druid-kafka-indexing-service"를 추가해서 나중에 OCI의 카프카에 연결하기 위한 드루이드 카프카 인덱싱 서비스를 활성화 해준다.- localhost:8888 접속
Superset 설치
docker pull apache/superset
docker run -d -p 8080:8088 -e
"SUPERSET_SECRET_KEY=your_secret_key_here" --name
superset apache/superset
docker exec -it superset superset fab create-admin \
--username admin \
--firstname Superset \
--lastname Admin \
--email admin@superset.com \
--password admin
docker exec -it superset superset db upgrade
docker exec -it superset superset init- localhost:8080 접속 admin/admin
Druid - Superset 연동
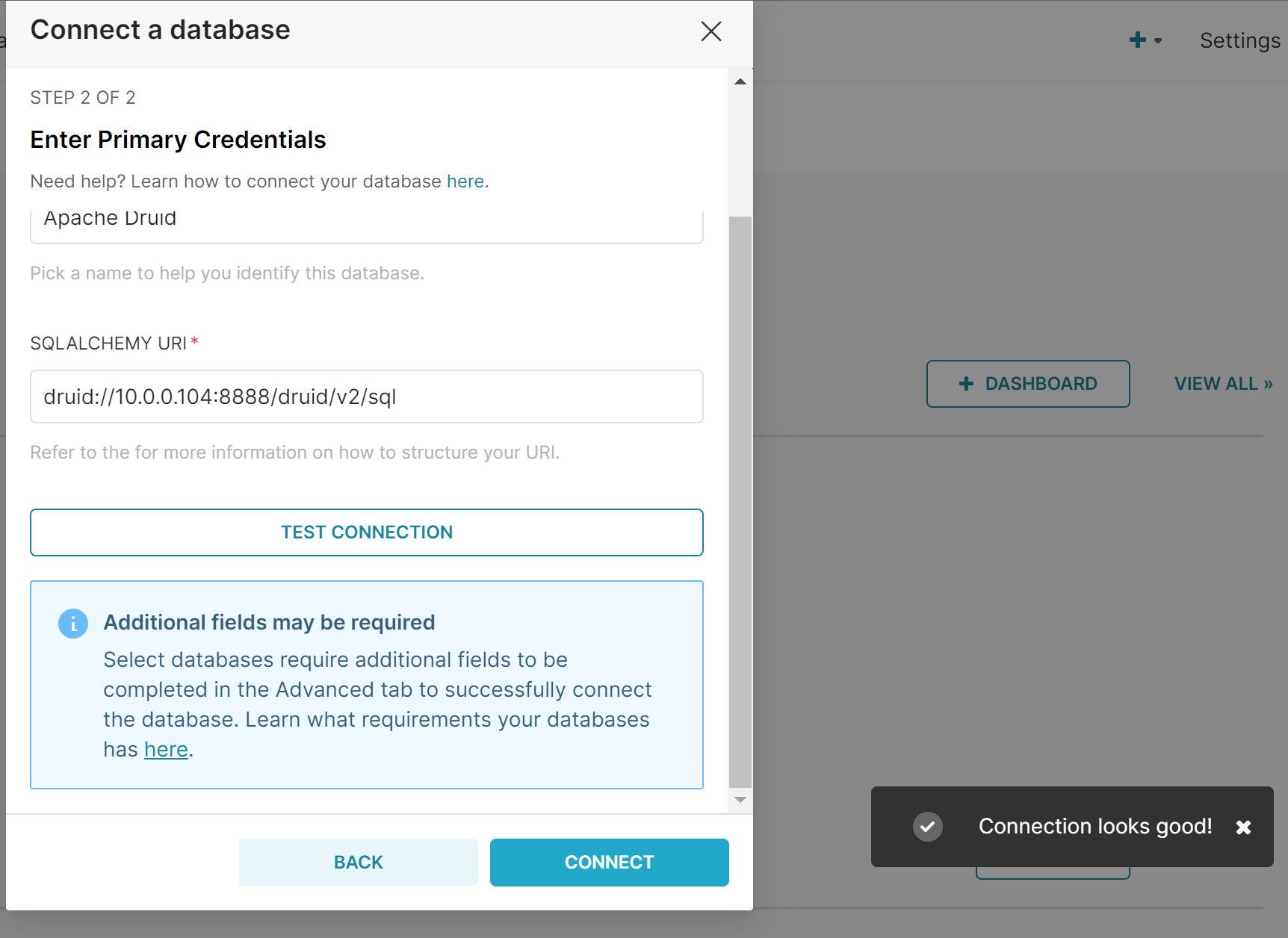
- URL: druid://druid host ip:8888/druid/v2/sql
Oracle Cloud 설정 (Kafka & DB)
도커 컴포즈
version: '3'
services:
mysql:
image: mysql:8.0
container_name: mysql
ports:
- 3308:3306
environment:
MYSQL_ROOT_PASSWORD: admin
MYSQL_USER: mysqluser
MYSQL_PASSWORD: mysqlpw
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
zookeeper:
container_name: zookeeper
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
container_name: kafka
image: wurstmeister/kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 132.226.231.51
KAFKA_ADVERTISED_PORT: 9092
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
mysql-sink:
image: mysql:8.0
container_name: mysql-sink
ports:
- 3307:3306
environment:
MYSQL_ROOT_PASSWORD: admin
MYSQL_USER: mysqluser
MYSQL_PASSWORD: mysqlpw
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
postgresql:
image: quay.io/debezium/postgres:9.6
container_name: postgres-sink
ports:
- "5432:5432"
environment:
- POSTGRES_USER=postgresuser
- POSTGRES_PASSWORD=postgrespw
volumes:
- C:/postgres/data:/var/lib/postgresKAFKA_ADVERTISED_HOST_NAME: 132.226.231.51(oracle cloud pulic ip)을 설정해줘서 나중에 로컬에 설치된 드루이드가 OCI에 설치된 Kafka 클러스터에 접근할 때 카프카가 수신할 ip를 지정해준다.
MySQL 설정(생략)
Kafka 설정
server.properties 수정
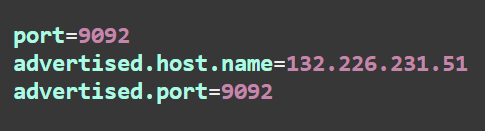
커넥터 설정 및 생성
source-custom-connector
curl --location --request POST 'http://localhost:8083/connectors' \
--header 'Content-Type: application/json' \
--data '{
"name": "source-custom-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "root",
"database.password": "admin",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"database.allowPublicKeyRetrieval": "true",
"database.include.list": "sourcedb",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "dbhistory.sourcedb",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "true",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "true",
"transforms": "unwrap,addTopicPrefix",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"transforms.unwrap.delete.handling.mode":"rewrite" ,
"transforms.addTopicPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.addTopicPrefix.regex":"(.*)",
"transforms.addTopicPrefix.replacement":"$1",
"include.schema.changes": "true"
}
}'sink-custom-connector1
curl --location --request POST 'http://localhost:8083/connectors' \
--header 'Content-Type: application/json' \
--data '{
"name": "sink-custom-connector1",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"connection.url": "jdbc:mysql://mysql-sink:3307/custom_sinkdb?user=mysqluser&password=mysqlpw",
"auto.create": "false",
"auto.evolve": "true",
"delete.enabled": "true",
"insert.mode": "upsert",
"pk.mode": "record_key",
"table.name.format":"${topic}",
"tombstones.on.delete": "true",
"connection.user": "mysqluser",
"connection.password": "mysqlpw",
"topics.regex": "dbserver1.sourcedb.(.*)",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "true",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "true",
"transforms": "unwrap, route, TimestampConverter",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"transforms.unwrap.delete.handling.mode":"rewrite" ,
"transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.route.regex": "([^.]+)\\.([^.]+)\\.([^.]+)",
"transforms.route.replacement": "$3",
"transforms.TimestampConverter.type": "org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.TimestampConverter.format": "yyyy-MM-dd HH:mm:ss",
"transforms.TimestampConverter.target.type": "Timestamp",
"transforms.TimestampConverter.field": "update_date",
"include.schema.changes": "true"
}
}'sink-custom-connector2
curl --location --request POST 'http://localhost:8083/connectors' \
--header 'Content-Type: application/json' \
--data '{
"name": "sink-custom-connector2",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"connection.url": "jdbc:postgresql://postgres-sink:5432/custom_sinkdb?user=postgresuser&password=postgrespw",
"auto.create": "false",
"auto.evolve": "true",
"delete.enabled": "true",
"insert.mode": "upsert",
"pk.mode": "record_key",
"table.name.format":"${topic}",
"tombstones.on.delete": "true",
"connection.user": "postgresuser",
"connection.password": "postgrespw",
"topics.regex": "dbserver1.sourcedb.(.*)",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "true",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "true",
"transforms": "unwrap, route, TimestampConverter",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"transforms.unwrap.delete.handling.mode":"rewrite" ,
"transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.route.regex": "([^.]+)\\.([^.]+)\\.([^.]+)",
"transforms.route.replacement": "$3",
"transforms.TimestampConverter.type": "org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.TimestampConverter.format": "yyyy-MM-dd HH:mm:ss",
"transforms.TimestampConverter.target.type": "Timestamp",
"transforms.TimestampConverter.field": "update_date",
"include.schema.changes": "true"
}
}'로컬 드루이드에서 클라우드 카프카에 연결
- 드루이드 Load data에서 Apache Kafka 선택
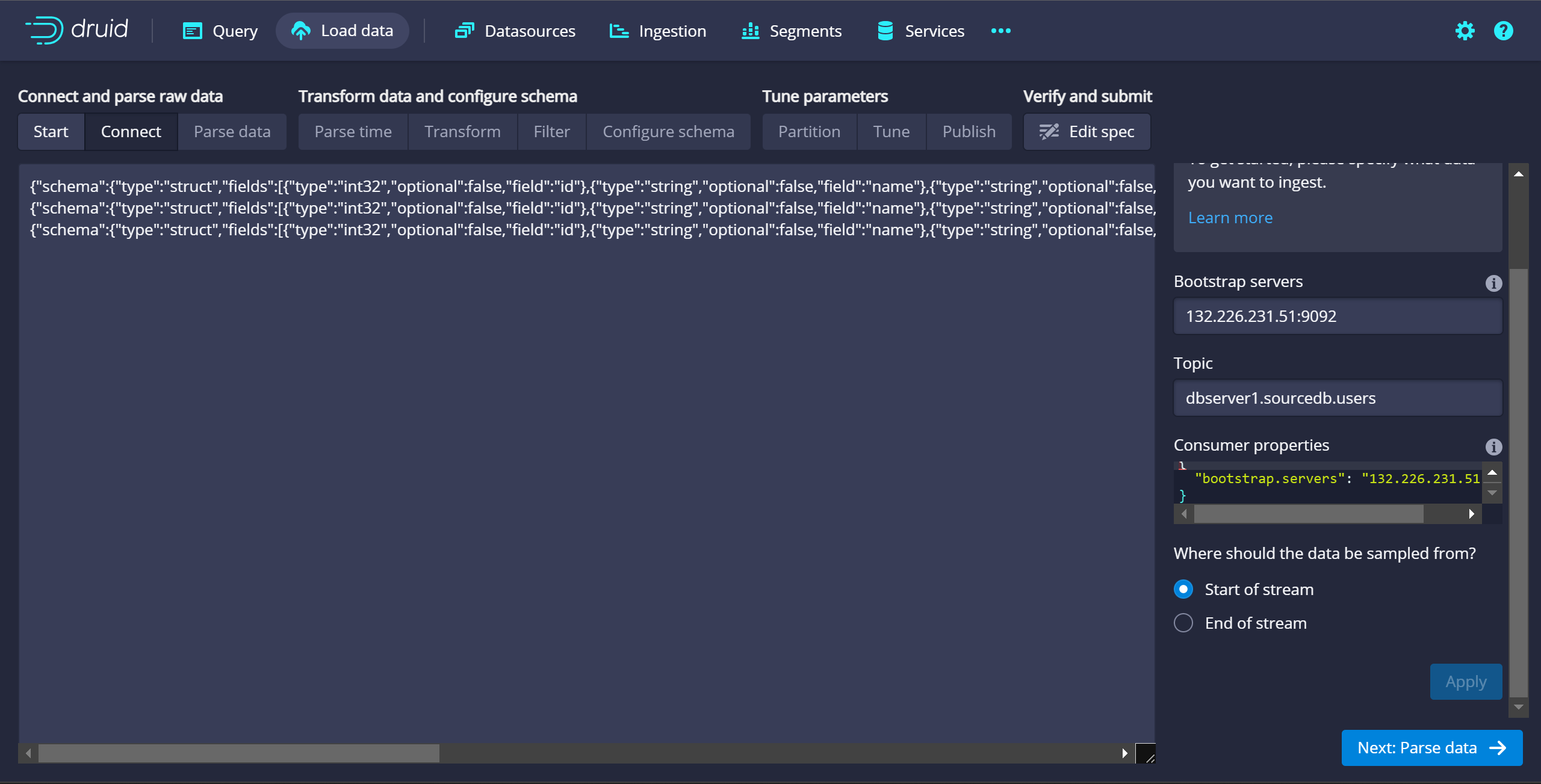
- Bootstrap server에 OCI의 ip 와 카프카 포트 입력
- 토픽 이름 입력
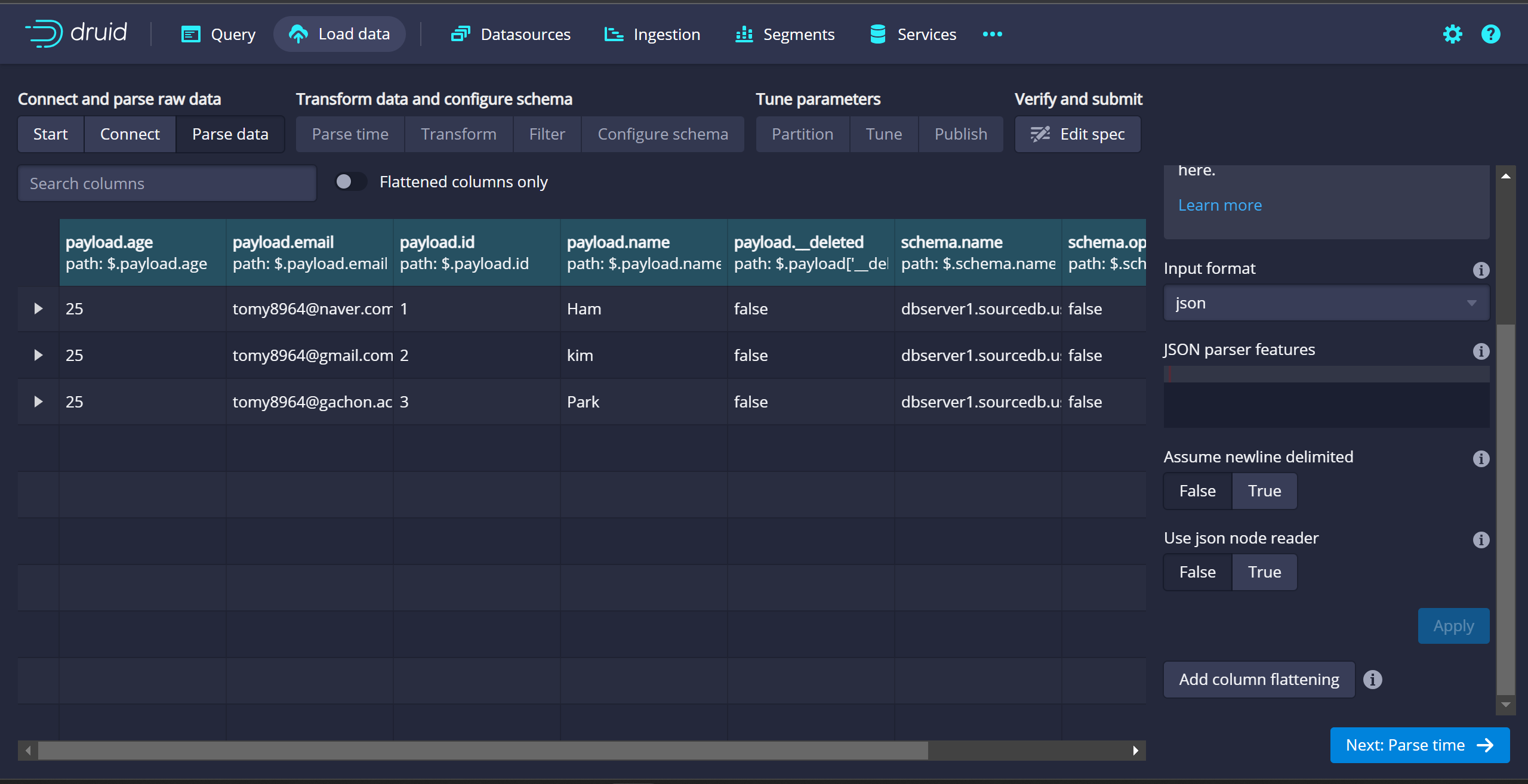
- Parse data
- Parse time
- Tranform
- filter
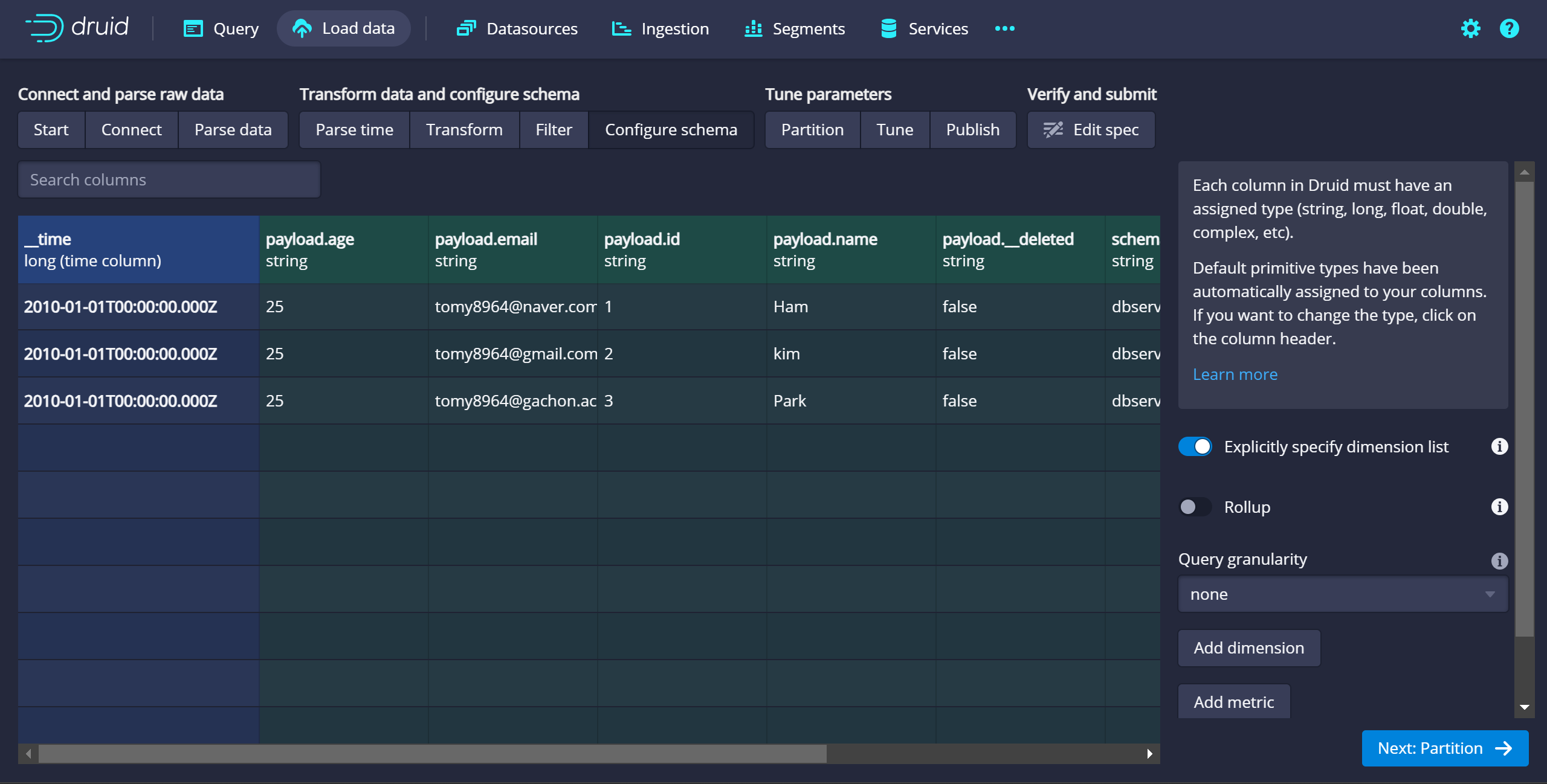
- Configure schema
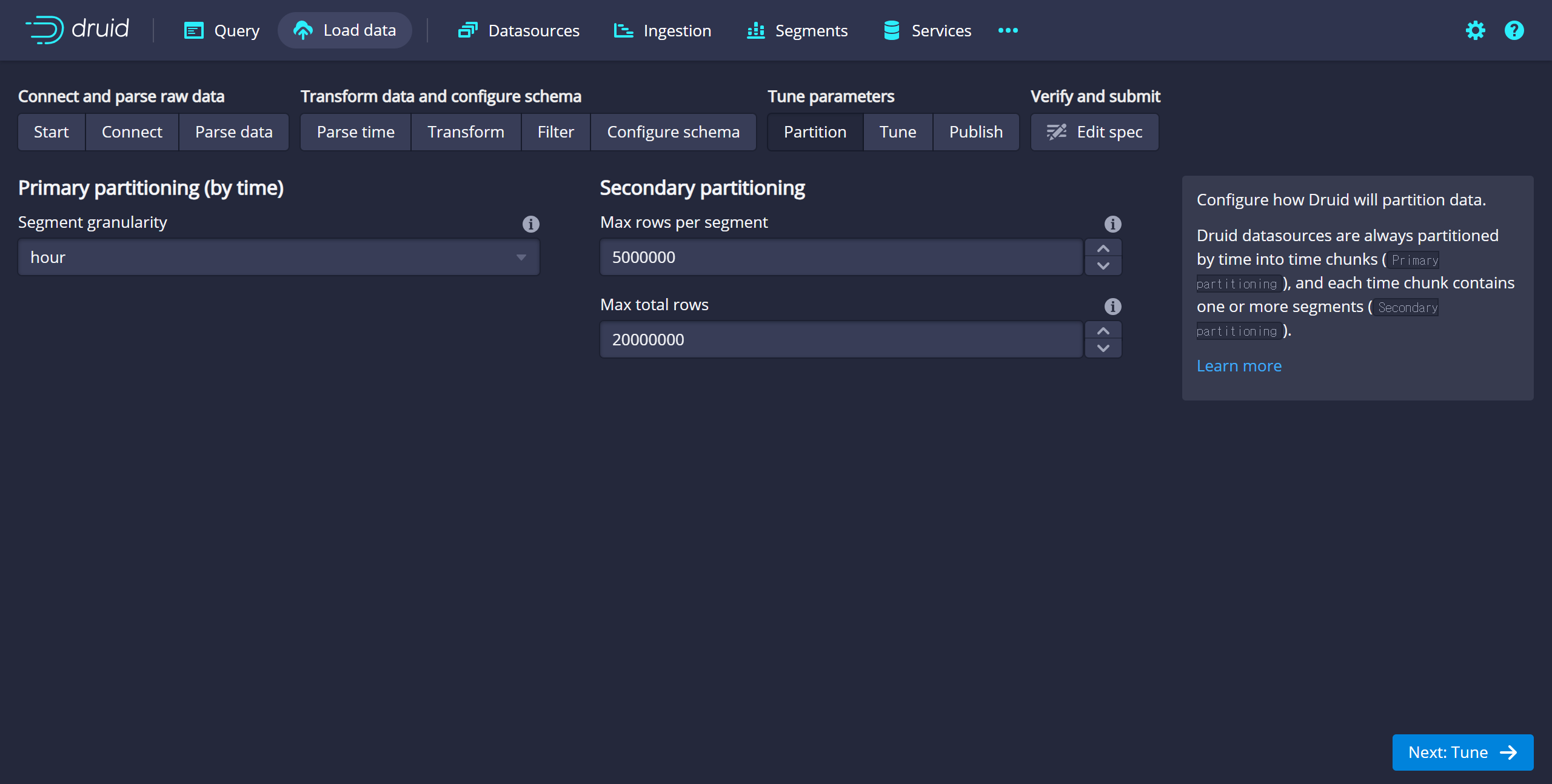
- Partition - Segment granularity: hour
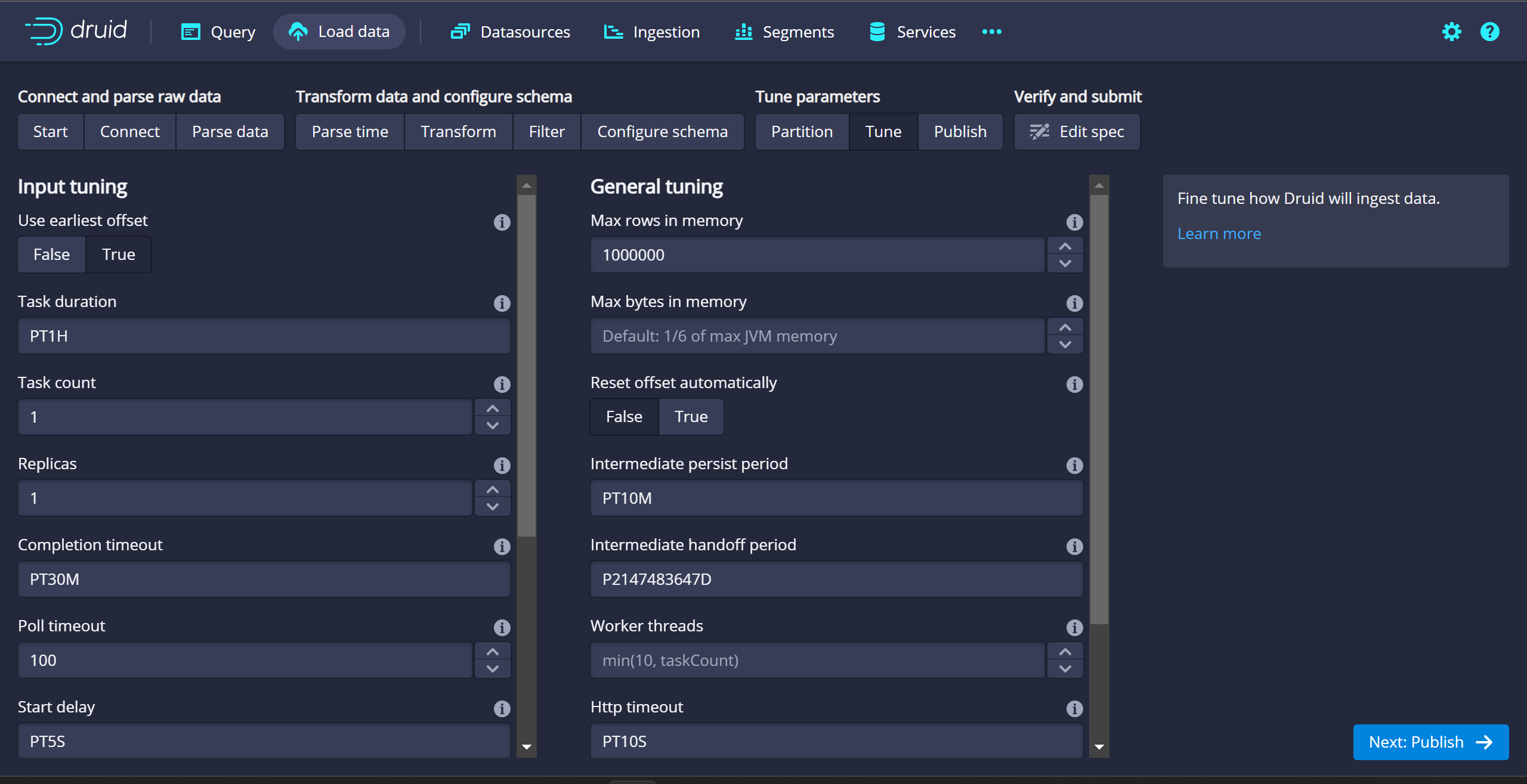
- Tune - Use earliest offset: True
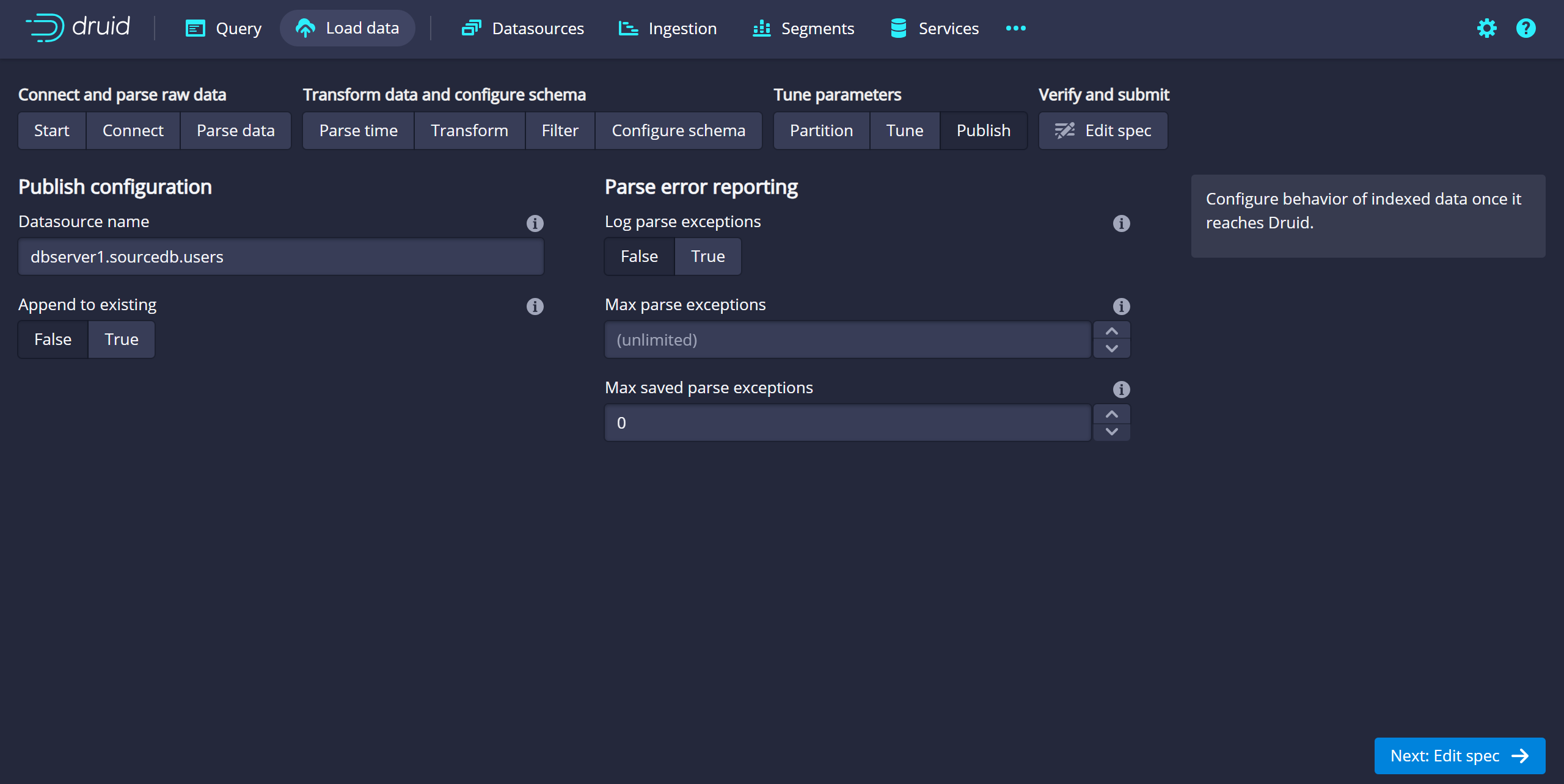
- publish
Spec 생성 완료
Druid Supervisors & Task 생성 확인
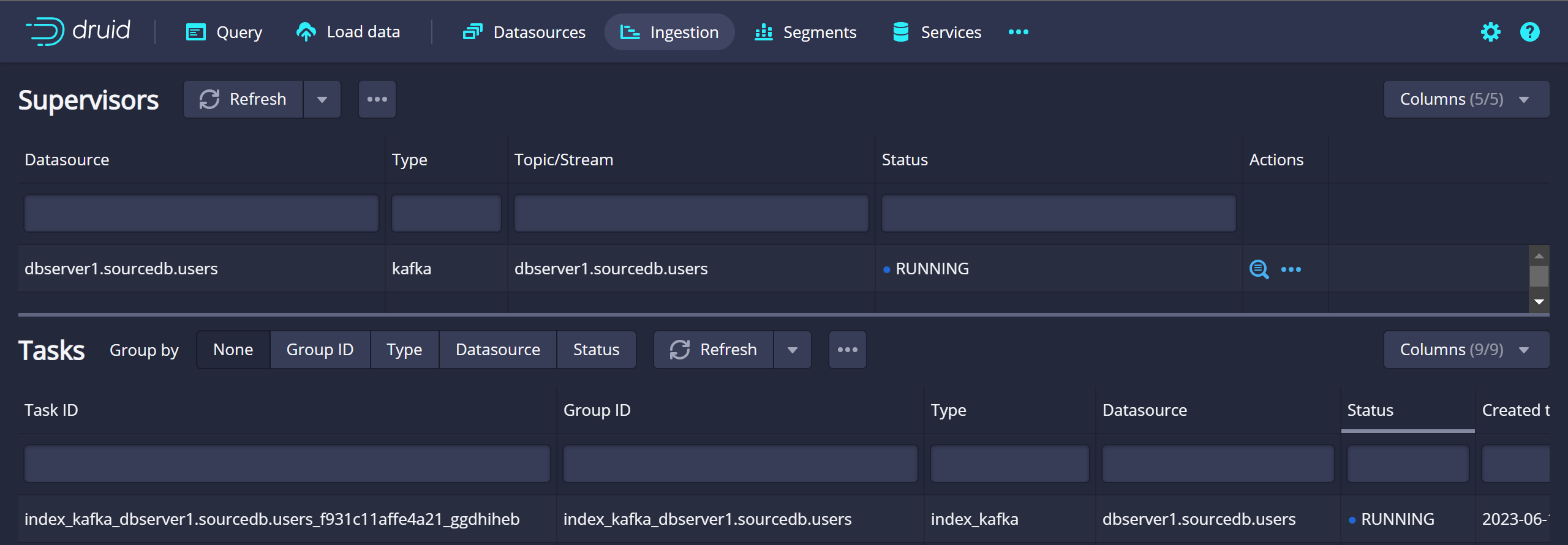
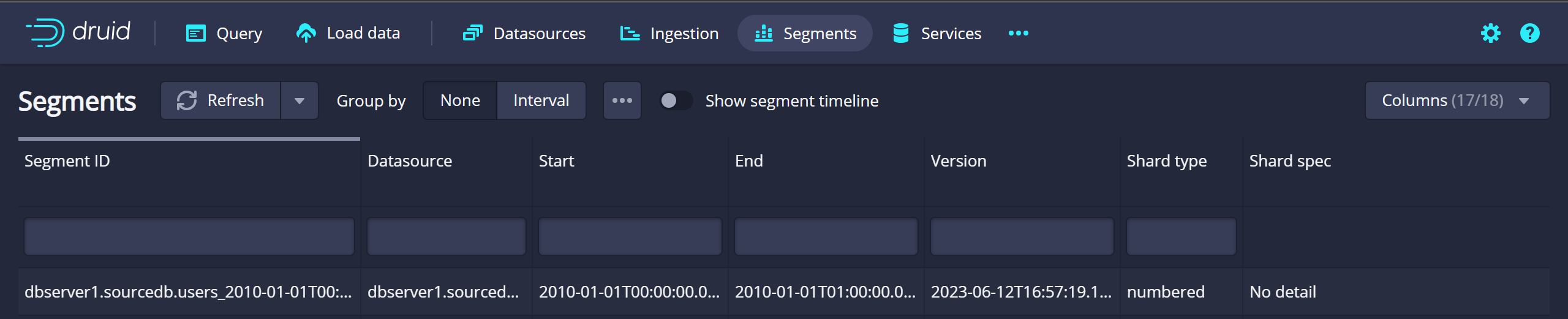
Druid Segment 생성 확인
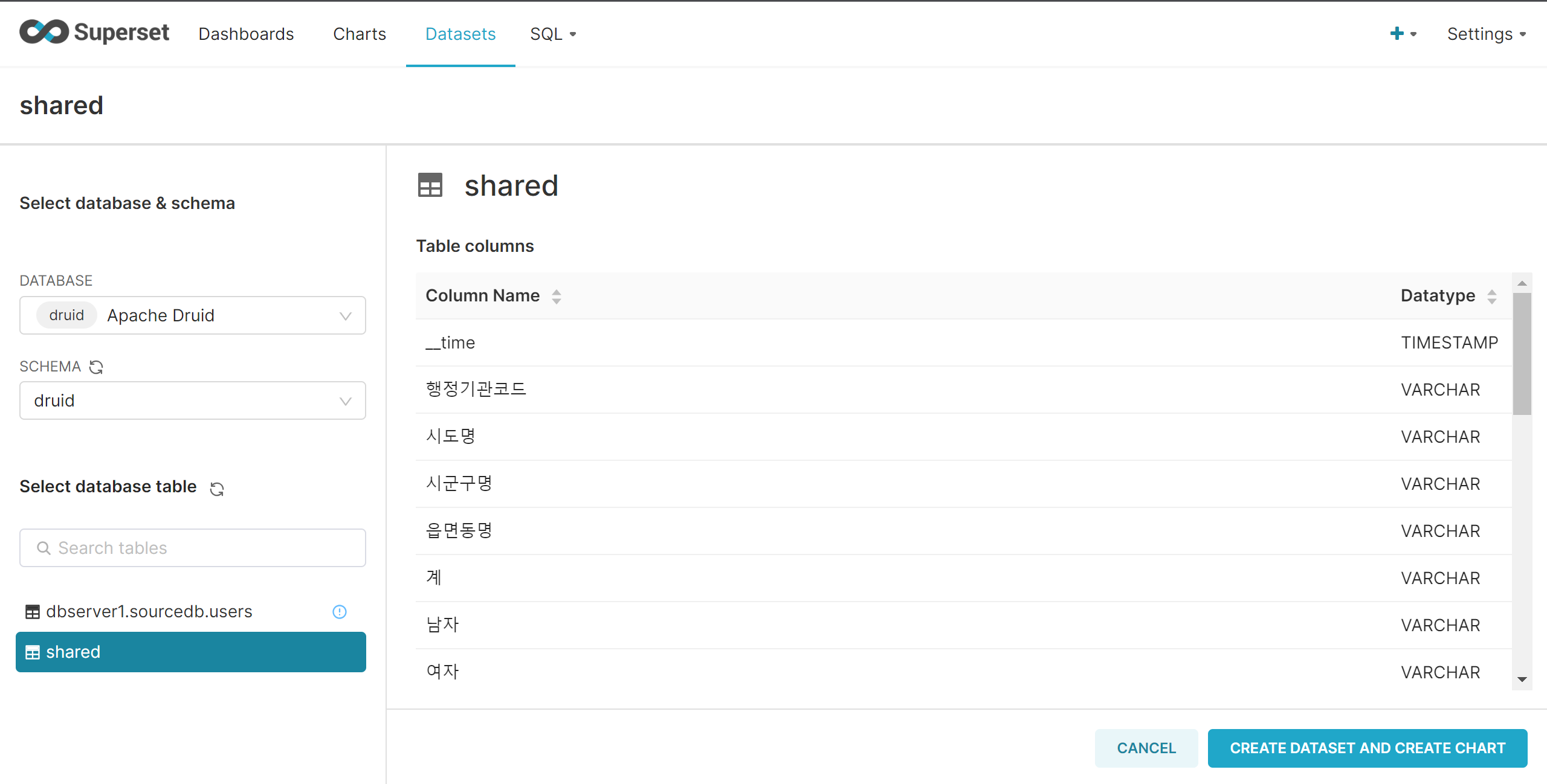
Superset에서 Druid Dataset 생성
Superset에서 druid DB 확인
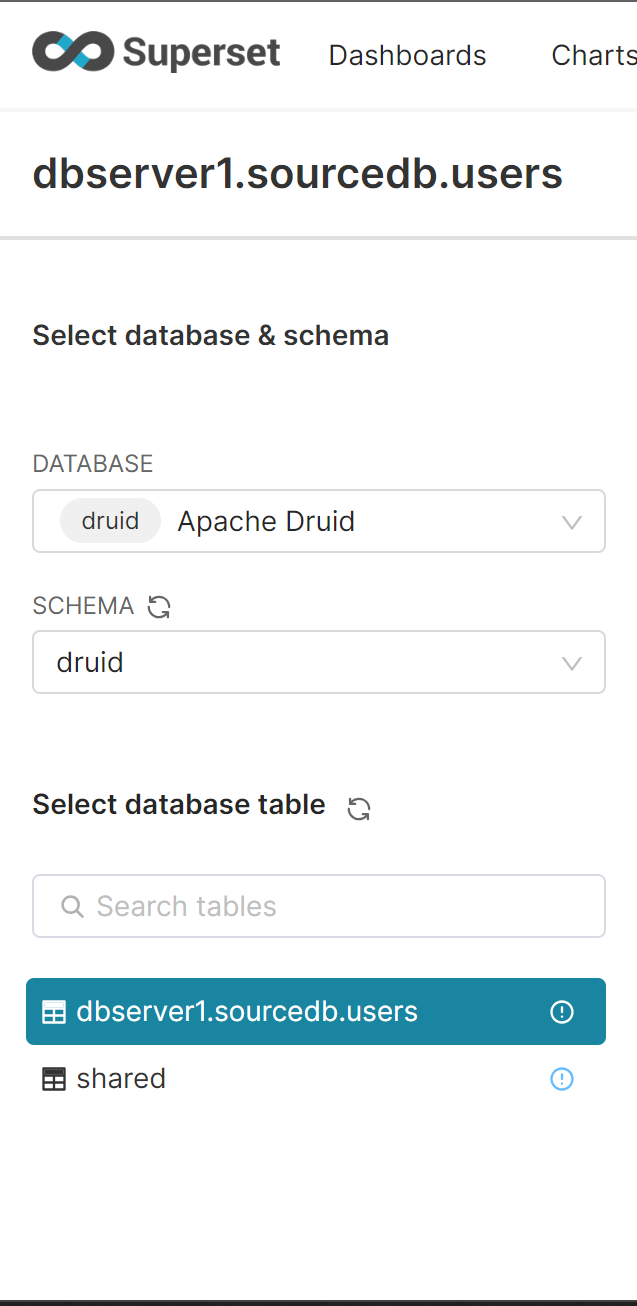
Superset Dataset 생성
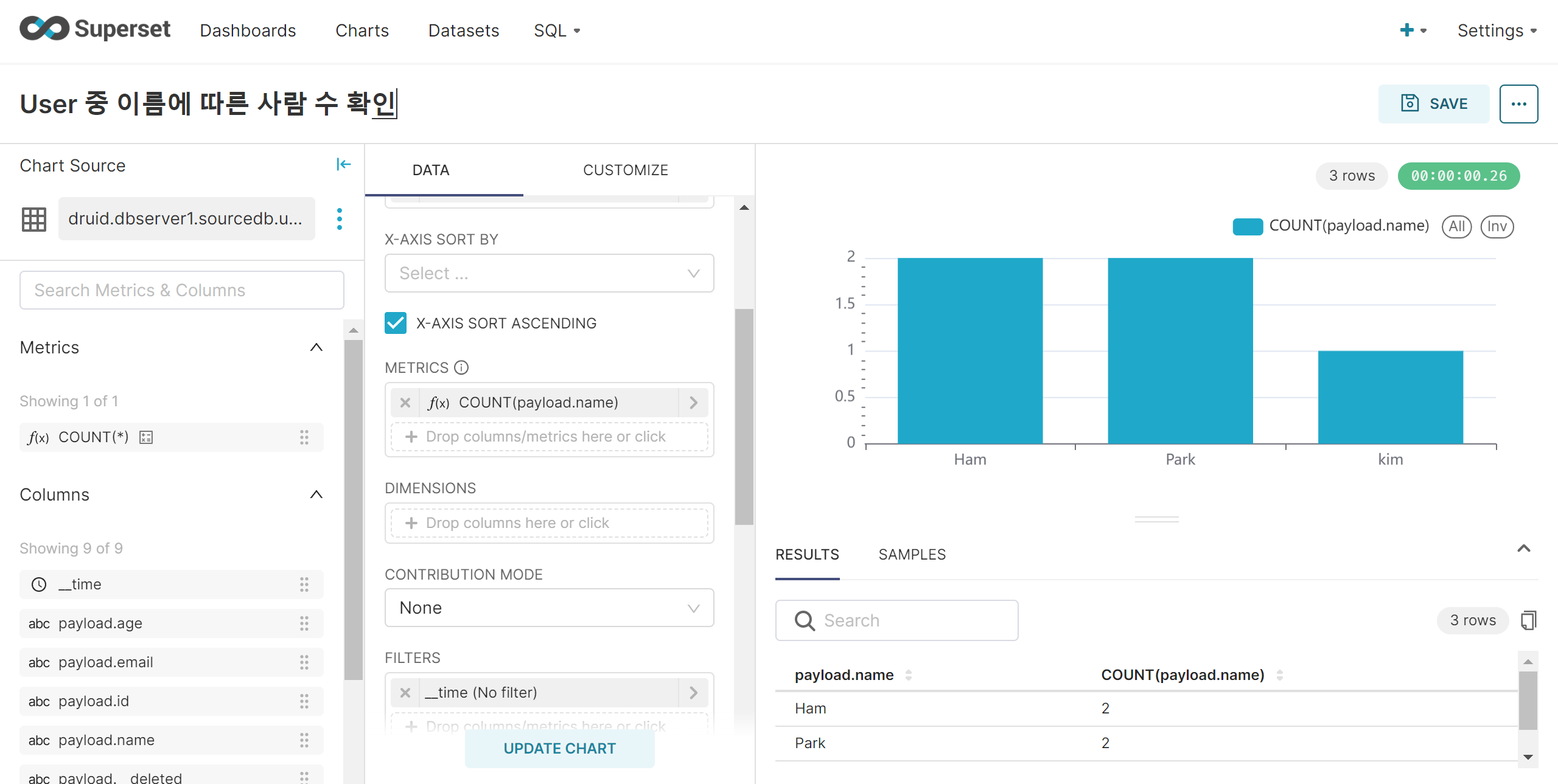
Superset Dashboard 생성
Kafka Streams
- dbserver1.sourcedb.users 토픽을 읽어와서 dbserver1.soucedb.streams 토픽에 저장하는 간단한 스트림즈 구현
package com.example.demo;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import java.util.Collections;
import java.util.Map;
import java.util.Properties;
@SpringBootApplication
public class KafkaStreams {
public static void main(String[] args) {
// Configure Kafka consumer properties
Properties kafkaProps = new Properties();
kafkaProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "http://132.226.231.51/:9092");
kafkaProps.put(ConsumerConfig.GROUP_ID_CONFIG, "kafka-streams");
kafkaProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kafkaProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// Create a Kafka consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(kafkaProps);
// Subscribe to the Kafka topic
consumer.subscribe(Collections.singleton("dbserver1.sourcedb.users"));
// Start consuming messages from Kafka topic
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
// Process the record and convert it to a format compatible with further processing or storage
String processedData = processRecord(record);
// Perform your custom logic here with the processed data
System.out.println("Processed data: " + processedData);
}
}
}
private static String processRecord(ConsumerRecord<String, String> record) {
// Implement your logic to process the Kafka record and convert it to the desired format
ObjectMapper objectMapper = new ObjectMapper();
try {
// Parse the JSON payload into a map
Map<String, Object> payloadMap = objectMapper.readValue(record.value(), new TypeReference<Map<String, Object>>() {});
// Remove the unnecessary schema field
payloadMap.remove("schema");
// Convert the payload map to JSON string
String processedData = objectMapper.writeValueAsString(payloadMap);
// Send the processed data to the target Kafka topic
sendToTargetTopic(processedData, "dbserver1.sourcedb.streams");
return processedData;
} catch (Exception e) {
System.err.println("Error occurred while processing the record: " + e.getMessage());
// Handle error or retry logic here
return null;
}
}
}CDC + Druid + Superset (실시간성) Demo
OCI Source DB Mysql에 데이터 삽입

로컬 드루이드에서 Task 확인

드루이드 DataSource 확인
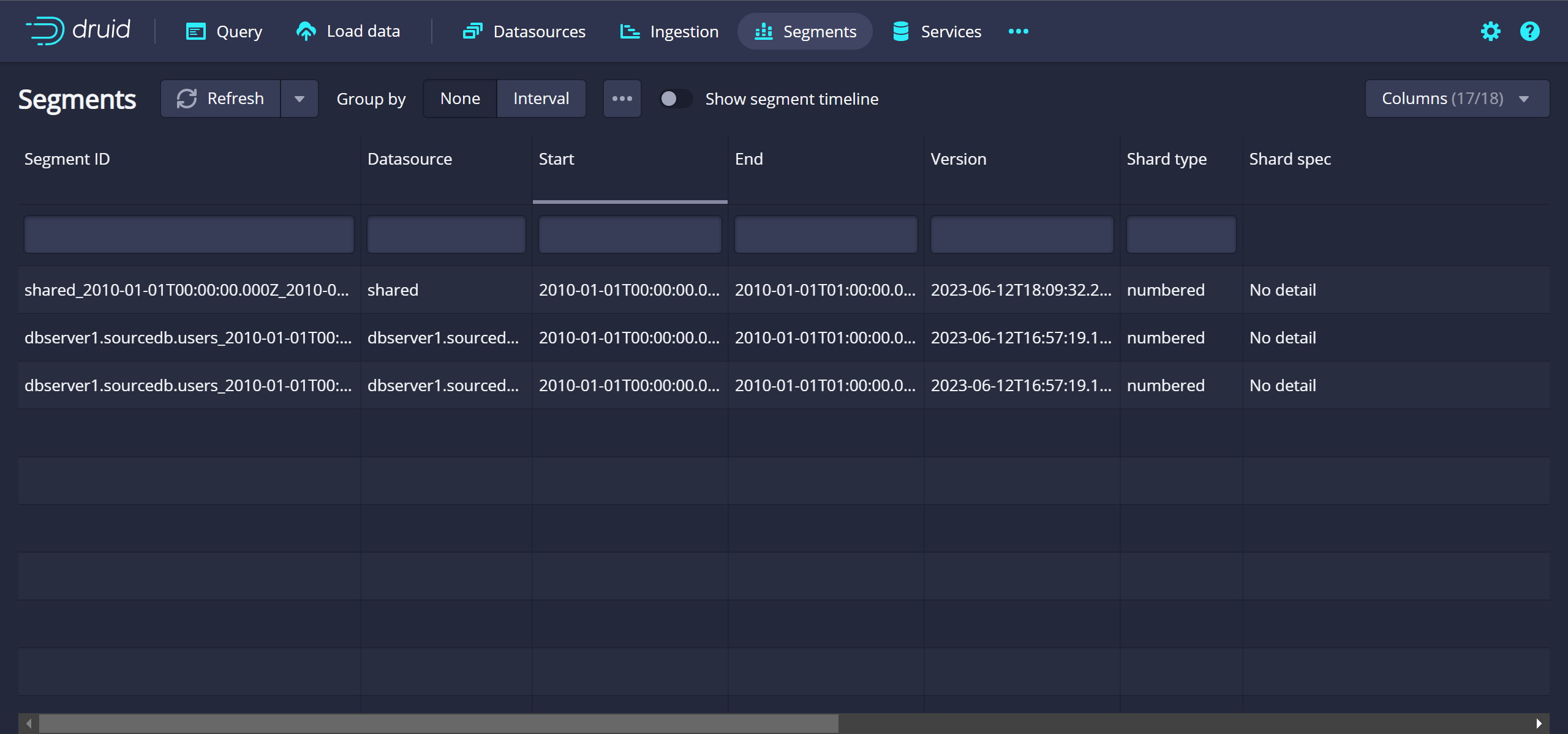
드루이드 Segment 확인
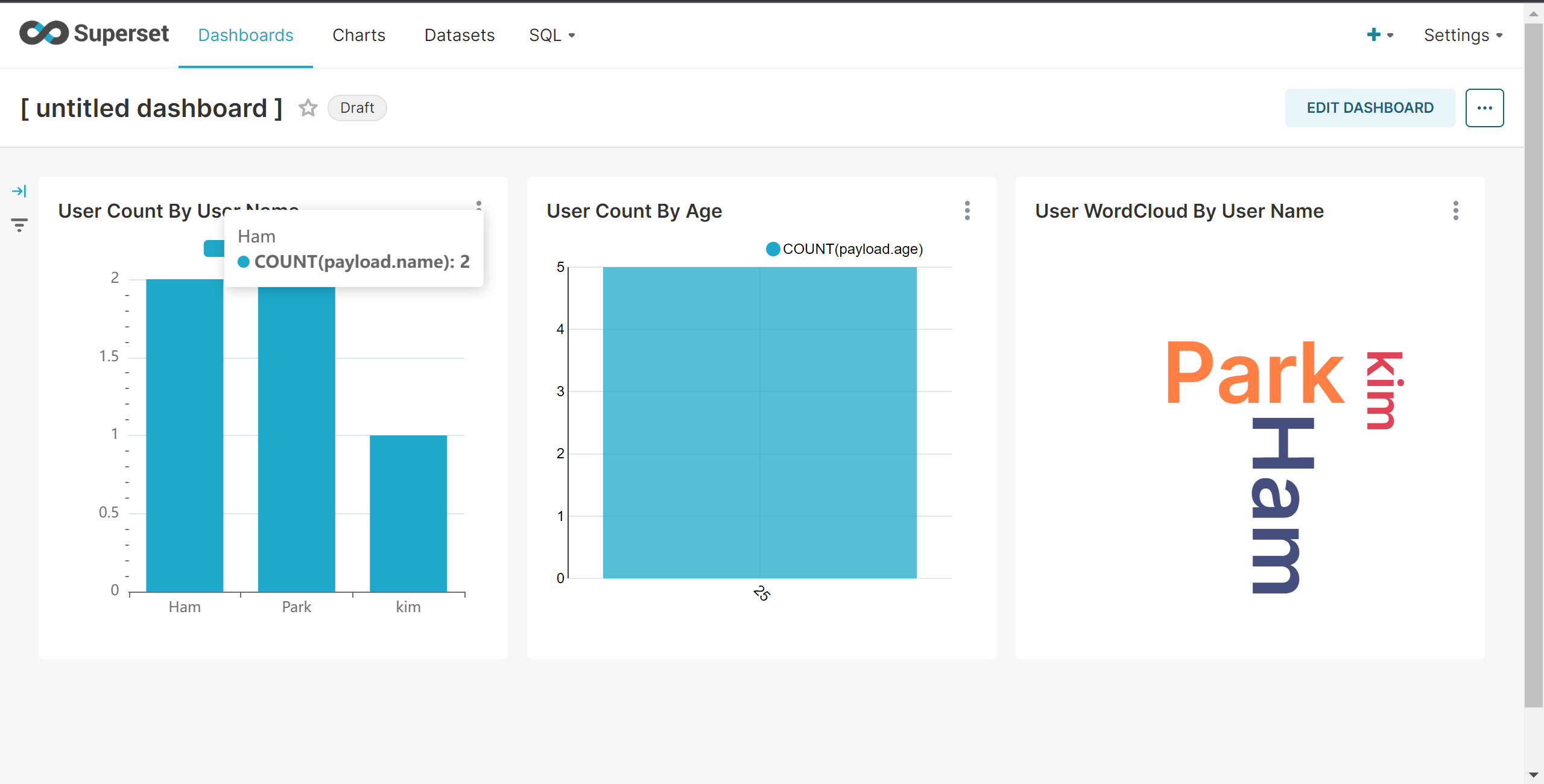
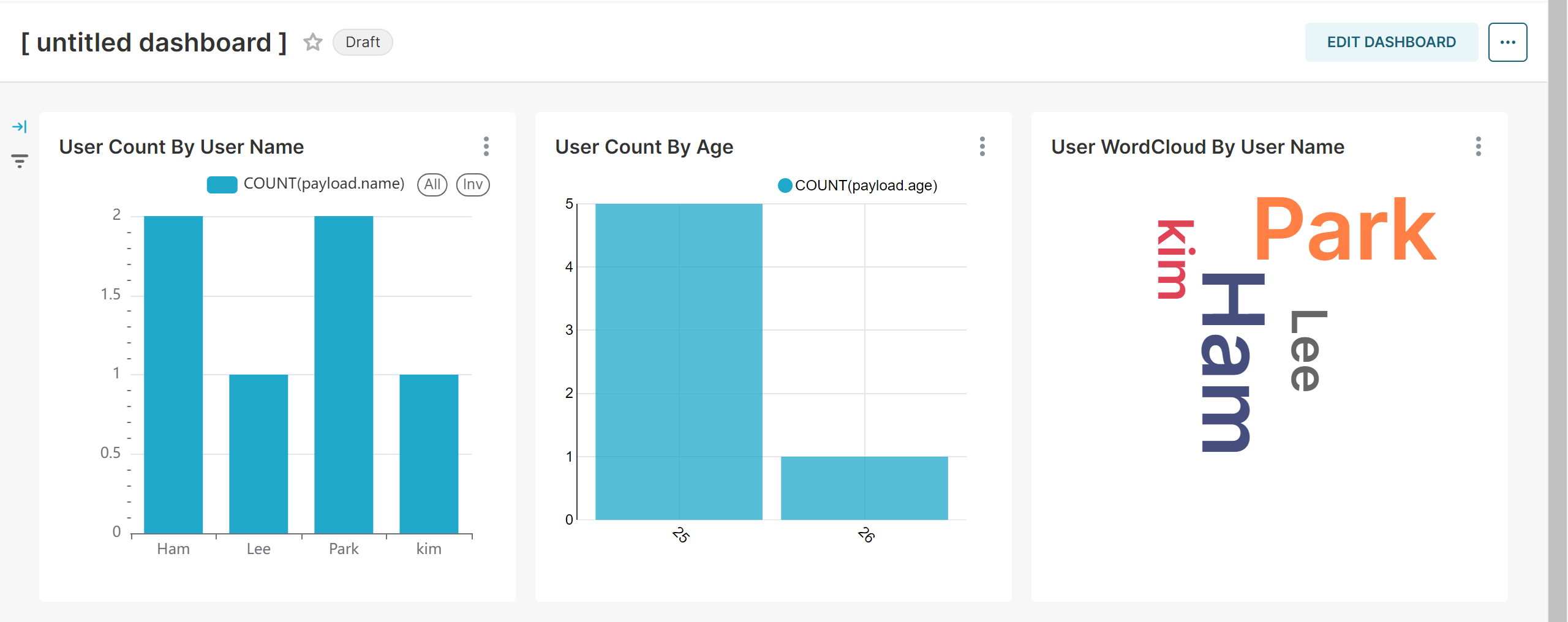
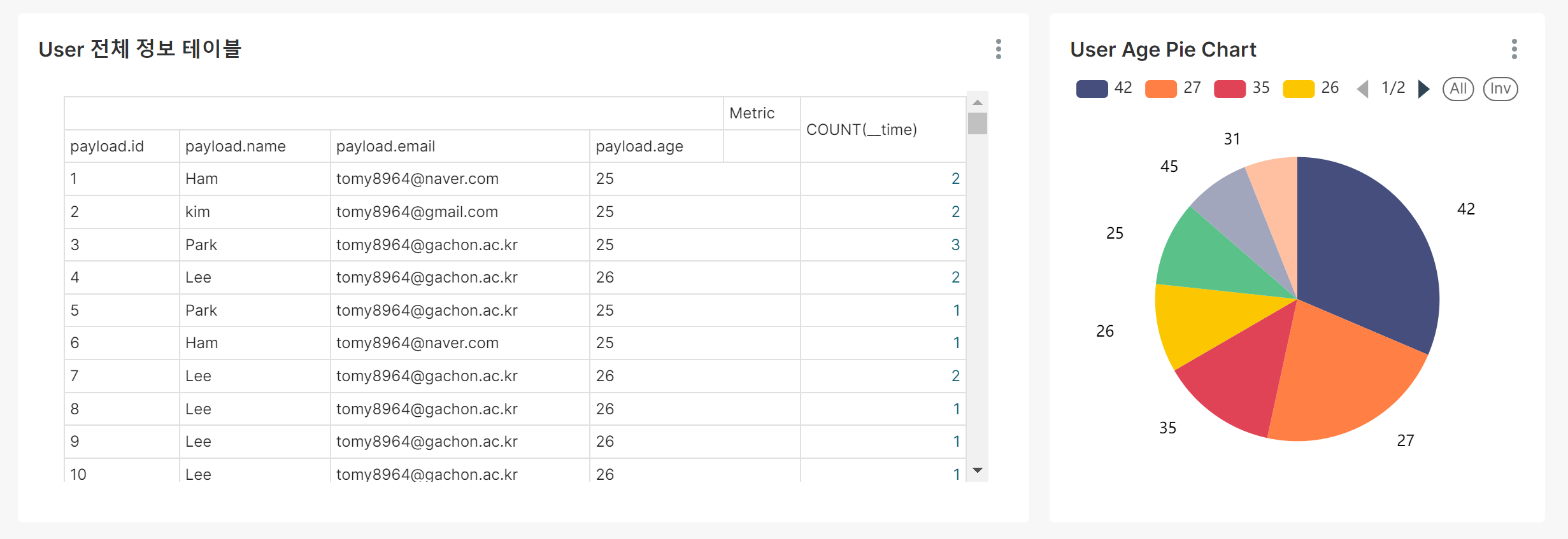
Superset Dashboard 확인 - 이름이 Lee 이고 나이가 26 인 사람이 추가됨
팀프로젝트 Data + Druid + Superset(배치성) demo
드루이드 load data
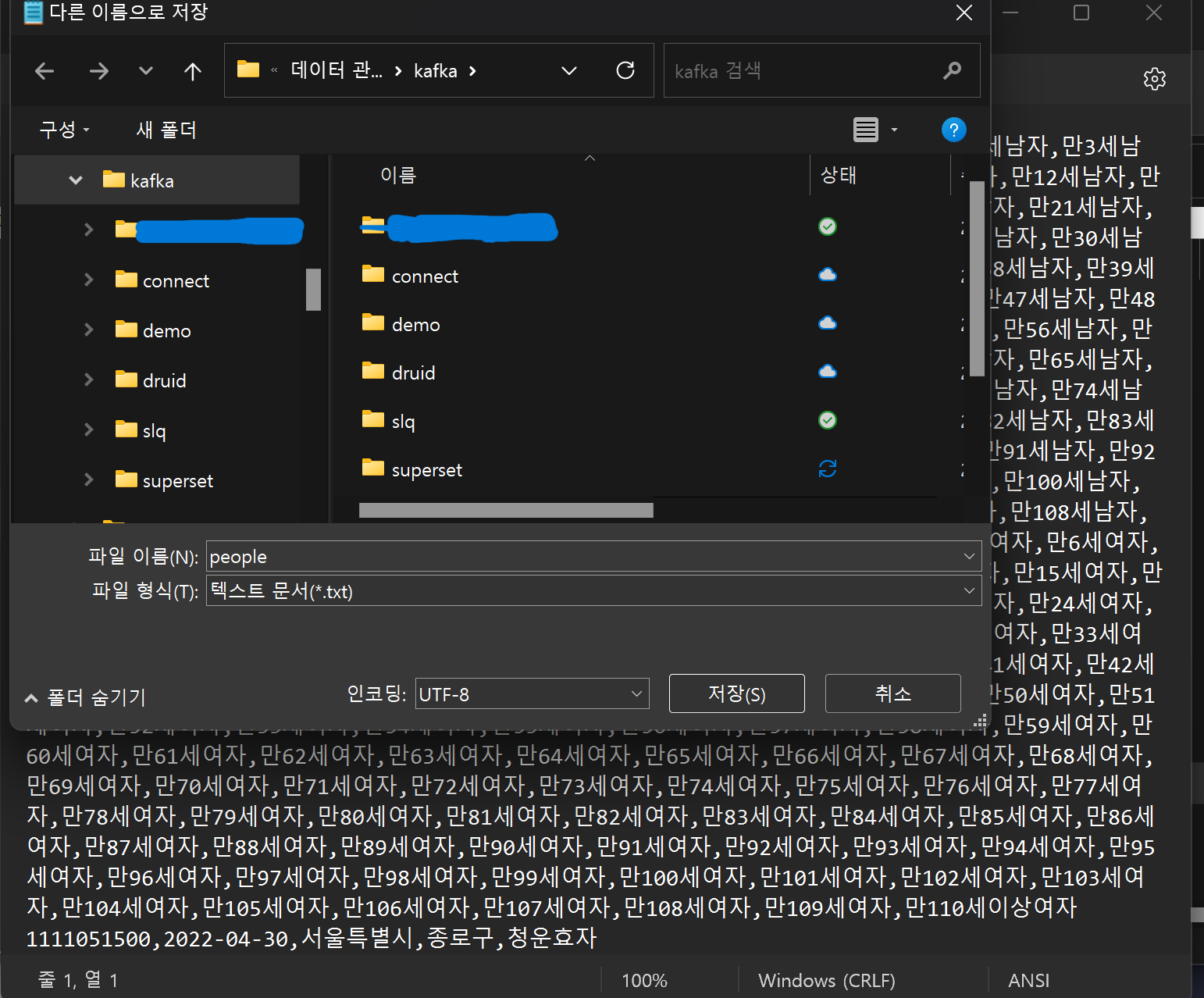
- 팀 프로젝트 데이터(서울시 읍면동에 등록된 주민의 연령별 수의 2022년~2023년까지의 월별 데이터) druid의 base directory로 복사

💡 파일의 인코딩이 깨지는 현상 메모장으로 utf-8로 변환
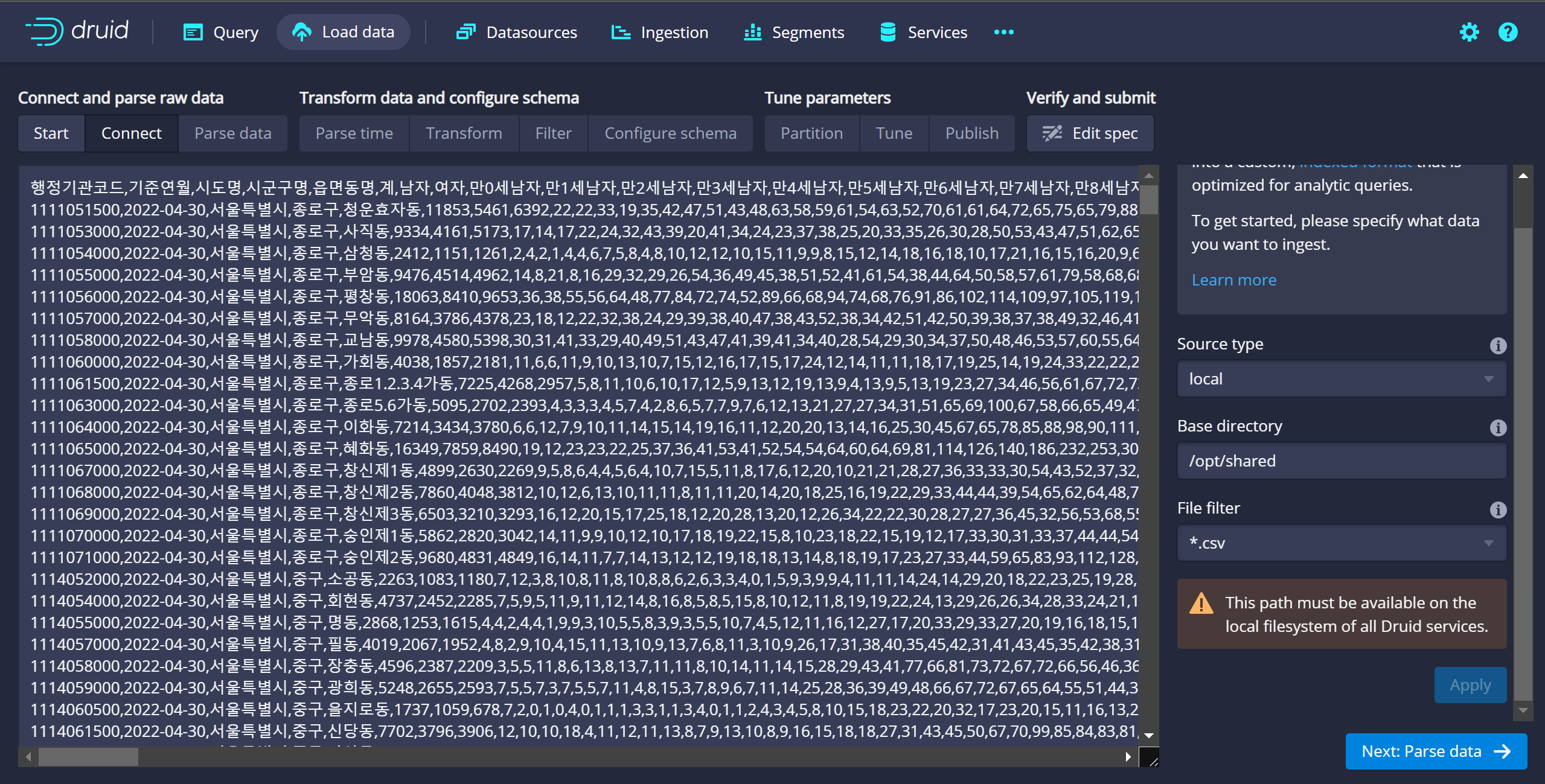
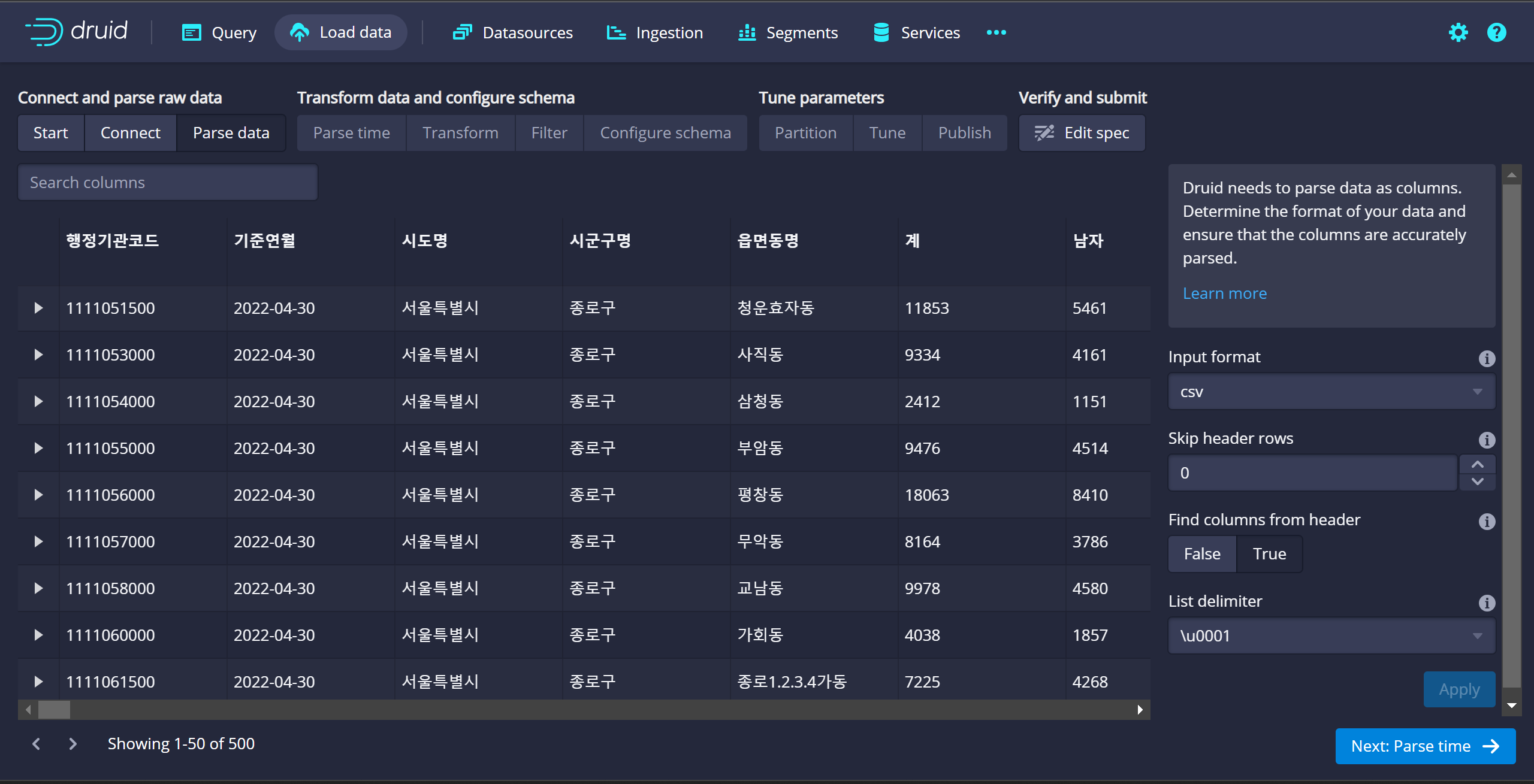
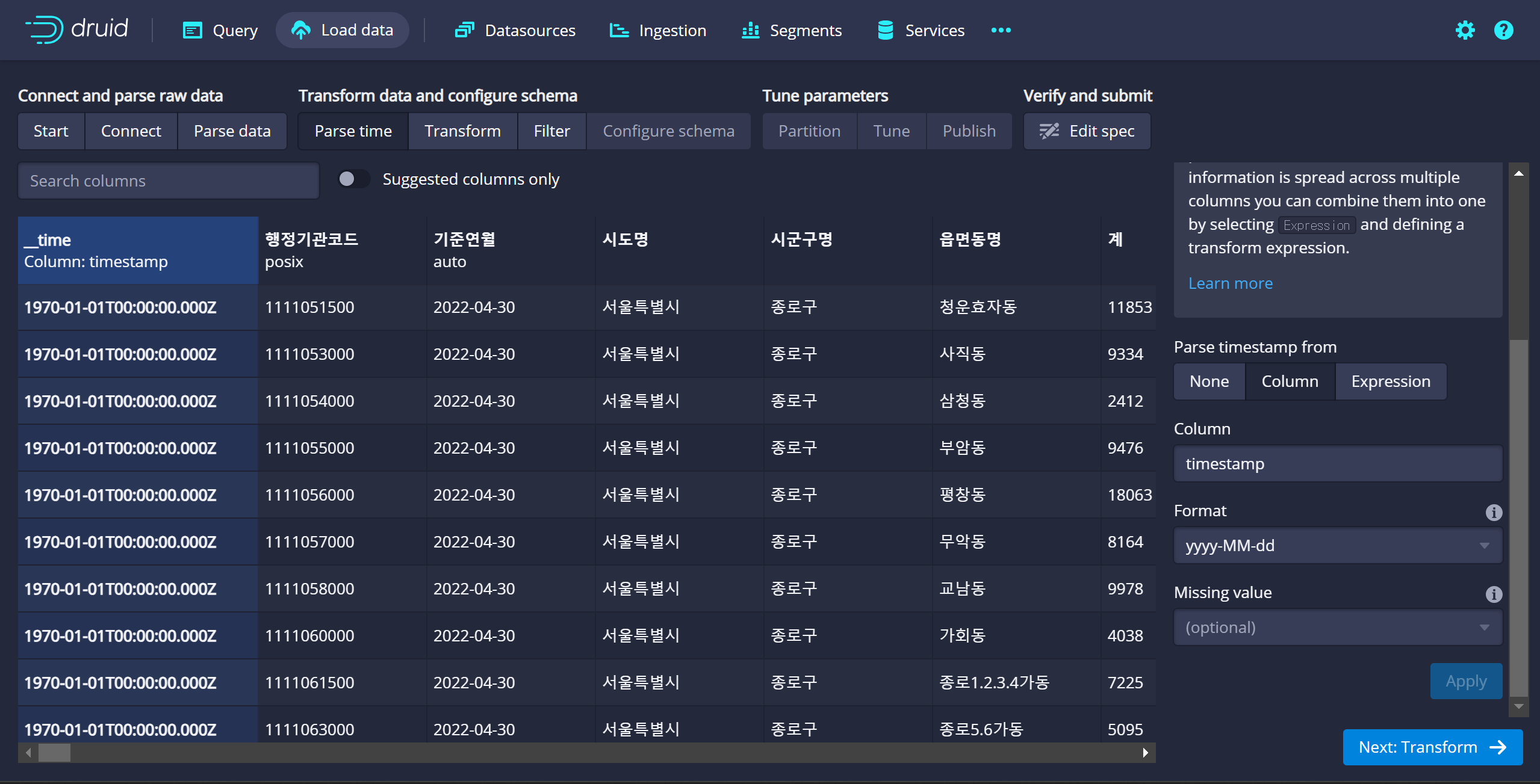
timstamp Column → 기준연월 기준으로 지정
Tasks 생성 확인

Datasource 생성 확인
Superset Dataset 생성
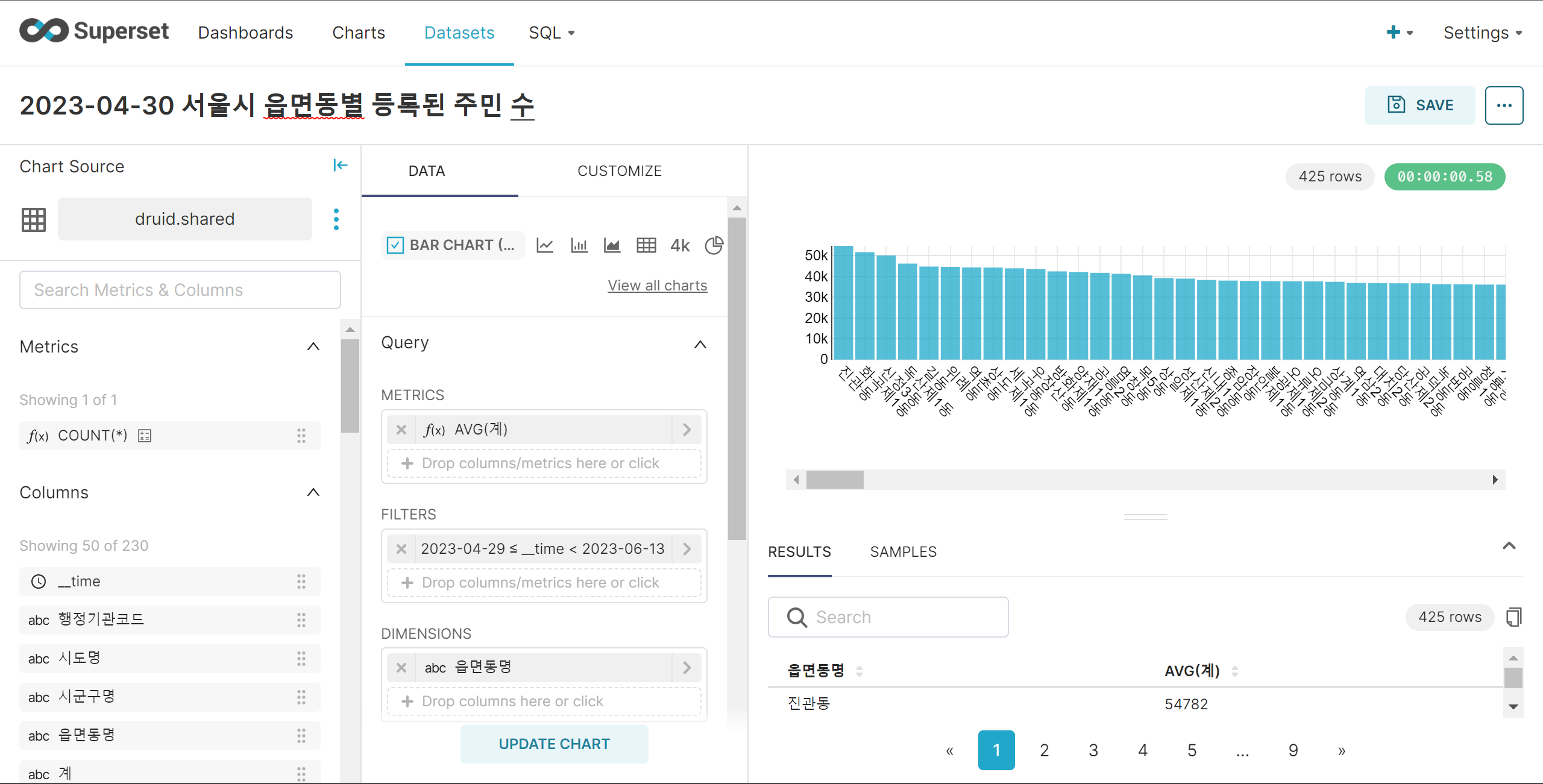
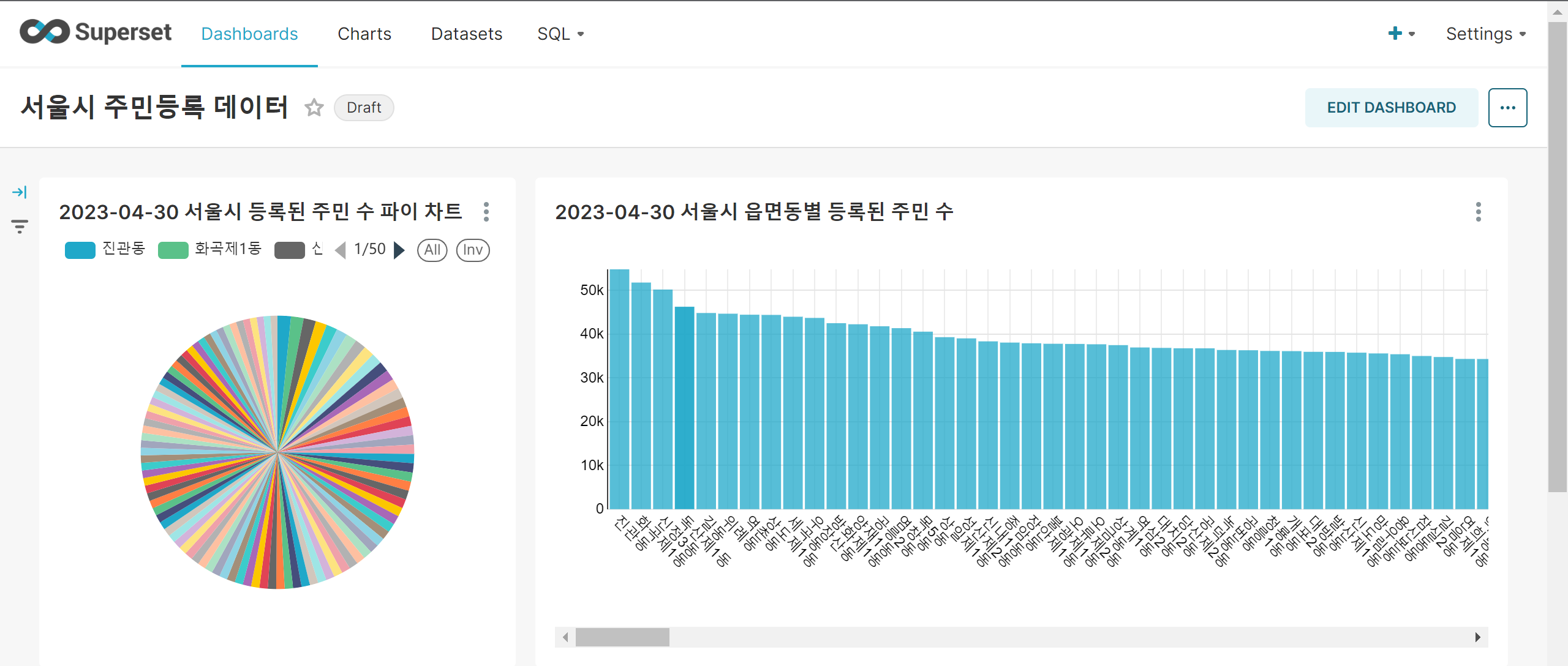
Superset Dashboard visualization
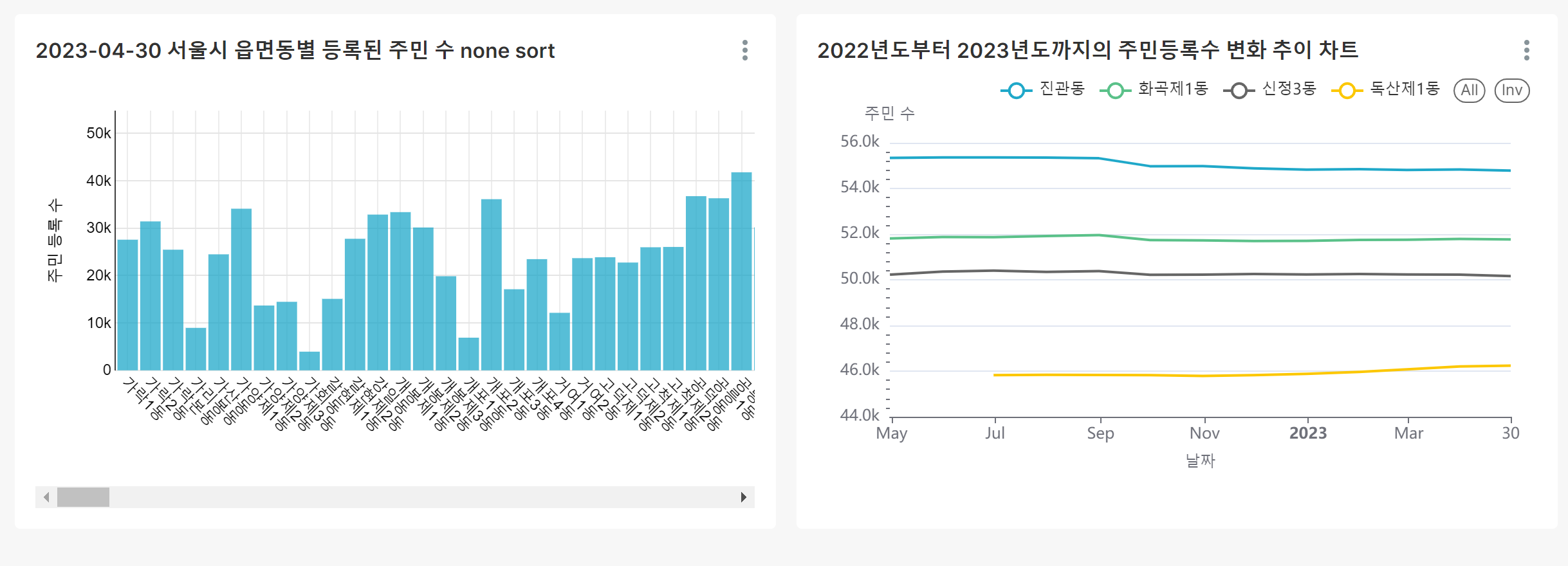
팀 프로젝트 Data 서울시 읍면동별 등록된 주민 수 2022~2023
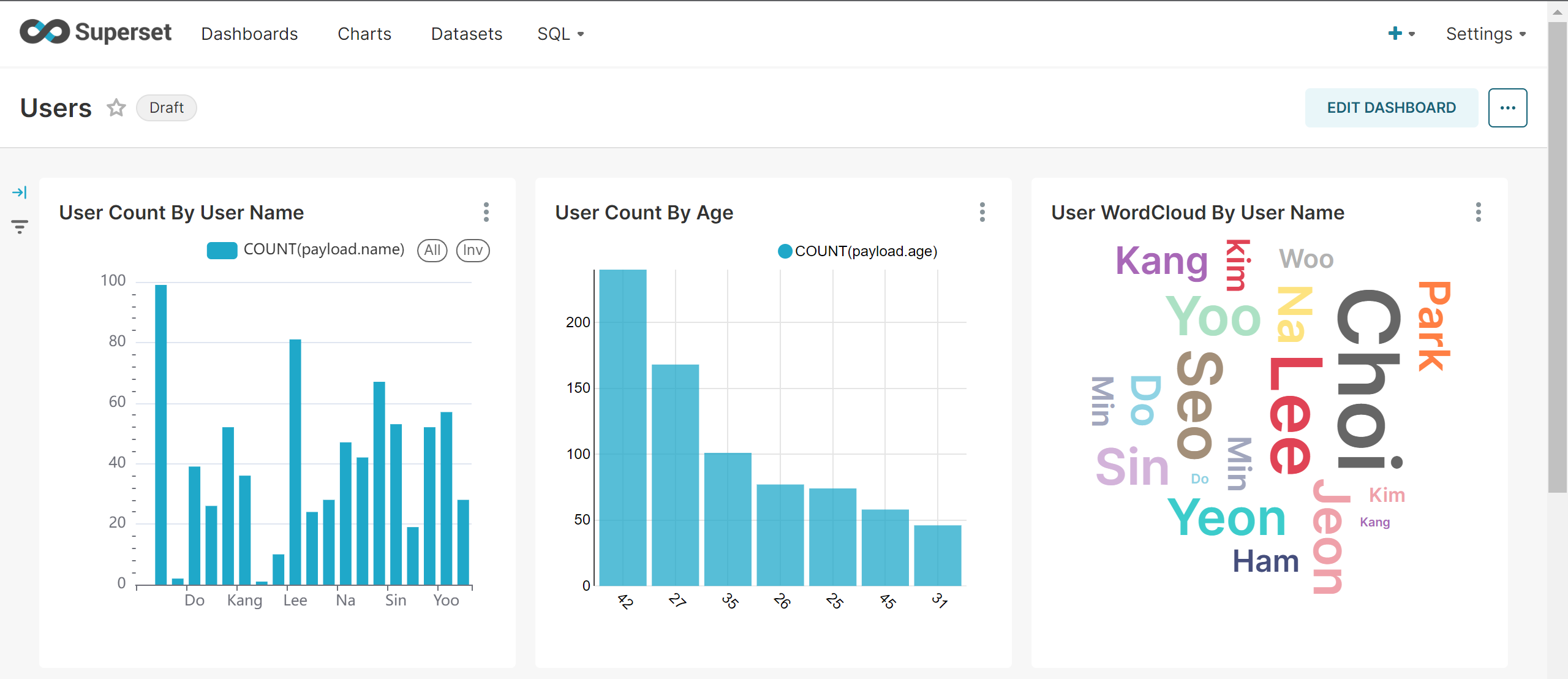
SourceDB에 저장된 Users Table의 실시간성 데이터

가오리의 개발 이야기