Vitis AI Overview
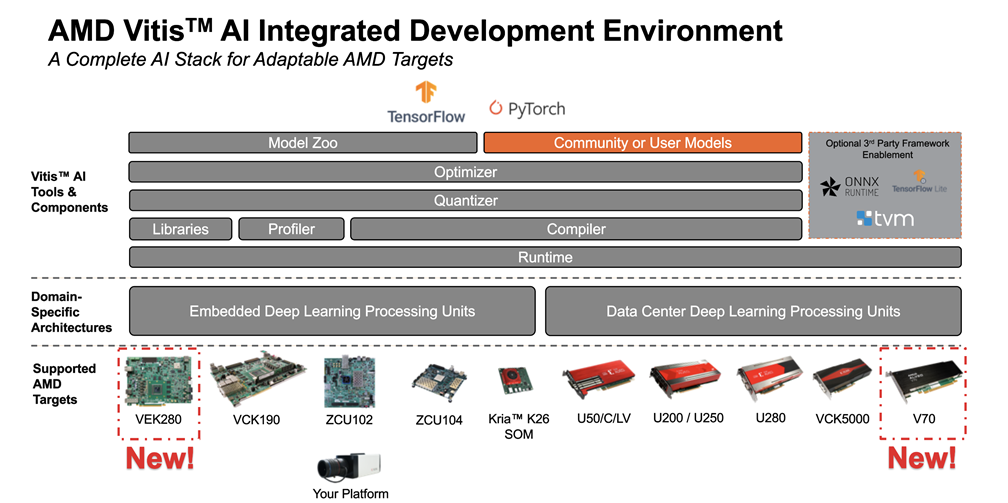
Vitis AI Tools
-
Vitis AI Model Zoo : 여러 AI model이 AMD 플랫폼에서 돌아가도록 파인튜닝(?) 된거 같은 것들이 있는 깃헙
-
Vitis AI Optimizer : 가지치기와 파인튜닝으로 모델 복잡성 줄임

-
Vitis AI Quantizer : FP32 weight들을 INT8 로 변환

-
Vitis AI Compiler : 양자화된 AI 모델을 DPU instruction set으로 변환

-
Vitis AI Profiler : AI App 분석 도구. 병목 현상 식별, CPU와 DPU, 메모리 로드율 확인 등 성능 조정 툴
-
Vitis AI Library : XRT(Xilinx Runtime)와 통합된 DPU AI inference 를 위한 API
Vitis AI Runtime
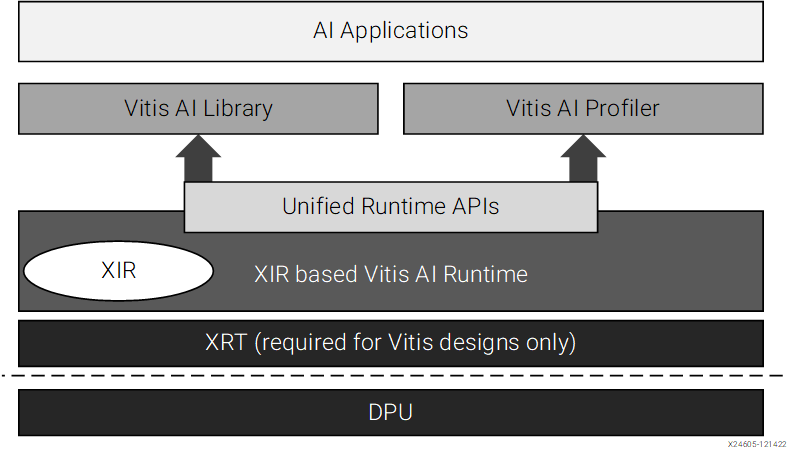
- 배포하는데 도움을 준는 상위 수준 런타임 API
- XIR(AMD Intermediate Repersentation)은 Vitis AI에서 신경망 operators 를 나타내는데 사용되는 내부 IR
Vitis AI Containers
containers를 이용하여 AI software 를 release 함
포함 내용
- Tools container
- exmaples on the public GitHub
- Vitis AI Model Zoo
Tools Container
- Containers (Docker Hub)
- Unified Compiler
- Compiler flow for DPUCZDX8G (Edge)
- Compiler flow for DPUCVDX8G (Edge)
- Compiler flow for DPUCV2DX8G (Edge and Data Center)
- Pre-built conda enviroment
conda activate vitis-ai-tensorflow2
- Versal Runtime tools
Pruning 하는 법(TensorFlow2)
- Creating a Model
model = keras.Sequential([
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(), layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
])- Creating a Pruning Runner
from tf_nndct.pruning import IterativePruningRunner
input_shape = [28, 28, 1]
input_spec = tf.TensorSpec((1, *input_shape), tf.float32)
runner = IterativePruningRunner(model, input_spec)-
Pruning the Model
- 모델 성능 평가를 위한 함수 지정
- 첫 번째 인자는 평가할
keras.Model의 객체여야 함 - 모델의 성능을 나타낼 Python value를 반환해야함
- 첫 번째 인자는 평가할
def evaluate(model): model.compile(loss="categorical_crossentropy", optimizer="adam", metrics= ["accuracy"]) score = model.evaluate(x_test, y_test, verbose=0) return score[1]- 모델 분석 실행
runner.ana(evaluate)- 가지치기 비율 결정
[FLOPs of pruned model] = (1 – ratio) * [FLOPs of original model]비율 값은 (0, 1)
sparse_model = runner.prune(ratio=0.2) - 모델 성능 평가를 위한 함수 지정
-
Fine-tuning a Sparse Model
sparse_model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
sparse_model.fit(x_train, y_train, batch_size=128, epochs=15, validation_split=0.1)
sparse_model.save_weights("model_sparse_0.2", save_format="tf")- Iterative Pruning
pruning 비율 값을 올려가며 가지치기 반복, fine-tuning. 해당 과정 반복
model.load_weights("model_sparse_0.2")
input_shape = [28, 28, 1]
input_spec = tf.TensorSpec((1, *input_shape), tf.float32)
runner = IterativePruningRunner(model, input_spec)
sparse_model = runner.prune(ratio=0.5)- Getting the Pruned Model
model.load_weights("model_sparse_0.5")
input_shape = [28, 28, 1]
input_spec = tf.TensorSpec((1, *input_shape), tf.float32)
runner = IterativePruningRunner(model, input_spec)
slim_model = runner.get_slim_model()
# slim_model = runner.get_slim_model(".vai/mnist_ratio_0.5.spec") 파일 경로를 직접 지정
# 모델 저장
slim_model.save('/tmp/model')
loaded_model = tf.keras.models.load_model('/tmp/model')tensorflow2 API
Quantizing the Model
-
vai_q_tensorflow2 설치
- Using Docker Container
[docker] $ conda activate vitis-ai-tensorflow2 # [optional] [docker] $ sudo env CONDA_PREFIX=/opt/vitis_ai/conda/envs/vitis-ai-tensorflow2/ PATH=/opt/vitis_ai/conda/bin:$PATH conda install patch_package.tar.bz2- Source Code with the Whell Package
[host] $ sh build.sh [host] $ pip install pkgs/*.whl- Source Code with the Conda Package
# GPU version [host] $ conda build vai_q_tensorflow2_gpu_feedstock --output-folder ./conda_pkg/ # Install conda package on your machine [host] $ conda install --use-local ./conda_pkg/linux-64/*.tar.bz2 -
Inspecting the Float Model
model = tf.keras.models.load_model('float_model.h5')
from tensorflow_model_optimization.quantization.keras import vitis_inspect
inspector = vitis_inspect.VitisInspector(target="DPUCADF8H_ISA0")
inspector.inspect_model(model,
plot=True,
plot_file="model.svg",
dump_results=True,
dump_results_file="inspect_results.txt",
verbose=0)
target: string. target DPU. default = None
model: tf.keras.Model instance. 검사할 float model
input_shape: ist(int) or list(list(int)) or tuple(int) or dictionary(int). 입력 레이어에 대한 모양. defualt = None
plot: bool. 이미지 저장 여부. default = False
plot_file: string. 결과 텍스트 파일의 경로. defualt = 'model.svg"
dump_results: bool. 결과 덤프하고 텍스트 저장할지. defualt = False
dump_results_file: string. 텍스트 파일 경로. default = 'inspect_results.txt"
verbose: int. log 수준. defualt = 0
- vai_q_tensorflow2 실행
-
Post-training quantization (PTQ)
모델 정확도 저하가 거의 없음
대표 데이터 셋이 필요 -
Quantization aware training (QAT)
순방향 및 역방향 에러를 양자화
이미 좋은 정확도를 보이는 부동 소수점 학습 모델로 시작하는 것이 좋음3-1. PTQ
model = tf.keras.models.load_model('float_model.h5')
from tensorflow_model_optimization.quantization.keras import vitis_quantize
quantizer = vitis_quantize.VitisQuantizer(model)
quantized_model = quantizer.quantize_model(calib_dataset=calib_dataset,
calib_steps=100,
calib_batch_size=10,
**kwargs)
calib_dataset: calibration 과정에 쓰이는 dataset
calib_steps: 교정 단계. default = None
calib_batch_size: 배치당 샘플 수. default = 32
input_shape: int형 list, tuple, dictionary. default = 입력 레이어의 모양
**kwargs: 사용자 정의 구성 dictionary
model = tf.keras.models.load_model('float_model.h5')
# *Call Vai_q_tensorflow2 api to create the quantize training model
from tensorflow_model_optimization.quantization.keras import vitis_quantize
quantizer = vitis_quantize.VitisQuantizer(model)
qat_model = quantizer.get_qat_model(
init_quant=True, # Do init PTQ quantization will help us to get a better initial state for the quantizers, especially for the `pof2s_tqt` strategy. Must be used together with calib_dataset
calib_dataset=calib_dataset)
# Then run the training process with this qat_model to get the quantize finetuned model.
# Compile the model
qat_model.compile(
optimizer= RMSprop(learning_rate=lr_schedule),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=keras.metrics.SparseTopKCategoricalAccuracy())
# Start the training/finetuning
qat_model.fit(train_dataset)
# save model manually
qat_model.save('trained_model.h5')
# save the model periodically during fit using callbacks
qat_model.fit(
train_dataset,
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath='./quantize_train/'
save_best_only=True,
monitor="sparse_categorical_accuracy",
verbose=1,
)])
quantized_model = vitis_quantizer.get_deploy_model(qat_model) quantized_model.save('quantized_model.h5')
from tensorflow_model_optimization.quantization.keras import vitis_quantize
quantized_model = tf.keras.models.load_model('quantized_model.h5')
quantized_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics= keras.metrics.SparseTopKCategoricalAccuracy())
quantized_model.evaluate(eval_dataset)
3-3. Fast Finetuning
정확도 손실이 큰 경우 AdaQuant 알고리즘을 사용하여 빠른 미세 조정을 시행해야함
PTQ보다 시간이 오래걸리지만 정확도가 만족스럽지 않을때 시도
quantized_model = quantizer.quantize_model(calib_dataset=calib_dataset, calib_steps=None,
calib_batch_size=None, include_fast_ft=True,
fast_ft_epochs=10)
include_fast_ft: boolean. fast finetuning
fast_ft_epochs: epochs
- Save
quantized_model.save('quantized_model.h5')optional
- Export to ONNX
model = tf.keras.models.load_model('float_model.h5')
from tensorflow_model_optimization.quantization.keras import vitis_quantize
quantizer = vitis_quantize.VitisQuantizer(model)
quantized_model = quantizer.quantize_model(calib_dataset=calib_dataset,
output_format='onnx',
onnx_opset_version=11,
output_dir='./quantize_results',
**kwargs)
onnx_opset_version: int. opset version. default = 11
output_dir: string. directory. default = './quantize_results'
- Evaluate
Vitis_quantize module 필요
rom tensorflow_model_optimization.quantization.keras import vitis_quantize quantized_model = tf.keras.models.load_model('quantized_model.h5')
quantized_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics= keras.metrics.SparseTopKCategoricalAccuracy())
quantized_model.evaluate(eval_dataset)- Dump the results
from tensorflow_model_optimization.quantization.keras import vitis_quantize
quantized_model = keras.models.load_model('./quantized_model.h5') vitis_quantize.VitisQuantizer.dump_model(model=quantized_model,
dataset=dump_dataset,
output_dir='./dump_results') dump_dataset의
batch_size는 target device의 batch_size와 같아야 한다.
Quantization Configuration
vai_q_tensorflow2 API
Model Compile
Deploy
dpu_runner = runner.Runner(subgraph,"run")
# populate input/output tensors
jid = dpu_runner.execute_async(fpgaInput, fpgaOutput)
dpu_runner.wait(jid)
# process fpgaOutputDebug with VART
