[논문 리뷰 & 코드 구현] Stable Diffusion (High-Resolution Image Synthesis with Latent Diffusion Models)
생성형 모델의 기초
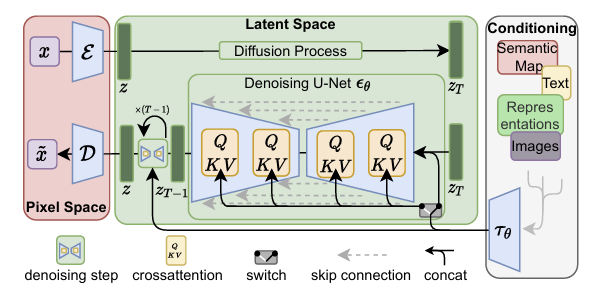
DDPM, DDIM 등 디퓨전 기반 생성 모델들이 발표된 뒤, 고질적인 속도와 리소스 문제를 해결하기 위해 다양한 연구들이 진행됐다. DALL-E 등 획기적인 모델들이 개발되었지만, 여전히 디퓨전 기반 모델들은 GAN에 비해 아쉬운 점이 많았다. 속도 뿐만 아니라 고화질 이미지 생성에도 문제가 있었다. 하지만 2022년 발표된, 흔히 Stable Diffusion이라 불리는 이 모델은 GAN, VAE, Diffusion 등 다양한 생성 모델의 이점을 조금씩 활용한 아주 획기적인 발명이었다. 속도, 화질 면에서 개선했을 뿐만 아니라, conditioning을 줄 수 있어 text-to-image 등 다양한 task에도 적용이 가능하다.
Stable Diffusion은 그 성능 덕에 현재까지도 많은 방식으로 활용되고 있다.
논문 링크
0. Abstract
 Diffusion 모델 (DM)은 이미지 생성 분야에서 좋은 성능을 보였지만, 픽셀 단위로 계산이 일어나므로 GPU 사용량이 굉장히 많았다. 본 논문에서 제시하는 Latent Diffusion model (LDM)은 픽셀 공간 대신 잠재 공간에서 diffusion training을 진행하기에 한정된 자원으로도 높은 성능을 유지한다. 뿐만 아니라 cross-attention을 사용하여 텍스트나 bounding box 등 다양한 conditioning이 가능하게 한다. 결국 다양한 작업에서 활용이 가능하기에, 기존 모델들에 비해 연산량은 적고 성능과 활용성은 뛰어나다.
Diffusion 모델 (DM)은 이미지 생성 분야에서 좋은 성능을 보였지만, 픽셀 단위로 계산이 일어나므로 GPU 사용량이 굉장히 많았다. 본 논문에서 제시하는 Latent Diffusion model (LDM)은 픽셀 공간 대신 잠재 공간에서 diffusion training을 진행하기에 한정된 자원으로도 높은 성능을 유지한다. 뿐만 아니라 cross-attention을 사용하여 텍스트나 bounding box 등 다양한 conditioning이 가능하게 한다. 결국 다양한 작업에서 활용이 가능하기에, 기존 모델들에 비해 연산량은 적고 성능과 활용성은 뛰어나다.
1. Introduction
Image synthesis 분야는 높은 계산 자원이 요구된다. AR transformer 등 likelihood 기반 모델들은 수십 억 개의 파라미터를 필요로 한다. GAN은 비교적 낫지만, 복잡한 분포나 멀티 모달 문제에서는 한계를 보였다. 더 최근에는 diffusion 기반 모델이 좋은 성능을 보여주었으며, 다양한 작업에 바로 적용이 가능했다. GAN의 고질적인 문제 (mode collapse, 학습 불안정성)은 해결하면서도 AR보다 적은 파라미터를 사용하였다.
하지만 DM 역시 likelihood 기반 모델이다. 데이터의 미세한 디테일까지 과도하게 모델링하려는 경향이 있어 계산 자원이 많이 소모된다. 과도한 계산량 요구로 인해 접근성이 떨어지며, 심지어 이미 학습된 경우에도 추론 시 시간과 자원이 많이 요구된다.
따라서 본 논문에서는 DM의 강력한 성능은 유지하면서도 훈련과 추론 과정의 계산 복잡도를 모두 줄일 수 있는 방법을 제시하고자 한다. 먼저 DM의 근본적인 성질을 알아보자. 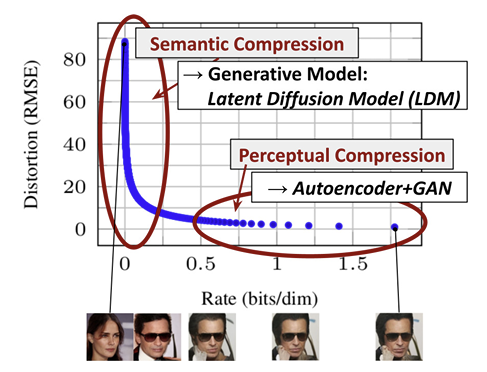 위 그래프는 'Perceptual compression'과 'Semantic compression'를 비교한다. 전자는 bit-rate가 큰 'low-level' 정보로, 사람 눈으로 인지가 가능한 부분이다. Autoencoder나 GAN은 주로 이 부분을 학습하는데 주력한다. 반면 DM은 후자를 주로 학습하게 되는데, 사람이 감지할 수 없는 'high-level' 정보에 지나친 자원을 소비하는 경향이 존재한다. 따라서 perceptually equivalent하지만 계산적으로 더 적합한 space를 찾는 것을 목표로 한다.
위 그래프는 'Perceptual compression'과 'Semantic compression'를 비교한다. 전자는 bit-rate가 큰 'low-level' 정보로, 사람 눈으로 인지가 가능한 부분이다. Autoencoder나 GAN은 주로 이 부분을 학습하는데 주력한다. 반면 DM은 후자를 주로 학습하게 되는데, 사람이 감지할 수 없는 'high-level' 정보에 지나친 자원을 소비하는 경향이 존재한다. 따라서 perceptually equivalent하지만 계산적으로 더 적합한 space를 찾는 것을 목표로 한다.
그래서 저자들이 제시하는 모델은 다음과 같다. 먼저 autoencoder를 학습하여 'perceptually equivalent'한 저차원 공간으로 데이터를 보낸다. 이는 Perceptual compression 과정으로, 사람 눈에 중요하지 않은 세부 정보를 제거하는 것으로 이해할 수 있다. 이렇게 압축화된 잠재 공간에서 DM을 훈련하는데, 의미적, 개념적 정보를 학습하여 새로운 이미지를 생성한다. 이는 Semantic compression이며, 이전과 달리 압축된 잠재 공간에서 학습하므로 효율적으로 진행된다.
한 번 훈련된 autoencoder는 다른 diffusion model에도 재사용이 가능하며, 다양한 task도 수행가능해진다. 특히 transformer 구조를 DM의 U-Net에 연결하면 conditioning (text 등)도 가능하다. 이러한 일련의 모델을 LDM (Latent Diffusion Model)이라 한다.
결론적으로 본 논문에서 제시하는 LDM은 다양한 이점이 있다. 고해상도 이미지에도 효과적으로 적용되며, 다양한 작업에서 높은 성능을 보인다. 또한, 기존 DM에 비해 비용이 크게 감소하였으며 멀티모달 training도 가능하다.
2. Related Work
Generative Models for Image Synthesis
기존 생성 모델들을 다시 살펴보자.
- GAN : 고화질 이미지 생성 효율적 생성 but 학습 어려움, 전체 분포 반영 어려움
- Likelihood Based Model (VAE, flow based): 최적화 용이 but 품질 낮음
- ARM : 좋은 성능 but 계산량 많이 요구됨
Diffusion Probabilistic Models
Density estimation과 sample quality 측면에서 SOTA 성능을 보여준다. 이는 U-Net을 활용하여 '이미지'에 대한 inductive bias를 갖는 특성에서 기인한다. 하지만 픽셀 단위로 훈련 및 평가를 진행하기 때문에 느린 샘플링 속도와 높은 훈련 비용을 피할 수 없다.
이 두 가지 문제점을 모두 해결하기 위해 LDM은 잠재공간을 활용한다.
Two-Stage Image Synthesis
앞서 설명한 다양한 생성 모델들의 단점을 보완하기 위해 2-stage 모델 구조를 적용시킨 연구들도 많았다. 대표적으로 VQ-VAE, VQ-GAN 등이 있다.
VQ-VAE는 일반적인 오토인코더 구조를 따르지만, 잠재 공간에서 이산적인 코드(quantized code)를 사용해 가장 가까운 벡터로 매핑하는 방식이다. 이는 자연어 모델처럼 학습 가능하므로, text-to-image 등의 task도 수행이 가능해지며 이미지 품질은 크게 개선된다.
VQ-GAN은 여기에 적대적 학습을 추가한 것이다. GAN의 Discriminator 모델을 적용한다.
하지만 이러한 방법들은 trade-off가 명확히 존재했다. 잠재공간으로의 압축률을 낮추면 계산 비용이 증가하고, 압축률을 높이면 품질이 저하되는 trade-off가 발생한다.
반면 본 논문의 LDM은 convolution 구조를 사용해 고차원 잠재 공간에서도 더 완만하게 스케일링이 가능하다. 뿐만 아니라, 압축 수준을 자유롭게 선택 가능하다. 이는 오토인코더가 충분한 정보를 보존하도록 학습하여, diffusion 모델이 불필요한 디테일 복원에 신경 쓰지 않도록 한다고 볼 수 있다.
3. Method
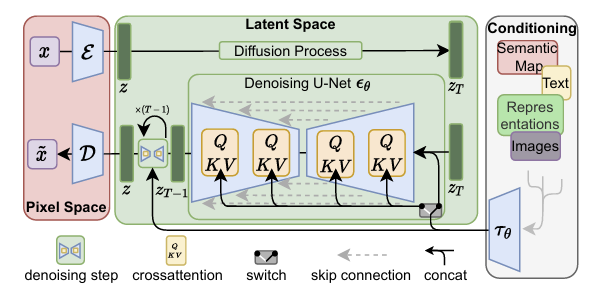 전체 과정은 위 도식과 같다. Encoder와 Decoder가 존재하는 autoencoder로 'perceptually equivalent'한 latent space로 매핑한다. 그 latent space에서 Diffusion 학습을 진행하며, conditioning을 cross attention으로 모델 내부에 적용시킬 수도 있다.
전체 과정은 위 도식과 같다. Encoder와 Decoder가 존재하는 autoencoder로 'perceptually equivalent'한 latent space로 매핑한다. 그 latent space에서 Diffusion 학습을 진행하며, conditioning을 cross attention으로 모델 내부에 적용시킬 수도 있다.
저차원 공간에서 DM을 학습 및 샘플링하기 때문에 계산이 효율적이고, U-Net 기반 모델을 사용하기 때문에 inductive bias를 활용할 수 있다. 뿐만 아니라 한 번 학습된 잠재 공간을 다양한 task에 적용할 수 있다.
3-1. Perceptual Image Compression
Autoencoder의 training function은 다음과 같다.
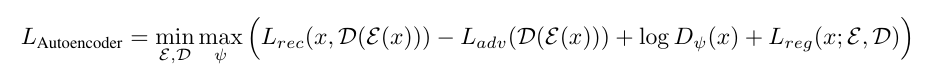
인코더 는 input 를 잠재 표현으로 인코딩하고, 디코더 는 반대로 재구성한다.
이때 인코더의 downsampling factor는 으로 설정한다.
위 식의 두 번째와 세 번째 loss는 GAN의 adverserial loss와 유사하다. 생성된 출력 이 실제와 구별되지 않도록 판별자 를 속이는 것과, 판별자가 실제 데이터 를 판별하는 것을 동시에 학습한다.
또한 잠재 공간에서 분산이 커지는 것을 방지하기 위해 정규화를 추가해주는데, 두 가지 방식으로 실험을 진행했다. 먼저 KL-reg는 VAE와 비슷한 방식으로 잠재 공간 z의 분포를 표준 정규 분포 )에 가깝게 만든다.
두 번째 방식은 VQ-reg로 디코더 안에 vector quantization을 적용한다. VQGAN과 비슷한 방식이다. 잠재 공간 z를 이산적인 코드북으로 양자화하여 정규화하고, 그 과정에서 발생한 손실을 로 정의한다.
또한 본 연구에서 LDM은 latent space를 1차원이 아닌 2차원 구조로 설계하여 우수한 reconstruction 성능을 보여준다.
3-2. Latent Diffusion Models
DDPM에서는 픽셀 단위로 노이즈를 예측하지만, (자세한 내용은 DDPM 포스트) LDM에서는 latent embedding 를 입력으로 받는다. 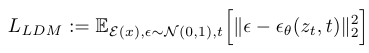
3-3. Conditioning Mechanisms
LDM에는 다양한 condition을 입력으로 넣어줄 수 있다. Cross-attention을 활용하여 유연한 conditioning이 가능하다. 이제 domain-specific한 encoder 로 텍스트, semantic map 등을 project하여 U-Net에 매핑시키면 된다.
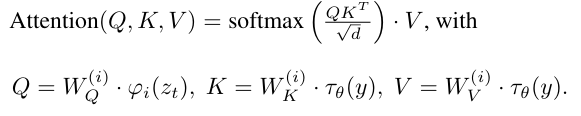 흔히 보는 cross-attention 수식이며, conditioning 정보 는 인코더에 넣은 뒤 K와 V에 적용시킨다.
흔히 보는 cross-attention 수식이며, conditioning 정보 는 인코더에 넣은 뒤 K와 V에 적용시킨다.
최종적으로 아래의 목적함수를 이용해 와 를 동시에 최적화한다.
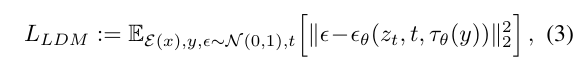
4. Experiments
 먼저 VQ-정규화 방식이 KL-정규화 방식에 비해 때때로 나은 샘플 품질을 보인다고 한다.
먼저 VQ-정규화 방식이 KL-정규화 방식에 비해 때때로 나은 샘플 품질을 보인다고 한다.
4-1. On Perceptual Compression Tradeoffs
{1, 2, 4, 8, 16, 32}의 다양한 downsampling factor에 따라 성능을 비교해본다. 참고로 factor 1일 때는 그냥 pixel DM이라 생각하면 된다.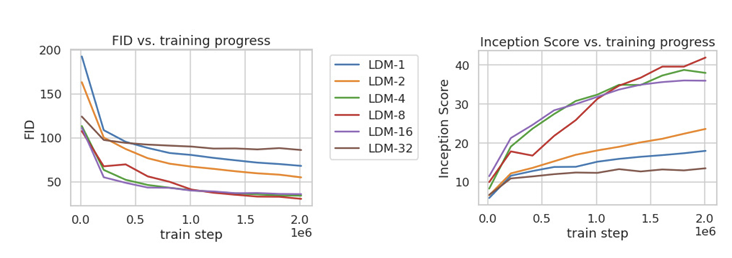 Factor가 너무 작을 경우 학습이 느리고, 너무 클 경우 성능 개선이 정체되는 현상이 나타난다. 따라서 LDM-{4-16}이 품질과 속도 사이 적절한 균형을 유지한다고 한다.
Factor가 너무 작을 경우 학습이 느리고, 너무 클 경우 성능 개선이 정체되는 현상이 나타난다. 따라서 LDM-{4-16}이 품질과 속도 사이 적절한 균형을 유지한다고 한다.
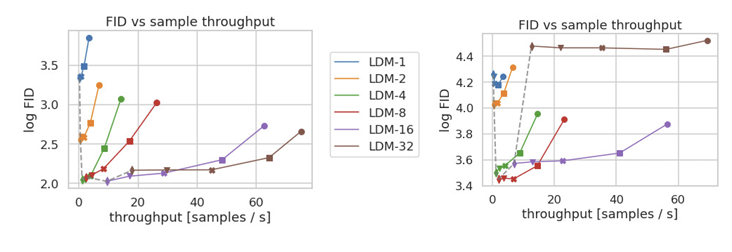 CelebA (왼쪽), ImageNet (오른쪽) 데이터셋에서 각각 학습 속도와 성능을 비교하였다. 여기서도 LDM-4, LDM-8이 가장 적절하다는 것을 알 수 있다.
CelebA (왼쪽), ImageNet (오른쪽) 데이터셋에서 각각 학습 속도와 성능을 비교하였다. 여기서도 LDM-4, LDM-8이 가장 적절하다는 것을 알 수 있다.
4-2. Image Generation
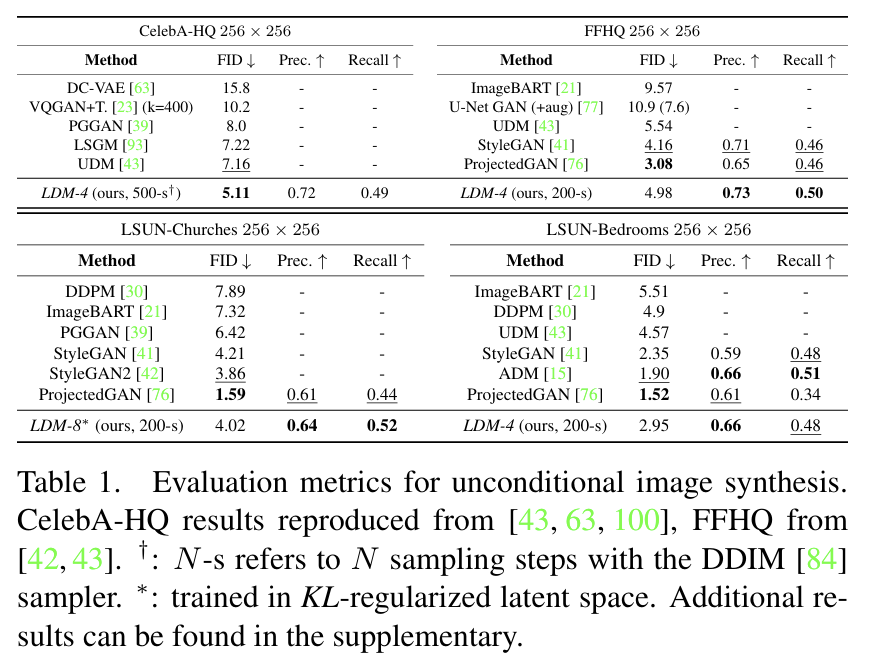
4가지 데이터셋에 대해 이미지 생성 결과를 보여준다. CelebA의 경우 SOTA를 달성하였으며, 다른 데이터셋에 대해서도 기존 DM보다 성능은 좋고 파라미터는 적다. 또한, GAN에 비해 precision과 recall이 높은 것으로 보아 mode 문제를 해결하였다는 것을 알 수 있다.
4-3. Conditional Latent Diffusion
Conditional LDM으로 text-to-image를 수행한 결과는 다음과 같다. Conditional LDM은 text가 아닌 condition도 입력받을 수 있다. 여기서는 layout 정보를 conditioning 한 결과다.
Conditional LDM은 text가 아닌 condition도 입력받을 수 있다. 여기서는 layout 정보를 conditioning 한 결과다.  또한 다음과 같이 학습 시 ()보다 큰 이미지 생성에도 잘 활용될 수 있다.
또한 다음과 같이 학습 시 ()보다 큰 이미지 생성에도 잘 활용될 수 있다.

4-4. Super-Resolution
Super resolution 실행한 결과는 다음과 같다.
 기존의 SR3 모델보다 좀 더 사실적인 이미지로 복원한다고 한다.
기존의 SR3 모델보다 좀 더 사실적인 이미지로 복원한다고 한다.
4-5. Impainting
마지막으로 impainting task에서 LDM을 다른 모델들과 비교한다.
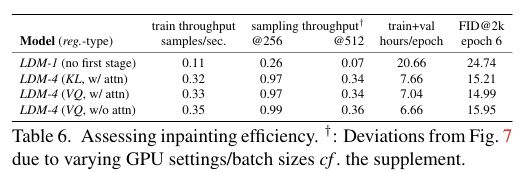 픽셀 기반 DM에 비해 2.7배 이상 빠르면서 FID score는 1.6배 이상 높다고 한다!
픽셀 기반 DM에 비해 2.7배 이상 빠르면서 FID score는 1.6배 이상 높다고 한다!
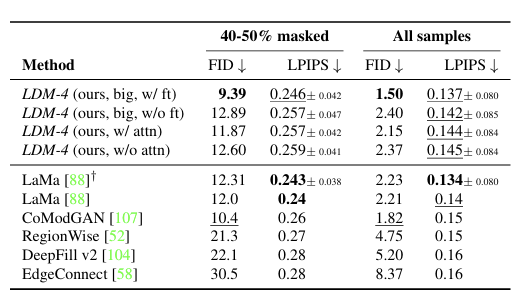
여기서 좀 더 큰 모델 (big)을 사용하고 fine tuning (w/ ft)을 더해주었을 때 SOTA를 달성한다고 한다.

5. Limitations & Societal Impact
- Limitations : 픽셀 기반 모델에 비해 빠르긴하지만, 여전히 GAN에 비해서는 느리다. 또한 높은 정밀도를 요구하는 작업에는 적합하지 않을 수 있다.
- Societal Impact : 훈련 및 샘플링 비용을 크게 낮췄기 때문에 많은 사람들이 손쉽게 사용할 수 있다. 하지만 그만큼 악용, 조작 등의 문제가 발생할 수 있고 개인정보 침해, 편향 등 윤리적 문제도 고려해야 할 것이다.
모델 구현
tbd
마무리
Stable Diffusion은 지금까지 배워온 다양한 생성 모델들을 총망라한듯한 느낌이었다. VAE, GAN, DDPM 등 각각의 장단점을 파악하고 활용한 점이 인상 깊었다. 다만 생성 모델 시리즈는 아마 여기서 마무리할 것 같다.
최근에는 self-attention 대신 diffusion을 기반으로 하는 LLM 연구도 등장하고 있는데, 요쪽을 한 번 살펴보겠다. 부족한 글 읽어주셔서 감사합니다...
참고 자료
Rombach, et al., "High-Resolution Image Synthesis with Latent Diffusion Models", 2022.
