DDPM에 이어 생성 ai 시리즈 네번째 모델, DDIM을 알아보겠다. DDPM이 획기적이긴 하지만, GAN 등의 방법에 비해 생성 속도가 너무 느리다고 알려져 있다. 그렇기에 실제로 코드로 구현하고 생성 작업을 할 때는 DDIM이 더 많이 쓰인다고 한다. DDPM의 수식을 약간 변형시키는 것만으로 샘플링 과정의 속도를 놀라울 정도로 개선한다. 이전 포스트와 마찬가지로 수식 위주로 살펴보자...
논문 링크
0. Abstract
 DDPM은 GAN 류의 방식을 사용하지 않고 고품질 이미지 생성이 가능한 획기적인 모델이었다. 하지만, 근본적으로 markov chain 성질에 의존하기 때문에 샘플링 시 (이미지 생성 시) 시간이 너무 오래걸린다는 치명적인 단점이 존재한다. DDIM은 이를 non-Markovian 과정으로 변형한다. 기존과 loss function은 동일하지만, stochastic한 과정을 deterministic하게 바꾸었기 때문에 같은 품질의 이미지를 훨씬 적은 스텝만으로도 생성이 가능해진다.
DDPM은 GAN 류의 방식을 사용하지 않고 고품질 이미지 생성이 가능한 획기적인 모델이었다. 하지만, 근본적으로 markov chain 성질에 의존하기 때문에 샘플링 시 (이미지 생성 시) 시간이 너무 오래걸린다는 치명적인 단점이 존재한다. DDIM은 이를 non-Markovian 과정으로 변형한다. 기존과 loss function은 동일하지만, stochastic한 과정을 deterministic하게 바꾸었기 때문에 같은 품질의 이미지를 훨씬 적은 스텝만으로도 생성이 가능해진다.
뿐만 아니라, DDPM과 달리 interpolation시 의미론적인 해석이 가능하며, image encoding (latent space로 매핑)도 잘 된다.
1. Introduction
생성 모델 분야에서는 GAN 등의 적대 신경망 모델이 확실히 좋은 품질의 샘플 생성이 가능했다. 시간이 좀 지나면서 DDPM, NCSN 등 adversarial training을 하지 않고도 비슷한 성능을 내는 모델들이 등장했다.
하지만 이러한 디퓨전 모델들은 고품질의 샘플을 생성하기 위해 많은 iteration을 거쳐야 했기에 속도가 너무 느리다. Markov chain의 특성상 샘플링 시 매 단계마다 stochastic한 과정이 포함되며, 특히 DDPM은 1000 스텝을 거쳐야 한다.
따라서 본 논문에서는 DDPM의 수식을 약간 변형하고 재해석하는 것으로 샘플링 시간을 비약적으로 단축한다. Diffusion process를 non-Markovian 하게 변형하면서도 훈련 시 사용하는 function은 변하지 않음을 보인다. 이게 얼마나 대단한 것이냐면, 일단 non-Markovian 하기 때문에 stochastic한 과정이 deterministic하게 바뀐다. 이러면 샘플링 시 몇 단계씩 건너뛰는게 가능해져 시간이 엄청 단축된다. 그러면서도 loss function은 그대로기 때문에 새롭게 모델을 훈련할 필요 없이 기존 diffusion 모델을 쓸 수 있다. 그냥 샘플링 시에만 변화를 주는 것이다.
DDIM의 장점은 3가지로 제시하는데, 먼저 이미지 생성 시 DDPM 보다 약 10배에서 100배 빠르다. 또한, DDPM과 달리 '일관성'이 보장되어, 같은 latent space에서는 일관된 샘플이 생성된다. 마지막으로 interpolation 시 sematically meaningful하다. 역시 stochastic한 생성 과정이 사라지기 때문이다.
2. Background (DDPM 설명)
DDPM에 대한 간략한 설명 부분인데, 그냥 이 글을 보고 오는게 나을듯 하다.
주의할 점은 원본 DDPM에서 사용하는 기호와 이 논문에서 사용하는 기호가 약간 다른데, 이 포스트에서는 DDPM 쪽에 맞추겠다. 여기서 는 DDPM의 를 의미한다.
일단 최종 loss function은 다음과 같다. DDPM에서 많이 봤을 수식이다.
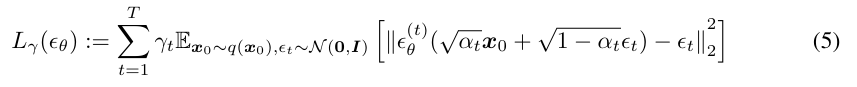 여기서 coefficient 로 고정된 것이 DDPM의 인 것이다.
여기서 coefficient 로 고정된 것이 DDPM의 인 것이다.
원본 DDPM 논문에서는 명시적으로 설명하지 않은 부분이 있어 미리 짚고 넘어가겠다. Reverse process에서 구체적으로 어떤 일이 일어나나면, 우선 latent variable 에서 시작하여 학습된 네트워크 를 이용해 을 추정한다. 이를 기반으로 에서 을 샘플링하고, 다시 반복하여 최종적으로 까지 도달한다. 아래 두 과정이 순차적으로 한 스텝 씩 반복되는 것이다.
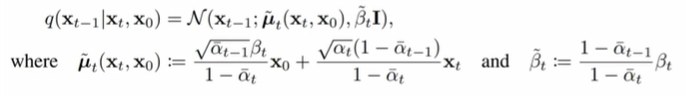
샘플링 시 DDPM은 총 T step을 거치는데, 이는 앞서 설명했듯 sequential하게 진행된다. Markovian 성질로 인해 특정 시점 은 에 의존하기 때문이다.
이는 결국 병렬처리가 불가능하기 때문에 다른 딥러닝 모델보다 지나치게 느리다.
3. Variational Inference for Non-Markovian Forward Processes
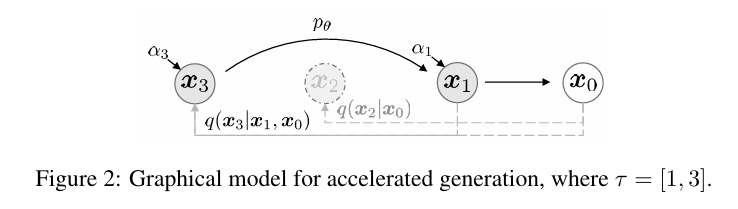
 DDPM과 DDIM의 차이를 가장 잘 보여주는 그림이다. 전자는 markovian 한 성질을 갖지만, 후자를 보면 직전 상태 뿐만 아니라 에도 의존하기 때문에 non-markovian하다.
DDPM과 DDIM의 차이를 가장 잘 보여주는 그림이다. 전자는 markovian 한 성질을 갖지만, 후자를 보면 직전 상태 뿐만 아니라 에도 의존하기 때문에 non-markovian하다.
3-1. Non-Markovian Forward Process
우선 아래는 DDPM에서 나온 forward process 식이다. 안에 markovian하게 정의된 것을 볼 수 있다.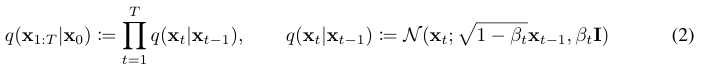 이걸 DDIM에서는 아래와 같이 non-markovian하게 변형한다.
이걸 DDIM에서는 아래와 같이 non-markovian하게 변형한다.
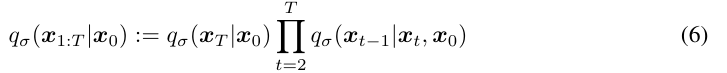 베이즈 정리를 사용하면 쉽게 증명이 가능하다.
베이즈 정리를 사용하면 쉽게 증명이 가능하다.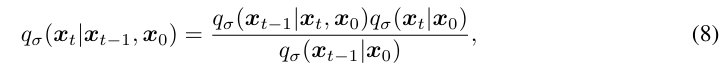 그리고 DDPM에서처럼 분포로 표현할 수 있는데, 증명 과정은 아래에 써놓겠다.
그리고 DDPM에서처럼 분포로 표현할 수 있는데, 증명 과정은 아래에 써놓겠다.
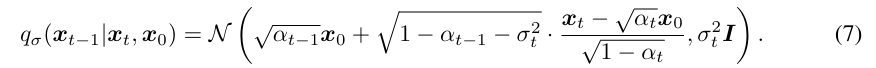 참고로 여기서 모든 는 를 의미한다.
참고로 여기서 모든 는 를 의미한다.
이제 베이즈 정리 (8번 수식)를 이용하면 우리는 가 와 에 의존하는 non-markovian forward process를 최종적으로 얻을 수 있다!
증명과정 (7번 수식)
Bishop의 PRML에 나와있는 정리를 사용했다고 한다.
 먼저 분포의 평균 부분이다. 2.115번 정리를 이용하면, 임의의 상수 C (행렬 A 부분) 를 둘 수 있다.
먼저 분포의 평균 부분이다. 2.115번 정리를 이용하면, 임의의 상수 C (행렬 A 부분) 를 둘 수 있다. 다음으로 분산 부분인데, 이 역시 같은 정리를 활용한다. 구하고자하는 분포의 분산을 로 두어 C를 정리 할 수 있다.
다음으로 분산 부분인데, 이 역시 같은 정리를 활용한다. 구하고자하는 분포의 분산을 로 두어 C를 정리 할 수 있다.
 구한 분포를 이용해서 를 한 번 다시 구해보면,
구한 분포를 이용해서 를 한 번 다시 구해보면,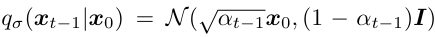 변형 과정에 문제 없음을 확인할 수 있다.
변형 과정에 문제 없음을 확인할 수 있다.
3-2. Generative Process and Unified Variational Inference Objective
 처음에 설명한 DDPM의 샘플링 과정과 같은 방식으로 진행한다. 다만 이제 non-markovian하게 바뀐 것 뿐이다.
처음에 설명한 DDPM의 샘플링 과정과 같은 방식으로 진행한다. 다만 이제 non-markovian하게 바뀐 것 뿐이다.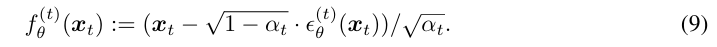 먼저 훈련된 모델 을 통해 에서 를 예측한다 (함수 ).
먼저 훈련된 모델 을 통해 에서 를 예측한다 (함수 ).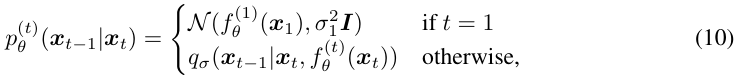 그러면 이제 자리에 예측값을 넣어주고 을 샘플링하는 reverse process가 진행된다.
그러면 이제 자리에 예측값을 넣어주고 을 샘플링하는 reverse process가 진행된다.
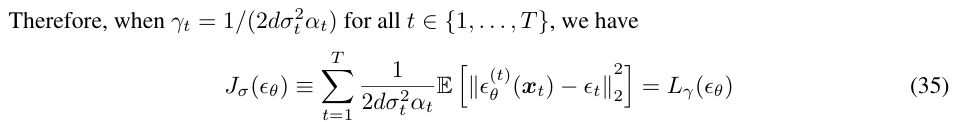
결국 우리가 DDPM에서 볼 수 있던 똑같은 loss function (을 사용하여 를 학습할 수 있고, 마찬가지로 대신 노이즈 의 term으로 바꾸어 모델을 정의한다.
4. Sampling Process
학습을 마친 뒤, 이제 실제로 이미지를 생성 (sampling)할 때를 알아보자. DDPM과 DDIM의 training objective가 같은 것을 확인했으므로, pretrained DDPM에 새로운 generative process를 적용하면 된다. 핵심은 분포의 표준편차 를 조정하는 것에 있다.
4-1. DDIM
10번 수식에서 을 샘플링하면 다음과 같이 나타낼 수 있다: (reparameterization trick)
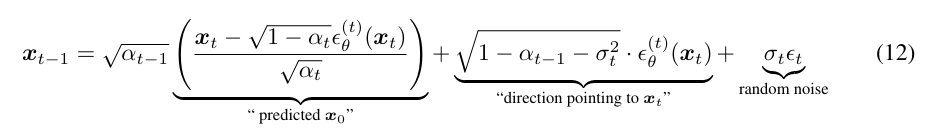 는 를 따르는 가우시안 노이즈이며, t 마다 샘플링을 하기 때문에 stochastic한 요소다.
는 를 따르는 가우시안 노이즈이며, t 마다 샘플링을 하기 때문에 stochastic한 요소다.
이제 여기서 의 값에 따라 큰 차이가 존재한다. 모든 시점 t에 대해 으로 둔다면, 샘플링시 stochastic한 과정이 사라져 이 과정이 deterministic 해진다. Implicit probabilistic model이 되는 것이다. 그래서 바로 이 경우를 DDIM이라고 하는 것이다!
참고로 일 때가 DDPM이다. 가 살아있기 때문에 stochastic한 것이다.
4-2. Accelerated Generation Processes
DDIM에서도 여전히 한 단계씩 모든 t에 대해 샘플링하기에 느린거 아닌가? 라는 생각이 들 수 있다. 원래 forward process가 T step이면 reverse process도 T step이 필요하다. 하지만 이제 더 이상 forward process에 의존적이지 않으므로 T 보다 작은 step도 고려 가능하다.
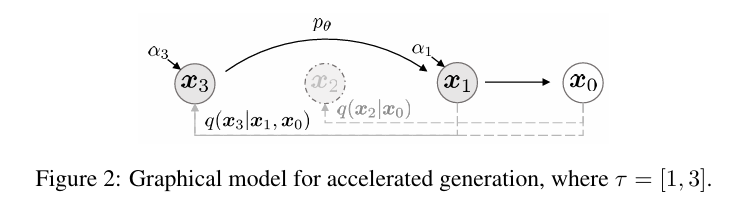 의 sub-sequence를 로 두어 총 길이 S의 subset 를 정의하자. 이제 생성 단계에서는 이 새로운 sampling trajectory에 맞춰 sampling을 한다. 원래 step T 보다 작으므로, 생성 속도가 빨라지는 것이다.
의 sub-sequence를 로 두어 총 길이 S의 subset 를 정의하자. 이제 생성 단계에서는 이 새로운 sampling trajectory에 맞춰 sampling을 한다. 원래 step T 보다 작으므로, 생성 속도가 빨라지는 것이다.
4-3. Relevance to Neural ODEs
이처럼 determistic한 DDIM 샘플링 과정은 ODE로 해석이 가능하다. 오일러 방법론을 활용하여 연속적인 ODE 형태로 풀면 다음과 같다.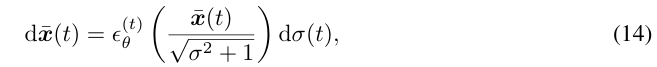
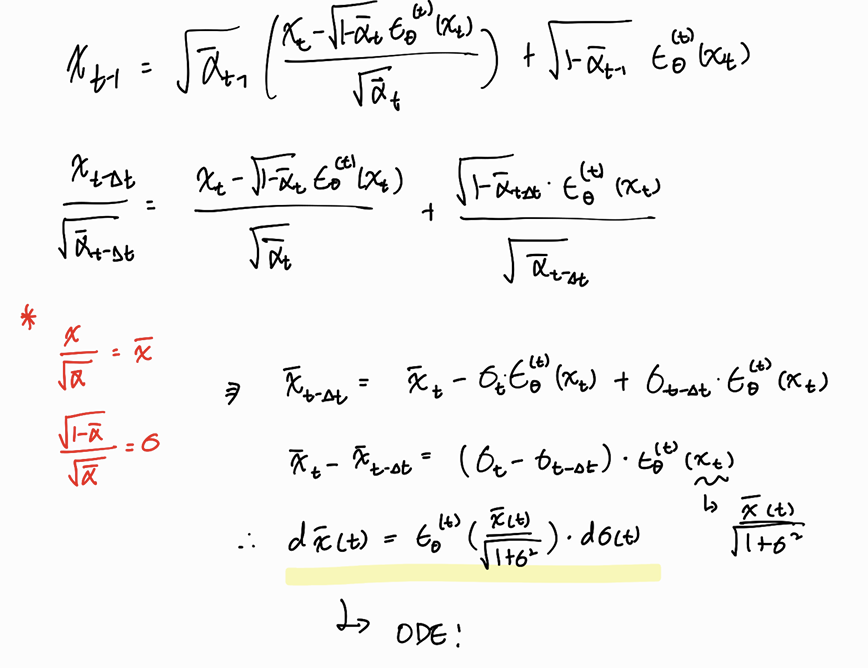 이게 왜 의미가 있냐하면, t에서 t-1로 가는 이산적인 과정이 linearize될 수 있고, 생성과정을 reverse할 수 있게 된다. 즉, ->, 이미지를 latent space에 encoding이 가능하다.
이게 왜 의미가 있냐하면, t에서 t-1로 가는 이산적인 과정이 linearize될 수 있고, 생성과정을 reverse할 수 있게 된다. 즉, ->, 이미지를 latent space에 encoding이 가능하다.
아래 실험에서 알아보겠지만, DDIM의 결정론적 특성 덕분에 같은 latent에서는 같은 이미지가 나오게 되고, 이를 통해 interpolation, image encoding이 가능하다.
5. Experiments
세 가지 실험 결과를 보이는데, 먼저 DDPM보다 월등히 뛰어난 속도이다. 또한, 초기 latent 를 고정한 상태에서는 high-level feature가 일관적이다. 이를 통해 semantic interpolation도 가능하다. 마지막으로, DDPM과 달리 stochastic하지 않기 때문에 sample encoding이 가능하다.
5-1. Sample Quality and Efficiency
로 스텝 수를 조정하고, 로 stochastic 정도를 조절한다. 즉 여기서 이면 DDIM, 이면 DDPM, 그 사이면 interpolation이다.
 추가적으로 값이 보다 큰 경우도 테스트해본다.
추가적으로 값이 보다 큰 경우도 테스트해본다.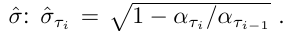
결과는 다음과 같다. DDIM은 스텝 수가 적을 때도 성능이 잘 유지되는 모습을 보인다.
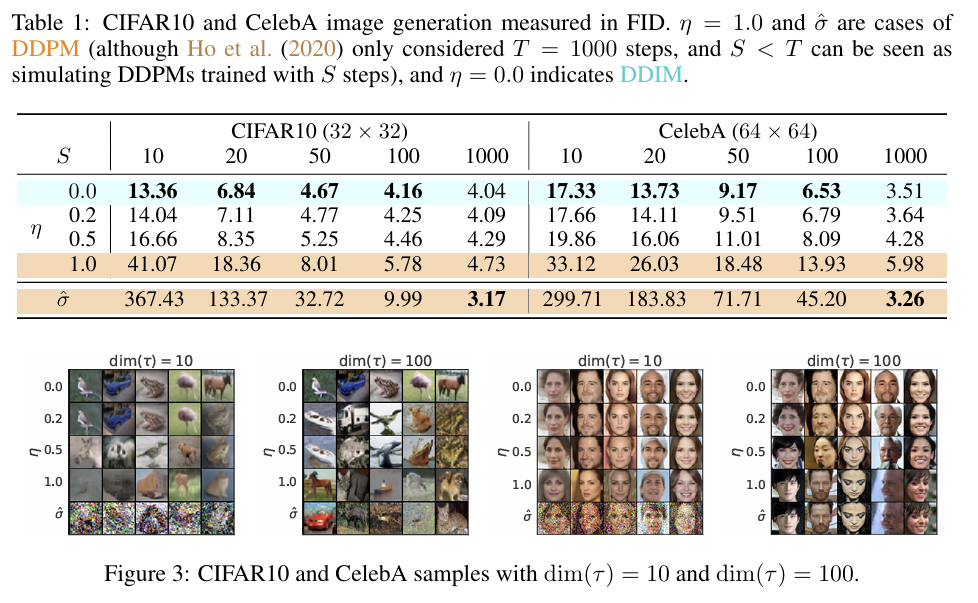 놀랍게도 DDIM은 단 20~100 step으로 DDPM이 1000 step에 걸쳐 생성한 이미지와 비슷한 품질을 낸다. DDPM보다 10~50배 빠르다 볼 수 있다!
놀랍게도 DDIM은 단 20~100 step으로 DDPM이 1000 step에 걸쳐 생성한 이미지와 비슷한 품질을 낸다. DDPM보다 10~50배 빠르다 볼 수 있다!
5-2. Sample Consistency
DDIM은 결정론적이다. 그렇기에 같은 초기 latent 상태 에 대해서는 유사한 을 생성하지 않을까?
 같은 에 대해 관계없이 유사한 feature가 나온다는 점을 볼 수 있다!
같은 에 대해 관계없이 유사한 feature가 나온다는 점을 볼 수 있다!
5-3. Interpolation
High-level feature가 로 인코딩될 수 있다는 점은, 상태에서 샘플들 간 interpolation이 가능하다는 것을 암시한다.
 DDPM에서와 달리 '의미론적인' (semantically meaningful) interpolation이 가능하다!
DDPM에서와 달리 '의미론적인' (semantically meaningful) interpolation이 가능하다!
5-4. Reconstruction from Latent Space
마지막으로 이미지 encoding과 재구성에 대해 실험한 결과다. 앞서 설명했듯 DDIM은 ODE로 Euler integration하므로, 에서 로 encoding하고 다시 으로 재구성이 가능하다 (DDPM에서는 불가능).
 결과를 보면 Neural ODE와 normalizing flow와 마찬가지로 S가 클 때 더 낮은 error를 보인다.
결과를 보면 Neural ODE와 normalizing flow와 마찬가지로 S가 클 때 더 낮은 error를 보인다.
모델 구현
이제 DDIM을 실제로 구현해보겠다. 계속 강조했듯이, DDIM의 loss는 DDPM과 수식적으로 같기 때문에 새로운 훈련 과정은 필요없다. 따라서 저번 포스트에서 훈련한 DDPM 모델을 그대로 사용할 것이다. 여기서는 DDIM에 맞는 새로운 sampling function만 구현하면 된다!
전체 코드는 깃허브 참조.
논문의 수식을 그대로 따라가면 된다. 에 따라 time step을 정확히 설정하는 것이 중요하다.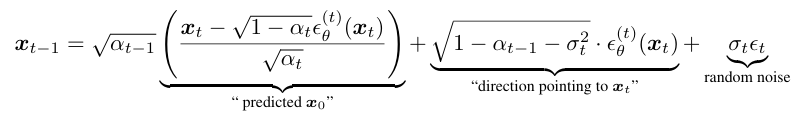
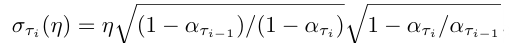
T_steps = 1000
beta = torch.linspace(1e-4, 0.02, T_steps).to(device)
alpha = 1. - beta
alpha_bar = torch.cumprod(alpha, dim=0)
alpha_bar_prev = torch.cat([torch.tensor([1.0], device=device), alpha_bar[:-1]])
# DDIM Sampling
def fast_sample(model, x_T, steps, eta=0.0):
tau_steps = np.linspace(0, T_steps - 1, steps, dtype=int) # smaller sampling trajectory length
# match with new sampling steps
ddim_alpha = alpha_bar[tau_steps]
ddim_alpha_prev = torch.cat([torch.tensor([1.0], device=device), alpha_bar[tau_steps[:-1]]])
ddim_sigma = eta * ((1 - ddim_alpha_prev) / (1 - ddim_alpha) * (1 - ddim_alpha / ddim_alpha_prev))**0.5
x_t = x_T
for step in reversed(range(len(tau_steps))):
t = torch.full((x_T.shape[0],), tau_steps[step], device=device, dtype=torch.long)
eps_theta = model(x_t, t)
sigma = ddim_sigma[step]
eps = torch.randn_like(x_t) if step > 0 else 0
pred_x0 = (x_t - (1 - ddim_alpha[step])**0.5 * eps_theta) / (ddim_alpha[step]**0.5)
dir_xt = (1 - ddim_alpha_prev[step] - sigma**2)**0.5 * eps_theta
noise = sigma * eps
x_t = ddim_alpha_prev[step]**0.5 * pred_x0 + dir_xt + noise # sample x_{t-1}
x_0 = x_t
return x_0
DDPM 구현 시 사전 훈련된 U-Net을 그대로 사용하고, 1000개의 이미지를 샘플링해본다. 이때 50 step만 사용해 샘플링을 가속화시키고, 으로 두어 순수한 DDIM 환경으로 설정한다.
## Use same model
DDIM_model = UNet(n_channels=32).to(device)
DDIM_model.load_state_dict(torch.load('/content/drive/MyDrive/Colab Notebooks/results/ddpm_model.pth'))
## Check inference time for 1000 samples
start_time = time.time()
with torch.no_grad():
x_T = torch.randn(1000, 3, 32, 32).to(device)
x_0 = fast_sample(DDIM_model, x_T, steps=50, eta=0.0)
x_0 = x_0.permute(0, 2, 3, 1).clamp(0, 1).detach().cpu().numpy() * 255
for i in range(5):
cv2_imshow(x_0[i])
end_time = time.time()
elapsed_time = end_time - start_time
min, sec = divmod(elapsed_time, 60)
print(f"Inference Time: {int(min)}m {sec:.2f}s")



 DDPM으로 생성한 이미지와 그렇게 큰 차이는 없어보인다.
DDPM으로 생성한 이미지와 그렇게 큰 차이는 없어보인다.
하지만, 속도가 매우 빠르다. DDPM에서는 1000장 생성에 7분 30초 가량 소요됐지만, DDIM에서는 단 23초 만에 끝난다. 이는 엄청난 속도 개선이다.
마지막으로, 5-2에서 알아본 sample consistency 특성을 실제로 검증해보았다. 같은 초기 상태 에 대해 같은 모델로 3번 생성해볼 것이다. 먼저 DDPM은 다음과 같다.
# Sample an image 3 times (DDPM)
with torch.no_grad():
x_T = torch.randn(1, 3, 32, 32).to(device) # initial latent space
for i in range(3):
print(f"DDPM Generation {i+1}:")
x_0 = sample(DDPM_model, x_T)
x_0 = x_0.permute(0, 2, 3, 1).clamp(0, 1).detach().cpu().numpy() * 255
cv2_imshow(x_0[0])
print("Generation completed.")

 이처럼 매번 다른 최종 이미지가 생성된다. DDPM은 stochastic하기 때문이다.
이처럼 매번 다른 최종 이미지가 생성된다. DDPM은 stochastic하기 때문이다.
반면 완전히 deterministic한 상태의 DDIM은 3번 모두 같은 최종 이미지를 생성한다. 물론 를 조정해 stochastic 성질을 더해주면 다른 결과가 나온다.
# Sample an image 3 times (DDIM)
with torch.no_grad():
x_T = torch.randn(1, 3, 32, 32).to(device) # initial latent space
for i in range(3):
print(f"DDIM Generation {i+1}:")
x_0 = fast_sample(DDIM_model, x_T, steps=100, eta=0.0)
x_0 = x_0.permute(0, 2, 3, 1).clamp(0, 1).detach().cpu().numpy() * 255
cv2_imshow(x_0[0])
print("Generation completed.")



상세 코드: https://github.com/tony3ynot/DDPM_and_DDIM
마무리
수식 정리하느라 정말 힘들었다;; 그치만 정리하고 나니깐 왜 DDIM을 더 많이 쓰는지 알 것 같다. 실제로 테스트해봤을 때도 훨씬 빠르다.
Neural ODE도 개념만 들어봐서 이번에 거의 처음으로 알아보게 됐는데, 상당히 흥미로운 분야인 것 같다. 추후에 자세히 알아보도록 하겠다.
참고 자료
Song, et al., "Denoising Diffusion Implicit Models", 2022.
