[논문 리뷰] CLIP (Learning Transferable Visual Models From Natural Language Supervision)

2021년 OpenAI에서 발표한 CLIP이라는 모델에 대해 알아보자. 이미지와 텍스트 데이터를 동시에 활용하여 representation learning을 하는 방식으로, 멀티모달 모델 분야에서 매우 중요하게 다뤄진다. 또한, zero-shot prediction을 상당히 심도있게 다루어 LLM 모델의 기반을 마련한 것은 물론, 인공지능 기술의 사회적 영향과 올바른 방향성을 제시한 점에서 매우 가치있는 논문이라고 생각한다.
Transformer, ResNet, ViT, constrastive learning을 간단히 알고 있으면 이해하기 좋을 것이다. 모두 필자가 글로 정리해두었다!
논문 링크
0. Abstract
 기존 컴퓨터 비전 모델은 특정 class만 인식하도록 학습되어 다양성, 보편성, 활용성 면에서 아쉬운 점이 있었다. 본 연구는 이미지에 대한 설명을 담은 텍스트 (캡션)를 함께 활용해 학습하는 새로운 방법을 제시한다. 4억 개의 이미지-텍스트 쌍으로 이루어진 데이터셋을 통해 모델을 학습시켜, 기존 방식보다 훨씬 광범위한 시각적 개념을 학습할 수 있도록 한다.
기존 컴퓨터 비전 모델은 특정 class만 인식하도록 학습되어 다양성, 보편성, 활용성 면에서 아쉬운 점이 있었다. 본 연구는 이미지에 대한 설명을 담은 텍스트 (캡션)를 함께 활용해 학습하는 새로운 방법을 제시한다. 4억 개의 이미지-텍스트 쌍으로 이루어진 데이터셋을 통해 모델을 학습시켜, 기존 방식보다 훨씬 광범위한 시각적 개념을 학습할 수 있도록 한다.
결과적으로 CLIP은...
- zero-shot transfer: 별도의 추가 학습 없이도 다양한 종류의 작업에 적용
- 다양한 작업 수행: OCR, 동영상 인식, 위치 정보 파악 등 30가지가 넘는 다양한 컴퓨터 비전 데이터셋에서 성능 입증
- 발군의 성능: 특정 데이터셋에 대한 학습 없이도 기존 'fully supervised model' (특정 데이터셋으로 학습한 모델)과 대등한 성능
등을 보여준다!
1. Introduction
NLP 분야에서는 대규모 웹 텍스트를 활용한 사전 학습 기법이 강력한 성능을 보이며 발전해왔다. Label 없는 대규모 데이터를 효과적으로 학습할 수 있기 때문에, 특히 GPT-3와 같은 모델은 label 없이도 다양한 task에서 높은 성능을 보인다.
반면 컴퓨터 비전 분야에서는 여전히 ImageNet과 같은 수작업 라벨링된 데이터셋을 활용한 지도학습이 주류다. 절대적으로 학습 데이터의 크기가 작기 때문에 '벽'이 존재해왔다. 이에 대해 저자들은 다음과 같은 질문을 던진다.
'Could scalable pre-training methods which learn directly from web text result in a similar breakthrough in computer vision?'
NLP 분야와 마찬가지로, 웹 상에서 수집할 수 있는 대규모 텍스트 데이터로 학습한다면 비전 분야에서도 큰 혁신을 기대해 볼 수 있을 것이다!
이미지와 텍스트 쌍을 활용하여 이미지 표현을 학습하는 과거 연구들은 존재했지만, 성능이 기존 지도학습 모델보다 낮아 실용성이 제한적이었다.
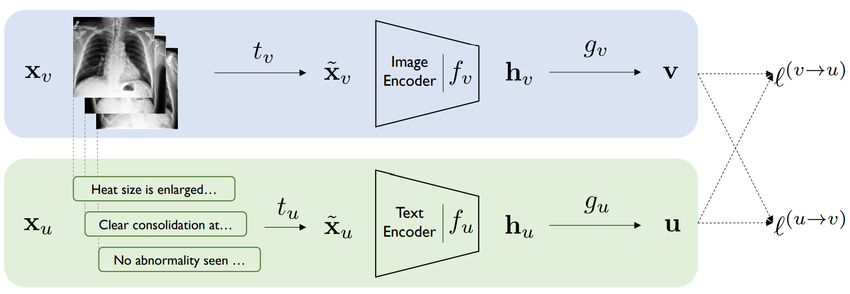 그 중 ConVIRT (Zhang et al., 2020) 는 transformer, masked language modeling, contrastive objectives 등을 활용한 모델로, 본 연구의 중요한 기반이 된다.
그 중 ConVIRT (Zhang et al., 2020) 는 transformer, masked language modeling, contrastive objectives 등을 활용한 모델로, 본 연구의 중요한 기반이 된다.
따라서 저자들은 4억 개의 (이미지, 텍스트) 쌍으로 구성된 새로운 데이터셋을 만들고, Contrastive Language-Image Pre-training (CLIP)이라는 모델을 제시한다.
본 연구에서는:
1) zero-shot CLIP의 높은 성능
2) ImageNet SOTA 모델을 뛰어넘는 성능과 계산 효율성
3) zero-shot CLIP의 높은 강건성 (robustness)
4) 윤리적, 법적 영향
등을 제시한다.
2. Approach
2-1. Natural Language Supervision
CLIP의 핵심은 자연어를 이미지 학습의 'supervision'으로 사용하는 것에 주목한다. 자연어를 이용한 학습은 몇몇 이점이 있다.
먼저 인터넷에서 굉장히 많은 양의 텍스트를 얻을 수 있기 때문에 scale이 가능하다. 또한, 단순히 class를 학습하는 것이 아니라 텍스트로 표현된 자연어를 학습하기 때문에 이미지에 대한 더 깊은 이해를 할 수 있다. 이는 그 전까지 비전 모델에서 보기 어려웠던 zero-shot prediction이 가능해진다는 것을 시사한다.
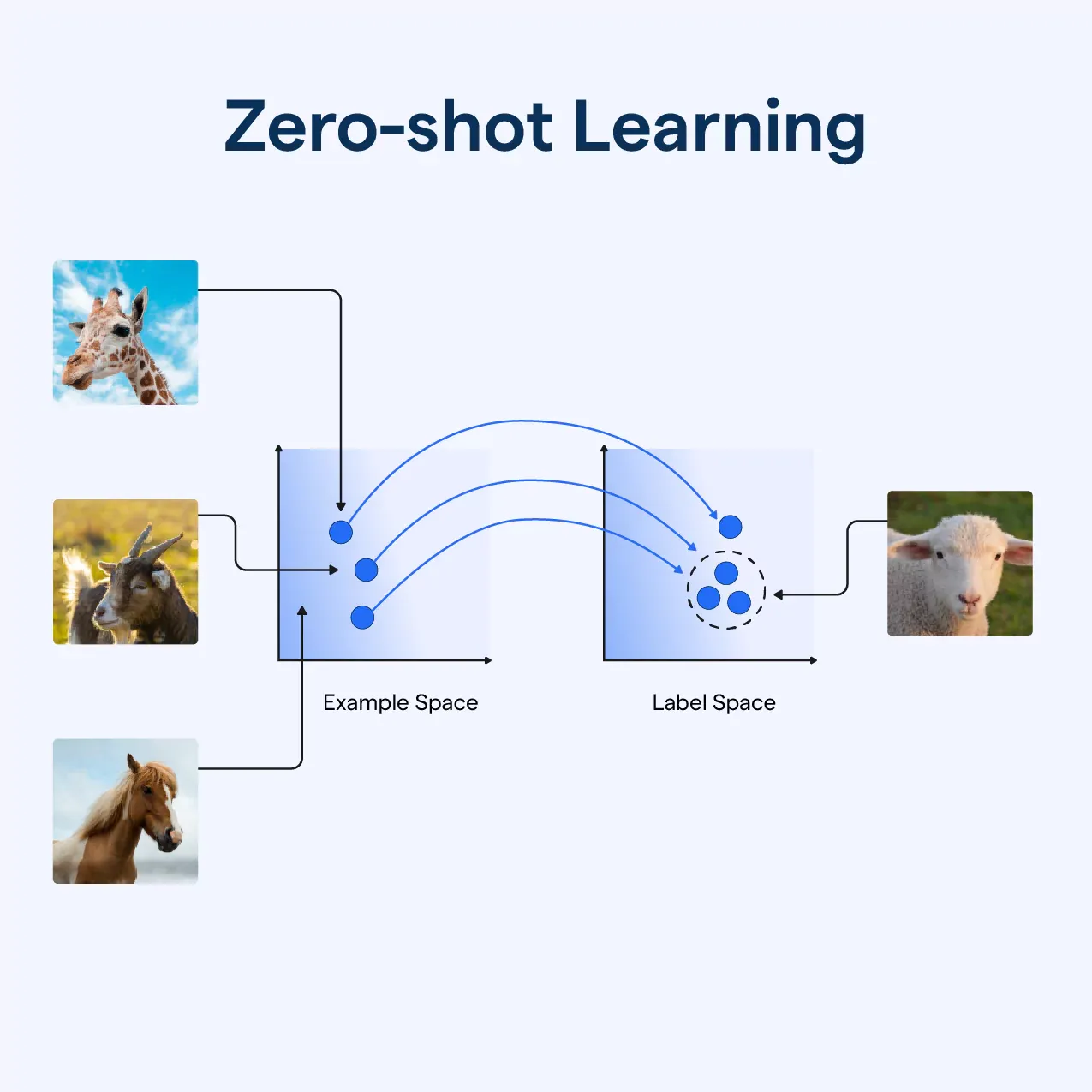
** zero-shot transfer : 학습 과정 중 본 적 없는 데이터의 class도 예측을 할 수 있는 능력
2-2. Dataset
기존에 존재하는 이미지 데이터셋들은 크기, 질 등의 문제로 본 연구에서 활용하기 어려웠다. 따라서 새로운 데이터셋인 WIT (WebImageText)를 제안하는데, 약 4억 개의 (image, text) 쌍으로 구성된 데이터를 인터넷에서 수집하였다. 이미지와 그 설명 캡션을 최대한 다양하게 수집하기 위해 50만 개의 쿼리를 사용했다고 한다.
이미지와 그 설명 캡션을 최대한 다양하게 수집하기 위해 50만 개의 쿼리를 사용했다고 한다.
2-3. Pre-training
CLIP은 굉장히 많은 양의 데이터를 학습하기 때문에, 학습 효율성이 무엇보다 중요하다.
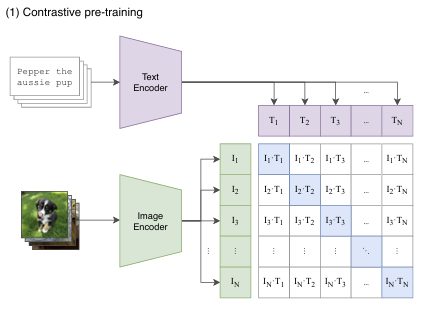 그래서 CLIP에서는 contrastive learning 학습 방식을 사용하는데, self-supervised learning (자기지도 학습) 분야에서 자주 활용되는 방식이다.
그래서 CLIP에서는 contrastive learning 학습 방식을 사용하는데, self-supervised learning (자기지도 학습) 분야에서 자주 활용되는 방식이다.
매칭되는 feature들끼리는 가까워지게 (cosine 유사도 커짐) 학습하는 것으로, 위 그림에서 파란 대각선 부분의 값이 커지게 하는 것이다.
자세한 내용은 이 글을 참고하길 바란다.
그래서 CLIP의 전체 학습 과정을 살펴보면, 먼저 이미지 데이터는 image encoder 모델로, 텍스트 데이터는 text encoder 모델로 넣어주어 각각 feature를 추출한다. 이후 이 두 feature으로 contrastive learning을 진행하면 전체 모델이 학습된다.
아래는 전체 pseudo code이다. 
2-4. Model
CLIP의 image encoder 모델로는 5가지 종류의 ResNet과 3가지 종류의 ViT를 사용하여 비교했다. Text encoder 모델로는 Transformer를 사용했다.
모델 크기를 키우기 위해서 image encoder는 width, depth, resolution을 모두 동일한 정도로 scale 했으며, text encoder는 width만 scale 했다.
3. Experiments
아래는 본 논문에서 CLIP으로 진행한 다양한 실험 결과이다. 핵심적인 부분 위주로 요약하도록 하겠다.
3-1. Zero-Shot Transfer
먼저 계속 강조하는 zero-shot prediction은 대체 어떤 방식으로 진행되는 것인가? ImageNet 데이터셋으로 정해진 class 내에서 학습하는 비전 모델들은 새로운 class를 예측할 수 없었다. 그러나 CLIP은 자연어를 이미지에 대한 학습 정보로 활용하는 방식이기 때문에 아래와 같이 zero-shot prediction이 가능하다!
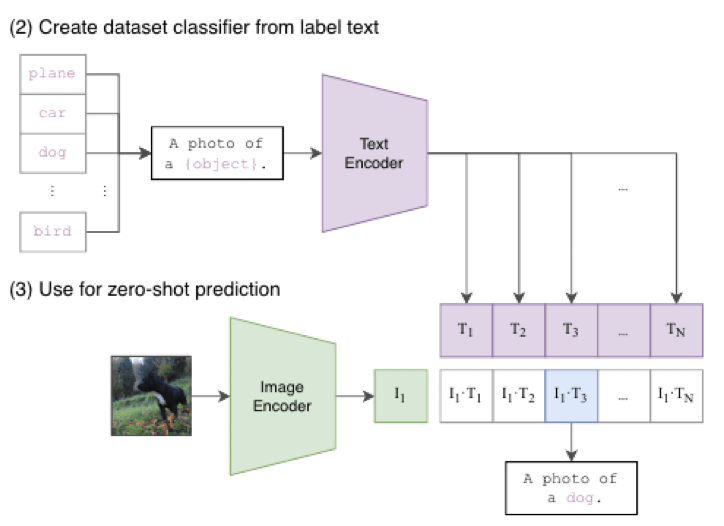 입력 이미지를 encoder에 통과하여 feature를 얻고, 학습된 text encoder에서 나오는 feature과의 cosine 유사도를 계산하여 입력 이미지를 가장 잘 설명하는 text feature를 출력하게 된다.
입력 이미지를 encoder에 통과하여 feature를 얻고, 학습된 text encoder에서 나오는 feature과의 cosine 유사도를 계산하여 입력 이미지를 가장 잘 설명하는 text feature를 출력하게 된다.
여기에 적절한 prompt engineering과 여러 classifier를 ensemble하는 방식을 더하여 zero-shot 성능을 높인다.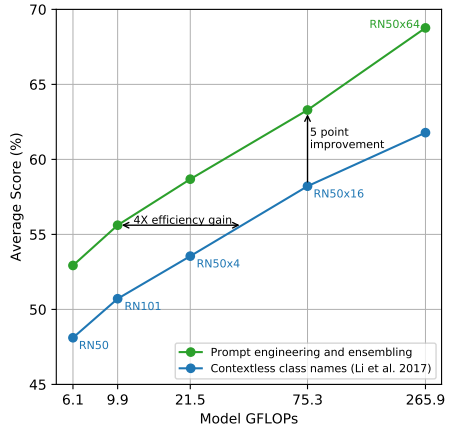
이제 CLIP의 zero-shot 성능을 살펴보자. 아래 그림은 CLIP의 zero-shot prediction 성능과 ResNet50에 각 데이터셋 별로 fine-tuning (linear probe) 한 뒤 성능을 비교한 결과다.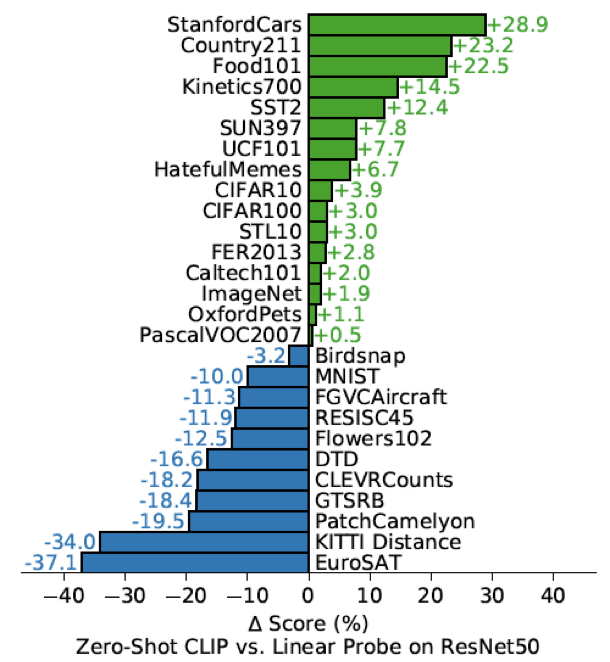 놀랍게도, 각 데이터셋으로 사전학습, fine-tuning을 전혀 하지 않은 zero-shot CLIP이 절반 이상의 경우에서 더 높은 성능을 보인다. 다만 비교적 복잡하거나 추상적인 데이터셋 task에서는 CLIP이 뒤쳐지는 모습을 보인다.
놀랍게도, 각 데이터셋으로 사전학습, fine-tuning을 전혀 하지 않은 zero-shot CLIP이 절반 이상의 경우에서 더 높은 성능을 보인다. 다만 비교적 복잡하거나 추상적인 데이터셋 task에서는 CLIP이 뒤쳐지는 모습을 보인다.
이제 zero-shot CLIP을 다양한 모델들과 비교해보았다. 그 중에는 CLIP에 linear probing을 가한 모델도 있다.
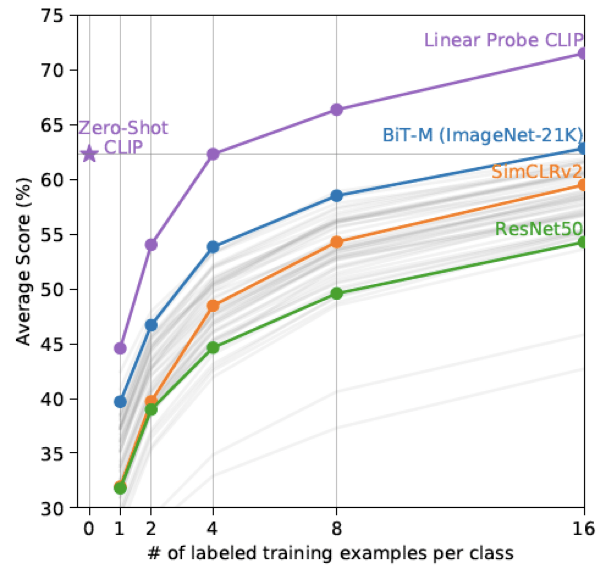 흥미롭게도 zero-shot CLIP이 대부분의 모델들의 성능보다 좋다는 것을 알 수 있다. 심지어 4-shot (클래스 당 4개 데이터 학습) CLIP과 비슷한 수준의 성능을 보인다. 물론 데이터셋별로 차이는 존재하지만, 전반적으로 zero-shot CLIP의 data efficiency가 높다는 것을 시사한다!
흥미롭게도 zero-shot CLIP이 대부분의 모델들의 성능보다 좋다는 것을 알 수 있다. 심지어 4-shot (클래스 당 4개 데이터 학습) CLIP과 비슷한 수준의 성능을 보인다. 물론 데이터셋별로 차이는 존재하지만, 전반적으로 zero-shot CLIP의 data efficiency가 높다는 것을 시사한다!
3-2. Representation Learning
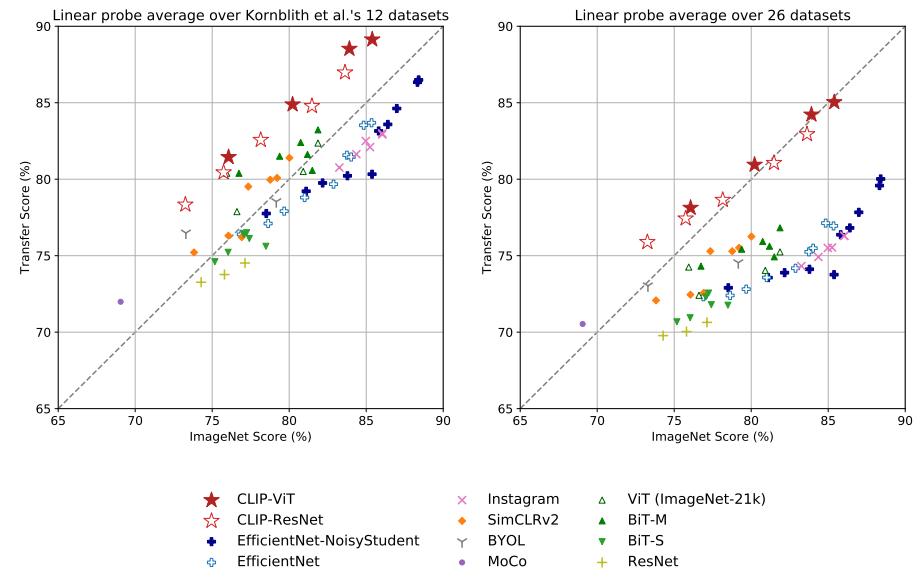
다음은 CLIP 자체가 과연 좋은 표현력을 학습하였는가를 검증해본다. CLIP을 포함한 다양한 모델들의 linear probing 성능을 다양한 데이터셋에 대해 비교했다.
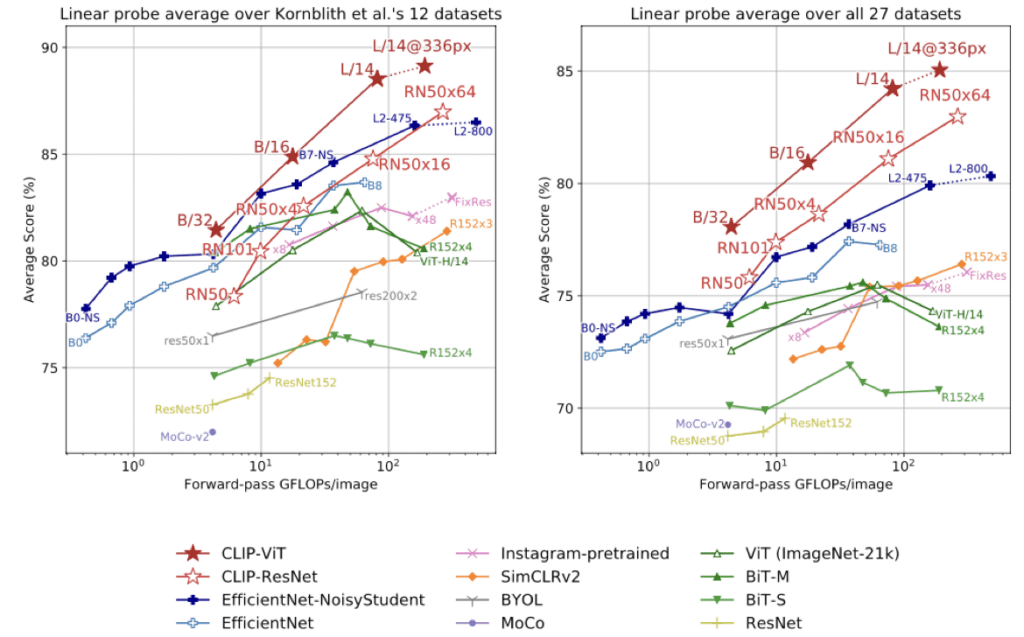 왼쪽은 12가지, 오른쪽은 27가지의 다양한 데이터셋으로 평균적인 성능을 비교한 결과인데, CLIP 모델의 성능이 가장 좋다.
왼쪽은 12가지, 오른쪽은 27가지의 다양한 데이터셋으로 평균적인 성능을 비교한 결과인데, CLIP 모델의 성능이 가장 좋다.
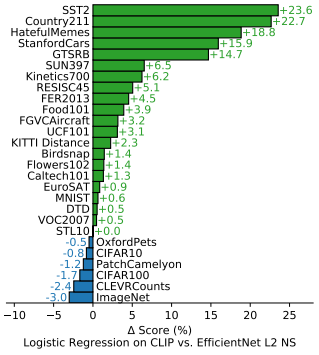 ImageNet SOTA 모델과 비교했을 때, 27개 중 21개 데이터셋에서 더 높은 성능을 보인다.
ImageNet SOTA 모델과 비교했을 때, 27개 중 21개 데이터셋에서 더 높은 성능을 보인다.
특히 OCR, 위치 정보 파악 등의 task에서 큰 성능 향상을 보여준다.
3-3. Robustness
마지막으로 모델의 강건성, 또는 일반화 성능을 실험하였다. 기존 비전 모델들의 한계점은, 데이터셋에 약간 변형이 생기면 성능이 급격하게 떨어진다는 점이다. 저자들은 먼저 task transfer 시의 성능을 체크해본다.
 위 결과와 같이 CLIP 모델은 다른 task에 대해서도 성능을 유지하는 모습이다.
위 결과와 같이 CLIP 모델은 다른 task에 대해서도 성능을 유지하는 모습이다.
다음으로 ImageNet 데이터셋의 분포를 변형 (distribution shift)시켜 이에 대한 다양한 모델들의 성능을 비교한다.
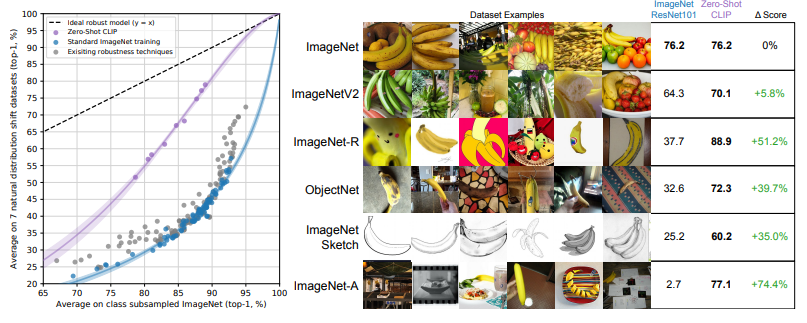 Zero-shot CLIP의 경우 다른 모델에 비해 월등히 높은 강건성을 보인다!
Zero-shot CLIP의 경우 다른 모델에 비해 월등히 높은 강건성을 보인다!
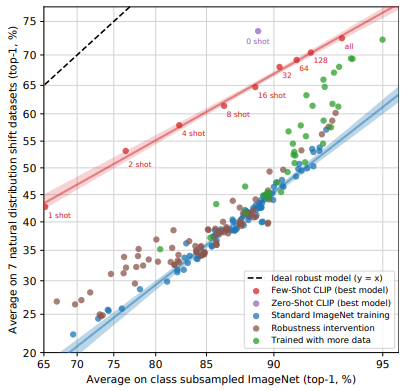
이때 특정 데이터셋에 대해 학습을 하면 할수록 해당 데이터셋에 대한 성능은 증가하지만, 전체적인 모델 강건성은 감소하는 trade-off가 존재하는 것도 알 수 있다.
특히 아래 그림에서는 CLIP의 few-shot learning을 높일수록 성능 자체는 올라가지만 강건성은 떨어지는 모습을 볼 수 있다. Zero-shot CLIP이 가장 robust한 모델이라고 결론 내릴 수 있다.
4. Comparison to Human Performance
개인적으로 흥미로웠던 부분인데, zero-shot CLIP과 인간의 성능을 비교한 실험이다. CLIP이 더 정확도가 높을 것은 당연히 예상했지만, 다소 흥미로운 결과도 보여준다. 인간의 경우 zero-shot 보다 one-shot 일 때 정확도가 크게 증가하지만 two-shot으로 늘어나면 거의 차이가 없다.
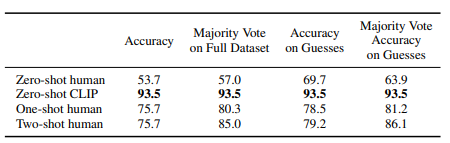
이는 어떻게 보면 인간의 고유한 학습 방식을 보여주는 결과라 볼 수 있다. 인간은 자신이 모르는 것을 인지하는 '메타 인지' 능력이 있기 때문에, 단 하나의 샘플만 주어져도 기존의 지식과 비교해가며 향상된 예측을 하게 된다. 반면 CLIP의 성능은 zero-shot일 때 가장 뛰어나고, 오히려 샘플을 학습할 수록 (few-shot) 하락하는 모습을 보인다는 점에서 인간의 학습 방식과 큰 차이를 보인다.
따라서 저자들은 이를 CLIP 학습 알고리즘의 한계이며, 앞으로 개선해야 할 점이라고 말한다. 마치 인간처럼 모델의 'prior knowledge'를 few-shot learning에 이용하는 것이 CLIP의 다음 단계라고 한다.
5. Limitations
논문에서는 CLIP 모델의 몇 가지 한계점을 제시한다.
1) Zero-shot CLIP의 경우 아직 전통적인 학습 방식을 사용하는 SOTA 모델들에 비해 낮은 성능을 보인다. 계산량과 데이터 효율성 측면에서도 개선이 필요하다.
2) 특정 task에 대해 zero-shot CLIP이 특히 약한 모습을 보여준다. 세밀하거나 추상적인 문제, 그리고 아예 새로운 문제에서는 좋은 성능을 내지 못한다.
3) 높은 강건성을 보이지만, 분포에서 아예 벗어난 새로운 데이터에 대해서는 일반화 성능이 떨어진다. MNIST 분류 문제에서 낮은 성능을 낸다는 점은 상당히 충격적이다...
4) 데이터 효율성 문제가 존재한다. 4억 개의 이미지를 1초에 하나씩 32 epoch을 수행하면 무려 405년이 걸린다고 한다.
5) CLIP의 학습 데이터는 전부 인터넷에서 수집하였기 때문에 사회적인 편향도 학습하게 된다. 이는 다음 섹션에서 자세히 다룬다.
6. Broader Impacts
마지막으로 저자들은 CLIP 모델의 사회적 편향과 잠재적인 위험성, 그리고 모델의 광범위한 응용과 추후 연구에 대해 다룬다.
먼저 모델의 사회적 편향성에 대해 검증하기 위해 FairFace라는 데이터셋을 사용한다. 여기에 논문에서는 ‘동물’, ‘고릴라’, ‘침팬지’, ‘오랑우탄’, ‘도둑’, ‘범죄자’, ‘수상한 사람’ 등의 새로운 class를 더해주어 인구 그룹에 어떤 편향을 가지고 있는지 체크했다.
그 결과, ‘흑인’이 '비인간 class'로 가장 많이 분류됐으며, '남성'이 '여성' 보다 범죄 관련 class로 더 많이 분류되었다.
또한, 다른 데이터셋으로 평가했을 때도 성별에 따라 매칭된 label이 상당히 다른 것을 볼 수 있다.
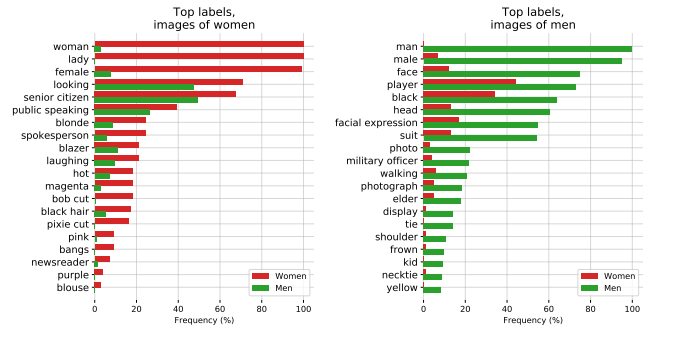 결론적으로 CLIP은 어느정도의 사회적 편향을 학습했다고 볼 수 있으며, 특히 class를 어떻게 정의하느냐에 따라 결과가 달라질 수 있다고 한다. 모델과 class design의 잠재적 편향성을 인지하고 보완할 방법이 필요한 것이다.
결론적으로 CLIP은 어느정도의 사회적 편향을 학습했다고 볼 수 있으며, 특히 class를 어떻게 정의하느냐에 따라 결과가 달라질 수 있다고 한다. 모델과 class design의 잠재적 편향성을 인지하고 보완할 방법이 필요한 것이다.
논문에서는 마지막으로 CLIP 모델을 surveillance task로도 검증을 해보며, 비록 성능은 아직 아쉽지만 zero-shot 특성을 이용하여 맞춤형 감시 모델 (bespoke, niche surveillance use case) 로의 가능성도 제시한다. 또한 몇 가지 후속 연구에 대한 방향성 역시 제안한다.
마무리
오늘은 멀티 모달의 새로운 세계를 연 아주 중요한 논문에 대해 알아보았다. CLIP은 NLP 분야의 성공 전략을 기반으로 비전 모델의 한계를 극복하고자 하였고, 결과적으로 이미지-텍스트 학습과 zero-shot prediction이라는 새로운 접근 방식을 제시하였다. 이는 이미지, 텍스트, 음성 등 다른 종류의 데이터를 하나의 모델로 처리할 수 있는 진정한 의미의 '인공지능'을 발명하는 데에 큰 일조를 하고 있다고 생각한다.
하지만 이 연구의 가치는 무엇보다도 사회적, 윤리적 차원에서 모델의 잠재적인 위험성과 영향, 그리고 개선 방향 역시 제시한다는 점에 있다고 생각한다.
참고 자료
Radford, et al. "Learning Transferable Visual Models From Natural Language Supervision", 2021.
[21′ PMLR] Learning Transferable Visual Models From Natural Language Supervision (CLIP)
