
PEFT (Parameter-Efficient Fine-Tuning)는 대규모 사전 학습된 모델(Pre-trained Model)을 효율적으로 fine-tuning 하는 기법이다. 일반적인 전체 모델의 파라미터를 업데이트하는 방식과 달리, PEFT는 일부 선택된 파라미터만 조정하여 연산량과 메모리 사용량을 크게 줄일 수 있다.
 이 연구에서는 delta tuning이라고도 하는데, vanilla fine-tuning (full fine-tuning)과 달리 조정하는 파라미터 수가 전체 파라미터보다 현저히 적다.
이 연구에서는 delta tuning이라고도 하는데, vanilla fine-tuning (full fine-tuning)과 달리 조정하는 파라미터 수가 전체 파라미터보다 현저히 적다.
이에 따른 PEFT의 장점은 다음과 같다:
✅ 메모리 절약 - 모델 전체를 업데이트하지 않기 때문에 GPU VRAM 사용량이 크게 줄어듦
✅ 빠른 학습 속도 - 적은 파라미터만 조정하므로 학습 시간이 단축됨
✅ 다양한 task에 적용 가능 - 하나의 큰 모델을 여러 태스크에 맞게 효율적으로 조정 가능
✅ 기존 모델 성능 유지 - 원래 모델의 가중치를 유지하므로 과적합 위험이 낮음
위 그림에서 볼 수 있듯 PEFT에는 다양한 방법이 존재한다. 따라서 오늘은 각 방법의 대표적인 기법 위주로 알아볼 것이다. 또한, PEFT의 근본적인 특성에 관한 상당히 흥미로운 관점을 제시하는 연구도 있어 간단하게 다룰 것이다.
Methods
1. Addition-Based Method
이 방법은 기존 모델 구조를 변경하지 않고, 추가적인 모듈(행렬, 네트워크 등)을 삽입하여 파라미터 효율적인 미세 조정을 수행한다.

1) Adapters-based Tuning
모델의 각 레이어 사이에 작은 어댑터 네트워크를 추가하는 방식이다. 기존 모델 가중치는 고정하며, 추가된 어댑터 네트워크만 학습한다.
(Houlsby et al., 2019.)
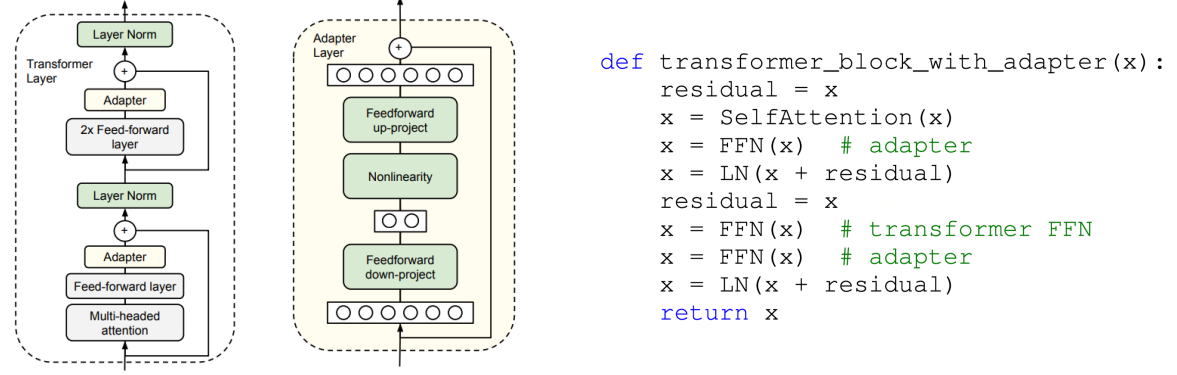 연구에 따르면, 어댑터를 사용했을 때 일반적인 fine-tuning에 비해 훈련 속도가 무려 60%나 빠르다고 한다. 또한 더 뛰어난 강건성을 보인다고 한다.
연구에 따르면, 어댑터를 사용했을 때 일반적인 fine-tuning에 비해 훈련 속도가 무려 60%나 빠르다고 한다. 또한 더 뛰어난 강건성을 보인다고 한다.
2) Prompt-based Tuning
입력에 최적의 프롬프트를 추가하여 모델 출력을 조정하는 방식이다. 입력 프롬프트에 해당하는 파라미터만을 학습하며, 모델 자체의 파라미터는 변경하지 않는다.
(Lester et al., 2021.)
 위에서 볼 수 있듯, 각 사진 별로 정확도를 높일 수 있는 적절한 프롬프트를 찾는 것이 핵심이다. 이 prompt tuning을 인간이 직접하는 것이 아니라 모델이 학습하게 하여 최적의 프롬프트를 찾는 것이 핵심이다.
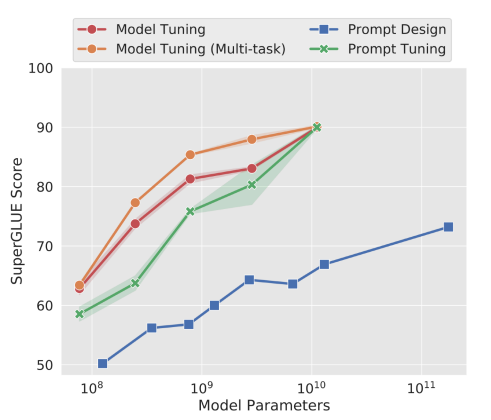
위에서 볼 수 있듯, 각 사진 별로 정확도를 높일 수 있는 적절한 프롬프트를 찾는 것이 핵심이다. 이 prompt tuning을 인간이 직접하는 것이 아니라 모델이 학습하게 하여 최적의 프롬프트를 찾는 것이 핵심이다. 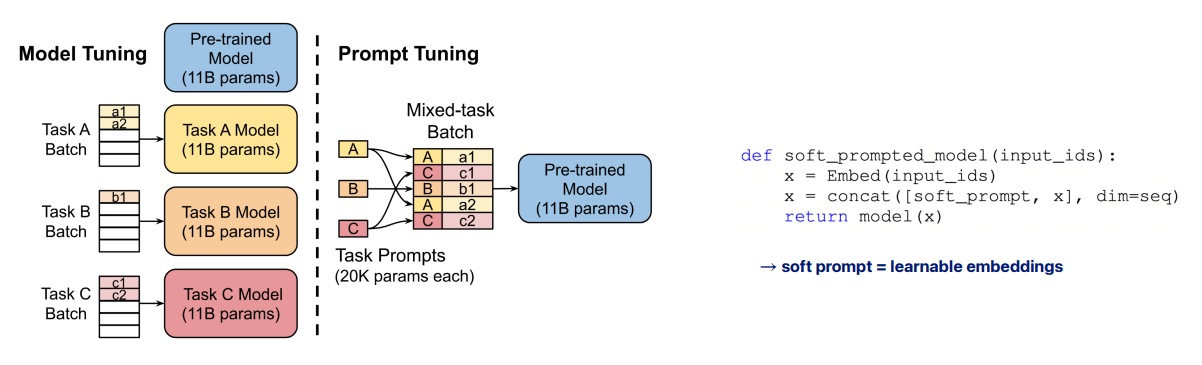 실제로 인간이 직접 prompt design (파란선)했을 때보다 모델이 tuning (초록선)했을 때 성능이 월등히 뛰어나다.
실제로 인간이 직접 prompt design (파란선)했을 때보다 모델이 tuning (초록선)했을 때 성능이 월등히 뛰어나다.
2. Specification-Based Method
이 방법은 전체 모델의 일부 특정 파라미터만 선택적으로 학습하는 방식이다.

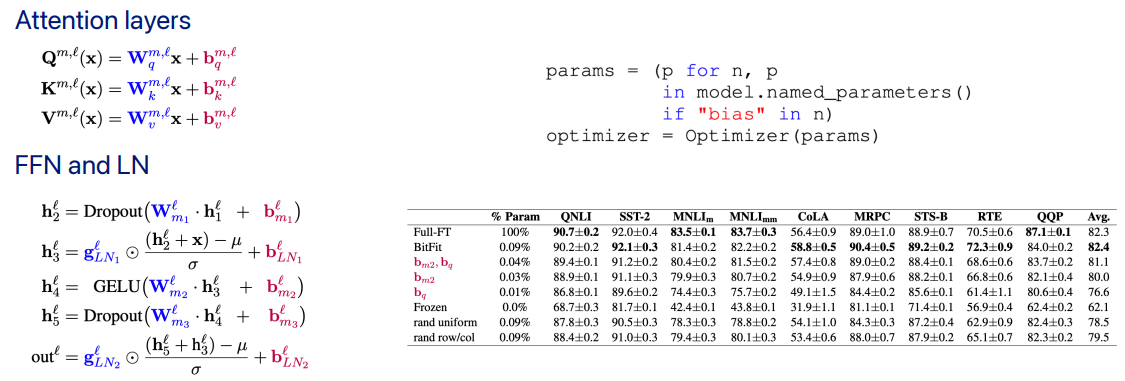
대표적으로 BitFit (Bias-terms Fine-tuning)이라는 기법이 존재하는데, 모델의 bias 파라미터만 학습하는 방식이다. 학습할 파라미터 수가 극히 적어 메모리와 연산량이 매우 절약된다.
(Zaken et al., 2021.)
3. Reparameterization-Based Method
이 방법은 기존 모델의 일부 파라미터를 저차원 공간에서 재구성하거나 새로운 표현 방식으로 변환하여 학습을 수행하는 방식이다.

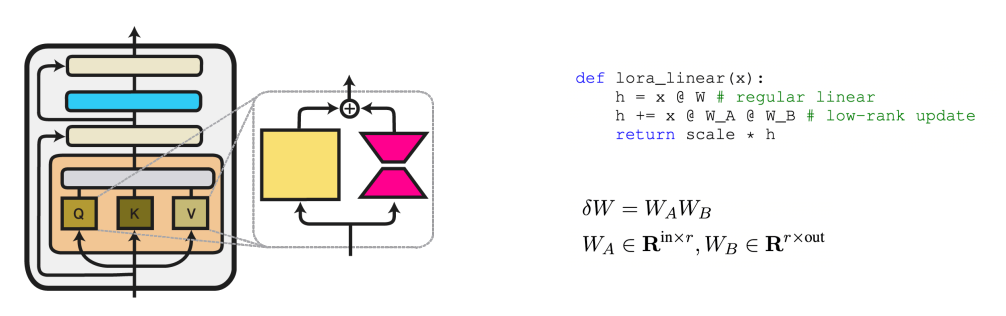
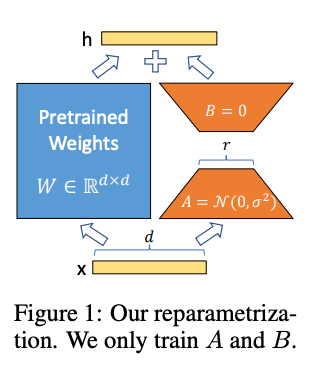
Microsoft에서 발표한 LoRA (Low-Rank Adaptation)가 가장 유명한 기법인데, 아래와 같이 기존 가중치 (파란 부분)는 고정하면서 학습 가능한 저차원의 가중치 행렬 (주황색)을 adapter로 추가하여 모델을 조정한다. 이때 중요한 것은 행렬 A와 B가 마치 오토 인코더의 느낌으로 기존 가중치 행렬보다 훨씬 낮은 차원을 갖기 때문에 파라미터 수를 크게 줄이면서도 성능은 유지할 수 있다.
(Hu et al., 2021.)
Unified View of PEFT
다양한 PEFT의 기법을 살펴보았는데, 근본적으로는 모두 같은 방식으로 치환될 수 있다는 흥미로운 연구를 간단히 소개하고자 한다.
이 연구에서는 adapters, prefix-tuning (위에서 다루진 않았지만 언어 모델에서 사용하는 방식), LoRA 등의 서로 다른 PEFT 기법들이 수학적으로 어떻게 유사한지 증명한다.
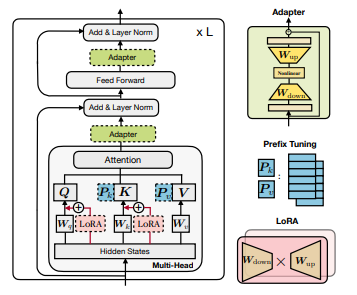 위 그림처럼 3가지 기법은 서로 구조나 쓰이는 부분 등이 다른 것을 볼 수 있다. 하지만, 수학적으로 표현하면 어떻게 될까?
위 그림처럼 3가지 기법은 서로 구조나 쓰이는 부분 등이 다른 것을 볼 수 있다. 하지만, 수학적으로 표현하면 어떻게 될까?
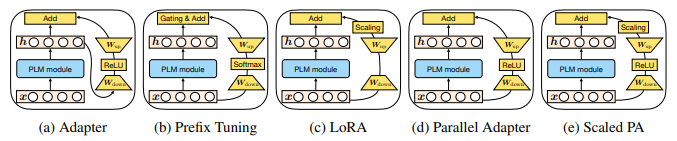
Adapters :
Prefix-tuning :
LoRA :
.
.
.
Adapter와 LoRA는 뭔가 유사한데... prefix-tuning을 더 자세히 풀어보자 (여기서 는 prefix-vector로, 이 부분을 학습하여 tuning하는 방식이다).
그럼 최종적으로 다음과 같이 표현이 가능한데:
라 정의하고 adapter 수식 형태로 다시 표현하면 다음과 같다.
.
.
.
결국 세 방식은 약간의 차이만 있을 뿐 근본적인 구조는 동일하다. 저차원으로 매핑하고 되돌리는 행렬 , 그리고 그 사이 활성화 함수 가 적용 (ReLU, softmax 등등) 된 구조가 residual하게 더해진다.
 이러한 unified view를 기반으로 저자들은 새로운 PEFT 기법을 제시하여 좋은 성능을 보인다.
이러한 unified view를 기반으로 저자들은 새로운 PEFT 기법을 제시하여 좋은 성능을 보인다.
참고 자료
서울대학교 김태섭 교수님의 MLDL2 강의 자료
He, et al., "Towards a Unified View of Parameter-Efficient Transfer Learning", 2022.
