2015년 ILSVRC에서 1위를 달성하며 비전 분야에서 빼놓을 수 없는 모델 중 하나인 ResNet에 대해 다뤄본다. 먼저 논문의 핵심 내용을 살펴보고 pytorch로 모델을 직접 구현할 것이다.
논문 링크
0. Abstract

ResNet이 해결하고자 한 문제 상황은 바로 첫 줄에 나와있다. 딥러닝 모델은 보통 '깊을수록 성능이 좋다', 즉 신경망의 layer가 많을수록 성능이 뛰어날 것이라는 믿음이 있었다.
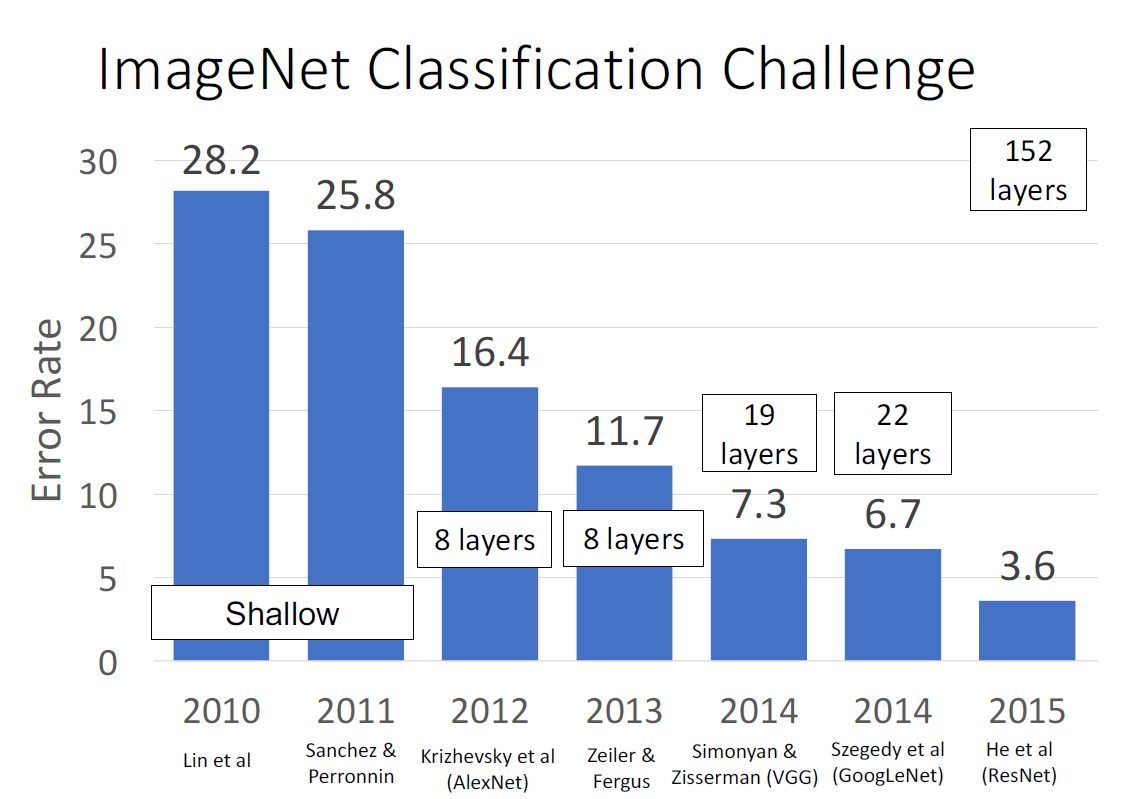
실제로 ImageNet Classification Challenge에서 neural net의 깊이가 클수록 좋은 성능을 보여주었다. 그러면 무작정 layer를 많이 쌓으면 되지 않을까? 하지만 본 논문의 저자 Kaiming He 등은 '깊을수록 학습하기 어렵다'는 문제를 맞닥뜨렸다. 그리고 이 문제를 'Residual Network'라는 획기적인 구조를 통해 해결할 수 있었다.
결과적으로 ResNet은 전년도의 1위 GoogLeNet의 깊이(22 layer)를 아득히 뛰어넘은 깊이(152 layer)로 학습할 수 있었고, 더 높은 성능을 얻을 수 있었다.
1. Introduction

결국 중요한 것은 네트워크의 깊이인데, 학습 과정에서 두 가지의 문제가 발생한다.
1) vanishing/exploding gradients
네트워크의 깊이를 늘렸을 때 그래디언트 관련 문제가 발생한다. 이것은 normalized initialization, intermediate normalization layers 등으로 해결할 수 있었기에 여기서 다룰 문제는 아니다.
2) degradation problem
두번째 문제가 더 중요한데, 바로 성능 자체가 떨어진다는 문제다. 분명 더 깊을수록 성능이 좋아야 할텐데... 그렇다면 더 깊을수록 과적합돼서 그런 것이 아닐까?
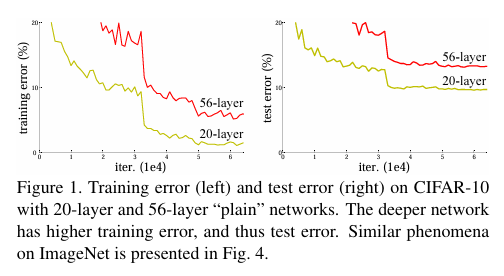
놀랍게도 문제는 overfitting이 아니라, training error 자체도 높은 것으로 보아 오히려 underfitting이 발생한 것이다.
근데 조금 이상한 점은, 이론상 깊은 모델은 얕은 모델을 emulate 할 수 있다. 예를 들어, 56-layer 모델이 20-layer 짜리 모델의 파라미터를 그대로 복사하고, 나머지 36개의 layer는 단순히 identity mapping을 하면 똑같은 표현력을 가질 것이다.
그럼 이 문제는 왜 발생한 것이며, 어떻게 해결할 수 있을까?
저자는 이 문제의 원인에 대해서는 명확히 밝히진 못했다.
다만, 이는 optimization 과정에서의 'exponentially low convergence rate' 때문이라 추측하였으며,
Residual Network 구조를 통해 효과적으로 해결해낼 수 있었다.
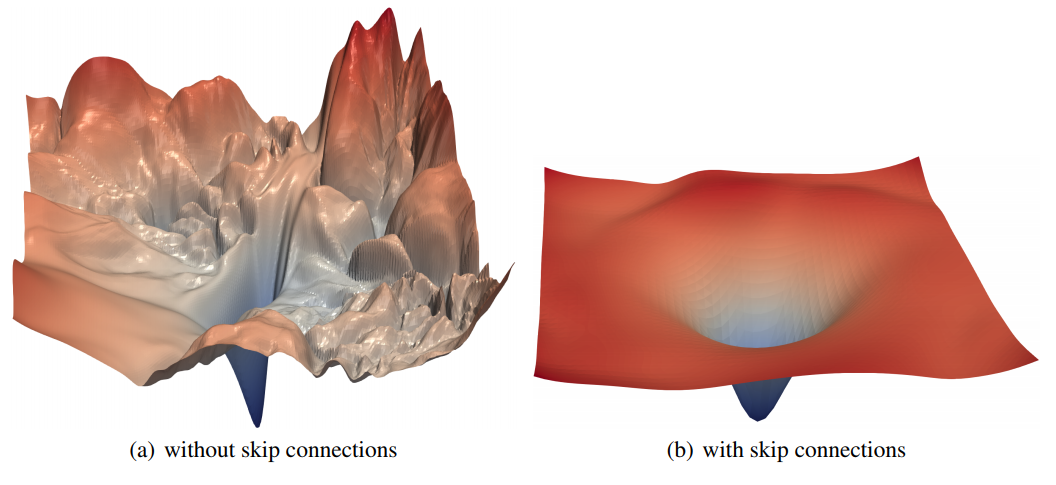
*참고로 이후의 연구(Li, Hao, et al. "Visualizing the Loss Landscape of Neural Nets." 2018)에서 문제의 원인은 Loss Landscape가 복잡함(chaotic)에 있다는 것을 밝혀냈다.
아래의 그림은 ResNet의 핵심 제안인 skip connection의 유무에 따라 Loss Landscape의 복잡도가 확연히 다르다는 것을 보여준다.
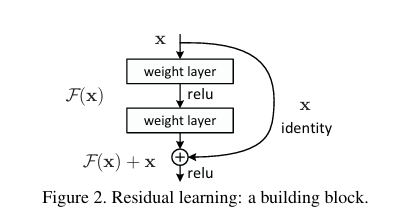
2. ResNet 핵심 요소
2-1. Residual Learning
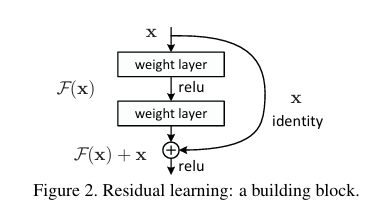
위 그림은 Residual Learning의 구조를 한 눈에 보여준다.
이고, 우리가 원하는 output을 라고 한다면 ...
여기에 단순히 를 다시 더해주는 skip-connection이 Residual Learning의 전부다!
즉, 가 되는 것이고, 모델 입장에서는 '잔차(residual)'인 만 학습하면 되는 것이다.
두 가지 수식이 나오는데, (1)은 x와 F(x)의 차원이 같을 때의 경우이며,
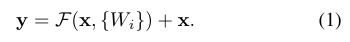 (2)는 차원이 다를 경우(이후 설명할 내용) linear projection 를 적용하여 차원을 맞춰준다.
(2)는 차원이 다를 경우(이후 설명할 내용) linear projection 를 적용하여 차원을 맞춰준다.
그렇다면... 두 개 이상의 layer를 skip하여 더해주는 것만으로 왜 학습이 잘 되는 것일까? 두 개 정도의 이유를 생각해 볼 수 있을 것 같다.
1) gradient 입장에서 일종의 '지름길'을 만들어주어 깊은 레이어까지 잘 전달이 되는 것이다.
Skip connection을 통해 전달되는 x는 역전파 과정에서 곱해지는 gradient 요소의 개수가 적기 때문에 gradient가 0에 수렴하는 문제가 덜 발생할 것이다. 이전 레이어의 gradient가 깊은 레이어까지 잘 전달이 되는 것이다!
2) 가 identity에 가깝도록 preconditioning 하는 효과가 있다.
깊은 네트워크에서 과연 매 레이어마다 값이 급격하게 바뀌는 것이 좋을까, 아니면 조금씩 차근차근 바뀌는 것이 좋을까? 학습 측면에서 이상적인 것은 후자다. 애써 layer 30까지 잘 학습했는데 layer 32에서 갑자기 값이 크게 변해버리면 말짱도루묵 아닌가?
따라서 우리는 깊은 레이어에서 아예 가 되도록 하는 것이 이상적이다.
Skip connection이 존재하는 것만으로 이건 굉장히 쉬워지는데...
, 즉 를 단순히 0에 가깝게 만들어버리면 된다! (weight initialization시 보통 0에 가깝게 초기화된다는 것을 생각해보면 이건 상당히 쉬운 과정이다.)
따라서 skip connection은 모델에게 조금씩 차근차근 학습하도록 preconditioning 하는 효과가 있다고 생각할 수 있다.
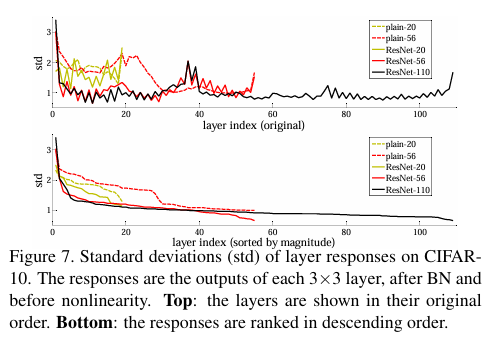 실제로 본 논문에서도 ResNet이 깊어질수록 layer output의 편차가 작아진다는 결과를 제시한다.
실제로 본 논문에서도 ResNet이 깊어질수록 layer output의 편차가 작아진다는 결과를 제시한다.
2-2. Architecture
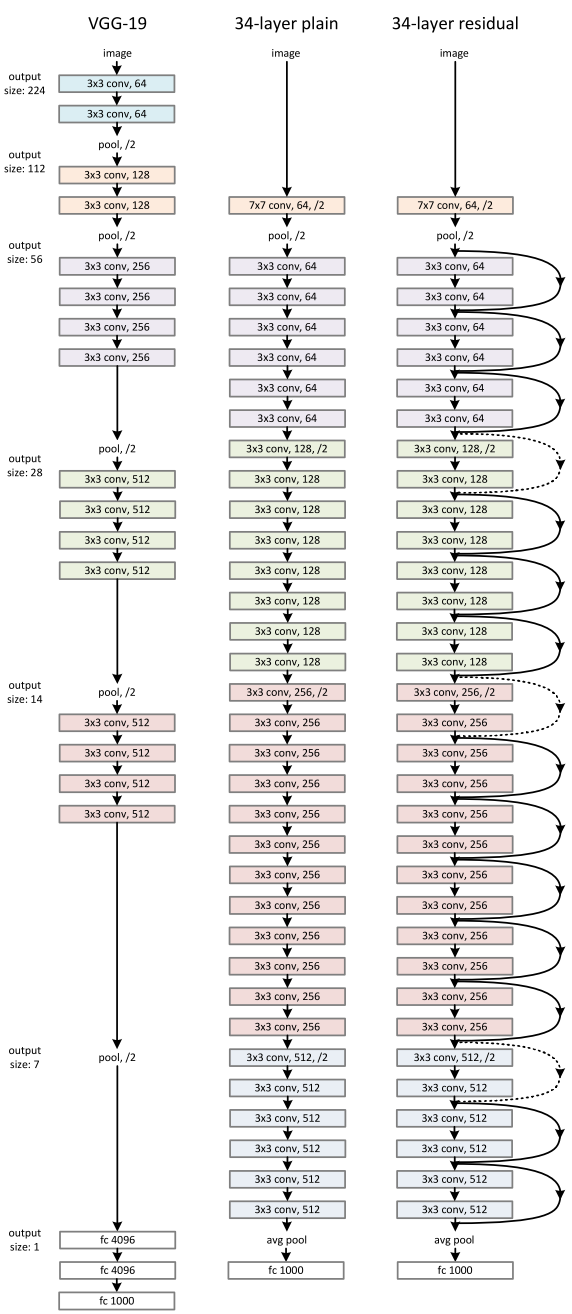 왼쪽부터 차례대로 VGG-19, plain 모델, residual 모델이다.
왼쪽부터 차례대로 VGG-19, plain 모델, residual 모델이다.
저자는 VGG-19의 핵심 아이디어를 활용한 모델에 residual learning의 아이디어를 적용한다.
3x3 conv layer를 반복해서 쌓으며, 중간에 pooling (stride=2를 통한)으로 사이즈를 반으로 줄이고 channel size는 두 배로 늘린다.
여기서 실선은 identity shortcut으로, input과 output 차원이 같을 때 위의 수식 (1)을 사용한다.
점선은 projection shortcut으로 차원이 다를 경우에 수식 (2)를 사용하는데, 1x1 conv, stride=2를 적용하여 사이즈와 차원(channel size)을 맞춰준다.
2-3. Bottleneck
ResNet-50, ResNet-101, ResNet-152 등 깊은 ResNet 모델에서는 연산량을 줄이기 위해 bottleneck 구조를 사용한다. 3x3 conv만 사용하는 기존 방법에서는 channel size가 2배씩 증가하므로 깊어질수록 연산량이 기하급수적으로 늘어난다.
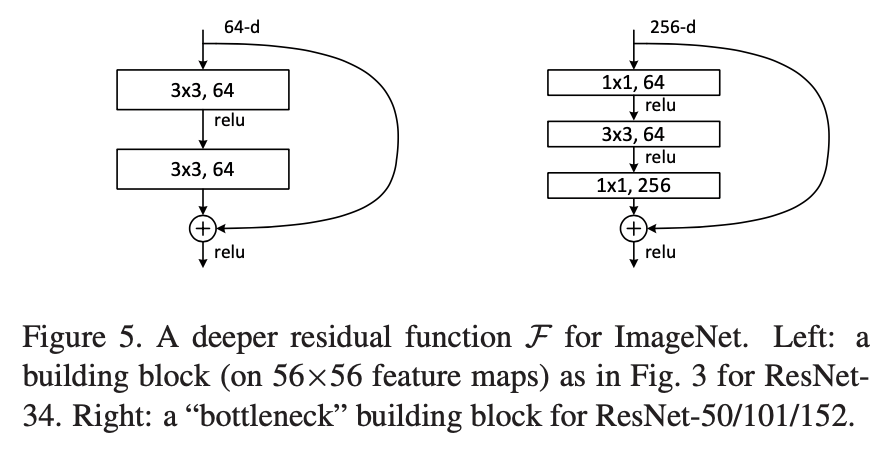 따라서 논문에서는 오른쪽 구조 bottleneck block을 제시하는데, 1x1 conv를 이용하여 일차적으로 input dimension을 줄여준다. 이렇게 되면 3x3 conv가 연산해야 하는 차원 수가 줄어들기 때문에 연산량이 크게 감소하는 효과를 볼 수 있다! 그 이후 다시 1x1 conv를 적용하여 output dimension을 맞춰준다.
따라서 논문에서는 오른쪽 구조 bottleneck block을 제시하는데, 1x1 conv를 이용하여 일차적으로 input dimension을 줄여준다. 이렇게 되면 3x3 conv가 연산해야 하는 차원 수가 줄어들기 때문에 연산량이 크게 감소하는 효과를 볼 수 있다! 그 이후 다시 1x1 conv를 적용하여 output dimension을 맞춰준다.
결과적으로 저자는 bottleneck 구조를 활용하여 매우 깊은 ResNet도 효과적으로 훈련할 수 있었고, 실제로 깊을수록 더 높은 성능을 냈다.
이제 전체적인 구조를 살펴보면:
 5가지 다른 레이어의 ResNet을 제시하고 있는데, 여기서 downsampling, 즉 점선 shortcut은 conv3, conv4, conv5의 첫 레이어에서 진행한다(input과 output 차원이 다르기 때문!).
5가지 다른 레이어의 ResNet을 제시하고 있는데, 여기서 downsampling, 즉 점선 shortcut은 conv3, conv4, conv5의 첫 레이어에서 진행한다(input과 output 차원이 다르기 때문!).
참고로 50-layer 이상의 모델에서는 conv2_1에서도 점선 연결을 한다. 예시로 50-layer model의 conv2_1을 보면, input 채널 수는 64이지만 output은 256이 된다. 따라서 여기서도 projection shortcut을 적용해야 하는 것이다.
실제로 pytorch 모델 구현 시에도 이 부분을 놓치지 않으려고 노력했다.
3. Experiments
1) ImageNet Classification
먼저 학습 데이터셋에 대한 성능을 살펴보자.
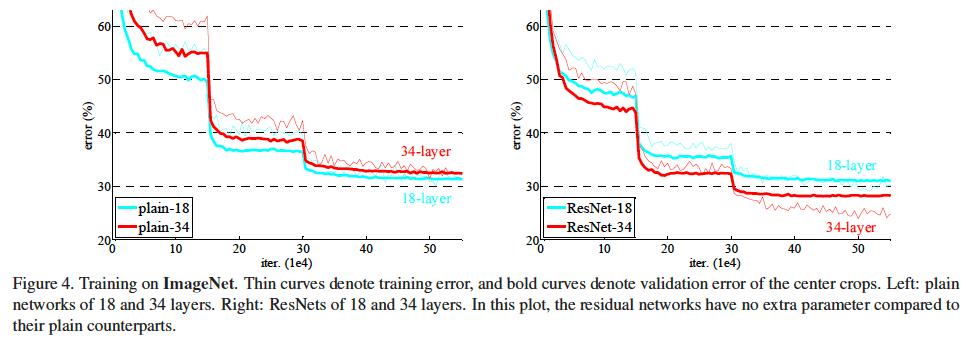 Residual learning을 적용하지 않은 왼쪽 그래프의 경우, 깊은 모델이 학습 데이터셋에 대한 성능이 더 떨어지는 문제를 보인다. 반면 ResNet 구조를 활용하였을 땐, 모델을 더 깊게 만들어도 학습이 잘 돼서 성능이 더 좋은 현상을 볼 수 있다. 즉, 기존의 underfitting 문제가 해결된 것이다!
Residual learning을 적용하지 않은 왼쪽 그래프의 경우, 깊은 모델이 학습 데이터셋에 대한 성능이 더 떨어지는 문제를 보인다. 반면 ResNet 구조를 활용하였을 땐, 모델을 더 깊게 만들어도 학습이 잘 돼서 성능이 더 좋은 현상을 볼 수 있다. 즉, 기존의 underfitting 문제가 해결된 것이다!
다음으로 검증 데이터셋에 대한 성능인데,
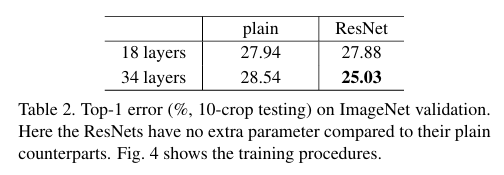 마찬가지로 ResNet을 사용했을 때 같은 깊이임에도 validation error이 낮다는 것을 알 수 있다!
마찬가지로 ResNet을 사용했을 때 같은 깊이임에도 validation error이 낮다는 것을 알 수 있다!
2) Identity vs. Projection
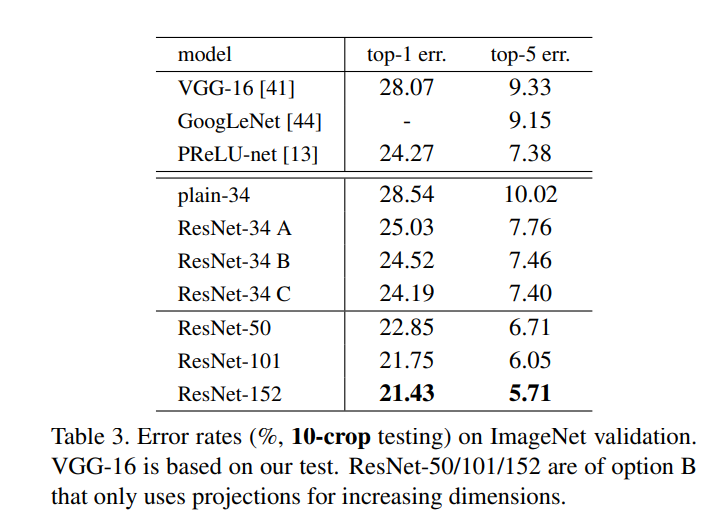 ResNet-34에 대해 option A, B, C를 비교한 것인데, 그 차이는 다음과 같다:
ResNet-34에 대해 option A, B, C를 비교한 것인데, 그 차이는 다음과 같다:
A - 증가하는 차원 (점선 연결)에 대해 zero-padding shortcut, 모든 shortcut은 parameter-free
B - 증가하는 차원 (점선 연결)에 대해 projection shortcut, 나머지는 identity shortcut
C - 전부 projection shortcut
성능은 C-B-A 순으로 좋지만, 저자들이 구현한 모델은 option B를 사용한다. 성능 차이가 사실상 미미하고, identity shortcut이 bottleneck 구조에서 중요하기 때문이다.
3) 모델의 깊이
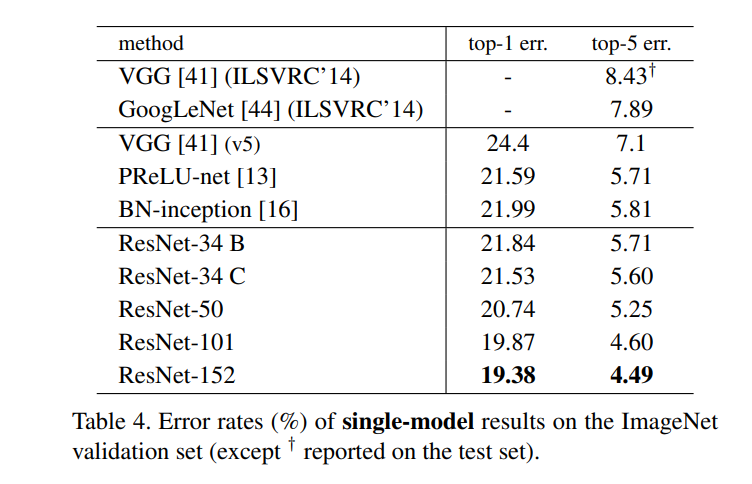
ResNet-34부터 ResNet-152까지, 다양한 깊이의 ResNet을 비교해보면 깊이가 늘어날수록 성능이 좋아진다는 것을 알 수 있다. 실제로 ILSVRC에서 1위를 차지한 모델은 가장 깊은 모델인 ResNet-152를 2개 앙상블한 모델이었다.
4) CIFAR-10 관련
CIFAR-10 데이터셋에서도 SOTA의 성능을 얻을 수 있었다!
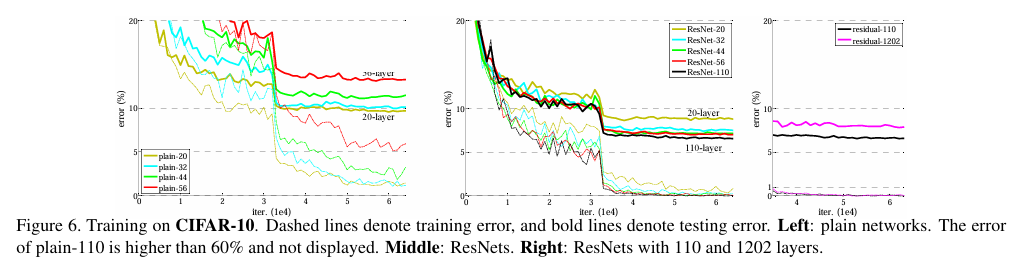 마찬가지로 layer가 많은 모델일수록 성능이 좋아지는 현상을 보인다. 다만, 맨 오른쪽 그래프는 깊이를 극단적으로 늘린 ResNet-1202의 성능을 보여주는데, 학습 에러는 낮지만 검증 에러가 ResNet-110보다 높은 것으로 보아 overfitting이 됐다는 것을 시사한다. 뭐든지 과유불급인듯 하다...
마찬가지로 layer가 많은 모델일수록 성능이 좋아지는 현상을 보인다. 다만, 맨 오른쪽 그래프는 깊이를 극단적으로 늘린 ResNet-1202의 성능을 보여주는데, 학습 에러는 낮지만 검증 에러가 ResNet-110보다 높은 것으로 보아 overfitting이 됐다는 것을 시사한다. 뭐든지 과유불급인듯 하다...
*참고로 CIFAR-10 데이터셋에서는 ImageNet의 경우와 layer 수가 다른데, 이미지 사이즈 자체가 32x32로 훨씬 작아서 모델 구조를 약간 수정했기 때문이다. Conv1에서 7x7 필터 대신 3x3 필터를 사용하는 등 작은 이미지 사이즈 특성에 맞추었다. 혹시나 ResNet을 직접 구현해서 사용한다면 학습 이미지의 특성에 따라 적절히 수정하면 좋을듯 하다. 개인적으로 CIFAR-10을 훈련할 때 오리지널 ResNet (ImageNet용)을 구현해서 생각보다 성능이 안 나와 의아했던 경험이 있었다. 아마 초반의 7x7 필터가 작은 이미지에 대해 너무 aggressive하게 image feature를 추출하는 것 같다.
모델 구현
논문에 대한 내용은 여기서 마무리하고, 아래는 pytorch로 직접 구현한 코드이다.
ImageNet 데이터셋의 original ResNet과 CIFAR-10/100 데이터셋의 modified ResNet을 모두 구현했다.
전체 코드는 정리해서 깃허브에 남겨두었다.
설명이 좀 필요한 부분만 이 포스트에서 직접 다루겠다.
먼저, bottleneck 구조가 논문과 약간 다른 점이 있다. 논문에서는 bottleneck의 첫번째 1x1 conv에서 stride=2를 이용한 downsampling을 한다. 하지만, 성능 면에서 3x3 conv에서 하는 것이 좋다고 한다. ResNet v1.5라고도 불리며, torchvision에서도 이 버전을 제공한다.
# Bottleneck for ResNet-50/101/152
# downsampling stride at 3x3 convolution, instead of the first 1x1 convolution (original paper)
# A.K.A ResNet V1.5 (https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, inner_channels, stride = 1, projection = None):
super().__init__()
# bottleneck structure
self.residual = nn.Sequential(nn.Conv2d(in_channels, inner_channels, 1, bias=False),
nn.BatchNorm2d(inner_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inner_channels, inner_channels, 3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(inner_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inner_channels, inner_channels * self.expansion, 1, bias=False),
nn.BatchNorm2d(inner_channels * self.expansion))
self.projection = projection
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = self.residual(x)
# projection shortcut & identity shortcut
if self.projection is not None:
shortcut = self.projection(x)
else:
shortcut = x
out = self.relu(residual + shortcut)
return out다음으로 batch normalization의 initialization 부분인데, residual block의 마지막 배치 정규화 층 가중치를 0으로 초기화한다. 학습 초기에 residual block이 identity function처럼 동작하게 되어, 깊은 네트워크의 학습을 안정화하는데 도움이 된다고 한다.
자세한 건 이 논문을 참고하길 바란다.
# zero-initialize the last BN in each residual branch
# 0.2~0.3%p accuracy gain according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, block):
nn.init.constant_(m.residual[-1].weight, 0)점선 연결/실선 연결 부분은 이런 식으로 구현했다. Downsampling (stride=2)하거나 차원이 다를 때 projection shortcut을 정의한다.
# projection shortcut when downsampling / dimension-matching
if stride != 1 or self.in_channels != inner_channels * block.expansion:
projection = nn.Sequential(
nn.Conv2d(self.in_channels, inner_channels * block.expansion, 1, stride=stride, bias=False),
nn.BatchNorm2d(inner_channels * block.expansion))
# identity shortcut otherwise
else:
projection = None
CIFAR-10/100 데이터셋에 대해서는 모델 구조가 조금 다르다. 우선 bottleneck 대신 basic block만 사용하고, 처음 conv에서 kernel size=3, output dim=16이다.
그리고 conv_2, conv_3, conv_4 총 3개의 stage만 있다 (원래는 4).
# ResNet Architecture (CIFAR-10)
class ResNet_c(nn.Module):
def __init__(self, block, num_block_list, num_classes = 10): # num_classes = 100
super().__init__()
self.in_channels = 16
# change on the first conv layer (output dim = 16, kernel size = 3)
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
# 3 stages
# feature map size = 32x32x16
self.stage1 = self.make_stage(block, 16, num_block_list[0], stride=1)
# feature map size = 16x16x32
self.stage2 = self.make_stage(block, 32, num_block_list[1], stride=2)
# feature map size = 8x8x64
self.stage3 = self.make_stage(block, 64, num_block_list[2], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(64, num_classes)
.
.
.
그래서 layer 수도 오리지널 버전과 조금씩 다르다!
def resnet20():
return ResNet_c(BasicBlock, [3, 3, 3])
def resnet32():
return ResNet_c(BasicBlock, [5, 5, 5])
def resnet44():
return ResNet_c(BasicBlock, [7, 7, 7])
def resnet56():
return ResNet_c(BasicBlock, [9, 9, 9])
def resnet110():
return ResNet_c(BasicBlock, [18, 18, 18])
def resnet1202():
return ResNet_c(BasicBlock, [200, 200, 200])상세 코드: https://github.com/tony3ynot/ResNet-for-ImageNet-and-CIFAR
(좋아요 눌러주세요)
마무리
사실 ResNet은 너무 유명하고 딥러닝 기초 단계에서 배우는 모델이기에 굳이 논문을 리뷰하고 직접 구현까지 해야하나? 라는 생각도 있었다. 특히나 transformer 등장 이후 ResNet보다 훨씬 성능도 좋고 빠른 모델이 너무나 많은데, 상황이 급변하는 딥러닝 세계 속 outdated 된 모델이 아닐까하는 생각도 든다. 하지만 ResNet의 가치는 그 무엇보다 저자들의 철학에 담겨있다고 생각한다. 불명확한 문제를 정말 간단하지만, 독창적인 방법으로 해결해냈다는 점이 참 대단한 것 같다. 그리고 현재까지도 다양한 모델이 나왔지만, ResNet의 skip connection과 bottleneck 구조는 여전히 널리 쓰이고 있다. Pretrained 모델로도 ResNet을 많이 사용하는 것을 보면 이 기본적이고도 혁신적인 모델을 공부할 가치는 충분하다.
딥러닝 초보의 주관이 많이 반영된 부족한 글이지만, 여러분들에게도 조금이나마 도움이 됐다면 기쁠 것 같다!
참고자료
본문:
He, et al. "Deep Residual Learning for Image Recognition". 2015
Li, Hao, et al. "Visualizing the Loss Landscape of Neural Nets". 2018
[16′ CVPR] Deep Residual Learning for Image Recognition (ResNet)
코드:
'혁펜하임'님의 Legend 13 강의 코드 자료에서 큰 도움을 받았습니다.
https://github.com/akamaster/pytorch_resnet_cifar10/blob/master/resnet.py
