2014년 발표된 GAN은 비지도 학습 중 적대적 (adversarial) 학습이란 독특한 방식을 사용해 인공지능 분야의 새로운 혁신을 일으켰다. 특히 styleGAN 등 다양한 이미지 생성 모델의 시초가 되는 아주 중요한 모델이다.
그래서 이 모델을 생성 ai 시리즈의 첫 모델로 공부해보고자 한다.
논문 링크
0. Abstract
 본 연구에서는 'adversarial process'를 통해 새로운 형식의 생성형 모델을 구축하는데, 이는 두 모델 G와 D를 동시에 훈련하는 과정으로 이뤄진다. G는 생성성 모델이며 학습 데이터의 분포를 학습하고, D는 데이터 샘플이 학습 데이터인지 혹은 G가 생성한 데이터인지 분간하는 작업을 수행한다. 이때 G는 최대한 D를 속이려고 노력하고, D는 어떻게든 잘 구별을 하려는 방식으로 학습한다. 이러한 적대적인 학습 과정 속 모델은 결국 더 품질 높은 데이터를 생성해낼 수 있게 된다.
본 연구에서는 'adversarial process'를 통해 새로운 형식의 생성형 모델을 구축하는데, 이는 두 모델 G와 D를 동시에 훈련하는 과정으로 이뤄진다. G는 생성성 모델이며 학습 데이터의 분포를 학습하고, D는 데이터 샘플이 학습 데이터인지 혹은 G가 생성한 데이터인지 분간하는 작업을 수행한다. 이때 G는 최대한 D를 속이려고 노력하고, D는 어떻게든 잘 구별을 하려는 방식으로 학습한다. 이러한 적대적인 학습 과정 속 모델은 결국 더 품질 높은 데이터를 생성해낼 수 있게 된다.
과거의 생성형 모델은 마르코프 체인이나 여러 inference tool을 사용해야 했지만, GAN은 당시 딥러닝 모델들처럼 multilayer perceptron 기반으로 역전파 학습이 가능하단 점에서 혁신적이었다.
1. Introduction
당시 딥러닝 분야에서는 역전파 기반의 심층 신경망과 dropout, ReLU 등을 통한 안정적인 그래티언트 학습이 가능했다. 하지만 deep generative model 분야에서는 확률 계산 상의 어려움 등으로 이러한 기법들을 적용시키기 어려웠다. 따라서 본 논문의 GAN은 이러한 기존 문제를 해결하고 딥러닝 기법들을 적극 활용할 수 있도록 하였다.
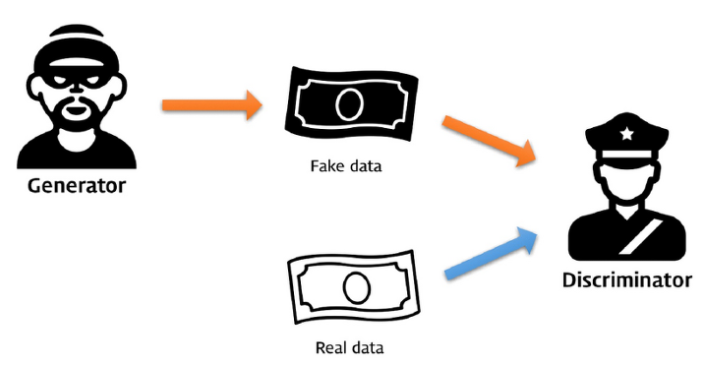
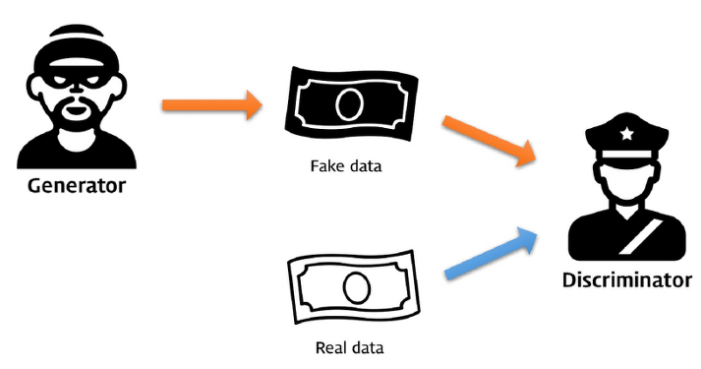 GAN은 generator와 discriminator 두 모델로 구성돼 있는데, generator는 마치 위조 지폐를 만들어내는 위조범이고 discriminator는 그 위조 지폐를 판별하는 경찰과 같이 생각할 수 있다. 위조범이 경찰을 속이기 위해 더욱 정밀하게 위조 지폐를 만들수록 경찰 역시 잘 구별하기 위해 더더욱 노력을 할 것이다.
GAN은 generator와 discriminator 두 모델로 구성돼 있는데, generator는 마치 위조 지폐를 만들어내는 위조범이고 discriminator는 그 위조 지폐를 판별하는 경찰과 같이 생각할 수 있다. 위조범이 경찰을 속이기 위해 더욱 정밀하게 위조 지폐를 만들수록 경찰 역시 잘 구별하기 위해 더더욱 노력을 할 것이다.
GAN은 이러한 적대적 학습 관계를 활용하여 두 모델 모두 성능이 높아지는 것을 목표로 한다. 중요한 것은 각 모델은 모두 multilayer perceptron 기반이기에 역전파 학습과 dropout, ReLU 등의 기법이 적용 가능하다. 또한, MCMC, NCE, 마르코프 체인 등 확률, 근사 추론 계산이 일절 사용되지 않기 때문에 계산량 및 속도 면에서 기존 생성 모델보다 뛰어나다.
2. Adversarial Nets
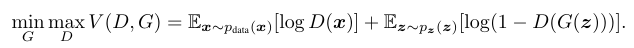 GAN의 목적함수 수식이다. G 모델은 전체 loss를 minimize하고 D 모델은 maximize하는 minimax game이다.
GAN의 목적함수 수식이다. G 모델은 전체 loss를 minimize하고 D 모델은 maximize하는 minimax game이다.
1) : 원본 데이터 분포에서 샘플 x를 뽑아 D 모델에 넘겨주어 기댓값을 계산한다. 이때 는 입력 데이터가 원본 데이터 분포일 확률로, D 모델은 식을 최대화하는 것을 목적으로 한다.
2) : 의 노이즈 분포에서 샘플 z를 뽑아 G 모델에 넘겨준다. 그 생성 결과인 를 최대한 원본 데이터 분포와 비슷하게 만드는데, 이때 G 모델은 를 1에 가깝게 만들어 궁극적으로 식을 최소화하는 것을 목적으로 한다.
 실제 학습 과정에서는 위 알고리즘을 따르는데, 한 iteration에서 D는 k번 최적화 (gradient ascent)한 뒤 G를 1번 최적화 (gradient descent)한다.
실제 학습 과정에서는 위 알고리즘을 따르는데, 한 iteration에서 D는 k번 최적화 (gradient ascent)한 뒤 G를 1번 최적화 (gradient descent)한다.
또한, 학습 초반에는 G의 성능이 떨어지기 때문에 를 최소화하는 할 때 gradient가 너무 작아 학습이 어려울 수 있다. 따라서 대신 를 최대화하는 것이 더 학습이 잘 된다고 한다.
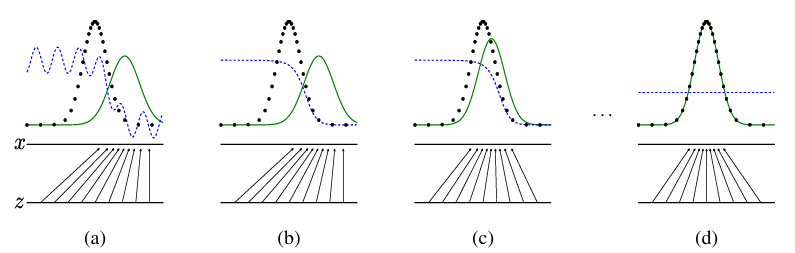 결과적으로 GAN은 원본 데이터 분포 (검은 점)에 생성된 데이터 분포 (초록선)를 근사할 수 있게 된다. 참고로 파란 점선은 discriminative distribution으로 D 모델이 입력 데이터에 대해 구별한 확률값을 나타낸다. 학습이 충분히 진행되면 D가 원본 데이터와 생성 데이터를 구분할 수 없게 되어 확률이 0.5로 고정된다.
결과적으로 GAN은 원본 데이터 분포 (검은 점)에 생성된 데이터 분포 (초록선)를 근사할 수 있게 된다. 참고로 파란 점선은 discriminative distribution으로 D 모델이 입력 데이터에 대해 구별한 확률값을 나타낸다. 학습이 충분히 진행되면 D가 원본 데이터와 생성 데이터를 구분할 수 없게 되어 확률이 0.5로 고정된다.
3. Theoretical Results
결국 GAN의 목표는 를 로, (discriminative distribution)을 0.5로 수렴시키는 것이다. 다음은 이 두 목표가 목적 함수에 의해 수학적으로 어떻게 증명될 수 있는지 보여준다.
3-1. Global Optimality
먼저 G가 고정됐을 때 D의 optimal point 는 다음과 같이 표현됨을 증명하는 과정이다.
 이제 최적의 D를 찾았으므로 목적함수는 다음과 같이 나타낼 수 있다. 이제 C(G) 함수를 최소화하도록 G를 최적화하면 된다!
이제 최적의 D를 찾았으므로 목적함수는 다음과 같이 나타낼 수 있다. 이제 C(G) 함수를 최소화하도록 G를 최적화하면 된다!
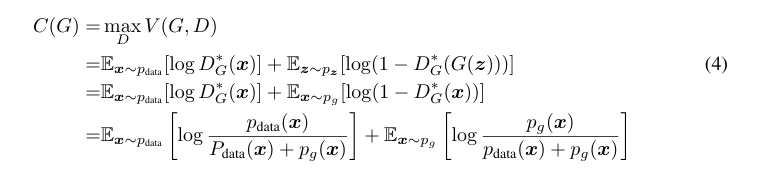 이제 드디어 C(G)의 global minimum은 일 때라는 것을 증명할 수 있게 된다.
이제 드디어 C(G)의 global minimum은 일 때라는 것을 증명할 수 있게 된다.
증명의 편이를 위해 (4) 수식에서 를 빼주면 (5) 수식의 KL divergence 꼴로 나타낼 수 있다. 이를 (6) 수식처럼 Jensen-Shannon Divergence로 재구성하면 와 가 얼마나 유사한지 distance 개념으로 표현할 수 있게 된다!
결국 는 로 완전히 동일할 때 최솟값인 0을 갖게 되고, 전체 C(G)의 global minimum은 가 된다.
 이러한 일련의 증명 과정을 통해, 논문에서 제시한 목적 함수는 실제로 가 되도록 하는 것을 보여준다.
이러한 일련의 증명 과정을 통해, 논문에서 제시한 목적 함수는 실제로 가 되도록 하는 것을 보여준다.
3-2. Convergence of Algorithm 1
이제 위의 Algorithm 1에 의해 최적화 과정이 잘 이뤄지는지 살펴본다. 목적함수 V(G,D)를 에 대한 함수로 표현하면 convex하다. 그렇기 때문에 이는 gradient-descent로 풀어낼 수 있으며, 에 대한 충분히 적은 update 만으로도 global optima 로 잘 수렴한다는 것을 알 수 있다.

4. Experiments
MNIST, Toronto Face Database(TFD), CIFAR-10에 대해 학습 진행하였다.
 실제로 GAN이 생성한 이미지 (노란색 박스)를 보면 상당히 그럴싸하다. 학습 데이터와 동일한 형태의 데이터는 생성하지 않은 것으로 보아 단순히 학습 이미지를 '암기'한 것이 아니라는 점 또한 알 수 있다.
실제로 GAN이 생성한 이미지 (노란색 박스)를 보면 상당히 그럴싸하다. 학습 데이터와 동일한 형태의 데이터는 생성하지 않은 것으로 보아 단순히 학습 이미지를 '암기'한 것이 아니라는 점 또한 알 수 있다.
5. Advantages & Disadvantages
1) 장점
계산량 측면:
- 마르코프 체인 사용할 필요 없음
- 역전파 만으로 gradient 학습이 가능
- 학습 중 inference 과정 필요 없음
표현력 측면:
- 마르코프 체인보다 선명한 표현 가능
2) 단점
- 가 명시적으로 표현되지 않음
- G와 D가 학습 과정에서 잘 동기화돼야 함 (D 최적화 없이 G가 너무 많이 최적화되면 안됨)
모델 구현
이제 GAN을 코드로 구현해보고, MNIST 데이터셋으로 학습하였다. 마지막에는 실제로 MNIST 데이터를 생성하도록 하였다.
전체 코드는 깃허브 참조.
먼저 G 모델과 D 모델을 구현했는데, 그 output은 각각 생성된 이미지, 그리고 확률값이다.
## Generator Model
latent_dim = 100
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, 1*28*28),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), 1, 28, 28)
return img
## Discriminator Model
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(1*28*28, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
flattened = img.view(img.size(0), -1)
output = self.model(flattened)
return output다음과 같이 D 모델, G 모델을 순차적으로 훈련해주었다.
for epoch in range(n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# labels
real = torch.ones(imgs.size(0), 1).to(DEVICE)
fake = torch.zeros(imgs.size(0), 1).to(DEVICE)
# real images
real_imgs = imgs.to(DEVICE)
# fake images (generated)
z = torch.normal(mean=0, std=1, size=(imgs.shape[0], latent_dim)).to(DEVICE)
generated_imgs = generator(z)
## Train Discriminator
optimizer_D.zero_grad()
real_loss = loss(discriminator(real_imgs), real) # train on real images
fake_loss = loss(discriminator(generated_imgs), fake) # train on fake images
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
## Train Generator
z = torch.normal(mean=0, std=1, size=(imgs.shape[0], latent_dim)).to(DEVICE)
generated_imgs = generator(z)
optimizer_G.zero_grad()
g_loss = loss(discriminator(generated_imgs), real)
g_loss.backward()
optimizer_G.step()마지막으로 G 모델로 이미지를 생성해보면 나름 MNIST 데이터와 비슷하게 나온다!



상세 코드: https://github.com/tony3ynot/GAN_MNIST
마무리
이렇게 오늘은 이미지 생성 모델 중 첫번째로 GAN을 알아보았다. 생성 모델 분야는 특히 수학적 증명과 확률 통계 관련 수식이 많이 쓰이고 중요하게 다뤄지는 것 같다. 이러한 부분에 초점을 두어 공부해 나가야겠다.
참고 자료
Goodfellow, et al., "Generative Adversarial Nets", 2014.
