
생성 ai 시리즈의 세번째 모델, 흔히 diffusion 모델로 부르는 대망의 DDPM이다. VAE와 마찬가지로 논문의 길이에 비해 수식이 많다. 따라서 본 포스트에는 최대한 DDPM의 핵심 수식과 그 발상을 위주로 알아보도록 하겠다. VAE, U-Net에 대해 미리 알고 있으면 좋을듯 하다.
논문 링크
0. Abstract
 본 연구에서는 diffusion probabilistic 잠재변수 모델로 높은 성능의 이미지 생성 방법을 제시한다. VAE와 마찬가지로 variational bound를 학습하며, score matching 방식의 Langevin Dynamics과 큰 연관성을 보인다.
본 연구에서는 diffusion probabilistic 잠재변수 모델로 높은 성능의 이미지 생성 방법을 제시한다. VAE와 마찬가지로 variational bound를 학습하며, score matching 방식의 Langevin Dynamics과 큰 연관성을 보인다.
*Score-based generative modeling은 좀 더 공부한 뒤 추후 포스트로 자세히 다뤄보겠다.
1. Introduction
GAN, VAE, flow 등 다양한 생성형 모델이 diffusion 기반 모델에 비해 좋은 성과를 내고 있는 상황 속, 본 연구는 diffusion model의 새로운 방향을 제시한다.
Diffusion 모델은 전반적으로 markov chain에 기반하여 두 가지 과정을 거친다.
먼저 아래 그림에서 왼쪽 방향 화살표에 해당하는 변분추론을 진행하는데, 이 과정을 forward process 혹은 diffusion process라 한다. 원본 이미지에 점진적으로 노이즈를 추가하여 완전한 가우시안 노이즈에 도달하도록 한다.
그 후 reverse process, 혹은 denoising process (오른쪽 화살표)를 거쳐 노이즈에서 이미지를 sampling하도록 한다. 바로 이 과정에서 뉴럴 네트워크를 통해 파라미터를 학습한다.
이 모든 과정은 특정 시간 t의 잠재 상태가 바로 직전 상태에만 의존한다는 markov chain의 성질에 기반한 것이다.
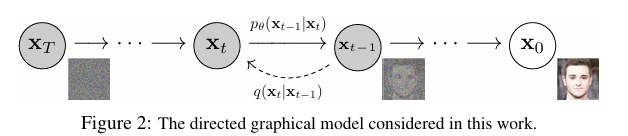
기존에 존재하던 diffusion model은 학습이 효율적이었지만, 높은 퀄리티의 sample 생성은 불가했다. 하지만 본 연구에서는 diffusion model로 다른 이미지 생성 모델에 견줄만한 성능을 보인다. 또한, 적절한 parameterization을 통해 DDPM의 과정이 Langevin dynamics의 denoising score matching과 연결됨을 보인다.
2. Background
1) Reverse Process
Joint distribution 을 reverse process라고 하며, markov chain의 성질을 이용해 아래와 같이 계산할 수 있다. 에서 시작하여 점진적으로 노이즈를 제거한다.
이때 중요한 것은 과정은 우리가 직접적으로 계산할 수 없기 때문에 trainable network를 통해 approximate 하는 것이다 (에 대해 train).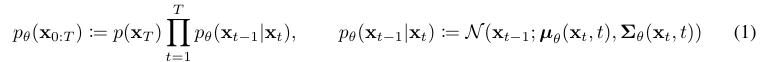
2) Forward Process
입력 이미지에 점진적으로 가우시안 노이즈를 더하는 과정이다. 이 값들은 스케쥴러로 사전 정의가 되어있으며 (학습해서 구할 수도 있다), 최종적인 단계 에서 분산이 1이 되도록 설계되어 있다.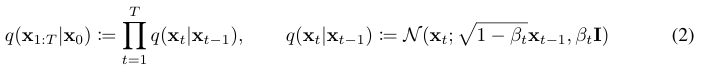 근데 이 과정을 좀 한 번에 할 수 없을까? 특정 시점 t에서의 평균과 분산을 알고 싶은데 이 방식으로 하면 t=0 부터 시작해서 계속 노이즈를 더해야하는 번거로운 과정이 수반된다.
근데 이 과정을 좀 한 번에 할 수 없을까? 특정 시점 t에서의 평균과 분산을 알고 싶은데 이 방식으로 하면 t=0 부터 시작해서 계속 노이즈를 더해야하는 번거로운 과정이 수반된다.
따라서 의 누적곱을 사용해 한 번에 특정 시점 t의 분포를 구하는 closed form 수식이 존재한다!
, 라 정의하였을 때,
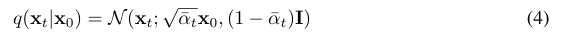
3) Variational Bound (likelihood training)
VAE와 마찬가지로 optimize 과정에서 log-likelihood의 variational bound를 대신 사용한다. 자세한 증명과정은 아래에 첨부하겠다.
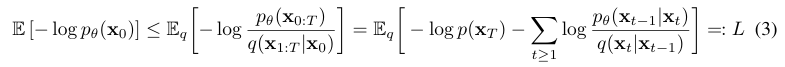 이걸 좀 더 전개하면 아래와 같은 3가지의 loss term의 조합식을 볼 수 있다:
이걸 좀 더 전개하면 아래와 같은 3가지의 loss term의 조합식을 볼 수 있다:
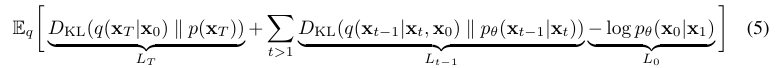 여기서 사실 중요한 부분은 바로 우리가 학습해야하는 이다. KL divergence에 대한 공식이 존재하고 forward process posterior 는 다음과 같이 tractable한 표현이 가능하기 때문에 학습하는데 문제 없다. 다음 섹션에서 더 자세히 뜯어볼 것이다.
여기서 사실 중요한 부분은 바로 우리가 학습해야하는 이다. KL divergence에 대한 공식이 존재하고 forward process posterior 는 다음과 같이 tractable한 표현이 가능하기 때문에 학습하는데 문제 없다. 다음 섹션에서 더 자세히 뜯어볼 것이다.
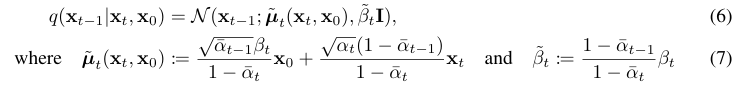
증명과정 1 (3~5번 수식)

증명과정 2 (6~7번 수식)


3. Diffusion models and denoising autoencoders
이제 Loss function의 세 부분을 어떻게 학습하는지 살펴볼 것이다.
3-1.
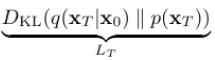 Forward process 부분이며, prior 에 근사하도록 만들기 때문에 prior matching, 혹은 regularization term이라고 볼 수 있다.
Forward process 부분이며, prior 에 근사하도록 만들기 때문에 prior matching, 혹은 regularization term이라고 볼 수 있다.
아까 variance 를 네트워크 내에서 학습가능하도록 정할 수도 있다고 했지만, 여기선 사전 정의된 스케쥴러를 사용하여 상수화한다. 따라서 에는 파라미터가 존재하지 않아 학습 과정에서 무시할 수 있다!
3-2.
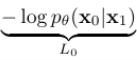 Reconstruction term이라고도 부르는데, reverse process의 마지막 단계이다. 모델이 에서 을 복원할 때의 discrete log-likelihood를 구하며, 다음과 같이 픽셀 단위로 모델링한다.
Reconstruction term이라고도 부르는데, reverse process의 마지막 단계이다. 모델이 에서 을 복원할 때의 discrete log-likelihood를 구하며, 다음과 같이 픽셀 단위로 모델링한다.
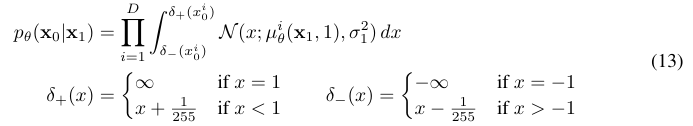
3-3.
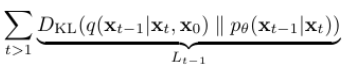 Reverse process 부분이며, denoising matching term이라고도 부른다. 실제 DDPM 학습 시 바로 이 부분만 학습이 일어나므로 사실상 본체라고 볼 수 있다.
Reverse process 부분이며, denoising matching term이라고도 부른다. 실제 DDPM 학습 시 바로 이 부분만 학습이 일어나므로 사실상 본체라고 볼 수 있다.
일단 위에서 언급한대로 KL의 왼쪽 부분은 tractable한 term으로 표현된다.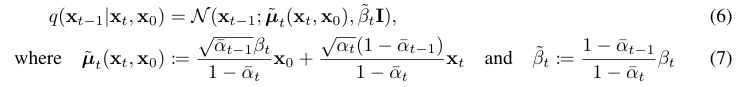 그리고 오른쪽 부분은 우리가 학습할 가 존재하며, 다음과 같이 표현하였다.
그리고 오른쪽 부분은 우리가 학습할 가 존재하며, 다음과 같이 표현하였다. 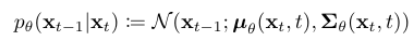 여기서 분산 부분 로 두어 학습 필요없이 t에만 의존하는 상수로 정의한다. (학습 안정성과 샘플링 단순화 효과가 있는듯 하다)
여기서 분산 부분 로 두어 학습 필요없이 t에만 의존하는 상수로 정의한다. (학습 안정성과 샘플링 단순화 효과가 있는듯 하다)
따라서 우린 평균 부분의 에만 집중을 하면 된다!
두 가우시안 분포에 p, q에 대해 KL divergence는 다음과 같이 나타낼 수 있다.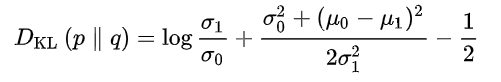 이를 이용해 를 표현해보면:
이를 이용해 를 표현해보면: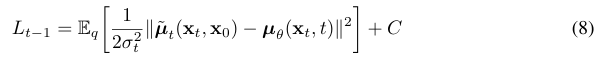 이와 같이 q 부분의 평균과 p 부분의 평균 사이 L2 loss를 구하는 형태가 된다.
이와 같이 q 부분의 평균과 p 부분의 평균 사이 L2 loss를 구하는 형태가 된다.
자, 여기서 한걸음 더 나아가서 를 reparameterization 해보자. 참고로 는 분포에서 샘플링하는 것이다. VAE에서와 동일한 방식으로 노이즈 을 분산에 곱해준다.
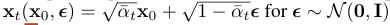 8번 수식의 를 다 바꿔주면 최종적으로 다음과 같이 전개된다 (증명 과정은 아래에):
8번 수식의 를 다 바꿔주면 최종적으로 다음과 같이 전개된다 (증명 과정은 아래에):
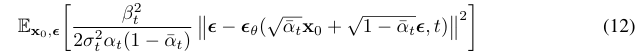 이젠 평균끼리 비교하는게 아니라 노이즈를 비교하게 된다. 즉, t 시점의 노이즈를 학습하고 예측하는 것으로, Langevin dynamics, 그리고 denoising score matching과 일맥상통한다.
이젠 평균끼리 비교하는게 아니라 노이즈를 비교하게 된다. 즉, t 시점의 노이즈를 학습하고 예측하는 것으로, Langevin dynamics, 그리고 denoising score matching과 일맥상통한다.
시각적으로 표현하면 아래와 같이 노이즈가 껴있는 이미지에서 '그 껴있는 노이즈' 자체를 predict하도록 수식이 바뀐 것이다!
저자들은 이 방식이 평균 를 예측하는 방식보다 더 효과적이라고 말한다. 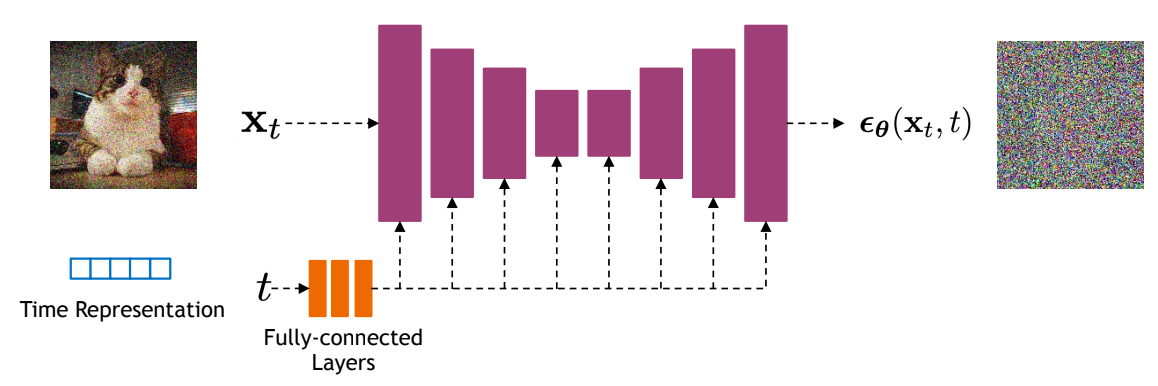
증명과정 (12번 수식)

3-4. Simplified training objective
앞서 정의한 denoising predictor (12번 수식)는 사실 weighting이 된 것이다. 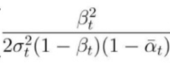 이제, 바로 이 부분을 단순히 1로 두어 훨씬 간단한 loss function을 정의한다.
이제, 바로 이 부분을 단순히 1로 두어 훨씬 간단한 loss function을 정의한다.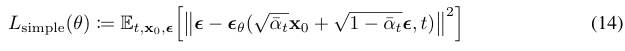 이는 구현 과정이 더 간편할 뿐만 아니라, sample quality 측면에서도 더 좋다고 한다. 기존의 가중치를 보면, 작은 t (노이즈가 아직 덜 추가됨)일 때 훨씬 커진다. 즉 노이즈가 거의 없을 때에 학습 비중을 더 많이 두게 되는데, 우리가 원하는 건 큰 t에서의 어려운 denoising task에 더 집중하는 것이다.
이는 구현 과정이 더 간편할 뿐만 아니라, sample quality 측면에서도 더 좋다고 한다. 기존의 가중치를 보면, 작은 t (노이즈가 아직 덜 추가됨)일 때 훨씬 커진다. 즉 노이즈가 거의 없을 때에 학습 비중을 더 많이 두게 되는데, 우리가 원하는 건 큰 t에서의 어려운 denoising task에 더 집중하는 것이다.
따라서 단순히 이 가중치를 없애는 것으로 모든 t에서 동일한 손실 기여도를 갖도록 할 수 있다.
실제로 DDPM 알고리즘을 보면 이 간단한 loss를 학습에 활용한다.

4. Experiments
시점 T=1000으로 고정하였으며, 는 에서 로 선형적으로 증가하도록 두었다. 또한, 사용하는 network 구조는 U-Net으로, group normalization을 활용하였다. 아마 U-Net은 input과 output의 크기가 같다는 특성 때문에 사용한 것 같다 (와 도 사이즈가 같다).
시점 파라미터인 t는 Transformer의 sinusoidal position embedding을 사용해 모델에 입력해주었다. Self-attention도 빼놓지 않았다.
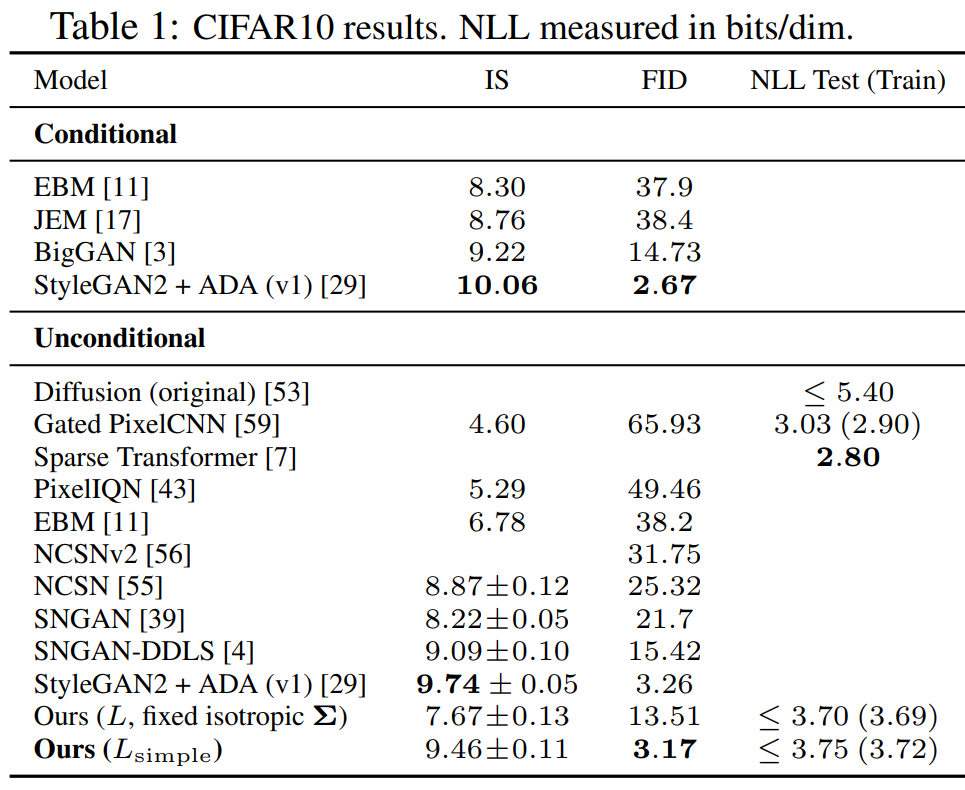 실험 결과 다른 모델들과 비교했을 때 뛰어난 성능(특히 FID)을 보여준다.
실험 결과 다른 모델들과 비교했을 때 뛰어난 성능(특히 FID)을 보여준다.
 실제로 생성한 이미지들을 보면 상당히 잘 생성해낸다는 것을 알 수 있다.
실제로 생성한 이미지들을 보면 상당히 잘 생성해낸다는 것을 알 수 있다.
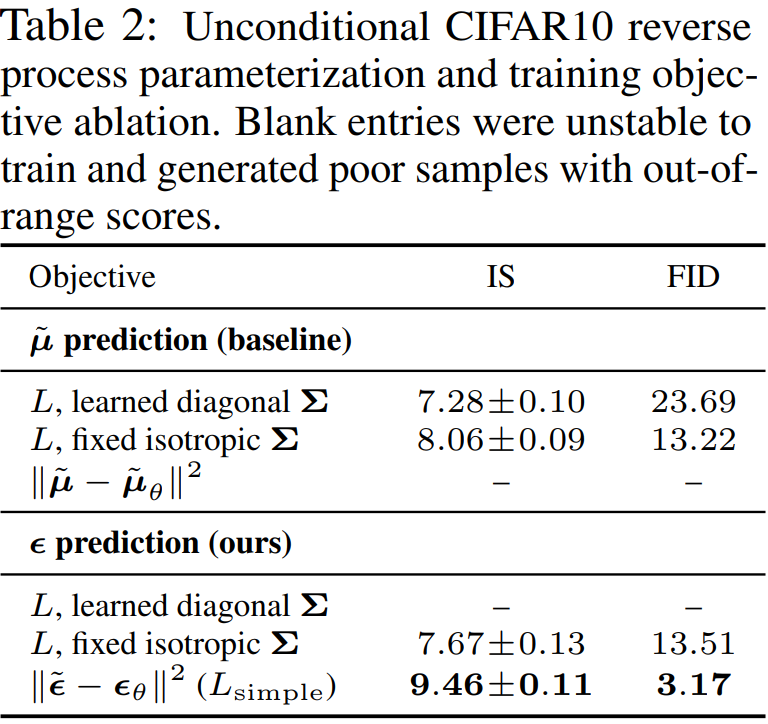 위에서 설명하였듯, loss function에서 분산을 학습할 때와 고정할 때, 평균을 예측할 때와 노이즈를 예측할 때, 그리고 또는 을 사용할 때 등을 비교한 결과다. Reverse process의 분산을 고정하고, 노이즈 을 예측하고, 그리고 을 사용할 때 가장 성능도 좋고 학습도 안정적이다.
위에서 설명하였듯, loss function에서 분산을 학습할 때와 고정할 때, 평균을 예측할 때와 노이즈를 예측할 때, 그리고 또는 을 사용할 때 등을 비교한 결과다. Reverse process의 분산을 고정하고, 노이즈 을 예측하고, 그리고 을 사용할 때 가장 성능도 좋고 학습도 안정적이다.
아래는 DDPM이 점진적으로 이미지를 생성해나가는 과정을 보여준다.

마지막으로 이건 두 이미지 사이 가중치를 두어 interpolation 한 결과다.

모델 구현
이제 DDPM을 실제로 구현해보고 이미지를 생성해보겠다. CIFAR-10 데이터셋으로 훈련하였다.
전체 코드는 깃허브 참조.
먼저 모델 구조는 위에서 간략하게 설명했듯이 U-Net을 따른다. 다만 attention block, time embedding, group norm 등 다양한 기법이 적용됐는데, 여기서는 자세히 다루지 않겠다. 아래와 같이 허깅페이스의 diffusers 모델을 그냥 불러올 수도 있다.
from diffusers import UNet2DModel
model = UNet2DModel(in_channels=3, out_channels=3, block_out_channels=(32, 64, 128, 128))만약 U-Net도 구현하고 싶다면 전체 코드를 참조하길 바란다.
## U-Net Architecture
class UNet(nn.Module):
def __init__(self, img_channels=3, n_channels=32, expansion=(1, 2, 2, 1), attn=(False, False, True, True), n_blocks=2):
super().__init__()
n_resolutions = len(expansion)
self.conv1 = nn.Conv2d(img_channels, n_channels, 3, padding=1)
self.time_emb = SinusoidalTimeEmbedding(n_channels*4)
# down sampling (encoder)
down = []
out_channels = in_channels = n_channels
for i in range(n_resolutions):
out_channels = in_channels * expansion[i]
for _ in range(n_blocks):
down.append(DownBlock(in_channels, out_channels, n_channels*4, attn[i]))
in_channels = out_channels
if i < n_resolutions - 1:
down.append(DownSample(in_channels))
self.down_layers = nn.Sequential(*down)
# connection
self.middle_layers = MiddleBlock(out_channels, n_channels*4)
# up sampling (decoder)
up = []
in_channels = out_channels
for i in reversed(range(n_resolutions)):
out_channels = in_channels
for _ in range(n_blocks):
up.append(UpBlock(in_channels, out_channels, n_channels*4, attn[i]))
out_channels = in_channels // expansion[i]
up.append(UpBlock(in_channels, out_channels, n_channels*4, attn[i]))
in_channels = out_channels
if i > 0:
up.append(UpSample(in_channels))
self.up_layers = nn.Sequential(*up)
self.norm = nn.GroupNorm(8, in_channels)
self.silu = nn.SiLU()
self.conv2 = nn.Conv2d(in_channels, img_channels, 3, padding=1)
def forward(self, x, time):
x = self.conv1(x)
t = self.time_emb(time)
res = [x]
for layer in self.down_layers:
x = layer(x, t)
res.append(x)
x = self.middle_layers(x, t)
for layer in self.up_layers:
if isinstance(layer, UpSample):
x = layer(x, t)
else:
skip = res.pop()
x = torch.cat((x,skip), dim=1)
x = layer(x, t)
out = self.conv2(self.silu(self.norm(x)))
return out가장 중요한 것은 loss function인데, 논문의 수식을 그대로 구현하면 된다.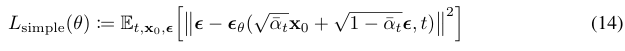
T_steps = 1000
beta = torch.linspace(1e-4, 0.02, T_steps).to(device)
alpha = 1. - beta
alpha_bar = torch.cumprod(alpha, dim=0)
alpha_bar_prev = torch.cat([torch.tensor([1.0], device=device), alpha_bar[:-1]])
sigma2 = (1 - alpha_bar_prev) / (1 - alpha_bar) * beta
def gather(coeff, t, x):
B, *dims = x.shape
out = torch.gather(coeff, index=t, dim=0)
return out.view([B] + [1]*len(dims))
## DDPM Loss Function (Training)
def ddpm_loss(model, x_0):
t = torch.randint(T_steps, size=(x_0.shape[0], ), device=x_0.device)
# sample x_t
mu = gather(alpha_bar, t, x_0)**0.5 * x_0
var = 1 - gather(alpha_bar, t, x_0)
eps = torch.randn_like(x_0) # Gaussian noise
x_t = mu + var**0.5 * eps
eps_theta = model(x_t, t)
loss = F.mse_loss(eps_theta, eps)
return loss
일반적인 딥러닝 모델과 마찬가지로 backpropagation으로 훈련하고 난 뒤, 실제로 랜덤한 에서 이미지를 생성하는 과정을 알아보자. 마찬가지로 논문의 수식을 그대로 적용하면 된다.
# DDPM Sampling
def sample(model, x_T):
x_t = x_T
for step in reversed(range(T_steps)):
t = torch.full((x_T.shape[0],), step, device=device)
eps_theta = model(x_t, t) # predict noise
coef = beta / (1 - alpha_bar)**0.5
mu = gather(1. / alpha**0.5, t, eps_theta) * (x_t - gather(coef, t, eps_theta)*eps_theta)
var = gather(sigma2, t, eps_theta)
z = torch.randn_like(x_t) if step else 0 # Gaussian noise (except last step)
x_t = mu + (var**0.5) * z # sample x_{t-1}
x_0 = x_t
return x_01000개의 이미지를 생성하고 그 중 5개만 뽑아보았다. 총 샘플링 시간은 약 7분 30초 걸렸다.
DDPM_model = UNet(n_channels=32).to(device)
DDPM_model.load_state_dict(torch.load('/content/drive/MyDrive/Colab Notebooks/results/ddpm_model.pth'))
## Check inference time for 1000 samples
start_time = time.time()
with torch.no_grad():
x_T = torch.randn(1000, 3, 32, 32).to(device)
x_0 = sample(DDPM_model, x_T)
x_0 = x_0.permute(0, 2, 3, 1).clamp(0, 1).detach().cpu().numpy() * 255
for i in range(5):
cv2_imshow(x_0[i])
end_time = time.time()
elapsed_time = end_time - start_time
min, sec = divmod(elapsed_time, 60)
print(f"Inference Time: {int(min)}m {sec:.2f}s")




훈련을 오래하진 않아서 정확한 사진은 아니지만 그래도 뭔가 그럴듯한 결과물이 생성됐다. 다만, 샘플링하는데 너무 느린 느낌이다. 따라서 이를 개선하기 위해 제안된 DDIM을 다음 포스트에서 알아보겠다. 또한, 실제로 샘플링해보면서 그 속도와 성능 차이를 비교해보겠다.
상세 코드: https://github.com/tony3ynot/DDPM_and_DDIM
마무리
Diffusion model의 시대를 열었다고도 볼 수 있는 DDPM을 리뷰하고 수식들을 정리하는 과정에서 솔직히 부족함을 많이 느꼈다. Score-based modeling, DDPM을 개선한 DDIM, flow-matching 등에 대해 공부해볼 것이다. 원래 바로 Stable Diffusion을 리뷰하려 했지만 조금 돌아가야 할 것 같다. 조금 더뎌도 확실하게 짚고 가보자......
참고 자료
Ho, et al., "Denoising Diffusion Probabilistic Models", 2020.
권민기님의 Diffusion Model 수학이 포함된 tutorial 영상
코드 참조:
HuggingFace Diffusers 공식 문서
