생성 ai 시리즈의 두 번째 모델로 VAE를 알아볼 것이다. 이 시리즈의 최종 목표인 Diffusion model을 위해서는 반드시 거쳐야 할 관문인데, 수식이 너무 많아서 좀 미뤄왔었다. 이번에 정리해보면서 확률 쪽 공부를 다시 한 것 같다... 아직 부족하지만 최대한 이해한 부분 위주로 살펴보겠다...
논문 링크
0. Abstract
 VAE는 variational inference (변분 추론)을 auto-encoder 구조에 적용하여 계산 불가한 (intractable) posterior의 근사 분포를 계산할 수 있는 방법이다.
VAE는 variational inference (변분 추론)을 auto-encoder 구조에 적용하여 계산 불가한 (intractable) posterior의 근사 분포를 계산할 수 있는 방법이다.
저자들은 이 연구를 통해 두 가지의 성과를 보이는데:
1) 계산 불가한 확률 분포를 효과적으로 근사할 수 있으며,
2) MCMC 등 복잡한 샘플링을 이용하지 않고 역전파 학습이 가능하게 한다.
이는 결국 이미지의 생성으로도 응용이 될 수 있는 것이다.
말로 해선 너무 복잡한 것 같지만, 'variational lower bound', 그리고 'reparameterization trick' 이렇게 두 가지에 초점을 두고 보면 될 것 같다.
1. Introduction
Intractable (계산 불가능한) posterior 분포를 지닌 연속적인 잠재 변수 (latent variable) 기반 모델에서 효율적인 학습과 추론을 하기 위해서는 어떻게 해야 할까?
보통 이 intractable posterior에 근사하는 분포를 정의하여 optimize 하는 방식을 사용하지만, 이 역시 계산이 어렵고 복잡하다.
본 연구에서는 variational lower bound (ELBO)와 reparameterization을 이용해 미분 가능한 학습기 SGVB를 제시한다. 또한 이를 auto-encoder 모델에 적용하여, 복잡한 MCMC 샘플링을 사용하지 않고도 추론과 파라미터 훈련이 가능한 AEVB 알고리즘을 제시한다. 이러한 일련의 과정을 통해, 데이터의 잠재 공간(latent space)을 학습하여 새로운 데이터를 생성하는 모델인 VAE에 최종 도달한다.
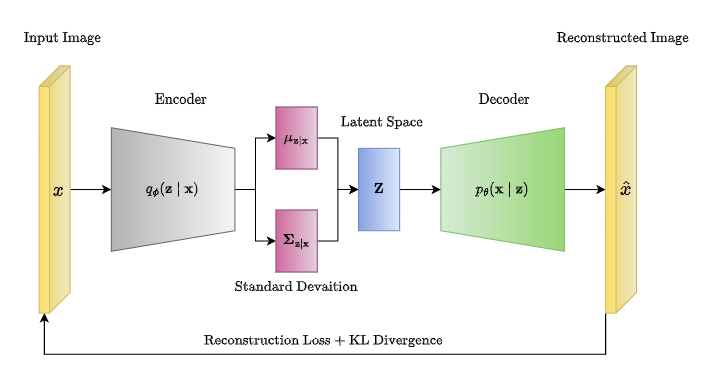
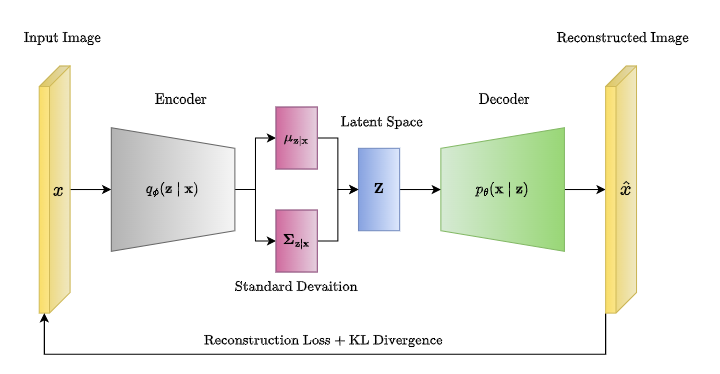 모델 전체적인 구조를 보면, encoder를 통해 input x의 분포를 학습하고 잠재변수 z의 분포 (평균과 분산)를 생성한다. 이는 reparameterization으로 미분가능한 형태로 변형되어 decoder의 input으로 연결된다. 최종적으로 decoder에서 x와 최대한 유사한 데이터를 생성해낸다. 결국 전반적으로 x -> z -> x' 의 매핑 과정을 거치는 것이다.
모델 전체적인 구조를 보면, encoder를 통해 input x의 분포를 학습하고 잠재변수 z의 분포 (평균과 분산)를 생성한다. 이는 reparameterization으로 미분가능한 형태로 변형되어 decoder의 input으로 연결된다. 최종적으로 decoder에서 x와 최대한 유사한 데이터를 생성해낸다. 결국 전반적으로 x -> z -> x' 의 매핑 과정을 거치는 것이다.
2. Method
2-1. 문제 상황
1) Intractability
Auto-encoder에서 잠재변수 z로 x를 생성하는 상황에서 Likelihood는 로 표현할 수 있다. 이 가능도를 에 대해 최대화를 하는 것이 결국 목표가 되는데, 문제는 계산이 안된다는 것이다. 는 gaussian이라 가정을 하더라도 는 굉장히 복잡하기 때문에, z에 대해 전부 샘플링해야 할 것이다.
또한, 이 논문에서 true posterior이라 부르는 역시 계산이 불가능하다.
2) A large dataset
결국 이를 어떻게든 계산하고자 MCMC와 같은 샘플링 방법을 사용해왔는데, 큰 데이터셋에서는 속도가 매우 느려지는 문제가 있다.
따라서 본 연구에서는 이러한 문제들을 해결하기 위해 posterior 를 근사한 를 대신 사용한다. 최대한 이 둘이 근사하도록 를 학습하는 것이 바로 encoder에서 하는 역할이다.
반면 decoder에서는 샘플링한 z로 x를 생성하는 과정으로 를 사용하는데, 여기서는 를 최적화한다.
2-2. The Variational Bound
먼저 개별 데이터의 log-likelihood는 다음과 같이 분해될 수 있다. 자세한 증명은 아래 첨부해 두겠다.
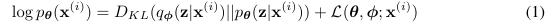 이때 여기서 KL Divergence 식은 계산이 불가하다. 우리가 구해야하는 대상인 posterior 이 존재하기 때문이다. 다만 KL Divergence는 항상 non-negative인 term이므로, 다음과 같이 표현할 수 있다.
이때 여기서 KL Divergence 식은 계산이 불가하다. 우리가 구해야하는 대상인 posterior 이 존재하기 때문이다. 다만 KL Divergence는 항상 non-negative인 term이므로, 다음과 같이 표현할 수 있다.
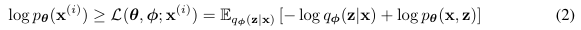 부등호 기준으로 우항을 바로 variational lower bound, 혹은 ELBO라 부른다. 이 부분은 계산이 가능하도록 변환이 가능하므로 이 ELBO를 maximize 하는 것으로 log-likelihood를 간접적으로 optimize 할 수 있는 것이다.
부등호 기준으로 우항을 바로 variational lower bound, 혹은 ELBO라 부른다. 이 부분은 계산이 가능하도록 변환이 가능하므로 이 ELBO를 maximize 하는 것으로 log-likelihood를 간접적으로 optimize 할 수 있는 것이다.
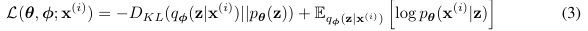 ELBO를 뜯어보면 위와 같이 변형할 수 있다.
ELBO를 뜯어보면 위와 같이 변형할 수 있다.
앞 부분은 KL Divergence 인데, 주목할 점은 우리의 'proxy posterior'인 를 z의 prior과 유사해지도록 학습하게 된다. 다시 말해 인코더 네트워크가 prior matching을 하여 일종의 regularization이 발생한다. 따라서 이 부분을 regularization term이라고 부른다.
*참고로 는 gaussian으로 전제한다.
뒷부분은 디코더 네트워크를 표현한다. z로부터 x를 생성할 때 likelihood를 높이는 방향으로 학습되므로, 이는 reconstruction term이라고 부른다.
이제 이 lower bound를 와 에 대해 편미분하여 optimize 하면 된다!
증명 과정
2-3. Reparameterization Trick
논문의 순서와는 살짝 다르게, reparameterization trick을 먼저 설명하고자 한다.
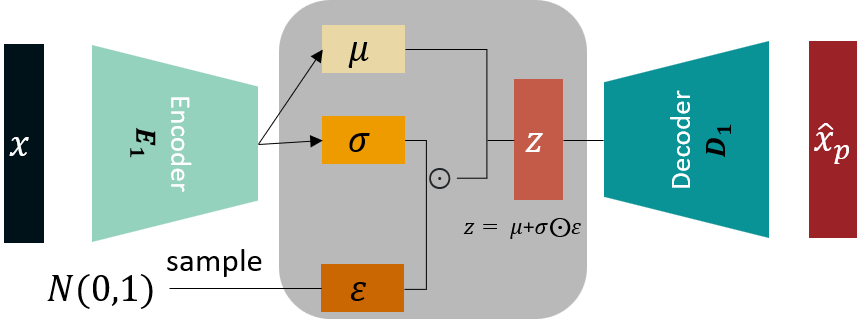 Encoder는 의 분포, 즉 와 를 뽑아내게 된다. 이제 여기서 z를 샘플링하여 decoder로 넘겨주게 되는데, 문제는 미분이 안돼서 encoder 부분은 역전파 학습이 안된다. 어떤 함수가 미분이 가능하려면 결정론적 함수여야 하지만 이 상황에서는 분포에 따른 확률적 랜덤 샘플링인 것이다.
Encoder는 의 분포, 즉 와 를 뽑아내게 된다. 이제 여기서 z를 샘플링하여 decoder로 넘겨주게 되는데, 문제는 미분이 안돼서 encoder 부분은 역전파 학습이 안된다. 어떤 함수가 미분이 가능하려면 결정론적 함수여야 하지만 이 상황에서는 분포에 따른 확률적 랜덤 샘플링인 것이다.
따라서 저자들은 에서 샘플링하는 방식을 결정론적인 함수로 매핑하는 방식으로 바꾼다. 이게 바로 reparameterization trick이다.
 이렇게 z를 라는 함수로 매핑을 한다. 좀 더 구체적으로 표현하자면 다음과 같은데:
이렇게 z를 라는 함수로 매핑을 한다. 좀 더 구체적으로 표현하자면 다음과 같은데:
~
z의 분포에 location-shift를 적용하고 정규분포 을 따르는 랜덤 노이즈 를 적용하는 식으로 reparameterization을 할 수 있다. 이렇게 되면 이제 인코더 파라미터 에 대해서도 학습이 가능해진다!
2-4. SGVB & AEVB
이제 아까 구한 variational lower bound를 다시 보자. Reparameterization trick으로 z에 관한 문제는 해결이 되었고, 이제 이 SGVB estimator를 가지고 와 에 대해 gradient를 구해 optimize하면 학습이 될 것이다.
다만, 여기서 regularization term과 reconstruction term은 계산하는 방식이 좀 다르다. 전자는 비교적 간단한 방식으로 학습을 진행할 수 있지만, 후자는 여전히 MCMC sampling에 기반하여 계산해야 한다. 따라서 아래와 같이 reconstruction term의 expectation 부분을 sampling 계산 방식으로 변형하게 된다. 다만 계산량 이슈로 L=1으로 정의하여 그냥 만 구하게 된다.
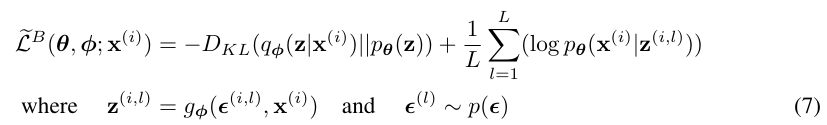
Neg-reconstruction Error 계산
그럼 먼저 reconstruction error를 구체적으로 어떻게 계산하는지 보이겠다. Decoder의 분포 를 데이터 종류에 따라 Bernoulli, 또는 Gaussian으로 가정하게 되는데, 각 경우에 대해 식이 다르게 전개된다.
 먼저 Bernoulli일 경우, cross entropy loss로 치환된다. 아래에 증명 과정이 있다. 이 경우 decoder의 output은 x가 생성될 확률 이다.
먼저 Bernoulli일 경우, cross entropy loss로 치환된다. 아래에 증명 과정이 있다. 이 경우 decoder의 output은 x가 생성될 확률 이다.
다음으로 Gaussian 분포를 가정하면 squared error 형태로 바뀌게 된다. 이 경우 decoder의 output은 와 이다.
Regularization 계산
다음으로 regularization term을 계산해보겠다. KL divergence에 관련된 공식이 이미 존재하지만, 논문에서 사용한 수식을 최대한 활용해보겠다.
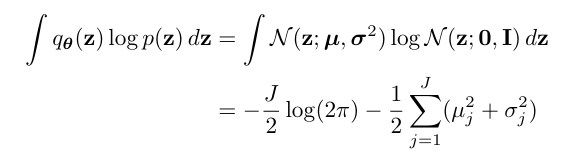
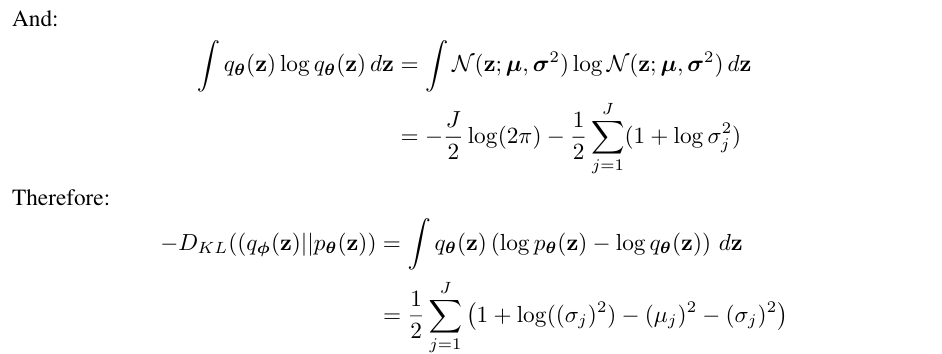 이처럼 미분이 가능한 형태로 변형이 된다!
이처럼 미분이 가능한 형태로 변형이 된다!
증명 과정
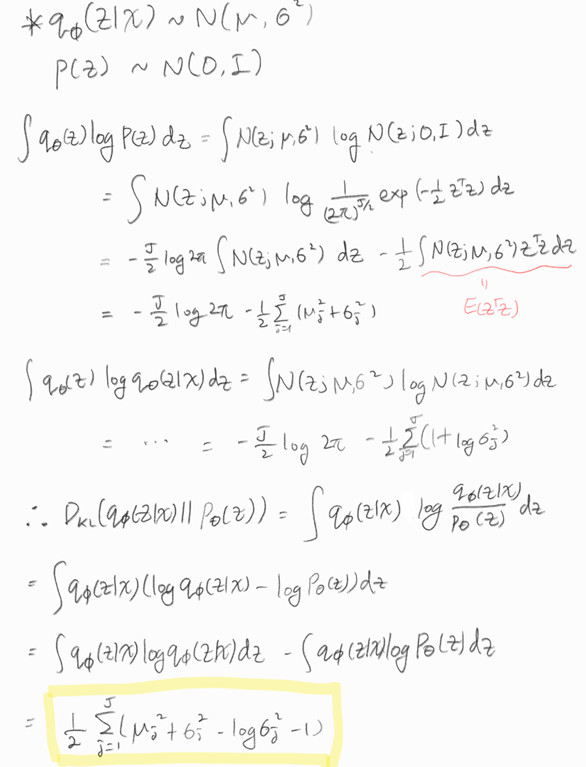
AEVB
최종적으로 전체 데이터셋에 대해 SGVB estimator로 훈련하는 알고리즘 AEVB가 도출된다.

2-5. VAE에서는...?
최종적으로 VAE를 정리해보면 다음 수식을 보면 된다.
먼저 approximate posterior는 정규분포를 가정한다. Encoder의 output은 그 평균과 분산이 된다.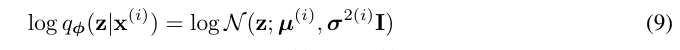 이제 decoder의 input으로 z를 posterior에서 샘플링하는데, reparametrization trick을 사용한다. 여기서 noise 은 역시 정규분포를 가정한다. Prior 도 정규분포를 가정했으므로 아래와 같은 estimator를 사용할 수 있다. 이제 이것을 maximize하는 방향으로 파라미터들을 update하면 된다.
이제 decoder의 input으로 z를 posterior에서 샘플링하는데, reparametrization trick을 사용한다. 여기서 noise 은 역시 정규분포를 가정한다. Prior 도 정규분포를 가정했으므로 아래와 같은 estimator를 사용할 수 있다. 이제 이것을 maximize하는 방향으로 파라미터들을 update하면 된다.
 참고로 훈련을 마친 후 이미지를 생성해보고 싶다면, Gaussian 분포에서 z를 랜덤하게 샘플링하여 decoder에 넘겨주면 된다. 그럼 그 output으로 x에 대한 분포가 나올텐데, 여기서 다시 x를 샘플링하면 이미지 생성이 되는 것이다!
참고로 훈련을 마친 후 이미지를 생성해보고 싶다면, Gaussian 분포에서 z를 랜덤하게 샘플링하여 decoder에 넘겨주면 된다. 그럼 그 output으로 x에 대한 분포가 나올텐데, 여기서 다시 x를 샘플링하면 이미지 생성이 되는 것이다!
3. Experiments
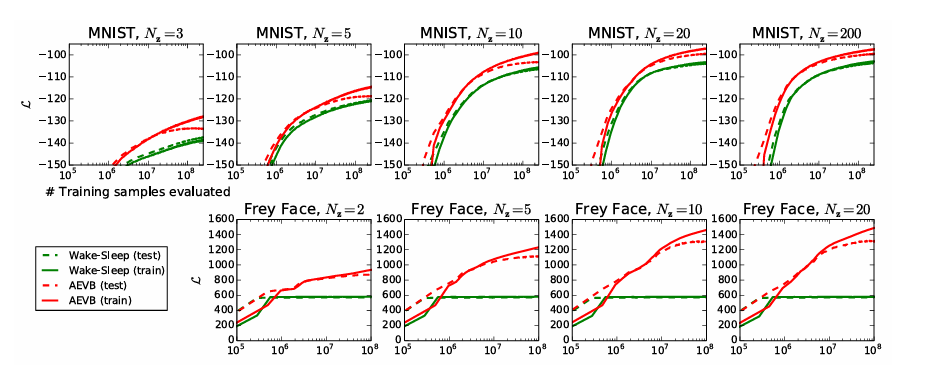 마찬가지로 연속적인 잠재 변수 기반 모델을 학습하는 또다른 알고리즘인 wake-sleep와 AEVB를 비교한 결과다. Lower bound 최적화 시 AEVB가 더 빠르게 수렴하고 높은 성능을 보인다. 뿐만 아니라, 학습 데이터가 늘어나도 overfitting이 발생하지 않는다. 이는 regularization term 덕분이라고 볼 수 있다.
마찬가지로 연속적인 잠재 변수 기반 모델을 학습하는 또다른 알고리즘인 wake-sleep와 AEVB를 비교한 결과다. Lower bound 최적화 시 AEVB가 더 빠르게 수렴하고 높은 성능을 보인다. 뿐만 아니라, 학습 데이터가 늘어나도 overfitting이 발생하지 않는다. 이는 regularization term 덕분이라고 볼 수 있다.
 실제로 VAE가 생성한 이미지들을 보면 상당히 그럴듯하게 나오는 것을 볼 수 있다.
실제로 VAE가 생성한 이미지들을 보면 상당히 그럴듯하게 나오는 것을 볼 수 있다.
마무리
VAE를 정리하는데 시간이 많이 들었다. 생성 모델 분야가 워낙 수식이 중요하다보니 어쩔 수 없나...
다음 모델은 드디어 대망의 Diffusion model, DDPM이다.
참고 자료
