조건부 기댓값
기존의 기댓값을 구하는 방식은
E[y]=integra y * p(y) dy 의 공식을 이용하여서 구하였다. 여기에서 확률 p를 조건부로 바꾸어주면 조건부기댓값이 된다.
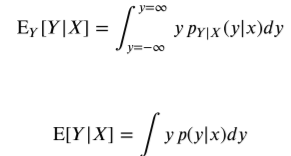
그렇다면 기댓값과 조건부 기댓값의 차이점은 무엇인가?
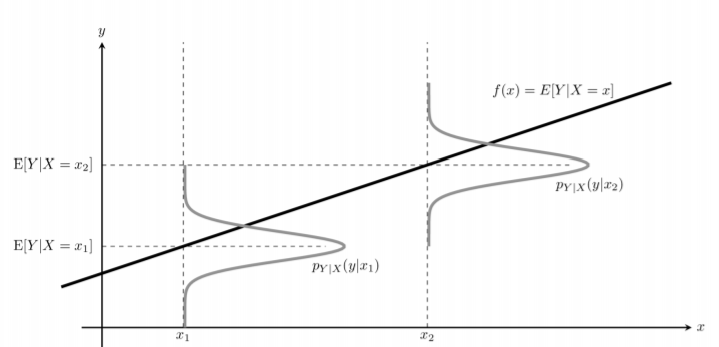
위와 같이 x1, x2일떄의 조건부 확률분포가 존재할때 각 확률분포의 평균을 찾아주는 것이 조건부기댓값이라고 부를 수 있다.
이때 위의 식을 다시금 봐보자. E[y]는 이미 값이 결정된 결정론적 값. 즉, 상수이다. 하지만 E[y|x]는 f(x)값에 따라서 변하게 된다. 표본값 x에 따라서 달라지게 되는 확률변수 값이다.
예측문제
그런데 우리가 이걸 도대체 왜 하냐면 예측문제를 풀기위해서이다.
1. 분류문제
2. 회귀분석문제(숫자 예측)
그래서 우리가 하고 있는 것은 회귀분석을 위해서이다.
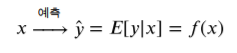
회귀분석이라는 것은 x값이 주어졌을떄 조건부 확률분포 f(x)의 기댓값을 찾아내는 과정이다.
조건부기댓값의 성질
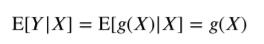
X에 대한 Y값이 결정적으로 나오는 완벽한 상관관계(x에 대한 y값이 바로나오는 경우)를 가진다고 한다면 g(X)는 확률변수가 아닌 상수가 되게 되기 때문에 위와 같이 기댓값을 굳이 구해줄 필요가 업어지게 된다.
마찬가지로 위의 성질로 인하여 아래의 성질이 만족하게 된다.
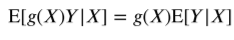
전체 기댓값의 법칙
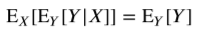
조건부기댓값도 확률변수이므로 조건이 되는 확률변수에 대해 다시 기댓값을 구할 수 있다. 만약 이렇게 된다면 그냥 Y의 기댓값과 다르지 않게 된다.
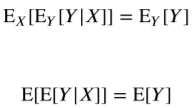
이를 전체 기댓값의 법칙 또는 반복 기댓값의 법칙이라고 한다.
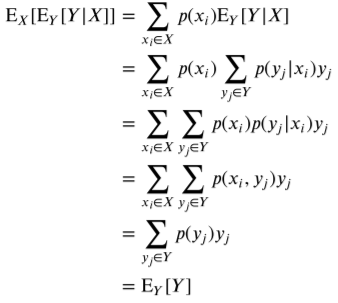
조건부 분산
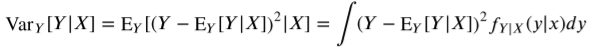
위와 같이 값에 평균을 뺀 값의 제곱에 확률을 곱하면 조건부 분산을 구할 수 있다.
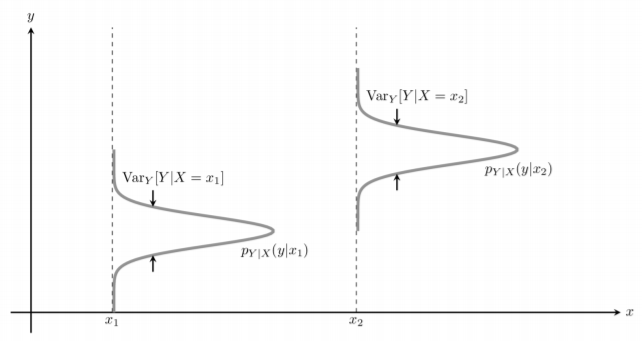
이러한 특징은 그래프로 표현하였을 때 그래프의 폭이 달라지는 것을 결정하는 역활을 맞게 된다.
전체 분산의 법칙
위의 법칙들을 정리하면 다음과 같은 공식을 구해낼 수 있다.
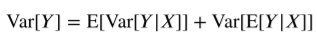
이는 평균적인 폭이 어느정도 된다는 것을 보여주는 식이다. 그래서 이러한 평균적인 폭은 곧 회귀분석에서 값을 찾아냈을 때 오차가 어느정도 된다는 것을 보여주는 지표가 된다.
전체 분산의 법칙 = 예측 오차의 평균
세부적으로
Var[E[𝑌 |𝑋]] : 조건부 기댓값이 얼마나 변화하는 지를 나타내는 값(추후 예측 모델의 복잡도로 사용되게 된다.)
E[Var[𝑌 |𝑋]] : 분산되어 있는 데이터들의 얼마나 펄치어져 있는지에 대한 평균 값
그래서 최종적으로 y값의 분산이 나오게 된다.
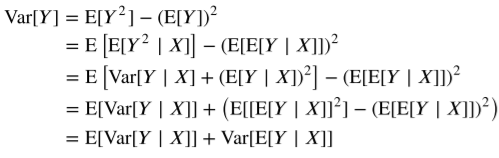
그래서 위의 식을 증명하면 위와 같이 나올 수 있다.
이 증명을 가지고 다음과 같이 쓸 수 있다.
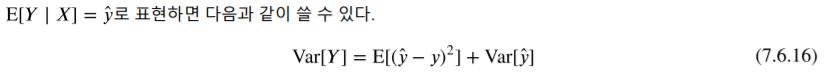
조건부분산의 기댓값 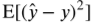 은 예측 오차 즉, 편향(bias)의 평균적인 크기를 뜻한다.
은 예측 오차 즉, 편향(bias)의 평균적인 크기를 뜻한다.
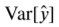 은 예측값의 변동 크기다.
은 예측값의 변동 크기다.
따라서 전체 분산의 법칙이 말하고자 하는 바는 예측 오차의 크기와 예측값의 변동의 합이 일정하므로 예측 오차를 줄이면 모형이 복잡해지고 과최적화가 되며 반대로 모형을 과최적화를 막기위해 단순하게 하면 예측 오차가 증가한다.
편향-분산 상충(Bias–variance Tradeoff) 법칙 이라고도 한다.
