기초통계학
1.7-1. 확률변수와 상관관계
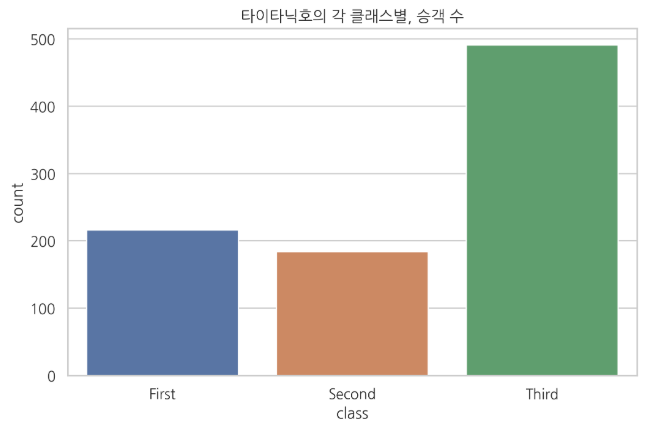
1. 확률적 데이터와 확률변수
2.7-2 기댓값과 확률변수의 변환
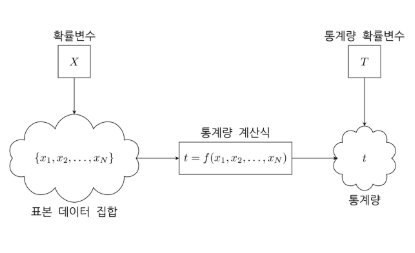
1\. 확률변수의 기댓값
3.7.3 분산과 표준편차
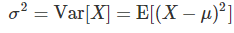
powered by 데이터 사이언스 스쿨모집단의 분산(폭)을 알아내기보면 알겠지만 원래는 s^2 이였던것이 σ^2으로 바뀌었다. 이는 모집단을 표본분산과 구분하기 위해서 새롭게 정의한 기호이다. (s는 σ로 표현하기 때문)상수의 분산은 0 이며 상수곱은 밖으로 나올때
4.7.4 다변수 확률변수
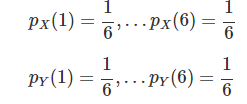
이산확률변수가 두 개 이상 있는 경우에느 각각의 확률분포 뿐만 아니라 복합적인 확률분포를 살펴보아야 한다. 이걸 결합확률분포함수라고 부른다.X와 Y 각각을 확률질량함수로 표현하면 위와 같고X와 Y를 함께 확률질량함수로 표현하면 위와 같다.결합확률질량함수에 대해 하나의
5.7.5 공분산과 상관계수
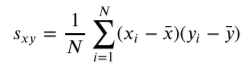
공분산/상관계수 : 다변수 확률변수 간의 상관 관계를 숫자로 나타낸 것표본공분산은 위와 같이 정의된다. 위의 공식을 이해하기 위해 아래의 그림을 보자데이터가 아래의 사각형안에 들어가 있다고 가정하자. 이제 공식은 잘 보면 각 데이터들에 대해 평균으로 부터의 면적을 구하
6.7.6 조건부기댓값과 예측 문제
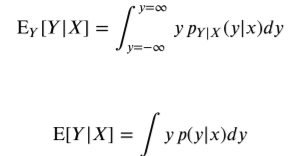
기존의 기댓값을 구하는 방식은Ey=integra y \* p(y) dy 의 공식을 이용하여서 구하였다. 여기에서 확률 p를 조건부로 바꾸어주면 조건부기댓값이 된다.그렇다면 기댓값과 조건부 기댓값의 차이점은 무엇인가?위와 같이 x1, x2일떄의 조건부 확률분포가 존재할때
7.8.1 사이파이를 이용한 확률분포 분석
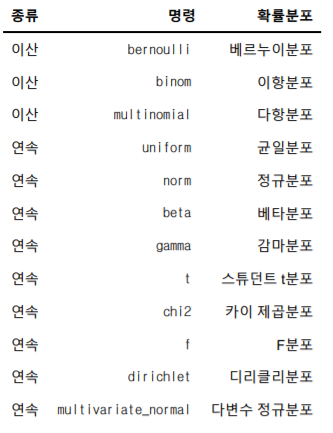
위에서 import한 라이브러리 중에서 stats라는 것이 중요한데, 이유는 아래와 같은 클래스들을 제공하기 때문이다.사용법은 다음과 같이 명령어를 치면 된다.위와 같이 작성하면 클래스들 중에서 정규분포 객체가 만들어지게 된다.이제 만들어진 객체의 모양을 지정하기 위해
8.8.2 베르누이분포와 이항분포(정리중)

결과가 두 가지 중 하나로만 나오는 실험이나 시행을 베르누이 시행이라고 부른다.베르누이 시행으로 나온 값들의 확률을 베르누이 확률이라고 부른다.