
Pandas

- 데이터 분석을 위한 사용이 쉽고 성능이 좋은 오픈소스 python 라이브러리
- R과 Pandas의 특징
- R보다 Pandas가 학습이 쉽습니다.
- R보다 Pandas가 성능이 좋습니다.
- R보다 Python은 활용할수 있는 분야가 많습니다.
- 크게 두가지 데이터 타입을 사용합니다.
- Series : index와 value로 이루어진 데이터 타입
- DataFrame : index, column, value로 이루어진 데이터 타입
라이브러리 설치 : conda install -c ankurankan pgmpy
import numpy as np
import pandas as pd데이터 타입은 2개 Series 와 DataFrame
1. Series : 동일한 데이터 타입의 index와 value로 구성

이렇게 생김
1. 생성
- 인덱스 미설정, 0~10 숫자 5개 인덱스
data = pd.Series(np.random.randint(10,size=5))
- 인덱스 설정, 0~10 숫자 5개 인덱스
(주의, index의 문자열 수가 인덱스 수와 일치하지 않으면 에러남)
data = pd.Series(np.random.randint(10,size=5,index="ABCDE"))
- Dict 형태로 삽입
data2 = pd.Series({"A":3,"B":4,"C":5})
2. 참조, 삽입,
- 인덱스 혹은 값만 보기
data.index # 인덱스만 보기
data.values # 값만 보기
-특정 위치 참조
data["C"]
data.C
data["C"] = 10 #데이터 삽입도 가능
data[["B","C"]] #리스트 형태로 넣으면 두개의 인덱스를 한 번에 볼 수 있음
data[0:1] # 오프셋 인덱스 가능
data[2::2] # 이렇게 뛰엄뛰엄 출력도 가능
3. Series 연산
- join 연산하기 (inner join만 되는 상태)
result = data1 + data2
- outer join 처럼 만들기
result[result.isnull()] = data1 # 이렇게 isnull로
#inner join에서 나온 none 값을 data1 으로 채울 수 잇음
result[result.isnull()] = data22. DataFrame
- 데이터 프레임은 여러개의 Series로 구성
- 같은 컬럼에 있는 value값은 같은 데이터 타입을 갖습니다.

이렇게 행(인덱스) 만이 아닌 열도 생김
각 열은 Series들이라서 한 타입만 들어감
앞으로 써보면 알겠지만 그냥 데이터베이스를 파이썬으로 옮겨놓은 느낌이 많이 남
1. 생성
- dict 형태로 생성하기, value가 리스트인게 차이점
data = {
"name" : ["dss","camp"],
"email" : ["dss@gmail.com","camp@daum.net"]
}
- list 형태로 생성하기, [[]] 형태로 쓰던걸 [{}]로 바뀜
- 또한 한 행을 기준으로 만듬
datas = [
{"name":"dss","email":"dss@gmail.com"},
{"name":"camp","email":"camp@daum.net"},
]
- 이렇게 만든 것들은 모두 DataFrame으로 바꾸어 주어야 함
df = pd.DataFrame(data) #이렇게 하면 인덱스는 0부터 찍힘
- Series랑 다르게 인덱스는 "AB"가 안되고 오직 리스트로만 삽입 가능
df = pd.DataFrame(data,index=["A","B"])
2. 참조, 수정
- 기본적인 것들을 보는 방법
df.index, df.columns, df.values
- 행단위로 데이터를 가져오기
df.loc[0] # 이렇게 하면 행 0번째 데이터 모두 긁어옴
df.loc[0]["email"] #이렇게 하면 0행 email 열 데이터를 긁어옴
- 행단위 수정할때 이렇게 dict형태와 loc을 이용하면
- 1. DataFrame에 데이터가 있다면 수정
- 2. DataFrame에 해당 행이 없다면 생성
df.loc[2] = {"name":"andy","email":"andy@naver.com"}
- 이것도 list를 이용해서 확장이 가능해서 리스트형태로 중복 확인 가능
df.loc[[0,2],["email","id"]]
#이와 같이 앞에 리스트는 행을 뒤의 리스트는 열을 나타내며,
#뒤에서도 비슷하게 사용 된다.
- 또한 칼럼명을 변경할 수도 있다. 이때 inplace 명령어로 칼럼을 넣을 수 있다.
df.rename(columns={"id":"userid"}, inplace = True)
- 열단위 참조, 수정할때는 이렇게 배열처럼 사용
df["id"] #단 데이터가 없다면 에러
df["id"] = "" #이렇게 하면 새로운 열 생성
- 얘도 확장이 가능해서
df[["name","email","id"]] 로 여러 열을 볼 수 있음
- 특수부위 참조
df.head() #위에서 5개 참조
df.head(6) #위에서 6개 참조
df.tail() #아래에서 5개 참조
df.tail(7) #아래에서 7개 참조
3. 기능
- 데이터 타입 확인
df.dtypes
- 데이터 형식 변경 방법
df["id"] = df["id"].astype("int")
# 변환된 결과를 따로 저장해 주는 건 아니다.
df.astype({"id":"int"})
# 이러한 방식으로 바로 바꿀 수도 있다.
4. Class 함수들
1) apply 함수
- map 함수와 동일, 단 함수를 따로 정의해 주어야만 함
def domain(email):
return email.split("@")[1].split(".")[0]
과 같이 도메인 주소만을 뽑아내는 함수가 있을 경우
- 아래처럼 특정 열의 모든 행 데이터에 적용 가능
df["email"] = df["email"].apply(domain)
- 그런데 위의 방식은 귀찮으니 lambda 사용
df["domain"] = df["email"]
.apply(lambda email: email.split("@")[1].split(".")[0])
2) append 함수(행단위), reset_index 함수
- 두 데이터 프레임을 위/아래로 붙이기
- 5행의 두 데이터 프레임이 존재한다고 가정할때 df1, df2
df3 = df1.append(df2)
- 하면 result에는 10행의 df1 그다음 df2 순의 데이터프레임이 생김
- 문제는 이렇게 하면 인덱스도 그대로 되어 있음
- 그래서 방법1
df3 = df1.append(df2, ignore_index=True)
- 방법2
df3.reset_index() #이렇게 하면 인덱스가 새로운 열로 만들어짐
df3.reset_index(drop=True) #이렇게 인덱스가 새로운 열로 만들어지지 않음
#하지만 df3에 저장되지 않음
df3.reset_index(drop=True, inplace=True) #이러면 문제 해결
# 또한 reset_index를 수행하면 Serise 객체를 DataFrame으로 전환한다.
3) concat 함수(행, 열단위)
- append 함수 mk2
- 데이터를 가로, 세로 모두 붙이기 가능
- 단 얘는 클래스 함수라기 보다는 pandas 내장 함수
- 이렇게 하면 세로로 붙여짐 참고로 인덱스는 또 엉망임
df3=pd.concat([df1,df2])
df3=pd.concat([df1,df2]).reset_index(drop=True)
- 세로로 붙이기 : 빈 곳은 none이 됨
df3 = pd.concat([df1,df2],axis=1)
- none 되는 걸 없애기 위한 inner join
df3 = pd.concat([df1,df2],axis=1,join="inner")
4) groupby, sort_values
- 보면 알겠지만 sql문의 groupby 맞음
- 중복된 칼럼을 하나로 합치는 기능
- 추종자들 : agg() / size(), min(), max(), mean()
- 그냥은 못쓰고 반드시 추종자를 뒤에 데리고 다니어야 함
groupby 함수 내에는 묶이는 대상, 뒤에는 추종자
result = df3.groupby("Name").size()
#이렇게 하면 이름의 숫자가 index도 없이 이상하게 나옴
result=df3.groupby("Name").size().reset_index(name="count")
#이렇게 하면 순서가 잘 정렬되어서 나옴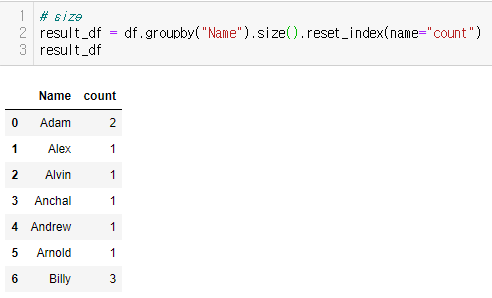
- 여기에서 주의해야하는 것이 agg() 와 다른 추종자들임
- agg는 혼자 독특한 놈이라서 다른 추종자들을 모두 사용할 수 있음 + 혼자 DataFrame 출력
- 나머지 추종자들은 그냥 Series 출력임
result=df3.groupby("Name").agg("mean").reset_index(name="count")
- 이렇게 원하는 추종자를 사용할 수 있으며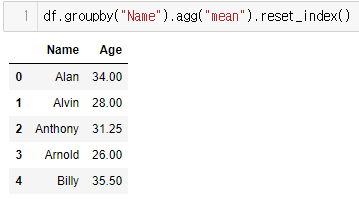
- 결과 역시 혼자 DataFrame임
- 다른 또 하나는 sort_value.
- 흔히 말하는 정렬
result.sort_values(["count","Name"],ascending=False,inplace=True)
- count를 기준으로 내림차순 정렬 후
- Name을 기준으로 동일한 count 값들을 내림차순 정렬 함
한번 ascending이 결정된 곳은 모두 동일하게 따라야 함3. Merge
1. Merge
- Merge 함수를 호출하는 방법은 두가지가 있다.
user_df = DataFrame()
money_df = DataFrame()
# 이와 같이 DateFrame이 두개 선언되어 있다고 할때
user_df.merge(money_df) # Class Method를 호출하는 방법
#하지만 이 경우 merge 결과는 user_df 에 저장되지 않느낟.
result_df = pd.merge(user_df,money_df) # Pandas에 정의된 merge함수 사용 방법
# 이경우에도 결과는 result_df 에 저장해주어야 한다.
- Merge는 Inner Join, Outer Join 이 있는 것과 같이 merge 내부에서도 조절가능
#default는 inner 이다.
result_df = pd.merge(user_df,money_df,how = "outer")
- 하지만 Outer Join의 문제점인 공통되지 않은 것은 Nan으로 채워진다는 문제점이 존재한다.
- 이를 해결하기위해 fillna class method가 존재한다.
result_df.fillna(value = 0,inplace=True)
# value는 NaN을 채울 값, inplace는 바롷 저장을 의미한다.
4. Pivot
- Pivot은 기존의 데이터 프레임을 응용하여 새로운 데이터프레임을 만드는 것을 의미한다.
- 함수를 소개하기 전에 csv 파일에 대해서 알아보자
- csv는 comma separate value의 약자로 데이터들이 ','(comma)를 기준으로 나뉘어 있다.
- 그렇기 때문에 csv에서 comma를 데이터 안에 넣으면 에러가 난다.
- 그럴때는 tsv(tab separate value)를 활용하여 데이터를 나누어 주어야 한다.
- 데이터 읽기
titanic = pd.read_csv("datas/train.csv")
#인코딩 문제가 발생 시 인코딩 값도 넣어준다.
titanic = pd.read_csv("datas/train.tsv",encoding = "euc-kr")
- 인코딩은 보통 세가지를 쓴다.
1. ascii : 영어와 문자만
2. euc-kr : 영어와 한국어와 문자만
3. utf-8 : 세계 모든 언어와 문자만
# utf-8은 당연하게도 위에 세개중 가장 메모리를 많이 찾이한다.
- 데이터 쓰기
pd.to_csv("train.tsv",sep="\t",index = Flase)
#이와 같이 to_csv 함수를 쓰면 tsv 나 csv 파일 모두 만들 수 있다.
-
pivot을 실해하기 전에 가장 중요한 것은 데이터 프레임의 groupby를 실행한 데이터프레임을 따로 가지고 있어야 한다는 점이다.
-
group by 안되어 있으면 ㅈ된다.
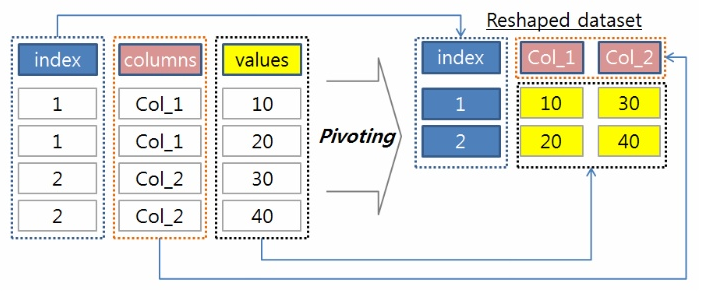
pivot은 쉽게 말해 3개의 컬럼을 하나의 데이터 프레임으로 만드는 것이다. -
pivot도 종류가 pivot(index, column,value)과 pivot_table(value,index,column,aggfunc) 가 있고
pivot은 groupby가 필수이고 pivot_table은 groupby로 만들어지는 새컬럼이 만들어지듯 사용자가 데이터프레임 내부에 새로운 컬럼을 정의해 주어야 한다. 한마디로 pivot_table은 인자로 groupby 비슷한 기능을 받을 수 있다.
- 우선 titanic.csv 파일에서 읽은 데이터를 groupby 해준다.
df1 = titanic.groupby(["Sex","Pclass"]).size().reset_index(name="counts")
result = df1.pivot("Sex","Pclass","counts")
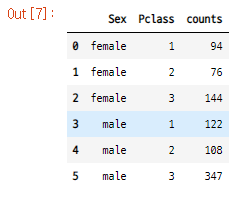
groupby로 만들어진 테이블
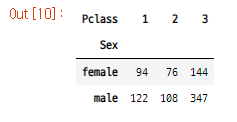
결과물
- pivot_table은 미리 컬럼을 새로 만들어 주어야 한다.
titanic["counts"]=1
- 또한 aggfunc인자로 numpy의 함수들을 넣어준다.
result = pivot_table("counts","Pclass","Survived",aggfunc=np.sum)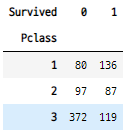
- 이렇게 만들어진 pivot도 데이터프레임이기 때문에 기존 데이터 프레임 연산을 모두 수행할 수 있다.
result["total"] = result[0] + result[1] #특정 컬럼의 합을 저장
result.loc["total"] = result.loc[1]+result.loc[2]+result.loc[3]
예술가