3. Approach #2: Event-based Servers
-
Server maintains set of active connections
- Array of connfd’s
-
Repeat:
- Determine which descriptors (connfd’s or listenfd) have pending inputs
- e.g., using select or epoll functions
- arrival of pending input is an event
- If listenfd has input, then accept connection
- and add new connfd to array
- Service all connfd’s with pending inputs
- Determine which descriptors (connfd’s or listenfd) have pending inputs
-
Details for select-based server in book
-
이벤트 기반의 방법이다. 여기에서는 프로세스가 딱 하나만 있다. connfd의 array를 가지고 있다.
-
connfd 또는 listenfd를 포함한 array를 가지고 있으면서 만약에 file descriptor 각각의 뭔가 pending input이 있다는 것을 확인해서 pending input이 있을때 그때에 해당하는 input에 대해서 맞는 action을 수행한다.
-
select, epoll을 사용해서 file descriptor을 살피어본다.
-
각 event에 맞추어서 해당하는 action을 수행해준다.
-
listenfd에 pending input이 있다면 accept이라는 함수가 connection을 맺어주면 된다. connfd를 받아서 array에 추가해주면 된다.
-
connfd에 해당하는 input이 왔으면 서비스를 해주면된다.
I/O Multiplexed Event Processing
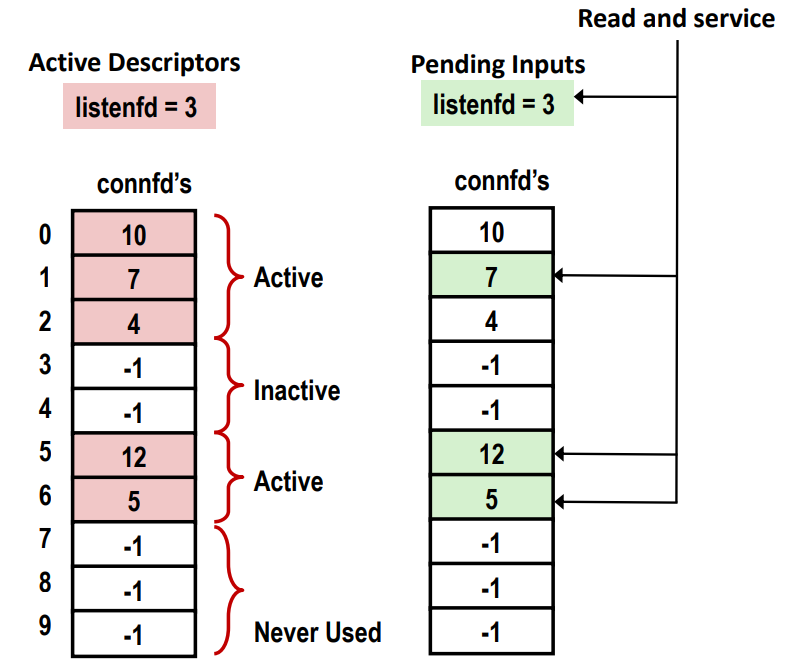
I/O multiplexing기반의 이벤트 처리라고 부른다. Active Descriptor이라고 해서 두가지가 존재한다. listenfd와 connfd가 있다. connfd의 번호가 할당된건 connfd값이 들어가 있는 것이다. -1이 아닌 것은 connection이 맺어진 것이다.
select, epoll함수를 통해서 file descriptor에 pending input이 있는지 확인한다.
만약에 pending input이 있다면 프로세서가 이를 처리해주면된다.
두번째 방식은 프로세스가 하나만 존재한다.
Pros and Cons of Event-based Servers
- One logical control flow and address space.
- Can single-step with a debugger.
- No process or thread control overhead.
- Design of choice for high-performance Web servers and search engines. e.g., Node.js, nginx, Tornado
- 논리적인 control flow가 단 하나이다.
- debugging할때도 단일 address space에 logical control flow도 하나라서 쉽다.
control overhead가 없다.
그래서 고성능 웹서버나 검색엔진에 사용한다.
- – Significantly more complex to code than process- or thread-based designs.
- – Hard to provide fine-grained concurrency
- E.g., how to deal with partial HTTP request headers
- – Cannot take advantage of multi-core
- Single thread of control
- 단점은 코딩하기가 복잡하다.
- fine-graind concurrency를 제공하지 않는다. server에 접속한 client를 handling하다가 중간에 다른 file descriptor에 온 pending input을 처리할 수 없다. 그래서 coarse-graind하게 처리한다.(https://icthuman.tistory.com/entry/FineGrained-vs-CoarseGrained) 그래서 한 작업이 계속 작업중이면 다른 pending input을 처리 못한다.
- 그래서 multi-core 기능을 적극적으로 활용못한다.
4. Approach #3: Thread-based Servers
- Very similar to approach #1 (process-based)
- …but using threads instead of processes
Traditional View of a Process
- Process = process context + code, data, and stack
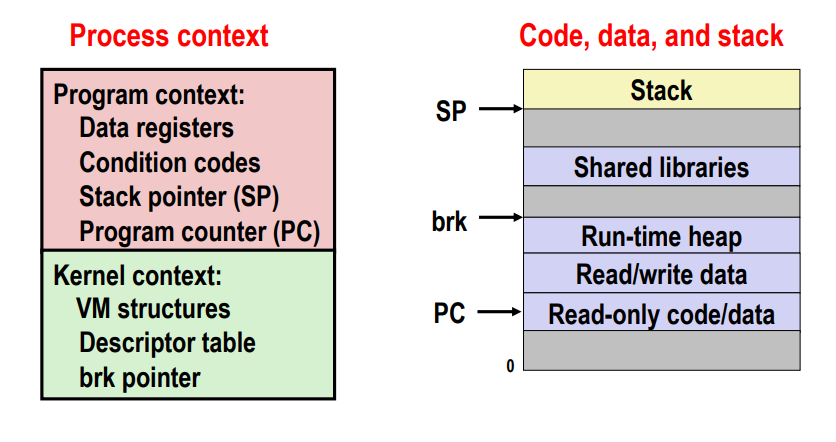
프로세스는 Process context와 프로세스와 관련된 code,data,stack으로 구성되어 있다.
Alternate View of a Process
- Process = thread + code, data, and kernel context
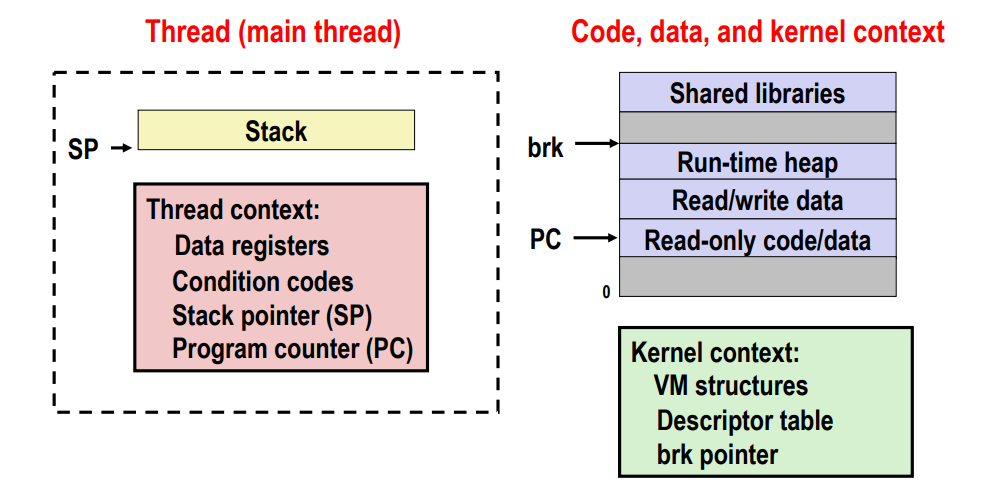
프로세스를 스레드 관점으로 볼 수 있다. program context와 stack을 스레드로 보고 코드 data 부분은 그대로 있고 keren context로 나뉘어진다.
스레드마다 스택이랑 thread context가 있다고 생각하면 된다.
A Process With Multiple Threads
- Multiple threads can be associated with a process
- Each thread has its own logical control flow
- Each thread shares the same code, data, and kernel context
- Each thread has its own stack for local variables
- but not protected from other threads
- Each thread has its own thread id (TID)
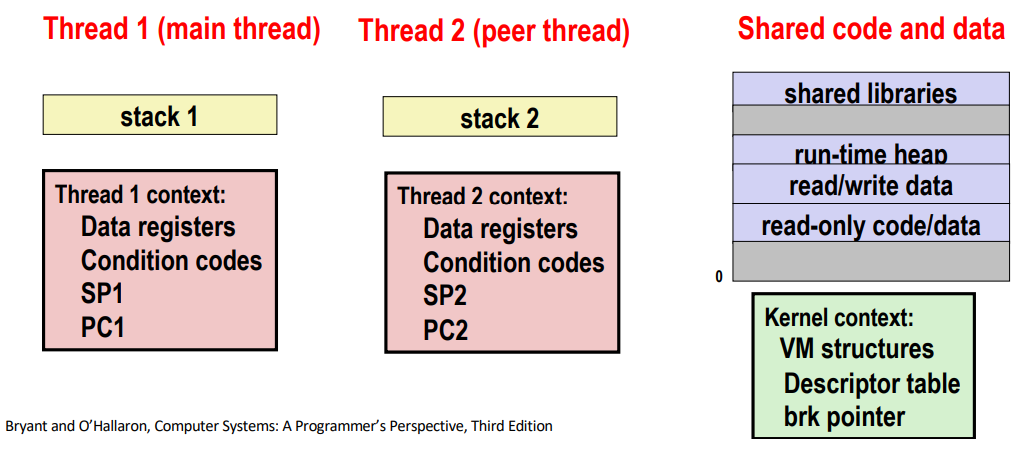
코드와 데이터부분, kerne context는 shared 부분이다. thread는 여러개 만들 수 있어서 code와 data를 접근하는게 여러개가 있을 수 있어서 이것을 thread라고 부른다. 각 스레드는 각자의 logical control flow를 가지고 있다.
스레드 아이디를 가지고 있고, 각각 보호된다.
Logical View of Threads
- Threads associated with process form a pool of peers
- Unlike processes which form a tree hierarchy
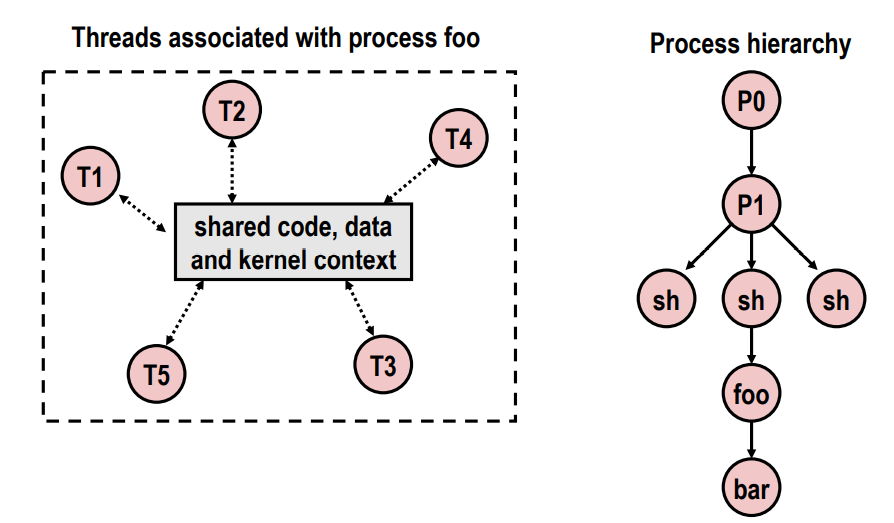
- Unlike processes which form a tree hierarchy
프로세스는 위와 같이 hierarchy를 가지고 있다면 thread는 코드, 데이터, 커널을 공유하고 있는데 이걸 공유하는 execution flow가 여러개가 있을 수 있다.
Concurrent Threads
- Two threads are concurrent if their flows overlap in time
- Otherwise, they are sequential
- Examples:
- Concurrent: A & B, A&C
- Sequential: B & C
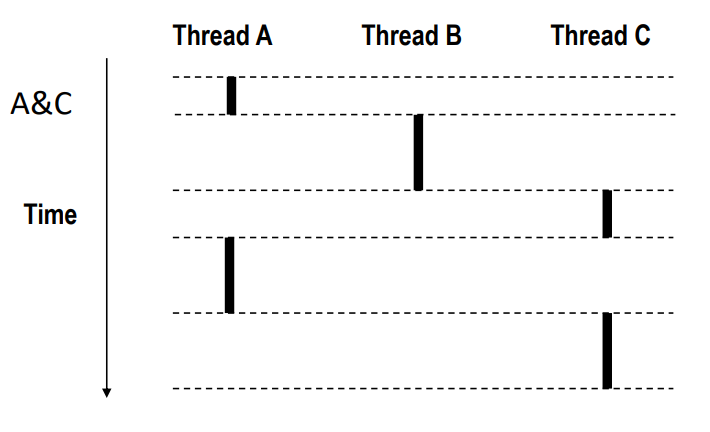
스레드 관점에서 보면 두개의 스레드는 그들의 execution flow가 시간에 따라서 overlap 될 수 있어서 concurrent하다고 한다.
이 세개의 스레드들은 한 프로세스의 code, data, kernel structure을 공유하고 있다. 하지만 execution flow는 각각 다르다.
B와 C는 overlap 되는 순간이 없기 떄문에 sequential하다고 부른다.
Concurrent Thread Execution
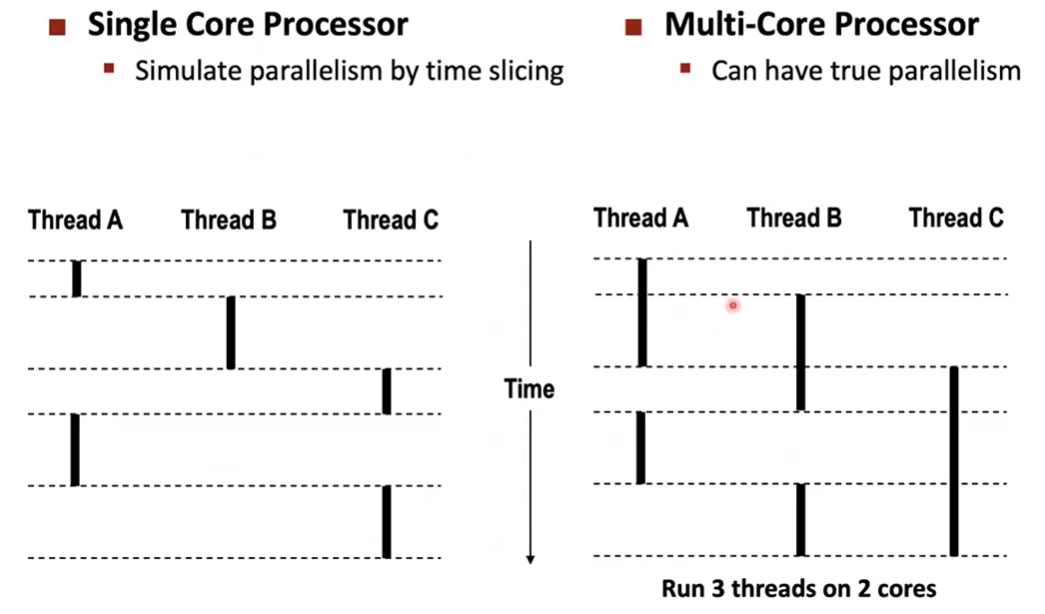
싱글이면 왼쪽처럼되지만 멀티이면 오른쪽과 같이 실행된다.
Threads vs. Processes
- How threads and processes are similar
- Each has its own logical control flow
- Each can run concurrently with others (possibly on different cores)
- Each is context switched
스레드는 코드와 데이터 공유, 프로세스는 공유 안함
- How threads and processes are different
- Threads share all code and data (except local stacks)
- Processes (typically) do not
- Threads are somewhat less expensive than processes
- Process control (creating and reaping) twice as expensive as thread control
- Linux numbers:
- ~20K cycles to create and reap a process
- ~10K cycles (or less) to create and reap a thread
- Threads share all code and data (except local stacks)
비슷한점은 각자 자신의 local stack이 존재한다.
스레드는 프로세스에 비해서 less expensive하다. 프로세스는 20K정도 걸리는데 thread는 10K정도 걸린다.
5. Posix Threads (Pthreads) Interface
- Pthreads: Standard interface for ~60 functions that manipulate threads from C programs
- Creating and reaping threads : 생성 및 reaping
- pthread_create()
- pthread_join()
- Determining your thread ID : 나의 스레드 id 반환
- pthread_self()
- Terminating threads : 스레드 제거
- pthread_cancel()
- pthread_exit()
- exit() [terminates all threads] : 현재 프로세스에 있는 모든 스레드를 제거한다.
- Synchronizing access to shared variables : 공유변수가 있다면 synchronizing 해야 한다.
- pthread_mutex_init
- pthreadmutex[un]lock
- Creating and reaping threads : 생성 및 reaping
커널에서 Posix Standard에 따라서 Pthread interface를 제공한다. 일반적으로 60개정도의 Pthread함수를 제공해주는데 C program을 통해서 스레드를 우리가 제어할 수 있다.
The Pthreads "hello, world" Program
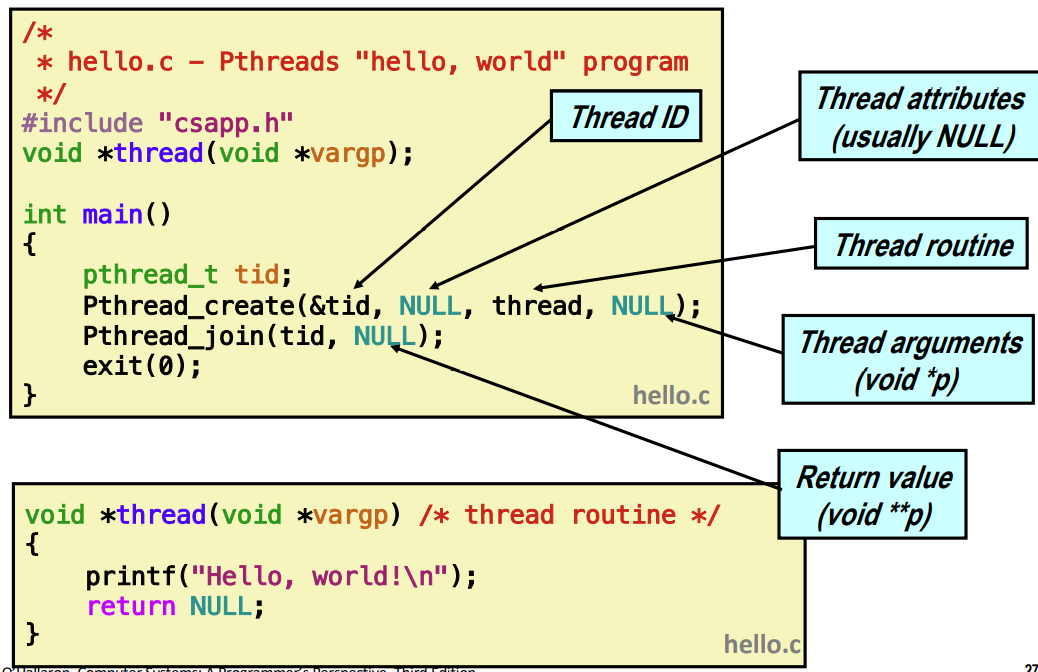
Pthread "hello, world" 프로그램이다.
main 함수에서 Pthread_create 하는데 새로운 프로세스를 만드는 것이 아닌 새로운 execution flow를 만드는 거라고 생각하면 된다. 인자로 Thread ID를 받는다. 스레드의 속성, 스레드가 실행할 함수, thread routine이 받는 인자이다.
그래서 스레드가 생성되면서 Thread routine이 실행된다.
Execution of Threaded “hello, world”
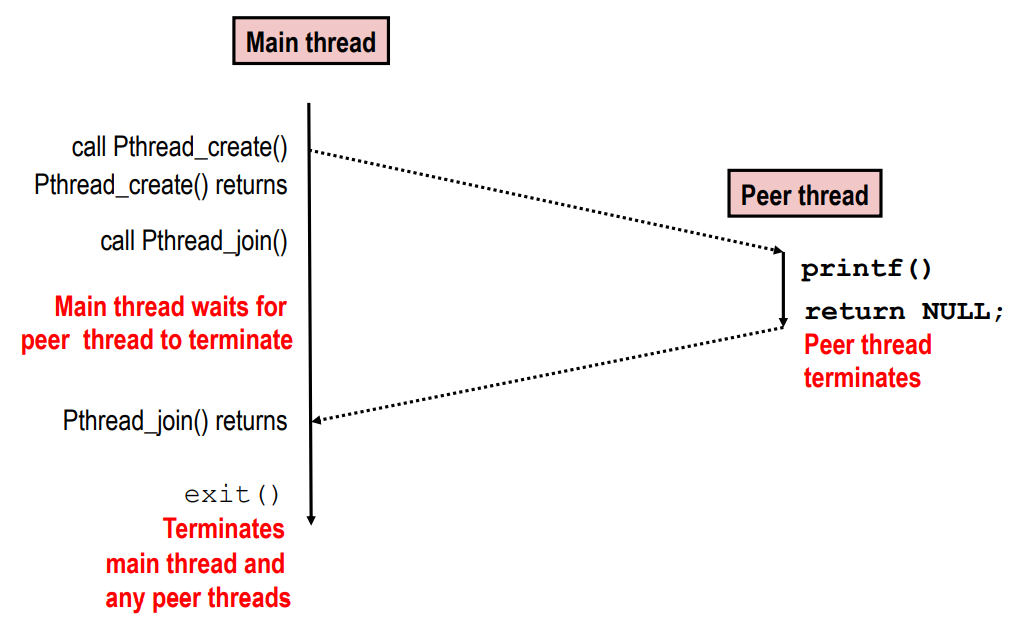
execution flow상에서는 스레드를 생성하고 peer thread가 생성이 된다. PThread는 새로 생긴 스레드를 reaping 하기 위해 돌아오는 것을 기다린다. 그리고 Peer thread는 THREAD 함수에 있던것을 실행하고 돌아온다. 그리고 Pthread_join함수를 호출하게 된다.
CPU가 하나라면 각 스레드의 실행 사이의 context swith가 이루어진다.
Thread-Based Concurrent Echo Server
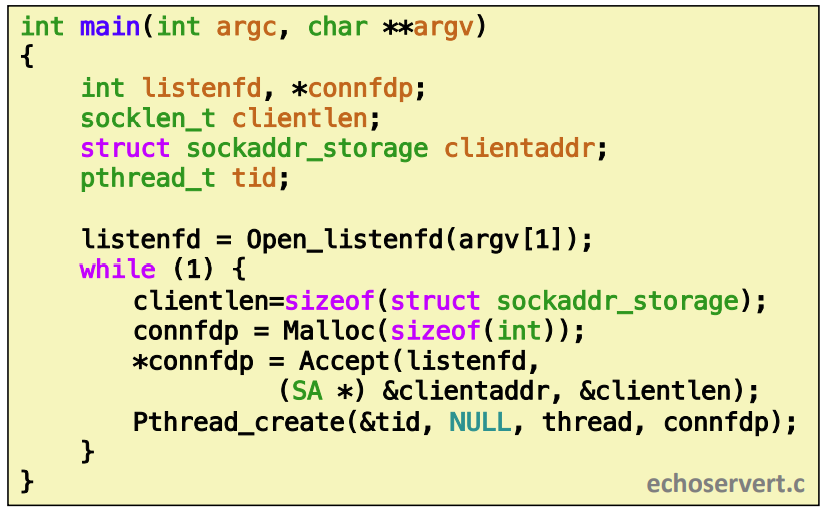
- malloc of connected descriptor necessary to avoid deadly race (later)
while에서 listen하다가 accept하게 되는데 그때 Malloc으로 connfdp를 하나 만든다. 이건 반드시 해야 한다.
스레드 Accept하고 Pthread_create 해서 thread 함수를 수행하게 한다. 그리고 스레드를 만들어 스레드의 file descriptor을 만들어서 인자로(connfdp) 전달해준다. 그럼 스레드 하나가 만들어진거다.

- Run thread in “detached” mode.
- Runs independently of other threads
- Reaped automatically (by kernel) when it terminates
- Free storage allocated to hold connfd.
- Close connfd (important!)
스레드 안에서는 Pthread_detach모드로 실행한다. 이건 다른 스레드와 독립적으로 하되 이게 termination 되었을때 커널이 자동적으로 reaping해준다.
메모리 누수를 줄이기 위해 끝나기 전에 Free해주고 echo로 응답 메세지를 출력한다. 그리고 Close로 해주어 메모리 누수를 없앤다.
Thread-based Server Execution Model
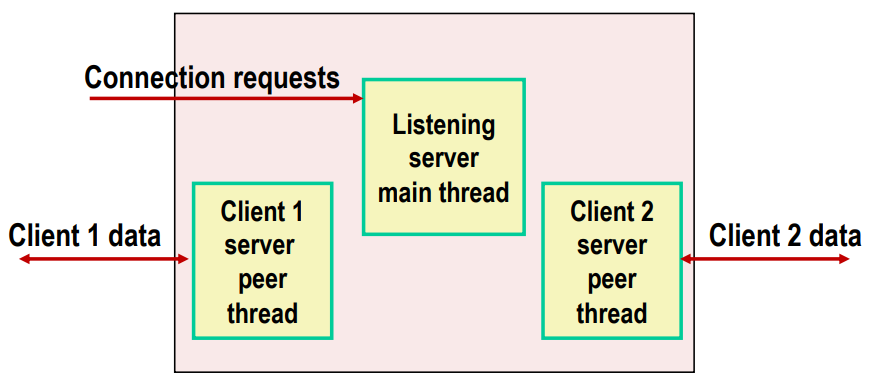
- Each client handled by individual peer thread
- Threads share all process state except TID
- Each thread has a separate stack for local variables
connection request가 오면 client1, client2 thread를 각각 띄어준다. 각각 독립적으로 돌아가는 individual peer thread에 의해서 client를 handling하고 있다.
이 스레드들은 pid는 다르지만 한 프로세스에 있어서 code, kernel, data를 공유하고 있다.
Issues With Thread-Based Servers
- Must run “detached” to avoid memory leak
- At any point in time, a thread is either joinable or detached
joinable : 다른 스레드가 그 스레드를 kill할 수 있다.
detached : 다른 스레드가 kill, reap 불가 대신 커널이 자동으로 reap해준다. - Joinable thread can be reaped and killed by other threads
- must be reaped (with pthread_join) to free memory resources
- Detached thread cannot be reaped or killed by other threads
- resources are automatically reaped on termination
- Default state is joinable
- use pthread_detach(pthread_self()) to make detached
- At any point in time, a thread is either joinable or detached
- Must be careful to avoid unintended sharing
- For example, passing pointer to main thread’s stack
- Pthread_create(&tid, NULL, thread,
(void *)&connfd);
sharing을 통해서 문제가 생길 수 있다. 스레드가 생성되었는데 메인 스레드 스택에 있는 변수를 reference할 수 있다.
- Pthread_create(&tid, NULL, thread,
- For example, passing pointer to main thread’s stack
- All functions called by a thread must be thread-safe
- (next lecture)
Pros and Cons of Thread-Based Designs
- Easy to share data structures between threads
- e.g., logging information, file cache
- Threads are more efficient than processes
스레드 기반의 장점 : 스레드들끼리 공유하고 있어서 data share가 쉽다.
context switch overhead도 줄어든다.
- – Unintentional sharing can introduce subtle and hard-to-reproduce errors!
- The ease with which data can be shared is both the greatest strength and the greatest weakness of threads
- Hard to know which data shared & which private
- Hard to detect by testing
- Probability of bad race outcome very low
- But nonzero!
- Future lectures
의도하지 않은 data sharing이 발생가능
Summary: Approaches to Concurrency
- Process-based
- Hard to share resources: Easy to avoid unintended sharing
- High overhead in adding/removing clients
- Event-based
- Tedious and low level
- Total control over scheduling
- Very low overhead
- Cannot create as fine grained a level of concurrency
- Does not make use of multi-core
- Thread-based
- Easy to share resources: Perhaps too easy
- Medium overhead
- Not much control over scheduling policies
- Difficult to debug
- Event orderings not repeatabl
