학부때 한번 들어놔서 다행이다. 휴.
데이터 베이스란?
정보 및 데이터의 집합, 혹은 데이터들이 저장된 저장소를 의미한다. 이러한 데이터 베이스는 데이터 베이스 관리 시스템 (DBMS)에 의해 제어, 관리 된다.
데이터 베이스는 크게,
- 관계형 데이터 베이스 (MySQL, Postgres, Oracle DB 등)
- 비관계형 데이터 베이스 (MongoDB, Redis 등)
로 나뉜다.
관계형 데이터 베이스 / 비관계형 데이터 베이스
관계형 데이터 베이스란, 데이터를 저장하는 여러가지 테이블이 서로 연결된 형태의 데이터 베이스를 뜻한다. 비관계형 데이터 베이스는, 그렇지 않은 형태의 데이터 베이스를 뜻한다.
1. 관계형 데이터 베이스
- 장점
- 데이터를 효율적으로 저장 및 관리 할 수 있다.
- 데이터의 완전성이 보장된다.
- 단점
- 데이터의 구조 및 테이블의 연결이 미리 확정되기 때문에, 데이터 베이스 변화와 확장이 유연하지 못하다.
2. 비관계형 데이터 베이스
- 장점
- 데이터의 구조가 정해지지 않았으므로, 변화에 유연. (단순하게 추가하면 되기때문.)
- 확장하려면 그냥 서버를 늘리면 된다.
- 단점
- 데이터 완전성이 덜 보장.
- 트랜잭션이 불안정.
관계형 데이터 베이스
우리는 앞으로의 프로젝트에서 관계형 데이터 베이스를 사용할 것이니, 관계형 데이터 베이스에 대해서만 좀더 깊게 알아보자.
관계형 데이터 베이스에서는 정보들이 이차원 테이블에 저장된다. (마치 엑셀 스프레드시트 처럼)

1. 왜 관계형?
테이블 하나에 모든 정보를 저장하면 되지 왜 굳이 테이블을 나누어 연결하는건가 라는 의문이 든다. 하지만 그렇게 하면 컴퓨터 자원을 효율적으로 사용하지 못한다. 예를 들어, 위의 suppliers 테이블을 보면, 첫번째 3줄에서 S#, STATUS, CITY 열이 중복되어 입력되는 것을 볼 수 있다. 만약 처리하는 데이터의 갯수가 억 단위라면, 위와 같은 중복을 줄여주는 것으로 많은 양의 컴퓨터 자원을 아낄 수 있을 것이다.
2. 일대일 관계
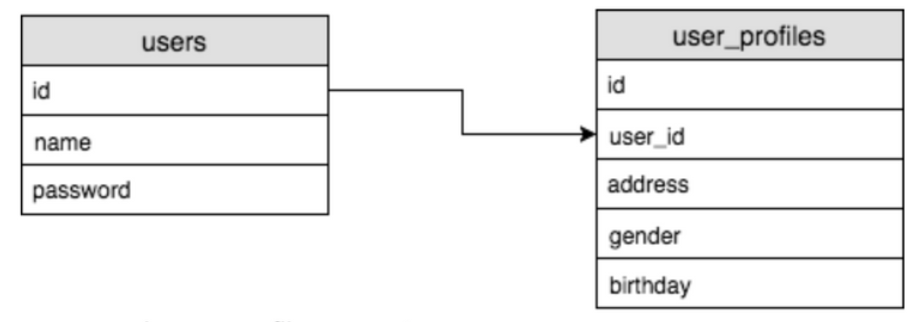
기본적으로 연결관계에 있는 테이블은 하나의 테이블에 다른 테이블의 정보를 담는 열을 포함한다. 위의 예제에서는 user_id 가 그것.
일대일 관계란, 한 데이터는 다른 테이블의 오직 하나의 데이터와 연결 됨을 의미한다. 예제 테이블에서 볼수 있듯, 한명의 고객 ID는 하나의 관련 정보(address, gender, birthday) 데이터와 연결된다.
3. 일대다 관계
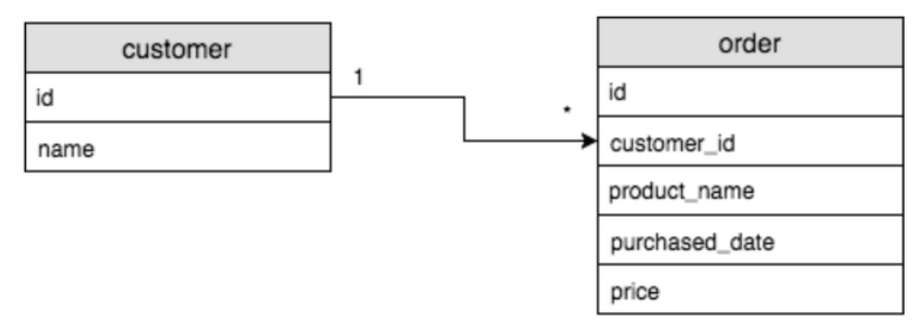
일대다의 관계는, 한 데이터가 여러 데이터와 연결됨을 의미한다. 예제 테이블에서 볼 수 있듯, 한명의 고객 ID는 주문 테이블의 여러가지의 물품 데이터와 연결될 수 있다.
4. 다대다 관계
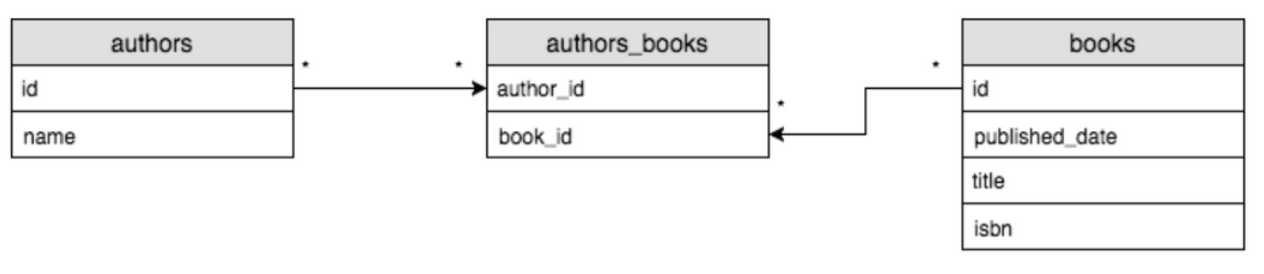
다대다 관계는, 말 그대로 여러 데이터가 여러개의 데이터가 여러개의 또 다른 데이터와 연결될 수 있음을 말한다. 한 작가는 여러 책을 쓸 수 있고, 또 책들은 여러 작가에 의해 쓰일 수 있다.
다대다 관계를 실제로 구현하기 위해서는 중간 테이블이 필수이다. 하나의 열에 여러 개의 데이터가 저장되는 꿈 같은 일은 일어나지 않기 때문 ⭐️
스타벅스 음료 모델링 실습
관계형 데이터베이스 형식을 이용하여, 스타벅스의 음료 종류를 모델링 해보도록 하자. 구현 사항은 음료 이름, 음료 이미지, 음료 설명, 카테고리, 영양 정보, 알러지 정보, 신상 정보 이다.
1. 스프레트 시트에 직접 데이터 작성
직접 데이터를 작성해 보는 것이 테이블을 어떻게 나누어야 할지 파악하는데 도움이 많이 된다.
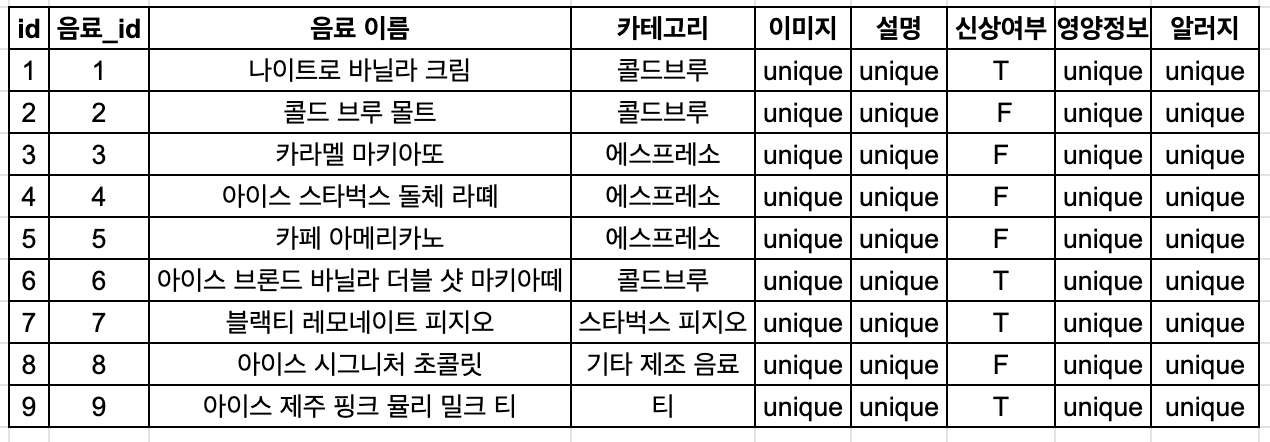
대략적으로 이렇게 나온다. 고유한 데이터의 경우 unique로 처리하였다.
2. 테이블 계획
찬찬히 데이터를 살펴보니 나누어줄 필요가 있는 테이블이 보인다.
- 카테고리가 중복되어 나타나는 것을 볼 수 있다. 카테고리의 이름을 일일이 작성하여 넣어주는 것 보다는, 따로 카테고리 테이블을 만들어, 그 테이블에서 카테고리의 id를 참조하여 저장하는게 더 효율적이다.
- 이미지가 여러개 일 경우 다른 데이터들이 중복해서 입력되어야 한다. 따라서 이미지 테이블을 생성하여 그곳에 이미지 데이터를 보관하고, 각 이미지에 해당되는 음료 id를 통해 접근하는 것이 더 바람직할 것.
- 영양 정보 및 알러지 정보는 unique로 처리하였지만, 그 속에는, 지방, 탄수화물, 단백질, 열량 등등, 수 많은 열이 포함된다. 따라서 테이블을 따로 생성하여 음료_id를 통해 데이터를 가져오는 것이 더 낫다.
3. 관계도 작성
계획에 따라서 관계도를 작성한다.
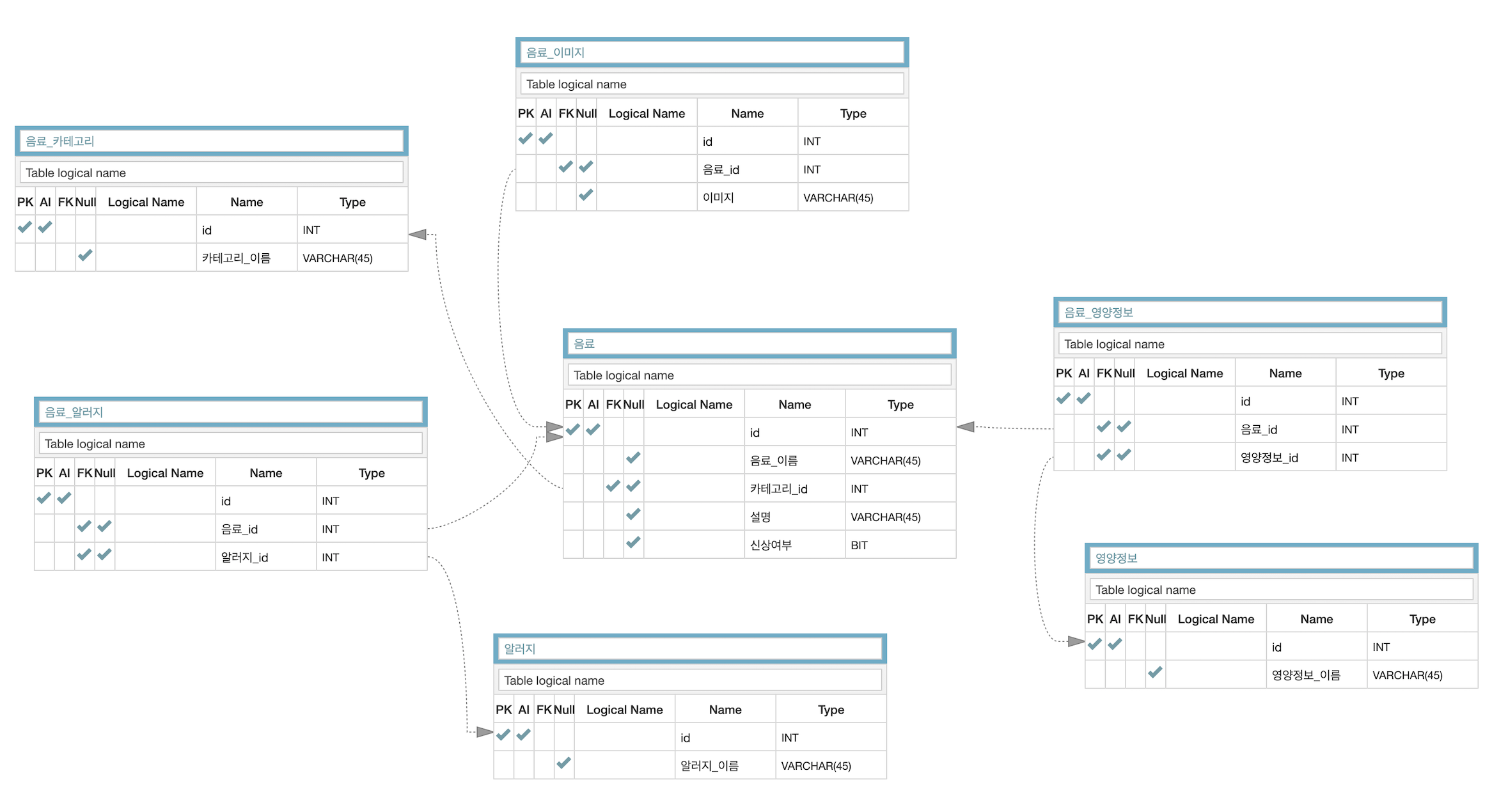
그나마 테이블이 6개 정도 밖에 안나오는 경우라 다행이지, 실제로 서비스를 만들면 20개는 우습게 나오지 않을까. 생각만해도 뇌에 과부하가 온다. 앞으로 수많은 테이블 스키마와 씨름하실 예정인 백엔드 개발자분들 리스펙 👍
