현재 글을 쓰는 시점인 12/14 기준,
2일 전에 학부 졸업과제인 캡스톤 팀 프로젝트가 끝이 났다.
학기 시작 후 9월 초부터 조장으로써 프로젝트를 진행했고, 나름 긴 시간을 투자한 프로젝트이다.
그 과정과, 결과에 대해 기록으로 남긴다.
배경 & 주제 선정
주제 - 'Slime Cover'
인공지능 기술을 활용하여 도서 줄거리 중에서 키워드를 선정하고,
책커버 디자인을 손쉽게 생성하는 서비스
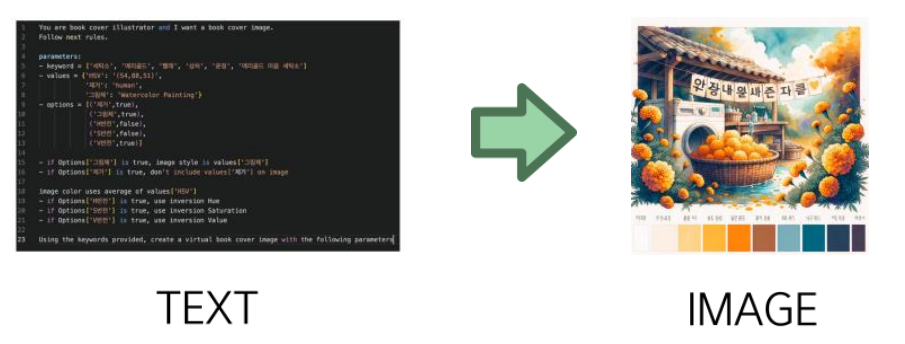
자유자재로 형태를 변화시킬 수 있는 슬라임의 특성과, 기획한 맞춤형 북커버의 의미가 유사하다 생각하여 선정하였음. Text to Image 방식으로, 책 본문 텍스트 분석을 통해 요약한 텍스트를 이용하여, 책의 느낌에 맞는 커버 이미지 생성
배경
사실 본인의 가족중에 한 분이 출판업계에서 일을 하고 계신다.
팀원들 각자 주제를 정하는 기간 중에 대화를 나누며 다음과 같은 생각이 들었다.
- 비용 감소
신생 or 독립 출판사는 북커버를 만드는 자본 조차 부담이 될 수 있다. 작가 또한 저렴한 가격으로 출판을 할 수 있기에 나쁘지 않은 아이디어. - 제작기간 단축
누구나 전문지식 없이 빠르게 풍부한 책 커버를 생성할 수 있다 - 불필요한 마찰 감소
실제로 현업에서, 일러스트 작가와의 의견 충돌로 인해 원고가 다 작성되었음에도 불구하고 도서 출판이 지연되는 상황이 다수 있다고 한다. - 유행과 다르게
요즘 북커버들을 보면, 다소 디자인이 고착화되어있다는 생각이 조금 든다. 이 부분도 개선할 수 있지 않을까? 생각이 들었다.
다음과 같은 이유들로, 기존 출판업계의 북커버 & 도서 디자인 부분에서 개선을 해보고자 하는 마음으로 주제를 정하게 되었다.
데이터 수집
우선 학습 & 분석을 위해서는 데이터가 필요하다.
다음과 같은 기술과, 과정을 통해 데이터를 수집했다.
1. 크롤링
크롤링은 웹에서 정보를 수집하는 자동화된 프로세스로, 웹 페이지를 방문하고, 웹 페이지에서 원하는 데이터를 추출하는 작업이다.
Python 코드로 작성하였고,
- Selenium - 동적 크롤링
- Beautifulsoup - 정적 크롤링
다음과 같이 활용하였다.
도서 사이트 선정
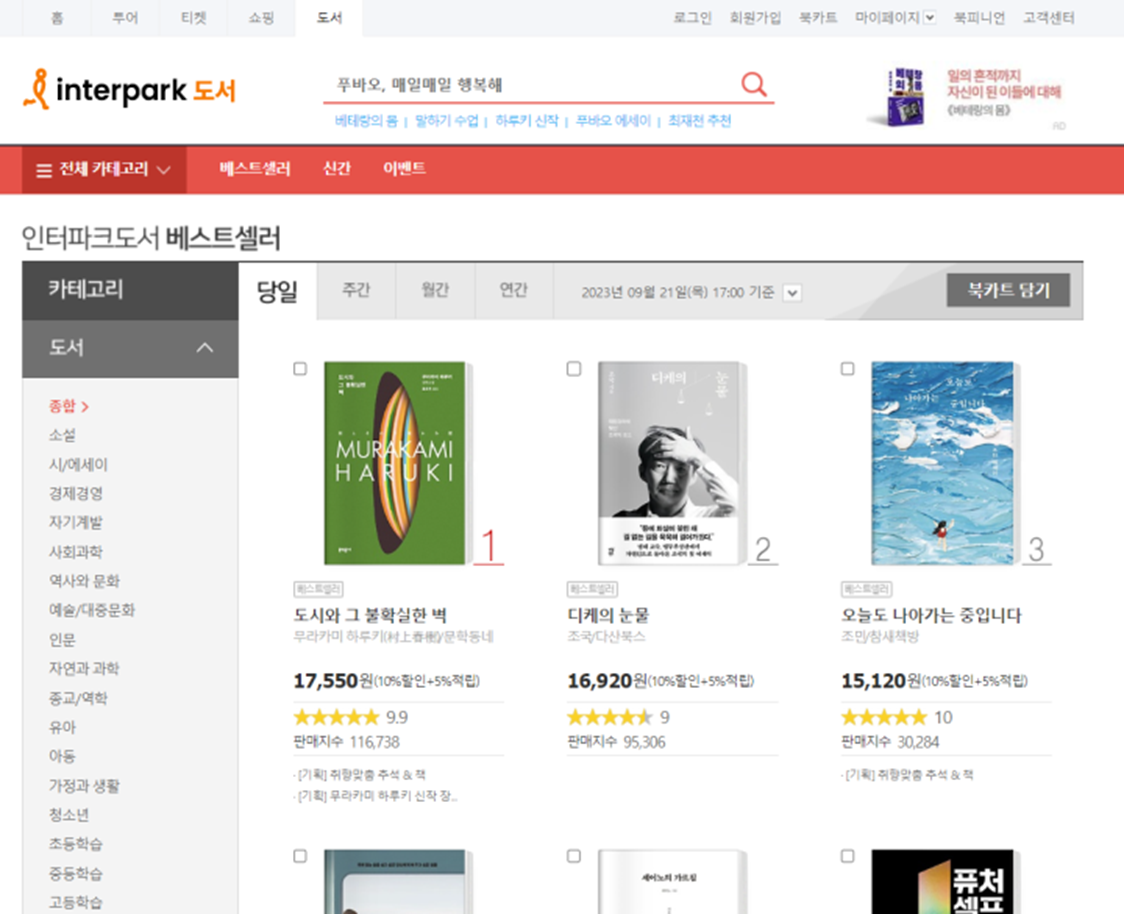
목적과 데이터 필요성, 웹사이트 구조, 다양한 도서 카테고리 등.
이외에도 교보문고, 알라딘 도서 등 도서 사이트를 조사해봤지만, 위와 같은 이유들로 인터파크 도서 사이트를 크롤링 대상으로 선정하였다.
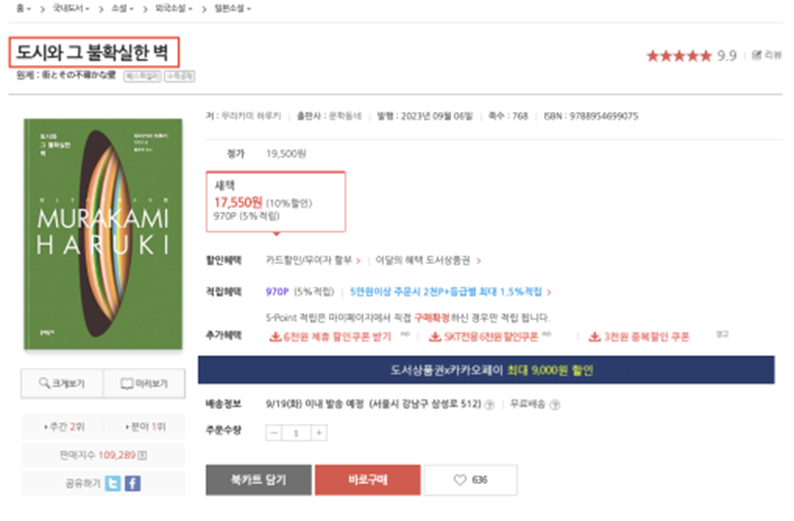


소설, 시/에세이, 가정과 생활, 자연과학, 인문
5개 장르로 나누어 크롤링을 진행하였다.
또한, 크롤링 해온 값들로는
책 표지(이미지), 제목, 책소개, 본문중에서, 출판사 서평(후에 삭제) 값들을 크롤링했다.
크롤링 기준
-
책 소개, 본문중에서 모두 존재하는가?
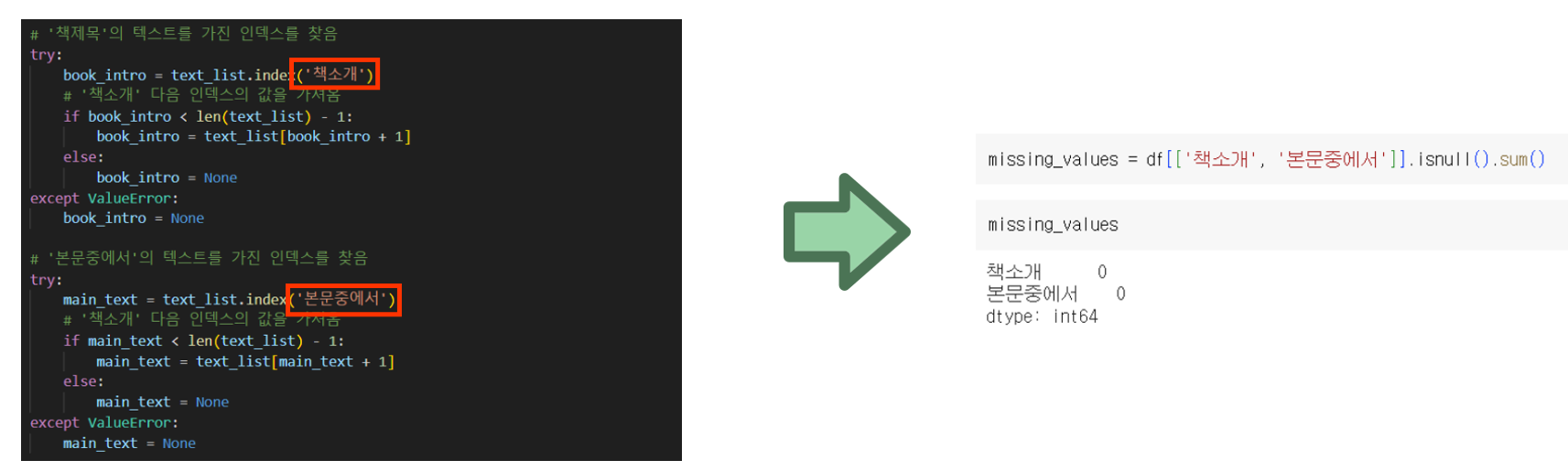
책 소개, 본문중에서 등 해당 값들이 존재하지 않는 책도 있었다. 예외 설정을 해주어 일관된 값만 긁어오도록 해주었다. -
세트와 단행본을 구별할 수 있는가?

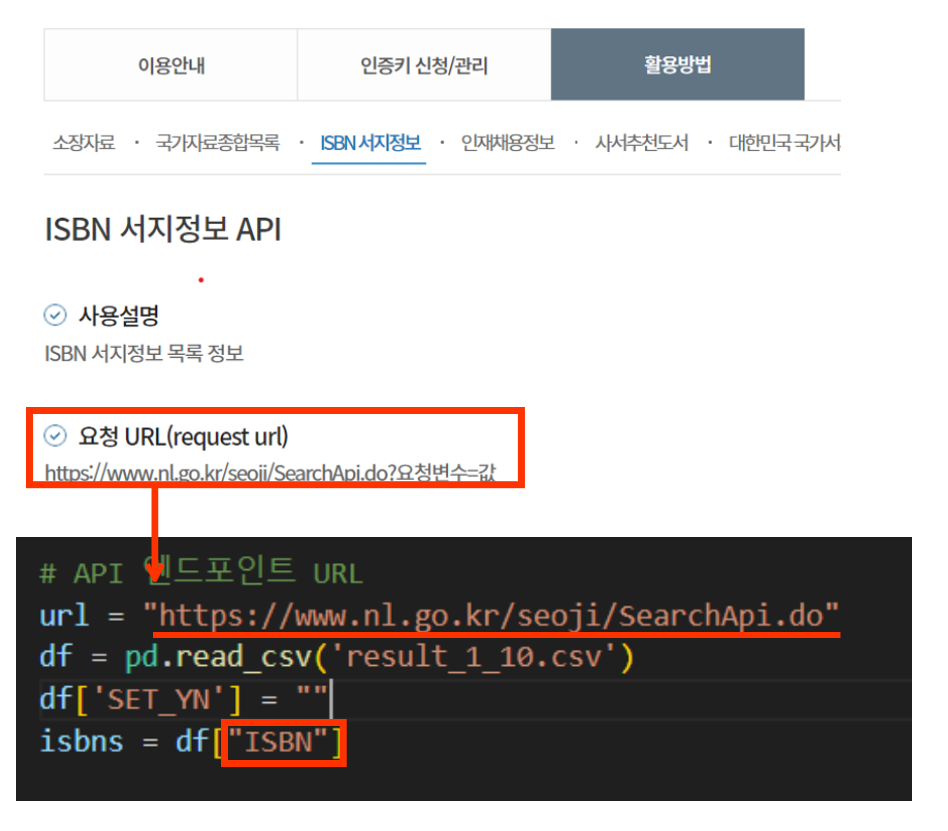
후에 학습을 진행할 때, 특히 이미지 학습 관련하여 소설 전집과 같은 비슷한 이미지의 연속이 너무 많이 있다면 과적합이 일어날 수 있을지도 모른다 생각했다. 이에, ISBN값(도서별 고유 일련번호)을 사용하는 ISBN 서지 정보 API를 활용하여, 세트 여부를 구분했다. -
이미지가 정상적으로 존재하는가?

다음과 같이 성인용 이미지나, 이미지가 준비중인 경우 제대로 크롤링을 진행할 수 없었기에, 예외처리하여 진행하였음
크롤링 결과
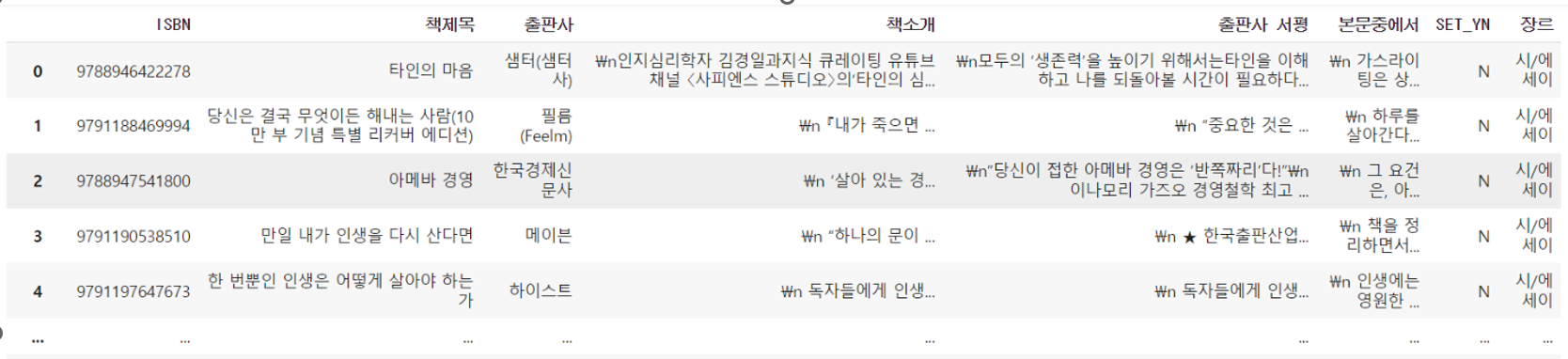
csv 형식으로 텍스트 데이터를 수집하였고, 세트 여부에 맞게 다시 나누어준 후,
텍스트 전처리까지 해주었다. 이미지 데이터도 마찬가지로 수집했고, 기준에 맞추어 분석과 학습에 잘 사용할 수 있도록 나누어줬다.
시행 착오
팀원은 총 5명이였고, 복수전공 학과에서 진행한 프로젝트였기에 다들 학과가 달랐다.
(과학학과, 사회학과, 문헌정보학과 등)
사실 이 서비스를 웹 데모까지, 서비스화 하려면 다양한 기술들이 필요하겠지만, 가장 걱정이였던 부분은 인공지능 부분이였다. 블랙박스 모델로도 불리는 인공지능은, 가벼운 개념과 지식으로는 다소 접근하기 어려운 부분이 있다. (거기다 공대 학부생은 5명 중 나 뿐이였....)
그렇다 보니 어쩌면 당연한 결과일지도 모르지만, 정말 많은 시행착오가 있었다.
자세한 기술들을 언급하기 전에, 시행착오 과정 먼저 언급하고 다음 글에서 최종 방향과, 사용한 기술 스택들에 대해 다루도록 하겠다.
1. 1차 접근
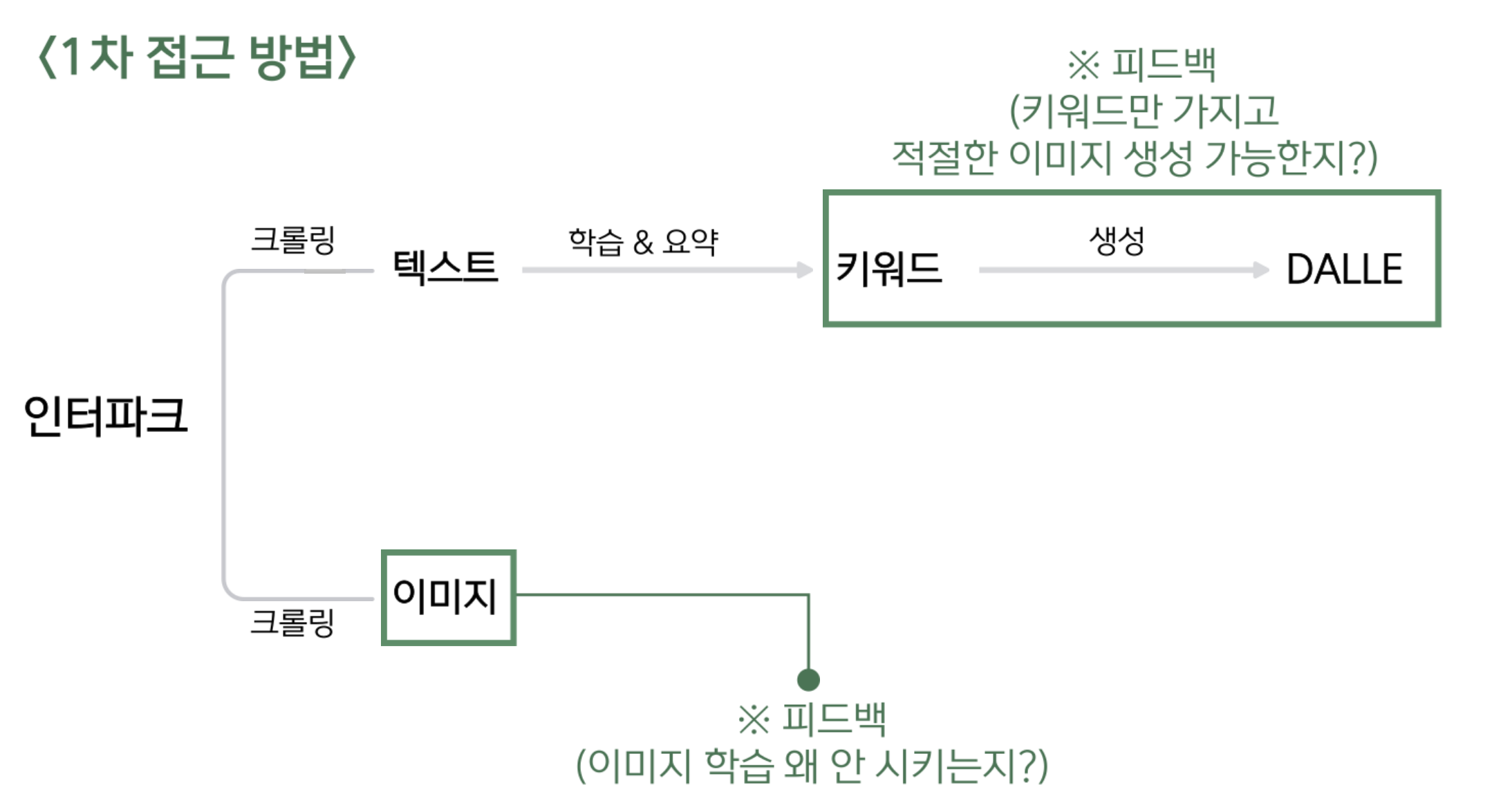
최초 구상했던 흐름도이다.
인터파크 도서 사이트에서 텍스트 데이터와 이미지 데이터를 각각 크롤링 한 후, 학습과 요약을 거쳐 본문 내용을 충분히 포함하는 키워드(5~10개)로 요약하고, 해당 키워드를 DALLE라는 생성형 이미지 인공지능에 넣어 이미지를 만들어내는 구상을 세웠었다.
하지만, 다음과 같은 피드백들이 있었다.
-
수집한 이미지는 왜 학습시키지 않는가?
프로젝트 초기에 구상을 하면서, 이미지 학습 분야에 지식이 전혀 없었다. 이 부분은 보류하고 있었기에 다음과 같은 피드백을 받지 않았나싶다. 추후 계획했다. -
감정 분류와 함께 화풍을 분류하는 모델도 개발하는 것이 어떤가?
텍스트 데이터 학습 & 요약 과정에서 감정 분석도 같이 진행을 했다. 화풍 분류 이야기가 나온 것은, 위와 같은 맥락이였지 않았을까 싶다. -
다양한 장르에서 선호하는 디자인을 식별하고 제작할 수 있게 하는 것은 어떤가?
장르별로 추가 크롤링을 진행했다.
피드백 이후 흐름도
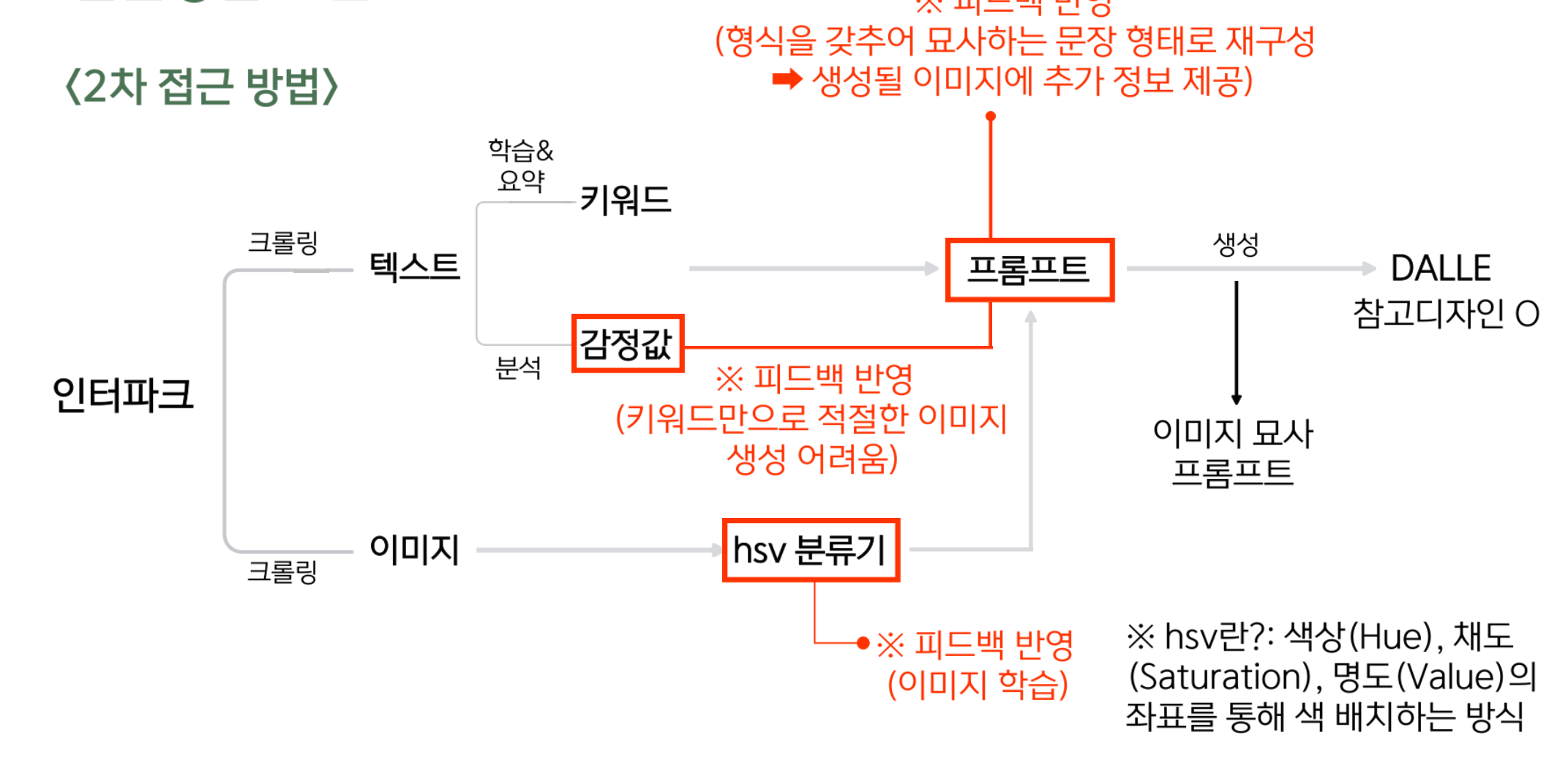
2. 2차 접근
2차 피드백 이후 흐름도이다.
장르별 크롤링을 추가로 진행하였고, 분석 부분에 감정값 분석을 추가하였다.
또한, 이미지 학습을 위해 kmeans를 활용하여 이미지 별 색상군을 추출하여, 장르별로 자주 나오는 색상군을 학습하였다.
이미지 묘사 프롬프트는 허깅페이스 사의 clip interrogator api를 활용하였는데, 이미지를 넣으면 이미지를 설명하는 텍스트를 뽑아준다.(imagetotext 방식)
하지만, 여전히 문제는 있었고, 피드백은 있었다.
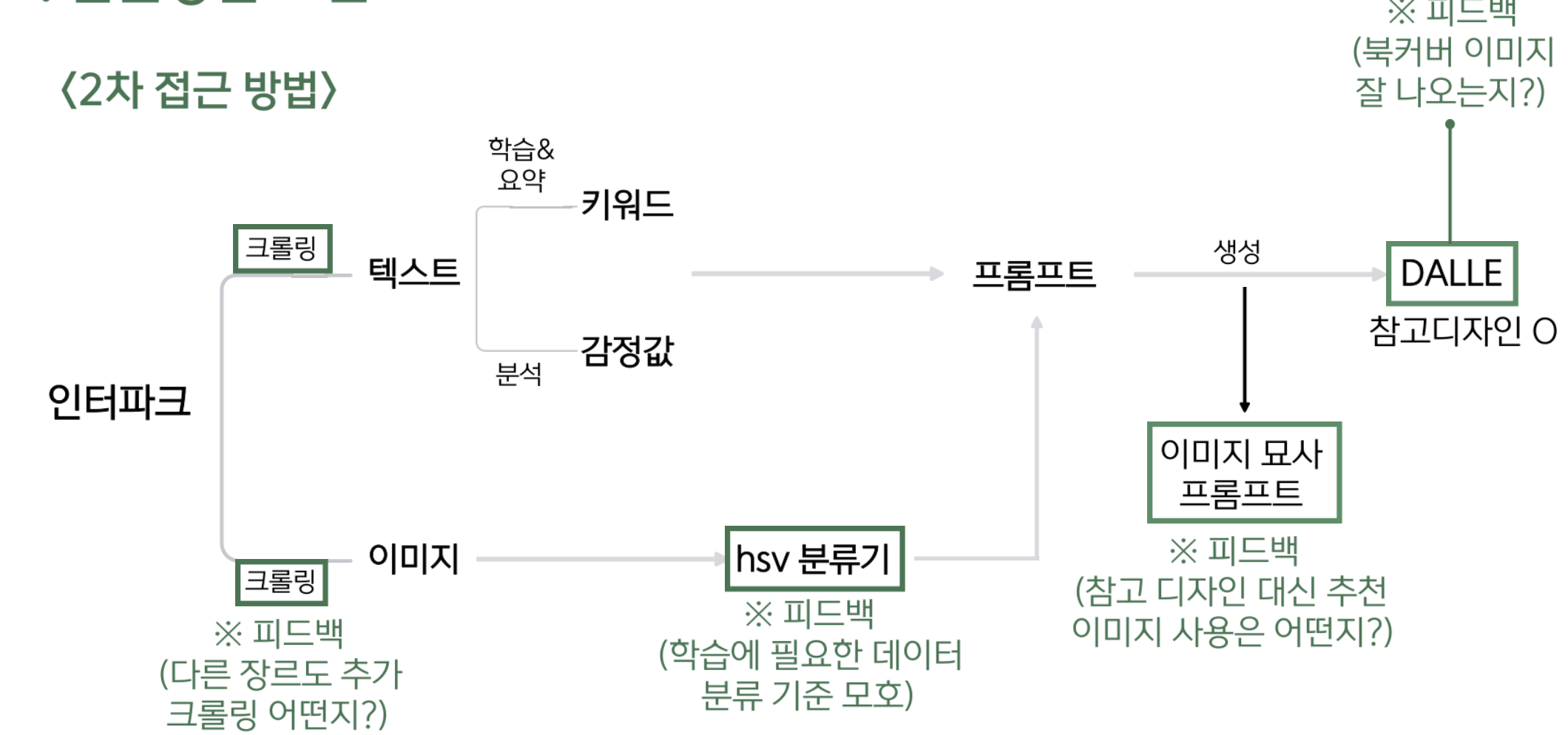
-
장르가 너무 적은 것 아닌가?
이 부분은, 현실적으로 무리였다. 아직 한 장르에 대한 서비스 구축도 제대로 되지 않았기에, 우선순위가 낮다 판단하여 장르를 추가적으로 크롤링하지는 않고, 학습을 위한 데이터를 재분류 하는 식으로 진행했다. -
hsv분류기 만드는데 학습 데이터가 그래서.. 정확한 input이 그래서 무엇인가?
내부 고찰을 하며 나왔던 이야기이다.
우선 hsv값이 무엇이냐 하면, rgb 값 처럼 색조, 채도, 명도 값을 표현하는 방식 중 하나이다. 학습에 필요한 데이터 분류 기준이 애매하다는 것이 무엇인가 하면, 쉽게 말해서 책의 감정값과 해당 책 이미지의 hsv값을 태깅하여 학습을 진행하려 했는데.. 눈으로 봐도 그 feature 값이 명확히 보이지 않았던게 문제였다.
예를 들어, '슬픔'이라는 감정이 있다면 연상되는 색이 몇 가지 있을 것 이다. 검정, 파랑, 회색 등.. 다소 부정적인 색깔들 위주로 떠오를 것 이다. 하지만, 실제 북커버 이미지는 꼭 텍스트의 감정을 따라가는 경우만 있지는 않았다. 또한, 북커버 이미지 특성상 단순한 이미지, 일러스트에 배경이 주를 이루는 경우가 많이 있어, kmeans를 통해 hsv값을 추출했을 때 그 값이 배경값에 섞여 생각보다 제대로 나오지 않았다. 이외에도 여러가지 이유들로 hsv분류기는 후에 화풍분류기로 통합시키는 것으로 결정했다. -
이미지 묘사 프롬프트
사실 이미지 묘사 프롬프트 api를 사용하려 했던 것은, 참고 디자인이 있는 경우를 위해서였다. 우리 서비스를 이용하는 입장에서, 참고 디자인이 있는 경우, 해당 참고 디자인을 묘사하는 텍스트를 프롬프트에 추가한다면 더 좋은 이미지가 나올 수 있지 않을까 생각했는데, 그럼 참고이미지가 없을때는 이 서비스는 의미가 없는 서비스가 아니냐는 피드백이 있었다. 이에, 처음부터 모델로써 함께 학습시켜버리는 방법을 찾아봤다.
피드백 이후 흐름도
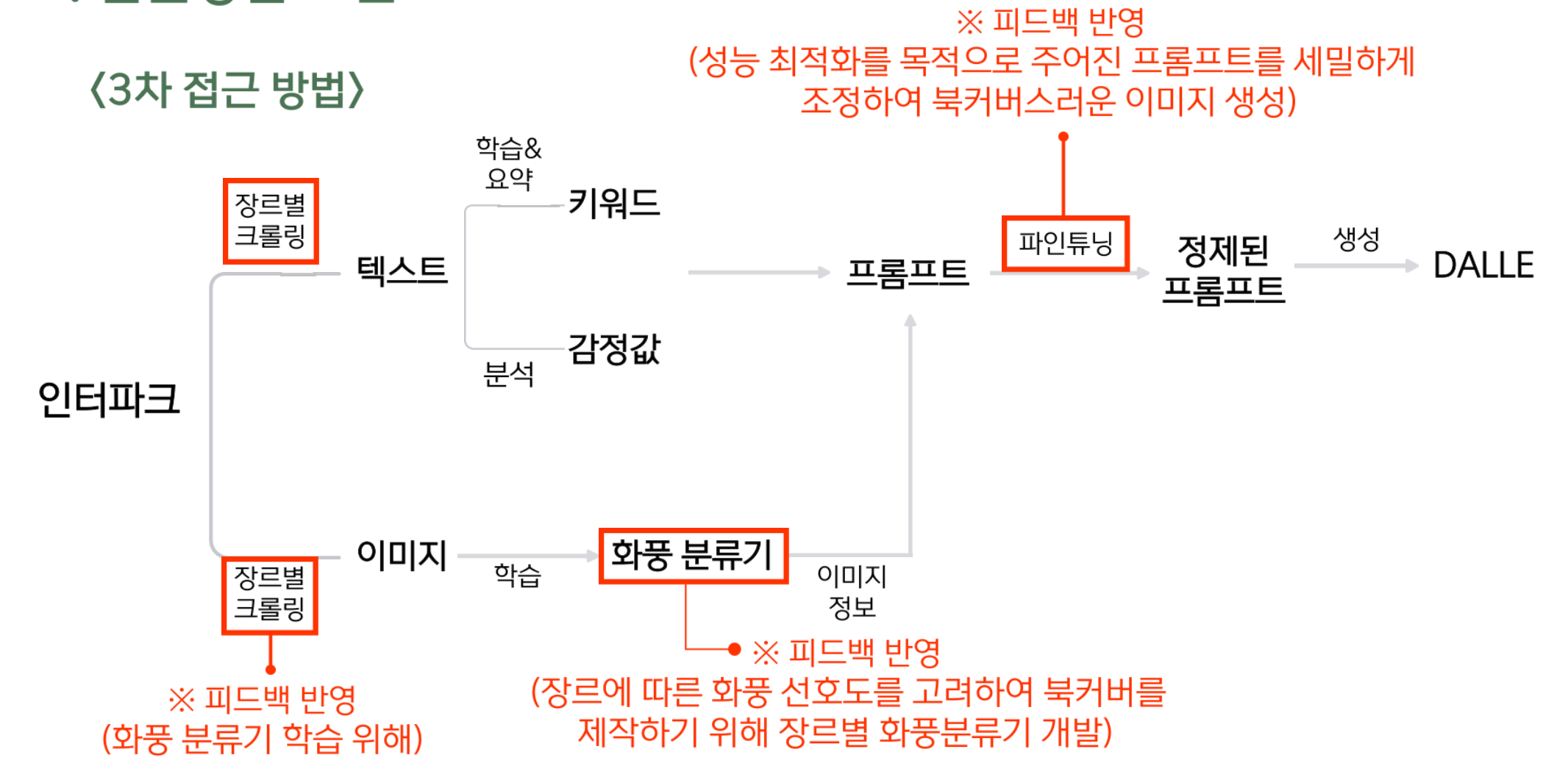
3. 3차 접근
3차 피드백 이후 흐름도이다.
장르에 따른 화풍 선호도를 고려한 북커버를 제작하기 위해 장르별 화풍 분류기를 개발하고자 하였다. AutoML 방식 등.. 그 과정에서 다양한 삽질을 했지만, 솔직히 너무 어려웠다. 개념도 개념이지만, 기본 툴을 활용하는 것 조차도 어려웠으니... 이는 후에 포기했다.
그리고 DALLE를 이용해서, 요약된 텍스트를 넣고 샘플용 이미지를 만드는 과정에서 프롬프트가 조금 더 정제된 형태로 들어간다면 이미지가 더 잘 나올 것 같다는 의견이 나왔고, DALLE 파인 튜닝을 이용하여 프롬프트를 조금 더 정제된 형태로 만들어보기로 했다.
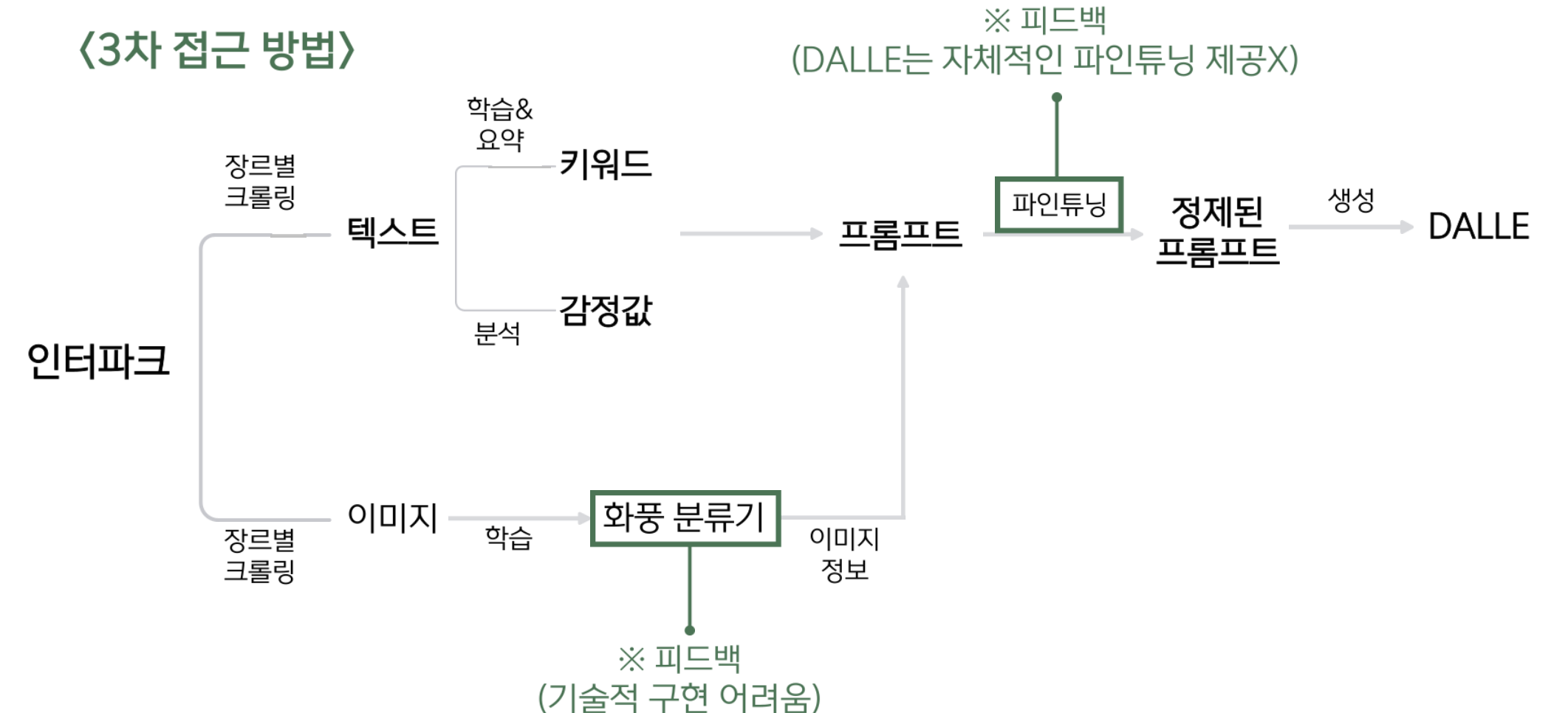
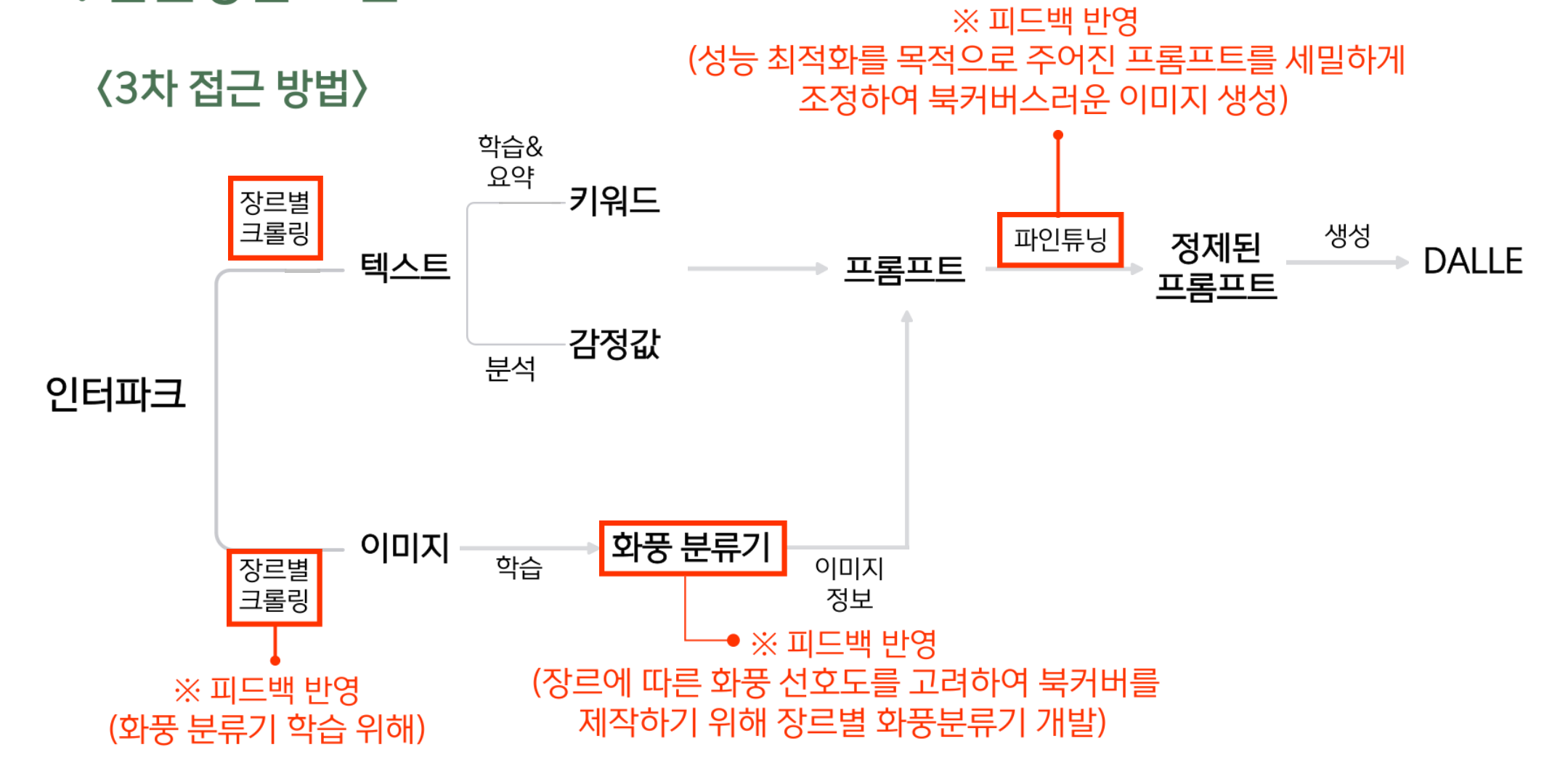
피드백 이후 흐름도. 화풍 분류기는 결국 포기하였고... DALLE는 자체적으로 파인튜닝을 제공하지 않기 때문에 이 부분도 막혔다.
최종
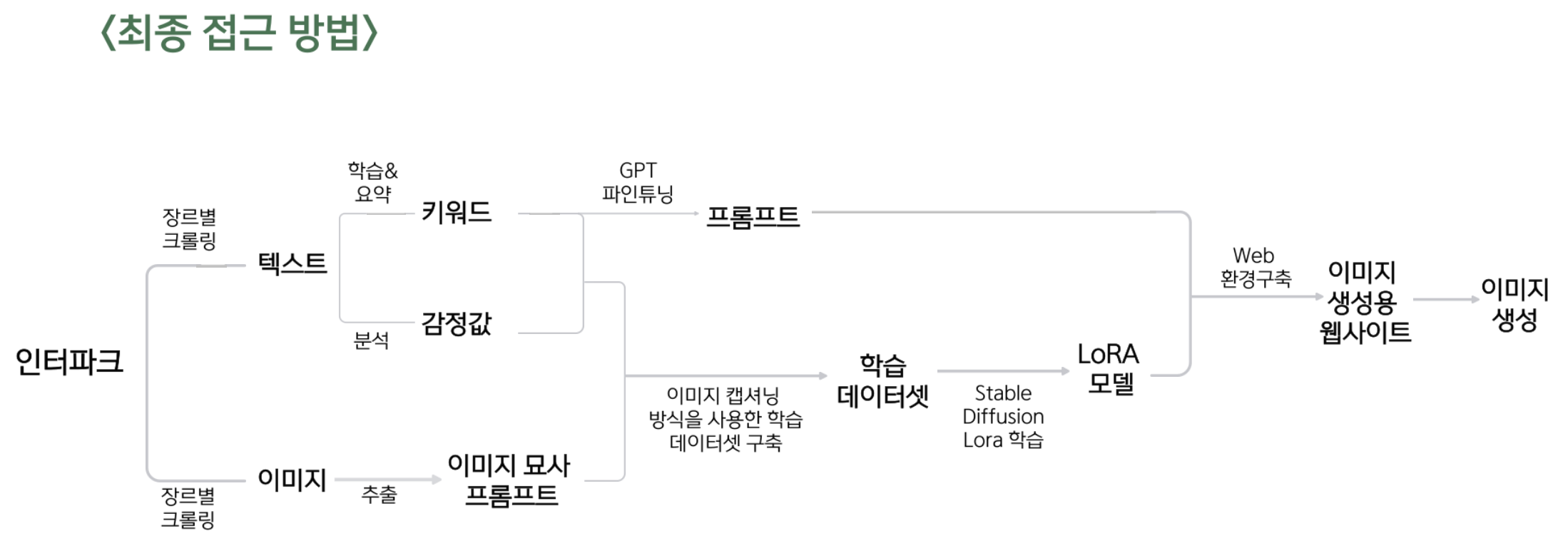
최종 흐름도는 다음과 같다.
가장 크게 달라진 점으로는 DALLE -> StableDiffusion을 사용하기로 한 것.
사실 DALLE가 정말 만족스러운 사진들을 잘 뽑아줬었다.



예시를 보면, 생각보다 꽤 잘 뽑아준다. 하지만, 뭐랄까 우리가 원하는. 우리가 익숙한 북커버 형태라기 보다는, 외국 동화 도서 같은 느낌이 강했고, 그림체가 고정되는 느낌이 많이 들었다.
달리를 사용하게 된다면, 퀄리티는 어느정도 보장할 수 있겠지만, 우리 팀의 본질적 목표였던 사용자 맞춤 이미지에는 한 발 멀어지는 것이 아닌가 하는 생각이 들었다.
그래서 우리는 최종적으로 개발자가 직접 더 많은 부분을 다루고 수정할 수 있는 Stable Diffsuion을 활용하기로 하였고, 학습은 LoRA와 Dreambooth를 사용하기로 했다.
이후 부분은 다음 글에서 다루겠다.
