
최종 진행 방향
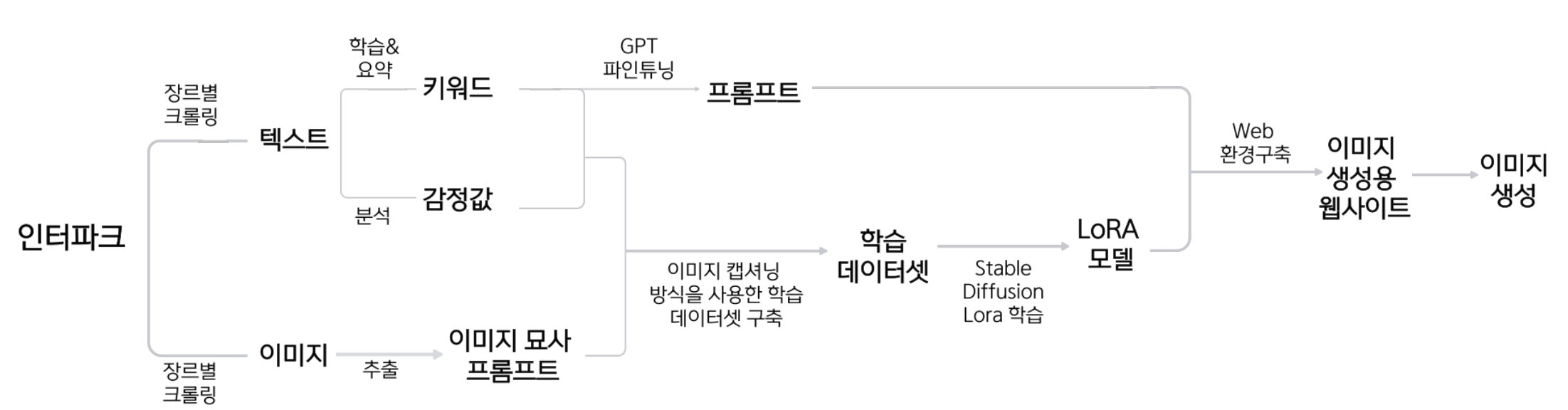
앞의 글에서 언급했던 최종 흐름도이며,
순서대로 자세하게 설명하겠다.
(사용한 코드가 많기때문에, 코드는 파트별로 중요한 부분만 기록하였다.)
1. 키워드
키워드를 만들어내는 과정은 다음 과정을 거쳤다.
원본 텍스트 데이터 --(Clova Summary API)--> 요약된 텍스트 데이터 --(TF/IDF & KEYBERT)--> 키워드
Clova Summary API
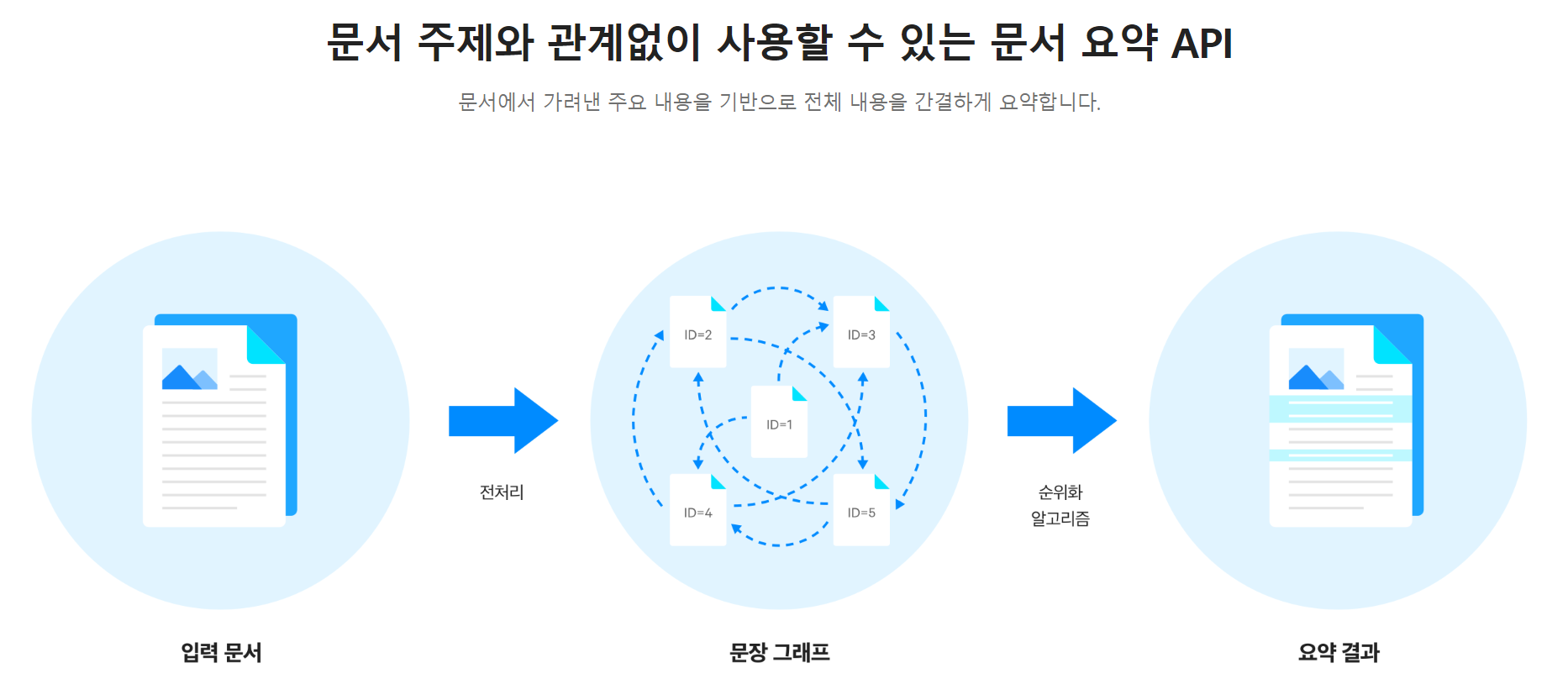
- Naver Cloud Platform의 clova summary api
https://www.ncloud.com/product/aiService/clovaSummary
원본 텍스트를 요약하는 방법으로는 네이버 클라우드의 요약 api를 사용하였다.
(네이버 클라우드는 처음 가입하면 10만 크레딧을 주기 때문에..)
- 코드 일부 발췌
#NLTK를 사용하여 문장으로 텍스트를 분할합니다.
sentences = nltk.sent_tokenize(summarys)
total_sentences = len(sentences)다음과 같이 문장들을 토큰 단위로 분리해준다.
part1 = ' '.join(sentences[:total_sentences // 4])
part2 = ' '.join(sentences[total_sentences // 4: 2 * total_sentences // 4])
part3 = ' '.join(sentences[2 * total_sentences // 4: 3 * total_sentences // 4])
part4 = ' '.join(sentences[3 * total_sentences // 4:])또한, clova summary api의 경우, 1500자가 넘어가면 안되기 때문에, 문장 길이 별 구간을 나누어주었다.
language = "ko" # Language of document (ko, ja )
model = "general" # Model used for summaries (general, news)
tone = "0" # Converts the tone of the summarized result. (0, 1, 2, 3)
# * 0: 원문의 어투를 유지
# * 1: 해요체로 변환합니다.
# <예시> 조사한다 → 조사해요
# * 2: 정중체로 변환합니다.
# 예시)조사한다 → 조사합니다
# * 3: 명사형 종결체로 변환합니다.
# <예시> 조사한다 → 조사함모델 내의 파라미터 값 부분. clova summary api는 신기하게도 어투를 정해줄 수 있다. 본문의 느낌을 최대한 살려야하기에 원문 그대로의 어투로 유지해주었고, general 타입에 한국어로 지정해주었다.
TF/IDF & KEYBERT
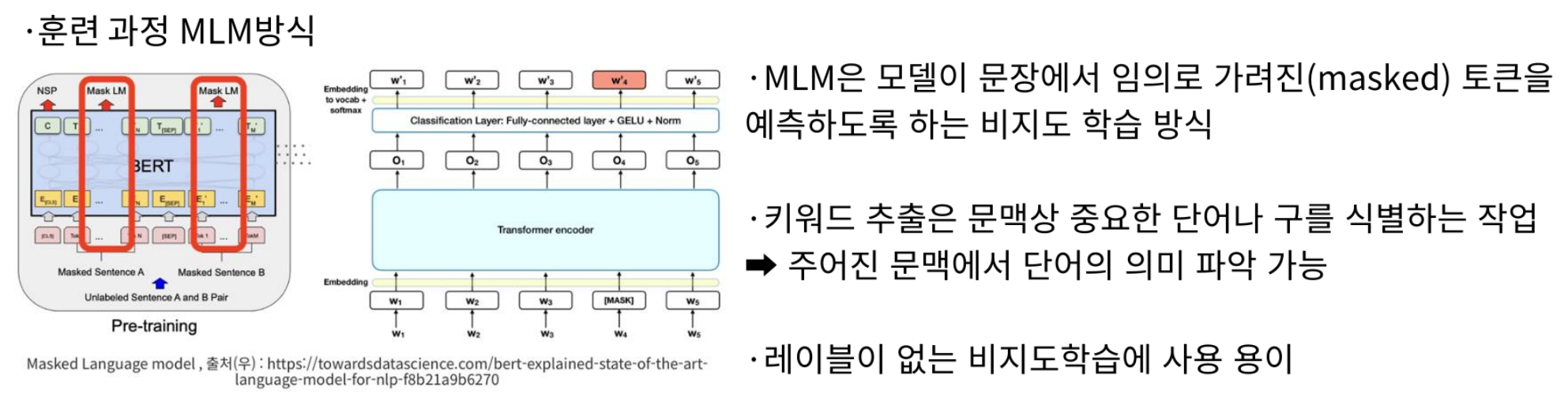
요약된 텍스트는 TF/IDF와 KEYBERT를 이용하여 키워드로 요약하였다.
우선 MLM 방식으로 pretrain 모델을 학습시켰다. pretrain 모델은 sk/kobert-base-v1을 사용했다.
코드가 좀 길어서 colab으로 남겨두었다.
pretrain 모델을 만든 이후, 본격적인 키워드 생성 파이프라인을 만들었다.
형태소 분석기는 Konlpy의 Okt, KKma 등을 사용해본 후, 복합명사 추출에 좀 더 탁월한 khaiii를 활용하였다.
- TF/IDF
# Khaiii 형태소 분석기 객체 초기화
api = KhaiiiApi()
def extract_nouns(text):
"""텍스트에서 명사만을 추출하는 함수"""
nouns = []
for word in api.analyze(text):
for morph in word.morphs:
if morph.tag in ['NNG', 'NNP', 'NNB', 'NR']:
nouns.append(morph.lex)
return ' '.join(nouns)
text = extract_nouns(book_combined)
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# Treat the string as a single document in a list
documents = [text]
# Create a TfidfVectorizer object
vectorizer = TfidfVectorizer()
# Apply the vectorizer to the document
tfidf_matrix = vectorizer.fit_transform(documents)
# Get the words corresponding to the columns of the TF-IDF matrix
words = vectorizer.get_feature_names_out()
# Create a DataFrame with the TF-IDF scores
tfidf_df = pd.DataFrame(tfidf_matrix.toarray(), columns=words)
# Sort the DataFrame by TF-IDF scores in descending order and get the top 5 terms
top_5_tfidf = tfidf_df.T.sort_values(by=0, ascending=False).head(5)
# Print only the words (index of the DataFrame)
top_5_words = top_5_tfidf.index.tolist()
print(top_5_words)
결과적으로 해당 코드를 시행하면, 요약된 텍스트에서 TF/IDF 방식을 활용했을 때 가중치 top 5 단어들을 추출할 수 있다. TF/IDF는 주로 문맥보다는 통계적 방식을 이용하지만, 자주 나오는 단어도 글을 대표하는 특성이 어느정도는 있다고 생각하기 때문에 해당 방식을 사용하였다.

- KEYBERT
SEQ_LEN = 128
BATCH_SIZE = 16
EPOCHS=2
LR=1e-5
pretrained_path ="경로"
config_path = os.path.join(pretrained_path, '/"경로"config.json')
vocab_path = os.path.join(pretrained_path, '/"경로"vocab.txt')
DATA_COLUMN = "document"
LABEL_COLUMN = "label"경로 설정 및 파라미터 값들을 설정
# 토크나이저와 모델을 로드합니다.
config = BertConfig.from_json_file(config_path)
tokenizer = BertTokenizer(vocab_file=vocab_path, do_lower_case=False)
model = BertForPreTraining(config)# Create a KeyBERT model
kw_model = KeyBERT()
# Extract keywords
keywords = kw_model.extract_keywords(book_text, top_n=5)
# Print the extracted keywords
for keyword in keywords:
print(keyword)
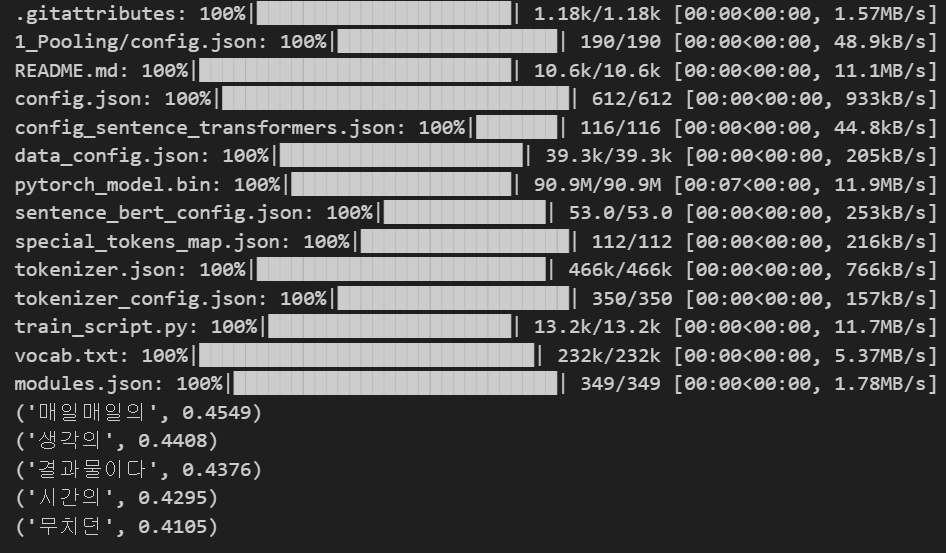
다음과 같이 가중치와 함께 키워드들을 추출할 수 있었다.
keyword_noun = []
for keyword in keywords:
# Analyze each keyword separately
for word in api.analyze(keyword):
for morph in word.morphs:
if morph.tag in ['NNG', 'NNP', 'NNB', 'NR']:
# Add the noun to the list
keyword_noun.append(morph.lex)
print(keyword_noun)
해당 코드를 이용하여, 조사 등을 삭제하고 명사만 추출하도록 설정. 키워드가 성공적으로 추출된 것을 확인할 수 있으며, 앞의 TF/IDF의 키워드와 합쳐서 후에 사용하였다.
2. 감정값
감정값을 추출하는 과정은 다음 과정을 거쳤다.
요약된 텍스트 데이터 --(Clova Sentiment API)--> 감정값
해당 과정은 간단하게 진행되었고,
후에 Stable Diffusion LoRA 학습 시 이미지 캡셔닝 파트에서 활용하였다.
기존에 수집한 텍스트 데이터를 input으로
BERT 감정분석, google cloud 감정분석, Clova Sentiment API 이렇게 총 3가지를 써보았고,
그래프로 3개의 감정분석기를 비교해본 결과, clova가 가장 한 감정에 치우치지 않는 모습을 보여주었다.
사실 감정이라는 영역은 수치화하기 애매한 부분이기 때문에, 100개 정도 팀원들과 함께 직접 읽어보았고 실제로 clova가 가장 감정을 잘 나타내었다는 결론에 도달했다.
Clova Summary API
- Naver Cloud Platform의 Clova Sentiment API
https://www.ncloud.com/product/aiService/clovaSentiment
import sys
import requests
import json
import pandas as pd
import re
df = pd.read_csv('SUMMARY.csv')
book_text_summary_sentiment = []
i = 0
for sum in df['book_text_summary']:
client_id = "?"
client_secret = "?"
url="https://naveropenapi.apigw.ntruss.com/sentiment-analysis/v1/analyze"
headers = {
"X-NCP-APIGW-API-KEY-ID": client_id,
"X-NCP-APIGW-API-KEY": client_secret,
"Content-Type": "application/json"
}
content = sum
data = {
"content": content
}
# print(json.dumps(data, indent=4, sort_keys=True))
response = requests.post(url, data=json.dumps(data), headers=headers)
rescode = response.status_code
if(rescode == 200):
# 수정된 정규 표현식을 사용하여 "negative", "positive", "neutral"의 값을 추출
negative_match = re.search(r'"negative":\s*([\d.]+)', response.text)
positive_match = re.search(r'"positive":\s*([\d.]+)', response.text)
neutral_match = re.search(r'"neutral":\s*([\d.]+)', response.text)
if negative_match:
negative_value = float(negative_match.group(1))
else:
negative_value = None
if positive_match:
positive_value = float(positive_match.group(1))
else:
positive_value = None
if neutral_match:
neutral_value = float(neutral_match.group(1))
else:
neutral_value = None
book_text_summary_sentiment.append([negative_value,neutral_value,positive_value])
print(f'{(i/len(df))*100}% 진행')
else:
print("Error")
book_text_summary_sentiment.append([None,None,None])
i += 1
# 'book_text_summary_sentiment' 리스트를 10000개로 확장하여 길이를 일치시킴
book_text_summary_sentiment += [None] * (len(df) - len(book_text_summary_sentiment))
# DataFrame에 'book_text_summary_sentiment' 열을 추가
df['book_text_summary_sentiment'] = book_text_summary_sentiment
# 이외의 열 제거
df.drop('book_text_summary', axis=1, inplace=True)
df.to_csv('SENTIMENT.csv', index=False, encoding='utf-8-sig')코드가 길지 않아서 전문으로 올린다.
요약된 본문을 input으로 넣은 후, api를 사용하여 3가지 감정(부정, 긍정, 중립) 으로 추출한다.
추출 후, csv 파일에 각 컬럼에 감정 % 값을 저장해준다.
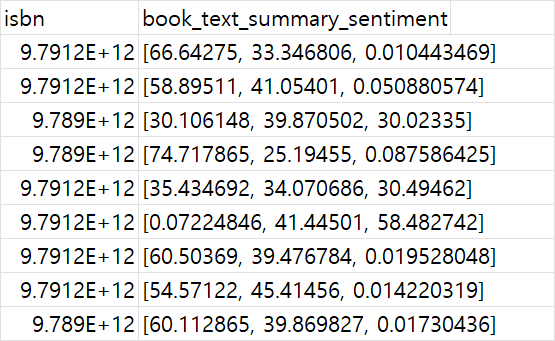
다음과 같은 형태로 저장된다.
3. 이미지 묘사 프롬프트
허깅페이스 사의 clip interrogator api를 활용하였다.
이미지 캡셔닝 시 활용하기 위해 추출하였다.
import os
import pandas as pd
import shutil
"""
이미지 프롬프트 추출 함수입니다.
25번째 줄에서 모드, 최대 플레이버 수 등 파라미터 값 설정 가능합니다
results.csv 파일에 저장됩니다.
"""
# gradio_client 패키지 설치
try:
from gradio_client import Client
except ImportError:
os.system('pip install gradio_client')
from gradio_client import Client
def process_batch(image_batch, output_csv):
df = pd.DataFrame(columns=['ISBN', 'image_prompt'])
# 각 이미지에 대해 프롬프트 추출
for image_path in image_batch:
result = client.predict(
image_path,
"best", # 모드 선택
2, # 최대 플레이버 수_최소 2, 최대 24
api_name="/clipi2"
)
file_name_without_ext = os.path.splitext(os.path.basename(image_path))[0]
new_row = pd.DataFrame({'ISBN': [file_name_without_ext], 'image_prompt': [result]})
df = pd.concat([df, new_row], ignore_index=True)
# 튜플에서 문자열만 선택
df['image_prompt'] = df['image_prompt'].apply(lambda x: x[0] if isinstance(x, tuple) else x)
# 실시간 진행 상황 출력
print(f"Processed {image_list.index(image_path) + 1} out of {len(image_list)} images.")
# 데이터프레임을 .csv 파일에 추가 (이전 결과와 합침)
if os.path.exists(output_csv):
df.to_csv(output_csv, mode='a', header=False, index=False)
else:
df.to_csv(output_csv, index=False)
client = Client("https://fffiloni-clip-interrogator-2.hf.space/")
image_directory = "./images"
image_list = [os.path.join(image_directory, f) for f in os.listdir(image_directory) if f.endswith(('.png', '.jpg', '.jpeg'))]
# Load the last processed image and start index from a file or configuration
if os.path.exists("last_processed_info.txt"):
with open("last_processed_info.txt", "r") as info_file:
last_processed_image, start_index = map(int, info_file.readline().split())
else:
last_processed_image = None
start_index = 0
# 배치 사이즈 설정
# 현재까지 처리한 이미지의 개수를 출력하는 로그
BATCH_SIZE = 1
for i in range(start_index, len(image_list), BATCH_SIZE):
image_batch = image_list[i:i+BATCH_SIZE]
process_batch(image_batch, "results.csv")
# Update the last processed image and start index
last_processed_image = int(os.path.splitext(os.path.basename(image_batch[0]))[0])
start_index = i
# Save the last processed image and start index to a file
with open("last_processed_info.txt", "w") as info_file:
info_file.write(f"{last_processed_image} {start_index}")
print(f"Results saved in results.csv")
save_path =
shutil.copy("results.csv", save_path)
print(f"Results copied to {save_path}")
중간에 끊기는 경우가 종종 있어서, 데이터 프레임을 생성 후 csv 파일을 만들었을 때 기존 csv 파일이 존재한다면, 이전 부분부터 덮어씌우는 방식으로 이어지게끔 코드를 작성해 주었다.
모드는 best, classic, fast 모드가 존재하는데, classic 모드는 너무 많은 정보를 추출하고, fast 모드는 반대로 너무 적은 정보를 추출한다. 이외에 flavor값은 일종의 자유도 같은 느낌인데, 적게 설정할수록 이미지에 딱 맞는. 크게 벗어나지 않는 단어들로 프롬프트를 구성해준다. 가장 낲은 값으로 설정해주었다.
출력된 값에서 근본적인 이미지를 나타내는 가장 앞 부분의 값만 가져오면

다음과 같은 형태로 추출할 수 있다.
