4. GPT 파인튜닝
다음으로는 키워드를 활용하여 프롬프트를 만드는 과정이다. GPT 파인튜닝을 이용하여, 단순하게 키워드의 나열만 프롬프트에 넣는 것이 아닌, 조금 더 무언가를 묘사하는 형태로 바꾸어 넣어주자는 취지로 해당 기술을 사용하였다.
def generate_prompt(book_intro, book_text):
keywords = key(book_intro, book_text)
openai.api_key = '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'
# GPT-4 모델을 사용한 텍스트 생성 요청
response = openai.Completion.create(
engine="text-davinci-003", # GPT-4 모델 지정
prompt = f"""이 {keywords}키워드들로 커버이미지를 만드는 stablediffusion프롬프트를 작성해주세요:
요구사항은 다음과 같습니다.
1. 키워드 두 세트의 키워드를 하나로 합쳐줘
2. 중복되는 단어에 가중치를 두어 1~2줄 정도의 간결한 프롬프트작성
3. 추상적 단어보다는 키워드를 바탕으로 북커버 이미지를 묘사해줘
""",
max_tokens= 500 # 생성할 최대 토큰 수후에 키워드로 요약해주는 파이프라인에 추가하여 사용하였으며,
input으로 키워드 값을 받고, 해당 키워드를 재조합하여 형태에 맞게 재생성해주었다.
- 예시

5. 학습 데이터셋 구축
학습 과정을 기록하기 이전에, 앞의 글에서 LoRA 학습을 진행하겠다고 밝혔다.
우선, Stable Diffusion과 LoRA에 대해 간단하게 짚고 넘어가려 한다.
LoRA 모델이란?
LoRA(Low-Rank Adaptation)은 Stable Diffusion 모델을 세부 조정하기 위한 학습 기법이다. Stable Diffusion에는 이외에도 Dreambooth, textual inversion과 같은 학습 기법도 있는데, LoRA는 모델의 크기 차원에서 매우 다르다. Dreambooth는 강력하지만, ckpt(체크포인트) 파일 전체를 학습하고 output으로 내놓기 때문에 크기가 매우 크다(2-7GB). Textual inversion은 파일이 작지만, 할 수 있는게 많지 않다. LoRA는 이 두가지를 적절히 섞은 정도라고 보면 된다.
LoRA 모델은 단독으로 사용 및 학습할 수 없고, ckpt 확장자명의 모델 체크포인트와 함께 사용해야 한다. LoRA는 함께 사용하는 모델 파일에 작은 변화를 가하여 스타일을 변경시키는 역할만 하기 때문
(그렇다. 스타일을 변경시키는 역할. 우리는 LoRA 방식을 이용하여 장르 별 그림체를 학습하기로 했다.)
LoRA 작동 원리
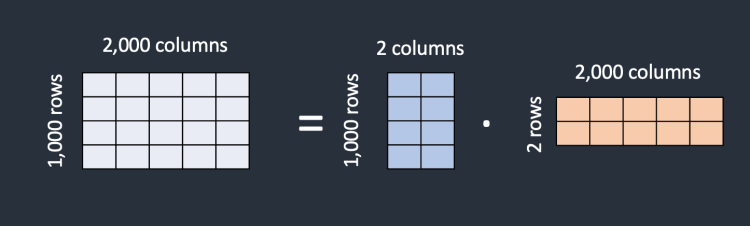
간단하게 짚고 넘어가겠다. 예를 들어, 어떤 모델이 1000개의 행과 2000개의 열로 구성된 행렬을 가지고 있다고 가정해보자. 그러면 그 모델에는 2백만개의 숫자가 저장된다. LoRA는 이 행렬을 1000 2 행렬과 2 2000 행렬로 쪼갠다. 이렇게 하면 총 6천(1000 2 + 2 2000)의 숫자만 필요하고, 원래 행렬 대비 1/333 으로 크기가 줄어든다. 이 때문에 작은 크기로도 좋은 효과를 낼 수 있는 것 이다.
데이터 전처리
텍스트 데이터

앞서 수집한 키워드, 감정값, 이미지 프롬프트가 하나로 합쳐져있다.
하나의 string 형태로 묶어주는 과정을 거쳤고, 학습에 사용하려면 영어로 되어있어야 하기 때문에 파파고 api를 사용하여 영어로 바꿔주었다.
이미지 데이터
당연한 이야기겠지만, 이미지 데이터를 학습에 사용하려면 몇 가지 조건을 지켜야한다.
- 깔끔한 화질, 적당한 해상도
- feature값이 잘 드러나는 이미지
이렇게 두가지를 수정하였다.
우선, 현재 이미지 상태.
Stable Diffusion 학습에 사용하려면 최소 사이즈가 512 * 512는 되어야하는데.. 사진이 너무 작다. Opencv의 보간법을 사용하여 화질이 최대한 깨지지 않는 선에서, 사이즈를 늘려줬다.
import os
import cv2
import shutil
# 폴더 생성
folder_path = r"C:\Users\USER\Desktop\last2\testing"
os.makedirs(folder_path, exist_ok=True)
# 저장할 폴더 경로
output_folder = r"C:\Users\USER\Desktop\last2\testing"
# 특정 폴더 안의 이미지 파일들 불러오기
image_files = [f for f in os.listdir(r'C:\Users\USER\Desktop\last2\images') if f.endswith('.jpg')]
# 각 이미지를 읽어 크기 조절하고 저장
for image_file in image_files:
# 이미지 경로
image_path = os.path.join(r'C:\Users\USER\Desktop\last2\images', image_file)
# 이미지 읽기
image = cv2.imread(image_path)
# 이미지가 None이 아니라면 크기 조절 및 저장
if image is not None:
resized_image = cv2.resize(image, dsize=(256, 256), interpolation=cv2.INTER_CUBIC)
output_path = os.path.join(output_folder, image_file)
cv2.imwrite(output_path, resized_image)
else:
print(f"경고: {image_path}에서 이미지를 읽어올 수 없거나 손상되었습니다.")
# 원본 이미지 폴더 경로
original_folder = r"C:\Users\USER\Desktop\last2\testing"
# 저장할 폴더 경로
output_folder = r"C:\Users\USER\Desktop\last2\img"
# 특정 폴더 안의 이미지 파일들 불러오기
image_files = [f for f in os.listdir(original_folder) if f.endswith('.jpg')]
# 각 이미지를 읽어 크기 조절하고 저장
for image_file in image_files:
# 이미지 경로
image_path = os.path.join(original_folder, image_file)
# 이미지 읽기
image = cv2.imread(image_path)
# 이미지가 None이 아니라면 크기 조절 및 저장
if image is not None:
upscaled_image = cv2.resize(image, dsize=(512, 512), interpolation=cv2.INTER_LINEAR)
output_path = os.path.join(output_folder, image_file)
cv2.imwrite(output_path, upscaled_image)
else:
print(f"경고: {image_path}에서 이미지를 읽어올 수 없거나 손상되었습니다.")
print("이미지 업스케일 및 저장이 완료되었습니다.")
# 폴더 삭제
folder_path = "./testing"
shutil.rmtree(folder_path, ignore_errors=True)
또한, feature값이 잘 들어가는 이미지들을 장르별로 따로 분류해주었다.
30장씩 나누었는데, 사실 더 큰 크기로 학습을 시키고 싶었다. 하지만 컴퓨팅 파워의 한계로... LoRA 그림체 학습에 적절하다는 30장씩 총 5장르. 150장을 학습하였다.
데이터 캡셔닝
colab 환경에서 구글 드라이브를 연동하고, 데이터 캡셔닝을 진행하였다.
다음과 같이 이미지 하나 당, 텍스트 캡션을 하나씩 달아주었으며


잘 달린 것을 확인할 수 있다.
추가로, 글씨 부분이 까맣게 되어있는 것은, 제목이 들어갈 구역도 따로 학습할 수 있을까 하는 생각에 시도해보았던 것 인데, 따로 인식하지는 않는 것 같았다. (데이터가 더 많이 or 배치사이즈 조절이 필요했을지도..)
6. LoRA 학습
이미지 캡셔닝에서 링크 달았던 colab에 코드 첨부되어있음
가장 기본 파라미터값에, epoch과 배치 사이즈만 조금 조절했다. (GPU 사양 이슈 ㅠㅠ)
7. Web 환경 구축
이 부분이 가장 쉽지 않았다... 블로그에 다 쓰지는 못 했지만, 많은 시행착오들을 거치며 프로젝트 마감일까지 시간이 얼마 없는 상태였고, 그 외에 여러가지 문제들도 있었다.
- khaiii
앞서 키워드 추출 파트에서 khaiii 형태소 분석기를 사용한다고 밝혔는데, 이 khaiii가 아주 문제가 많았다.. khaiii는 리눅스 환경. 그 중에서도 18.04 이하 환경에서만 작동했다. 버전 호환을 맞춰주는게 아주 머리가 아팠다. - gradio
그라디오는 모델을 웹 상에 쉽게 배포하게 해주는 유용한 툴이다. 그런데 Stable Diffusion 자체가 학습 뿐만 아니라 이미지를 생성하는 과정에서도 상당한 gpu를 차지하기 때문에, 본인의 노트북으로는 도저히 감당할 수가 없어, colab 환경에서 gradio 호스팅을 진행해야 했다. 거기다 colab은 우분투 18.04가 아니지않나... 버전을 낮출 수도 없고, 그래서 앞서 말했던 khaiii도 파이프라인 안에 넣을 수가 없었다. (외부에서 연동해주는 방식으로 진행)
과정
1) window 환경에 ubuntu 18.04 설치

Windows 기능 켜기/끄기에 들어가서
- Linux용 Windows 하위 시스템
- 가상환경 플랫폼 활성
이렇게 2개를 켜준다. 이후 pc 재부팅
재부팅 이후, Microsoft Store에서 우분투 18.04를 설치
설치 이후 관리자 권한으로 실행하여 접속

code .해당 명령어를 입력하여 vscode 환경으로 열어준다.
vscode 측에서도 wsl extenstion을 설치하는 등의 과정을 거쳐야 하는데, 그 부분은 간단해서 생략했다.

연결이 잘 되었다.
추가로 ubuntu 18.04는 python 3.6.9 버전이 설치되어있는데, stable diffusion의 다른 툴을 사용하려면 해당 python 버전으로는 불가능해서, 가상환경을 설정하고 3.10.12 버전으로 바꾸어주었다.

(python 버전 업데이트 하고, 경로 바꾸어주는건 저장해둔 자료가 날아가서 기록을 못 했다.. ㅠ)
2) khaiii 설치
블로그 글 보고 그대로 따라했다..
카이는 설치 자체는 굉장히 간단하다.

가상환경과 함께 khaiii 설치가 잘 된 모습
3) 외부 연동
Gradio란?
쉽게 말해, 모델 배포를 웹 상에서 쉽게 할 수 있게 도와주는 툴.. 정도
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
book_intro_input = gr.Textbox(label="책 소개", placeholder="여기에 책 소개를 입력하세요")
book_text_input = gr.Textbox(label="책 본문", placeholder="여기에 책 본문을 입력하세요")
submit_button = gr.Button("생성")
output = gr.Textbox(label="생성된 프롬프트")
submit_button.click(gradio_interface, inputs=[book_intro_input, book_text_input], outputs=output)
demo.launch(share=True,debug=True)코드 일부를 가져왔다. 굉장히 사용하기 편리하다. 이 정도 형식만 갖춰주면 다음과 같은 웹을 호스팅 할 수 있고, lauch 함수 파라미터 중 share를 true로 설정해주면 로컬이 아닌, 모두가 접근 가능한 주소로 호스팅도 가능하다.
로컬로 접속한 모습
다음과 같이 책 소개, 책 본문 값 중 하나를 넣어준다.
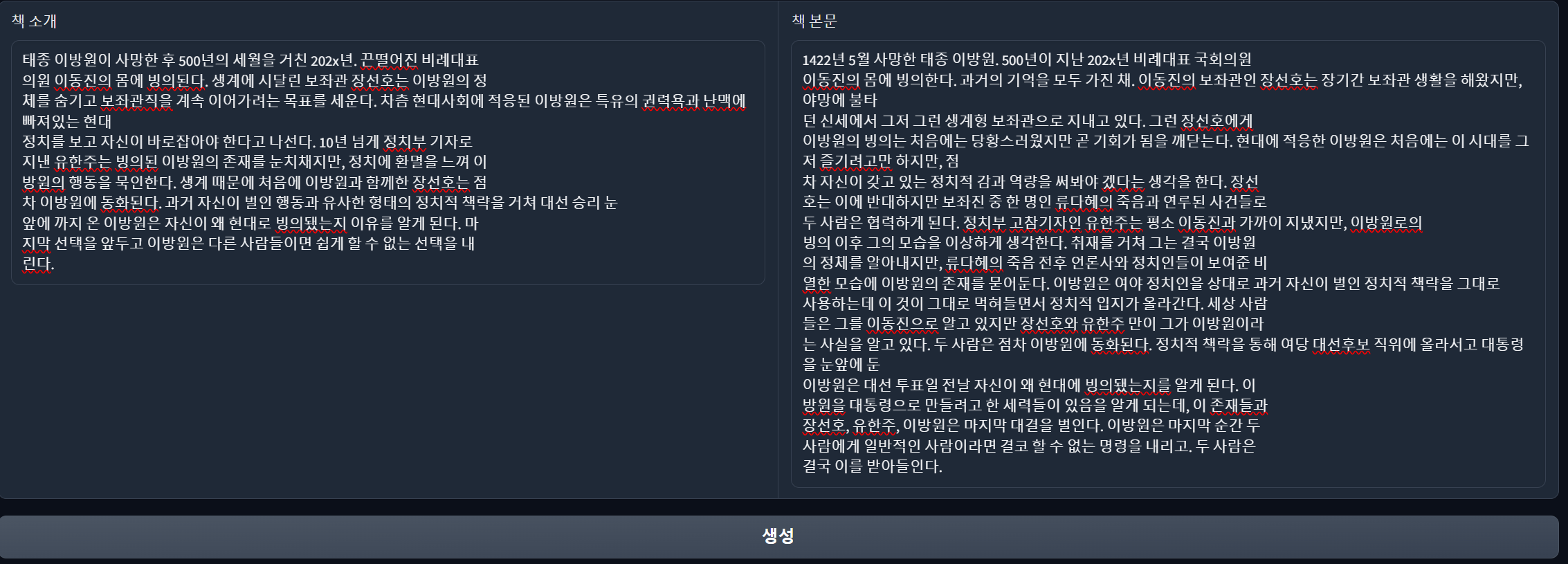
이후 생성 버튼을 누르면,

다음과 같은 형태로 출력해준다.
다시 한 번 요약하자면,
원본 텍스트 -> 키워드 -> 프롬프트
프로세스로 이루어져 있다.
또한, gradio는 정말 편리한 것이, api도 제공을 한다.
client url에 로컬 주소가 아닌, 서버 주소를 넣는다면 공유가 가능하다.
4) colab & vscode 연동 / gradio 웹 호스팅
내가 지금 로컬에서 ubuntu 18.04에 연결한 것 처럼, colab을 vscode 환경으로 연결했다.
그리고 그간 있었던 기능들을 모듈화하여 호스팅 환경을 구성해주었다.
코드는.. 여기서부터는 파일이 너무 많고 복잡해서 생략. 굳이 하나만 보이자면,
# 이미지 생성
def txt2img(prompt,category):
# if want gpu -> .to("cuda") toothlessjw/capstone_base runwayml/stable-diffusion-v1-5
repo_id = "toothlessjw/capstone_base"
pipeline = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16).to("cuda")
#pipeline.load_lora_weights(f"toothlessjw/{category}")
#pipeline.fuse_lora(lora_scale=0.8)
image = pipeline(f'(masterpiece, top quality, best quality), {prompt}',
num_interence_steps=50,
guidance_scale=10,
negative_prompt='blurry, worst quality, low quality, normal quality, lowres, bad anatomy, normal quality').images[0]
return image이미지를 생성하는 프로세스 모듈.
toothlessjw/capstone_base 는 dreambooth 방식을 이용하여 학습을 마친 ckpt 모델을
본인의 huggingface 계정에 업로드해둔 경로이다.
from diffusers import DiffusionPipeline을 사용하여 가지고 왔다.
추가로 로라 모델 5개도 장르별로 올려두었기에, pipeline.load_lora_weights를 사용하여 lora 가중치를 불러오고, fuse_lora 명령을 사용하여 그 정도를 조절한다. (1로 쓰게 되면 너무 진해서 이미지가 손상된다)
이외에 기본적인 성능 향상 프롬프트 등을 추가로 설정해주었다.
- 최종 웹 형태
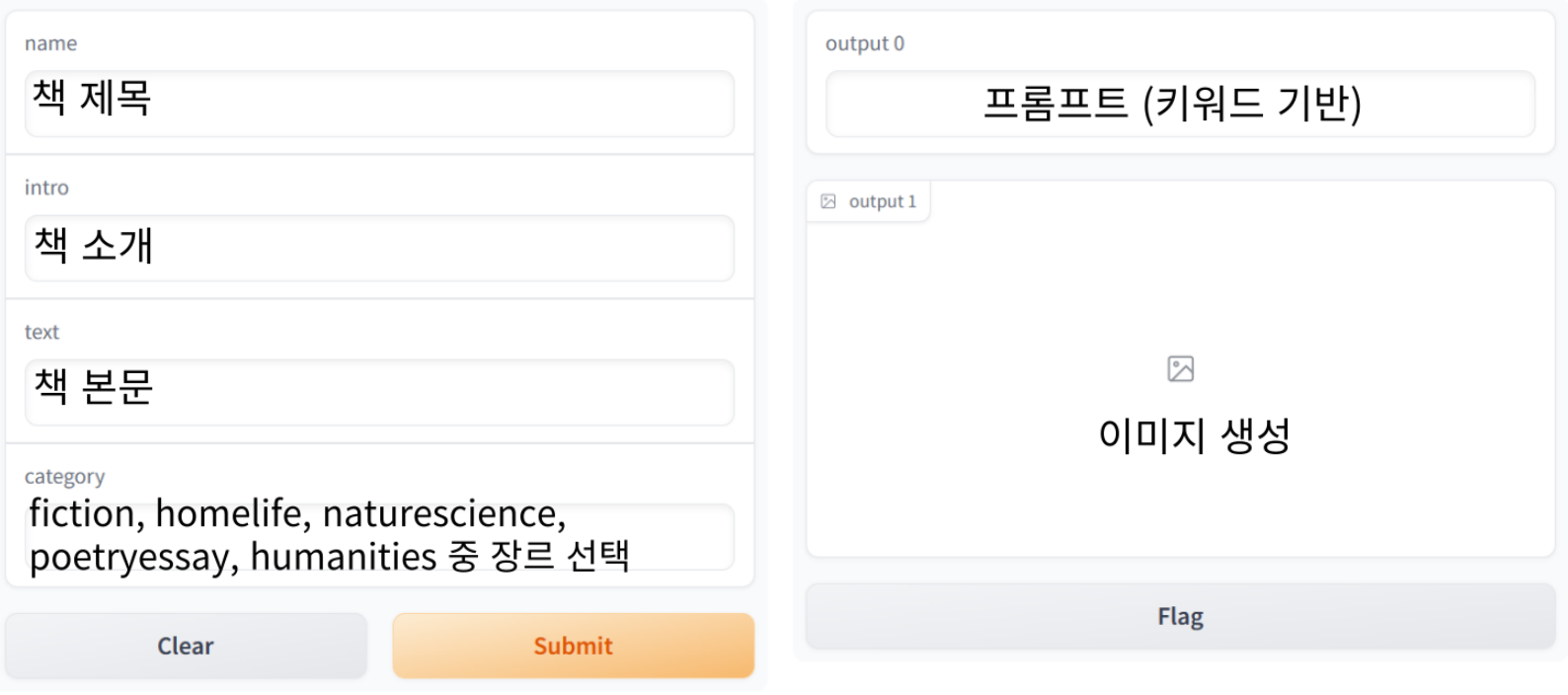
결과
-
소설 LoRA 모델 적용

-
가정과 생활 LoRA 모델 적용

-
자연과학 LoRA 모델 적용

