
Reference : Database Concepts - 2. Tables and Table Clusters
*GPT 번역 기반으로 내용이 정확하지 않을 수 있습니다.
2장 테이블 및 테이블 클러스터
이 장에서는 스키마 객체에 대한 소개와 가장 일반적인 유형의 스키마 객체인 테이블에 대해 논의합니다.
이 장에는 다음과 같은 섹션이 포함되어 있습니다:
- 스키마 객체 소개
- 테이블 개요
- 테이블 클러스터 개요
- 속성 클러스터링 테이블 개요
- 임시 테이블 개요
- 외부 테이블 개요
- 객체 테이블 개요
스키마 객체 소개
데이터베이스 스키마는 스키마 객체라고 불리는 데이터 구조의 논리적 컨테이너입니다. 스키마 객체의 예로는 테이블과 인덱스가 있습니다. SQL을 사용하여 스키마 객체를 생성하고 조작할 수 있습니다.
데이터베이스 사용자 계정은 암호와 특정 데이터베이스 권한을 가지고 있습니다. 각 사용자 계정은 사용자와 동일한 이름을 가진 단일 스키마를 소유합니다. 스키마에는 해당 사용자의 데이터가 포함됩니다. 예를 들어, hr 사용자 계정은 employees 테이블과 같은 스키마 객체를 포함하는 hr 스키마를 소유합니다. 실제 데이터베이스에서는 스키마 소유자가 보통 사람보다는 데이터베이스 애플리케이션을 나타냅니다.
스키마 내에서 특정 유형의 각 스키마 객체는 고유한 이름을 가집니다. 예를 들어, hr.employees는 hr 스키마의 employees 테이블을 나타냅니다. 그림 2-1은 hr라는 스키마 소유자와 hr 스키마 내의 스키마 객체를 보여줍니다.
그림 2-1 HR 스키마
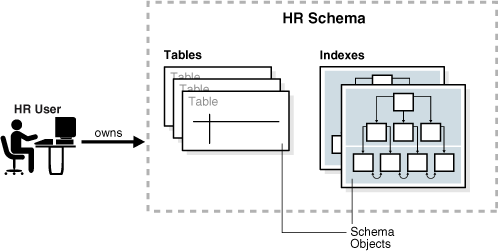
이 섹션에는 다음 주제가 포함되어 있습니다:
- 스키마 객체 유형
- 스키마 객체 저장소
- 스키마 객체 종속성
- SYS 및 SYSTEM 스키마
- 샘플 스키마
참고:
"데이터베이스 보안 개요"에서 사용자와 권한에 대해 자세히 알아보세요.
스키마 객체 유형
Oracle SQL은 많은 유형의 스키마 객체를 생성하고 조작할 수 있도록 합니다.
주요 스키마 객체 유형은 다음 표에 나와 있습니다.
표 2-1 스키마 객체
| 객체 | 설명 | 자세히 알아보기 |
|---|---|---|
| 테이블 | 테이블은 데이터를 행으로 저장합니다. 관계형 데이터베이스에서 가장 중요한 스키마 객체입니다. | "테이블 개요" |
| 인덱스 | 인덱스는 테이블이나 테이블 클러스터의 인덱스된 각 행에 대한 항목을 포함하는 스키마 객체로, 행에 대한 직접적이고 빠른 접근을 제공합니다. Oracle Database는 여러 유형의 인덱스를 지원합니다. 인덱스 구성 테이블은 데이터가 인덱스 구조에 저장된 테이블입니다. | "인덱스 및 인덱스 구성 테이블" |
| 파티션 | 파티션은 큰 테이블과 인덱스의 조각입니다. 각 파티션은 고유한 이름을 가지며, 선택적으로 고유한 저장 특성을 가질 수 있습니다. | "파티션 개요" |
| 뷰 | 뷰는 하나 이상의 테이블 또는 다른 뷰의 데이터를 사용자 정의한 표현입니다. 뷰는 실제로 데이터를 포함하지 않습니다. | "뷰 개요" |
| 시퀀스 | 시퀀스는 여러 사용자가 공유할 수 있는 사용자 생성 객체로 정수를 생성합니다. 일반적으로 시퀀스를 사용하여 기본 키 값을 생성합니다. | "시퀀스 개요" |
| 차원 | 차원은 같은 테이블에서 모든 열 집합이 나와야 하는 열 집합 쌍 간의 부모-자식 관계를 정의합니다. 차원은 일반적으로 고객, 제품, 시간과 같은 데이터를 분류하는 데 사용됩니다. | "차원 개요" |
| 동의어 | 동의어는 다른 스키마 객체에 대한 별칭입니다. 동의어는 단순히 별칭이므로 데이터 사전에서 정의하는 것 외에 저장이 필요하지 않습니다. | "동의어 개요" |
| PL/SQL 하위 프로그램 및 패키지 | PL/SQL은 Oracle의 SQL 절차 확장입니다. PL/SQL 하위 프로그램은 매개변수 집합과 함께 호출할 수 있는 이름이 있는 PL/SQL 블록입니다. PL/SQL 패키지는 논리적으로 관련된 PL/SQL 유형, 변수 및 하위 프로그램을 그룹화합니다. | "PL/SQL 하위 프로그램" |
다른 유형의 객체도 데이터베이스에 저장되고 SQL 문으로 생성 및 조작할 수 있지만, 스키마에 포함되지는 않습니다. 이러한 객체에는 데이터베이스 사용자 계정, 역할, 컨텍스트 및 사전 객체가 포함됩니다.
참고:
- Oracle Database Administrator’s Guide에서 스키마 객체를 관리하는 방법에 대해 알아보세요.
- Oracle Database SQL Language Reference에서 스키마 객체 및 데이터베이스 객체에 대해 자세히 알아보세요.
스키마 객체 저장소
일부 스키마 객체는 세그먼트라는 논리적 저장 구조 유형에 데이터를 저장합니다. 예를 들어, 비파티션 힙 구성 테이블이나 인덱스는 세그먼트를 생성합니다.
다른 스키마 객체, 예를 들어 뷰와 시퀀스는 메타데이터로만 구성됩니다. 이 주제는 세그먼트를 가진 스키마 객체만 설명합니다.
Oracle Database는 테이블스페이스 내에 스키마 객체를 논리적으로 저장합니다. 스키마와 테이블스페이스 간에는 관계가 없습니다. 테이블스페이스는 다른 스키마의 객체를 포함할 수 있으며, 스키마의 객체는 다른 테이블스페이스에 포함될 수 있습니다. 각 객체의 데이터는 하나 이상의 데이터 파일에 물리적으로 포함됩니다.
다음 그림은 테이블 및 인덱스 세그먼트, 테이블스페이스 및 데이터 파일의 가능한 구성을 보여줍니다. 하나의 테이블에 대한 데이터 세그먼트는 동일한 테이블스페이스의 두 데이터 파일에 걸쳐 있습니다. 세그먼트는 여러 테이블스페이스에 걸칠 수 없습니다.
그림 2-2 세그먼트, 테이블스페이스 및 데이터 파일
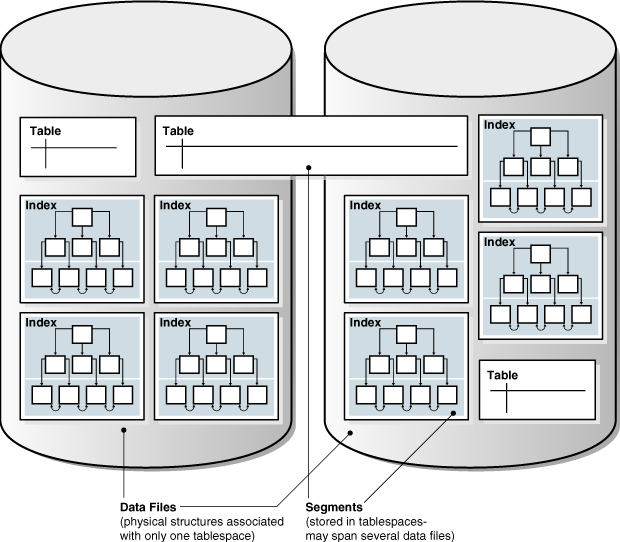
참고:
- "논리적 저장 구조"에서 테이블스페이스와 세그먼트에 대해 알아보세요.
- Oracle Database Administrator’s Guide에서 스키마 객체의 저장소를 관리하는 방법에 대해 알아보세요.
스키마 객체 종속성
일부 스키마 객체는 다른 객체를 참조하여 스키마 객체 종속성을 만듭니다.
예를 들어, 뷰는 테이블 또는 뷰를 참조하는 쿼리를 포함하고, PL/SQL 하위 프로그램은 다른 하위 프로그램을 호출합니다. 객체 A의 정의가 객체 B를 참조하면, A는 B에 종속된 객체이고, B는 A에 참조된 객체입니다.
Oracle Database는 종속 객체가 참조된 객체와 항상 최신 상태를 유지하도록 자동 메커니즘을 제공합니다. 종속 객체를 생성할 때 데이터베이스는 종속 객체와 참조된 객체 간의 종속성을 추적합니다. 참조된 객체가 종속 객체에 영향을 미칠 수 있는 방식으로 변경될 때 데이터베이스는 종속 객체를 무효화합니다. 예를 들어, 사용자가 테이블을 삭제하면 삭제된 테이블을 기반으로 한 뷰는 사용할 수 없습니다.
무효화된 종속 객체는 참조된 객체의 새 정의에 대해 다시 컴파일되어야 사용 가능합니다. 무효화된 종속 객체가 참조될 때 자동으로 다시 컴파일됩니다.
스키마 객체가 종속성을 생성하는 방법을 보여주는 예제로, 다음 샘플 스크립트는 test_table을 생성하고 이 테이블을 쿼리하는 프로시저를 생성합니다:
CREATE TABLE test_table ( col1 INTEGER, col2 INTEGER );
CREATE OR REPLACE PROCEDURE test_proc
AS
BEGIN
FOR x IN ( SELECT col1, col2 FROM test_table )
LOOP
-- process data
NULL;
END LOOP;
END;
/다음 쿼리는 test_proc 프로시저의 상태를 보여줍니다:
SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC';
OBJECT_NAME STATUS
----------- -------
TEST_PROC VALIDtest_table에 col3 열을 추가한 후에도 프로시저는 여전히 유효합니다. 왜냐하면 이 프로시저는 이 열에 대한 종속성이 없기 때문입니다:
SQL> ALTER TABLE test_table ADD col3 NUMBER;
Table altered.
SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC';
OBJECT_NAME STATUS
----------- -------
TEST_PROC VALID그러나 test_proc 프로시저가 의존하는 col1 열의 데이터 타입을 변경하면 프로시저가 무효화됩니다:
SQL> ALTER TABLE test_table MODIFY col1 VARCHAR2(20);
Table altered.
SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC';
OBJECT_NAME STATUS
----------- -------
TEST_PROC INVALID다음 예제에서와 같이 프로시저를 실행하거나 다시 컴파일하면 다시 유효하게 됩니다:
SQL> EXECUTE test_proc
PL/SQL procedure successfully completed.
SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC';
OBJECT_NAME STATUS
----------- -------
TEST_PROC VALID참고:
스키마 객체 종속성을 관리하는 방법에 대해 알아보려면 Oracle Database Administrator’s Guide와 Oracle Database Development Guide를 참조하십시오.
SYS 및 SYSTEM 스키마
모든 Oracle 데이터베이스에는 기본 관리 계정이 포함됩니다.
관리 계정은 매우 높은 권한을 가지며, 데이터베이스 시작 및 종료, 메모리 및 저장소 관리, 데이터베이스 사용자 생성 및 관리 등의 작업을 수행할 수 있는 권한이 있는 DBA만을 위한 계정입니다.
SYS 관리 계정은 데이터베이스가 생성될 때 자동으로 생성됩니다. 이 계정은 모든 데이터베이스 관리 기능을 수행할 수 있습니다. SYS 스키마는 데이터 사전의 기본 테이블과 뷰를 저장합니다. 이러한 기본 테이블과 뷰는 Oracle Database의 작동에 필수적입니다. SYS 스키마의 테이블은 데이터베이스만 조작할 수 있으며, 사용자에 의해 수정되어서는 안 됩니다.
SYSTEM 관리 계정도 데이터베이스가 생성될 때 자동으로 생성됩니다. SYSTEM 스키마는 관리 정보를 표시하는 추가 테이블과 뷰, 그리고 다양한 Oracle Database 옵션 및 도구에서 사용하는 내부 테이블과 뷰를 저장합니다. SYSTEM 스키마를 사용하여 비관리 사용자가 관심을 가질 만한 테이블을 저장해서는 안 됩니다.
참고:
- "사용자 계정"
- "관리자 권한으로 연결"
SYS,SYSTEM및 기타 관리 계정에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
샘플 스키마
Oracle 데이터베이스에는 일반적인 데이터베이스 작업을 설명하기 위해 Oracle 문서와 Oracle 교육 자료에서 사용하는 상호 연결된 스키마 세트인 샘플 스키마가 포함될 수 있습니다.
hr 샘플 스키마에는 직원, 부서 및 위치, 작업 기록 등에 대한 정보가 포함됩니다. 다음 그림은 hr 스키마의 테이블을 나타내는 엔터티 관계 다이어그램입니다. 이 매뉴얼의 대부분의 예는 이 스키마의 객체를 사용합니다.
그림 2-3 HR 스키마
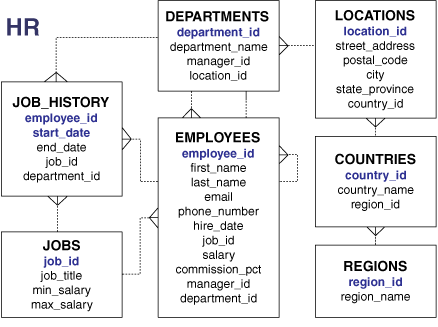
참고:
샘플 스키마를 설치하는 방법에 대해 알아보려면 Oracle Database Sample Schemas를 참조하십시오.
테이블 개요
테이블은 Oracle 데이터베이스에서 데이터 조직의 기본 단위입니다.
테이블은 정보가 기록되어야 하는 중요한 무언가인 엔티티를 설명합니다. 예를 들어, 직원은 엔티티가 될 수 있습니다.
Oracle 데이터베이스 테이블은 다음 기본 범주로 나뉩니다:
관계형 테이블
관계형 테이블은 단순한 열을 가지며 가장 일반적인 테이블 유형입니다. 예제 2-1은 관계형 테이블을 위한 CREATE TABLE 문을 보여줍니다.
객체 테이블
열은 객체 타입의 최상위 속성에 해당합니다. "객체 테이블 개요"를 참조하십시오.
관계형 테이블을 다음과 같은 조직적 특성을 가지도록 생성할 수 있습니다:
- 힙-조직 테이블은 행을 특정 순서 없이 저장합니다.
CREATE TABLE문은 기본적으로 힙-조직 테이블을 생성합니다. - 인덱스-조직 테이블은 기본 키 값에 따라 행을 정렬합니다. 일부 애플리케이션에서는 인덱스-조직 테이블이 성능을 향상시키고 디스크 공간을 더 효율적으로 사용합니다. "인덱스-조직 테이블 개요"를 참조하십시오.
- 외부 테이블은 메타데이터가 데이터베이스에 저장되지만 데이터는 데이터베이스 외부에 저장되는 읽기 전용 테이블입니다. "외부 테이블 개요"를 참조하십시오.
테이블은 영구 또는 임시일 수 있습니다. 영구 테이블 정의와 데이터는 세션 간에 유지됩니다. 임시 테이블 정의는 영구 테이블 정의와 동일하게 유지되지만 데이터는 트랜잭션 또는 세션 동안에만 존재합니다. 임시 테이블은 여러 작업을 실행하여 결과 집합을 일시적으로 유지해야 하는 애플리케이션에 유용합니다.
이 주제에는 다음 주제가 포함됩니다:
- 열
- 행
- 예제: CREATE TABLE 및 ALTER TABLE 문
- Oracle 데이터 타입
- 무결성 제약 조건
- 테이블 저장소
- 테이블 압축
참고:
테이블 관리 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
열(Columns)
테이블 정의에는 테이블 이름과 열 세트가 포함됩니다.
열은 테이블에서 설명하는 엔티티의 속성을 식별합니다. 예를 들어, employees 테이블의 employee_id 열은 직원 엔티티의 직원 ID 속성을 나타냅니다.
일반적으로 테이블을 생성할 때 각 열에 열 이름, 데이터 타입 및 너비를 지정합니다. 예를 들어, employee_id의 데이터 타입은 NUMBER(6)로, 이 열이 최대 6자리의 숫자 데이터를 포함할 수 있음을 나타냅니다. 너비는 DATE와 같이 데이터 타입에 의해 미리 결정될 수 있습니다.
가상 열(Virtual Columns)
테이블은 가상 열을 포함할 수 있으며, 이는 비가상 열과 달리 디스크 공간을 소비하지 않습니다.
데이터베이스는 사용자 지정 표현식 또는 함수를 계산하여 가상 열의 값을 필요할 때마다 도출합니다. 예를 들어, 가상 열 income은 salary 및 commission_pct 열의 함수일 수 있습니다.
참고:
가상 열 관리 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
보이지 않는 열(Invisible Columns)
보이지 않는 열은 사용자가 지정한 열로, 열 이름을 명시적으로 지정할 때만 값을 볼 수 있습니다. 기존 애플리케이션에 영향을 주지 않고 테이블에 보이지 않는 열을 추가하고 필요 시 열을 보이도록 만들 수 있습니다.
일반적으로 보이지 않는 열은 온라인 애플리케이션을 마이그레이션하고 발전시키는 데 도움이 됩니다. 예를 들어, SELECT * 문으로 세 개의 열을 쿼리하는 애플리케이션이 있을 때, 테이블에 네 번째 열을 추가하면 세 개의 열 데이터를 기대하는 애플리케이션이 중단됩니다. 네 번째 보이지 않는 열을 추가하면 애플리케이션이 정상적으로 작동합니다. 개발자는 네 번째 열을 처리하도록 애플리케이션을 변경하고 애플리케이션이 라이브될 때 열을 보이도록 만들 수 있습니다.
다음 예제는 보이지 않는 열 count가 있는 products 테이블을 생성한 다음 보이지 않는 열을 보이도록 만드는 예제입니다:
CREATE TABLE products ( prod_id INT, count INT INVISIBLE );
ALTER TABLE products MODIFY ( count VISIBLE );참고:
- 보이지 않는 열 관리 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
- 보이지 않는 열에 대한 자세한 내용은 Oracle Database SQL Language Reference를 참조하십시오.
행(Rows)
행은 테이블의 레코드에 해당하는 열 정보의 모음입니다.
예를 들어, employees 테이블의 행은 특정 직원의 속성(직원 ID, 성, 이름 등)을 설명합니다. 테이블을 생성한 후 SQL을 사용하여 행을 삽입, 쿼리, 삭제 및 업데이트할 수 있습니다.
예제: CREATE TABLE 및 ALTER TABLE 문
Oracle SQL 문을 사용하여 테이블을 생성하는 방법은 CREATE TABLE 문입니다.
예제 2-1: employees 테이블 생성
다음 예제는 hr 샘플 스키마의 employees 테이블에 대한 CREATE TABLE 문을 보여줍니다. 이 문은 employee_id, first_name 등과 같은 열을 지정하고 각 열에 대해 NUMBER 또는 DATE와 같은 데이터 타입을 지정합니다.
CREATE TABLE employees
( employee_id NUMBER(6)
, first_name VARCHAR2(20)
, last_name VARCHAR2(25)
CONSTRAINT emp_last_name_nn NOT NULL
, email VARCHAR2(25)
CONSTRAINT emp_email_nn NOT NULL
, phone_number VARCHAR2(20)
, hire_date DATE
CONSTRAINT emp_hire_date_nn NOT NULL
, job_id VARCHAR2(10)
CONSTRAINT emp_job_nn NOT NULL
, salary NUMBER(8,2)
, commission_pct NUMBER(2,2)
, manager_id NUMBER(6)
, department_id NUMBER(4)
, CONSTRAINT emp_salary_min
CHECK (salary > 0)
, CONSTRAINT emp_email_uk
UNIQUE (email)
) ;예제 2-2: employees 테이블 변경
다음 예제는 employees 테이블에 무결성 제약 조건을 추가하는 ALTER TABLE 문을 보여줍니다. 무결성 제약 조건은 비즈니스 규칙을 강제하고 테이블에 잘못된 정보가 입력되는 것을 방지합니다.
ALTER TABLE employees
ADD ( CONSTRAINT emp_emp_id_pk
PRIMARY KEY (employee_id)
, CONSTRAINT emp_dept_fk
FOREIGN KEY (department_id)
REFERENCES departments
, CONSTRAINT emp_job_fk
FOREIGN KEY (job_id)
REFERENCES jobs (job_id)
, CONSTRAINT emp_manager_fk
FOREIGN KEY (manager_id)
REFERENCES employees
) ;예제 2-3: employees 테이블의 행
다음 샘플 출력은 hr.employees 테이블의 8개 행과 6개 열을 보여줍니다.
EMPLOYEE_ID FIRST_NAME LAST_NAME SALARY COMMISSION_PCT DEPARTMENT_ID
----------- ----------- ------------- ------- -------------- -------------
100 Steven King 24000 90
101 Neena Kochhar 17000 90
102 Lex De Haan 17000 90
103 Alexander Hunold 9000 60
107 Diana Lorentz 4200 60
149 Eleni Zlotkey 10500 .2 80
174 Ellen Abel 11000 .3 80
178 Kimberely Grant 7000 .15위의 출력은 테이블, 열 및 행의 중요한 특성 중 일부를 설명합니다:
- 테이블의 행은 한 명의 직원의 속성을 설명합니다: 이름, 급여, 부서 등. 예를 들어, 출력의 첫 번째 행은 Steven King이라는 직원의 레코드를 보여줍니다.
- 열은 직원의 속성을 설명합니다. 예제에서
employee_id열은 기본 키로, 모든 직원이 고유하게 식별됩니다. 어떤 두 직원도 동일한 employee ID를 가질 수 없습니다. - 비키 열은 동일한 값을 가진 행을 포함할 수 있습니다. 예제에서 직원 101과 102의 급여 값은 동일합니다: 17000.
- 외래 키 열은 동일한 테이블 또는 다른 테이블의 기본 키나 고유 키를 참조합니다. 예제에서
department_id의 값90은departments테이블의department_id열에 해당합니다. - 필드는 행과 열의 교차점입니다. 하나의 값만 포함할 수 있습니다. 예를 들어, 직원 103의 부서 ID 필드는
60값을 포함합니다. - 필드는 값을 가질 수 없습니다. 이 경우 필드는 null 값을 포함한다고 합니다. 직원 100의
commission_pct열의 값은 null인 반면, 직원 149의 필드 값은.2입니다. 열이 null을 허용하지 않거나(NOT NULL) 기본 키 무결성 제약 조건이 정의된 경우, 이 열에 대한 값을 입력하지 않고는 행을 삽입할 수 없습니다.
참고:
CREATE TABLE 문법 및 의미에 대해 자세히 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
Oracle 데이터 타입
각 열에는 특정 저장 형식, 제약 조건 및 유효한 값 범위와 관련된 데이터 타입이 있습니다. 데이터 타입은 특정 속성 집합을 값과 연결합니다.
이러한 속성은 Oracle Database가 한 데이터 타입의 값을 다른 데이터 타입의 값과 다르게 처리하게 합니다. 예를 들어, NUMBER 데이터 타입의 값은 곱셈할 수 있지만 RAW 데이터 타입의 값은 곱셈할 수 없습니다.
테이블을 생성할 때 각 열에 대한 데이터 타입을 지정해야 합니다. 이후에 열에 삽입된 각 값은 해당 열의 데이터 타입을 따릅니다.
Oracle Database는 여러 내장 데이터 타입을 제공합니다. 가장 일반적으로 사용되는 데이터 타입은 다음 범주에 속합니다:
다른 중요한 내장 타입 범주에는 RAW, 대형 객체(LOB) 및 컬렉션이 포함됩니다. PL/SQL은 BOOLEAN, 참조 타입, 복합 타입(레코드) 및 사용자 정의 타입을 포함하는 상수 및 변수에 대한 데이터 타입을 가지고 있습니다.
참고:
- "LOB 개요"
- 내장 SQL 데이터 타입에 대해 자세히 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
- PL/SQL 데이터 타입에 대해 알아보려면 Oracle Database PL/SQL Packages and Types Reference를 참조하십시오.
- 내장 데이터 타입 사용 방법에 대해 알아보려면 Oracle Database Development Guide를 참조하십시오.
문자 데이터 타입
문자 데이터 타입은 문자열로 영숫자 데이터를 저장합니다. 가장 일반적인 문자 데이터 타입은 VARCHAR2로, 문자 데이터를 저장하는 가장 효율적인 옵션입니다.
바이트 값은 일반적으로 문자 집합이라고 하는 문자 인코딩 체계에 해당합니다. 데이터베이스 문자 집합은 데이터베이스 생성 시 설정됩니다. 문자 집합의 예로는 7비트 ASCII, EBCDIC 및 유니코드 UTF-8이 있습니다.
문자 데이터 타입의 길이 의미는 바이트 또는 문자로 측정될 수 있습니다. 문자열을 바이트 시퀀스로 처리하는 것은 바이트 의미(byte semantics)라고 합니다. 이는 문자 데이터 타입의 기본값입니다. 문자열을 문자 시퀀스로 처리하는 것은 문자 의미(character semantics)라고 합니다. 문자는 데이터베이스 문자 집합의 코드 포인트입니다.
참고:
- "Character Sets"
- 데이터 타입에 대한 간략한 소개를 보려면 Oracle Database 2 Day Developer's Guide를 참조하십시오.
- 문자 데이터 타입 선택 방법에 대해 알아보려면 Oracle Database Development Guide를 참조하십시오.
VARCHAR2 및 CHAR 데이터 타입
VARCHAR2 데이터 타입은 가변 길이 문자 리터럴을 저장합니다. 리터럴은 고정된 데이터 값입니다. 예를 들어, 'LILA', 'St. George Island', 및 '101'은 모두 문자 리터럴입니다. 5001은 숫자 리터럴입니다. 문자 리터럴은 단일 인용 부호로 묶여서 데이터베이스가 이를 스키마 객체 이름과 구별할 수 있도록 합니다.
참고: 이 설명서에서는 텍스트 리터럴, 문자 리터럴, 문자열이라는 용어를 상호 교환하여 사용합니다.
VARCHAR2 열이 있는 테이블을 생성할 때 최대 문자열 길이를 지정합니다. 예제 2-1에서 last_name 열의 데이터 타입은 VARCHAR2(25)로, 열에 저장된 이름이 최대 25바이트일 수 있음을 의미합니다.
각 행에 대해 Oracle Database는 값이 최대 길이를 초과하지 않는 한 각 값을 가변 길이 필드로 저장합니다. 예를 들어, 단일 바이트 문자 집합에서 행의 last_name 열 값으로 10자를 입력하면 해당 행 조각의 열은 25바이트가 아닌 10자(10바이트)만 저장합니다. VARCHAR2를 사용하면 공간 소비가 줄어듭니다.
VARCHAR2와 달리 CHAR는 고정 길이 문자 문자열을 저장합니다. CHAR 열이 있는 테이블을 생성할 때 열은 문자열 길이를 필요로 합니다. 기본값은 1바이트입니다. 데이터베이스는 값을 지정된 길이로 패딩하기 위해 공백을 사용합니다.
Oracle Database는 CHAR 값을 블랭크-패딩 비교 의미(nonpadded comparison semantics)를 사용하여 비교하고, VARCHAR2 값을 비패딩 비교 의미(blank-padded comparison semantics)를 사용하여 비교합니다.
참고:
블랭크-패딩 비교 의미 및 비패딩 비교 의미에 대한 자세한 내용은 Oracle Database SQL Language Reference를 참조하십시오.
NCHAR 및 NVARCHAR2 데이터 타입
NCHAR 및 NVARCHAR2 데이터 타입은 유니코드 문자 데이터를 저장합니다. 유니코드는 단일 문자 집합을 사용하여 모든 언어의 정보를 저장할 수 있는 범용 인코딩 문자 집합입니다. NCHAR는 고정 길이 문자 문자열을 저장하고 NVARCHAR2는 가변 길이 문자 문자열을 저장합니다.
데이터베이스를 생성할 때 국가 문자 집합을 지정합니다. NCHAR 및 NVARCHAR2 데이터 타입의 문자 집합은 AL16UTF16 또는 UTF8이어야 합니다. 두 문자 집합 모두 유니코드 인코딩을 사용합니다.
NCHAR 또는 NVARCHAR2 열이 있는 테이블을 생성할 때 최대 크기는 항상 문자 길이 의미로 지정됩니다. 문자 길이 의미는 NCHAR 또는 NVARCHAR2의 기본 및 유일한 길이 의미입니다.
참고:
Oracle의 글로벌화 지원 기능에 대해 알아보려면 Oracle Database Globalization Support Guide를 참조하십시오.
숫자 데이터 타입
Oracle Database 숫자 데이터 타입은 고정 및 부동 소수점 숫자, 0 및 무한대를 저장합니다. 일부 숫자 타입은 연산의 정의되지 않은 결과인 NaN(Not a Number) 값을 저장할 수도 있습니다.
Oracle Database는 숫자 데이터를 가변 길이 형식으로 저장합니다. 각 값은 지수 저장에 1바이트를 사용하여 과학적 표기법으로 저장됩니다. 데이터베이스는 맨티사를 저장하기 위해 최대 20바이트를 사용합니다. 맨티사는 부동 소수점 숫자의 중요한 자릿수를 포함하는 부분입니다. Oracle Database는 선행 및 후행 0을 저장하지 않습니다.
NUMBER 데이터 타입
NUMBER 데이터 타입은 고정 및 부동 소수점 숫자를 저장합니다. 데이터베이스는 거의 모든 크기의 숫자를 저장할 수 있습니다. 이 데이터는 Oracle Database를 실행하는 다양한 운영 체제 간에 이식 가능함이 보장됩니다. 숫자 데이터를 저장해야 하는 대부분의 경우에 NUMBER 데이터 타입을 권장합니다.
고정 소수점 숫자를 NUMBER(p,s) 형식으로 지정합니다. 여기서 p와 s는 다음 특성을 나타냅니다:
- 정밀도(Precision): 정밀도는 전체 자릿수를 지정합니다. 정밀도를 지정하지 않으면 열은 응용 프로그램이 제공하는 값을 반올림 없이 정확하게 저장합니다.
- 스케일(Scale): 스케일은 소수점 이하의 자릿수를 지정합니다. 양수 스케일은 소수점 이하의 자릿수를 가장 덜 중요한 자릿수까지 포함하여 셉니다. 음수 스케일은 소수점 좌측의 자릿수를 가장 덜 중요한 자릿수 직전까지 셉니다.
NUMBER(6)처럼 정밀도만 지정하고 스케일을 지정하지 않으면, 스케일은 0이 됩니다.
예제 2-1에서 salary 열은 NUMBER(8,2) 타입입니다. 따라서 정밀도는 8이고 스케일은 2입니다. 즉, 데이터베이스는 100,000의 급여를 100000.00으로 저장합니다.
부동 소수점 숫자
Oracle Database는 부동 소수점 숫자 전용으로 BINARY_FLOAT 및 BINARY_DOUBLE 두 가지 숫자 데이터 타입을 제공합니다.
이 타입은 NUMBER 데이터 타입이 제공하는 기본 기능을 모두 지원합니다. 그러나 NUMBER가 소수 정밀도를 사용하는 반면, BINARY_FLOAT 및 BINARY_DOUBLE은 이진 정밀도를 사용하여 더 빠른 산술 계산을 가능하게 하며 일반적으로 저장 요구 사항을 줄입니다.
BINARY_FLOAT 및 BINARY_DOUBLE은 근사치 숫자 데이터 타입입니다. 이들은 십진수 값을 정확하게 나타내지 않고 근사치로 저장합니다. 예를 들어, 0.1 값은 BINARY_DOUBLE 또는 BINARY_FLOAT로 정확하게 나타낼 수 없습니다. 이들은 과학 계산에 자주 사용됩니다. 이들의 동작은 Java와 XMLSchema의 FLOAT 및 DOUBLE 데이터 타입과 유사합니다.
참고:
숫자 타입의 정밀도, 스케일 및 기타 특성에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
날짜 및 시간 데이터 타입
날짜 및 시간 데이터 타입에는 DATE와 TIMESTAMP가 있습니다. Oracle Database는 시간 스탬프에 대해 포괄적인 시간대 지원을 제공합니다.
DATE 데이터 타입
DATE 데이터 타입은 날짜와 시간을 저장합니다. 비록 날짜와 시간이 문자 또는 숫자 데이터 타입으로 표현될 수 있지만, DATE에는 특수한 관련 속성이 있습니다.
데이터베이스는 내부적으로 날짜를 숫자로 저장합니다. 날짜는 세기, 년, 월, 일, 시간, 분, 초에 해당하는 7바이트의 고정 길이 필드에 저장됩니다.
참고: 날짜는 완전한 산술 연산을 지원하므로 숫자와 마찬가지로 날짜를 더하거나 뺄 수 있습니다.
데이터베이스는 지정된 형식 모델에 따라 날짜를 표시합니다. 형식 모델은 문자 문자열의 날짜 형식을 설명하는 문자 리터럴입니다. 표준 날짜 형식은 DD-MON-RR로, 01-JAN-11과 같은 형식으로 날짜를 표시합니다.
RR은 YY(년의 마지막 두 자리)와 유사하지만, 반환 값의 세기는 지정된 두 자리 년도와 현재 년도의 마지막 두 자리에 따라 다릅니다. 예를 들어, 1999년에 데이터베이스가 01-JAN-11을 표시한다고 가정합니다. 날짜 형식이 RR을 사용하면 11은 2011을 나타내며, 형식이 YY를 사용하면 11은 1911을 나타냅니다. 기본 날짜 형식을 데이터베이스 인스턴스 및 세션 수준에서 변경할 수 있습니다.
Oracle Database는 시간을 24시간 형식으로 저장합니다—HH:MI:SS. 시간이 입력되지 않은 경우 기본적으로 날짜 필드의 시간은 오전 00:00:00입니다. 시간만 입력된 경우 날짜 부분은 현재 월의 첫 번째 날로 기본 설정됩니다.
참고:
- 세기 및 날짜 형식 마스크에 대한 자세한 내용은 Oracle Database Development Guide를 참조하십시오.
- 날짜 형식 코드에 대한 자세한 내용은 Oracle Database SQL Language Reference를 참조하십시오.
- 날짜 및 시간 데이터 타입으로 산술 연산을 수행하는 방법에 대해 알아보려면 Oracle Database Development Guide를 참조하십시오.
TIMESTAMP 데이터 타입
TIMESTAMP 데이터 타입은 DATE 데이터 타입의 확장입니다.
TIMESTAMP는 DATE 데이터 타입에 저장된 정보에 추가하여 분수 초를 저장합니다. TIMESTAMP 데이터 타입은 이벤트 순서를 추적해야 하는 애플리케이션에서 정확한 시간 값을 저장하는 데 유용합니다.
DATETIME 데이터 타입인 TIMESTAMP WITH TIME ZONE 및 TIMESTAMP WITH LOCAL TIME ZONE은 시간대를 인식합니다. 사용자가 데이터를 선택할 때 값은 사용자 세션의 시간대로 조정됩니다. 이 데이터 타입은 지리적 지역 간에 날짜 정보를 수집하고 평가하는 데 유용합니다.
참고:
시간 스탬프 열에서 데이터를 생성하고 입력하는 구문에 대한 자세한 내용은 Oracle Database SQL Language Reference를 참조하십시오.
Rowid 데이터 타입
데이터베이스에 저장된 모든 행은 주소를 가집니다. Oracle Database는 ROWID 데이터 타입을 사용하여 데이터베이스의 모든 행의 주소(rowid)를 저장합니다.
rowid는 다음 범주로 나뉩니다:
- 물리적 rowid는 힙-조직 테이블, 테이블 클러스터 및 테이블 및 인덱스 파티션의 행 주소를 저장합니다.
- 논리적 rowid는 인덱스-조직 테이블의 행 주소를 저장합니다.
- 외부 rowid는 게이트웨이를 통해 액세스하는 DB2 테이블과 같은 외부 테이블의 식별자입니다. 이는 표준 Oracle Database rowid가 아닙니다.
모든 유형의 rowid를 지원하는 데이터 타입인 universal rowid 또는 urowid가 있습니다.
Rowid 사용
Oracle Database는 내부적으로 인덱스를 구성하는 데 rowid를 사용합니다.
B-트리 인덱스는 가장 일반적인 유형으로, 키의 정렬된 목록을 범위로 나눕니다. 각 키는 행의 주소를 가리키는 rowid와 연관되어 있어 빠르게 접근할 수 있습니다.
최종 사용자와 애플리케이션 개발자는 여러 중요한 기능에 rowid를 사용할 수 있습니다:
- rowid는 특정 행에 가장 빠르게 접근하는 수단입니다.
- rowid는 테이블이 어떻게 조직되었는지 볼 수 있는 기능을 제공합니다.
- rowid는 주어진 테이블의 행에 대한 고유 식별자입니다.
1]ROWID 데이터 타입을 사용하여 정의된 열을 사용하여 테이블을 생성할 수도 있습니다. 예를 들어, 무결성 제약 조건을 위반하는 행의 rowid를 저장하기 위해 ROWID 데이터 타입 열이 있는 예외 테이블을 정의할 수 있습니다. ROWID 데이터 타입을 사용하여 정의된 열은 다른 테이블 열처럼 동작합니다: 값은 업데이트될 수 있습니다.
ROWID 의사열(Pseudocolumn)
Oracle 데이터베이스의 모든 테이블에는 ROWID라는 의사열이 있습니다.
의사열은 테이블 열처럼 동작하지만 실제로 테이블에 저장되지 않습니다. 의사열에서 선택할 수 있지만, 값을 삽입, 업데이트 또는 삭제할 수는 없습니다. 의사열은 인수가 없는 SQL 함수와 유사합니다. 인수가 없는 함수는 일반적으로 결과 집합의 모든 행에 대해 동일한 값을 반환하는 반면, 의사열은 일반적으로 각 행에 대해 다른 값을 반환합니다.
ROWID 의사열의 값은 각 행의 주소를 나타내는 문자열입니다. 이러한 문자열은 ROWID 데이터 타입을 가집니다. 테이블의 구조를 SELECT 또는 DESCRIBE를 실행하여 나열할 때 이 의사열은 나타나지 않으며, 의사열은 공간을 차지하지 않습니다. 그러나 SQL 쿼리를 사용하여 예약어 ROWID를 열 이름으로 사용하여 각 행의 rowid를 검색할 수 있습니다.
다음 예제는 직원 100에 대한 employees 테이블의 행 rowid를 보여줍니다:
SQL> SELECT ROWID FROM employees WHERE employee_id = 100;
ROWID
------------------
AAAPecAAFAAAABSAAA참고:
- "Rowid Format"
- 주소로 행을 식별하는 방법에 대해 알아보려면 Oracle Database Development Guide를 참조하십시오.
- rowid 유형에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
형식 모델과 데이터 타입
형식 모델은 문자 문자열에 저장된 날짜 또는 숫자 데이터의 형식을 설명하는 문자 리터럴입니다. 형식 모델은 데이터베이스의 값의 내부 표현을 변경하지 않습니다.
문자 문자열을 날짜 또는 숫자로 변환할 때, 형식 모델은 데이터베이스가 문자열을 해석하는 방식을 결정합니다. SQL에서 형식 모델을 TO_CHAR 및 TO_DATE 함수의 인수로 사용하여 데이터베이스에서 반환되는 값을 형식화하거나 데이터베이스에 저장할 값을 형식화할 수 있습니다.
다음 문은 부서 80의 직원의 급여를 선택하고 TO_CHAR 함수를 사용하여 이 급여를 '$99,990.99'라는 숫자 형식 모델로 문자 값으로 변환합니다:
SQL> SELECT last_name employee, TO_CHAR(salary, '$99,990.99') AS "SALARY"
2 FROM employees
3 WHERE department_id = 80 AND last_name = 'Russell';
EMPLOYEE SALARY
------------------------- -----------
Russell $14,000.00다음 예제는 'YYYY MM DD' 형식 마스크를 사용하여 문자열 '1998 05 20'을 DATE 값으로 변환하기 위해 TO_DATE 함수를 사용하여 고용 날짜를 업데이트합니다:
SQL> UPDATE employees
2 SET hire_date = TO_DATE('1998 05 20','YYYY MM DD')
3 WHERE last_name = 'Hunold';참고:
형식 모델에 대해 자세히 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
무결성 제약 조건
무결성 제약 조건은 테이블의 하나 이상의 열에 대한 값을 제한하는 명명된 규칙입니다.
데이터 무결성 규칙은 잘못된 데이터가 테이블에 입력되지 않도록 방지합니다. 또한 제약 조건은 특정 종속성이 존재할 때 테이블 삭제를 방지할 수 있습니다.
제약 조건이 활성화되어 있으면 데이터베이스는 데이터가 입력되거나 업데이트될 때 데이터를 확인합니다. Oracle Database는 제약 조건에 맞지 않는 데이터를 입력하지 못하도록 합니다. 제약 조건이 비활성화된 경우 Oracle Database는 제약 조건에 맞지 않는 데이터를 데이터베이스에 입력할 수 있습니다.
예제 2-1에서 CREATE TABLE 문은 last_name, email, hire_date 및 job_id 열에 대해 NOT NULL 제약 조건을 지정합니다. 제약 조건 절은 열과 제약 조건의 조건을 식별합니다. 이러한 제약 조건은 지정된 열에 null 값이 포함되지 않도록 보장합니다. 예를 들어, job ID 없이 새로운 직원을 삽입하려고 하면 오류가 발생합니다.
테이블을 생성할 때 또는 생성 후에 제약 조건을 만들 수 있습니다. 필요에 따라 제약 조건을 일시적으로 비활성화할 수 있습니다. 데이터베이스는 데이터 사전에 제약 조건을 저장합니다.
참고:
- 무결성 제약 조건에 대해 알아보려면 "데이터 무결성"을 참조하십시오.
- 데이터 사전에 대해 알아보려면 "데이터 사전 개요"를 참조하십시오.
- SQL 제약 조건 절에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
테이블 저장소
Oracle Database는 테이블 데이터를 보관하기 위해 테이블스페이스의 데이터 세그먼트를 사용합니다.
세그먼트는 데이터 블록으로 구성된 확장을 포함합니다. 테이블의 데이터 세그먼트(또는 테이블 클러스터의 클러스터 데이터 세그먼트)는 테이블 소유자의 기본 테이블스페이스 또는 CREATE TABLE 문에 명명된 테이블스페이스에 위치합니다.
참고:
세그먼트의 유형과 생성 방법에 대해 알아보려면 "사용자 세그먼트"를 참조하십시오.
테이블 조직
기본적으로 테이블은 힙으로 조직되어 있으며, 이는 데이터베이스가 사용자가 지정한 순서가 아니라 가장 적합한 곳에 행을 배치한다는 것을 의미합니다. 따라서 힙-조직 테이블은 무순서 행의 모음입니다.
참고: 인덱스-조직 테이블은 다른 조직 원칙을 사용합니다.
사용자가 행을 추가하면 데이터베이스는 데이터 세그먼트의 첫 번째 사용 가능한 빈 공간에 행을 배치합니다. 행이 삽입된 순서대로 검색되는 것이 보장되지 않습니다.
hr.departments 테이블은 힙-조직 테이블입니다. 이 테이블은 부서 ID, 이름, 관리자 ID 및 위치 ID에 대한 열을 가지고 있습니다. 행이 삽입될 때 데이터베이스는 이를 적합한 곳에 저장합니다. 테이블 세그먼트의 데이터 블록은 다음 예제와 같이 무순서 행을 포함할 수 있습니다:
50,Shipping,121,1500
120,Treasury,,1700
70,Public Relations,204,2700
30,Purchasing,114,1700
130,Corporate Tax,,1700
10,Administration,200,1700
110,Accounting,205,1700열 순서는 테이블의 모든 행에 대해 동일합니다. 데이터베이스는 일반적으로 CREATE TABLE 문에 나열된 순서대로 열을 저장하지만 이 순서가 보장되지는 않습니다. 예를 들어, 테이블에 LONG 타입 열이 있는 경우 Oracle Database는 항상 이 열을 행에서 마지막에 저장합니다. 또한 테이블에 새 열을 추가하면 새 열은 마지막으로 저장됩니다.
테이블은 가상 열을 포함할 수 있으며, 이는 일반 열과 달리 디스크에서 공간을 차지하지 않습니다. 데이터베이스는 사용자 지정 표현식 또는 함수를 계산하여 가상 열의 값을 필요할 때마다 도출합니다. 가상 열을 인덱싱하고, 이에 대한 통계를 수집하고, 무결성 제약 조건을 생성할 수 있습니다. 따라서 가상 열은 비가상 열과 매우 유사합니다.
참고:
- 인덱스-조직 테이블 개요에 대해 알아보려면 "인덱스-조직 테이블 개요"를 참조하십시오.
- 가상 열에 대해 자세히 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
행 저장소(Row Storage)
데이터베이스는 데이터 블록에 행을 저장합니다. 256개 미만의 열이 포함된 테이블의 각 행은 하나 이상의 행 조각에 포함됩니다.
가능하면 Oracle Database는 각 행을 하나의 행 조각으로 저장합니다. 그러나 모든 행 데이터를 하나의 데이터 블록에 삽입할 수 없거나 기존 행에 대한 업데이트가 행이 데이터 블록을 초과하게 하는 경우 데이터베이스는 여러 행 조각을 사용하여 행을 저장합니다.
테이블 클러스터의 행은 비클러스터 테이블의 행과 동일한 정보를 포함합니다. 또한 테이블 클러스터의 행은 클러스터 키를 참조하는 정보를 포함합니다.
참고:
데이터 블록의 구성 요소에 대해 알아보려면 "데이터 블록 형식"을 참조하십시오.
행 조각의 Rowid
rowid는 실질적으로 행의 10바이트 물리적 주소입니다.
힙-조직 테이블의 모든 행에는 이 테이블에 고유한 rowid가 있으며, 이는 행 조각의 물리적 주소에 해당합니다. 테이블 클러스터의 경우 동일한 데이터 블록에 있는 다른 테이블의 행은 동일한 rowid를 가질 수 있습니다.
Oracle Database는 내부적으로 인덱스를 구성하기 위해 rowid를 사용합니다. 예를 들어, B-트리 인덱스의 각 키는 빠르게 접근할 수 있는 관련 행의 주소를 가리키는 rowid와 연관되어 있습니다. 물리적 rowid는 테이블 행에 가능한 가장 빠르게 접근할 수 있도록 하여 데이터베이스가 단일 I/O로 행을 검색할 수 있도록 합니다.
참고:
- rowid의 구조에 대해 알아보려면 "Rowid 형식"을 참조하십시오.
- B-트리 인덱스의 유형 및 구조에 대해 알아보려면 "B-트리 인덱스 개요"를 참조하십시오.
null 값 저장소
null은 열에 값이 없는 것입니다. null은 누락된, 알려지지 않은 또는 적용되지 않는 데이터를 나타냅니다.
null은 데이터 값이 있는 열 사이에 있을 경우 데이터베이스에 저장됩니다. 이러한 경우 0의 길이 열을 저장하기 위해 1바이트가 필요합니다. 행의 후행 null은 저장소가 필요 없습니다. 새 행 헤더가 이전 행의 나머지 열이 null임을 신호하기 때문입니다. 예를 들어, 테이블의 마지막 세 개의 열이 null이면 이 열에 대한 데이터가 저장되지 않습니다.
참고:
null 값에 대해 자세히 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
테이블 압축(Table Compression)
데이터베이스는 테이블 압축을 사용하여 테이블에 필요한 저장 공간을 줄일 수 있습니다.
압축은 디스크 공간을 절약하고 데이터베이스 버퍼 캐시의 메모리 사용을 줄이며, 일부 경우 쿼리 실행 속도를 높입니다. 테이블 압축은 데이터베이스 애플리케이션에 투명합니다.
기본 테이블 압축 및 고급 행 압축
사전 정의 기반 테이블 압축은 힙-조직 테이블에 대해 좋은 압축 비율을 제공합니다.
Oracle Database는 다음 유형의 사전 정의 기반 테이블 압축을 지원합니다:
- 기본 테이블 압축: 이 유형의 압축은 대량 로드 작업을 위해 설계되었습니다. 데이터베이스는 일반 DML을 사용하여 수정된 데이터를 압축하지 않습니다. 기본 테이블 압축을 달성하려면 직접 경로 INSERT 작업,
ALTER TABLE ... MOVE작업 또는 온라인 테이블 재정의를 사용해야 합니다. - 고급 행 압축: 이 유형의 압축은 OLTP 애플리케이션을 위해 설계되었으며 모든 SQL 작업으로 조작된 데이터를 압축합니다. 데이터베이스는 경쟁력 있는 압축 비율을 달성하면서 애플리케이션이 압축되지 않은 테이블에서 DML을 수행하는 것과 거의 동일한 시간에 DML을 수행할 수 있도록 합니다.
위의 압축 유형의 경우 데이터베이스는 행 주요 형식(row major format)으로 압축된 행을 저장합니다. 한 행의 모든 열이 함께 저장된 다음, 다음 행의 모든 열이 순서대로 저장됩니다. 데이터베이스는 중복 값을 블록의 시작 부분에 저장된 기호 테이블에 대한 짧은 참조로 대체합니다. 따라서 데이터베이스는 압축되지 않은 데이터를 재생성하는 데 필요한 정보를 데이터 블록 자체에 저장합니다.
압축된 데이터 블록은 일반 데이터 블록과 매우 유사하게 보입니다. 일반 데이터 블록에서 작동하는 대부분의 데이터베이스 기능과 기능은 압축된 블록에서도 작동합니다.
테이블스페이스, 테이블, 파티션 또는 서브파티션 수준에서 압축을 선언할 수 있습니다. 테이블스페이스 수준에서 지정된 경우 해당 테이블스페이스에 생성된 모든 테이블은 기본적으로 압축됩니다.
예제 2-4: 테이블 수준 압축
다음 문은 orders 테이블에 고급 행 압축을 적용합니다:
ALTER TABLE oe.orders ROW STORE COMPRESS ADVANCED;예제 2-5: 파티션 수준 압축
다음 CREATE TABLE 문 예제는 한 파티션에 대해 고급 행 압축을, 다른 파티션에 대해 기본 테이블 압축을 지정합니다:
CREATE TABLE sales (
prod_id NUMBER NOT NULL,
cust_id NUMBER NOT NULL, ... )
PCTFREE 5 NOLOGGING NOCOMPRESS
PARTITION BY RANGE (time_id)
( partition sales_2013 VALUES LESS THAN(TO_DATE(...)) ROW STORE COMPRESS BASIC,
partition sales_2014 VALUES LESS THAN (MAXVALUE) ROW STORE COMPRESS ADVANCED );참고:
- 행 형식(Row Format)에 대해 알아보려면 "행 형식"을 참조하십시오.
- 압축된 데이터 블록의 형식에 대해 알아보려면 "데이터 블록 압축"을 참조하십시오.
- 직접 경로 로드에 대해 알아보려면 "SQL*Loader"를 참조하십시오.
- 테이블 압축에 대해 알아보려면 Oracle Database Administrator’s Guide 및 Oracle Database Performance Tuning Guide를 참조하십시오.
하이브리드 컬럼 압축
하이브리드 컬럼 압축에서는 데이터베이스가 행 그룹의 동일한 열을 함께 저장합니다. 데이터 블록은 행 주요 형식으로 데이터를 저장하지 않으며, 행 및 컬럼 방법을 조합하여 사용합니다.
동일한 데이터 타입 및 유사한 특성을 가진 컬럼 데이터를 함께 저장하면 압축으로 인해 저장 공간이 크게 절약됩니다. 데이터베이스는 모든 SQL 작업으로 조작된 데이터를 압축하지만, 직접 경로 로드(direct path load)의 경우 압축 수준이 더 높습니다. 데이터베이스 작업은 압축된 객체에 대해 투명하게 작동하므로 애플리케이션 변경이 필요하지 않습니다.
참고: 하이브리드 컬럼 압축과 인메모리 컬럼 저장소(IM 컬럼 저장소)는 밀접한 관련이 있습니다. 주요 차이점은 하이브리드 컬럼 압축이 디스크 저장소를 최적화하는 반면, IM 컬럼 저장소는 메모리 저장소를 최적화한다는 것입니다.
참고:
IM 컬럼 저장소에 대해 알아보려면 "인메모리 영역"을 참조하십시오.
하이브리드 컬럼 압축의 유형
기본 저장소가 하이브리드 컬럼 압축을 지원하는 경우 요구 사항에 따라 다양한 유형의 압축을 지정할 수 있습니다.
압축 옵션은 다음과 같습니다:
- 웨어하우스 압축: 이 유형의 압축은 저장 공간 절약을 위해 최적화되어 있으며, 데이터 웨어하우스 애플리케이션을 위해 설계되었습니다.
- 아카이브 압축: 이 유형의 압축은 최대 압축 수준을 위해 최적화되어 있으며, 변경되지 않는 데이터 및 기록 데이터에 적합합니다.
하이브리드 컬럼 압축은 Oracle Exadata 저장소에서 데이터 웨어하우징 및 의사 결정 지원 애플리케이션을 위해 최적화되었습니다. Oracle Exadata는 Oracle Exadata 저장소 서버의 처리 능력, 메모리 및 Infiniband 네트워크 대역폭을 활용하여 하이브리드 컬럼 압축을 사용하여 압축된 테이블의 쿼리 성능을 극대화합니다.
다른 Oracle 저장소 시스템은 하이브리드 컬럼 압축을 지원하며 Oracle Exadata 저장소와 동일한 저장 공간 절약을 제공하지만 동일한 수준의 쿼리 성능을 제공하지 않습니다. 이러한 저장소 시스템의 경우 하이브리드 컬럼 압축은 자주 액세스되지 않는 오래된 데이터의 인-데이터베이스 아카이빙에 이상적입니다.
압축 단위(Compression Units)
하이브리드 컬럼 압축은 압축 단위라는 논리적 구성을 사용하여 행 집합을 저장합니다.
테이블에 데이터를 로드할 때 데이터베이스는 행 그룹을 컬럼 형식으로 저장하며, 각 컬럼의 값을 함께 저장하고 압축합니다. 데이터베이스가 행 집합의 컬럼 데이터를 압축한 후 데이터를 압축 단위에 맞춥니다.
예를 들어, 하이브리드 컬럼 압축을 daily_sales 테이블에 적용한다고 가정합니다. 매일의 끝에 테이블을 아이템과 판매 수량으로 채우며, 아이템 ID와 날짜는 복합 기본 키(composite primary key)를 형성합니다. 다음 테이블은 daily_sales의 행 하위 집합을 보여줍니다.
| Item_ID | Date | Num_Sold | Shipped_From | Restock |
|---|---|---|---|---|
| 1000 | 01-JUN-18 | 2 | WAREHOUSE1 | Y |
| 1001 | 01-JUN-18 | 0 | WAREHOUSE3 | N |
| 1002 | 01-JUN-18 | 1 | WAREHOUSE3 | N |
| 1003 | 01-JUN-14 | 0 | WAREHOUSE2 | N |
| 1004 | 01-JUN-18 | 2 | WAREHOUSE1 | N |
| 1005 | 01-JUN-18 | 1 | WAREHOUSE2 | N |
이 행 하위 집합이 하나의 압축 단위에 저장된다고 가정합니다. 하이브리드 컬럼 압축은 각 컬럼의 값을 함께 저장한 다음, 여러 알고리즘을 사용하여 각 컬럼을 압축합니다. 데이터베이스는 다양한 요인, 포함된 컬럼의 데이터 타입, 컬럼의 실제 값의 카디널리티 및 사용자가 선택한 압축 수준을 기반으로 알고리즘을 선택합니다.
다음 그래픽에 표시된 것처럼 각 압축 단위는 여러 데이터 블록에 걸쳐 있을 수 있습니다. 특정 컬럼의 값은 여러 블록에 걸쳐 있을 수도 있고 없을 수도 있습니다.
그림 2-4 압축 단위
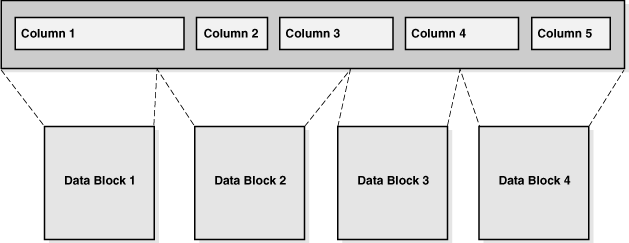
하이브리드 컬럼 압축이 공간 절약을 가져오지 않는 경우 데이터베이스는 데이터를 DBMS_COMPRESSION.COMP_BLOCK 형식으로 저장합니다. 이 경우 데이터베이스는 하이브리드 컬럼 압축 세그먼트에 있는 블록에 OLTP 압축을 적용합니다.
참고:
- "행 잠금(TX)"
- 하이브리드 컬럼 압축의 라이선스 요구 사항에 대해 알아보려면 Oracle Database Licensing Information User Manual을 참조하십시오.
- 하이브리드 컬럼 압축 사용 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
CREATE TABLE구문 및 의미에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.DBMS_COMPRESSION패키지에 대해 알아보려면 Oracle Database PL/SQL Packages and Types Reference를 참조하십시오.
DML 및 하이브리드 컬럼 압축
하이브리드 컬럼 압축은 다양한 유형의 DML 작업에 대한 행 잠금(row locking)에 영향을 미칩니다.
직접 경로 로드 및 일반 삽입(Conventional Inserts)
하이브리드 컬럼 압축을 사용하는 테이블에 데이터를 로드할 때 일반 삽입(conventional insert) 또는 직접 경로 로드(direct path load)를 사용할 수 있습니다. 직접 경로 로드는 전체 테이블을 잠가서 동시성을 줄입니다.
Oracle Database 12c Release 2 (12.2)는 하이브리드 컬럼 압축 형식에 대한 일반 배열 삽입을 지원합니다. 일반 배열 삽입의 장점은 다음과 같습니다:
- 삽입된 행은 행 수준 잠금을 사용하여 동시성을 증가시킵니다.
- 자동 데이터 최적화(ADO) 및 히트 맵은 행 수준 정책에 대해 하이브리드 컬럼 압축을 지원합니다. 따라서 데이터베이스는 다른 세그먼트에서 DML 활동이 발생하는 경우에도 적격 블록에 대해 하이브리드 컬럼 압축을 사용할 수 있습니다.
애플리케이션이 일반 배열 삽입을 사용할 때 데이터베이스는 다음 조건이 충족되면 압축 단위에 행을 저장합니다:
- 테이블이 ASSM 테이블스페이스에 저장됩니다.
- 호환성 수준이 12.2.0.1 이상입니다.
- 테이블 정의는
LONG타입 열이 없고 행 종속성이 없는 기존 하이브리드 컬럼 압축 테이블 제약 조건을 만족합니다.
일반 삽입은 redo 및 undo를 생성합니다. 따라서 일반 DML 문으로 생성된 압축 단위는 DML과 함께 롤백되거나 커밋됩니다. 데이터베이스는 일반 데이터 블록에 저장된 행과 마찬가지로 자동으로 인덱스 유지 관리를 수행합니다.
업데이트 및 삭제
기본적으로 데이터베이스는 업데이트 또는 삭제가 압축 단위의 모든 행에 적용되는 경우 압축 단위의 모든 행을 잠급니다. 이 문제를 피하려면 테이블에 대해 행 수준 잠금을 활성화할 수 있습니다. 이 경우 데이터베이스는 업데이트 또는 삭제 작업에 영향을 받는 행만 잠급니다.
참고:
- "자동 세그먼트 공간 관리(Automatic Segment Space Management)"
- 행 잠금(TX)에 대해 알아보려면 "행 잠금(TX)"을 참조하십시오.
- 일반 삽입을 수행하는 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
- INSERT 문에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
테이블 클러스터 개요
테이블 클러스터는 공통 열을 공유하고 관련 데이터를 동일한 블록에 저장하는 테이블 그룹입니다.
테이블이 클러스터되면 단일 데이터 블록에 여러 테이블의 행을 포함할 수 있습니다. 예를 들어, 하나의 블록에 employees와 departments 테이블의 행을 모두 저장할 수 있습니다.
클러스터 키는 클러스터된 테이블이 공통으로 가지는 열 또는 열들의 조합입니다. 예를 들어, employees와 departments 테이블은 department_id 열을 공유합니다. 테이블 클러스터를 생성할 때와 클러스터에 추가되는 각 테이블을 생성할 때 클러스터 키를 지정합니다.
클러스터 키 값은 특정 행 집합에 대한 클러스터 키 열의 값입니다. 동일한 클러스터 키 값을 포함하는 모든 데이터(예: department_id=20)는 물리적으로 함께 저장됩니다. 클러스터 키 값이 여러 테이블의 여러 행에 포함되어 있어도 클러스터와 클러스터 인덱스에는 해당 값이 한 번만 저장됩니다.
비유하자면, HR 매니저가 직원 폴더와 부서 폴더가 들어있는 두 개의 책장을 가지고 있다고 가정해 보겠습니다. 사용자들이 특정 부서의 모든 직원 폴더를 자주 요청하기 때문에, 매니저는 모든 폴더를 하나의 책장으로 재배치하여 검색을 쉽게 만듭니다. 매니저는 폴더를 부서 ID로 나누어, 부서 20의 모든 직원 폴더와 부서 20의 폴더 자체를 하나의 상자에, 부서 100의 모든 폴더를 다른 상자에 배치합니다.
테이블이 주로 쿼리되며(수정되지 않음), 테이블에서 자주 함께 쿼리되거나 조인되는 레코드가 있을 때 테이블 클러스터링을 고려해 보세요. 테이블 클러스터는 서로 다른 테이블의 관련 행을 동일한 데이터 블록에 저장하기 때문에, 적절히 사용된 테이블 클러스터는 비클러스터 테이블에 비해 다음과 같은 이점을 제공합니다:
- 클러스터된 테이블의 조인에 대한 디스크 I/O가 감소합니다.
- 클러스터된 테이블의 조인에 대한 액세스 시간이 개선됩니다.
- 클러스터 키 값이 각 행에 반복적으로 저장되지 않으므로 관련 테이블 및 인덱스 데이터를 저장하는 데 필요한 저장소가 적습니다.
일반적으로 다음 상황에서는 테이블 클러스터링이 적절하지 않습니다:
- 테이블이 자주 업데이트되는 경우.
- 테이블이 자주 전체 테이블 스캔을 요구하는 경우.
- 테이블이 자주 잘라내기를 요구하는 경우.
인덱스 클러스터 개요
인덱스 클러스터는 데이터를 찾기 위해 인덱스를 사용하는 테이블 클러스터입니다. 클러스터 인덱스는 클러스터 키에 대한 B-트리 인덱스입니다. 클러스터된 테이블에 행을 삽입하기 전에 클러스터 인덱스를 생성해야 합니다.
예제 2-6: 테이블 클러스터 및 관련 인덱스 생성
다음 예제와 같이 department_id 클러스터 키를 사용하여 employees_departments_cluster 클러스터를 생성한다고 가정합니다:
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4))
SIZE 512;
CREATE INDEX idx_emp_dept_cluster
ON CLUSTER employees_departments_cluster;HASHKEYS 절이 지정되지 않았기 때문에 employees_departments_cluster는 인덱스 클러스터입니다. 위 예제는 department_id 클러스터 키에 대한 idx_emp_dept_cluster라는 인덱스를 생성합니다.
예제 2-7: 인덱스 클러스터에 테이블 생성
다음과 같이 department_id 열을 클러스터 키로 지정하여 클러스터에 employees와 departments 테이블을 생성합니다(생략 부호는 열 사양이 들어갈 위치를 표시합니다):
CREATE TABLE employees ( ... )
CLUSTER employees_departments_cluster (department_id);
CREATE TABLE departments ( ... )
CLUSTER employees_departments_cluster (department_id);employees와 departments 테이블에 행을 추가한다고 가정합니다. 데이터베이스는 employees와 departments 테이블의 각 부서에 대한 모든 행을 동일한 데이터 블록에 물리적으로 저장합니다. 데이터베이스는 행을 힙에 저장하고 인덱스를 사용하여 행을 찾습니다.
그림 2-5는 employees와 departments를 포함하는 employees_departments_cluster 테이블 클러스터를 보여줍니다. 데이터베이스는 department 20의 직원 행을 함께, department 110의 직원 행을 함께 저장합니다. 테이블이 클러스터되지 않은 경우, 데이터베이스는 관련된 행이 함께 저장되도록 보장하지 않습니다.
그림 2-5 클러스터된 테이블 데이터
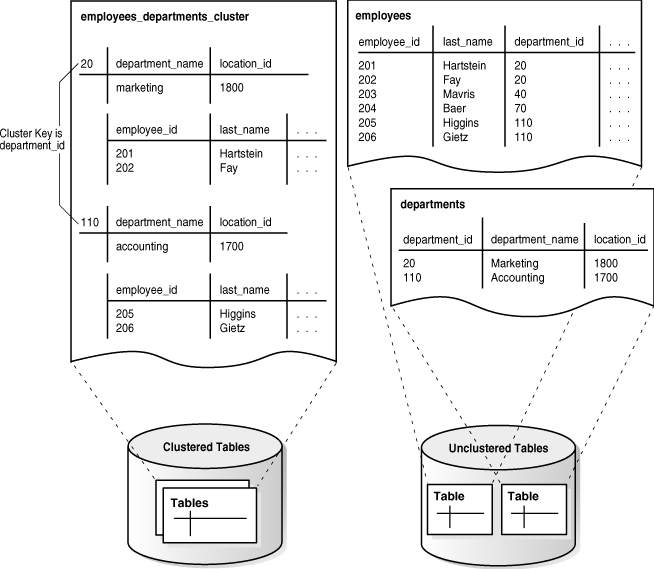
클러스터 인덱스는 클러스터 키 값을 데이터가 포함된 블록의 데이터베이스 블록 주소(DBA)와 연관시킵니다. 예를 들어, 키 20에 대한 인덱스 항목은 department 20의 직원 데이터를 포함하는 블록의 주소를 표시합니다:
20,AADAAAA9d클러스터 인덱스는 비클러스터 테이블의 인덱스처럼 별도로 관리되며, 테이블 클러스터와 다른 테이블스페이스에 존재할 수 있습니다.
참고:
- "Introduction to Indexes"
- 인덱스 클러스터 생성 및 관리 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
CREATE CLUSTER구문 및 의미에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
해시 클러스터 개요
해시 클러스터는 인덱스 키를 해시 함수로 대체한다는 점을 제외하면 인덱스 클러스터와 유사합니다. 별도의 클러스터 인덱스가 존재하지 않습니다. 해시 클러스터에서는 데이터가 인덱스입니다.
인덱스된 테이블이나 인덱스된 클러스터에서 Oracle Database는 별도의 인덱스에 저장된 키 값을 사용하여 테이블 행을 찾습니다. 인덱스된 테이블이나 테이블 클러스터에서 행을 찾거나 저장하려면 데이터베이스는 최소 두 번의 I/O를 수행해야 합니다:
- 키 값을 인덱스에서 찾거나 저장하기 위한 하나 이상의 I/O
- 테이블이나 테이블 클러스터에서 행을 읽거나 쓰기 위한 또 다른 I/O
해시 클러스터에서 행을 찾거나 저장하려면 Oracle Database는 행의 클러스터 키 값에 해시 함수를 적용합니다. 결과 해시 값은 클러스터의 데이터 블록에 해당하며, 데이터베이스는 해당 블록을 읽거나 씁니다.
해싱은 데이터 검색 성능을 향상시키기 위한 선택적 테이블 데이터 저장 방법입니다. 다음 조건이 충족될 때 해시 클러스터가 유익할 수 있습니다:
- 테이블이 수정보다 훨씬 자주 쿼리되는 경우.
- 해시 키 열이
WHERE department_id=20과 같은 등가 조건으로 자주 쿼리되는 경우. 이러한 쿼리에서는 클러스터 키 값이 해시됩니다. 해시 키 값은 행을 저장하는 디스크 영역을 직접 가리킵니다. - 해시 키의 수와 각 키 값과 함께 저장되는 데이터의 크기를 합리적으로 예측할 수 있는 경우.
해시 클러스터 생성
해시 클러스터를 생성하려면 해시 키를 추가하여 인덱스 클러스터와 동일한 CREATE CLUSTER 문을 사용합니다. 클러스터의 해시 값 수는 해시 키에 따라 다릅니다.
인덱스 클러스터의 키와 마찬가지로 클러스터 키는 클러스터 내 테이블이 공유하는 단일 열 또는 복합 키입니다. 해시 키 값은 클러스터 키 열에 삽입된 실제 또는 가능한 값입니다. 예를 들어, 클러스터 키가 department_id인 경우 해시 키 값은 10, 20, 30 등이 될 수 있습니다.
Oracle Database는 무한한 수의 해시 키 값을 입력으로 받아 유한한 수의 버킷으로 분류하는 해시 함수를 사용합니다. 각 버킷은 해시 값으로 알려진 고유한 숫자 ID를 가지고 있습니다. 각 해시 값은 해시 키 값(부서 10, 20, 30 등)에 해당하는 행을 저장하는 블록의 데이터베이스 블록 주소로 매핑됩니다.
다음 예제에서는 존재할 가능성이 있는 부서 수가 100이므로 HASHKEYS를 100으로 설정합니다:
CREATE CLUSTER employees_departments_cluster
(department_id NUMBER(4))
SIZE 8192 HASHKEYS 100;employees_departments_cluster를 생성한 후 클러스터에 employees와 departments 테이블을 생성할 수 있습니다. 그런 다음 인덱스 클러스터와 마찬가지로 해시 클러스터에 데이터를 로드할 수 있습니다.
참고:
- "인덱스 클러스터 개요"
- 해시 클러스터 생성 및 관리 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
해시 클러스터 쿼리
해시 클러스터 쿼리에서 데이터베이스는 사용자가 입력한 키 값을 해시하는 방법을 결정합니다.
예를 들어, 사용자가 p_id에 대해 다른 부서 ID 번호를 입력하여 다음과 같은 쿼리를 자주 실행한다고 가정합니다:
SELECT *
FROM employees
WHERE department_id = :p_id;
SELECT *
FROM departments
WHERE department_id = :p_id;
SELECT *
FROM employees e, departments d
WHERE e.department_id = d.department_id
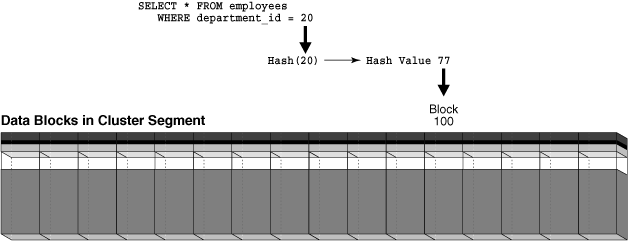
AND d.department_id = :p_id;사용자가 department_id=20인 직원을 쿼리하면 데이터베이스는 이 값을 버킷 77로 해시할 수 있습니다. 사용자가 department_id=10인 직원을 쿼리하면 데이터베이스는 이 값을 버킷 15로 해시할 수 있습니다. 데이터베이스는 내부적으로 생성된 해시 값을 사용하여 요청된 부서의 직원 행을 포함하는 블록을 찾습니다.
다음 그림은 해시 클러스터 세그먼트를 가로로 나열된 블록 행으로 묘사합니다. 그림에서 알 수 있듯이 쿼리는 단일 I/O로 데이터를 검색할 수 있습니다.
그림 2-6 해시 클러스터에서 데이터 검색
해시 클러스터의 제한 사항은 비인덱스 클러스터 키에 대한 범위 스캔이 불가능하다는 것입니다. 해시 클러스터 생성에서 생성된 해시 클러스터에 대해 별도의 인덱스가 없다고 가정합니다. ID가 20에서 100 사이인 부서를 쿼리하는 경우 해싱 알고리즘을 사용할 수 없습니다. 해시가 20에서 100 사이의 모든 값을 해시할 수 없기 때문입니다. 인덱스가 없으므로 데이터베이스는 전체 스캔을 수행해야 합니다.
참고:
"Index Range Scan"
해시 클러스터 변형
단일 테이블 해시 클러스터는 한 번에 하나의 테이블만 지원하는 해시 클러스터의 최적화된 버전입니다. 해시 키와 행 간의 일대일 매핑이 존재합니다.
단일 테이블 해시 클러스터는 사용자가 기본 키로 테이블에 빠르게 액세스해야 하는 경우 유익할 수 있습니다. 예를 들어, 사용자는 종종 employee_id로 employees 테이블에서 직원 레코드를 조회합니다.
정렬된 해시 클러스터는 해시 함수의 각 값에 해당하는 행을 데이터베이스가 효율적으로 정렬된 순서로 반환할 수 있도록 저장합니다. 데이터베이스는 내부적으로 최적화된 정렬을 수행합니다. 애플리케이션이 항상 정렬된 순서로 데이터를 사용하는 경우 이 기술은 데이터 검색 속도를 향상시킬 수 있습니다. 예를 들어, 애플리케이션은 항상 orders 테이블의 order_date 열을 기준으로 정렬할 수 있습니다.
참고:
단일 테이블 해시 클러스터 및 정렬된 해시 클러스터 생성 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
해시 클러스터 저장소
Oracle Database는 해시 클러스터에 대해 인덱스 클러스터와 다르게 공간을 할당합니다.
해시 클러스터 생성의 예에서 HASHKEYS는 존재할 가능성이 있는 부서 수를 지정하며, SIZE는 각 부서와 관련된 데이터 크기를 지정합니다. 데이터베이스는 다음 공식에 따라 저장 공간 값을 계산합니다:
HASHKEYS * SIZE / database_block_size따라서 해시 클러스터 생성 예제에서 블록 크기가 4096바이트인 경우 데이터베이스는 해시 클러스터에 최소 200블록을 할당합니다.
Oracle Database는 클러스터에 삽입할 수 있는 해시 키 값의 수를 제한하지 않습니다. 예를 들어, HASHKEYS가 100이어도 departments 테이블에 200개의 고유한 부서를 삽입하는 것을 막지 않습니다. 그러나 해시 값의 수가 해시 키 수를 초과하면 해시 클러스터 검색의 효율성이 감소합니다.
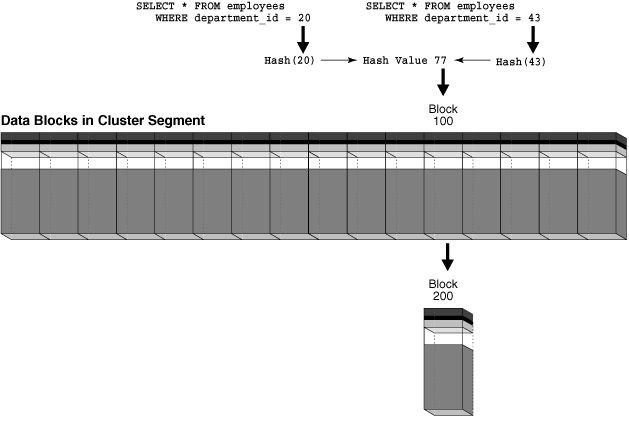
검색 문제를 설명하기 위해, 그림 2-6에서 블록 100이 department 20의 행으로 완전히 가득 차 있다고 가정합니다. 사용자가 department_id 43인 새로운 부서를 departments 테이블에 삽입합니다. 부서 수가 HASHKEYS 값을 초과했기 때문에 데이터베이스는 department_id 43을 해시 값 77로 해시합니다. 이는 department_id 20에 사용된 해시 값과 동일합니다. 여러 입력 값을 동일한 출력 값으로 해싱하는 것을 해시 충돌이라고 합니다.
사용자가 department 43에 대한 행을 클러스터에 삽입하면 데이터베이스는 이 행을 가득 찬 블록 100에 저장할 수 없습니다. 데이터베이스는 블록 100을 새로운 오버플로 블록(예: 블록 200)과 연결하고 삽입된 행을 새 블록에 저장합니다. 이제 블록 100과 200은 department 20 또는 43에 대한 데이터를 저장할 수 있습니다. 그림 2-7에 나타난 것처럼, department 20 또는 43을 쿼리하려면 이제 두 번의 I/O가 필요합니다: 블록 100과 관련된 블록 200입니다. 이 문제를 해결하려면 다른 HASHKEYS 값으로 클러스터를 다시 생성할 수 있습니다.
그림 2-7 해시 충돌이 발생할 때 해시 클러스터에서 데이터 검색
참고:
해시 클러스터에서 공간을 관리하는 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
속성 클러스터링 테이블 개요
속성 클러스터링 테이블(attribute-clustered table)은 사용자가 지정한 클러스터링 지침에 따라 디스크에서 데이터를 가까운 위치에 저장하는 힙 조직 테이블입니다. 이 지침은 단일 또는 여러 테이블의 열을 지정합니다.
지침은 다음과 같습니다:
-
CLUSTERING ... BY LINEAR ORDER지침은 지정된 열에 따라 테이블의 데이터를 정렬합니다.- 쿼리가 클러스터링 절에 지정된 열의 접두사를 자격으로 할 때는 기본값인
BY LINEAR ORDER클러스터링을 사용하는 것을 고려하십시오. 예를 들어,sh.sales의 쿼리가 고객 ID나 고객 ID와 제품 ID를 함께 자주 지정한다면,cust_id,prod_id순서로 테이블의 데이터를 클러스터링할 수 있습니다.
- 쿼리가 클러스터링 절에 지정된 열의 접두사를 자격으로 할 때는 기본값인
-
CLUSTERING ... BY INTERLEAVED ORDER지침은 Z-순서 함수와 유사한 특수 알고리즘을 사용하여 하나 이상의 테이블에서 다중 열 I/O 감소를 허용하는 방법으로 데이터를 정렬합니다.- 쿼리가 다양한 열 조합을 지정할 때는
BY INTERLEAVED ORDER클러스터링을 사용하는 것을 고려하십시오.예를 들어,sh.sales의 쿼리가 다양한 열 조합을 지정하는 경우, 이러한 차원의 열에 따라sales테이블의 데이터를 클러스터링할 수 있습니다.
- 쿼리가 다양한 열 조합을 지정할 때는
속성 클러스터링은 직접 경로 INSERT 작업에서만 사용할 수 있습니다. 일반적인 DML에서는 무시됩니다.
이 섹션에는 다음 주제가 포함됩니다:
속성 클러스터링 테이블의 장점
속성 클러스터링 테이블의 주요 이점은 I/O 감소로, 이는 테이블 스캔의 I/O 비용과 CPU 비용을 크게 줄일 수 있습니다. I/O 감소는 영역을 사용하거나 클러스터링된 값의 디스크 상의 물리적 근접성을 통해 물리적 I/O를 줄임으로써 발생합니다.
속성 클러스터링 테이블의 장점은 다음과 같습니다:
-
스타 스키마(star schema)에서 차원 열을 기반으로 사실 테이블(fact table)을 클러스터링할 수 있습니다.
- 스타 스키마에서는 대부분의 쿼리가 사실 테이블이 아닌 차원 테이블을 자격으로 지정하므로 사실 테이블 열을 클러스터링하는 것은 효과적이지 않습니다. Oracle Database는 차원 테이블의 열을 클러스터링하는 것을 지원합니다.
-
I/O 감소는 다음과 같은 여러 시나리오에서 발생할 수 있습니다:
- Oracle Exadata Storage Index, Oracle In-Memory min/max pruning, 또는 영역 맵과 함께 사용할 때
- 선형 정렬을 사용한 속성 클러스터링을 사용하는 OLTP 애플리케이션의 쿼리에서 접두사를 자격으로 지정할 때
- 교차 정렬(
BY INTERLEAVED ORDER) 클러스터링의 클러스터링 열 하위 집합에서
-
속성 클러스터링은 데이터 압축을 개선할 수 있으며, 이로 인해 간접적으로 테이블 스캔 비용을 줄일 수 있습니다. 동일한 값이 디스크에 가까이 있을 때 데이터베이스는 이를 더 쉽게 압축할 수 있습니다.
-
Oracle Database는 인덱스의 저장 및 유지 관리 비용을 부담하지 않습니다.
참고:
속성 클러스터링 테이블의 추가 장점에 대해 알아보려면 Oracle Database Data Warehousing Guide를 참조하십시오.
조인 속성 클러스터링 테이블
조인 열을 기반으로 하는 속성 클러스터링은 조인 속성 클러스터링(join attribute clustering)이라고 합니다. 테이블 클러스터와는 달리, 조인 속성 클러스터링 테이블은 동일한 데이터베이스 블록에 여러 테이블의 데이터를 저장하지 않습니다.
예를 들어, products 차원 테이블과 조인된 속성 클러스터링 테이블인 sales를 고려해보세요. sales 테이블은 sales 테이블의 행만 포함하지만, 행의 정렬은 products 테이블에서 조인된 열의 값에 따라 이루어집니다. 적절한 조인은 데이터 이동, 직접 경로 삽입 및 CREATE TABLE AS SELECT 작업 중에 실행됩니다. 반면, sales와 products가 표준 테이블 클러스터에 있는 경우, 데이터 블록은 두 테이블의 행을 포함합니다.
참고:
조인 속성 클러스터링에 대해 자세히 알아보려면 Oracle Database Data Warehousing Guide를 참조하십시오.
영역을 사용한 I/O 감소
영역(zone)은 관련 열의 최소 및 최대 값을 저장하는 연속적인 데이터 블록 세트입니다.
SQL 문이 영역에 저장된 열에 대한 조건을 포함할 때, 데이터베이스는 영역에 저장된 최소 및 최대 값과 조건 값을 비교합니다. 이를 통해 데이터베이스는 SQL 실행 중에 읽어야 할 영역을 결정합니다.
I/O 감소는 데이터베이스가 쿼리를 만족시키기 위해 필요한 데이터를 포함하지 않는 테이블 또는 인덱스 블록을 건너뛸 수 있는 능력입니다. 이 감소는 테이블 스캔의 I/O 및 CPU 비용을 크게 줄일 수 있습니다.
영역 맵(Zone Map)
영역 맵은 데이터를 영역으로 나누는 독립적인 접근 구조입니다. Oracle Database는 각 영역 맵을 물질화된 뷰의 유형으로 구현합니다.
테이블에 CLUSTERING이 지정될 때마다 데이터베이스는 지정된 클러스터링 열에 대해 자동으로 영역 맵을 생성합니다. 영역 맵은 속성 클러스터링 테이블의 연속 데이터 블록과 열의 최소 및 최대 값을 연관시킵니다. 속성 클러스터링 테이블은 영역 맵을 사용하여 I/O 감소를 수행합니다.
영역 맵을 사용하지 않는 속성 클러스터링 테이블을 생성할 수 있습니다. 또한 속성 클러스터링 테이블 없이 영역 맵을 생성할 수도 있습니다. 예를 들어, 거래가 시간 순서대로 정렬된 주식 거래 테이블과 같은 열 집합에서 자연스럽게 정렬된 테이블에 영역 맵을 생성할 수 있습니다. 영역 맵을 생성, 삭제 및 유지 관리하는 DDL 문을 실행합니다.
참고:
- "Overview of Materialized Views"
- 영역 맵에 대해 자세히 알아보려면 Oracle Database Data Warehousing Guide를 참조하십시오.
영역의 목적
영역의 느슨한 비유로, 데이터 블록과 유사한 비둘기 구멍으로 구성된 책장을 사용하는 판매 관리자를 고려해보세요.
각 비둘기 구멍에는 고객에게 판매된 셔츠를 설명하는 영수증(행)이 있으며, 배송 날짜 순으로 정렬되어 있습니다. 이 비유에서 영역 맵은 색인 카드의 스택과 같습니다. 각 카드는 영역(연속 범위)의 비둘기 구멍에 해당하며, 예를 들어 1-10번 비둘기 구멍과 같은 영역입니다. 각 영역에 대해 카드는 영역에 저장된 영수증의 최소 및 최대 배송 날짜를 나열합니다.
누군가가 특정 날짜에 배송된 셔츠를 알고 싶어하면, 관리자는 해당 날짜 범위가 포함된 카드를 찾을 때까지 카드를 뒤집어 영역을 확인하고, 해당 날짜가 포함된 비둘기 구멍에서만 영수증을 검색합니다. 이 방법으로 관리자는 책장의 모든 비둘기 구멍을 검색하지 않고도 영수증을 찾을 수 있습니다.
영역 맵 작동 방식: 예제
이 예제는 조건이 상수를 포함하는 쿼리에서 영역 맵이 데이터를 어떻게 가지치기할 수 있는지 설명합니다.
다음과 같이 lineitem 테이블을 생성한다고 가정합니다:
CREATE TABLE lineitem
( orderkey NUMBER ,
shipdate DATE ,
receiptdate DATE ,
destination VARCHAR2(50) ,
quantity NUMBER );lineitem 테이블에는 블록당 2개의 행이 있는 4개의 데이터 블록이 포함됩니다. 테이블 2-3은 테이블의 8개 행을 보여줍니다.
| 블록 | orderkey | shipdate | receiptdate | destination | quantity |
|---|---|---|---|---|---|
| 1 | 1 | 1-1-2014 | 1-10-2014 | San_Fran | 100 |
| 1 | 2 | 1-2-2014 | 1-10-2014 | San_Fran | 200 |
| 2 | 3 | 1-3-2014 | 1-9-2014 | San_Fran | 100 |
| 2 | 4 | 1-5-2014 | 1-10-2014 | San_Diego | 100 |
| 3 | 5 | 1-10-2014 | 1-15-2014 | San_Fran | 100 |
| 3 | 6 | 1-12-2014 | 1-16-2014 | San_Fran | 200 |
| 4 | 7 | 1-13-2014 | 1-20-2014 | San_Fran | 100 |
| 4 | 8 | 1-15-2014 | 1-30-2014 | San_Jose | 100 |
lineitem 테이블에 영역 맵을 생성하기 위해 CREATE MATERIALIZED ZONEMAP 문을 사용할 수 있습니다. 각 영역은 2개의 블록을 포함하며, orderkey, shipdate 및 receiptdate 열의 최소 및 최대 값을 저장합니다. 테이블 2-4는 영역 맵을 보여줍니다.
| 블록 범위 | 최소 orderkey | 최대 orderkey | 최소 shipdate | 최대 shipdate | 최소 receiptdate | 최대 receiptdate |
|---|---|---|---|---|---|---|
| 1-2 | 1 | 4 | 1-1-2014 | 1-5-2014 | 1-9-2014 | 1-10-2014 |
| 3-4 | 5 | 8 | 1-10-2014 | 1-15-2014 | 1-15-2014 | 1-30-2014 |
다음 쿼리를 실행할 때, 데이터베이스는 영역 맵을 읽고 블록 1과 2만 스캔하여 블록 3과 4를 건너뛸 수 있습니다. 이는 날짜 1-3-2014가 최소 및 최대 날짜 사이에 있기 때문입니다:
SELECT * FROM lineitem WHERE shipdate = '1-3-2014';참고:
- 영역 맵을 사용하는 방법에 대해 알아보려면 Oracle Database Data Warehousing Guide를 참조하십시오.
CREATE MATERIALIZED ZONEMAP문의 구문 및 의미에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
선형 정렬(Linear Ordering)을 사용한 속성 클러스터링 테이블(Attribute-Clustered Table)
테이블의 선형 정렬 방식은 사용자가 지정한 특정 순서의 속성에 따라 행을 범위로 나눕니다. Oracle Database는 기본 키-외래 키 관계를 통해 연결된 단일 또는 여러 테이블에서 선형 정렬을 지원합니다.
예를 들어, sales 테이블은 cust_id 및 prod_id 열을 범위로 나눈 다음 디스크에 이러한 범위를 클러스터링합니다. 테이블에 대해 BY LINEAR ORDER 지침을 지정하면 조건이 접두사 열 또는 지침의 모든 열을 지정할 때 상당한 I/O 감소가 발생할 수 있습니다.
sales의 쿼리가 고객 ID 또는 고객 ID와 제품 ID의 조합을 자주 지정한다고 가정해 보세요. 이러한 쿼리가 I/O 감소의 혜택을 받을 수 있도록 속성 클러스터링 테이블을 생성할 수 있습니다:
CREATE TABLE sales
(
prod_id NOT NULL NUMBER
, cust_id NOT NULL NUMBER
, amount_sold NUMBER(10,2) ...
)
CLUSTERING
BY LINEAR ORDER (cust_id, prod_id)
YES ON LOAD YES ON DATA MOVEMENT
WITH MATERIALIZED ZONEMAP;cust_id 및 prod_id 열 또는 접두사 cust_id를 자격으로 지정하는 쿼리는 I/O 감소를 경험합니다. prod_id만을 자격으로 지정하는 쿼리는 BY LINEAR ORDER 절의 접미사이기 때문에 I/O 감소가 크게 발생하지 않습니다. 다음 예제는 테이블 스캔 중 데이터베이스가 I/O를 줄이는 방법을 보여줍니다.
예제 2-8: cust_id만을 지정하는 경우
애플리케이션이 다음 쿼리를 발행합니다:
SELECT * FROM sales WHERE cust_id = 100;sales 테이블이 BY LINEAR ORDER 클러스터이기 때문에 데이터베이스는 cust_id 값이 100인 영역만 읽으면 됩니다.
예제 2-9: prod_id와 cust_id를 지정하는 경우
애플리케이션이 다음 쿼리를 발행합니다:
SELECT * FROM sales WHERE cust_id = 100 AND prod_id = 2300;sales 테이블이 BY LINEAR ORDER 클러스터이기 때문에 데이터베이스는 cust_id 값이 100이고 prod_id 값이 2300인 영역만 읽으면 됩니다.
참고:
- 선형 정렬을 사용하여 테이블을 클러스터링하는 방법에 대해 알아보려면 Oracle Database Data Warehousing Guide를 참조하십시오.
BY LINEAR ORDER절의 구문 및 의미에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
교차 정렬(Interleaved Ordering)을 사용한 속성 클러스터링 테이블(Attribute-Clustered Table)
교차 정렬은 Z-순서와 유사한 기술을 사용합니다.
교차 정렬을 사용하면 클러스터링 열의 조건 하위 집합에 따라 데이터베이스가 I/O를 가지치기할 수 있습니다. 교차 정렬은 데이터 웨어하우스의 차원 계층에 유용합니다.
속성 클러스터링 테이블과 선형 정렬과 마찬가지로, Oracle Database는 기본 키-외래 키 관계를 통해 연결된 단일 또는 여러 테이블에서 교차 정렬을 지원합니다. 속성 클러스터링 테이블이 아닌 다른 테이블의 열은 외래 키로 연결되어 속성 클러스터링 테이블에 조인되어야 합니다.
대규모 데이터 웨어하우스는 자주 스타 스키마로 데이터를 구성합니다. 차원 테이블은 부모-자식 계층을 사용하며 외래 키로 사실 테이블과 연결됩니다. 교차 순서로 사실 테이블을 클러스터링하면 데이터베이스가 테이블 스캔 중 차원 열의 값을 건너뛸 수 있는 특수 기능을 사용할 수 있습니다.
예제 2-10: 교차 정렬 예제
데이터 웨어하우스에 sales 사실 테이블과 두 개의 차원 테이블인 customers 및 products가 포함되어 있다고 가정합니다. 대부분의 쿼리는 customers 테이블 계층(cust_state_province, cust_city) 및 products 계층(prod_category, prod_subcategory)에 대한 조건을 가지고 있습니다. 다음 예제의 부분 문에서와 같이 sales 테이블에 교차 정렬을 사용할 수 있습니다:
CREATE TABLE sales
(
prod_id NUMBER NOT NULL
, cust_id NUMBER NOT NULL
, amount_sold NUMBER(10,2) ...
)
CLUSTERING sales
JOIN products ON (sales.prod_id = products.prod_id)
JOIN customers ON (sales.cust_id = customers.cust_id)
BY INTERLEAVED ORDER
(
( products.prod_category
, products.prod_subcategory
),
( customers.cust_state_province
, customers.cust_city
)
)
WITH MATERIALIZED ZONEMAP;참고:
BY INTERLEAVED ORDER절에 지정된 열은 실제 차원 테이블에 있을 필요는 없지만, 기본 키-외래 키 관계를 통해 연결되어야 합니다.
애플리케이션이 sales, products 및 customers 테이블을 조인하여 쿼리한다고 가정합니다. 쿼리는 다음과 같이 조건에 customers.prod_category 및 customers_cust_state_province 열을 지정합니다:
SELECT cust_city, prod_sub_category, SUM(amount_sold)
FROM sales, products, customers
WHERE sales.prod_id = products.prod_id
AND sales.cust_id = customers.cust_id
AND customers.prod_category = 'Boys'
AND customers.cust_state_province = 'England - Norfolk'
GROUP BY cust_city, prod_sub_category;위 쿼리에서 prod_category 및 cust_state_province 열은 CREATE TABLE 예제의 클러스터링 정의의 일부입니다. sales 테이블을 스캔하는 동안 데이터베이스는 영역 맵을 참조하여 이 영역의 rowid만 액세스할 수 있습니다.
참고:
- "Overview of Dimensions"
- 교차 정렬을 사용하여 테이블을 클러스터링하는 방법에 대해 알아보려면 Oracle Database Data Warehousing Guide를 참조하십시오.
BY INTERLEAVED ORDER절의 구문 및 의미에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
임시 테이블(Temporary Table) 개요
임시 테이블은 트랜잭션 또는 세션 기간 동안만 존재하는 데이터를 저장합니다.
임시 테이블의 데이터는 세션에만 국한됩니다. 각 세션은 자신의 데이터만 볼 수 있고 수정할 수 있습니다.
글로벌 임시 테이블(global temporary table) 또는 프라이빗 임시 테이블(private temporary table)을 생성할 수 있습니다. 다음 표는 이들의 주요 차이점을 보여줍니다.
표 2-5 임시 테이블 특성
| 특성 | 글로벌 | 프라이빗 |
|---|---|---|
| 네이밍 규칙 | 영구 테이블과 동일 | ORA$PTT_로 시작해야 함 |
| 테이블 정의의 가시성 | 모든 세션 | 테이블을 생성한 세션만 |
| 테이블 정의의 저장 | 디스크 | 메모리만 |
| 유형 | 트랜잭션 기반(ON COMMIT DELETE ROWS) 또는 세션 기반(ON COMMIT PRESERVE ROWS) | 트랜잭션 기반(ON COMMIT DROP DEFINITION) 또는 세션 기반(ON COMMIT PRESERVE DEFINITION) |
세 번째 유형의 임시 테이블은 커서 지속 임시 테이블(cursor-duration temporary table)로 알려져 있으며, 특정 유형의 쿼리를 위해 데이터베이스에서 자동으로 생성됩니다.
참고:
커서 지속 임시 테이블에 대해 더 알아보려면 Oracle Database SQL Tuning Guide를 참조하십시오.
임시 테이블의 목적
임시 테이블은 결과 집합을 버퍼링해야 하는 애플리케이션에 유용합니다.
예를 들어, 일정 애플리케이션은 대학생들이 선택 과목 학기 일정을 생성할 수 있게 합니다. 글로벌 임시 테이블의 행은 각 일정을 나타냅니다. 세션 동안 일정 데이터는 개인적입니다. 학생이 일정을 선택하면 애플리케이션은 선택한 일정의 행을 영구 테이블로 이동시킵니다. 세션이 끝나면 데이터베이스는 글로벌 임시 테이블에 있던 일정 데이터를 자동으로 삭제합니다.
프라이빗 임시 테이블은 동적 보고 애플리케이션에 유용합니다. 예를 들어, 고객 자원 관리(CRM) 애플리케이션은 동일한 사용자로 무기한 연결되며, 여러 세션이 동시에 활성화됩니다. 각 세션은 각 새로운 트랜잭션에 대해 ORA$PTT_crm이라는 프라이빗 임시 테이블을 생성합니다. 애플리케이션은 모든 세션에 대해 동일한 테이블 이름을 사용할 수 있지만 정의를 변경할 수 있습니다. 데이터와 정의는 세션에만 가시적입니다. 테이블 정의는 트랜잭션이 끝날 때까지 또는 테이블이 수동으로 삭제될 때까지 유지됩니다.
임시 테이블의 세그먼트 할당
영구 테이블과 마찬가지로, 글로벌 임시 테이블은 데이터 사전에 정적으로 정의된 영구 객체입니다. 프라이빗 임시 테이블의 메타데이터는 메모리에만 존재하지만, 디스크의 임시 테이블스페이스에 있을 수 있습니다.
글로벌 및 프라이빗 임시 테이블의 경우, 데이터베이스는 세션이 처음으로 데이터를 삽입할 때 임시 세그먼트를 할당합니다. 세션에 데이터가 로드될 때까지 테이블은 비어 있는 것처럼 보입니다. 트랜잭션 기반 임시 테이블의 경우, 데이터베이스는 트랜잭션이 끝날 때 임시 세그먼트를 해제합니다. 세션 기반 임시 테이블의 경우, 데이터베이스는 세션이 끝날 때 임시 세그먼트를 해제합니다.
참고:
"Temporary Segments"
임시 테이블 생성
CREATE ... TEMPORARY TABLE 문은 임시 테이블을 생성합니다.
GLOBAL TEMPORARY TABLE 또는 PRIVATE TEMPORARY TABLE을 지정하십시오. 두 경우 모두 ON COMMIT 절은 테이블 데이터가 트랜잭션 기반(기본값)인지 세션 기반인지 지정합니다. 데이터베이스 자체에 대해 임시 테이블을 생성하며, 각 PL/SQL 저장 프로시저에 대해 생성하는 것이 아닙니다.
CREATE INDEX 문으로 글로벌(프라이빗이 아닌) 임시 테이블에 대한 인덱스를 생성할 수 있습니다. 이러한 인덱스도 임시 인덱스입니다. 인덱스의 데이터는 임시 테이블의 데이터와 동일한 세션 또는 트랜잭션 범위를 가집니다. 글로벌 임시 테이블에 대한 뷰 또는 트리거도 생성할 수 있습니다.
참고:
- "Overview of Views"
- "Overview of Triggers"
- 임시 테이블을 생성 및 관리하는 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
CREATE ... TEMPORARY TABLE문법 및 의미에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
외부 테이블(External Table) 개요
외부 테이블은 데이터베이스에 있는 테이블처럼 외부 소스의 데이터에 접근합니다.
데이터는 액세스 드라이버가 제공되는 모든 형식으로 존재할 수 있습니다. SQL(직렬 또는 병렬), PL/SQL 및 Java를 사용하여 외부 테이블을 쿼리할 수 있습니다.
외부 테이블의 목적
외부 테이블은 Oracle 데이터베이스 애플리케이션이 비관계형 데이터에 접근해야 할 때 유용합니다.
예를 들어, SQL 기반 애플리케이션이 다음 형식으로 된 텍스트 파일의 레코드에 접근해야 할 수 있습니다:
100,Steven,King,SKING,515.123.4567,17-JUN-03,AD_PRES,31944,150,90
101,Neena,Kochhar,NKOCHHAR,515.123.4568,21-SEP-05,AD_VP,17000,100,90
102,Lex,De Haan,LDEHAAN,515.123.4569,13-JAN-01,AD_VP,17000,100,90외부 테이블을 생성하고, 텍스트 파일을 외부 테이블 정의에서 지정한 위치에 복사한 다음, SQL을 사용하여 텍스트 파일의 레코드를 쿼리할 수 있습니다. 유사하게, 외부 테이블을 사용하여 JSON 문서나 LOB에 읽기 전용 접근을 제공할 수 있습니다.
데이터 웨어하우스 환경에서 외부 테이블은 추출, 변환 및 로드(ETL) 작업을 수행하는 데 유용합니다. 예를 들어, 외부 테이블을 사용하면 데이터 로딩 단계와 변환 단계를 파이프라인화할 수 있습니다. 이 기술은 데이터베이스 내부에서 추가 처리를 준비하기 위해 데이터를 데이터베이스 내부에 스테이징할 필요성을 제거합니다.
외부 테이블은 가상 또는 비가상 열로 분할할 수 있습니다. 또한, 일부 파티션은 내부에 있고 일부는 외부에 있는 하이브리드 파티션 테이블을 생성할 수 있습니다. 내부 파티션과 마찬가지로, 외부 파티션도 파티션 프루닝 및 파티션별 조인과 같은 성능 향상의 이점을 누릴 수 있습니다. 예를 들어, Hadoop 분산 파일 시스템(HDFS) 또는 NoSQL 데이터베이스에 저장된 대량의 비관계형 데이터를 분석하기 위해 분할된 외부 테이블을 사용할 수 있습니다.
참고:
"Partitioned Tables"
객체 스토어(Object Store)의 데이터
외부 테이블을 사용하여 객체 스토어의 데이터에 접근할 수 있습니다.
운영 체제 파일과 빅 데이터 소스에 있는 외부 데이터에 대한 접근을 지원하는 것 외에도, Oracle은 객체 스토어에 있는 외부 데이터에 대한 접근을 지원합니다. 객체 스토리지는 클라우드에서 일반적이며, 메타데이터가 있는 모든 유형의 비정형 데이터를 개별 객체로 관리하는 평면 구조를 제공합니다. 객체 스토리지는 주로 클라우드의 데이터 저장 아키텍처이지만, 온프레미스 저장 하드웨어로도 사용할 수 있습니다.
DBMS_CLOUD 패키지를 사용하거나 외부 테이블을 수동으로 정의하여 객체 스토어의 데이터에 접근할 수 있습니다. Oracle은 DBMS_CLOUD 패키지를 사용할 것을 강력히 권장하며, 이는 추가 기능을 제공하고 Oracle Autonomous Database와 완전히 호환됩니다.
외부 테이블 액세스 드라이버
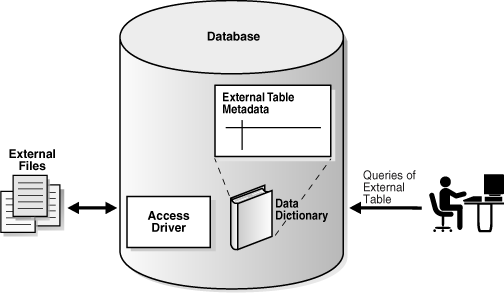
액세스 드라이버는 데이터베이스가 외부 데이터를 해석하는 API입니다. 액세스 드라이버는 데이터베이스 내부에서 실행되며, 외부 테이블의 데이터를 읽기 위해 드라이버를 사용합니다. 액세스 드라이버와 외부 테이블 계층은 데이터 파일의 데이터를 외부 테이블 정의와 일치하도록 변환하는 작업을 수행합니다.
다음 그림은 외부 데이터에 대한 SQL 접근을 나타냅니다.
그림 2-8 외부 테이블
Oracle은 외부 테이블을 위한 다음 액세스 드라이버를 제공합니다:
-
ORACLE_LOADER(기본값): SQL*Loader가 지원하는 대부분의 형식을 사용하여 외부 파일에 접근할 수 있습니다.ORACLE_LOADER드라이버를 사용하여 외부 파일을 생성, 업데이트 또는 추가할 수 없습니다. -
ORACLE_DATAPUMP: 외부 데이터를 언로드하거나 로드할 수 있습니다. 언로드 작업은 데이터베이스에서 데이터를 읽고 외부 파일로 표현된 외부 테이블에 데이터를 삽입합니다. 외부 파일이 생성된 후 데이터베이스는 이를 업데이트하거나 데이터를 추가할 수 없습니다. 로드 작업은 외부 테이블을 읽고 그 데이터를 데이터베이스로 로드합니다. -
ORACLE_HDFS: Hadoop 분산 파일 시스템(HDFS)에 저장된 데이터를 추출할 수 있습니다. -
ORACLE_HIVE: Apache Hive 데이터베이스에 저장된 데이터에 접근할 수 있습니다. 소스 데이터는 HDFS, HBase, Cassandra 또는 다른 시스템에 저장될 수 있습니다. 다른 액세스 드라이버와 달리 위치를 지정할 수 없으며, ORACLE_HIVE는 외부 메타데이터 저장소에서 위치 정보를 가져옵니다. -
ORACLE_BIGDATA: 구조화된 형식과 비구조화된 형식 모두에 저장된 데이터에 읽기 전용 접근을 제공합니다. 여기에는 Apache Parquet, Apache Avro, Apache ORC 및 텍스트 형식이 포함됩니다. 또한 이 드라이버를 사용하여 로컬 데이터를 쿼리할 수 있습니다. 이는 테스트와 작은 데이터 세트에 유용합니다.
외부 테이블 생성
내부적으로 외부 테이블을 생성하는 것은 데이터 사전에 메타데이터를 생성하는 것을 의미합니다. 일반 테이블과 달리 외부 테이블은 데이터베이스에 저장된 데이터를 설명하지 않으며 외부에 데이터가 어떻게 저장되는지 설명하지 않습니다. 외부 테이블 메타데이터는 외부 테이블 계층이 데이터베이스에 데이터를 어떻게 제공해야 하는지 설명합니다.
CREATE TABLE ... ORGANIZATION EXTERNAL 문은 두 부분으로 나뉩니다. 외부 테이블 정의는 열 유형을 설명합니다. 이 정의는 외부 데이터를 데이터베이스로 로드하지 않고 SQL을 사용하여 쿼리할 수 있게 하는 뷰와 유사합니다. 문장의 두 번째 부분은 외부 데이터를 열에 매핑합니다.
외부 테이블은 ORACLE_DATAPUMP 액세스 드라이버와 함께 CREATE TABLE AS SELECT를 사용하여 생성되지 않는 한 읽기 전용입니다. 외부 테이블의 제한 사항에는 인덱스가 있는 열과 열 객체에 대한 지원이 포함되지 않습니다.
참고:
외부 테이블에 대해 알아보려면 Oracle Database Utilities를 참조하십시오.
외부 테이블, 외부 연결 및 디렉터리 객체를 관리하는 방법에 대해 알아보려면 Oracle Database Administrator's Guide를 참조하십시오.
외부 테이블을 생성하고 쿼리하는 방법에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
블록체인 테이블 개요
블록체인 테이블은 중앙 집중식 블록체인 애플리케이션을 위해 설계된 추가 전용 테이블입니다.
Oracle 블록체인 테이블에서 피어(peer)는 데이터베이스가 변조 방지 원장을 유지할 것을 신뢰하는 데이터베이스 사용자입니다. 원장은 애플리케이션에 의해 정의되고 관리되는 블록체인 테이블로 구현됩니다. 기존 애플리케이션은 새로운 인프라나 프로그래밍 모델이 필요 없이 사기를 방지할 수 있습니다. 트랜잭션 처리량은 표준 테이블보다 낮지만, 성능은 분산 블록체인보다 우수합니다.
블록체인 테이블은 추가 전용으로, 허용되는 DML은 INSERT 명령뿐입니다. 테이블은 UPDATE, DELETE, MERGE, TRUNCATE 및 직접 경로 로드를 허용하지 않습니다. 데이터베이스 트랜잭션은 블록체인 테이블과 표준 테이블을 아우를 수 있습니다. 예를 들어, 하나의 트랜잭션이 표준 테이블과 두 개의 다른 블록체인 테이블에 행을 삽입할 수 있습니다.
행 체인(Row Chain)
블록체인 테이블에서 행 체인은 해싱 스킴으로 연결된 일련의 행입니다.
행 체인은 데이터베이스 인스턴스 ID와 체인 ID의 고유 조합으로 식별됩니다. 블록체인 테이블의 행은 정확히 하나의 행 체인에 속합니다. 단일 테이블은 여러 행 체인을 지원합니다.
참고: 표준 테이블의 체인된 행과 블록체인 테이블의 행 체인은 다릅니다. "체인"이라는 단어만 동일합니다.
체인의 각 행은 고유한 시퀀스 번호를 가집니다. 데이터베이스는 각 체인의 행에 대해 SHA2-512 해시 계산을 사용하여 행을 순서대로 나열합니다. 삽입된 각 행의 해시는 체인에서 이전에 삽입된 행의 해시 값과 삽입된 행의 내용에서 파생됩니다.
행 내용(Row Content)
행 내용은 열 데이터와 체인의 이전 행의 해시 값을 포함하는 연속된 바이트 시퀀스입니다.
블록체인 테이블을 생성할 때 데이터베이스는 여러 숨겨진 열을 생성합니다. 예를 들어, 열이 bank과 deposit인 블록체인 테이블 bank_ledger를 생성할 수 있습니다:
CREATE BLOCKCHAIN TABLE bank_ledger (bank VARCHAR2 (128), deposit NUMBER)
NO DROP UNTIL 31 DAYS IDLE
NO DELETE UNTIL 31 DAYS AFTER INSERT
HASHING USING "SHA2_512" VERSION "v1";데이터베이스는 자동으로 ORABCTAB 접두사를 가진 숨겨진 열을 생성합니다: ORABCTAB_INST_ID$, ORABCTAB_CHAIN_ID$, ORABCTAB_SEQ_NUM$ 등. 이러한 숨겨진 열은 변경하거나 관리할 수 없으며, 변조 방지 알고리즘을 구현합니다. 이 알고리즘은 커밋 시 특정 순서로 고유한 테이블 수준 잠금을 획득하여 교착 상태를 방지합니다.
참고: 블록체인 테이블의 행 내용은 표준 데이터 블록에 저장됩니다. 이 버전의 Oracle Database에서는 블록체인 테이블이 테이블 클러스터를 지원하지 않습니다.
인스턴스 ID, 체인 ID, 시퀀스 번호는 행을 고유하게 식별합니다. 각 행은 숨겨진 열 ORABCTAB_HASH$에 저장된 플랫폼 독립적인 SHA2-512 해시를 가집니다. 이 해시는 삽입된 행의 내용과 체인의 이전 행의 해시를 기반으로 합니다.
행 내용의 데이터 형식은 열 메타데이터와 내용에서 가져온 바이트로 구성됩니다. 열 메타데이터는 테이블에서의 위치, 데이터 타입, null 상태 및 바이트 길이와 같은 특성을 설명하는 20바이트 구조입니다. 열 내용은 행의 값을 나타내는 바이트 세트입니다. 예를 들어, Chase의 ASCII 표현은 43 68 61 73 65입니다. SQL의 DUMP 함수를 사용하여 열 메타데이터와 내용을 모두 얻을 수 있습니다.
해시 계산을 위한 행 내용에는 여러 열의 열 데이터 형식이 포함됩니다: 체인의 이전 행의 해시 값, 사용자 정의 열 및 고정된 수의 숨겨진 열.
블록체인 테이블의 사용자 인터페이스
표준 테이블과 마찬가지로 블록체인 테이블은 SQL로 생성되며 스칼라 데이터 타입, LOB 및 파티션을 지원합니다. 또한 블록체인 테이블에 대한 인덱스와 트리거를 생성할 수 있습니다.
블록체인 테이블을 생성하려면 CREATE BLOCKCHAIN TABLE 문을 사용합니다. 블록체인 테이블에는 NO DROP UNTIL n DAYS IDLE 절로 지정된 보존 기간이 있습니다. DROP TABLE을 사용하여 테이블을 제거할 수 있습니다.
Oracle 블록체인 테이블은 다음 인터페이스를 지원합니다:
-
DBMS_BLOCKCHAIN_TABLE패키지는 테이블 행에 다양한 작업을 수행할 수 있도록 합니다. 예를 들어,SIGN_ROW프로시저를 사용하여 이전에 삽입된 행의 내용에 서명을 적용합니다.VERIFY_ROWS를 사용하여 행이 변조되지 않았는지 확인합니다.NO DELETE절로 지정된 보존 기간이 지난 후 행을 제거하려면DELETE_ROWS를 사용합니다. -
DBMS_TABLE_DATA패키지는 열의 바이트 값을 검색하는 절차를 제공합니다. 해시나 사용자 서명이 계산된 행 데이터의 행 내용을 검색할 수 있습니다. -
DBA_BLOCKCHAIN_TABLES뷰는 행 보존 기간, 테이블 삭제 허용 전 비활성 기간 및 해시 알고리즘과 같은 테이블 메타데이터를 보여줍니다.
참고:
- 블록체인 테이블을 관리하는 방법에 대해 알아보려면 Oracle Database Administrator’s Guide를 참조하십시오.
DBMS_BLOCKCHAIN_TABLE패키지에 대해 자세히 알아보려면 Oracle Database PL/SQL Packages and Types Reference를 참조하십시오.DBMS_TABLE_DATA패키지에 대해 자세히 알아보려면 Oracle Database PL/SQL Packages and Types Reference를 참조하십시오.DBA_BLOCKCHAIN_TABLES뷰에 대해 알아보려면 Oracle Database Reference를 참조하십시오.
변경 불가능한 테이블 개요
변경 불가능한 테이블은 내부자에 의한 무단 데이터 수정과 인간 오류로 인한 실수로 인한 데이터 수정을 방지하는 읽기 전용 테이블입니다.
변경 불가능한 테이블에 새로운 행을 추가할 수 있지만, 기존 행을 수정할 수 없습니다. 변경 불가능한 테이블과 테이블 내 행에 대한 보존 기간을 지정해야 합니다. 지정된 행 보존 기간이 지난 후에만 행을 삭제할 수 있습니다.
변경 불가능한 테이블에는 시스템에서 생성한 숨겨진 열이 포함됩니다. 이 열은 블록체인 테이블의 열과 동일합니다. 행이 삽입되면 ORABCTAB_CREATION_TIME$ 및 ORABCTAB_USER_NUMBER$ 열에 대해 NULL이 아닌 값이 설정됩니다. 나머지 시스템 생성 숨겨진 열의 값은 NULL로 설정됩니다.
기존 애플리케이션을 변경하지 않고 변경 불가능한 테이블(immutable table)을 사용할 수 있습니다.
객체 테이블(Object Table) 개요
객체 테이블은 각 행이 객체를 나타내는 특별한 종류의 테이블입니다.
Oracle 객체 타입(object type)은 이름, 속성 및 메서드를 가진 사용자 정의 타입입니다. 객체 타입을 사용하면 고객 및 구매 주문과 같은 실제 엔티티를 데이터베이스의 객체로 모델링할 수 있습니다.
객체 타입은 논리적 구조를 정의하지만, 저장소를 생성하지는 않습니다. 다음 예제는 department_typ이라는 객체 타입을 생성합니다:
CREATE TYPE department_typ AS OBJECT
( d_name VARCHAR2(100),
d_address VARCHAR2(200) );
/다음 예제는 department_typ 객체 타입의 객체 테이블 departments_obj_t를 생성한 다음 테이블에 행을 삽입합니다. departments_obj_t 테이블의 속성(열)은 객체 타입 정의에서 파생됩니다:
CREATE TABLE departments_obj_t OF department_typ;
INSERT INTO departments_obj_t VALUES ('hr', '10 Main St, Sometown, CA');관계형 열과 마찬가지로 객체 테이블은 동일한 선언된 타입의 객체 인스턴스인 단일 종류의 행만 포함할 수 있습니다. 기본적으로 객체 테이블의 각 행 객체는 객체 테이블에서 고유하게 식별하는 논리적 객체 식별자(OID)를 가집니다. 객체 테이블의 OID 열은 숨겨진 열입니다.
참고:
- Oracle Database Object-Relational Developer's Guide에서 Oracle Database의 객체-관계형 기능에 대해 자세히 알아보십시오.
CREATE TYPE구문 및 의미에 대해 알아보려면 Oracle Database SQL Language Reference를 참조하십시오.
