
Reference : Database Concepts - 3. Indexes and Index-Organized Tables
*GPT 번역 기반으로 내용이 정확하지 않을 수 있습니다.
Indexes and Index-Organized Tables
인덱스는 테이블 행에 대한 접근을 빠르게 할 수 있는 스키마 객체입니다. 인덱스 조직 테이블은 인덱스 구조로 저장된 테이블입니다.
이 장은 다음 섹션을 포함합니다:
- 인덱스 소개
- B-트리 인덱스 개요
- 비트맵 인덱스 개요
- 함수 기반 인덱스 개요
- 애플리케이션 도메인 인덱스 개요
- 인덱스 조직 테이블 개요
Introduction to Indexes
인덱스는 테이블이나 테이블 클러스터와 연관된 선택적 구조로, 때때로 데이터 접근 속도를 높일 수 있습니다.
인덱스는 연관된 데이터 객체와 논리적 및 물리적으로 독립적인 스키마 객체입니다. 따라서 인덱스를 삭제하거나 생성해도 인덱스된 테이블에 물리적인 영향을 미치지 않습니다.
참고: 인덱스를 삭제해도 애플리케이션은 계속 작동하지만, 이전에 인덱스된 데이터에 대한 접근 속도가 느려질 수 있습니다.
비유를 들어 설명하자면, HR 관리자가 여러 개의 종이 상자가 있는 선반을 가지고 있다고 가정해 보세요. 직원 정보가 포함된 폴더가 상자에 무작위로 삽입되어 있습니다. 예를 들어, 직원 Whalen(ID 200)의 폴더는 상자 1의 바닥에서 10번째 위치에 있으며, 직원 King(ID 100)의 폴더는 상자 3의 바닥에 있습니다. 관리자는 폴더를 찾기 위해 상자 1의 바닥에서부터 모든 폴더를 하나씩 살펴보고, 상자에서 상자로 이동하면서 폴더를 찾을 때까지 계속합니다. 접근 속도를 높이기 위해, 관리자는 모든 직원 ID와 폴더 위치를 순서대로 나열한 인덱스를 생성할 수 있습니다.
ID 100: 상자 3, 위치 1 (바닥)
ID 101: 상자 7, 위치 8
ID 200: 상자 1, 위치 10
.
.
.마찬가지로, 관리자는 직원 성, 부서 ID 등 별도의 인덱스를 생성할 수 있습니다.
이 섹션에는 다음 주제가 포함됩니다:
- 인덱스의 장점과 단점
- 인덱스 사용성 및 가시성
- 키와 컬럼
- 복합 인덱스
- 고유 및 비고유 인덱스
- 인덱스 유형
- 데이터베이스가 인덱스를 유지하는 방법
- 인덱스 저장소
Advantages and Disadvantages of Indexes
인덱스의 존재 여부는 SQL 문장의 단어 변경을 필요로 하지 않습니다.
인덱스는 데이터 행에 대한 빠른 접근 경로입니다. 이는 실행 속도에만 영향을 미칩니다. 인덱스된 데이터 값을 기준으로 인덱스는 해당 값을 포함한 행의 위치를 직접 가리킵니다.
테이블의 하나 이상의 컬럼에 인덱스가 존재하면 데이터베이스는 경우에 따라 테이블의 소수의 무작위로 분포된 행을 검색할 수 있습니다. 인덱스는 디스크 I/O를 줄이는 여러 수단 중 하나입니다. 힙 조직 테이블에 인덱스가 없으면 데이터베이스는 값을 찾기 위해 전체 테이블을 스캔해야 합니다. 예를 들어, 인덱스되지 않은 hr.departments 테이블에서 위치 2700을 쿼리하려면 데이터베이스는 모든 행과 모든 블록을 검색해야 합니다. 데이터 볼륨이 증가함에 따라 이 접근 방식은 확장되지 않습니다.
인덱스의 단점은 다음과 같습니다:
- 인덱스를 수동으로 생성하려면 데이터 모델, 애플리케이션 및 데이터 분포에 대한 깊은 지식이 필요합니다.
- 데이터가 변경되면 이전의 인덱스 결정에 대한 재검토가 필요합니다. 인덱스가 더 이상 유용하지 않을 수 있으며, 새로운 인덱스가 필요할 수 있습니다.
- 인덱스는 디스크 공간을 차지합니다.
- 데이터 조작 언어(DML) 작업이 인덱스된 데이터에서 발생하면 데이터베이스는 인덱스를 업데이트해야 하며, 이는 성능 오버헤드를 발생시킵니다.
참고: Oracle Database 19c부터 Oracle Database는 애플리케이션 워크로드를 지속적으로 모니터링하여 인덱스를 자동으로 생성하고 관리할 수 있습니다. 자동 인덱싱은 고정된 간격으로 실행되는 데이터베이스 작업으로 구현됩니다.
다음과 같은 상황에서 인덱스 생성 고려:
- 인덱스된 컬럼이 자주 쿼리되고 테이블의 전체 행 수 중 소수의 비율만 반환되는 경우.
- 인덱스된 컬럼 또는 컬럼에 참조 무결성 제약 조건이 존재하는 경우. 인덱스는 부모 테이블 기본 키를 업데이트하거나, 부모 테이블로 병합하거나, 부모 테이블에서 삭제할 때 전체 테이블 잠금을 피하는 수단입니다.
- 테이블에 고유 키 제약 조건을 배치하려고 하며, 인덱스와 모든 인덱스 옵션을 수동으로 지정하려는 경우.
Index Usability and Visibility
인덱스는 사용 가능(default) 또는 사용 불가능하며, 가시성은 visible(default) 또는 invisible입니다.
이 속성은 다음과 같이 정의됩니다:
사용성
사용할 수 없는 인덱스는 옵티마이저에 의해 무시되며, DML 작업에 의해 유지되지 않습니다. 사용 불가능한 인덱스는 대량 로드의 성능을 향상시킬 수 있습니다. 인덱스를 삭제하고 나중에 다시 생성하는 대신, 인덱스를 사용 불가능하게 하고 다시 빌드할 수 있습니다. 사용 불가능한 인덱스 및 인덱스 파티션은 공간을 소비하지 않습니다. 사용 가능한 인덱스를 사용 불가능하게 하면 데이터베이스는 해당 인덱스 세그먼트를 삭제합니다.
가시성
보이지 않는 인덱스는 DML 작업에 의해 유지되지만, 기본적으로 옵티마이저에 의해 사용되지 않습니다. 인덱스를 보이지 않게 만드는 것은 이를 사용 불가능하게 만들거나 삭제하는 대안입니다. 보이지 않는 인덱스는 인덱스를 삭제하기 전에 제거를 테스트하거나, 전체 애플리케이션에 영향을 주지 않고 인덱스를 일시적으로 사용하는 경우에 특히 유용합니다.
Keys and Columns
키는 인덱스를 빌드할 수 있는 컬럼 또는 표현식의 집합입니다.
용어는 종종 혼용되지만, 인덱스와 키는 다릅니다. 인덱스는 사용자가 SQL 문을 사용하여 관리하는 데이터베이스에 저장된 구조입니다. 키는 엄격히 논리적 개념입니다.
다음 명령문은 샘플 테이블 oe.orders의 customer_id 컬럼에 인덱스를 생성합니다:
CREATE INDEX ord_customer_ix ON orders (customer_id);위의 명령문에서 customer_id 컬럼은 인덱스 키입니다. 인덱스 자체는 ord_customer_ix라고 명명됩니다.
참고: 기본 키와 고유 키는 자동으로 인덱스를 가지지만, 외래 키에 인덱스를 생성할 수도 있습니다.
Composite Indexes
복합 인덱스는 테이블의 여러 컬럼에 대한 인덱스입니다. 복합 인덱스는 연결된 인덱스라고도 합니다.
컬럼을 복합 인덱스에 포함하는 순서는 데이터를 검색하는 쿼리에 가장 적합한 순서로 정해야 합니다. 컬럼은 테이블에서 인접하지 않아도 됩니다.
복합 인덱스는 WHERE 절에서 복합 인덱스의 모든 컬럼 또는 선두 부분을 참조하는 SELECT 문에 대한 데이터 검색 속도를 높일 수 있습니다. 따라서 정의에서 사용된 컬럼의 순서가 중요합니다. 일반적으로 가장 자주 접근하는 컬럼이 먼저 옵니다.
예를 들어, 애플리케이션이 employees 테이블의 last_name, job_id, salary 컬럼을 자주 쿼리한다고 가정해보세요. 또한 last_name이 높은 카디널리티를 가지며, 이는 고유 값의 수가 테이블 행 수에 비해 많다는 의미입니다. 다음과 같은 컬럼 순서로 인덱스를 생성합니다:
CREATE INDEX employees_ix
ON employees (last_name, job_id, salary);이 인덱스를 사용하여 세 컬럼 모두, 또는 last_name 컬럼만, 또는 last_name과 job_id 컬럼만을 참조하는 쿼리를 처리할 수 있습니다. 이 예에서 last_name 컬럼을 참조하지 않는 쿼리는 인덱스를 사용하지 않습니다.
참고: 선두 컬럼의 카디널리티가 매우 낮은 경우 데이터베이스는 이 인덱스의 건너뛰기 스캔을 사용할 수 있습니다.
다음 조건을 충족하면 동일한 테이블에 동일한 컬럼 순서로 여러 인덱스가 존재할 수 있습니다:
- 인덱스 유형이 다른 경우.
- 예를 들어, 동일한 컬럼에 비트맵 및 B-트리 인덱스를 생성할 수 있습니다.
- 인덱스가 다른 파티션 스키마를 사용하는 경우.
- 예를 들어, 로컬 파티셔닝된 인덱스와 전역 파티셔닝된 인덱스를 생성할 수 있습니다.
- 인덱스의 고유 속성이 다른 경우.
- 예를 들어, 동일한 컬럼 집합에 대해 고유 인덱스와 비고유 인덱스를 모두 생성할 수 있습니다.
예를 들어, 동일한 테이블 컬럼에 대해 동일한 순서로 비파티션 인덱스, 전역 파티셔닝 인덱스 및 로컬 파티셔닝 인덱스가 존재할 수 있습니다. 동일한 순서로 동일한 수의 컬럼을 포함하는 인덱스는 한 번에 하나만 visible 상태일 수 있습니다.
이 기능은 다른 속성으로 기존 인덱스를 삭제하고 다시 생성할 필요 없이 애플리케이션을 마이그레이션할 수 있게 합니다. 또한 인덱스 키가 계속 증가하여 데이터베이스가 동일한 인덱스 블록 세트에 새 항목을 삽입하게 되는 OLTP 데이터베이스에서 유용합니다. 이러한 "핫 스팟"을 완화하기 위해 인덱스를 비파티션 인덱스에서 전역 파티셔닝 인덱스로 진화시킬 수 있습니다.
동일한 컬럼 집합에 대한 인덱스가 유형 또는 파티션 스키마에서 다르지 않은 경우 이러한 인덱스는 서로 다른 컬럼 순열을 사용해야 합니다. 예를 들어, 다음 SQL 명령문은 유효한 컬럼 순열을 지정합니다:
CREATE INDEX employee_idx1 ON employees (last_name, job_id);
CREATE INDEX employee_idx2 ON employees (job_id, last_name);Unique and Nonunique Indexes
인덱스는 고유 또는 비고유일 수 있습니다. 고유 인덱스는 테이블의 두 행이 키 컬럼 또는 컬럼에 중복 값을 가지지 않도록 보장합니다.
예를 들어, 애플리케이션은 두 명의 직원이 동일한 직원 ID를 가질 수 없도록 요구할 수 있습니다. 고유 인덱스에서는 각 데이터 값에 대해 하나의 rowid만 존재합니다. 잎 블록의 데이터는 키에 따라 정렬됩니다.
비고유 인덱스는 인덱스된 컬럼 또는 컬럼에 중복 값을 허용합니다. 예를 들어, employees 테이블의 first_name 컬럼은 여러 Mike 값을 포함할 수 있습니다. 비고유 인덱스의 경우 rowid는 키에 정렬된 순서로 포함됩니다. 따라서 비고유 인덱스는 인덱스 키와 rowid에 따라 정렬됩니다.
Oracle Database는 모든 키 컬럼이 null인 테이블 행을 인덱싱하지 않습니다. 다만 비트맵 인덱스 또는 클러스터 키 컬럼 값이 null인 경우는 예외입니다.
Types of Indexes
Oracle Database는 다양한 인덱싱 스키마를 제공하며, 이들 각각은 보완적인 성능 기능을 제공합니다.
B-트리 인덱스는 표준 인덱스 유형입니다. 이는 매우 선택적인 인덱스(각 인덱스 항목에 해당하는 행이 적은 경우)와 기본 키 인덱스에 적합합니다. 연결된 인덱스로 사용될 때, B-트리 인덱스는 인덱스된 컬럼에 따라 정렬된 데이터를 검색할 수 있습니다. B-트리 인덱스는 다음 표에 표시된 하위 유형을 가집니다.
표 3-1 B-트리 인덱스 하위 유형
| B-트리 인덱스 하위 유형 | 설명 | 자세히 알아보기 |
|---|---|---|
| 인덱스 조직 테이블 | 인덱스 조직 테이블은 힙 조직 테이블과 다르며, 데이터 자체가 인덱스입니다. | "Overview of Index-Organized Tables" |
| 역순 키 인덱스 | 이 유형의 인덱스에서는 인덱스 키의 바이트가 역순으로 저장됩니다. 예를 들어, 103은 301로 저장됩니다. 바이트 역순은 인덱스의 많은 블록에 삽입을 분산시킵니다. | "Reverse Key Indexes" |
| 내림차순 인덱스 | 이 유형의 인덱스는 특정 컬럼 또는 컬럼의 데이터를 내림차순으로 저장합니다. | "Ascending and Descending Indexes" |
| B-트리 클러스터 인덱스 | 이 유형의 인덱스는 특정 컬럼 또는 컬럼의 데이터를 내림차순으로 저장합니다. | "Ascending and Descending Indexes" |
다음 표는 B-트리 구조를 사용하지 않는 인덱스 유형을 보여줍니다.
표 3-2 B-트리 구조를 사용하지 않는 인덱스
| 유형 | 설명 | 자세히 알아보기 |
|---|---|---|
| 비트맵 및 비트맵 조인 인덱스 | 비트맵 인덱스에서는 인덱스 항목이 여러 행을 가리키기 위해 비트맵을 사용합니다. 반면에, B-트리 인덱스 항목은 단일 행을 가리킵니다. 비트맵 조인 인덱스는 두 개 이상의 테이블 조인을 위한 비트맵 인덱스입니다. | "Overview of Bitmap Indexes" |
| 함수 기반 인덱스 | 이 유형의 인덱스는 함수로 변환된 컬럼 또는 표현식을 포함합니다. B-트리 또는 비트맵 인덱스가 함수 기반이 될 수 있습니다. | "Overview of Function-Based Indexes" |
| 애플리케이션 도메인 인덱스 | 사용자가 애플리케이션 특정 도메인의 데이터에 대해 이 유형의 인덱스를 생성합니다. 물리적 인덱스는 전통적인 인덱스 구조를 사용할 필요가 없으며, Oracle 데이터베이스에 테이블로 저장되거나 외부 파일로 저장될 수 있습니다. | "Overview of Application Domain Indexes" |
How the Database Maintains Indexes
데이터베이스는 인덱스가 생성된 후 자동으로 유지하고 사용합니다.
인덱스는 기본 테이블에 대한 데이터 변경을 자동으로 반영합니다. 예를 들어, 행 추가, 업데이트, 삭제 등이 이에 해당합니다. 사용자의 작업은 필요하지 않습니다.
인덱스된 데이터의 검색 성능은 행이 삽입되더라도 거의 일정하게 유지됩니다. 하지만 테이블에 많은 인덱스가 존재하면 데이터베이스가 인덱스를 업데이트해야 하기 때문에 DML 성능이 저하될 수 있습니다.
Index Storage
Oracle Database는 인덱스 데이터를 인덱스 세그먼트에 저장합니다.
데이터 블록에서 인덱스 데이터에 사용할 수 있는 공간은 데이터 블록 크기에서 블록 오버헤드, 항목 오버헤드, rowid 및 각 값에 대해 인덱싱된 길이 바이트를 뺀 값입니다.
인덱스 세그먼트의 테이블스페이스는 소유자의 기본 테이블스페이스이거나 CREATE INDEX 명령문에 명시된 특정 테이블스페이스입니다. 관리의 용이성을 위해 인덱스를 테이블과 별도의 테이블스페이스에 저장할 수 있습니다. 예를 들어, 인덱스만 포함된 테이블스페이스를 백업하지 않음으로써 백업에 필요한 시간과 저장소를 줄일 수 있습니다.
Overview of B-Tree Indexes
B-트리는 균형 트리(balanced trees)의 약자로, 가장 일반적인 데이터베이스 인덱스 유형입니다. B-트리 인덱스는 값의 순서가 있는 목록으로, 값이 범위로 나뉩니다. 키를 행이나 행 범위와 연결함으로써 B-트리는 일치 검색 및 범위 검색을 포함한 다양한 쿼리에 대해 뛰어난 검색 성능을 제공합니다.
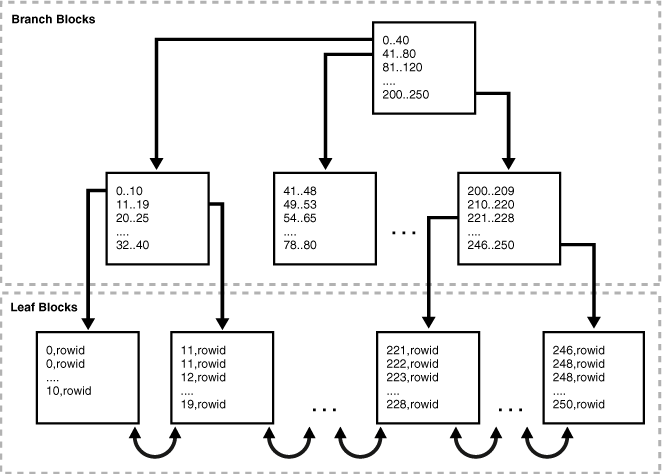
다음 그림은 B-트리 인덱스의 구조를 보여줍니다. 예제는 department_id 컬럼에 대한 인덱스를 보여줍니다. 이 컬럼은 employees 테이블의 외래 키 컬럼입니다.
그림 3-1 B-트리 인덱스의 내부 구조
이 섹션에는 다음 주제가 포함됩니다:
- 브랜치 블록 및 리프 블록
- 인덱스 스캔
- 역순 키 인덱스
- 내림차순 인덱스
- 인덱스 압축
Branch Blocks and Leaf Blocks
B-트리 인덱스에는 두 가지 유형의 블록이 있습니다: 검색을 위한 브랜치 블록과 키 값을 저장하는 리프 블록입니다. B-트리 인덱스의 상위 수준 브랜치 블록에는 하위 수준 인덱스 블록을 가리키는 인덱스 데이터가 포함됩니다.
그림 3-1에서 루트 브랜치 블록에는 다음 브랜치 수준의 가장 왼쪽 블록을 가리키는 항목 0-40이 포함되어 있습니다. 이 브랜치 블록에는 0-10 및 11-19와 같은 항목이 포함되어 있습니다. 각 항목은 해당 범위에 해당하는 키 값을 포함하는 리프 블록을 가리킵니다.
B-트리 인덱스는 균형이 잡혀 있어서 모든 리프 블록이 자동으로 동일한 깊이를 유지합니다. 따라서 인덱스의 어느 위치에서든 레코드를 검색하는 데 걸리는 시간이 거의 동일합니다. 인덱스의 높이는 루트 블록에서 리프 블록으로 이동하는 데 필요한 블록 수입니다. 브랜치 수준은 높이에서 1을 뺀 값입니다. 그림 3-1에서는 인덱스의 높이가 3이고 브랜치 수준이 2입니다.
브랜치 블록은 두 키 사이의 분기 결정을 내리는 데 필요한 최소 키 접두사를 저장합니다. 이 기법을 통해 데이터베이스는 각 브랜치 블록에 가능한 많은 데이터를 맞출 수 있습니다. 브랜치 블록에는 자식 블록을 가리키는 포인터가 포함됩니다. 키와 포인터의 수는 블록 크기에 의해 제한됩니다.
리프 블록에는 모든 인덱스된 데이터 값과 실제 행을 찾는 데 사용되는 해당 rowid가 포함됩니다. 각 항목은 (키, rowid)로 정렬됩니다. 리프 블록 내에서 키와 rowid는 왼쪽 및 오른쪽 형제 항목과 연결됩니다. 리프 블록 자체도 이중으로 연결됩니다. 그림 3-1에서 가장 왼쪽의 리프 블록(0-10)은 두 번째 리프 블록(11-19)과 연결되어 있습니다.
참고: 문자 데이터를 포함하는 컬럼의 인덱스는 데이터베이스 문자 세트의 문자 이진 값에 기반합니다.
Index Scans
인덱스 스캔에서 데이터베이스는 명령문에 지정된 인덱스된 컬럼 값을 사용하여 인덱스를 통해 행을 검색합니다. 데이터베이스가 값을 찾기 위해 인덱스를 스캔하는 경우, 이는 B-트리 인덱스의 높이 n만큼 I/O를 수행합니다. 이것이 Oracle Database 인덱스의 기본 원리입니다.
SQL 명령문이 인덱스된 컬럼만 접근하는 경우, 데이터베이스는 테이블이 아니라 인덱스에서 값을 읽습니다. 명령문이 인덱스되지 않은 컬럼을 인덱스된 컬럼 외에 접근하는 경우, 데이터베이스는 rowid를 사용하여 테이블의 행을 찾습니다. 일반적으로 데이터베이스는 인덱스 블록을 읽은 다음 테이블 블록을 번갈아 가며 데이터를 검색합니다.
참고 자료:
- Oracle Database SQL Tuning Guide: 인덱스 스캔에 대한 자세한 정보를 위해
Full Index Scan
전체 인덱스 스캔에서는 데이터베이스가 인덱스 전체를 순서대로 읽습니다. 전체 인덱스 스캔은 SQL 명령문의 WHERE 절이 인덱스의 컬럼을 참조하거나, 일부 경우에 조건이 지정되지 않은 경우 사용할 수 있습니다. 전체 스캔은 데이터를 인덱스 키로 정렬하기 때문에 정렬을 제거할 수 있습니다.
예제 3-1 전체 인덱스 스캔
다음 쿼리가 실행된다고 가정합니다:
SELECT department_id, last_name, salary
FROM employees
WHERE salary > 5000
ORDER BY department_id, last_name;이 예제에서 department_id, last_name 및 salary는 인덱스에서 복합 키입니다. Oracle Database는 인덱스의 전체 스캔을 수행하여 정렬된 순서로 읽고(부서 ID 및 성으로 정렬됨), salary 속성에서 필터링합니다. 이렇게 하면 데이터베이스는 employees 테이블보다 더 작은 데이터 집합을 스캔하며, 정렬 과정을 피할 수 있습니다.
전체 스캔은 다음과 같이 인덱스 항목을 읽을 수 있습니다:
50,Atkinson,2800,rowid
60,Austin,4800,rowid
70,Baer,10000,rowid
80,Abel,11000,rowid
80,Ande,6400,rowid
110,Austin,7200,rowid
.
.
.Fast Full Index Scan
빠른 전체 인덱스 스캔은 데이터베이스가 인덱스 블록을 임의 순서로 읽으면서 인덱스 자체의 데이터를 테이블에 접근하지 않고 읽는 전체 인덱스 스캔입니다.
빠른 전체 인덱스 스캔은 다음 두 가지 조건이 충족될 때 전체 테이블 스캔의 대안이 될 수 있습니다:
- 인덱스에는 쿼리에 필요한 모든 컬럼이 포함되어야 합니다.
- 모든 null이 포함된 행이 쿼리 결과 집합에 나타나지 않아야 합니다. 이를 보장하려면 인덱스의 적어도 하나의 컬럼에 다음 중 하나가 있어야 합니다:
NOT NULL제약 조건- 쿼리 결과 집합에서 null이 고려되지 않도록 하는 컬럼에 적용된 조건
예제 3-2 빠른 전체 인덱스 스캔
다음과 같은 ORDER BY 절이 포함되지 않은 쿼리가 실행된다고 가정합니다:
SELECT last_name, salary
FROM employees;last_name 컬럼에는 not null 제약 조건이 있습니다. last_name과 salary가 인덱스에서 복합 키인 경우, 빠른 전체 인덱스 스캔을 사용하여 인덱스 항목을 읽어 요청된 정보를 얻을 수 있습니다:
Baida,2900,rowid
Atkinson,2800,rowid
Zlotkey,10500,rowid
Austin,7200,rowid
Baer,10000,rowid
Austin,4800,rowid
.
.
.Index Range Scan
인덱스 범위 스캔은 인덱스의 하나 이상의 선도 컬럼이 조건에 지정되고, 인덱스 키에 대해 0, 1 또는 그 이상의 값이 가능한 경우의 인덱스 순서 스캔입니다.
조건은 하나 이상의 표현식과 논리(부울) 연산자의 조합을 지정합니다. 이는 TRUE, FALSE 또는 UNKNOWN 값을 반환합니다.
데이터베이스는 일반적으로 선택적 데이터 접근을 위해 인덱스 범위 스캔을 사용합니다. 선택성은 쿼리가 선택하는 테이블 행의 비율로, 0은 행이 없음을 의미하고 1은 모든 행을 의미합니다. 선택성은 WHERE last_name LIKE 'A%'와 같은 쿼리 조건에 묶여 있으며, 조건 조합일 수 있습니다. 값이 0에 가까울수록 조건은 더 선택적이 되며, 값이 1에 가까울수록 덜 선택적(또는 더 선택적이지 않음)입니다.
예를 들어, 사용
자가 성이 A로 시작하는 직원을 쿼리한다고 가정합니다. last_name 컬럼이 인덱싱된 경우 다음과 같이 항목이 있을 수 있습니다:
Abel,rowid
Ande,rowid
Atkinson,rowid
Austin,rowid
Austin,rowid
Baer,rowid
.
.
.데이터베이스는 범위 스캔을 사용할 수 있습니다. 왜냐하면 last_name 컬럼이 조건에서 지정되었으며, 각 인덱스 키에 대해 여러 rowid가 가능하기 때문입니다. 예를 들어, 두 명의 직원이 Austin이라는 이름을 가지고 있으므로 Austin 키에 대해 두 개의 rowid가 연관됩니다.
인덱스 범위 스캔은 양쪽 모두 제한되거나, 한쪽만 제한될 수 있습니다. 예를 들어, ID가 10에서 40 사이인 부서를 쿼리하거나, ID가 40을 초과하는 부서를 쿼리할 수 있습니다. 인덱스를 스캔하기 위해 데이터베이스는 리프 블록을 통해 앞뒤로 이동합니다. 예를 들어, ID가 10에서 40 사이인 값을 찾기 위해 인덱스는 10 이상인 가장 낮은 키 값을 포함하는 첫 번째 리프 블록을 찾습니다. 스캔은 40보다 큰 값을 찾을 때까지 리프 노드의 연결된 목록을 수평으로 계속 진행합니다.
Index Unique Scan
인덱스 범위 스캔과 달리 인덱스 고유 스캔은 인덱스 키에 대해 0 또는 1개의 rowid만 있어야 합니다.
데이터베이스는 UNIQUE 인덱스의 키 컬럼을 모두 등호 연산자로 참조하는 조건이 있을 때 고유 스캔을 수행합니다. 인덱스 고유 스캔은 두 번째 레코드를 찾을 수 없으므로 첫 번째 레코드를 찾으면 처리를 중지합니다.
예를 들어, 사용자가 다음 쿼리를 실행한다고 가정합니다:
SELECT *
FROM employees
WHERE employee_id = 5;employee_id 컬럼이 기본 키이고 다음과 같이 인덱싱되어 있다고 가정합니다:
1,rowid
2,rowid
4,rowid
5,rowid
6,rowid
.
.
.이 경우, 데이터베이스는 인덱스 고유 스캔을 사용하여 ID가 5인 직원의 rowid를 찾을 수 있습니다.
Index Skip Scan
인덱스 스킵 스캔은 복합 인덱스의 논리적 서브 인덱스를 사용합니다. 데이터베이스는 단일 인덱스를 여러 개의 별도 인덱스로 검색하는 것처럼 "건너뜁니다".
스킵 스캔은 복합 인덱스의 선도 컬럼에 몇 개의 고유 값이 있고 인덱스의 비선도 키에 많은 고유 값이 있는 경우에 유리합니다. 데이터베이스는 복합 인덱스의 선도 컬럼이 쿼리 조건에서 지정되지 않은 경우 인덱스 스킵 스캔을 선택할 수 있습니다.
예제 3-3 복합 인덱스의 스킵 스캔
sh.customers 테이블의 고객을 쿼리한다고 가정합니다:
SELECT * FROM sh.customers WHERE cust_email = 'Abbey@company.example.com';customers 테이블에는 cust_gender 컬럼이 있으며, 값은 M 또는 F 중 하나입니다. cust_gender, cust_email 컬럼에 복합 인덱스가 있다고 가정합니다. 다음 예제는 인덱스 항목의 일부를 보여줍니다:
F,Wolf@company.example.com,rowid
F,Wolsey@company.example.com,rowid
F,Wood@company.example.com,rowid
F,Woodman@company.example.com,rowid
F,Yang@company.example.com,rowid
F,Zimmerman@company.example.com,rowid
M,Abbassi@company.example.com,rowid
M,Abbey@company.example.com,rowid데이터베이스는 cust_gender가 WHERE 절에 지정되지 않았지만 이 인덱스의 스킵 스캔을 사용할 수 있습니다.
스킵 스캔에서 논리적 서브 인덱스의 수는 선도 컬럼의 고유 값 수에 따라 결정됩니다. 앞의 예에서 선도 컬럼에는 두 가지 가능한 값이 있습니다. 데이터베이스는 F 키와 M 키를 가진 두 개의 서브 인덱스로 논리적으로 인덱스를 나눕니다.
Abbey@company.example.com이라는 이메일을 가진 고객의 레코드를 검색할 때 데이터베이스는 먼저 F 값을 가진 서브 인덱스를 검색한 다음 M 값을 가진 서브 인덱스를 검색합니다. 개념적으로 데이터베이스는 다음과 같이 쿼리를 처리합니다:
SELECT * FROM sh.customers WHERE cust_gender = 'F'
AND cust_email = 'Abbey@company.example.com'
UNION ALL
SELECT * FROM sh.customers WHERE cust_gender = 'M'
AND cust_email = 'Abbey@company.example.com';Index Clustering Factor
인덱스 클러스터링 팩터는 직원 성과 같은 인덱스된 값과 관련된 행 순서를 측정합니다. 순서의 정도가 증가함에 따라 클러스터링 팩터는 감소합니다.
클러스터링 팩터는 인덱스를 사용하여 전체 테이블을 읽는 데 필요한 I/O 수를 대략적으로 측정하는 데 유용합니다:
- 클러스터링 팩터가 높으면, Oracle Database는 큰 인덱스 범위 스캔 동안 상대적으로 많은 I/O를 수행합니다. 인덱스 항목이 무작위 테이블 블록을 가리키므로 데이터베이스는 데이터를 검색하기 위해 동일한 블록을 여러 번 읽어야 할 수 있습니다.
- 클러스터링 팩터가 낮으면, Oracle Database는 큰 인덱스 범위 스캔 동안 상대적으로 적은 I/O를 수행합니다. 범위 내 인덱스 키가 동일한 데이터 블록을 가리키는 경향이 있으므로 데이터베이스는 데이터를 검색하기 위해 동일한 블록을 여러 번 읽을 필요가 없습니다.
클러스터링 팩터는 다음과 같은 경우 인덱스 스캔에 유용합니다:
- 데이터베이스가 큰 범위 스캔에 대해 인덱스를 사용할지 여부
- 인덱스 키와 관련된 테이블 정렬 정도
- 행이 인덱스 키에 따라 정렬된 경우 인덱스 조직 테이블, 파티셔닝 또는 테이블 클러스터 사용을 고려할지 여부
예제 3-4 클러스터링 팩터
employees 테이블이 두 개의 데이터 블록에 맞는다고 가정합니다. 표 3-3은 두 데이터 블록의 행을 나타냅니다(생략된 데이터는 표시되지 않음).
표 3-3 employees 테이블의 두 데이터 블록의 내용
| 데이터 블록 1 | 데이터 블록 2 |
|---|---|
100 Steven King SKING ... | |
156 Janette King JKING ... | |
115 Alexander Khoo AKHOO ... | |
. | |
. | 149 Eleni Zlotkey EZLOTKEY ... |
. | 200 Jennifer Whalen JWHALEN ... |
116 Shelli Baida SBAIDA ... | . |
204 Hermann Baer HBAER ... | . |
105 David Austin DAUSTIN ... | . |
130 Mozhe Atkinson MATKINSO ... | 137 Renske Ladwig RLADWIG ... |
166 Sundar Ande SANDE ... | 173 Sundita Kumar SKUMAR ... |
174 Ellen Abel EABEL ... | 101 Neena Kochar NKOCHHAR ... |
행은 성(굵게 표시된) 순서로 블록에 저장됩니다. 예를 들어, 데이터 블록 1의 맨 아래 행은 Abel을 설명하고, 그 다음 행은 Ande를 설명하며, 계속해서 Steven King까지 알파벳 순서로 진행됩니다. 블록 2의 맨 아래 행은 Kochar를 설명하고, 그 다음 행은 Kumar를 설명하며, 계속해서 Zlotkey까지 알파벳 순서로 진행됩니다.
last_name 컬럼에 인덱스가 있다고 가정합니다. 각 이름 항목은 rowid와 일치합니다. 개념적으로 인덱스 항목은 다음과 같습니다:
Abel,block1row1
Ande,block1row2
Atkinson,block1row3
Austin,block1row4
Baer,block1row5
.
.
.employee ID 컬럼에 별도의 인덱스가 있다고 가정합니다. 개념적으로 인덱스 항목은 다음과 같습니다. employee ID가 두 블록 전체에 거의 무작위로 분포되어 있습니다:
100,block1row50
101,block2row1
102,block1row9
103,block2row19
104,block2row39
105,block1row4
.
.
.다음 명령문은 ALL_INDEXES 뷰에서 이 두 인덱스의 클러스터링 팩터를 쿼리합니다:
SQL> SELECT INDEX_NAME, CLUSTERING_FACTOR
2 FROM ALL_INDEXES
3 WHERE INDEX_NAME IN ('EMP_NAME_IX','EMP_EMP_ID_PK');
INDEX_NAME CLUSTERING_FACTOR
-------------------- -----------------
EMP_EMP_ID_PK 19
EMP_NAME_IX 2EMP_NAME_IX의 클러스터링 팩터는 낮습니다. 이는 단일 리프 블록의 인접 인덱스 항목이 동일한 데이터 블록의 행을 가리키는 경향이 있다는 것을 의미합니다. EMP_EMP_ID_PK의 클러스터링 팩터는 높습니다. 이는 동일한 리프 블록의 인접 인덱스 항목이 동일한 데이터 블록의 행을 가리킬 가능성이 훨씬 적다는 것을 의미합니다.
Reverse Key Indexes
역순 키 인덱스는 각 인덱스 키의 바이트를 물리적으로 역순으로 저장하면서 컬럼 순서를 유지하는 B-트리 인덱스 유형입니다.
예를 들어, 인덱스 키가 20이고, 이 키에 저장된 두 바이트가 C1,15인 경우 표준 B-트리 인덱스에서는 역순 키 인덱스는 바이트를 15,C1로 저장합니다.
키를 역순으로 변환하면 B-트리 인덱스의 오른쪽에 있는 리프 블록에 대한 경합 문제가 해결됩니다. 이 문제는 여러 인스턴스가 동일한 블록을 반복해서 수정하는 Oracle Real Application Clusters(Oracle RAC) 데이터베이스에서 특히 심각할 수 있습니다. 예를 들어, orders 테이블에서 주문의 기본 키가 순차적인 경우 하나의 인스턴스는 주문 20을 추가하고, 다른 인스턴스는 21을 추가하며, 각 인스턴스는 인덱스의 오른쪽 리프 블록에 키를 기록합니다.
역순 키 인덱스에서는 바이트 순서를 반전시켜 인덱스의 모든 리프 키에 삽입을 분산시킵니다. 예를 들어, 표준 키 인덱스에서는 인접한 20 및 21과 같은 키가 이제 별도의 블록에 멀리 떨어져 저장됩니다. 따라서 순차 키의 삽입에 대한 I/O가 더 균등하게 분산됩니다.
데이터가 컬럼 키로 정렬되지 않기 때문에 역순 키 배열은 일부 경우에 인덱스 범위 스캔 쿼리를 실행할 수 있는 능력을 제거합니다. 예를 들어, 사용자가 20보다 큰 주문 ID를 쿼리하면 데이터베이스는 이 ID를 포함하는 블록에서 시작하여 리프 블록을 수평으로 진행할 수 없습니다.
Ascending and Descending Indexes
오름차순 인덱스에서는 Oracle Database가 데이터를 오름차순으로 저장합니다. 기본적으로 문자 데이터는 값의 각 바이트에 포함된 이진 값에 따라 정렬되고, 숫자 데이터는 가장 작은 숫자에서 가장 큰 숫자로, 날짜는 가장 이른 값에서 가장 늦은 값으로 정렬됩니다.
다음 SQL 명령문을 예로 들어 오름차순 인덱스를 살펴보겠습니다:
CREATE INDEX emp_deptid_ix ON hr.employees(department_id); Oracle Database는 hr.employees 테이블을 department_id 컬럼으로 정렬합니다. 데이터베이스는 오름차순 인덱스를 department_id 및 해당 rowid 값으로 오름차순으로 로드하여 0부터 시작합니다. 데이터베이스는 인덱스를 사용할 때 정렬된 department_id 값을 검색하고 관련 rowid를 사용하여 요청된 department_id 값을 가지는 행을 찾습니다.
CREATE INDEX 명령문에서 DESC 키워드를 지정하여 내림차순 인덱스를 생성할 수 있습니다. 이 경우 인덱스는 특정 컬럼 또는 컬럼의 데이터를 내림차순으로 저장합니다. 표 3-3의 employees.department_id 컬럼에 대한 인덱스가 내림차순인 경우 250을 포함하는 리프 블록은 트리의 왼쪽에, 0을 포함하는 블록은 오른쪽에 위치하게 됩니다. 내림차순 인덱스를 검색하는 기본 방법은 가장 높은 값에서 가장 낮은 값으로 검색하는 것입니다.
내림차순 인덱스는 일부 컬럼을 오름차순으로, 다른 컬럼을 내림차순으로 정렬하는 쿼리에 유용합니다. 예를 들어, 다음과 같이 last_name 및 department_id 컬럼에 복합 인덱스를 생성한다고 가정합니다:
CREATE INDEX emp_name_dpt_ix ON hr.employees(last_name ASC, department_id DESC); 사용자가 last_name을 오름차순(A부터 Z)으로, department ID를 내림차순(높은 값부터 낮은 값)으로 정렬하여 hr.employees를 쿼리하면 데이터베이스는 이 인덱스를 사용하여 데이터를 검색하고 정렬 단계를 피할 수 있습니다.
Index Compression
Oracle Database는 인덱스의 공간을 줄이기 위해 다양한 압축 알고리즘을 사용할 수 있습니다.
Prefix Compression
Oracle Database는 B-트리 인덱스 또는 인덱스 조직 테이블의 기본 키 컬럼 값의 일부를 압축하기 위해 접두사 압축(키 압축이라고도 함)을 사용할 수 있습니다. 접두사 압축은 인덱스가 소비하는 공간을 크게 줄일 수 있습니다.
비압축 인덱스 항목은 하나의 조각으로 구성됩니다. 접두사 압축을 사용하는 인덱스 항목은 접두사 항목(그룹 조각)과 접미사 항목(고유 또는 거의 고유한 조각) 두 개의 조각으로 구성됩니다. 데이터베이스는 인덱스 블록에서 접두사 항목을 접미사 항목 간에 공유함으로써 압축을 달성합니다.
참고: 키가 고유한 조각을 정의하지 않은 경우, 데이터베이스는 그룹 조각에 rowid를 추가하여 이를 제공합니다.
기본적으로 고유 인덱스의 접두사는 마지막을 제외한 모든 키 컬럼으로 구성되며, 비고유 인덱스의 접두사는 모든 키 컬럼으로 구성됩니다. 다음과 같이 oe.orders 테이블의 두 컬럼에 대해 고유 복합 인덱스를 생성한다고 가정합니다:
CREATE UNIQUE INDEX orders_mod_stat_ix ON orders ( order_mode, order_status );위의 예에서 인덱스 키는 online,0일 수 있습니다. rowid는 항목의 키 데이터 부분에 저장되며, 키 자체의 일부가 아닙니다.
참고: 단일 컬럼에 대해 고유 인덱스를 생성하는 경우, Oracle Database는 공통 접두사가 없으므로 접두사 키 압축을 사용할 수 없습니다.
또는 동일한 컬럼에 대해 비고유 인덱스를 생성한다고 가정합니다:
CREATE INDEX orders_mod_stat_ix ON orders ( order_mode, order_status );또한 order_mode 및 order_status 컬럼에 반복 값이 발생한다고 가정합니다. 인덱스 블록은 다음과 같은 항목을 가질 수 있습니다:
online,0,AAAPvCAAFAAAAFaAAa
online,0,AAAPvCAAFAAAAFaAAg
online,0,AAAPvCAAFAAAAFaAAl
online,2,AAAPvCAAFAAAAFaAAm
online,3,AAAPvCAAFAAAAFaAAq
online,3,AAAPvCAAFAAAAFaAAt이 예에서 키 접두사는 order_mode와 order_status 값의 연결로, 예를 들어 online,0일 수 있습니다. 접미사는 rowid로, 예를 들어 AAAPvCAAFAAAAFaAAa와 같습니다. rowid는 고유한 데이터베이스에서 고유하므로 전체 인덱스 항목을 고유하게 만듭니다.
이 예에서 기본 접두사 압축(COMPRESS 키워드를 지정)으로 인덱스가 생성된 경우, online,0 및 online,3과 같은 중복 키 접두사는 압축됩니다. 개념적으로 데이터베이스는 다음과 같이 압축을 달성합니다:
online,0
AAAPvCAAFAAAAFaAAa
AAAPvCAAFAAAAFaAAg
AAAPvCAAFAAAAFaAAl
online,2
AAAPvCAAFAAAAFaAAm
online,3
AAAPvCAAFAAAAFaAAq
AAAPvCAAFAAAAFaAAt접미사 항목(rowid)은 인덱스 행의 압축된 버전을 형성합니다. 각 접미사 항목은 동일한 인덱스 블록에 저장된 접두사 항목을 참조합니다.
또는 접두사 압축을 사용하는 인덱스를 생성할 때 접두사 길이를 지정할 수 있습니다. 예를 들어, COMPRESS 1을 지정한 경우, 접두사는 order_mode이고 접미사는 order_status,rowid가 됩니다. 인덱스 블록 예제의 값에 대해 인덱스는 접두사 online의 중복 발생을 제거합니다. 개념적으로 다음과 같이 표현될 수 있습니다:
online
0,AAAPvCAAFAAAAFaAAa
0,AAAPvCAAFAAAAFaAAg
0,AAAPvCAAFAAAAFaAAl
2,AAAPvCAAFAAAAFaAAm
3,AAAPvCAAFAAAAFaAAq
3,AAAPvCAAFAAAAFaAAt인덱스는 특정 접두사를 리프 블록당 한 번씩만 저장합니다. B-트리 인덱스의 리프 블록에서만 키가 압축됩니다. 브랜치 블록에서는 키 접미사가 잘릴 수 있지만 키는 압축되지 않습니다.
Advanced Index Compression
Oracle Database 12c Release 1(12.1.0.2)부터 고급 인덱스 압축은 기존 접두사 압축을 향상시켜 힙 조직 테이블의 지원되는 인덱스에 적용됩니다.
Benefits of Advanced Index Compression
접두사 압축은 지원되는 인덱스 유형, 압축 비율 및 사용 편의성에 제한이 있습니다. 접두사 압축은 각 블록에 대해 고정된 중복 키 제거를 사용하지만, 고급 인덱스 압축은 각 블록마다 적응형 중복 키 제거를 사용합니다. 고급 인덱스 압축의 주요 이점은 다음과 같습니다:
- 데이터베이스는 내부 알고리즘(예: 열 내 접두사, 중복 키 제거, rowid 압축 등)을 사용하여 각 블록에 대한 최상의 압축을 자동으로 선택합니다. 접두사 압축과 달리 고급 인덱스 압축은 사용자가 데이터 특성을 알 필요가 없습니다.
- 고급 압축은 비고유 및 고유 인덱스 모두에서 작동합니다. 접두사 압축은 일부 비고유 인덱스에서 잘 작동하지만, 선도 컬럼에 많은 반복이 없는 인덱스에서는 비율이 낮습니다.
- 압축된 인덱스는 비압축 인덱스와 동일한 방식으로 사용할 수 있습니다. 인덱스는 동일한 접근 경로(고유 키 조회, 범위 스캔, 빠른 전체 스캔)를 지원합니다.
- 인덱스는 부모 테이블 또는 포함된 테이블스페이스에서 고급 압축을 상속할 수 있습니다.
How Advanced Index Compression Works
고급 인덱스 압축은 각 블록에 대해 최상의 압축을 제공하기 위해 블록 수준에서 작동합니다. 데이터베이스는 다음 기법을 사용합니다:
- 인덱스 생성 중 리프 블록이 가득 차면 데이터베이스는 블록을 최적 수준으로 자동으로 압축합니다.
- DML 작업으로 인해 인덱스 블록을 재구성할 때, 데이터베이스가 들어오는 인덱스 항목에 충분한 공간을 만들 수 있으면 블록 분할이 발생하지 않습니다. 고급 인덱스 압축 없이 DML을 수행할 때는 블록이 가득 차면 항상 인덱스 블록 분할이 발생합니다.
Advanced Index Compression HIGH
Oracle Database 12c Release 2(12.2) 이전 릴리스에서는 저압축(COMPRESS ADVANCED LOW)만 고급 인덱스 압축의 형태로 제공되었습니다. 이제 고압축(COMPRESS ADVANCED HIGH)을 지정할 수 있으며, 이는 기본값입니다. HIGH 옵션의 고급 인덱스 압축은 다음과 같은 이점을 제공합니다:
- 대부분의 경우 더 높은 압축 비율을 제공하며, 인덱스를 접근하는 쿼리의 성능을 향상시킵니다.
- 고급 저압축보다 더 복잡한 압축 알고리즘을 사용합니다.
- 데이터를 압축 단위(특수 온디스크 형식)에 저장합니다.
참고:
HIGH압축을 적용하면 모든 블록에 압축이 적용됩니다.LOW압축을 적용하면 데이터베이스가 일부 블록을 압축하지 않을 수 있습니다. 통계를 사용하여 압축되지 않은 블록의 수를 확인할 수 있습니다.
예제 3-5 고급 고압축을 사용하여 인덱스 생성
이 예제에서는 hr.employees 테이블에 대한 인덱스에 고급 인덱스 압축을 활성화합니다:
CREATE INDEX hr.emp_mndp_ix
ON hr.employees(manager_id, department_id)
COMPRESS ADVANCED;다음 쿼리는 압축 유형을 보여줍니다:
SELECT COMPRESSION FROM DBA_INDEXES WHERE INDEX_NAME ='EMP_MNDP_IX';
COMPRESSION
-------------
ADVANCED HIGHOverview of Bitmap Indexes
비트맵 인덱스에서는 데이터베이스가 각 인덱스 키에 대해 비트맵을 저장합니다. 전통적인 B-트리 인덱스에서는 하나의 인덱스 항목이 단일 행을 가리킵니다. 비트맵 인덱스에서는 각 인덱스 키가 여러 행을 가리키기 위해 비트맵을 사용합니다.
비트맵 인덱스는 주로 데이터 웨어하우징 또는 쿼리가 많은 컬럼을 임의 방식으로 참조하는 환경에 적합합니다. 비트맵 인덱스가 필요한 상황은 다음과 같습니다:
- 인덱스된 컬럼의 카디널리티가 낮으며, 이는 고유 값의 수가 테이블 행 수에 비해 작다는 의미입니다.
- 인덱스된 테이블이 읽기 전용이거나 DML 명령문으로 인해 크게 수정되지 않습니다.
데이터 웨어하우스 예제에서 sh.customers 테이블에는 cust_gender 컬럼이 있으며, 가능한 값은 M과 F입니다. 특정 성별의 고객 수에 대한 쿼리가 일반적인 경우, customers.cust_gender 컬럼은 비트맵 인덱스의 후보가 될 수 있습니다.
비트맵의 각 비트는 가능한 rowid에 해당합니다. 비트가 설정된 경우 해당 rowid를 가진 행이 키 값을 포함합니다. 매핑 함수는 비트 위치를 실제 rowid로 변환하여 비트맵 인덱스는 B-트리 인덱스와 동일한 기능을 제공하지만 다른 내부 표현을 사용합니다.
단일 행의 인덱스된 컬럼이 업데이트되면, 데이터베이스는 개별 비트가 아닌 인덱스 키 항목(예: M 또는 F)을 잠급니다. 키가 여러 행을 가리키기 때문에 인덱스된 데이터에서 DML을 수행하면 일반적으로 이 모든 행을 잠급니다. 이로 인해 비트맵 인덱스는 많은 OLTP 애플리케이션에 적합하지 않습니다.
Example: Bitmap Indexes on a Single Table
이 예제에서는 sh.customers 테이블의 일부 컬럼이 비트맵 인덱스의 후보가 될 수 있습니다.
다음 쿼리를 고려해보세요:
SQL> SELECT cust_id, cust_last_name, cust_marital_status, cust_gender
2 FROM sh.customers
3 WHERE ROWNUM < 8 ORDER BY cust_id;
CUST_ID CUST_LAST_ CUST_MAR C
---------- ---------- -------- -
1 Kessel M
2 Koch F
3 Emmerson M
4 Hardy M
5 Gowen M
6 Charles single F
7 Ingram single F
7 rows selected.cust_marital_status 및 cust_gender 컬럼은 카디널리티가 낮지만, cust_id 및 cust_last_name은 그렇지 않습니다. 따라서 cust_marital_status 및 cust_gender에 대해 비트맵 인덱스가 적절할 수 있습니다. 다른 컬럼에 대해서는 비트맵 인덱스가 유용하지 않을 가능성이 큽니다. 대신 이러한 컬럼에 대해 고유 B-트리 인덱스가 가장 효율적인 표현 및 검색을 제공할 것입니다.
표 3-4는 cust_gender 컬럼에 대한 비트맵 인덱스를 보여줍니다. 이는 각 성별에 대해 별도의 비트맵으로 구성됩니다.
표 3-4 단일 컬럼에 대한 샘플 비트맵
| 값 | 행 1 | 행 2 | 행 3 | 행 4 | 행 5 | 행 6 | 행 7 |
|---|---|---|---|---|---|---|---|
| M | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| F | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
매핑 함수는 비트맵의 각 비트를 customers 테이블의 rowid로 변환합니다. 각 비트 값은 테이블의 해당 행의 값에 따라 다릅니다. 예를 들어, M 값에 대한 비트맵은 customers 테이블의 첫 번째 행에서 성별이 M이기 때문에 첫 번째 비트로 1을 포함합니다. cust_gender='M' 비트맵은 2, 6 및 7 행에서 값이 M이 아니므로 비트가 0입니다.
참고: 비트맵 인덱스는 B-트리 인덱스와 달리 null 값으로 구성된 키를 포함할 수 있습니다. null을 인덱싱하는 것은
COUNT와 같은 집계 함수가 있는 일부 SQL 명령문에 유용할 수 있습니다.
고객의 인구 통계를 조사하는 분석가는 "몇 명의 여성 고객이 싱글 또는 이혼한 상태입니까?"와 같은 질문을 할 수 있습니다. 이 질문은 다음 SQL 쿼리에 해당합니다:
SELECT COUNT(*)
FROM customers
WHERE cust_gender = 'F'
AND cust_marital_status IN ('single', 'divorced'); 비트맵 인덱스는 결과 비트맵에서 1 값을 세어 이 쿼리를 효율적으로 처리할 수 있습니다. 표 3-5에 표시된 것처럼 조건을 충족하는 고객을 식별하기 위해 데이터베이스는 결과 비트맵을 사용하여 테이블에 접근할 수 있습니다.
표 3-5 두 컬럼에 대한 샘플 비트맵
| 값 | 행 1 | 행 2 | 행 3 | 행 4 | 행 5 | 행 6 | 행 7 |
|---|---|---|---|---|---|---|---|
M | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
F | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
single | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
divorced | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
single 또는 divorced, 그리고 F | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
비트맵 인덱싱은 WHERE 절에 여러 조건이 있는 인덱스를 효율적으로 병합합니다. 일부 조건만 충족하는 행은 테이블 자체에 접근하기 전에 필터링됩니다. 이 기술은 응답 시간을 크게 향상시킵니다.
Bitmap Join Indexes
비트맵 조인 인덱스는 두 개 이상의 테이블 조인을 위한 비트맵 인덱스입니다.
테이블 컬럼의 각 값에 대해 인덱스는 인덱스된 테이블의 해당 행의 rowid를 저장합니다. 반면, 표준 비트맵 인덱스는 단일 테이블에 생성됩니다.
비트맵 조인 인덱스는 제한을 사전에 수행하여 조인해야 할 데이터 양을 줄이는 효율적인 수단입니다. 예를 들어, 사용자가 특정 직무 유형을 가진 직원 수를 자주 쿼리하는 경우 비트맵 조인 인덱스가 유용할 수 있습니다. 일반적인 쿼리는 다음과 같습니다:
SELECT COUNT(*)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
AND jobs.job_title = 'Accountant';위의 쿼리는 일반적으로 jobs.job_title 인덱스를 사용하여 Accountant 행을 검색한 다음 job ID를 찾고, employees.job_id 인덱스를 사용하여 일치하는 행을 찾습니다. 인덱스 자체에서 데이터를 검색하여 테이블 스캔을 피하려면 다음과 같이 비트맵 조인 인덱스를 생성할 수 있습니다:
CREATE BITMAP INDEX employees_bm_idx
ON employees (jobs.job_title)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id;다음 그림에서와 같이 인덱스 키는 jobs.job_title이고 인덱스된 테이블은 employees입니다.
그림 3-2 비트맵 조인 인덱스
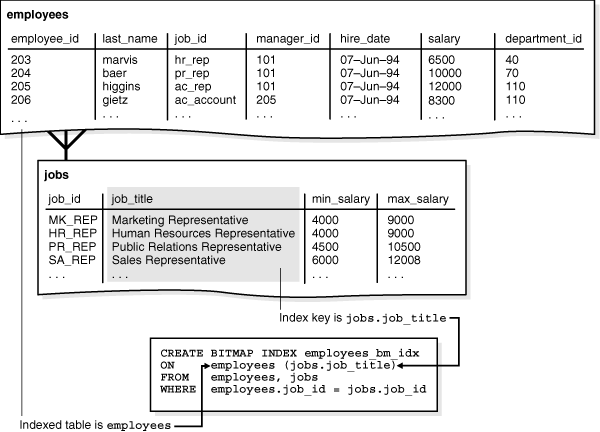
개념적으로 employees_bm_idx는 SQL 쿼리에서 jobs.title 컬럼의 인덱스입니다. 다음 쿼리(샘플 출력 포함)는 인덱스 키 jobs.job_title이 employees 테이블의 행을 가리키는 예입니다. 회계사 수를 쿼리하면 인덱스가 인덱스된 정보를 포함하므로 employees 및 jobs 테이블에 접근할 필요가 없습니다.
SELECT jobs.job_title AS "jobs.job_title", employees.rowid AS "employees.rowid"
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
ORDER BY job_title;
jobs.job_title employees.rowid
----------------------------------- ------------------
Accountant AAAQNKAAFAAAABSAAL
Accountant AAAQNKAAFAAAABSAAN
Accountant AAAQNKAAFAAAABSAAM
Accountant AAAQNKAAFAAAABSAAJ
Accountant AAAQNKAAFAAAABSAAK
Accounting Manager AAAQNKAAFAAAABTAAH
Administration Assistant AAAQNKAAFAAAABTAAC
Administration Vice President AAAQNKAAFAAAABSAAC
Administration Vice President AAAQNKAAFAAAABSAAB
.
.
.데이터 웨어하우스에서 조인 조건은 차원 테이블의 기본 키 컬럼과 사실 테이블의 외래 키 컬럼 간의 동등 조인(동등 연산자를 사용)입니다. 비트맵 조인 인덱스는 사전에 조인을 물리화하는 대안인 물리화된 조인 뷰보다 스토리지 면에서 훨씬 효율적일 수 있습니다.
Bitmap Storage Structure
Oracle Database는 각 인덱스 키에 대한 비트맵을 저장하기 위해 B-트리 인덱스 구조를 사용합니다.
예를 들어, jobs.job_title이 비트맵 인덱스의 키 컬럼인 경우 하나의 B-트리가 인덱스 데이터를 저장합니다. 리프 블록은 개별 비트맵을 저장합니다.
예제 3-6 비트맵 저장소 예제
jobs.job_title 컬럼에 고유 값이 Shipping Clerk, Stock Clerk 및 몇 가지 다른 값이 있다고 가정합니다. 이 인덱스의 비트맵 인덱스 항목에는 다음 구성 요소가 있습니다:
- 인덱스 키로서의 직무 제목
- rowid 범위에 대한 낮은 rowid 및 높은 rowid
- 범위 내 특정 rowid에 대한 비트맵
개념적으로 이 인덱스의 리프 블록은 다음과 같은 항목을 포함할 수 있습니다:
Shipping Clerk,AAAPzRAAFAAAABSABQ,AAAPzRAAFAAAABSABZ,0010000100
Shipping Clerk,AAAPzRAAFAAAABSABa,AAAPzRAAFAAAABSABh,010010
Stock Clerk,AAAPzRAAFAAAABSAAa,AAAPzRAAFAAAABSAAc,1001001100
Stock Clerk,AAAPzRAAFAAAABSAAd,AAAPzRAAFAAAABSAAt,0101001001
Stock Clerk,AAAPzRAAFAAAABSAAu,AAAPzRAAFAAAABSABz,100001
.
.
.같은 직무 제목이 여러 항목에 나타납니다. 이는 rowid 범위가 다르기 때문입니다.
세션이 한 직원의 job ID를 Shipping Clerk에서 Stock Clerk으로 업데이트합니다. 이 경우 세션은 이전 값(Shipping Clerk)과 새 값(Stock Clerk)에 대한 인덱스 키 항목에 대한 독점 접근이 필요합니다. Oracle Database는 이 두 항목이 가리키는 행을 UPDATE가 커밋될 때까지 잠급니다. 이 과정에서 Accountant 또는 다른 키가 가리키는 행은 잠기지 않습니다.
비트맵 인덱스 데이터는 하나의 세그먼트에 저장됩니다. Oracle Database는 각 비트맵을 하나 이상의 조각으로 저장합니다. 각 조각은 단일 데이터 블록의 일부를 차지합니다.
Overview of Function-Based Indexes
함수 기반 인덱스는 함수나 하나 이상의 컬럼을 포함하는 표현식의 값을 계산하여 인덱스에 저장합니다. 함수 기반 인덱스는 B-트리 인덱스 또는 비트맵 인덱스일 수 있습니다.
인덱스된 함수는 산술 표현식이거나 SQL 함수, 사용자 정의 PL/SQL 함수, 패키지 함수 또는 C 호출을 포함하는 표현식일 수 있습니다. 예를 들어, 함수는 두 컬럼의 값을 더할 수 있습니다.
Uses of Function-Based Indexes
함수 기반 인덱스는 WHERE 절에 함수가 포함된 명령문을 평가하는 데 효율적입니다. 데이터베이스는 함수가 쿼리에 포함될 때만 함수 기반 인덱스를 사용합니다. 그러나 데이터베이스가 INSERT 및 UPDATE 명령문을 처리할 때는 명령문을 처리하기 위해 함수를 평가해야 합니다.
예제 3-7 산술 표현식을 기반으로 한 인덱스
다음과 같은 함수 기반 인덱스를 생성한다고 가정합니다:
CREATE INDEX emp_total_sal_idx
ON employees (12 * salary * commission_pct, salary, commission_pct);데이터베이스는 다음과 같은 쿼리를 처리할 때 위의 인덱스를 사용할 수 있습니다(샘플 출력 포함):
SELECT employee_id, last_name, first_name,
12*salary*commission_pct AS "ANNUAL SAL"
FROM employees
WHERE (12 * salary * commission_pct) < 30000
ORDER BY "ANNUAL SAL" DESC;
EMPLOYEE_ID LAST_NAME FIRST_NAME ANNUAL SAL
----------- ------------------------- -------------------- ----------
159 Smith Lindsey 28800
151 Bernstein David 28500
152 Hall Peter 27000
160 Doran Louise 27000
175 Hutton Alyssa 26400
149 Zlotkey Eleni 25200
169 Bloom Harrison 24000예제 3-8 UPPER 함수를 기반으로 한 인덱스
UPPER(column_name) 또는 LOWER(column_name) SQL 함수에 정의된 함수 기반 인덱스는 대소문자를 구분하지 않는 검색을 용이하게 합니다. 예를 들어, employees의 first_name 컬럼에 대소문자가 섞여 있는 문자가 포함된다고 가정합니다. hr.employees 테이블에서 다음과 같은 함수 기반 인덱스를 생성합니다:
CREATE INDEX emp_fname_uppercase_idx
ON employees ( UPPER(first_name) ); emp_fname_uppercase_idx 인덱스는 다음과 같은 쿼리를 용이하게 합니다:
SELECT *
FROM employees
WHERE UPPER(first_name) = 'AUDREY';예제 3-9 테이블의 특정 행 인덱싱
함수 기반 인덱스는 테이블의 특정 행만 인덱싱하는 데에도 유용합니다. 예를 들어, sh.customers 테이블의 cust_valid 컬럼 값이 I 또는 A인 경우, A 행만 인덱싱하려면 함수가 A 행 외의 행에 대해 null 값을 반환하도록 할 수 있습니다. 다음과 같이 인덱스를 생성할 수 있습니다:
CREATE INDEX cust_valid_idx
ON customers ( CASE cust_valid WHEN 'A' THEN 'A' END );Optimization with Function-Based Indexes
WHERE 절에 표현식이 포함된 쿼리에 대해 옵티마이저는 함수 기반 인덱스에 대한 범위 스캔을 사용할 수 있습니다.
범위 스캔 접근 경로는 특히 조건이 매우 선택적인 경우(즉, 상대적으로 적은 수의 행을 선택하는 경우) 유용합니다. 예제 3-7에서 인덱스가 12*salary*commission_pct 표현식에 대해 빌드된 경우, 옵티마이저는 인덱스 범위 스캔을 사용할 수 있습니다.
가상 컬럼도 표현식에서 파생된 데이터에 대한 접근 속도를 높이는 데 유용합니다. 예를 들어, 가상 컬럼 annual_sal을 12*salary*commission_pct로 정의하고 annual_sal에 함수 기반 인덱스를 생성할 수 있습니다.
옵티마이저는 SQL 명령문의 표현식을 파싱한 후 명령문과 함수 기반 인덱스의 표현식 트리를 비교하여 표현식을 매칭합니다. 이 비교는 대소문자를 구분하지 않으며, 공백을 무시합니다.
Overview of Application Domain Indexes
애플리케이션 도메인 인덱스는 특정 애플리케이션에 맞춘 인덱스입니다.
광범위한 인덱싱은 다음을 가능하게 합니다:
- 문서, 공간 데이터, 이미지, 비디오 클립 등과 같은 맞춤형 복합 데이터 유형에 대한 인덱스를 수용합니다(참고: "Unstructured Data").
- 전문 인덱싱 기술을 활용합니다.
애플리케이션 특정 인덱스 관리 루틴을 indextype 스키마 객체로 캡슐화한 후 테이블 컬럼이나 객체 유형의 속성에 도메인 인덱스를 정의할 수 있습니다. 확장 인덱싱은 애플리케이션 특정 연산자를 효율적으로 처리할 수 있습니다.
애플리케이션 소프트웨어, 즉 cartridge는 도메인 인덱스의 구조와 내용을 제어합니다. 데이터베이스는 도메인 인덱스를 빌드, 유지 및 검색하기 위해 애플리케이션과 상호 작용합니다. 인덱스 구조 자체는 인덱스 조직 테이블로 데이터베이스에 저장되거나 외부 파일로 저장될 수 있습니다.
Overview of Index-Organized Tables
인덱스 조직 테이블은 B-트리 인덱스 구조의 변형으로 저장된 테이블입니다. 힙 조직 테이블은 행을 적절한 위치에 삽입합니다.
인덱스 조직 테이블에서는 테이블의 행이 테이블의 기본 키에 대해 정의된 인덱스에 저장됩니다. B-트리의 각 인덱스 항목에는 비키 컬럼 값도 저장됩니다. 따라서 인덱스가 데이터이며 데이터가 인덱스입니다. 애플리케이션은 SQL 명령문을 사용하여 인덱스 조직 테이블을 힙 조직 테이블처럼 조작합니다.
인덱스 조직 테이블에 대한 비유로, HR 관리자가 여러 개의 종이 상자가 있는 책장을 가지고 있다고 가정해 보세요. 각 상자는 번호가 매겨져 있지만(1, 2, 3, 4 등) 상자는 순서대로 선반에 놓여 있지 않습니다. 대신 각 상자에는 다음 상자의 위치를 가리키는 포인터가 있습니다.
상자에 직원 기록이 포함된 폴더가 저장됩니다. 폴더는 직원 ID 순서로 정렬됩니다. 직원 King의 ID가 100이며, 이는 가장 낮은 ID이므로 그의 폴더는 상자 1
의 맨 아래에 있습니다. 직원 101의 폴더는 100 위에, 102는 101 위에 있고, 계속해서 상자 1이 가득 찰 때까지 이어집니다. 시퀀스의 다음 폴더는 상자 2의 맨 아래에 있습니다.
이 비유에서 폴더를 직원 ID로 정렬하면 별도의 인덱스를 유지하지 않고도 폴더를 효율적으로 검색할 수 있습니다. 사용자가 직원 107, 120 및 122의 기록을 요청하는 경우, 관리자는 인덱스를 검색하고 폴더를 별도로 검색하는 대신 순서대로 폴더를 검색하여 각 폴더를 찾을 수 있습니다.
인덱스 조직 테이블은 기본 키나 유효한 키 접두사에 대해 테이블 행에 더 빠르게 접근할 수 있도록 합니다. 행의 비키 컬럼이 리프 블록에 존재하면 추가적인 데이터 블록 I/O가 피할 수 있습니다. 예를 들어, 직원 100의 급여는 인덱스 행 자체에 저장됩니다. 또한 행이 기본 키 순서로 저장되므로 기본 키나 접두사에 의한 범위 접근은 최소한의 블록 I/O만 필요합니다. 또 다른 이점은 별도의 기본 키 인덱스의 공간 오버헤드를 피할 수 있다는 점입니다.
인덱스 조직 테이블은 관련 데이터 조각이 함께 저장되어야 하거나 데이터가 특정 순서로 물리적으로 저장되어야 할 때 유용합니다. 이 유형의 테이블은 정보 검색, 공간 데이터 및 OLAP 애플리케이션에 일반적으로 사용됩니다.
Index-Organized Table Characteristics
데이터베이스 시스템은 인덱스 조직 테이블에서 모든 작업을 B-트리 인덱스 구조를 조작하여 수행합니다.
다음 표는 인덱스 조직 테이블과 힙 조직 테이블의 차이점을 요약합니다.
표 3-6 힙 조직 테이블과 인덱스 조직 테이블의 비교
| 힙 조직 테이블 | 인덱스 조직 테이블 |
|---|---|
| rowid는 행을 고유하게 식별합니다. 기본 키 제약 조건은 선택적으로 정의될 수 있습니다. | 기본 키는 행을 고유하게 식별합니다. 기본 키 제약 조건이 정의되어야 합니다. |
ROWID 가상 컬럼의 물리적 rowid는 보조 인덱스를 빌드할 수 있습니다. | ROWID 가상 컬럼의 논리적 rowid는 보조 인덱스를 빌드할 수 있습니다. |
| 개별 행은 rowid로 직접 접근할 수 있습니다. | 개별 행은 기본 키로 간접적으로 접근할 수 있습니다. |
| 순차적 전체 테이블 스캔은 일부 순서로 모든 행을 반환합니다. | 전체 인덱스 스캔 또는 빠른 전체 인덱스 스캔은 일부 순서로 모든 행을 반환합니다. |
| 다른 테이블과 테이블 클러스터에 저장될 수 있습니다. | 테이블 클러스터에 저장될 수 없습니다. |
LONG 데이터 유형과 LOB 데이터 유형의 컬럼을 포함할 수 있습니다. | LOB 컬럼을 포함할 수 있지만 LONG 컬럼은 포함할 수 없습니다. |
| 가상 컬럼을 포함할 수 있습니다(관계형 힙 테이블만 지원됨). | 가상 컬럼을 포함할 수 없습니다. |
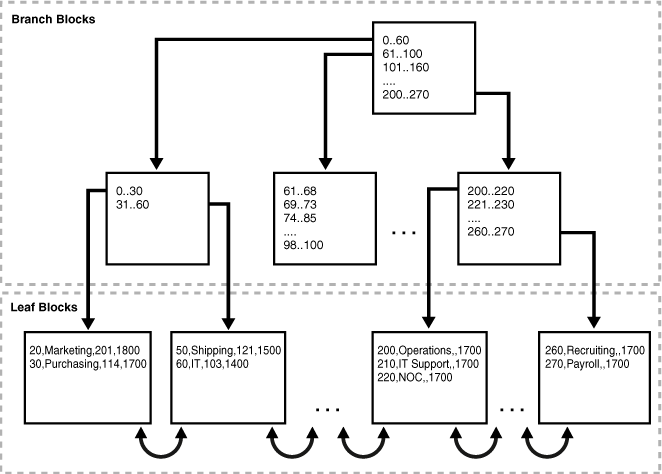
그림 3-3은 인덱스 구성 departments 테이블의 구조를 보여줍니다. 리프 블록은 테이블의 행을 포함하며, primary key에 따라 순차적으로 정렬됩니다. 예를 들어, 첫 번째 리프 블록의 첫 번째 값은 department ID가 20, department name이 Marketing, manager ID가 201, location ID가 1800인 것을 보여줍니다.
그림 3-3 인덱스 조직 테이블의 구조
예제 3-10 인덱스 조직 테이블 스캔
인덱스 조직 테이블은 모든 데이터를 동일한 구조로 저장하고 rowid를 저장할 필요가 없습니다. 그림 3-3에서 보여지는 것처럼, 인덱스 조직 테이블의 리프 블록 1은 다음과 같은 항목을 포함할 수 있으며, 기본 키 순서로 정렬됩니다:
20,Marketing,201,1800
30,Purchasing,114,1700인덱스 조직 테이블의 리프 블록 2는 다음과 같은 항목을 포함할 수 있습니다:
50,Shipping,121,1500
60,IT,103,1400기본 키 순서로 인덱스 조직 테이블의 행을 스캔하면 다음 순서로 블록을 읽습니다:
- 블록 1
- 블록 2
예제 3-11 힙 조직 테이블 스캔
힙 조직 테이블의 데이터 접근을 인덱스 조직 테이블과 대조하기 위해, 힙 조직 departments 테이블 세그먼트의 블록 1에 다음과 같은 행이 포함되어 있다고 가정합니다:
50,Shipping,121,1500
20,Marketing,201,1800블록 2에는 동일한 테이블의 행이 다음과 같이 포함되어 있습니다:
30,Purchasing,114,1700
60,IT,103,1400이 힙 조직 테이블에 대한 B-트리 인덱스 리프 블록은 다음 항목을 포함합니다. 첫 번째 값은 기본 키이고, 두 번째 값은 rowid입니다:
20,AAAPeXAAFAAAAAyAAD
30,AAAPeXAAFAAAAAyAAA
50,AAAPeXAAFAAAAAyAAC
60,AAAPeXAAFAAAAAyAAB기본 키 순서로 테이블 행을 스캔하면 테이블 세그먼트 블록을 다음 순서로 읽습니다:
- 블록 1
- 블록 2
- 블록 1
- 블록 2
따라서 이 예제에서 블록 I/O 수는 인덱스 조직 예제의 두 배입니다.
Index-Organized Tables with Row Overflow Area
인덱스 조직 테이블을 생성할 때, 별도의 세그먼트를 row 오버플로우 영역으로 지정할 수 있습니다.
인덱스 조직 테이블에서는 인덱스 항목이 전체 행을 포함할 수 있기 때문에 인덱스 항목이 클 수 있습니다. 별도의 세그먼트를 사용하여 항목을 저장하는 것이 유용합니다. 반면, B-트리 항목은 키와 rowid로 구성되어 보통 작습니다.
row 오버플로우 영역이 지정된 경우, 데이터베이스는 인덱스 조직 테이블의 행을 다음 부분으로 나눌 수 있습니다:
- 인덱스 항목
- 이 부분에는 모든 기본 키 컬럼 값, row의 오버플로우 부분을 가리키는 물리적 rowid 및 선택적으로 몇 개의 비키 컬럼 값이 포함됩니다. 이 부분은 인덱스 세그먼트에 저장됩니다.
- 오버플로우 부분
- 이 부분에는 나머지 비키 컬럼 값이 포함됩니다. 이 부분은 오버플로우 저장소 영역 세그먼트에 저장됩니다.
Secondary Indexes on Index-Organized Tables
보조 인덱스는 인덱스 조직 테이블에 대한 인덱스입니다.
일종의 인덱스에 대한 인덱스와 같은 개념입니다. 이는 독립적인 스키마 객체이며 인덱스 조직 테이블과 별도로 저장됩니다.
Oracle Database는 인덱스 조직 테이블에 대해 논리적 rowid를 사용합니다. 논리적 rowid는 테이블 기본 키의 base64 인코딩 표현입니다. 논리적 rowid 길이는 기본 키 길이에 따라 다릅니다.
행은 삽입으로 인해 인덱스 리프 블록 내에서 또는 블록 간에 이동할 수 있습니다. 행은 힙 조직 행처럼 이동하지 않습니다. 인덱스 조직 테이블의 행은 영구적인 물리적 주소를 가지지 않기 때문에 데이터베이스는 기본 키를 기반으로 하는 논리적 rowid를 사용합니다.
예를 들어, departments 테이블이 인덱스 조직 테이블이라고 가정합니다. location_id 컬럼은 각 부서의 ID를 저장합니다. 테이블은 다음과 같은 행을 저장하며, 마지막 값은 location ID입니다:
10,Administration,200,1700
20,Marketing,201,1800
30,Purchasing,114,1700
40,Human Resources,203,2400location_id 컬럼에 대한 보조 인덱스는 다음과 같은 인덱스 항목을 가질 수 있습니다. 쉼표 뒤의 값은 논리적 rowid입니다:
1700,*BAFAJqoCwR/+
1700,*BAFAJqoCwQv+
1800,*BAFAJqoCwRX+
2400,*BAFAJqoCwSn+보조 인덱스는 기본 키 또는 기본 키의 접두사가 아닌 컬럼을 사용하여 인덱스 조직 테이블에 빠르고 효율적으로 접근할 수 있습니다. 예를 들어, ID가 1700보다 큰 부서 이름을 쿼리하면 보조 인덱스를 사용하여 데이터 접근 속도를 높일 수 있습니다.
Logical Rowids and Physical Guesses
보조 인덱스는 논리적 rowid를 사용하여 테이블 행을 찾습니다.
논리적 rowid에는 물리적 추측이 포함되어 있으며, 이는 처음 생성될 때 인덱스 항목의 물리적 rowid입니다. Oracle Database는 물리적 추측을 사용하여 기본 키 검색을 우회하여 인덱스 조직 테이블의 리프 블록으로 직접 탐색할 수 있습니다. 행의 물리적 위치가 변경되면, 논리적 rowid는 물리적 추측이 잘못되더라도 유효하게 남아 있습니다.
힙 조직 테이블의 경우, 보조 인덱스를 통한 접근은 보조 인덱스의 스캔과 행을 포함하는 데이터 블록을 가져오기 위한 추가 I/O를 포함합니다. 인덱스 조직 테이블의 경우, 보조 인덱스를 통한 접근은 물리적 추측의 사용 및 정확성에 따라 다릅니다:
- 물리적 추측이 없는 경우, 접근은 보조 인덱스 스캔과 기본 키 인덱스의 고유 스캔을 포함합니다.
- 물리적 추측이 있는 경우, 접근은 다음과 같이 달라집니다:
- 물리적 추측이 정확한 경우, 접근은 보조 인덱스 스캔과 행을 포함하는 데이터 블록을 가져오기 위한 추가 I/O를 포함합니다.
- 물리적 추측이 부정확한 경우, 접근은 잘못된 데이터 블록을 가져오기 위한 보조 인덱스 스캔과 I/O를 포함하며, 그 후 기본 키 값에 의해 인덱스 조직 테이블의 고유 스캔이 수행됩니다.
Bitmap Indexes on Index-Organized Tables
인덱스 조직 테이블에 대한 보조 인덱스는 비트맵 인덱스일 수 있습니다. 비트맵 인덱스는 각 인덱스 키에 대한 비트맵을 저장합니다.
인덱스 조직 테이블에 비트맵 인덱스가 있는 경우, 모든 비트맵 인덱스는 힙 조직 매핑 테이블을 사용합니다. 매핑 테이블은 인덱스 조직 테이블의 논리적 rowid를 저장합니다. 각 매핑 테이블 행은 인덱스 조직 테이블 행에 대한 하나의 논리적 rowid를 저장합니다.
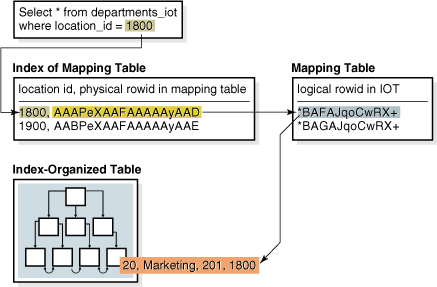
데이터베이스는 검색 키를 사용하여 비트맵 인덱스에 접근합니다. 데이터베이스가 키를 찾으면 비트맵 항목이 물리적 rowid로 변환됩니다. 힙 조직 테이블의 경우, 데이터베이스는 물리적 rowid를 사용하여 기본 테이블에 접근합니다. 인덱스 조직 테이블의 경우, 데이터베이스는 물리적 rowid를 사용하여 매핑 테이블에 접근하고, 매핑 테이블은 논리적 rowid를 반환하여 데이터베이스가 인덱스 조직 테이블에 접근할 수 있습니다. 다음 그림은 departments_iot 테이블에 대한 쿼리를 위한 인덱스 접근을 설명합니다.
그림 3-4 인덱스 조직 테이블의 비트맵 인덱스
참고: 인덱스 조직 테이블에서 행이 이동해도 해당 인덱스 조직 테이블에 빌드된 비트맵 인덱스는 사용 불가능해지지 않습니다.
