
Reference : Database Concepts - 4. Partitions, Views, and Other Schema Objects
*GPT 번역 기반으로 내용이 정확하지 않을 수 있습니다.
Partitions, Views, and Other Schema Objects
테이블과 인덱스는 가장 중요하고 자주 사용되는 스키마 객체이지만, 데이터베이스는 이 외에도 많은 유형의 스키마 객체를 지원합니다. 이 장에서는 가장 일반적으로 사용되는 스키마 객체들에 대해 설명합니다.
이 장에는 다음 섹션이 포함되어 있습니다:
- 파티션 개요
- 샤드 테이블 개요
- 뷰 개요
- 물리화된 뷰 개요
- 시퀀스 개요
- 디멘션 개요
- Synonym 개요
Overview of Partitions
오라클 데이터베이스에서 파티션을 사용하면 매우 큰 테이블과 인덱스를 작은 조각으로 분해하여 관리할 수 있습니다. 각 파티션은 고유의 이름과 저장 특성을 가질 수 있는 독립적인 객체입니다.
파티션을 설명하는 비유로, 인사 관리자에게 직원 폴더가 들어있는 큰 상자가 하나 있다고 가정해 보세요. 각 폴더에는 직원의 고용 날짜가 기록되어 있습니다. 특정 월에 고용된 직원을 찾기 위해 인덱스를 생성하는 대신, 파티션 전략을 사용하여 각 월에 고용된 직원의 폴더가 들어있는 작은 상자를 여러 개로 나눌 수 있습니다.
작은 상자를 사용하는 것은 여러 가지 장점이 있습니다. 예를 들어, 6월에 고용된 직원의 폴더를 찾으려면 6월 상자만 찾으면 됩니다. 또한, 작은 상자 중 하나가 손상되더라도 다른 상자는 여전히 사용할 수 있습니다. 사무실을 옮길 때도 큰 상자 하나를 옮기는 것보다 작은 상자 여러 개를 옮기는 것이 더 쉽습니다.
애플리케이션의 관점에서 보면, 오직 하나의 스키마 객체만 존재합니다. SQL 문은 파티션된 테이블에 접근하기 위해 수정이 필요하지 않습니다. 파티션은 특히 대용량 데이터를 관리하는 다양한 유형의 데이터베이스 애플리케이션에 유용합니다. 이점은 다음과 같습니다:
- 가용성 증가: 파티션이 사용할 수 없는 경우에도 객체 전체가 사용할 수 없는 것은 아닙니다. 쿼리 옵티마이저는 쿼리 계획에서 참조되지 않은 파티션을 자동으로 제거하므로 파티션이 사용할 수 없더라도 쿼리에 영향을 주지 않습니다.
- 스키마 객체 관리 용이성: 파티션된 객체는 개별적으로 또는 집합적으로 관리할 수 있는 조각으로 구성됩니다. DDL 문은 전체 테이블이나 인덱스 대신 파티션을 조작할 수 있습니다. 예를 들어, 리소스 집약적인 작업을 테이블이나 인덱스를 한 번에 하나의 파티션으로 나눠 수행할 수 있습니다. 문제가 발생하면 전체 테이블 이동이 아닌 파티션 이동만 다시 해야 합니다. 또한, 파티션을 삭제하면 수많은 DELETE 문을 실행하지 않아도 됩니다.
- OLTP 시스템에서 공유 리소스에 대한 경합 감소: 일부 OLTP 시스템에서는 파티션을 사용하여 공유 리소스에 대한 경합을 줄일 수 있습니다. 예를 들어, DML이 하나의 세그먼트 대신 여러 세그먼트에 분배됩니다.
- 데이터 웨어하우스에서 쿼리 성능 향상: 데이터 웨어하우스에서는 파티션을 사용하여 애드혹 쿼리 처리 속도를 높일 수 있습니다. 예를 들어, 백만 개의 행이 있는 판매 테이블을 분기별로 파티션할 수 있습니다.
Partition Characteristics
테이블이나 인덱스의 각 파티션은 열 이름, 데이터 유형 및 제약 조건과 같은 동일한 논리적 특성을 가져야 합니다.
예를 들어, 테이블의 모든 파티션은 동일한 열 및 제약 조건 정의를 공유합니다. 그러나 각 파티션은 소속된 테이블스페이스와 같은 별도의 물리적 특성을 가질 수 있습니다.
Partition Key
파티션 키는 파티션 테이블의 각 행이 속할 파티션을 결정하는 하나 이상의 열 집합입니다. 각 행은 명확하게 하나의 파티션에 할당됩니다.
sales 테이블에서 time_id 열을 범위 파티션 키로 지정할 수 있습니다. 데이터베이스는 이 열에 있는 날짜가 지정된 범위에 속하는지 여부에 따라 행을 파티션에 할당합니다. Oracle Database는 파티션 키를 사용하여 삽입, 업데이트 및 삭제 작업을 적절한 파티션으로 자동으로 방향을 잡습니다.
Partitioning Strategies
Oracle Partitioning은 데이터베이스가 데이터를 파티션에 배치하는 방법을 제어하는 여러 파티션 전략을 제공합니다. 기본 전략은 범위, 목록 및 해시 파티션입니다.
단일 레벨 파티션은 하나의 데이터 분포 방법만 사용합니다. 예를 들어, 목록 파티션 또는 범위 파티션만 사용하는 경우입니다. 복합 파티션에서는 테이블이 하나의 데이터 분포 방법으로 파티션되고 각 파티션이 두 번째 데이터 분포 방법을 사용하여 하위 파티션으로 나뉩니다. 예를 들어, channel_id에 대한 목록 파티션과 time_id에 대한 범위 하위 파티션을 사용할 수 있습니다.
예제 4-1 파티션 테이블의 샘플 행 집합
이 파티션 예제에서는 sales 테이블을 다음 행으로 채우고자 합니다:
PROD_ID CUST_ID TIME_ID CHANNEL_ID PROMO_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- --------- ---------- ---------- ------------- -----------
116 11393 05-JUN-99 2 999 1 12.18
40 100530 30-NOV-98 9 33 1 44.99
118 133 06-JUN-01 2 999 1 17.12
133 9450 01-DEC-00 2 999 1 31.28
36 4523 27-JAN-99 3 999 1 53.89
125 9417 04-FEB-98 3 999 1 16.86
30 170 23-FEB-01 2 999 1 8.8
24 11899 26-JUN-99 4 999 1 43.04
35 2606 17-FEB-00 3 999 1 54.94
45 9491 28-AUG-98 4 350 1 47.45 Range Partitioning
범위 파티션에서는 파티션 키의 값 범위에 따라 데이터베이스가 행을 파티션에 매핑합니다. 범위 파티션은 가장 일반적인 유형의 파티션이며 종종 날짜와 함께 사용됩니다.
time_id 열을 파티션 키로 사용하는 다음 SQL 문을 사용하여 time_range_sales라는 파티션 테이블을 생성한다고 가정해 보겠습니다.
CREATE TABLE time_range_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
(PARTITION SALES_1998 VALUES LESS THAN (TO_DATE('01-JAN-1999','DD-MON-YYYY')),
PARTITION SALES_1999 VALUES LESS THAN (TO_DATE('01-JAN-2000','DD-MON-YYYY')),
PARTITION SALES_2000 VALUES LESS THAN (TO_DATE('01-JAN-2001','DD-MON-YYYY')),
PARTITION SALES_2001 VALUES LESS THAN (MAXVALUE)
);그 후, 예제 4-1의 행을 time_range_sales에 로드합니다. 코드는 네 개의 파티션에 대한 행 분포를 보여줍니다. 데이터베이스는 PARTITION BY RANGE 절에 지정된 규칙에 따라 time_id 값에 기반하여 각 행에 대해 파티션을 선택합니다. 범위 파티션 키 값은 지정된 파티션에 대한 비포함 상한을 결정합니다.
Interval Partitioning
간격 파티션은 범위 파티션의 확장입니다.
범위 파티션을 초과하는 데이터를 삽입하면 Oracle Database가 지정된 간격의 파티션을 자동으로 생성합니다. 예를 들어, 각 월의 데이터를 별도의 파티션에 저장하는 판매 이력 테이블을 생성할 수 있습니다.
간격 파티션을 사용하면 범위 파티션을 명시적으로 생성할 필요가 없습니다. 새 파티션에 고정 간격을 사용하는 거의 모든 범위 파티션 테이블에 대해 간격 파티션을 사용할 수 있습니다. 범위 파티션을 다른 간격으로 생성하거나 항상 특정 파티션 속성을 설정하지 않는 한 간격 파티션을 고려하십시오.
간격으로 파티션할 때 적어도 하나의 범위 파티션을 지정해야 합니다. 범위 파티션 키 값은 전환점을 결정합니다. 데이터베이스는 전환점을 초과하는 데이터에 대해 간격 파티션을 자동으로 생성합니다. 각 간격 파티션의 하한은 이전 범위 또는 간격 파티션의 포함 상한입니다. 예제 4-2에서 값 01-JAN-2011은 p2 파티션에 있습니다.
데이터베이스는 전환점을 초과하는 데이터에 대해 간격 파티션을 생성합니다. 간격 파티션은 데이터베이스가 지정된 범위 또는 간격의 파티션을 생성하도록 지시함으로써 범위 파티션을 확장합니다. 데이터베이스는 테이블에 삽입된 데이터가 모든 기존 범위 파티션을 초과할 때 파티션을 자동으로 생성합니다. 예제 4-2에서 p3 파티션은 파티션 키 time_id 값이 01-JAN-2013 이상인 행을 포함합니다.
예제 4-2 간격 파티션
다양한 폭의 네 개의 파티션이 있는 판매 테이블을 생성한다고 가정해 보겠습니다. 2013년 1월 1일 전환점을 초과하는 데이터에 대해 데이터베이스가 한 달 간격의 파티션을 생성하도록 지정합니다. 파티션 p3의 상한은 전환점을 나타냅니다. p3 파티션과 그 아래의 모든 파티션은 범위 섹션에 속하며, 그 이상의 모든 파티션은 간격 섹션에 속합니다.
CREATE TABLE interval_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY RANGE (time_id)
INTERVAL(NUMTOYMINTERVAL(1, 'MONTH'))
( PARTITION p0 VALUES LESS THAN (TO_DATE('1-1-2010', 'DD-MM-YYYY'))
, PARTITION p1 VALUES LESS THAN (TO_DATE('1-1-2011', 'DD-MM-YYYY'))
, PARTITION p2 VALUES LESS THAN (TO_DATE('1-7-2012', 'DD-MM-YYYY'))
, PARTITION p3 VALUES LESS THAN (TO_DATE('1-1-2013', 'DD-MM-YYYY')) );2014년 10월 10일에 판매된 데이터를 삽입합니다:
SQL> INSERT INTO interval_sales VALUES (39,7602,'10-OCT-14',9,null,1,11.79);
1 row created.USER_TAB_PARTITIONS를 쿼리하면 데이터베이스가 2014년 10월 10일의 판매 데이터를 위해 새 파티션을 생성했음을 보여줍니다. 판매 날짜가 전환점을 초과했기 때문입니다:
SQL> COL PNAME FORMAT a9
SQL> COL HIGH_VALUE FORMAT a40
SQL> SELECT PARTITION_NAME AS PNAME, HIGH_VALUE
2 FROM USER_TAB_PARTITIONS WHERE TABLE_NAME = 'INTERVAL_SALES';
PNAME HIGH_VALUE
--------- ----------------------------------------
P0 TO_DATE(' 2007-01-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
P1 TO_DATE(' 2008-01-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
P2 TO_DATE(' 2009-07-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
P3 TO_DATE(' 2010-01-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1598 TO_DATE(' 2014-11-01 00:00:00', 'SYYYY-M
M-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAList Partitioning
목록 파티션에서는 데이터베이스가 각 파티션에 대한 파티션 키로 사용되는 불연속 값 목록을 사용합니다. 파티션 키는 하나 이상의 열로 구성될 수 있습니다.
목록을 사용하여 개별 행을 특정 파티션에 매핑하는 방법을 제어할 수 있습니다. 목록을 사용하면 정렬되지 않은 키를 사용하여 관련 데이터 집합을 그룹화하고 구성할 수 있습니다.
예제 4-3 목록 파티션
다음 문을 사용하여 channel_id 열을 파티션 키로 하는 list_sales라는 목록 파티션 테이블을 생성한다고 가정합니다:
CREATE TABLE list_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY LIST (channel_id)
( PARTITION even_channels VALUES ('2','4'),
PARTITION odd_channels VALUES ('3','9')
);그 후, 예제 4-1의 행을 테이블에 로드합니다. 코드는 두 파티션에 대한 행 분포를 보여줍니다. 데이터베이스는 PARTITION BY LIST 절에 지정된 규칙에 따라 channel_id 값에 기반하여 각 행에 대해 파티션을 선택합니다. channel_id 값이 2 또는 4인 행은 EVEN_CHANNELS 파티션에 저장되고, 값이 3 또는 9인 행은 ODD_CHANNELS 파티션에 저장됩니다.
Hash Partitioning
해시 파티션에서는 데이터베이스가 사용자 지정 파티션 키에 해싱 알고리즘을 적용하여 행을 파티션에 매핑합니다.
행의 목적지는 데이터베이스가 행에 적용하는 내부 해시 함수에 의해 결정됩니다. 파티션 수가 2의 제곱일 때 해싱 알고리즘은 모든 파티션에 대략 균일한 행 분포를 생성합니다.
해시 파티션은 큰 테이블을 나누어 관리 용이성을 높이는 데 유용합니다. 큰 테이블 대신 여러 작은 조각을 관리할 수 있습니다. 해시 파티션의 손실은 나머지 파티션에 영향을 주지 않으며 독립적으로 복구할 수 있습니다. 해시 파티션은 높은 업데이트 경합이 있는 OLTP 시스템에서도 유용합니다. 예를 들어, 세그먼트가 여러 조각으로 나뉘어 각 조각이 업데이트되는 경우 단일 세그먼트가 경합을 경험하는 경우보다 경합이 줄어듭니다.
다음 문을 사용하여 prod_id 열을 파티션 키로 하는 hash_sales라는 해시 파티션 테이블을 생성한다고 가정합니다:
CREATE TABLE hash_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY HASH (prod_id)
PARTITIONS 2;그 후, 예제 4-1의 행을 테이블에 로드합니다. 코드는 두 파티션에 대한 가능한 행 분포를 보여줍니다. 이 파티션의 이름은 시스템이 생성합니다.
행을 삽입할 때 데이터베이스는 행을 파티션에 무작위로 균등하게 분배하려고 시도합니다. 행이 배치될 파티션을 지정할 수 없습니다. 데이터베이스는 해시 함수를 적용하며, 그 결과로 행이 속하는 파티션이 결정됩니다.
Reference Partitioning
참조 파티션에서는 자식 테이블의 파티션 전략이 부모 테이블
과의 외래 키 관계를 통해 정의됩니다. 부모 테이블의 각 파티션에 대해 자식 테이블에 정확히 하나의 해당 파티션이 존재합니다. 부모 테이블은 특정 파티션에 부모 레코드를 저장하고 자식 테이블은 해당 파티션에 자식 레코드를 저장합니다.
예를 들어, orders 테이블은 line_items 테이블의 부모 테이블로, order_id에 대해 기본 키와 외래 키가 정의됩니다. 테이블은 참조에 따라 파티션됩니다. 예를 들어, 데이터베이스가 order 233을 orders의 Q3_2015 파티션에 저장하면 line_items의 Q3_2015 파티션에도 order 233의 모든 항목을 저장합니다. Q4_2015 파티션을 orders에 추가하면 데이터베이스는 자동으로 Q4_2015를 line_items에도 추가합니다.
참조 파티션의 장점은 다음과 같습니다:
- 부모 및 자식 테이블 모두에 대해 동일한 파티션 전략을 사용함으로써 모든 파티션 키 열을 중복하지 않도록 할 수 있습니다. 이 전략은 비정규화의 수작업을 줄이고 공간을 절약합니다.
- 부모 테이블에 대한 유지 관리 작업이 자동으로 자식 테이블에도 적용됩니다. 예를 들어, 마스터 테이블에 파티션을 추가하면 데이터베이스는 자동으로 이를 하위 테이블에 전파합니다.
- 데이터베이스는 부모 테이블과 자식 테이블의 파티션 간에 파티션별 조인을 자동으로 사용하여 성능을 향상시킵니다.
- 모든 기본 파티션 전략과 함께 참조 파티션을 사용할 수 있으며 간격 파티션과 함께 참조 파티션 테이블을 복합 파티션 테이블로 만들 수도 있습니다.
예제 4-4 참조 파티션 테이블 생성
이 예제는 order_date에 대해 범위 파티션된 부모 테이블 orders를 생성합니다. 참조 파티션된 자식 테이블 order_items는 Q1_2015, Q2_2015, Q3_2015 및 Q4_2015의 네 개의 파티션으로 생성되며, 각 파티션은 해당 부모 파티션의 주문에 대한 order_items 행을 포함합니다.
CREATE TABLE orders
( order_id NUMBER(12),
order_date DATE,
order_mode VARCHAR2(8),
customer_id NUMBER(6),
order_status NUMBER(2),
order_total NUMBER(8,2),
sales_rep_id NUMBER(6),
promotion_id NUMBER(6),
CONSTRAINT orders_pk PRIMARY KEY(order_id)
)
PARTITION BY RANGE(order_date)
( PARTITION Q1_2015 VALUES LESS THAN (TO_DATE('01-APR-2015','DD-MON-YYYY')),
PARTITION Q2_2015 VALUES LESS THAN (TO_DATE('01-JUL-2015','DD-MON-YYYY')),
PARTITION Q3_2015 VALUES LESS THAN (TO_DATE('01-OCT-2015','DD-MON-YYYY')),
PARTITION Q4_2015 VALUES LESS THAN (TO_DATE('01-JAN-2006','DD-MON-YYYY'))
);
CREATE TABLE order_items
( order_id NUMBER(12) NOT NULL,
line_item_id NUMBER(3) NOT NULL,
product_id NUMBER(6) NOT NULL,
unit_price NUMBER(8,2),
quantity NUMBER(8),
CONSTRAINT order_items_fk
FOREIGN KEY(order_id) REFERENCES orders(order_id)
)
PARTITION BY REFERENCE(order_items_fk);자세한 내용은 Oracle Database VLDB 및 Partitioning Guide에서 참조 파티션에 대한 개요를 참조하십시오.
Composite Partitioning
복합 파티션에서는 테이블이 하나의 데이터 분포 방법으로 파티션되고 각 파티션이 두 번째 데이터 분포 방법을 사용하여 하위 파티션으로 나뉩니다. 따라서 복합 파티션은 기본 데이터 분포 방법을 결합합니다. 특정 파티션에 대한 모든 하위 파티션은 데이터의 논리적 하위 집합을 나타냅니다.
복합 파티션은 여러 가지 이점을 제공합니다:
- SQL 문에 따라 하나 또는 두 개의 차원에서 파티션 제거가 성능을 향상시킬 수 있습니다.
- 쿼리는 한 차원 또는 두 차원 모두에서 전체 또는 부분 파티션별 조인을 사용할 수 있습니다.
- 단일 테이블의 병렬 백업 및 복구를 수행할 수 있습니다.
- 단일 레벨 파티션보다 파티션 수가 많아 병렬 실행에 유리할 수 있습니다.
- 많은 문이 파티션 제거 또는 파티션별 조인으로부터 이점을 얻을 수 있다면 다른 차원에 대해 파티션하여 롤링 윈도우를 구현할 수 있습니다.
- 파티션 키로 식별하여 데이터를 다르게 저장할 수 있습니다. 예를 들어, 특정 제품 유형의 데이터를 읽기 전용 압축 형식으로 저장하고 다른 제품 유형의 데이터를 압축하지 않도록 결정할 수 있습니다.
범위, 목록 및 해시 파티션은 복합 파티션 테이블에 대한 하위 파티션 전략으로 사용할 수 있습니다. 다음 그림은 범위-해시 및 범위-목록 복합 파티션의 그래픽 뷰를 제공합니다.
그림 4-1 복합 범위-목록 파티션
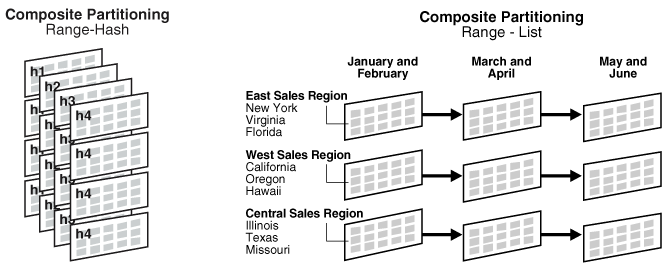
데이터베이스는 복합 파티션 테이블의 모든 하위 파티션을 별도의 세그먼트로 저장합니다. 따라서 하위 파티션 속성은 테이블의 속성이나 하위 파티션이 속한 파티션의 속성과 다를 수 있습니다.
Partitioned Tables
파티션된 테이블은 하나 이상의 파티션으로 구성되며, 개별적으로 관리되며 다른 파티션과 독립적으로 작동할 수 있습니다.
테이블은 파티션되거나 비파티션될 수 있습니다. 파티션된 테이블이 단 하나의 파티션으로 구성되더라도, 이 테이블은 추가 파티션을 가질 수 없는 비파티션된 테이블과는 다릅니다.
Segments for Partitioned Tables
파티션된 테이블은 하나 이상의 테이블 파티션 세그먼트로 구성됩니다.
hash_products라는 파티션된 테이블을 생성하면 이 테이블에 대한 테이블 세그먼트가 할당되지 않습니다. 대신, 데이터베이스는 각 테이블 파티션의 데이터를 고유의 파티션 세그먼트에 저장합니다. 각 테이블 파티션 세그먼트에는 테이블 데이터의 일부가 포함됩니다.
외부 테이블이 파티션되면 모든 파티션이 데이터베이스 외부에 위치합니다. 하이브리드 파티션 테이블에서는 일부 파티션이 세그먼트에 저장되고 다른 일부는 외부에 저장됩니다. 예를 들어, sales 테이블의 일부 파티션은 데이터 파일에 저장되고 다른 일부는 스프레드시트에 저장될 수 있습니다.
Compression for Partitioned Tables
힙-조직화 테이블의 일부 또는 모든 파티션은 압축 형식으로 저장할 수 있습니다.
압축은 공간을 절약하고 쿼리 실행 속도를 높일 수 있습니다. 따라서 삽입 및 업데이트 작업이 적은 데이터 웨어하우스 환경 및 OLTP 환경에서 유용할 수 있습니다.
테이블 압축에 대한 속성을 테이블스페이스, 테이블 또는 테이블 파티션 수준에서 선언할 수 있습니다. 테이블스페이스 수준에서 선언된 경우, 해당 테이블스페이스에서 생성된 테이블은 기본적으로 압축됩니다. 테이블의 압축 속성을 변경하면 해당 변경 사항은 해당 테이블에 입력되는 새로운 데이터에만 적용됩니다. 따라서 하나의 테이블 또는 파티션에 압축된 블록과 압축되지 않은 블록이 모두 포함될 수 있으며, 압축으로 인해 데이터 크기가 증가하지 않도록 보장됩니다. 압축으로 인해 블록의 크기가 증가할 수 있는 경우 데이터베이스는 해당 블록에 압축을 적용하지 않습니다.
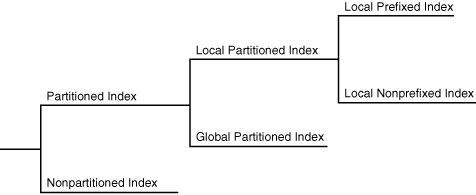
Partitioned Indexes
파티션된 인덱스는 파티션된 테이블과 마찬가지로 작고 관리하기 쉬운 조각으로 나누어진 인덱스입니다.
글로벌 인덱스는 생성된 테이블과 독립적으로 파티션되며, 로컬 인덱스는 테이블의 파티션 방법에 자동으로 연결됩니다. 파티션된 테이블과 마찬가지로 파티션된 인덱스는 관리 용이성, 가용성, 성능 및 확장성을 향상시킵니다.
다음 그림은 인덱스 파티션 옵션을 보여줍니다.
그림 4-2 인덱스 파티션 옵션
Local Partitioned Indexes
로컬 파티션된 인덱스에서는 인덱스가 테이블과 동일한 열, 동일한 수의 파티션 및 동일한 파티션 경계를 가지고 파티션됩니다.
각 인덱스 파티션은 기본 테이블의 정확히 하나의 파티션과 연결되어 있어, 인덱스 파티션의 모든 키는 단일 테이블 파티션에 저장된 행만 참조합니다. 이 방식으로 데이터베이스는 인덱스 파티션과 연관된 테이블 파티션을 자동으로 동기화하여 각 테이블-인덱스 쌍을 독립적으로 만듭니다.
로컬 파티션된 인덱스는 데이터 웨어하우스 환경에서 일반적입니다. 로컬 인덱스의 장점은 다음과 같습니다:
- 가용성이 증가합니다. 특정 파티션의 데이터를 유효하지 않거나 사용할 수 없게 만드는 작업은 해당 파티션에만 영향을 미칩니다.
- 파티션 유지 관리가 단순화됩니다. 테이블 파티션을 이동하거나 데이터가 파티션에서 벗어나면 연관된 로컬 인덱스 파티션만 다시 빌드하거나 유지 관리해야 합니다. 글로벌 인덱스에서는 모든 인덱스 파티션을 다시 빌드하거나 유지 관리해야 합니다.
- 파티션의 시점 복구가 발생하면 인덱스를 복구 시점까지 복구할 수 있습니다. 전체 인덱스를 다시 빌드할 필요가 없습니다.
해시 파티션의 예제에서는 prod_id 열을 파티션 키로 사용하는 hash_sales 테이블을 생성하는 구문을 보여줍니다. 다음 예제에서는 hash_sales 테이블의 time_id 열에 로컬 파티션된 인덱스를 생성합니다:
CREATE INDEX hash_sales_idx ON hash_sales(time_id) LOCAL;그림 4-3에서는 hash_products 테이블이 두 개의 파티션을 가지고 있어 hash_sales_idx도 두 개의 파티션을 가지게 됩니다. 각 인덱스 파티션은 다른 테이블 파티션과 연관됩니다. 인덱스 파티션 SYS_P38은 테이블 파티션 SYS_P33의 행을 인덱싱하며, 인덱스 파티션 SYS_P39는 테이블 파티션 SYS_P34의 행을 인덱싱합니다.
그림 4-3 로컬 인덱스 파티션
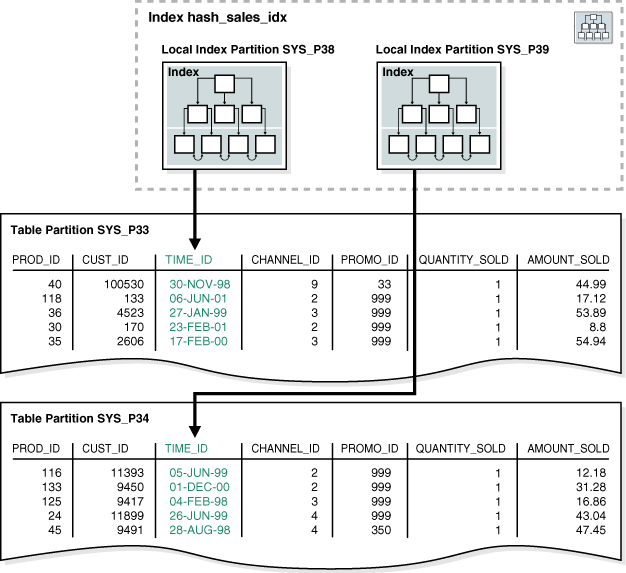
로컬 인덱스에 파티션을 명시적으로 추가할 수 없습니다. 대신, 테이블에 파티션을 추가할 때만 로컬 인덱스에 새 파티션이 추가됩니다. 마찬가지로, 로컬 인덱스에서 파티션을 명시적으로 삭제할 수 없습니다. 대신, 기본 테이블에서 파티션을 삭제할 때만 로컬 인덱스 파티션이 삭제됩니다.
다른 인덱스와 마찬가지로 파티션된 테이블에 비트맵 인덱스를 생성할 수 있습니다. 유일한 제한은 비트맵 인덱스가 파티션된 테이블에 로컬이어야 하며 글로벌 인덱스가 될 수 없다는 것입니다. 글로벌 비트맵 인덱스는 비파티션 테이블에서만 지원됩니다.
Local Prefixed and Nonprefixed Indexes
로컬 파티션된 인덱스는 접두 또는 비접두일 수 있습니다.
인덱스 하위 유형은 다음과 같이 정의됩니다:
- 로컬 접두 인덱스: 이 경우 파티션 키가 인덱스 정의의 선두에 있습니다. 범위 파티션 예제의
time_range_sales예제에서 테이블은time_id에 대해 범위로 파티션됩니다. 이 테이블에 대한 로컬 접두 인덱스는 인덱스 리스트의 첫 번째 열로time_id를 가집니다. - 로컬 비접두 인덱스: 이 경우 파티션 키가 인덱스 열 리스트의 선두에 없으며 리스트에 없을 수도 있습니다. 로컬 파티션 인덱스 예제의
hash_sales_idx예제에서는 인덱스가 로컬 비접두입니다. 이는 파티션 키인product_id가 인덱스 리스트의 선두에 없기 때문입니다.
두 유형의 인덱스 모두 파티션 제거(또는 파티션 프루닝)를 활용할 수 있습니다. 파티션 제거는 옵티마이저가 파티션을 제외하여 데이터 액세스를 가속화할 때 발생합니다. 쿼리에서 파티션을 제거할 수 있는지 여부는 쿼리 조건자에 따라 달라집니다. 로컬 접두 인덱스를 사용하는 쿼리는 항상 인덱스 파티션 제거를 허용하지만 로컬 비접두 인덱스를 사용하는 쿼리는 그렇지 않을 수 있습니다.
Local Partitioned Index Storage
테이블 파티션과 마찬가지로 로컬 인덱스 파티션은 고유의 세그먼트에 저장됩니다. 각 세그먼트는 전체 인덱스 데이터의 일부를 포함합니다. 따라서 네 개의 파티션으로 구성된 로컬 인덱스는 단일 인덱스 세그먼트가 아닌 네 개의 개별 세그먼트에 저장됩니다.
Global Partitioned Indexes
글로벌 파티션 인덱스는 기본 테이블과 독립적으로 파티션된 B-트리 인덱스입니다. 단일 인덱스 파티션은 모든 테이블 파티션을 가리킬 수 있지만, 로컬 파티션된 인덱스에서는 인덱스 파티션과 테이블 파티션 간에 일대일 대응이 존재합니다.
일반적으로 글로벌 인덱스는 OLTP 애플리케이션에 유용합니다. 이러한 시스템에서는 빠른 액세스, 데이터 무결성 및 가용성이 중요합니다. OLTP 시스템에서 테이블이 하나의 키, 예를 들어 employees.department_id 열로 파티션될 수 있지만, 애플리케이션은 employee_id나 job_id와 같은 여러 키로 데이터를 액세스할 필요가 있을 수 있습니다. 이 경우 글로벌 인덱스가 유용할 수 있습니다.
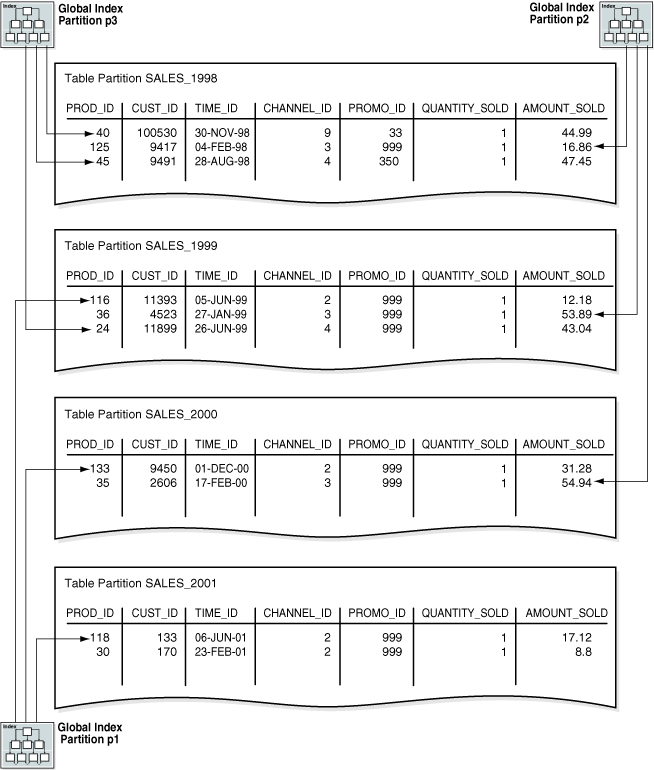
예를 들어, "범위 파티션"의 time_range_sales 테이블에 대해 channel_id 열로 범위 파티션된 글로벌 인덱스를 생성한다고 가정해 보겠습니다. 이 테이블에서는 1998년 판매 데이터는 하나의 파티션에, 1999년 판매 데이터는 다른 파티션에 저장됩니다. 다음 예제에서는 channel_id 열로 범위 파티션된 글로벌 인덱스를 생성합니다:
CREATE INDEX time_channel_sales_idx ON time_range_sales (channel_id)
GLOBAL PARTITION BY RANGE (channel_id)
(PARTITION p1 VALUES LESS THAN (3),
PARTITION p2 VALUES LESS THAN (4),
PARTITION p3 VALUES LESS THAN (MAXVALUE));그림 4-4에서는 글로벌 인덱스 파티션이 여러 테이블 파티션을 가리킬 수 있음을 보여줍니다. 인덱스 파티션 p1은 channel_id가 2인 행을 가리키고, 인덱스 파티션 p2는 channel_id가 3인 행을, 인덱스 파티션 p3는 channel_id가 4 또는 9인 행을 가리킵니다.
그림 4-4 글로벌 파티션 인덱스
Partial Indexes for Partitioned Tables
부분 인덱스는 관련 파티션된 테이블의 인덱싱 속성과 상관된 인덱스입니다.
이 상관 관계는 테이블 파티션을 인덱싱할지 여부를 지정할 수 있게 합니다. 부분 인덱스는 다음과 같은 이
점을 제공합니다:
- 인덱스되지 않은 테이블 파티션은 불필요한 인덱스 저장 공간을 소비하지 않습니다.
- 로드 및 쿼리 성능이 향상될 수 있습니다: Oracle Database 12c 이전에는 파티션 교환 작업이 사용 가능한 글로벌 인덱스를 유지하기 위해 물리적 업데이트를 필요로 했습니다. Oracle Database 12c부터는 파티션 유지 관리 작업에 관련된 파티션이 부분 글로벌 인덱스의 일부가 아닌 경우 글로벌 인덱스 유지 관리 없이 인덱스가 사용 가능 상태로 유지됩니다.
- 인덱스 생성을 시도할 때 일부 테이블 파티션만 인덱싱하면 인덱스 생성에 필요한 정렬 공간을 줄일 수 있습니다.
테이블의 개별 파티션에 대한 인덱싱을 켜거나 끌 수 있습니다. 부분 로컬 인덱스는 인덱싱이 꺼진 테이블 파티션에 대해 사용 가능한 인덱스 파티션을 가지지 않습니다. 글로벌 인덱스는 파티션이 인덱싱되지 않은 모든 데이터를 제외합니다. 고유 제약 조건을 적용하는 인덱스에 대해 부분 인덱스를 지원하지 않습니다.
그림 4-5는 그림 4-4와 동일한 글로벌 인덱스를 보여줍니다. 단, 글로벌 인덱스가 부분적으로 되어 있습니다. 테이블 파티션 SALES_1998 및 SALES_2000은 인덱싱 속성이 OFF이므로 부분 글로벌 인덱스가 이를 인덱싱하지 않습니다.
그림 4-5 부분 글로벌 파티션 인덱스

Overview of Sharded Tables
Oracle 데이터베이스에서 샤딩은 큰 테이블을 더 관리하기 쉬운 조각으로 나눌 수 있게 해줍니다. 각 조각은 여러 데이터베이스에 저장될 수 있습니다.
각 데이터베이스는 자체 로컬 리소스(CPU, 메모리, 플래시 또는 디스크)를 갖춘 전용 서버에서 호스팅됩니다. 이러한 구성의 각 데이터베이스를 샤드라고 합니다. 모든 샤드를 합쳐 하나의 논리적 데이터베이스를 구성하며, 이를 샤드 데이터베이스(SDB)라고 합니다.
수평 파티션은 테이블을 샤드에 걸쳐 나누어 각 샤드가 동일한 열을 가진 테이블을 포함하되 서로 다른 행 집합을 가지도록 합니다. 이러한 방식으로 나뉜 테이블을 샤드 테이블이라고도 합니다.
다음 그림은 테이블을 세 개의 샤드에 걸쳐 수평 파티션하는 방법을 보여줍니다.
그림 4-6 샤드에 걸친 테이블의 수평 파티션
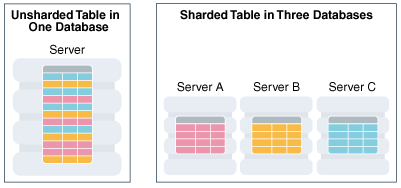
샤딩은 공유-없는(shared-nothing) 하드웨어 인프라를 기반으로 하며 샤드가 CPU, 메모리 또는 스토리지 장치와 같은 물리적 리소스를 공유하지 않기 때문에 단일 장애 지점을 제거합니다. 샤드는 소프트웨어 측면에서도 느슨하게 결합되어 클러스터웨어를 실행하지 않습니다.
샤드는 일반적으로 전용 서버에서 호스팅됩니다. 이러한 서버는 일반 하드웨어 또는 엔지니어드 시스템일 수 있습니다. 샤드는 단일 인스턴스 또는 Oracle RAC 데이터베이스에서 실행될 수 있습니다. 온프레미스, 클라우드 또는 온프레미스 및 클라우드 하이브리드 구성에서 배치될 수 있습니다.
데이터베이스 관리자의 관점에서는 SDB가 집합적으로 또는 개별적으로 관리될 수 있는 여러 데이터베이스로 구성됩니다. 그러나 애플리케이션의 관점에서는 SDB가 단일 데이터베이스처럼 보입니다: 샤드의 수와 데이터의 분포는 데이터베이스 애플리케이션에 완전히 투명합니다.
샤딩은 샤드 데이터베이스 아키텍처에 적합한 사용자 정의 OLTP 애플리케이션을 위해 설계되었습니다. 샤딩을 사용하는 애플리케이션은 잘 정의된 데이터 모델 및 데이터 분포 전략(일관된 해시, 범위, 목록 또는 복합)을 가져야 하며 주로 샤딩 키를 사용하여 데이터를 액세스합니다. 샤딩 키의 예로는 customer_id, account_no 또는 country_id가 있습니다.
Sharded Tables
샤드 테이블은 여러 데이터베이스(샤드)에 나누어져 더 관리하기 쉬운 조각으로 분할된 테이블입니다.
Oracle Sharding은 Oracle Database 파티션 기능을 기반으로 구현됩니다. Oracle Sharding은 기본적으로 파티션을 샤드에 분산하여 분산 파티션을 지원합니다.
파티션은 샤드 키를 기준으로 테이블스페이스 수준에서 샤드에 분산됩니다. 키의 예로는 고객 ID, 계좌 번호 및 국가 ID가 있습니다.
다음 데이터 유형이 샤드 키로 지원됩니다:
NUMBERINTEGERSMALLINTRAW(N)VARCHAR(N)VARCHAR2(N)CHARDATETIMESTAMP
샤드 테이블의 각 파티션은 별도의 테이블스페이스에 존재하며 각 테이블스페이스는 특정 샤드와 연결됩니다. 샤딩 방법에 따라 연결이 자동으로 설정되거나 관리자가 정의할 수 있습니다.
샤드 테이블의 파티션이 여러 샤드에 존재하더라도 애플리케이션에서는 테이블이 단일 데이터베이스의 파티션된 테이블처럼 보이고 동작합니다. 애플리케이션에서 발행한 SQL 문은 샤드를 참조하거나 샤드의 수와 구성을 기반으로 하지 않습니다.
예제 4-5 샤드 테이블
익숙한 테이블 파티션 구문은 행을 샤드에 걸쳐 파티션하는 방법을 지정합니다. 예를 들어 다음 SQL 문은 샤드 키 cust_id를 기준으로 테이블을 수평 파티션하여 샤드에 분산하는 샤드 테이블을 생성합니다:
CREATE SHARDED TABLE customers
( cust_id NUMBER NOT NULL
, name VARCHAR2(50)
, address VARCHAR2(250)
, region VARCHAR2(20)
, class VARCHAR2(3)
, signup DATE
CONSTRAINT cust_pk PRIMARY KEY(cust_id)
)
PARTITION BY CONSISTENT HASH (cust_id)
PARTITIONS AUTO
TABLESPACE SET ts1
;위의 테이블은 일관된 해시(consistant hash)에 의해 파티션됩니다. 이는 확장 가능한 분산 시스템에서 일반적으로 사용되는 해시 파티션의 특수 유형입니다. 이 기술은 테이블스페이스를 샤드에 걸쳐 자동으로 분산하여 데이터와 워크로드를 고르게 분배합니다. 샤드 테이블에는 글로벌 인덱스가 지원되지 않지만 로컬 인덱스는 지원됩니다.
Tablespace Sets
Oracle Sharding은 테이블스페이스 세트라는 단위로 테이블스페이스를 생성하고 관리합니다. PARTITIONS AUTO 절은 파티션 수를 자동으로 결정하도록 지정합니다. 이 유형의 해싱은 샤드 간의 데이터 마이그레이션 시 더 많은 유연성과 효율성을 제공합니다. 이는 탄력적인 확장성을 위해 중요합니다.
테이블스페이스는 SDB에서 데이터 분포의 논리적 단위입니다. 샤드에 걸쳐 파티션을 분배하는 것은 다른 샤드에 있는 테이블스페이스에 파티션을 자동으로 생성하여 달성됩니다. 다중 샤드 조인의 수를 최소화하기 위해 관련 테이블의 해당 파티션은 항상 동일한 샤드에 저장됩니다. 샤드 테이블의 각 파티션은 별도의 테이블스페이스에 저장됩니다.
참고: 테이블스페이스 세트는 오직 Oracle 관리 파일만 지원합니다.
개별 테이블스페이스는 테이블스페이스 세트 전체를 독립적으로 삭제하거나 변경할 수 없습니다.
TABLESPACE SET은 사용자 정의 샤딩 방법과 함께 사용할 수 없습니다.
Overview of Views
뷰는 하나 이상의 테이블을 논리적으로 표현한 것입니다. 본질적으로 뷰는 저장된 쿼리입니다.
뷰는 기반이 되는 테이블에서 데이터를 가져옵니다. 이 테이블을 기반 테이블(base table)이라고 합니다. 기반 테이블은 테이블일 수도 있고 다른 뷰일 수도 있습니다. 뷰에서 수행된 모든 작업은 실제로 기반 테이블에 영향을 미칩니다. 뷰는 대부분 테이블이 사용되는 곳에서 사용할 수 있습니다.
참고: 물리화된 뷰는 표준 뷰와 다른 데이터 구조를 사용합니다.
뷰를 사용하면 다양한 유형의 사용자에게 데이터 표현을 맞춤화할 수 있습니다. 뷰는 다음과 같은 경우에 자주 사용됩니다:
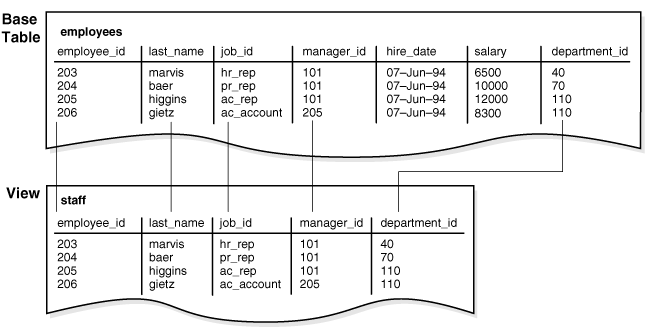
- 테이블의 사전 정의된 행 또는 열 집합에 대한 접근을 제한하여 추가적인 테이블 보안 수준을 제공: 예를 들어, 그림 4-7은
staff뷰가 기반 테이블employees의salary또는commission_pct열을 표시하지 않는 것을 보여줍니다. - 데이터 복잡성 숨기기: 예를 들어, 조인으로 정의된 단일 뷰가 여러 테이블의 관련 열 또는 행 집합을 나타낼 수 있습니다. 그러나 뷰는 이 정보가 실제로 여러 테이블에서 유래된 것임을 숨깁니다. 쿼리는 또한 테이블 정보를 사용하여 광범위한 계산을 수행할 수 있습니다. 따라서 사용자는 조인이나 계산을 수행하는 방법을 알지 않고 뷰를 쿼리할 수 있습니다.
- 기반 테이블과 다른 관점에서 데이터 표현: 예를 들어, 뷰의 열 이름을 변경해도 뷰가 기반하는 테이블에는 영향을 미치지 않습니다.
- 기반 테이블 정의의 변경 사항으로부터 애플리케이션 격리: 예를 들어, 뷰 정의 쿼리가 네 개의 열을 가진 테이블의 세 개 열을 참조하고 테이블에 다섯 번째 열이 추가되면 뷰의 정의는 영향을 받지 않으며 뷰를 사용하는 모든 애플리케이션도 영향을 받지 않습니다.
다음 예제에서는 hr.employees 테이블이 여러 열과 많은 행을 가지고 있다고 가정합니다. 사용자가 이 중 다섯 개의 열만 보거나 특정 행만 보도록 하려면 다음과 같이 뷰를 생성할 수 있습니다:
CREATE VIEW staff AS
SELECT employee_id, last_name, job_id, manager_id, department_id
FROM employees;모든 서브쿼리와 마찬가지로 뷰를 정의하는 쿼리에는 FOR UPDATE 절을 포함할 수 없습니다. 다음 그림은 staff라는 뷰를 보여줍니다. 뷰가 기반 테이블의 다섯 개 열만 표시하는 것을 주목하세요.
그림 4-7 뷰
Characteristics of Views
테이블과 달리 뷰는 저장 공간이 할당되지 않으며 데이터도 포함하지 않습니다. 대신 뷰는 뷰가 참조하는 기반 테이블에서 데이터를 추출하거나 유도하는 쿼리로 정의됩니다. 뷰는 다른 객체를 기반으로 하므로 데이터 사전에서 뷰를 정의하는 쿼리에 대한 저장 공간 외에는 저장 공간이 필요하지 않습니다.
뷰는 참조된 객체에 대한 종속성을 가지며, 데이터베이스가 자동으로 처리합니다. 예를 들어, 뷰의 기반 테이블을 삭제하고 다시 생성하면 데이터베이스가 새로운 기반 테이블이 뷰 정의에 적합한지 여부를 결정합니다.
Data Manipulation in Views
뷰는 테이블에서 유래되므로 많은 유사점을 가집니다. 사용자는 뷰를 쿼리할 수 있으며 일부 제한 사항이 있지만 뷰에서 DML을 수행할 수 있습니다. 뷰에서 수행된 작업은 뷰의 일부 기반 테이블의 데이터에 영향을 미치며, 이는 기반 테이블의 무결성 제약 조건과 트리거에 종속됩니다.
다음 예제에서는 hr.employees 테이블의 뷰를 생성합니다:
CREATE VIEW staff_dept_10 AS
SELECT employee_id, last_name, job_id,
manager_id, department_id
FROM employees
WHERE department_id = 10
WITH CHECK OPTION CONSTRAINT staff_dept_10_cnst;정의 쿼리는 부서 10의 행만 참조합니다. CHECK OPTION은 뷰가 선택할 수 없는 행이 INSERT 또는 UPDATE 문에서 발생하지 않도록 뷰에 제약 조건을 생성합니다. 따라서 부서 10의 직원에 대한 행은 삽입할 수 있지만, 부서 30의 행은 삽입할 수 없습니다.
자세한 내용은 Oracle Database SQL Language Reference에서 CREATE VIEW 문에서 서브쿼리 제한에 대해 알아보십시오.
How Data Is Accessed in Views
Oracle Database는 뷰 정의를 데이터 사전에 뷰를 정의하는 쿼리 텍스트로 저장합니다.
SQL 문에서 뷰를 참조할 때 Oracle Database는 다음 작업을 수행합니다:
- 뷰에 대한 쿼리를 (가능한 경우) 뷰를 정의하는 쿼리 및 모든 기본 뷰와 병합합니다.
- Oracle Database는 뷰를 참조하지 않고 쿼리를 발행한 것처럼 병합된 쿼리를 최적화합니다. 따라서 Oracle Database는 뷰 정의에 참조된 열이든 사용자 쿼리에서 참조된 열이든 관계없이 모든 기본 테이블 열에 대한 인덱스를 사용할 수 있습니다.
- 때때로 Oracle Database는 뷰 정의를 사용자 쿼리와 병합할 수 없습니다. 이러한 경우 Oracle Database는 참조된 열의 모든 인덱스를 사용할 수 없습니다.
- 공유 SQL 영역에서 병합된 문을 구문 분석합니다.
- Oracle Database는 뷰를 참조하는 문이 유사한 문을 포함한 기존 공유 SQL 영역이 없는 경우에만 새 공유 SQL 영역에서 문을 구문 분석합니다. 따라서 뷰는 공유 SQL과 관련된 메모리 사용 감소의 이점을 제공합니다.
- SQL 문을 실행합니다.
다음 예제는 뷰를 쿼리할 때 데이터 접근을 설명합니다. employees 및 departments 테이블을 기반으로 employees_view를 생성한다고 가정합니다:
CREATE VIEW employees_view AS
SELECT employee_id, last_name, salary, location_id
FROM employees JOIN departments USING (department_id)
WHERE department_id = 10;사용자가 employees_view의 다음 쿼리를 실행합니다:
SELECT last_name
FROM employees_view
WHERE employee_id = 200;Oracle Database는 뷰와 사용자 쿼리를 병합하여 다음과 같은 쿼리를 생성하고 데이터를 검색하기 위해 이를 실행합니다:
SELECT last_name
FROM employees, departments
WHERE employees.department_id = departments.department_id
AND departments.department_id = 10
AND employees.employee_id = 200;Updatable Join Views
조인 뷰는 FROM 절에 여러 테이블 또는 뷰가 포함된 뷰입니다.
다음 예제에서는 employees 및 departments 테이블을 조인하여 부서 10 또는 30에 속한 직원만 포함하는 staff_dept_10_30 뷰를 생성합니다:
CREATE VIEW staff_dept_10_30 AS
SELECT employee_id, last_name, job_id, e.department_id
FROM employees e, departments d
WHERE e.department_id IN (10, 30)
AND e.department_id = d.department_id;업데이트 가능한 조인 뷰(또는 수정 가능한 조인 뷰)는 두 개 이상의 기반 테이블 또는 뷰를 포함하며 DML 작업을 허용합니다. 업데이트 가능한 뷰는 SELECT 문의 최상위 FROM 절에 여러 테이블이 포함되며 WITH READ ONLY 절로 제한되지 않습니다.
뷰가 본질적으로 업데이트 가능하려면 몇 가지 기준을 충족해야 합니다. 예를 들어 일반적인 규칙은 조인 뷰에서 INSERT, UPDATE 또는 DELETE 작업이 한 번에 하나의 기반 테이블만 수정할 수 있다는 것입니다. USER_UPDATABLE_COLUMNS 데이터 사전 뷰를 쿼리하여 staff_dept_10_30 뷰가 업데이트 가능함을 보여줍니다:
SQL> SELECT TABLE_NAME, COLUMN_NAME, UPDATABLE
2 FROM USER_UPDATABLE_COLUMNS
3 WHERE TABLE_NAME = 'STAFF_DEPT_10_30';
TABLE_NAME COLUMN_NAME UPD
------------------------------ ------------------------------ ---
STAFF_DEPT_10_30 EMPLOYEE_ID YES
STAFF_DEPT_10_30 LAST_NAME YES
STAFF_DEPT_10_30 JOB_ID YES
STAFF_DEPT_10_30 DEPARTMENT_ID YES조인 뷰의 모든 업데이트 가능한 열은 키 유지 테이블의 열과 매핑되어야 합니다. 키 유지 테이블은 쿼리 출력에서 기본 테이블의 각 행이 최대 한 번만 나타나는 테이블입니다. staff_dept_10_30 뷰에서는 department_id가 departments 테이블의 기본 키이므로 employees 테이블의 각 행이 결과 집합에서 최대 한 번 나타나 employees 테이블이 키 유지됩니다. departments 테이블은 각 행이 결과 집합에서 여러 번 나타날 수 있으므로 키 유지되지 않습니다.
Object Views
뷰가 가상 테이블인 것처럼 객체 뷰는 가상 객체 테이블입니다. 뷰의 각 행은 객체 타입의 인스턴스인 객체입니다. 객체 타입은 사용자 정의 데이터 타입입니다.
관계형 데이터를 객체 타입으로 저장된 것처럼 검색, 업데이트, 삽입 및 삭제할 수 있습니다. 또한 객체, REF 및 컬렉션(중첩된 테이블 및 VARRAY)과 같은 객체 데이터 타입이 포함된 뷰를 정의할 수 있습니다.
관계형 뷰와 마찬가지로 객체 뷰는 데이터베이스 관리자가 사용자가 보기를 원하는 데이터만 표시할 수 있습니다. 예를 들어, 객체 뷰는 IT 프로그래머에 대한 데이터를 표시할 수 있지만 급여와 같은 민감한 데이터는 생략할 수 있습니다. 다음 예제에서는 employee_type 객체를 생성한 다음 이를 기반으로 한 it_prog_view를 생성합니다:
CREATE TYPE employee_type AS OBJECT
(
employee_id NUMBER (6),
last_name VARCHAR2 (25),
job_id VARCHAR2 (10)
);
/
CREATE VIEW it_prog_view OF employee_type
WITH OBJECT IDENTIFIER (employee_id) AS
SELECT e.employee_id, e.last_name, e.job_id
FROM employees e
WHERE job_id = 'IT_PROG';객체 뷰는 관계형 테이블에서 데이터를 가져와 객체 테이블로 정의된 것처럼 액세스할 수 있으므로 객체 지향 애플리케이션으로 전환하거나 프로토타이핑하는 데 유용합니다. 기존 테이블을 다른 물리적 구조로 변환하지 않고 객체 지향 애플리케이션을 실행할 수 있습니다.
Overview of Materialized Views
물리화된 뷰는 쿼리 결과를 사전에 스키마 객체로 저장한 것입니다. 쿼리의 FROM 절에는 테이블, 뷰 또는 물리화된 뷰가 있을 수 있습니다.
물리화된 뷰는 종종 복제에서 마스터 테이블 또는 데이터 웨어하우스에서 사실 테이블로 사용됩니다. 물리화된 뷰는 데이터를 요약, 계산, 복제 및 분배합니다. 이는 다음과 같은 다양한 컴퓨팅 환경에서 적합합니다:
- 데이터 웨어하우스에서는 물리화된 뷰가 합계 및 평균과 같은 집계 함수를 사용하여 데이터를 계산하고 저장할 수 있습니다. 요약은 조인과 집계 작업을 사전에 계산하고 결과를 테이블에 저장하여 쿼리 시간을 단축시키는 집계 뷰입니다. 물리화된 뷰는 요약과 동등합니다. 물리화된 뷰를 사용하여 집계 없이 조인을 계산할 수도 있습니다.
- 물리화된 뷰 복제에서는 XStream 및 Oracle GoldenGate를 사용하여 뷰가 특정 시점의 테이블의 전체 또는 일부 복사본을 포함합니다. 물리화된 뷰는 분산 사이트에서 데이터를 복제하고 여러 사이트에서 수행된 업데이트를 동기화합니다. 이 형태의 복제는 필드 판매와 같이 데이터베이스가 항상 네트워크에 연결되지 않는 환경에 적합합니다.
- 모바일 컴퓨팅 환경에서는 물리화된 뷰가 중앙 서버에서 모바일 클라이언트로 데이터 하위 집합을 다운로드할 수 있습니다. 중앙 서버에서 주기적인 갱신과 클라이언트가 중앙 서버로 업데이트를 전파할 수 있습니다.
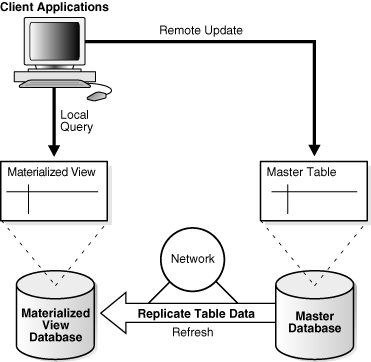
복제 환경에서 물리화된 뷰는 다른 데이터베이스의 테이블(마스터 데이터베이스)과 데이터를 공유합니다. 물리화된 뷰가 마스터 사이트에 있는 테이블을 마스터 테이블이라고 합니다. 그림 4-8은 다른 데이터베이스의 마스터 테이블을 기반으로 한 데이터베이스의 물리화된 뷰를 보여줍니다. 마스터 테이블에 대한 업데이트는 물리화된 뷰 데이터베이스로 복제됩니다.
그림 4-8 물리화된 뷰
Characteristics of Materialized Views
물리화된 뷰는 인덱스와 비물리화된 뷰의 일부 특성을 공유합니다.
물리화된 뷰는 다음과 같은 점에서 인덱스와 유사합니다:
- 실제 데이터를 포함하고 저장 공간을 소비합니다.
- 마스터 테이블의 데이터가 변경될 때 갱신될 수 있습니다.
- 쿼리 재작성 작업에 사용될 때 SQL 실행 성능을 향상시킬 수 있습니다.
- SQL 애플리케이션 및 사용자에게 투명합니다.
물리화된 뷰는 비물리화된 뷰와 유사합니다. 이는 다른 테이블 및 뷰의 데이터를 나타내기 때문입니다. 인덱스와 달리 사용자는 SELECT 문을 사용하여 물리화된
뷰를 직접 쿼리할 수 있습니다. 필요한 갱신 유형에 따라 뷰는 DML 문을 사용하여 업데이트할 수도 있습니다.
다음 예제에서는 sh 샘플 스키마의 세 개의 마스터 테이블을 기반으로 한 물리화된 집계 뷰를 생성하고 채웁니다:
CREATE MATERIALIZED VIEW sales_mv AS
SELECT t.calendar_year, p.prod_id, SUM(s.amount_sold) AS sum_sales
FROM times t, products p, sales s
WHERE t.time_id = s.time_id
AND p.prod_id = s.prod_id
GROUP BY t.calendar_year, p.prod_id;다음 예제에서는 물리화된 뷰 sales_mv의 마스터 테이블인 sales 테이블을 삭제한 후 sales_mv를 쿼리합니다. 쿼리는 데이터를 선택합니다. 이는 행이 마스터 테이블의 데이터와 별도로 저장(물리화)되었기 때문입니다:
SQL> DROP TABLE sales;
Table dropped.
SQL> SELECT * FROM sales_mv WHERE ROWNUM < 4;
CALENDAR_YEAR PROD_ID SUM_SALES
------------- ---------- ----------
1998 13 936197.53
1998 26 567533.83
1998 27 107968.24물리화된 뷰는 파티션될 수 있습니다. 파티션된 테이블에 대해 물리화된 뷰를 정의하고 물리화된 뷰에 대해 하나 이상의 인덱스를 정의할 수 있습니다.
Refresh Methods for Materialized Views
데이터베이스는 기본 테이블의 변경 후 물리화된 뷰를 갱신하여 데이터를 유지 관리합니다. 갱신 방법은 증분 또는 전체 갱신일 수 있습니다.
Complete Refresh
전체 갱신은 물리화된 뷰를 정의하는 쿼리를 실행합니다. 전체 갱신은 물리화된 뷰를 처음 생성할 때 발생합니다. 단, 물리화된 뷰가 미리 빌드된 테이블을 참조하거나 테이블을 BUILD DEFERRED로 정의한 경우는 예외입니다.
전체 갱신은 데이터베이스가 대량의 데이터를 읽고 처리해야 하는 경우 느릴 수 있습니다. 물리화된 뷰를 생성한 후 언제든지 전체 갱신을 수행할 수 있습니다.
Incremental Refresh
증분 갱신(또는 빠른 갱신)은 기존 데이터에 대한 변경 사항만 처리합니다. 이 방법은 물리화된 뷰를 처음부터 다시 빌드할 필요를 제거합니다. 변경 사항만 처리하면 매우 빠른 갱신 시간이 가능합니다.
물리화된 뷰를 수동으로 또는 정기적인 시간 간격으로 갱신할 수 있습니다. 또는 물리화된 뷰를 기본 테이블과 동일한 데이터베이스에 구성하여 기본 테이블에 변경 사항이 커밋될 때마다 갱신할 수 있습니다.
빠른 갱신에는 다음 두 가지 형태가 있습니다:
- 로그 기반 갱신
- 이 유형의 갱신에서는 물리화된 뷰 로그 또는 직접 로더 로그가 기본 테이블에 대한 변경 사항을 기록합니다. 물리화된 뷰 로그는 기본 테이블의 변경 사항을 기록하는 스키마 객체로, 이 기본 테이블에 정의된 물리화된 뷰를 증분 갱신할 수 있습니다. 각 물리화된 뷰 로그는 단일 기본 테이블과 연결됩니다.
- 파티션 변경 추적(PCT) 갱신
- PCT 갱신은 기본 테이블이 파티션된 경우에만 유효합니다. PCT 갱신은 영향을 받는 물리화된 뷰 파티션이나 영향을 받는 데이터 부분을 모두 제거한 다음 이를 다시 계산합니다. 데이터베이스는 수정된 기본 테이블 파티션을 사용하여 뷰의 영향을 받는 파티션이나 데이터 부분을 식별합니다. 기본 테이블에서 파티션 유지 관리 작업이 발생한 경우 PCT 갱신은 유일하게 사용할 수 있는 증분 갱신 방법입니다.
In-Place and Out-of-Place Refresh
전체 및 증분 방법에 대해 데이터베이스는 물리화된 뷰를 장소 내에서 갱신하거나 장소 외에서 갱신할 수 있습니다.
장소 외 갱신은 하나 이상의 외부 테이블을 생성하고 외부 테이블에서 갱신 문을 실행한 다음 물리화된 뷰 또는 영향을 받은 파티션을 외부 테이블과 교체합니다. 이 기술은 갱신 문이 완료되는 데 오랜 시간이 걸리는 경우 특히 갱신 중 고가용성을 달성합니다.
Oracle Database 12c에서는 동기 갱신을 도입하여 장소 외 갱신의 일종을 제공합니다. 동기 갱신은 기본 테이블의 내용을 수정하지 않고 동기 갱신 패키지의 API를 사용합니다. 이 패키지는 이러한 변경 사항을 기본 테이블과 물리화된 뷰에 동시에 적용하여 일관성을 보장합니다. 이 접근 방식은 일련의 테이블과 이에 정의된 물리화된 뷰가 항상 동기화되도록 합니다. 데이터 웨어하우스에서 동기 갱신 방법은 다음과 같은 이유로 적합합니다:
- 증분 데이터 로드가 엄격히 제어되며 주기적으로 발생합니다.
- 테이블과 물리화된 뷰는 종종 동일한 방식으로 파티션되거나 파티션이 기능적 종속 관계에 있습니다.
Query Rewrite
쿼리 재작성은 마스터 테이블을 기준으로 작성된 사용자 요청을 물리화된 뷰를 포함한 의미적으로 동일한 요청으로 변환합니다.
기본 테이블에 대량의 데이터가 포함된 경우 집계 또는 조인을 계산하는 것은 비용이 많이 들고 시간이 많이 소요됩니다. 물리화된 뷰에는 미리 계산된 집계 및 조인이 포함되어 있으므로 쿼리 재작성은 물리화된 뷰를 사용하여 쿼리에 빠르게 응답할 수 있습니다.
쿼리 변환기는 사용자의 개입 없이 물리화된 뷰를 사용하도록 요청을 투명하게 재작성합니다. 따라서 SQL 문에서 물리화된 뷰를 참조할 필요가 없습니다. 쿼리 재작성은 투명하기 때문에 물리화된 뷰를 추가하거나 삭제해도 애플리케이션 코드의 SQL이 무효화되지 않습니다.
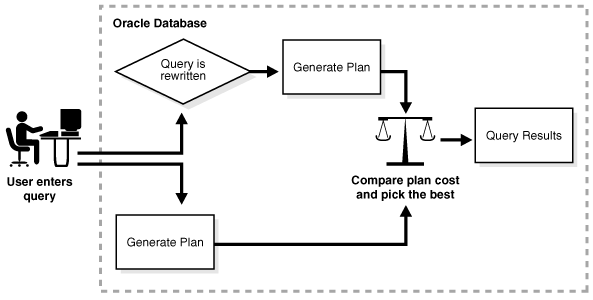
일반적으로 물리화된 뷰를 사용하여 쿼리를 재작성하면 세부 테이블보다 응답 시간이 단축됩니다. 다음 그림에서는 데이터베이스가 원래 쿼리와 재작성된 쿼리에 대한 실행 계획을 생성하고 비용이 가장 낮은 계획을 선택하는 과정을 보여줍니다.
그림 4-9 쿼리 재작성
Overview of Sequences
시퀀스는 여러 사용자가 고유한 정수를 생성할 수 있는 스키마 객체입니다. 시퀀스 생성기는 숫자 데이터 타입에 대한 서로게이트 키를 생성하는 데 매우 확장 가능하고 성능이 뛰어난 방법을 제공합니다.
Sequence Characteristics
시퀀스 정의는 시퀀스의 이름과 시퀀스가 오름차순 또는 내림차순인지 여부와 같은 일반 정보를 나타냅니다.
시퀀스 정의는 다음 사항도 나타냅니다:
- 숫자 간의 간격
- 데이터베이스가 생성된 시퀀스 번호 집합을 메모리에 캐시해야 하는지 여부
- 시퀀스가 한계에 도달했을 때 순환해야 하는지 여부
다음 예제에서는 샘플 스키마 oe에서 customers_seq 시퀀스를 생성합니다. 애플리케이션은 이 시퀀스를 사용하여 customers 테이블에 행을 추가할 때 고객 ID 번호를 제공할 수 있습니다:
CREATE SEQUENCE customers_seq
START WITH 1000
INCREMENT BY 1
NOCACHE
NOCYCLE;customers_seq.nextval에 대한 첫 번째 참조는 1000을 반환합니다. 두 번째 참조는 1001을 반환합니다. 이후 각 참조는 이전 참조보다 1 큰 값을 반환합니다.
Concurrent Access to Sequences
동일한 시퀀스 생성기가 여러 테이블에 대한 숫자를 생성할 수 있습니다.
생성기는 기본 키를 자동으로 생성하고 여러 행이나 테이블에 대한 키를 조정할 수 있습니다. 예를 들어, 시퀀스는 orders 테이블과 customers 테이블에 대한 기본 키를 생성할 수 있습니다.
시퀀스 생성기는 디스크 I/O나 트랜잭션 잠금의 오버헤드 없이 고유한 번호를 생성할 수 있는 멀티유저 환경에서 유용합니다. 예를 들어, 두 사용자가 동시에 orders 테이블에 새 행을 삽입합니다. order_id 열에 고유한 번호를 생성하기 위해 시퀀스를 사용하면 두 사용자는 다음 사용할 수 있는 주문 번호를 입력하기 위해 서로 기다릴 필요가 없습니다. 시퀀스는 각 사용자가 올바른 값을 자동으로 생성합니다.
시퀀스를 참조하는 각 사용자는 해당 세션에서 마지막으로 생성된 현재 시퀀스 번호에 액세스할 수 있습니다. 사용자는 새로운 시퀀스 번호를 생성하거나 세션에서 마지막으로 생성된 현재 번호를 사용할 수 있습니다. 세션에서 시퀀스 번호를 생성한 후 이 번호는 이 세션에만 사용 가능합니다. 롤백된 트랜잭션에서 생성되고 사용된 경우 개별 시퀀스 번호는 건너뛸 수 있습니다.
경고: 애플리케이션이 간격 없는 번호 집합을 필요로 하는 경우 Oracle 시퀀스를 사용할 수 없습니다. 자체 개발한 코드를 사용하여 데이터베이스에서 활동을 직렬화해야 합니다.
Overview of Dimensions
일반적인 데이터 웨어하우스에는 두 가지 중요한 구성 요소가 있습니다: 디멘션과 사실(facts)입니다.
디멘션은 시간, 지리, 제품, 부서 및 유통 채널과 같이 비즈니스 질문을 지정하는 데 사용되는 모든 범주입니다. 사실은 특정 디멘션 값 집합과 관련된 이벤트 또는 엔티티로, 예를 들어 판매된 단위 또는 수익입니다.
다차원 요청의 예는 다음과 같습니다:
- 2013년 및 2014년 동안 지리 디멘션의 상태에서 국가로, 국가에서 지역으로의 점증적 집계 수준에서 모든 제품에 대한 총 판매를 보여줍니다.
- 2013년 및 2014년 동안 남미의 영토별 비용을 보여주는 크로스 탭 분석을 만듭니다. 가능한 모든 소계를 포함합니다.
- 2014년 자동차 제품의 판매 수익을 기준으로 아시아에서 상위 10명의 판매 대표를 나열하고 그들의 수수료를 순위 매깁니다.
많은 다차원 질문은 집계된 데이터와 시간, 지리 또는 예산을 기준으로 한 데이터 세트 간의 비교를 필요로 합니다.
디멘션을 생성하면 쿼리 재작성 기능의 사용 범위가 넓어집니다. 쿼리를 물리화된 뷰로 투명하게 재작성함으로써 데이터베이스는 쿼리 성능을 향상시킬 수 있습니다.
Hierarchical Structure of a Dimension
디멘션 테이블은 열 쌍 또는 열 집합 간의 계층적(부모/자식) 관계를 정의하는 논리 구조입니다.
예를 들어, 디멘션은 행 내에서 city 열이 state 열의 값을 암시하고, state 열이 country 열의 값을 암시한다고 나타낼 수 있습니다.
고객 디멘션에서는 고객이 도시, 주, 국가, 하위 지역 및 지역으로 롤업될 수 있습니다. 데이터 분석은 일반적으로 디멘션 계층의 상위 수준에서 시작하여 상황에 따라 점점 더 세부적으로 분석합니다.
자식 수준의 각 값은 부모 수준의 하나의 값과만 연관됩니다. 계층적 관계는 계층의 다음 수준까지의 함수적 종속성입니다.
디멘션에는 데이터 저장이 할당되지 않습니다. 디멘션 정보는 디멘션 테이블에 저장되며, 사실 정보는 사실 테이블에 저장됩니다.
Creation of Dimensions
CREATE DIMENSION SQL 문을 사용하여 디멘션을 생성합니다.
이 문은 다음을 지정합니다:
- 각 디멘션에서 열 또는 열 집합을 식별하는 여러
LEVEL절 - 인접한 레벨 간의 부모/자식 관계를 지정하는 하나 이상의
HIERARCHY절 - 개별 레벨과 관련된 추가 열 또는 열 집합을 식별하는 선택적
ATTRIBUTE절
다음 문은 샘플 스키마 sh에서 customers_dim 디멘션을 생성하는 데 사용되었습니다:
CREATE DIMENSION customers_dim
LEVEL customer IS (customers.cust_id)
LEVEL city IS (customers.cust_city)
LEVEL state IS (customers.cust_state_province)
LEVEL country IS (countries.country_id)
LEVEL subregion IS (countries.country_subregion)
LEVEL region IS (countries.country_region)
HIERARCHY geog_rollup (
customer CHILD OF
city CHILD OF
state CHILD OF
country CHILD OF
subregion CHILD OF
region
JOIN KEY (customers.country_id) REFERENCES country )
ATTRIBUTE customer DETERMINES
(cust_first_name, cust_last_name, cust_gender,
cust_marital_status, cust_year_of_birth,
cust_income_level, cust_credit_limit)
ATTRIBUTE country DETERMINES (countries.country_name);디멘션의 열은 동일한 테이블에서 가져올 수도 있고(비정규화), 여러 테이블에서 가져올 수도 있습니다(완전 정규화 또는 부분 정규화). 예를 들어, 정규화된 시간 디멘션은 날짜 테이블, 월 테이블 및 연도 테이블을 포함하며 각 날짜 행을 월 행에, 각 월 행을 연도 행에 연결하는 조인 조건이 있습니다. 완전히 비정규화된 시간 디멘션에서는 날짜, 월 및 연도 열이 동일한 테이블에 있습니다. 정규화되었든 비정규화되었든 열 간의 계층적 관계는 CREATE DIMENSION 문에서 지정해야 합니다.
Overview of Synonyms
Synonym은 스키마 객체에 대한 별칭입니다. 예를 들어, 테이블 또는 뷰, 시퀀스, PL/SQL 프로그램 단위, 사용자 정의 객체 타입 또는 다른 synonym에 대해 synonym을 생성할 수 있습니다. Synonym은 단순히 별칭이기 때문에 데이터 사전에서 정의에 대한 저장 공간 외에는 저장 공간이 필요하지 않습니다.
Synonym은 데이터베이스 사용자에게 SQL 문을 단순화할 수 있습니다. Synonym은 기본 스키마 객체의 정체와 위치를 숨기는 데도 유용합니다. 기본 객체의 이름을 변경하거나 이동해야 하는 경우 synonym만 다시 정의하면 됩니다. Synonym을 기반으로 한 애플리케이션은 수정 없이 계속 작동합니다.
개인 synonym과 공용 synonym을 모두 생성할 수 있습니다. 개인 synonym은 특정 사용자의 스키마에 있으며 그 사용자가 다른 사람에게 제공 여부를 제어합니다. 공용 synonym은 PUBLIC이라는 사용자 그룹에 의해 소유되며 모든 데이터베이스 사용자가 접근할 수 있습니다.
예제 4-6 공용 Synonym
데이터베이스 관리자가 hr.employees 테이블에 대한 공용 synonym인 people을 생성한다고 가정합니다. 그런 다음 사용자가 oe 스키마에 연결하고 synonym이 참조하는 테이블의 행 수를 셉니다.
SQL> CREATE PUBLIC SYNONYM people FOR hr.employees;
Synonym created.
SQL> CONNECT oe
Enter password: password
Connected.
SQL> SELECT COUNT(*) FROM people;
COUNT(*)
----------
107공용 synonym을 과도하게 사용하면 데이터베이스 통합이 더 어려워지므로 신중하게 사용해야 합니다. 다음 예제와 같이 다른 관리자가 공용 synonym인 people을 생성하려고 하면 데이터베이스에 공용 synonym people이 하나만 존재할 수 있으므로 생성이 실패합니다. 공용 synonym을 과도하게 사용하면 애플리케이션 간 네임스페이스 충돌이 발생합니다.
SQL> CREATE PUBLIC SYNONYM people FOR oe.customers;
CREATE PUBLIC SYNONYM people FOR oe.customers
*
ERROR at line 1:
ORA-00955: name is already used by an existing object
SQL> SELECT OWNER, SYNONYM_NAME, TABLE_OWNER, TABLE_NAME
2 FROM
DBA_SYNONYMS
3 WHERE SYNONYM_NAME = 'PEOPLE';
OWNER SYNONYM_NAME TABLE_OWNER TABLE_NAME
---------- ------------ ----------- ----------
PUBLIC PEOPLE HR EMPLOYEESSynonym 자체는 보안 대상이 아닙니다. Synonym에 대한 객체 권한을 부여할 때 실제로는 기본 객체에 대한 권한을 부여하는 것입니다. Synonym은 GRANT 문에서 객체의 별칭으로만 작용합니다.
