
KAIST 권영진 교수님께서 진행해주신 OS특강
bottom-up보단 top-down이 이해하기 편할 것.
OS는 전형적으로 사람이 design한 것 절대 암기과목이 아님.
design principle(level of indirection)
PA = f(VA)로 mapping (seg, page, seg page) -> PA, VA 분리
#PF, demand paging
하드웨어가 PA로 접근하기 위해 filesystem과 PMA, interrupt
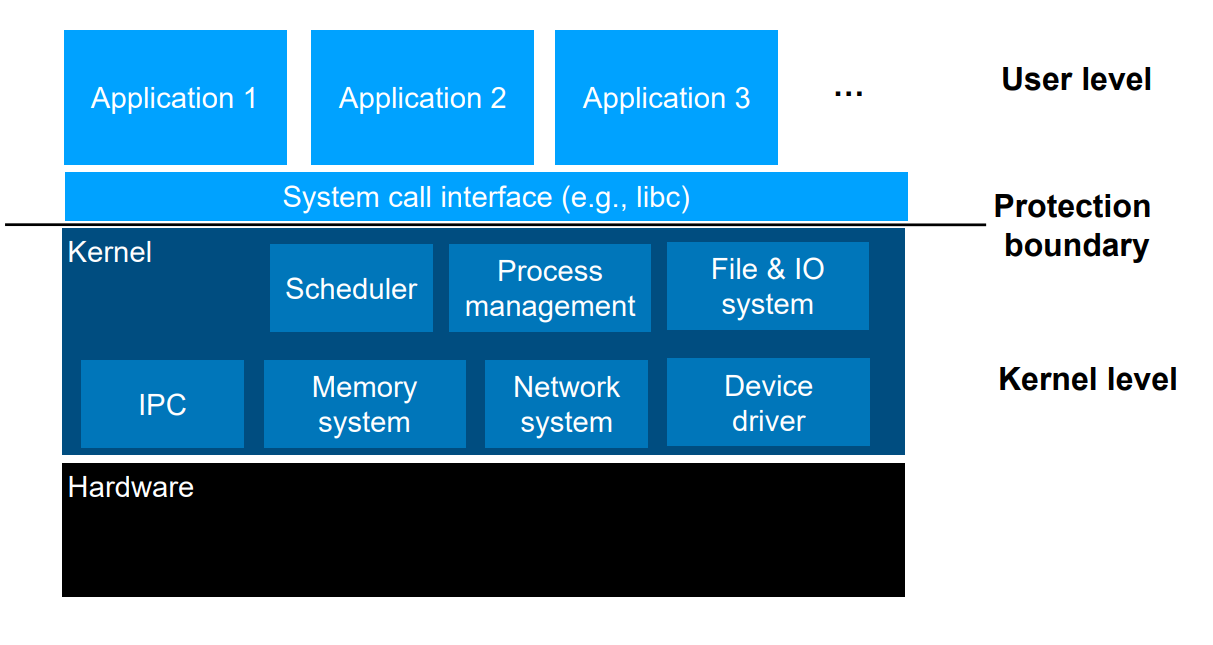
User level은 Kernel level과 Protection boundary로 나뉘어져 있어 접근이 제한되어있다. Kernel level(OS)은 user가 하드웨어를 읽을 수 있게 해준다.
재접근하였을 때 캐싱된 값이면 약 10배 더 빠르게 실행되고, 캐싱되지 않은 값도 demand paging으로 약 2배 더 빠르게 시행된다.
즉, 같은 operation이여도 OS에 따라 다른 성능을 보인다. OS 동작원리.
근본적으로.. 운영체제는 왜 필요할까?
hardware들을 application이 쉽게 이용할 수 있게 API로 expose한다.
ex) SSD를 뜯어보면 명령어만 수백만개. 이를 각각 프로그래밍해서 제어할려면 매우 어렵다.
이게 왜 필요할까..? 생각해보면 Design 관점에서부터 생각해야한다. Abstractions(-> System call), Protection&Isolation(Virtual memory), Sharing(-> Scheduling) 등 top-down으로!
-영상자료: A Philosophy of Software design
CS중 가장 중요한 것은?
Abstraction(추상화)
- Ignore details & easier to understand
Problem decomposition
- Devide and Conquer
-- Building an abstraction that gives an illusion that each application runs on a single machine
let's call it PROCESS
Process는 PC(computer)를 abstract 한 것
-- OS designers provide APIs to applications to use the abstractions
let's call it System call
Abstraction of address space
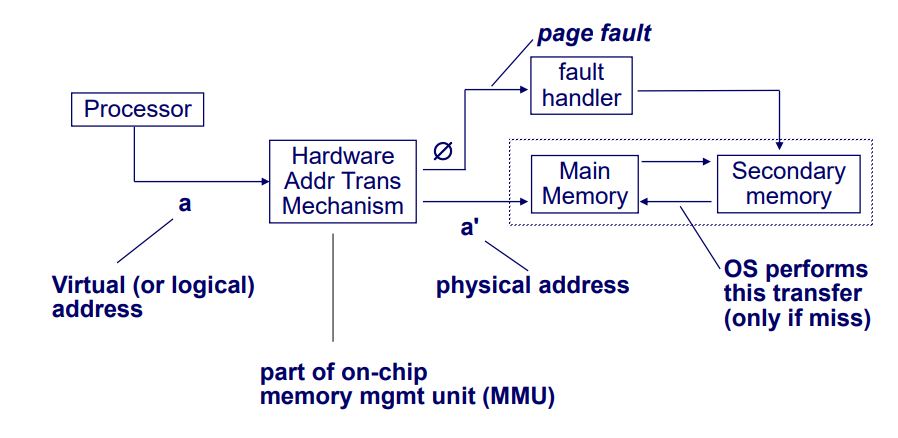
Processor가 virtual(or logical) adress를 Hardware Addr Trans Mechanism(MMU)에 보내어 접근했을 때 OS로 판단한다. physical address로 변환하거나 page fault(ex. seg fault)
page table은 DRAM에 저장되어있다. virtual address를 physical address로 변환하는 것은 하드웨어(MMU)가 하고 그 룰을 OS가 정해준다. (SW도 변환이 가능하지만 너무 느리다.)
이를 Mechanism이라 하고 policy에 따라서 진행된다고 표현한다.
이렇게 분할하여 구현하고 HW, SW로 구분한다.
paging에서의 OS는 policy, hardware는 mechanism을 수행.
When to allocate physical memory
Demand paging : Application first accesses unallocated physical memory
메모리를 필요한 만큼만 할당하고 사용하지 않기 때문에 받는 족족 physical memory에 저장하고 paging하면 낭비가 심하다. 따라서 정말 네가 필요할 때! 만 해주겠다는 방식.
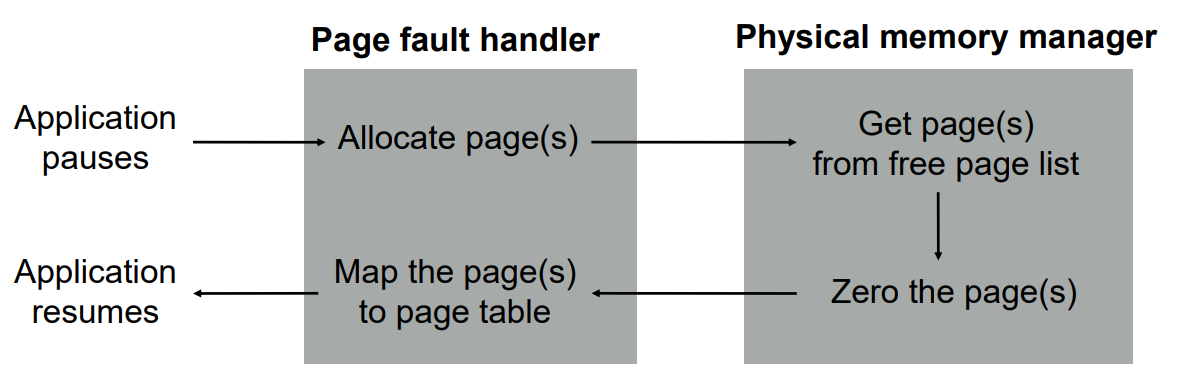
zero page를 안하면 protection rule 위반 -> DRAM을 비워서 넘겨주어야 한다.
malloc의 buff는 0이 아니라 쓰레기값이 저장되어있다. 그 이유는?
- 같은 유닛 내에서 동작하기에 protection이 필요가 없다.
Page fault handling
변수 값을 저장할 때 stack, 주소로 저장할 때는 heap에 저장된다.
하드디스크에서 값을 가져와서 함수는 text(code), 변수는 data에 allocate한다.
그러면 stack이나 heap에 저장된 변수들을 가져올려면?
data나 text(code)는 하드디스크에서 initialize, stack이나 heap은 0으로 initialize하여 저장
memory는 file-backed와 anonymous로 구분된다.
file-backed: code, data
anonymous: heap, stack
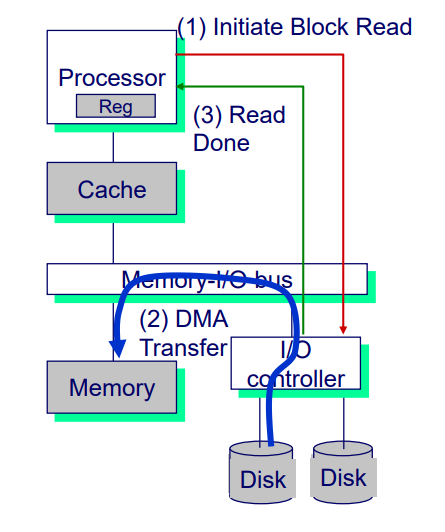
kernel의 page fault handler가 file system에 #block 주소 요청 이 때 DMA(Direct memory Access)로 cpu bypass
-> 이 동작은 cpu 없이 동작하기 때문에 cpu는 모른다! 이를 알려주기 위해 동작하는 mechanism이 interrupt -> OS resumes suspended process
User -> (System call handler) -> Kernel(VA, File, Memory)
커널 수행기간에 갑자기 바뀌는 요소 두 가지: interrupt와 exception
-- 문맥전환은 process간 전환
Abstaction of storage
memory와 storage는 같은 view point로 설계
location of data is identified by offset (lseek 함수)
OS subsystem maps the file to physical storage
let's call it File system
Index로 file의 logical block을 받아서 storage의 physical block으로 mapping
-- SW가 한다. 속도차이가 무의미하다.
Index의 종류가 어마무시하게 많다. ex) indirect inode pointer, extent tree, b+ tree, FAT
memory design과 차이점 발생
internal nodes는 어디에 저장되어야 할까? -- storage에 있다가 memory에 올라온다.
-종료되었을 때 메모리가 보존되어야하기 때문
indexing에 hardware 도움 필요 x
physical block에 allocate할 때는?
-when storing the file ( fsync() )
optimization for slow storage device
-DRAM cachis -> page cache
file system overview
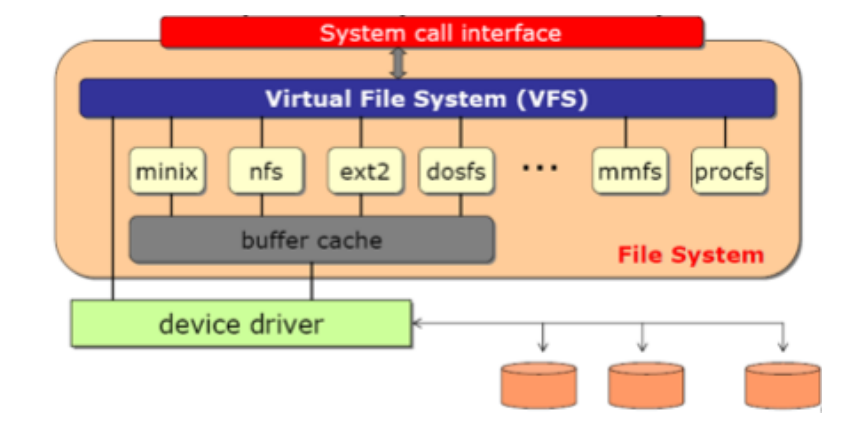
VFS(virtual file system) (pintOS엔 없음 linux에 있음)
ㄴ POSIX(Open, read, write, fweek, close)
왜 필요할까? 복잡한 개별 file system의 abstraction. 하나의 공통된 interface로 가능하다. read/write하면 각 필요한 시스템으로 가서 read/write.
Layer of abstraction
Problems of using buffer cache
프로그래머 입장에서 반드시 지켜야 함
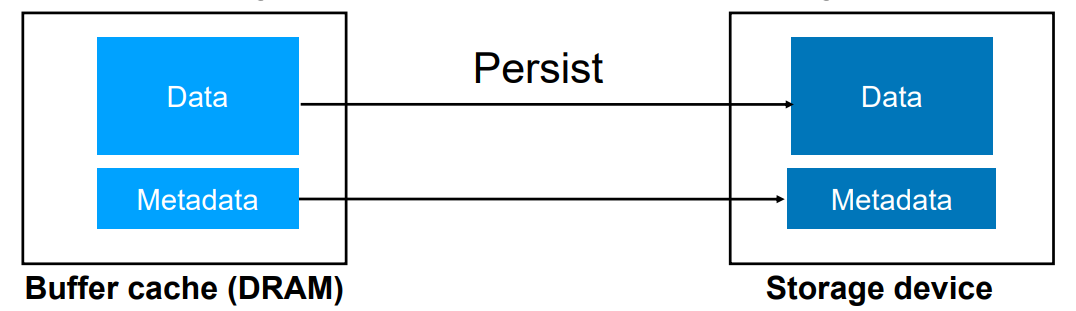
데이터를 page cachce에 성능때문에 반드시 올리는데 DRAM에 올라가고(Data와 Metadata) 어느 시점에 반드시 Storage device로 Persist로 올라가야한다.
어느 시점이 최신 시점일까? 당연히 DRAM. 그리고 한쪽이 변형될 수 있다. Consistant하게 해야한다.
fsync 했을 때 data persisted 됨.
Consistency: Atomicity and Durability
Atomicity: all or nothing. data가 전부 써지던가 or 안써지던가. 일부만 써지는 것은 Not Atomically한 것.
Durabillity: storage에 반드시 persist 하는 것.
Non-atomic update

OS는 순서대로 저장하지 않음 OS may reorder data when writing to storage.
Crash consistency example
Foo를 Bar로 1B씩 update할 수 있다면?
sigle write
write(/a/log)중간에 crash가 난다면? B, a, r중 뭐가 먼저 써질지도 모른다. Fao, For ...
때문에 우리는 Foo던 Bar던 하나만 출력하게 해야한다.
-> Rollback logging(WAL)
creat(/a/log)
write(/a/log, "Foo")
write(/a/file, "Bar")
unlink(/a/log)는 중하수.. 이렇게 짜면 틀림
why? Reordered가 된다! => 또 Fao나 For.. 가 나올 수 있다.
-> Rollback logging with ordering
creat(/a/log)
write(/a/log, "Foo")
fsync(/a/log)
write(/a/file, "Bar")
fsync(/a/file)
unlink(/a/log)는 중수.. 버그가 또 생김!
ex) vi로 directory 접근하면?
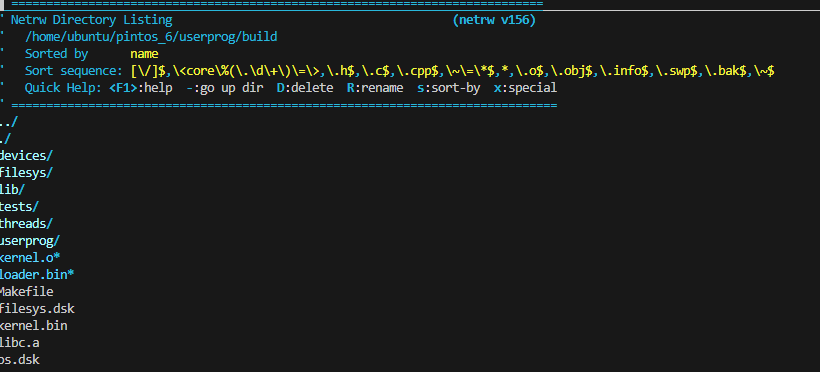
directory 정보가 나오고 disk로 안넘어감 즉 /a/ may not contain /a/log
file의 존재는 있는데 접근이 안됨
-> Correct version
creat(/a/log)
write(/a/log, "Foo")
fsync(/a/log)
fsync(/a/)
write(/a/file, "Bar")
fsync(/a/file)
unlink(/a/log)