- OLTP 시스템에서 인덱스 설계는 매우 중요.
- 인덱스튜닝, SQL튜닝의 하이라이트.
1. 인덱스 설계가 어려운 이유
- 인덱스가 많을경우 발생하는 문제
- DML성능 저하 (-> TPS 저하)
- 데이터 베이스 사이즈 증가(-> 디스크공간 낭비)
- 데이터베이스 관리 및 운영 비용 상승(백업, 복제, 재구성을 위한 운영비용)
- 한테이블에 인덱스 여섯개가 있으면, 신규 데이터 1건입력할때마다 여섯개 인덱스에도 데이터를 입력해야한다.
- 테이블과 다르게 인덱스는 정렬을 유지해야하므로, 수직적 탐색을 통해 입력할 블록부터 찾는다.
- 찾은 블록에 여유공간이 없으면 인덱스 분할(Index Split)도 발생한다.
개발단계 최적 인덱스 설계 중요성
- 운영중 인덱스 변경시에는 영향받는 SQL을 모두 찾아 성능을 검증해야한다.
- 시스템 개발단계에서는 비교적 쉽계 인덱스변경이 가능하지만, 운영환경에서는 일이커진다.
(금융권에선 불가능에 가깝다) - 신규인덱스는 변경영향도가 적다, BUT 신규인덱스를 추가할수록 시스템수준 TPS가 나빠진다.
2. 가장 중요한 두 가지 선택 기준
- 가장 일반적인 방식은 INDEX RANGE SCAN, 이를위해 선두컬럼 조건절 사용이 필수.
So, 결합 인덱스 구성시 첫번째 기준은 조건절에 항상 사용하거나, 자주사용하는 컬럼을 선정 - 두번째 기준은 그렇게 선정한 컬럼중 등치(=)조건으로 자주 조회하는 컬럼을 앞쪽에 두어야 한다.
3. 스캔 효율성 이외의 판단 기준
그외 인덱스 설계시 고려해야할 항목
- 수행빈도 (가장중요)
- 업무상 중요도
- 클러스터링 팩터
- 데이터량
- DML부하 (=기존 인덱스 개수, 초당 DML발생량, 자주갱신하는 컬럼 포함 여부)
- 저장공간
- 인덱스 관리비용.
수행빈도가 중요한 고려항목중 하나
- 자주수행하지않는 SQL이면 인덱스스캔에 약간이 비효율이 있어도 큰문제는 아님.
- 수행빈도가 높은 SQL에서는 인덱스 설계 기준들을 이용해 최적의 인덱스를 구성해야한다 > 시스템전체성능과 관련
- 드라이빙테이블(OUTER TABLE)의 인덱스는 인덱스스캔 과정에 비효율이있더라도 큰문제가 아닐수 있지만
INNER쪽 테이블의 스캔과정에 비효율이 있을경우 성능에 큰 문제가 생길 수 있다 - OUTER 테이블추출건수만큼 INNER 테이블에 액세스하기때문에 횟수만큼 비효율적 스캔을 반복한다.
- 수행빈도가 매우높은 SQL이라면 인덱스를 최적으로 구성해줘야한다
- NL조인의 INNER쪽 인덱스는 등치조건 컬럼을 선두에 두는것이 중요하고, 될수있으면 테이블 액세스없이 인덱스에서 필터링을 마치도록 구성해야 한다.
데이터량
- 데이터량이 적다면 굳이 인덱스를 많이 만들필요가없다, FULL SCAN으로도 충분히 빠르기 때문
- 데이터량이 적을때 인덱스를 많이 만들어도 저장공간이나 트랜잭션 부하측면에서 문제될게없다
- 초대용량테이블은 INSERT도 많다. 초당DML발생량은 트랜잭션 성능(TPS)에 직접적 영향
- 이때 진정한 튜닝전문가가 빛을 발한다. 인덱스 하나를 줄였을때 시스템에 미치는 영향은 적지않다.
4. 공식을 초월한 전략적 설계
- 조건절 패턴이 10개일때, 최적을달성해야할 핵심적 액세스경로 1~2개를 선택해 최적인덱스를 설계하고
- 나머지 액세스경로는 약간 비효율이 있더라도 목표성능을 만족하는 수준으로 인덱스를 구성할 수 있어야한다.
- 업무상황을 이해하고 나름의 판단기준으로 왜그렇게 선택했는지 근거를 답할 수 있어야 한다.
- 인덱스 개수를 최소화하면, 사용빈도가 높거나 중요한 액세스경로가 새로 도출되었을때 최적의 인덱스를 추가할 여유도 생긴다.
5. 소트 연산을 생략하기 위한 컬럼 추가
- 인덱스는 항상 정렬상태를 유지하므로 ORDER BY, GROUP BY 를 위한 소트연산을 생략해준다.
- 조건절에 들어가지않는 컬럼이더라도 소트 연산을 생략할 목적으로 인덱스에 추가함으로써 성능개선을 도모할 수 있다.
- 등치조건이 아닌 조건절 컬럼들은 반드시 ORDER BY컬럼보다 뒤쪽에두어야 소트 연산을 생략할 수 있다.
I/O를 최소화하면서 소트연산을 생략하는 인덱스 구성 공식
- 등치조건 연산자로 사용한 조건절 컬럼 선정
- ORDER BY 절에 기술한 컬럼 추가
- 등치(=) 연산자가 아닌 조건절 컬럼은 데이터 분포를 고려해 추가 여부 결정.
(데이터가적은 조건절 컬럼은 인덱스에 추가하는게 좋다 > 테이블 랜덤 액세스를 줄일수 있기 때문
많으면 굳이 추가하지않아도됨 > 테이블에서 필터링할때와 큰 성능차이가 없음)
IN 조건은 '='이; 아니다.
SELECT 고객번호, 고객명, 거주지역, 혈액형, 연령
FROM 고객
WHERE 거주지역 = '서울'
AND 혈액형 IN ('A','O')
ORDER BY 연령
--인덱스는 [거주지역+혈액형+연령]
- IN조건이 등치조건이 되려면 IN-List Iterator방식으로 풀려야한다. (union all로 묶는것.)
- 그러면 in조건은 '='이 됐지만 union all위아래 두집합을 묶어 '연령'순으로 정렬하는 문제가 남는다.
- 소트연산을 생략하려면 union all위쪽 실행하고 이어 아래실행했을때 그 결과가 연령순으로 정렬되야한다.
그게 가능하려면 서울에 거주하는 모든 A형이 O형보다 어려아한다. - 불가능한 일이므로 옵티마이저는 소트연산을 생략하지 않는다.
- 소트연산을 생략하려면 IN조건이 IN-List Iterator 방식으로 풀려선 안된다, 즉 IN조건절을 인덱스 액세스 조건으로 사용하면 안된다, 필터조건으로 사용해야한다, 따라서 인덱스를 [거주지역+연령+혈액형] 순으로 구성해야 한다
6. 결합 인덱스 선택도
- 인덱스 생성여부 결정시 선택도가 충분히 낮은지갖 중요한 판단기준
- 선택도란 전체레코드중 조건절에 의해 선택되는 레코드 비율
- 선택도에 총 레코드수를 곱해 카디널리티를 구한다.
- 인덱스 선택도는 인덱스컬럼을 모두 =로 조회할때 평균적으로 선택되는 비율
- 선택도가 높은 인덱스는 생성해봐야 효용가치가 별로 없다. 테이블 액세스가 많이 발생하기때문
- 아래는 계약 ID와 취급지점ID, 두컬럼에 대한 카디널리티를 조회하는 쿼리
SELECT COUNT() AS NDV, MAX(CNT) AS MX_CARD, MIN(CNT) MN_CARD, AVG(CNT) AS AVG_CARD
FROM (
SELECT 계약ID, 취급지점ID, COUNT() CNT
FROM 계작조직
WHERE (계약ID IS NOT NULL OR 취급지점 IS NOT NULL)
GROUP BY 계약ID, 취급지점ID
)
컬럼순서 결정시, 선택도 이슈
- 인덱스설계시 항상 사용하는 컬럼을 앞쪽에 두고 그중 '='조건을 앞쪽에 위치시킨다.
- 그중 선택도가 낮은 컬럼을 앞쪽에 두려는 노력은 의미없거나 오히려 손해일 수 있따.
- 고객등급, 고객번호 둘다 필수 '='조건이면 순서는 크게상관없지만, 둘중하나이상이 조건절에서 누락되거나 범위검색 조건일 수 있으면 복잡해짐
- 고객번호는 필수인데 고객등급이 조건절에서 누락되거나 범위검색조건일수 있으면 고객등급을 앞쪽에 두는것이 유리 INDEX SKIP SCAN이나 IN-List조건을 활용할 수 있기 때문.
- 인덱스 생성여부를 결정할 때는 선택도가 매우중요, 컬럼간 순서를 결정할때는 선택도보다 필수조건여부, 연산자 형태가 더 중요한 판단기준, 어느컬럼을 앞에둘지는 상황에 따라 판단
7. 중복 인덱스 제거
- P244 중복제거 실습 반복해서 해볼것
- 중복인덱스 제거방법
- 완전중복(한 인덱스의 컬럼이 다른인덱스의 컬럼을 모두 포함할때)일경우 인덱스 삭제
- 완전중복은아니지만 선두컬럼의 카디널리티가 매우 낮을때(불완전 중복)
EX)선두컬럼으로 필터시 평균 5건정도가 조회된다면 후행컬럼을 덕지덕지붙여 여러 인덱스를 만들필요가없다.
8. 인덱스 설계도 작성
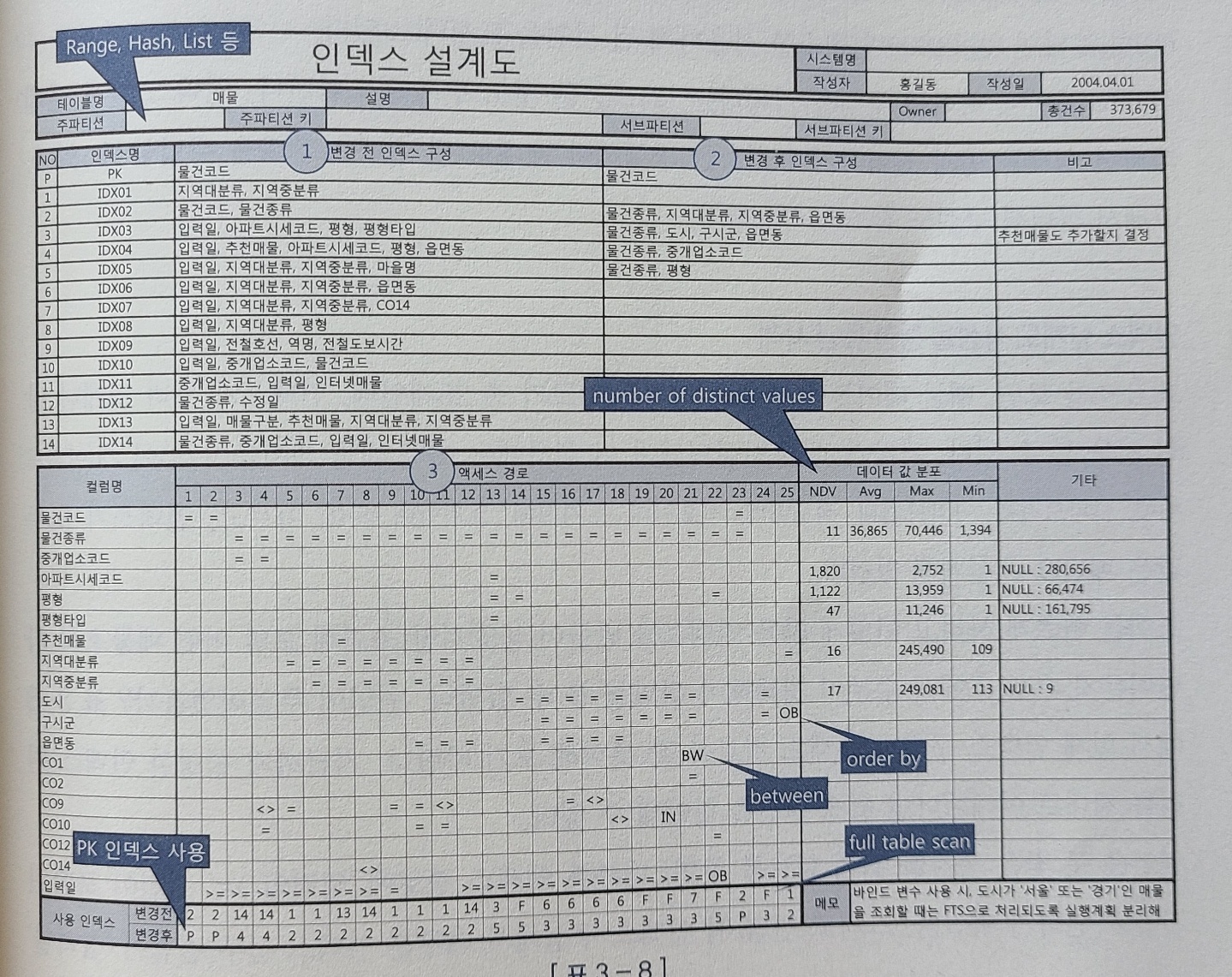

늙어가면서 기억을 남기는 개발자